
1. 设计模式了解哪些?
单例模式:确保一个类只有一个实例,并提供全局访问点,适用场景数据库连接池、线程池、日志管理器等(避免重复创建消耗资源)。
工厂模式:定义创建对象的接口,让子类决定实例化哪个类,适用场景根据不同条件创建不同类型的对象(如游戏中根据难度生成敌人)。
代理模式:为其他对象提供一种代理以控制对这个对象的访问。适用场景远程代理(如访问远程服务器的对象)、保护代理(权限控制,如验证用户才能访问敏感数据)
装饰器模式:动态地给一个对象添加额外职责,比继承更灵活,适用场景给 UI 组件添加额外功能(如窗口添加滚动条、边框)。
策略模式:定义一系列算法,将每个算法封装起来,并使它们可以相互替换。适用场景根据运行时条件选择不同的算法(如排序策略、支付方式),可避免使用大量if-else或switch语句。
2. 单例模式讲一下?
单例模式核心目标是确保一个类全局只有一个实例,并提供统一的访问点,适用场景
数据库连接池:避免创建多个连接池浪费资源。
日志管理器:所有模块共享同一个日志记录器,避免日志文件冲突。
配置文件读取器:全局统一读取配置,防止配置不一致。
线程安全版的单例模式实现如下
双重检查锁定:
public class Singleton {
privatestaticvolatile Singleton instance; // 使用 volatile 禁止指令重排
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) { // 第一次检查,不加锁
synchronized (Singleton.class) { // 仅在第一次创建时加锁
if (instance == null) { // 第二次检查,避免多线程重复创建
instance = new Singleton();
}
}
}
return instance;
}
}
volatile 关键字确保变量的可见性和禁止指令重排(防止半初始化对象被使用)。
双重检查:外层检查避免已创建实例时的锁竞争,内层检查确保多线程安全。
枚举实现:
public enum Singleton {
INSTANCE; // 枚举实例,全局唯一
// 可以添加方法
public void doSomething() {
System.out.println("单例方法被调用");
}
}
实现代码简单,也是线程安全的。
饿汉式:
public class Singleton {
// 类加载时就创建实例(不管是否使用)
private static final Singleton INSTANCE = new Singleton();
private Singleton() {}
public static Singleton getInstance() {
return INSTANCE; // 直接返回已创建的实例
}
}
JVM 保证类加载时只创建一个实例,所以是线程安全的。
3. 面向对象的特征有哪些?
Java面向对象的三大特性包括:封装、继承、多态:
封装:封装是指将对象的属性(数据)和行为(方法)结合在一起,对外隐藏对象的内部细节,仅通过对象提供的接口与外界交互。封装的目的是增强安全性和简化编程,使得对象更加独立。
继承:继承是一种可以使得子类自动共享父类数据结构和方法的机制。它是代码复用的重要手段,通过继承可以建立类与类之间的层次关系,使得结构更加清晰。
多态:多态是指允许不同类的对象对同一消息作出响应。即同一个接口,使用不同的实例而执行不同操作。多态性可以分为编译时多态(重载)和运行时多态(重写)。它使得程序具有良好的灵活性和扩展性。
4. hashmap 扩容原理是什么?
hashMap默认的负载因子是0.75,即如果hashmap中的元素个数超过了总容量75%,则会触发扩容,扩容分为两个步骤:
第1步是对哈希表长度的扩展(2倍)
第2步是将旧哈希表中的数据放到新的哈希表中。
因为我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。
如我们从16扩展为32时,具体的变化如下所示:

因此元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
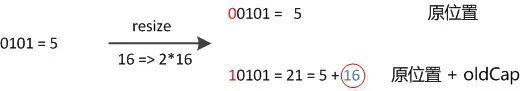
因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。可以看看下图为16扩充为32的resize示意图:
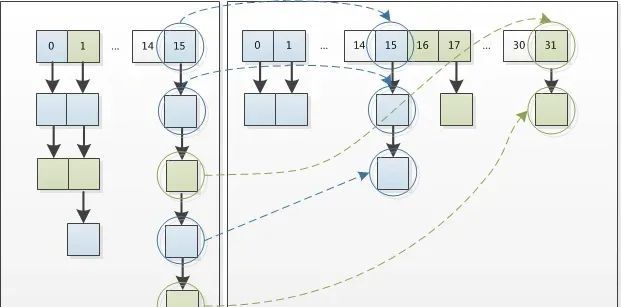
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。
5. java 锁有哪些?
Java中的锁是用于管理多线程并发访问共享资源的关键机制。锁可以确保在任意给定时间内只有一个线程可以访问特定的资源,从而避免数据竞争和不一致性。Java提供了多种锁机制,可以分为以下几类:
内置锁(synchronized):Java中的synchronized关键字是内置锁机制的基础,可以用于方法或代码块。当一个线程进入synchronized代码块或方法时,它会获取关联对象的锁;当线程离开该代码块或方法时,锁会被释放。如果其他线程尝试获取同一个对象的锁,它们将被阻塞,直到锁被释放。其中,syncronized加锁时有无锁、偏向锁、轻量级锁和重量级锁几个级别。偏向锁用于当一个线程进入同步块时,如果没有任何其他线程竞争,就会使用偏向锁,以减少锁的开销。轻量级锁使用线程栈上的数据结构,避免了操作系统级别的锁。重量级锁则涉及操作系统级的互斥锁。
ReentrantLock:java.util.concurrent.locks.ReentrantLock是一个显式的锁类,提供了比synchronized更高级的功能,如可中断的锁等待、定时锁等待、公平锁选项等。ReentrantLock使用lock()和unlock()方法来获取和释放锁。其中,公平锁按照线程请求锁的顺序来分配锁,保证了锁分配的公平性,但可能增加锁的等待时间。非公平锁不保证锁分配的顺序,可以减少锁的竞争,提高性能,但可能造成某些线程的饥饿。
读写锁(ReadWriteLock):java.util.concurrent.locks.ReadWriteLock接口定义了一种锁,允许多个读取者同时访问共享资源,但只允许一个写入者。读写锁通常用于读取远多于写入的情况,以提高并发性。
乐观锁和悲观锁:悲观锁(Pessimistic Locking)通常指在访问数据前就锁定资源,假设最坏的情况,即数据很可能被其他线程修改。synchronized和ReentrantLock都是悲观锁的例子。乐观锁(Optimistic Locking)通常不锁定资源,而是在更新数据时检查数据是否已被其他线程修改。乐观锁常使用版本号或时间戳来实现。
自旋锁:自旋锁是一种锁机制,线程在等待锁时会持续循环检查锁是否可用,而不是放弃CPU并阻塞。通常可以使用CAS来实现。这在锁等待时间很短的情况下可以提高性能,但过度自旋会浪费CPU资源。
6. synchronized锁升级过程介绍一下?
具体的锁升级的过程是:无锁->偏向锁->轻量级锁->重量级锁。
无锁:这是没有开启偏向锁的时候的状态,在JDK1.6之后偏向锁的默认开启的,但是有一个偏向延迟,需要在JVM启动之后的多少秒之后才能开启,这个可以通过JVM参数进行设置,同时是否开启偏向锁也可以通过JVM参数设置。
偏向锁:这个是在偏向锁开启之后的锁的状态,如果还没有一个线程拿到这个锁的话,这个状态叫做匿名偏向,当一个线程拿到偏向锁的时候,下次想要竞争锁只需要拿线程ID跟MarkWord当中存储的线程ID进行比较,如果线程ID相同则直接获取锁(相当于锁偏向于这个线程),不需要进行CAS操作和将线程挂起的操作。
轻量级锁:在这个状态下线程主要是通过CAS操作实现的。将对象的MarkWord存储到线程的虚拟机栈上,然后通过CAS将对象的MarkWord的内容设置为指向Displaced Mark Word的指针,如果设置成功则获取锁。在线程出临界区的时候,也需要使用CAS,如果使用CAS替换成功则同步成功,如果失败表示有其他线程在获取锁,那么就需要在释放锁之后将被挂起的线程唤醒。
重量级锁:当有两个以上的线程获取锁的时候轻量级锁就会升级为重量级锁,因为CAS如果没有成功的话始终都在自旋,进行while循环操作,这是非常消耗CPU的,但是在升级为重量级锁之后,线程会被操作系统调度然后挂起,这可以节约CPU资源。
了解完 4 种锁状态之后,我们就可以整体的来看一下锁升级的过程了。
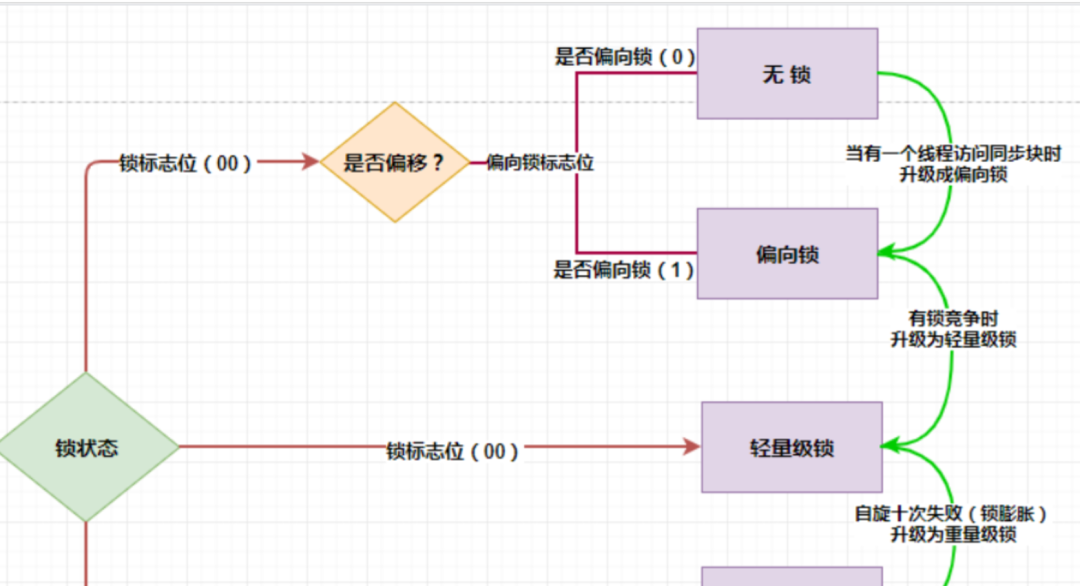
线程A进入 synchronized 开始抢锁,JVM 会判断当前是否是偏向锁的状态,如果是就会根据 Mark Word 中存储的线程 ID 来判断,当前线程A是否就是持有偏向锁的线程。如果是,则忽略 check,线程A直接执行临界区内的代码。
但如果 Mark Word 里的线程不是线程 A,就会通过自旋尝试获取锁,如果获取到了,就将 Mark Word 中的线程 ID 改为自己的;如果竞争失败,就会立马撤销偏向锁,膨胀为轻量级锁。
后续的竞争线程都会通过自旋来尝试获取锁,如果自旋成功那么锁的状态仍然是轻量级锁。然而如果竞争失败,锁会膨胀为重量级锁,后续等待的竞争的线程都会被阻塞。
7. 项目用到 redis,讲一下 redis 缓存更新策略
对于读数据,我会选择旁路缓存策略,如果 cache 不命中,会从 db 加载数据到 cache。
对于写数据,我会选择更新 db 后,再删除缓存。
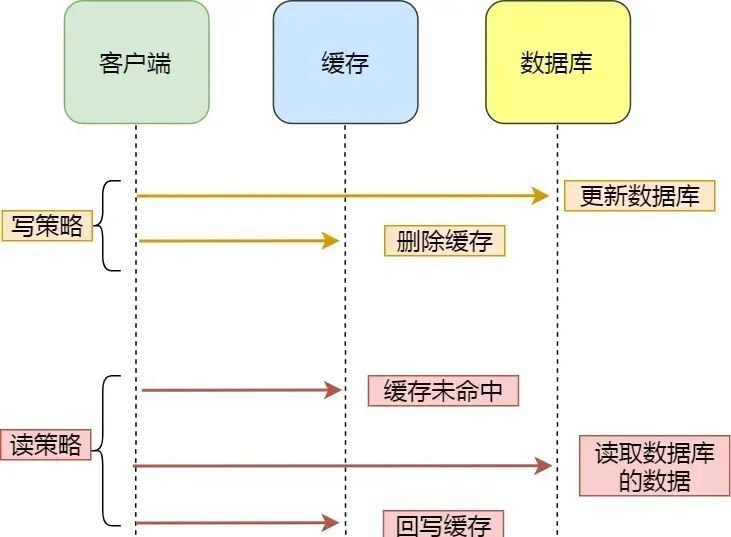
缓存是通过牺牲强一致性来提高性能的,这是由CAP理论决定的。缓存系统适用的场景就是非强一致性的场景,它属于CAP中的AP。所以,如果需要数据库和缓存数据保持强一致,就不适合使用缓存。
所以使用缓存提升性能,就是会有数据更新的延迟。这需要我们在设计时结合业务仔细思考是否适合用缓存。然后缓存一定要设置过期时间,这个时间太短、或者太长都不好:
太短的话请求可能会比较多的落到数据库上,这也意味着失去了缓存的优势。
太长的话缓存中的脏数据会使系统长时间处于一个延迟的状态,而且系统中长时间没有人访问的数据一直存在内存中不过期,浪费内存。
但是,通过一些方案优化处理,是可以最终一致性的。
针对删除缓存异常的情况,可以使用 2 个方案避免:
删除缓存重试策略(消息队列)
订阅 binlog,再删除缓存(Canal+消息队列)
消息队列方案
我们可以引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
举个例子,来说明重试机制的过程。
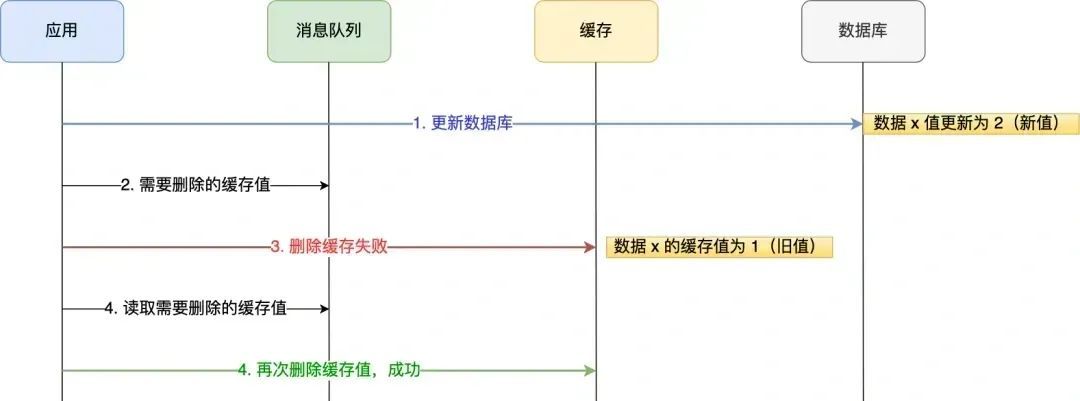
重试删除缓存机制还可以,就是会造成好多业务代码入侵。
订阅 MySQL binlog,再操作缓存
「先更新数据库,再删缓存」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用。
下图是 Canal 的工作原理:
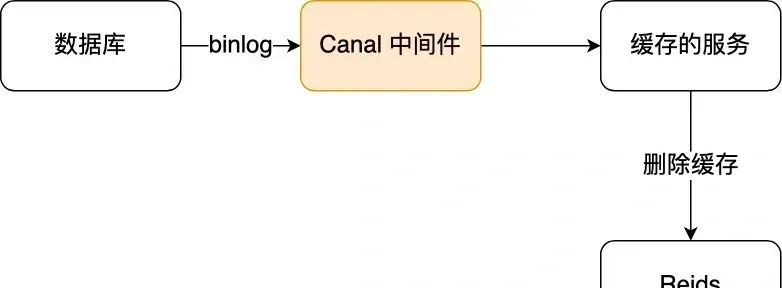
将binlog日志采集发送到MQ队列里面,然后编写一个简单的缓存删除消息者订阅binlog日志,根据更新log删除缓存,并且通过ACK机制确认处理这条更新log,保证数据缓存一致性
8. 算法
给定一个公式,求 1 到 n 中满足条件的最大值,简单的模拟保存最大值























暂无评论内容