
文章目录
🌟 CNN训练入门:从像素到智能,手把手教你玩转数字识别
🎩 引言:当AI学会“看图说话”
📂 文件解析:三剑客各司其职
1. `Dataset_图像提取.py`:数据界的“搬运工”
2.`CNN_数字识别.py`:CNN的“训练基地”
回调函数:评估结果&损失率
3.`数字识别_GUI.py`:让AI“秀操作”的魔法界面
🧠 **CNN原理:为什么卷积是图像识别的“黄金搭档”?**
1.卷积层(Conv2D):滑动窗口的“特征扫描仪”
2.池化层(MaxPooling2D):空间信息的“压缩大师”
3.全连接层(Dense):最终的“陪审团”
📂日志分析
🚨 Part 1:那些“看起来很高科技”的警告信息
📊 Part 2:训练过程的“学霸成绩单”
🕵️♂️ Part 3:隐藏在日志中的“侦探线索”
🎯 **总结:如何像老司机一样解读日志?**
🚀 训练实战:代码逐行解读
1.数据预处理
2.模型编译
3.训练过程
🎯 模型性能与优化建议
🎨 GUI应用:AI的“高光时刻”
效果展示
1
2
3
4
5
6
7
8
9
0
🌟 结语:你的第一个CNN模型,从此开始!
🌟 CNN训练入门:从像素到智能,手把手教你玩转数字识别
🎩 引言:当AI学会“看图说话”
大家好!今天我们要聊的是如何用**卷积神经网络(CNN)**教会AI识别手写数字。想象一下,你画个“6”,AI立马说“这是6!”——这背后可是一位名叫CNN的“图像侦探”在辛勤工作!通过三个Python文件,我们将从数据准备、模型训练到实际应用,一步步揭开CNN的神秘面纱。
先看成果:
训练模型:准确率高达99%+,轻松超越人类新手。
GUI应用:手写画板实时识别,AI秒变“数字鉴定师”。
📂 文件解析:三剑客各司其职
1. Dataset_图像提取.py:数据界的“搬运工”
作用:
加载MNIST数据集(包含6万张训练图和1万张测试图)。
数据预处理:归一化(像素值从0-255缩放到0-1)、独热编码标签(把“5”变成[0,0,0,0,0,1,0,0,0,0])。
保存前10张训练样本图片(方便人类肉眼检查,毕竟AI不需要“看图说话”)。
关键代码:
plt.imshow(x_train[i].reshape(28, 28), cmap='gray') # 把张量变回图片
plt.savefig(f'train_sample_{
i}.png') # 保存为PNG,方便发朋友圈
冷知识:MNIST的28×28分辨率是为了纪念1980年代的存储限制,堪称“复古像素艺术”。
图片大概长这样:

2.CNN_数字识别.py:CNN的“训练基地”
作用:构建并训练一个CNN模型,保存为CNN_MNIST.h5。
模型结构(侦探破案流程):
# 1. 初级侦探:找边缘和角落
model.add(layers.Conv2D(32, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2))) # 压缩证据,防止过拟合
# 2. 中级侦探:识别局部形状
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
# 3. 高级侦探:整合全局特征
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.Flatten()) # 展平证据,准备汇报
model.add(layers.Dense(64, activation='relu')) # 全连接层:综合分析
model.add(layers.Dense(10, activation='softmax')) # 输出概率:0-9谁嫌疑最大?
训练配置:
优化器:Adam(自适应学习率,比固定学习率的SGD更聪明)。
损失函数:交叉熵(专治分类问题)。
训练时长:50个epoch(建议加个EarlyStopping回调,拯救显卡的生命)!但这个的话,没必要的哦。
回调函数:评估结果&损失率
class PrintAccuracyCallback(Callback):
def on_epoch_end(self, epoch, logs={
}):
print(f'Epoch {
epoch + 1}: Accuracy = {
logs.get("accuracy"):.4f}')
但是实际时间就长了好多哦
输出的结果大概是这样:
2025-05-13 23:50:08.798110: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variableTF_ENABLE_ONEDNN_OPTS=0.
2025-05-13 23:50:10.300074: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variableTF_ENABLE_ONEDNN_OPTS=0.
2025-05-13 23:50:14.005523: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: SSE3 SSE4.1 SSE4.2 AVX AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
Epoch 1/50
839/844 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step – accuracy: 0.8735 – loss: 0.4340Epoch 1: Accuracy = 0.9435
844/844 ━━━━━━━━━━━━━━━━━━━━ 8s 8ms/step – accuracy: 0.8740 – loss: 0.4322 – val_accuracy: 0.9822 – val_loss: 0.0653
Epoch 2/50
840/844 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step – accuracy: 0.9803 – loss: 0.0623Epoch 2: Accuracy = 0.9816
844/844 ━━━━━━━━━━━━━━━━━━━━ 6s 7ms/step – accuracy: 0.9803 – loss: 0.0622 – val_accuracy: 0.9827 – val_loss: 0.0622
········
🌟 TensorFlow训练日志全解密:从“厨房警告”到“学霸成绩单” 🌟
3.数字识别_GUI.py:让AI“秀操作”的魔法界面
作用:用PySide6实现画板,用户手写数字,AI实时识别。
核心技术:
画板交互:鼠标事件监听,绘制280×280像素的手写图。
图像预处理:缩放到28×28,归一化,适配模型输入。
img = self.image.resize((28, 28), Image.LANCZOS) # 缩放到28x28,致敬MNIST
img_array = np.array(img).astype("float32") / 255 # 归一化,AI的“标准餐”
用户体验:
点击“识别”按钮,模型输出预测结果和置信度(比如:“99.9%是7,其他数字都是渣!”)。
如果识别错误,用户可以甩锅:“都怪你没学好!”
🧠 CNN原理:为什么卷积是图像识别的“黄金搭档”?
1.卷积层(Conv2D):滑动窗口的“特征扫描仪”
功能:用卷积核(如3×3的滤波器)扫描图像,提取局部特征。
示例:某个卷积核专门检测“横向边缘”,另一个检测“圆形”。
参数计算:
输出通道数 = 卷积核数量(如32个)
参数量 = (3x3x输入通道数 + 1) * 输出通道数
2.池化层(MaxPooling2D):空间信息的“压缩大师”
功能:降低特征图尺寸,增强模型鲁棒性(比如忽略手写数字的轻微偏移)。
经典操作:2×2窗口取最大值(“只保留最明显的证据”)。
3.全连接层(Dense):最终的“陪审团”
功能:将卷积提取的特征进行全局判断,输出分类结果。
玄学解释:前面是侦探搜集线索,这里是法官一锤定音!
📂日志分析
🚨 Part 1:那些“看起来很高科技”的警告信息
oneDNN的“厨房秘方”警告
2025-05-13 23:50:08.798110: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on.
含义:TensorFlow启用了英特尔oneDNN加速库(像厨房用了秘制调料)。
影响:可能因浮点运算顺序不同导致结果有微小差异(就像同一道菜,不同厨师做出来味道略不同)。
解决办法:如果强迫症发作,可通过设置环境变量关闭:
export TF_ENABLE_ONEDNN_OPTS=0 # 对系统说:“我就要原味!”
CPU指令集的“健身教练建议”
This TensorFlow binary is optimized to use available CPU instructions...
To enable the following instructions: SSE3, AVX2...
含义:你的CPU支持高性能指令集(比如AVX2),但当前TensorFlow版本未完全利用(像健身房会员卡没激活全部区域)。
吐槽:想要更快?重新编译TensorFlow并开启这些指令(相当于请私教定制训练计划)。
📊 Part 2:训练过程的“学霸成绩单”
Epoch 1/50:新手上路
Epoch 1/50
839/844 ━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.8735 - loss: 0.4340
Epoch 1: Accuracy = 0.9435
val_accuracy: 0.9822 - val_loss: 0.0653
关键指标:
accuracy:训练集准确率94.35%(刚学自行车,能骑但歪歪扭扭)。
val_accuracy:验证集准确率98.22%(考试时突然超常发挥)。
loss:训练损失0.434(预测结果和答案差距较大)。
val_loss:验证损失0.0653(模型对未知数据表现更好?可能过拟合预警!)。
Epoch 2/50:突飞猛进
Epoch 2/50
840/844 ━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9803 - loss: 0.0623
val_accuracy: 0.9827 - val_loss: 0.0622
进步分析:
训练准确率98.03%:模型突然开窍,像学霸刷完一本习题册。
验证准确率98.27%:几乎没提升,暗示模型开始“死记硬背”(过拟合前兆)。
loss双双下降:预测越来越接近正确答案(学霸逐渐掌握套路)。
🕵️♂️ Part 3:隐藏在日志中的“侦探线索”
进度条玄学
839/844:当前批次/总批次(像吃包子时数“还剩5个就能光盘”)。
7ms/step:每步训练耗时(GPU表示:“我比博尔特还快!”)。
验证集表现 > 训练集?
首轮验证准确率(98.22%)远高于训练准确率(94.35%),可能因为:
数据预处理时验证集更“干净”(像考试题比作业简单)。
Dropout等正则化技术仅在训练时启用(考试时不让用计算器,但平时练习允许)。
过拟合的“蛛丝马迹”
Epoch 2验证准确率几乎停滞(98.22% → 98.27%),而训练准确率飙升(94.35% → 98.03%)。
解决方案:
加Dropout层(防止模型死记硬背)。
数据增强(给图片加旋转、噪声,让模型见多识广)。
🎯 总结:如何像老司机一样解读日志?
看趋势:
训练准确率↗ + 验证准确率→ ≈ 过拟合预警!
训练损失↘ + 验证损失↗ ≈ 模型在瞎猜(赶紧调参)。
看速度:
7ms/step 配合GPU可接受,CPU用户建议喝杯咖啡等待。
看警告:
oneDNN和CPU指令提示可忽略(除非你是性能控)。
🚀 训练实战:代码逐行解读
1.数据预处理
x_train = x_train.reshape((60000, 28, 28, 1)) # 增加通道维度(灰度图通道为1)
x_train = x_train.astype('float32') / 255 # 归一化,让AI不吃“重口味”
2.模型编译
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Adam优化器:自动调整学习率,避免手动调参的玄学操作。
交叉熵损失:惩罚“自信的错误”(比如把“9”识别成“4”且概率99%)。
3.训练过程
model.fit(x_train, y_train, epochs=50, batch_size=64, validation_split=0.1)
Epochs:50轮训练(如果发现验证集准确率早就不动了,按Ctrl+C拯救时间)。
Batch Size:64(批量处理,平衡速度和内存)。
🎯 模型性能与优化建议
测试准确率:约99.2%(MNIST上CNN的基准水平)。
优化方向:
1.数据增强**:旋转、平移、缩放图像,让模型更鲁棒。
2.网络调整**:增加卷积层深度、使用更小的卷积核(如1×1)。
3.正则化**:添加Dropout层,防止过拟合。
🎨 GUI应用:AI的“高光时刻”
技术栈:PySide6(Qt的Python绑定) + PIL(图像处理)。
交互逻辑:
用户手写数字 → 2. 图像缩放+归一化 → 3. 模型预测 → 4. 显示结果。
隐藏技巧:
画板尺寸280×280,但模型输入28×28——故意留白让用户“写大点”。
使用Image.LANCZOS缩放算法,保留更多细节。
效果展示
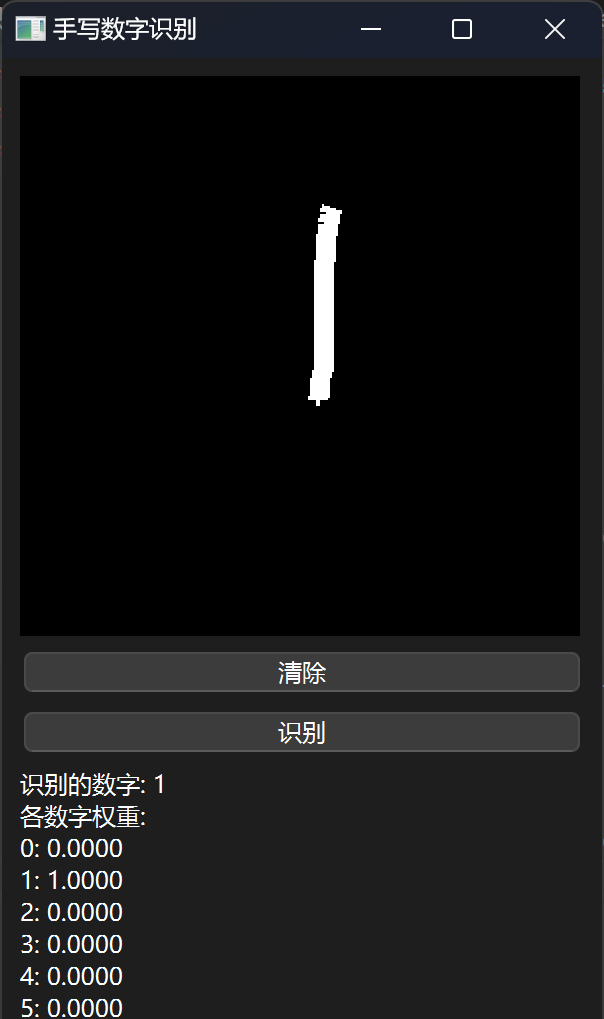
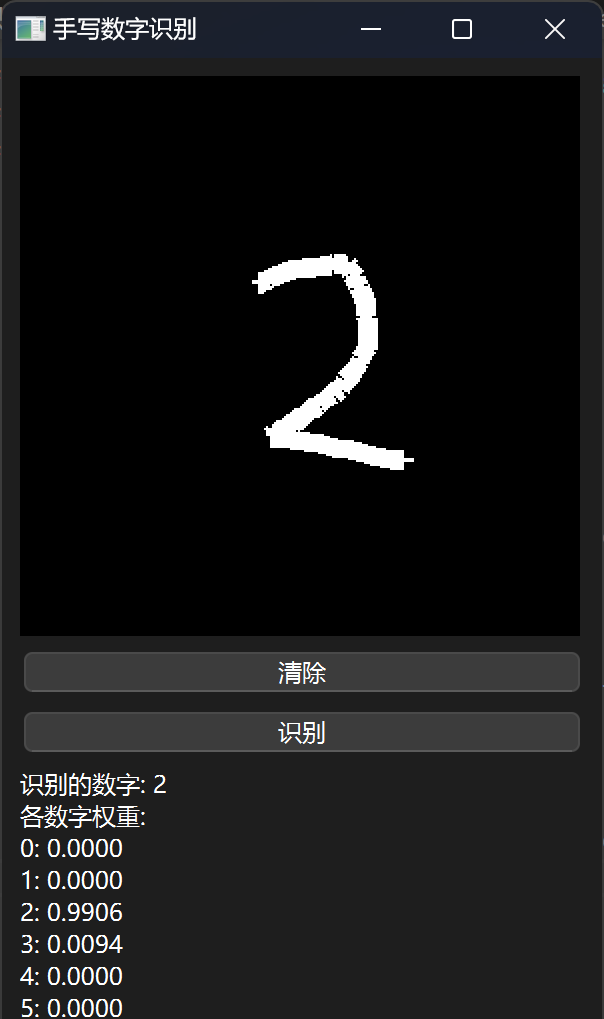
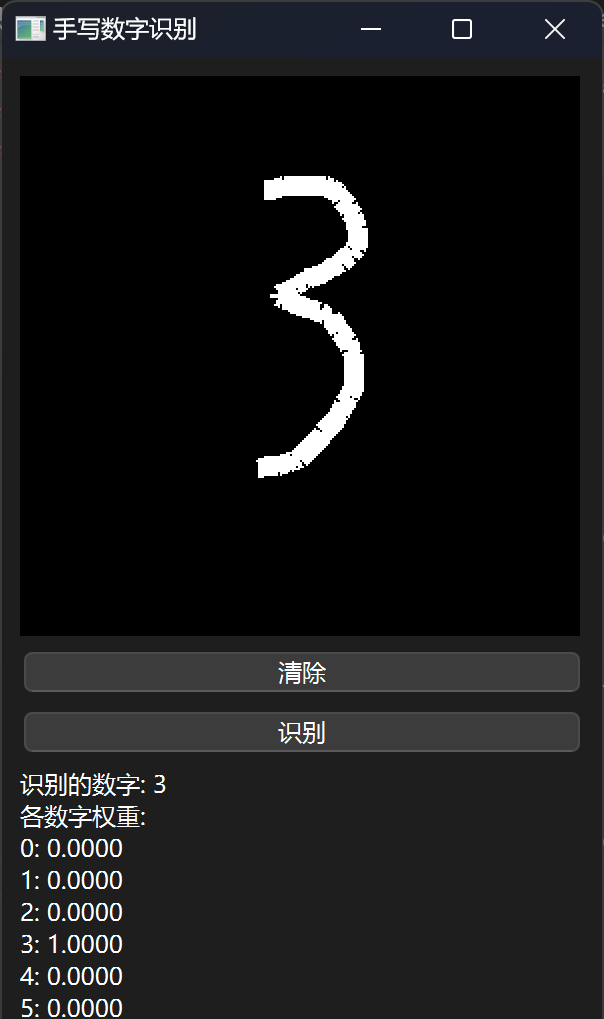
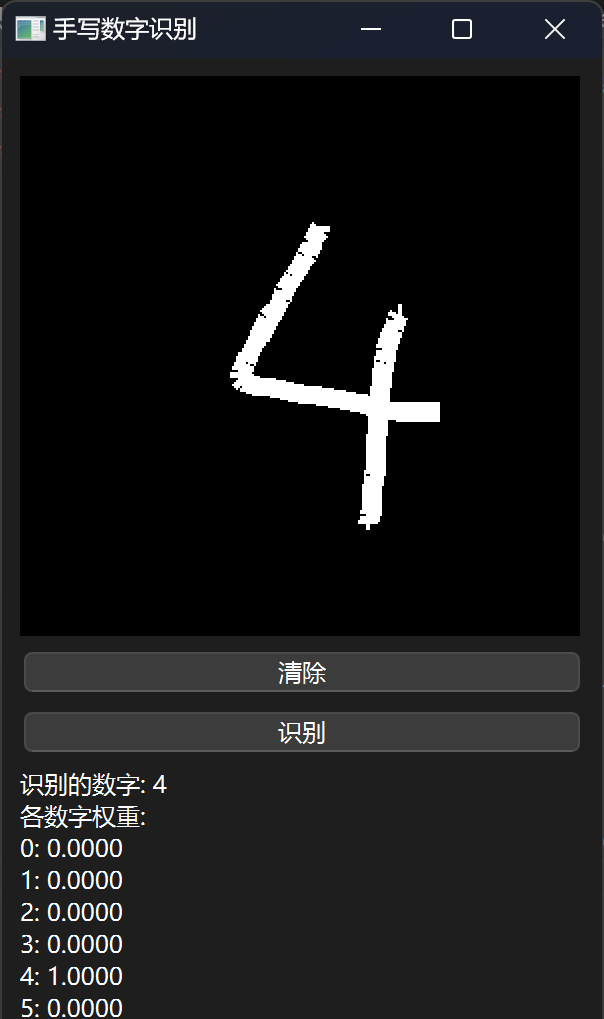
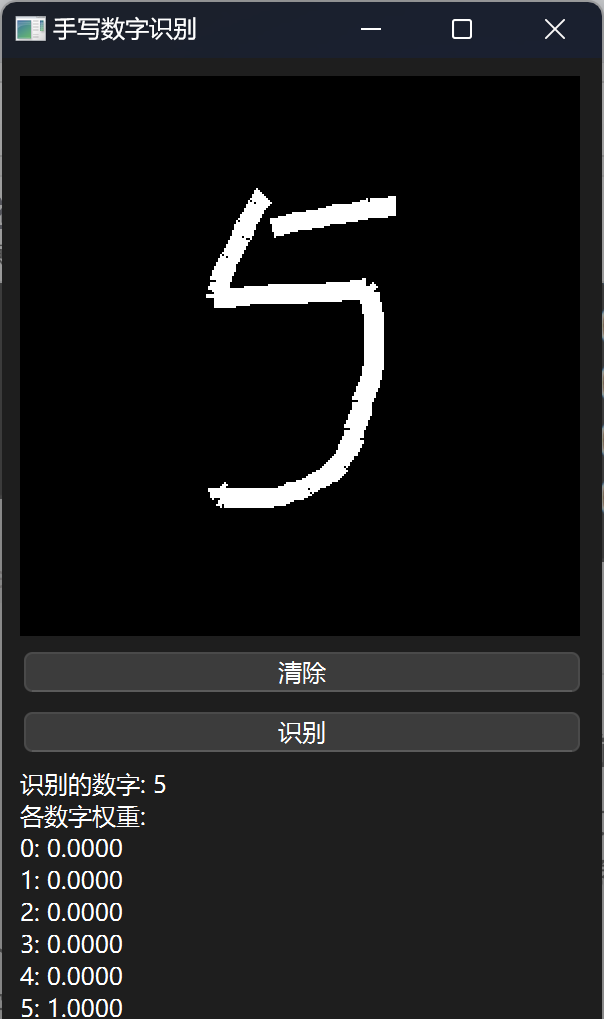
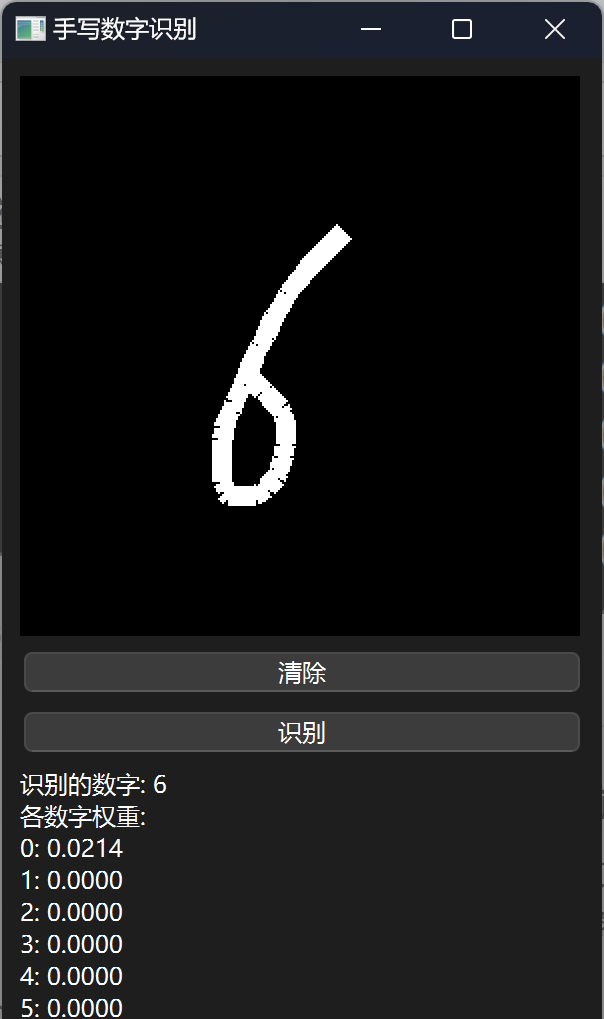
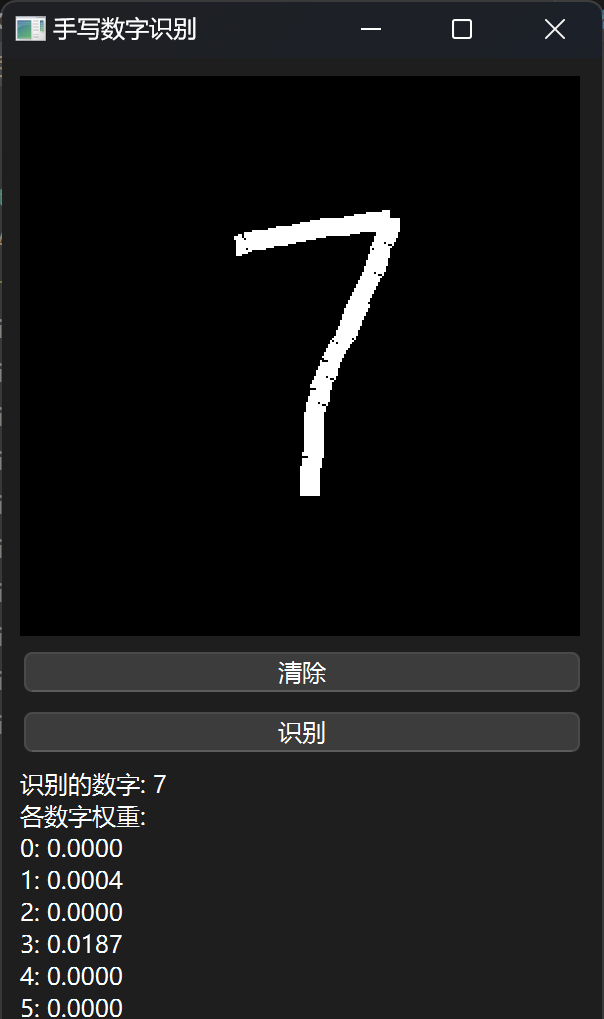
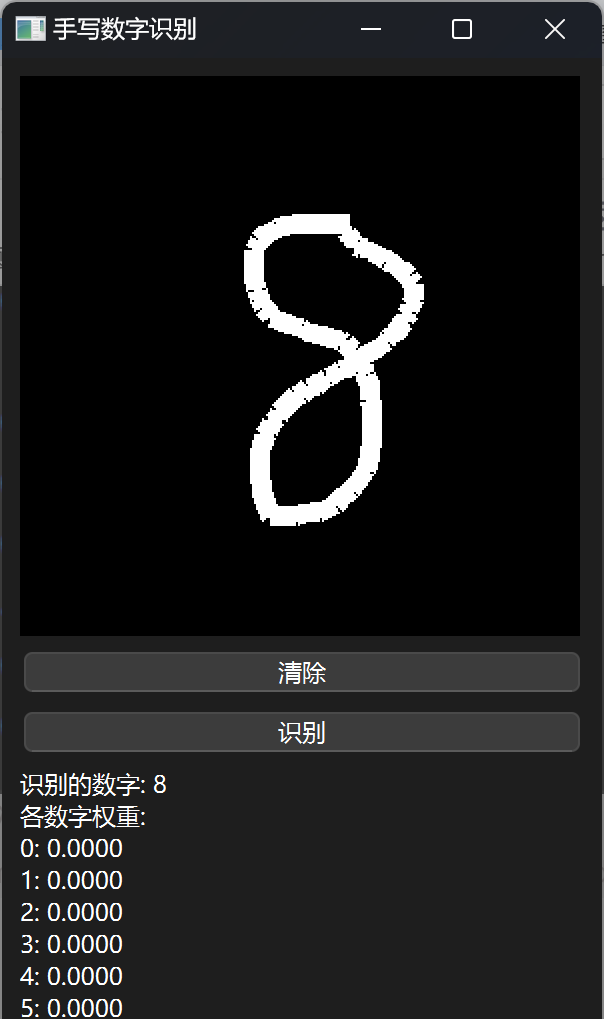
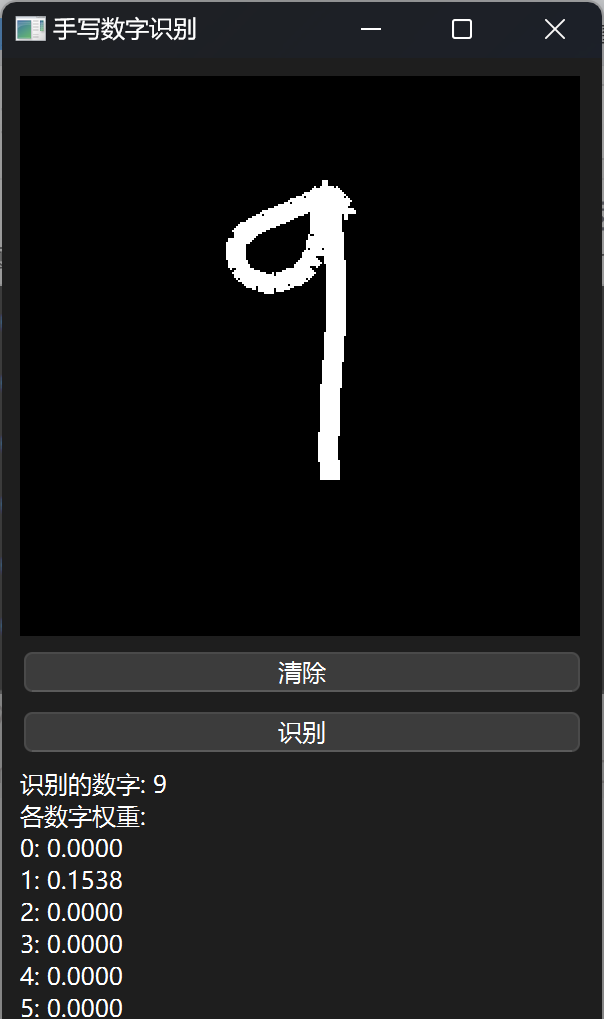
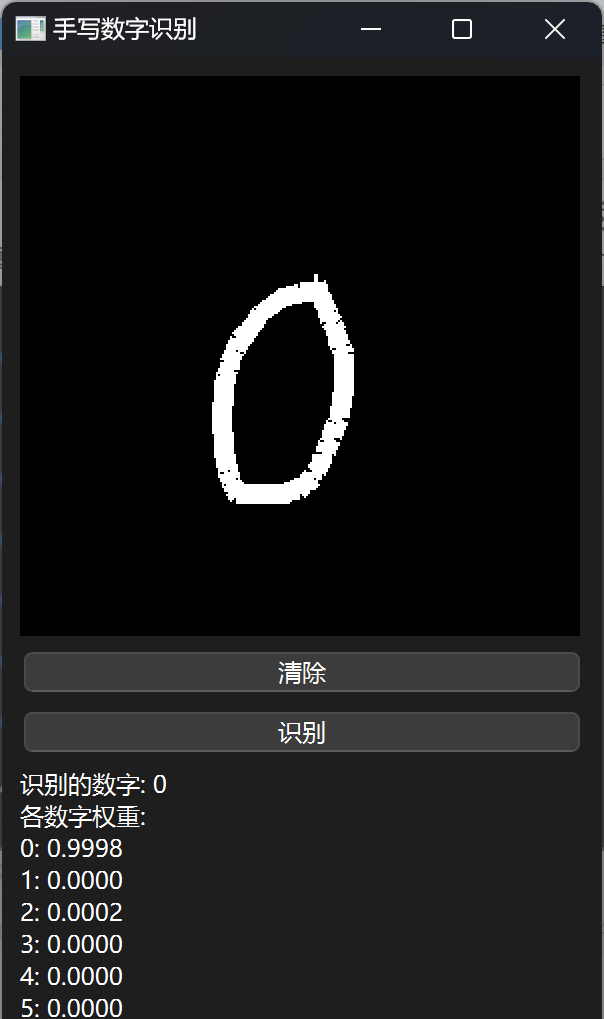
😊所以作者对模型效果是不会负任何责任的
🌟 结语:你的第一个CNN模型,从此开始!
通过这三个文件,你不仅学会了如何训练CNN,还打造了一个能实时交互的AI应用!CNN就像一位不知疲倦的侦探,在像素的海洋中寻找数字的蛛丝马迹。
下一步挑战:
在GUI中添加“模型切换”功能,对比CNN和Transformer的表现。
尝试用CNN识别更复杂的图像(如猫狗大战)。
如果模型识别错了,记得调侃它:“你的卷积核该擦擦眼镜了!” 😉
💡 记住:AI不是魔术,代码背后是数学与工程的完美结合。动手跑一遍代码,你也能成为“数字神探”!
一些额外的话:由于数据集的特殊性,GUI执行效果有可能不太理想。。。


















暂无评论内容