
目录
一、MySQL 的配置
1.1 开启并配置 Binlog
1.2 重启 MySQL 服务
1.3 赋值数据同步权限
二、安装并配置 Canal
2.1 下载并解压Canal
2.2 修改配置
2.2.1 结合 Kafka
2.2.1.1 修改canal.properties
2.2.1.2 修改instance.properties
2.2.2 结合 RabbitMQ
2.2.2.1 修改canal.properties
2.2.2.2 修改instance.properties
2.3 拷贝 jar 包
2.4 启动 Canal
三、Canal 执行原理
四、常见错误
4.1 Unrecognized VM option 'PermSize=128m'
一、MySQL 的配置
1.1 开启并配置 Binlog
找到 MySQL 配置文件,Linux 默认配置在 /etc/my.cnf 文件中,而 Windows 在安装目录的路径如下:
MySQL 8.0 及更高版本:C:ProgramDataMySQLMySQL Server 8.0my.ini
MySQL 5.7 及更低版本:C:Program FilesMySQLMySQL Server 5.7my.ini (具体路径可能因安装时的选择而有所不同)
需要注意的是,ProgramData 可能是一个隐藏文件夹,您可能需要在文件资源管理器中设置显示隐藏的文件和文件夹才能看到它。
修改成如下配置(基于 MySQL8)
log-bin="AOYUNLAN"
binlog_format=ROW
binlog-do-db=cloud其中:binlog-do-db 指的是需要同步的数据库名,需改改为你自己需要同步的数据库名,如果此项不配置,则所有数据库都会开启 Binlog,如果需要指定开启多个只需要如下配置即可:
binlog-do-db=cloud
binlog-do-db=cloud2
binlog-do-db=cloud3binlog_format 支持三种数据库格式:
STATEMENT (语句模式):基于 SQL 语句的复制。binlog 中记录的是执行的 SQL 语句。
优点:节省空间,因为只记录语句,不需要记录每一行数据的变化。
缺点:某些情况下可能会导致主从数据不一致,例如使用了不确定函数,如 NOW() 、 RAND() 或依赖于上下文的语句(如 LIMIT 基于行的偏移量)。
ROW (行模式):基于行的复制。binlog 中记录的是每行数据的变化。
优点:数据的一致性更好,几乎不会出现主从数据不一致的情况。
缺点:会产生大量的日志,特别是在表中有大量数据更新时,binlog 体积较大。
MIXED (混合模式):默认情况下使用 STATEMENT 模式,如果遇到某些不确定的语句,会自动切换到 ROW 模式。
优点:试图结合 STATEMENT 和 ROW 模式的优点,在大部分情况下使用 STATEMENT 节省日志空间,在必要时切换到 ROW 保证数据一致性。
缺点:由于模式的切换可能会导致一些复杂的情况,增加了理解和调试的难度。
但需要注意的是:基于 Canal 实现的数据同步只能使用 ROW 格式,因为它不能将 SQL 语句执行变成对应的数据,所以它只能获取修改后的数据进行同步。
演示内容为 ROW 行模式
1.2 重启 MySQL 服务
Linux 平台使用命令重启:systemctl restart mysqld
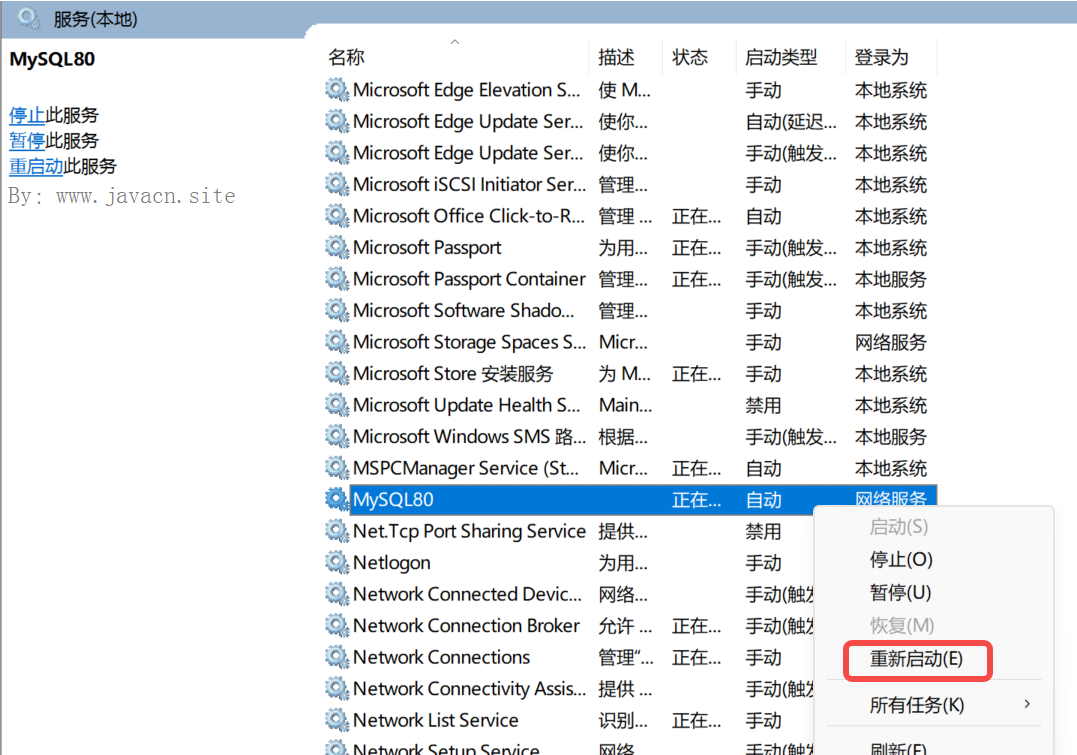
Windows 平台找到服务列表中的 MySQL 服务重启即可,如下图所示:
1.3 赋值数据同步权限
在 MySQL 中执行以下命令给 Canal 赋值同步权限:
use mysql;
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;因为 Canal 配置文件(example/instance.properties)默认是 canal/canal,如果不设置本步骤,需要修改 instance.properties 配置文件即可(可以设置为 Root 用户)。
二、安装并配置 Canal
2.1 下载并解压Canal
下载 Canal,下载地址:https://github.com/alibaba/canal/releases
解压到一个没有中文路径和空格的目录中。

2.2 修改配置
2.2.1 结合 Kafka
2.2.1.1 修改canal.properties
canal.serverMode=kafka
canal.mq.servers=127.0.0.1:90922.2.1.2 修改instance.properties
打开 Canal 目录下 confexample 中的 instance.properties 配置文件进行修改:
1. 打开注释并修改“canal.instance.mysql.slaveId=20”,不能为 1,这个表示从节点 id,因为默认主节点 id 为 1,所以这里不能为 1.
2. 连接的 MySQL 地址检查下是否需要修改“canal.instance.master.address=127.0.0.1:3306”。
3. 修改配置“canal.mq.topic=canal_test”,发送到 Kafka 某个主题下。2.2.2 结合 RabbitMQ
2.2.2.1 修改canal.properties
canal.serverMode = rabbitMQ
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host = 127.0.0.1:5672
rabbitmq.virtual.host = 虚拟主机
rabbitmq.exchange = canal.exchange
rabbitmq.routingKey = canal-routing-key
rabbitmq.queue = canal.queue
rabbitmq.deliveryMode = direct
rabbitmq.username = 用户名
rabbitmq.password = 密码
rabbitmq.deliveryMode = direct(交换机类型)2.2.2.2 修改instance.properties
#################################################
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=20
# position info
canal.instance.master.address=127.0.0.1:3316
# mq config
canal.mq.topic=canal-routing-key2.3 拷贝 jar 包
将 plugin 下的 jar 包拷贝到 lib 目录。
2.4 启动 Canal
执行 bin/startup.bat 启动。
三、Canal 执行原理
Canal 的执行原理是基于 MySQL 的 主从复制协议 实现的增量数据订阅与消费服务,其核心是通过模拟 MySQL Slave 的行为,从 Master 获取 binlog 事件并解析后投递到消息队列(如 RabbitMQ/Kafka)。以下是详细原理分解:
伪装为 Slave
Canal 启动后,会伪装成 MySQL 的 Slave 节点,向 Master 发送 dump 请求(基于 COM_BINLOG_DUMP 命令)。
拉取 binlog
Master 收到请求后,将 binlog 事件推送给 Canal(协议与真正的 MySQL Slave 一致)。
解析与存储
Canal 解析 binlog(支持 ROW/STATEMENT/MIXED 格式),并将原始事件转换为结构化数据(如 JSON)。Canal 推荐 MySQL 使用 binlog_format=ROW,能直接捕获行数据变更(INSERT/UPDATE/DELETE 的完整前/后镜像)。
投递消息队列
解析后的数据按配置的路由规则发送到 RabbitMQ/Kafka,供下游消费者订阅。
位点管理
Canal 定期记录消费的 binlog 位置(position 或 GTID),确保重启后能从断点继续同步。
四、常见错误
4.1 Unrecognized VM option 'PermSize=128m'
启动 Canal 报错如下信息:
Unrecognized VM option 'PermSize=128m'
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
这是识别不到启动参数“PermSize=128m”。
解决方案:打开启动脚本 startup.bat/sh 将“PermSize=128m”参数删除之后重启启动即可。


















暂无评论内容