
数据解析
前言
一、常见数据类型
1.结构化数据
2.半结构化数据
3.非结构化数据
二、HTML概述
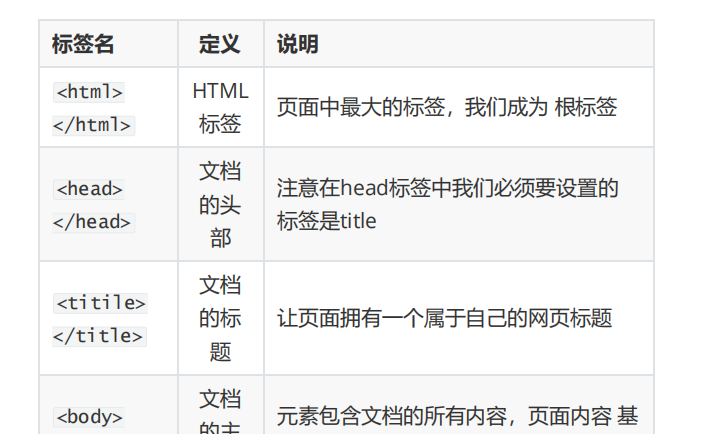
1.HTML骨架格式
2.HTML标签关系
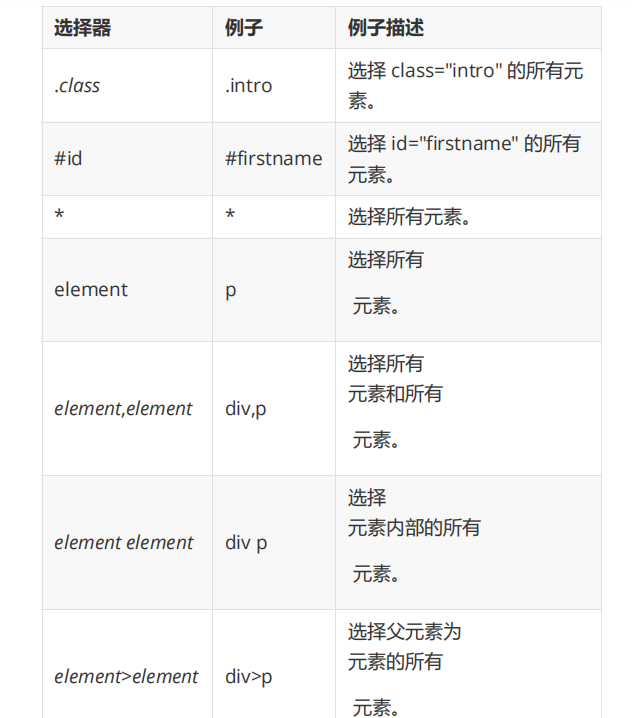
三、CSS选择器
1.标签选择器
2.类选择器
3.ID选择器
4.组合选择器
5.后代选择器
6.伪类选择器
7.属性提取器
8.小结
四、xpath节点提取
1.什么是xpath
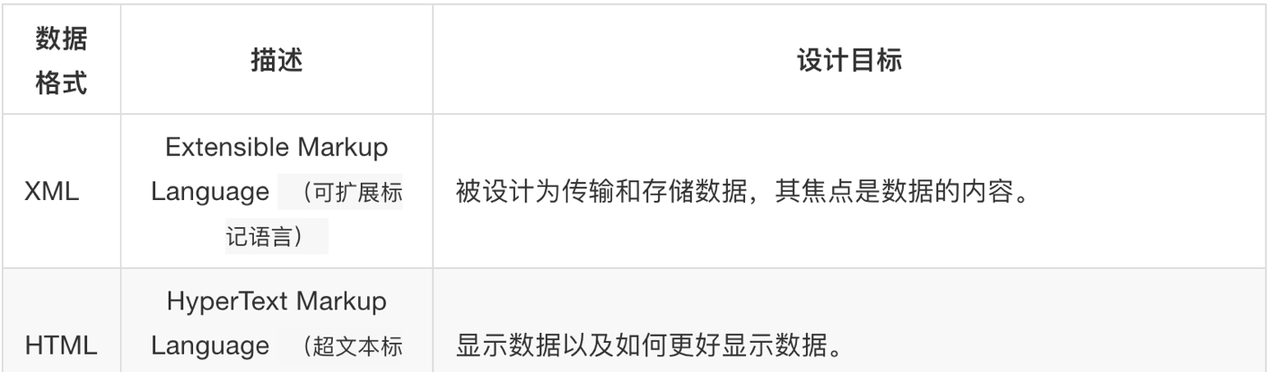
2.认识xml
1.html和xml的区别
2.xml的树结构
3.xpath的节点关系
4.xpath语法
5.小结
前言
对于爬虫中的数据解析,简单理解就是在通用爬虫获取到的响应数据中,进一步提取出我们需要的某些特定数据,是指对网页中指定的内容进行提取的过程。
一、常见数据类型
1.结构化数据
结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
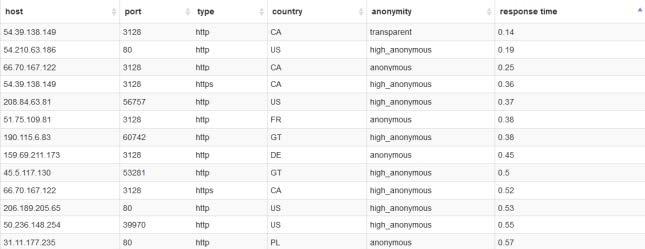
2.半结构化数据
非关系模型的、有基本固定结构模式的数据,例如日志文件、XML文档、JSON文档等。
https://www.bejson.com/jsoneditoronline/这个也是json文件。
3.非结构化数据
顾名思义,就是没有固定结构的数据。各种文档、图片、视频/音频等都属于非结构化数据。对于这类数据,我们一般直接整体进行存储,而且一般存储为二进制的数据格式。
总结:能看懂的就是结构化的数据,看不懂的,就是非结构化数据
二、HTML概述
HTML 指的是超文本标记语言 (Hyper Text Markup Language)是用来描述网页的一种语言。
H(很)T(甜)M(蜜)L(啦)
HTML 不是一种编程语言,而是一种标记语言 (markup language)
标记语言是一套标记标签(markup tag)
所谓超文本,有2层含义:
因为它可以加入图片、声音、动画、多媒体等内容(超越文本限制 )
不仅如此,它还可以从一个文件跳转到另一个文件,与世界各地主机的文件连接(超级链接文本)。
<h1> 我是一个大标题 </h1>
一句话说出他们:
网页是由网页元素组成的 , 这些元素是利用html标签描述出来,然后通过浏览器解析,就可以显示给用户了。
门外汉眼中的效果页面
![图片[1] - 爬虫知识零基础到入门-数据解析-css, xpath(三) - 宋马](https://pic.songma.com/blogimg/20250603/9ce320cbfdcc4e329dfd61900ff0afe2.png)
爬虫工程是中的页面

1.HTML骨架格式
日常生活的书信,我们要遵循共同的约定。

同理:HTML 有自己的语言语法骨架格式:(要遵循,要专业) 要求务必非常流畅的默写下来。
<html>
<head>
<title></title>
</head>
<body>
</body>
</html>
html骨架标签总结
2.HTML标签关系
主要针对于双标签 的相互关系分为两种: 请大家务必熟悉记住这种标签关系,因为后面我们标签嵌套特别多,很容易弄混他们的关系。
嵌套关系
<head>
<title> </title>
</head>
![图片[2] - 爬虫知识零基础到入门-数据解析-css, xpath(三) - 宋马](https://pic.songma.com/blogimg/20250603/9ef53af462604d1cacf3b2f6c4bcfc06.png)
2.并列关系
<head></head>
<body></body>
![图片[3] - 爬虫知识零基础到入门-数据解析-css, xpath(三) - 宋马](https://pic.songma.com/blogimg/20250603/80eb8069bcbe49eca36ed8c1ac3a0c81.png)
倡议:
如果两个标签之间的关系是嵌套关系,子元素最好缩进一个tab键的身位(一个tab是4个空格)。如果是并列关系,最好上下对齐。
一句话说出他们:
html双标签可以分为: 一种是 父子级 包含关系的标签 一种是 兄弟级 并列关系的标签
三、CSS选择器
咱们数据解析部分对应使用的第三模块是parsel
pip install parsel
在 CSS 中,选择器是一种模式,用于选择需要添加样式的元素。那么我们就可以使用css选择器,在html中找到数据所对应的标签。此方式也是一个专门在html中提取数据的方法。
1.标签选择器
标签选择器其实就是我们经常说的html代码中的标签。例如html、span、p、div、a、img等等;比如我们想要设置网页中的p标签内一段文字的字体和颜色,那么css代码就如下所示:
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p>css标签选择器的介绍</p>
<p>标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
span = selector.css('span').getall()
print(span)
2.类选择器
类选择器在我们今后的css样式编码中是最常用到的,它是通过为元素设置单独的class来赋予元素样式效果。使用语法:(我们这里为p标签单独设置一个class类属性,代码就如下所示)
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
p = selector.css('.top').getall()
print(p)
详细讲解:
1、类选择器都是使用英文圆点(.)开头;
2、每个元素可以有多个类名,名称可以任意起名(但不要起中文,一般都是与内容相关的英文缩写)
3.ID选择器
ID选择器类似于类选择符,作用同类选择符相同,但也有一些重要的区别。
使用语法:
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
p = selector.css('#content').getall()
print(p)
详细讲解:
1、ID选择器为标签设置id=“ID名称”,而不是class=“类名称”。
2、ID选择符的前面是符号为井号(#),而不是英文圆点(.)。
3、ID选择器的名称是唯一的,即相同名称的id选择器在一个页面只能出现一次;
4.组合选择器
可以多个选择器一起使用,就是组合选择器
5.后代选择器
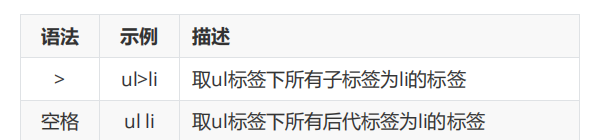
6.伪类选择器
![图片[4] - 爬虫知识零基础到入门-数据解析-css, xpath(三) - 宋马](https://pic.songma.com/blogimg/20250603/527e0a12edad49c1a5cfa6a80f51d199.png)
案例:
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID
选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
p = selector.css('p:nth-child(2)').getall()
print(p)
7.属性提取器

# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID
选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
p = selector.css('p::text').getall()
print(p)
a = selector.css('a::attr(href)').get()
print(a)
8.小结

四、xpath节点提取
1.什么是xpath
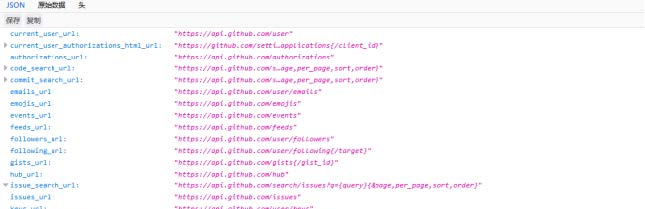
XPath (XML Path Language) 是一门在 HTMLXML 文档中查找信息的语言,可用来在 HTMLXML 文档中对元素和属性进行遍历。
W3School官方文档:https://www.w3school.com.cn/xpath/index.asp
2.认识xml
知识点:
html和xml的区别
xml中各个元素的的关系和属性
1.html和xml的区别
2.xml的树结构
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
上面的xml内容可以表示为下面的树结构
![图片[5] - 爬虫知识零基础到入门-数据解析-css, xpath(三) - 宋马](https://pic.songma.com/blogimg/20250603/4fc59bccad484659b36278da2e7e6169.png)
上面的这种结构关系在xpath被进一步细化
3.xpath的节点关系
知识点:
认识xpath中的节点
了解xpath中节点之间的关系
每个html的标签我们都称之为节点。(根节点、子节点、同级节点)
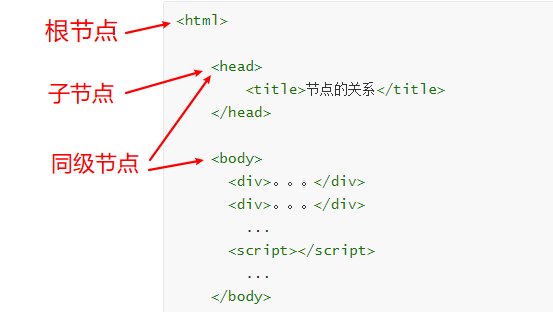
4.xpath语法
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
下面列出了最有用的表达式:
![图片[6] - 爬虫知识零基础到入门-数据解析-css, xpath(三) - 宋马](https://pic.songma.com/blogimg/20250603/eb60694bf8a94b7f9630ad0e34342d16.png)
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
![图片[7] - 爬虫知识零基础到入门-数据解析-css, xpath(三) - 宋马](https://pic.songma.com/blogimg/20250603/6528736a2d5041f39ebfbb030a83daa1.png)
选取未知节点
![图片[8] - 爬虫知识零基础到入门-数据解析-css, xpath(三) - 宋马](https://pic.songma.com/blogimg/20250603/679b35d5e816434a8386d20ff104e63b.png)
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
![图片[9] - 爬虫知识零基础到入门-数据解析-css, xpath(三) - 宋马](https://pic.songma.com/blogimg/20250603/dd86009d634540509cc2ecea9e85dab0.png)
案例
<div>
<ul>
<li class="item-1">
<a href="link1.html">第一个
</a>
</li>
<li class="item-2">
<a href="link2.html">第二个
</a>
</li>
<li class="item-3">
<a href="link3.html">第三个
</a>
</li>
<li class="item-4">
<a href="link4.html">第四个
</a>
</li>
<li class="item-5">
<a href="link5.html">第五个
</a>
</li>
</ul>
</div>
import parsel # str --> Selector对象 具有xpath方法 提取到的数据返回一个列表
html_str = """
<div>
<ul>
<li class="item-1">
<a href="link1.html">第一个
</a>
</li>
<li class="item-2">
<a href="link2.html">第二个
</a>
</li>
<li class="item-3">
<a href="link3.html">第三个
</a>
</li>
<li class="item-4">
<a href="link4.html">第四个
</a>
</li>
<li class="item-5">
<a href="link5.html">第五个
</a>
</li>
</ul>
</div>
"""
# 1、转换数据类型
# data = parsel.Selector(html_str).extract() #parsel能够把缺失的html标签补充完成
data = parsel.Selector(html_str) # parsel能够把缺失的html标签补充完成
# 2、解析数据--list类型
# print(data)
# 2、1 从根节点开始,获取所有<a>标签
result = data.xpath('/html/body/div/ul/li/a').extract()
# 2、2 跨节点获取所有<a>标签
result = data.xpath('//a').extract()
# 2、3 选取当前节点 使用场景:需要对选取的标签的下一级标签进行多次提取
result = data.xpath('//ul')
result2 = result.xpath('./li').extract() # 提取当前节点下的<li>标签
result3 = result.xpath('./li/a').extract() # 提取当前节点下的<a>标签
# 2、4 选取当前节点的父节点,获取父节点的class属性值
result = data.xpath('//a')
result4 = result.xpath('../@class').extract()
# 2、5 获取第三个<li>标签的节点(两种方法)
result = data.xpath('//li[3]').extract()
result = data.xpath('//li')[2].extract()
# 2、6 通过定位属性的方法获取第四个<a>标签
result = data.xpath('//a[@href="link4.html"]').extract()
# 2、7 用属性定位标签,获取第四个<a>标签包裹的文本内容
result = data.xpath('//a[@href="link4.html"]/text()').extract()
# 2、8 获取第五个<a>标签的href属性值
result = data.xpath('//li[5]/a/@href').extract()
# 了解 模糊查询
result = data.xpath('//li[contains(@class,"it")]').extract()
# 同时获取<li>标签的属性以及<a>标签的文本
# result = data.xpath('//li/@class|//a/text()').extract()
print(result)
如何选取多个标签?
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。(逻辑运算符)
5.小结
xpath的概述XPath (XML Path Language),解析查找提取信息的
语言
xpath的节点关系:根节点,子节点,同级节点
xpath的重点语法获取任意节点: //
xpath的重点语法根据属性获取节点: 标签[@属性 = ‘值’]
xpath中获取节点的文本:text()
xpath的获取节点属性值: @属性名

















暂无评论内容