
在Volsdf实验复现的过程中,一共出现4个代码文件,分别是environment.yml、download_data.sh 、exp_runner.py、eval.py,其中environment.yml是用于配置项目环境的文件,download_data.sh是用于下载数据集的文件,exp_runner.py是用于训练Volsdf模型的文件,eval.py是用于评估训练好的Volsdf模型的文件。
1、environment.yml代码详解(环境)
后缀名为 .yml 文件是一种特定格式的配置文件,通常用于存储和传输数据。
environment.yml文件是一个 Conda 环境配置文件,用于定义和管理 Python 环境,里面包含三个板块,分别是:①name;②channels;③dependencies。
name: volsdf:
这行指令定义了一个名为 volsdf 的 Conda 环境。
环境名称用于标识不同的 Python 环境,方便在不同项目中切换和管理。
channels:
这是一个列表,指定了 Conda 环境中要使用的软件包渠道(channel)。
dependencies:
这也是一个列表,列出了环境所需的软件包及其版本。
每个条目的格式是 <package_name>=<version>.
2、download_data.sh代码详解(数据集)
后缀名为.sh的文件是shell脚本文件,该文件里面存储的是Linux的相关命令,通过bash命令执行该文件,其结果是对该文件存储的linux命令依次执行。
下述代码是download_data.sh文件的存储内容:
confsmkdir -p data#检查data目录是否存在,如果不存在,则就创建一个,如果存在,则跳过此命令。
cd data#进入data这个目录
echo "Downloading the DTU dataset ..."#在命令行出输出“正在下载DTU数据集”
wget https://www.dropbox.com/s/s6psnh1q91m4kgo/DTU.zip#从该链接获取DTU数据集的压缩包
echo "Start unzipping ..."#在命令行出输出“开始解压……”
unzip DTU.zip#解压DTU数据集的压缩包
echo "DTU dataset is ready!"#在命令行出输出“DTU数据集已经准备完毕”
rm -f DTU.zip#删除DTU数据集的压缩包
echo "Downloading the BlendedMVS dataset ..."#在命令行出输出“正在下载BlendedMVS数据集”
wget https://www.dropbox.com/s/c88216wzn9t6pj8/BlendedMVS.zip#从该链接获取BlendedMVS数据集的压缩包
echo "Start unzipping ..."#在命令行出输出“开始解压……”
unzip BlendedMVS.zip#解压BlendedMVS数据集的压缩包
echo "BlendedMVS dataset is ready!"#在命令行出输出“BlendedMVS数据集已经准备完毕”
rm -f BlendedMVS.zip#删除BlendedMVS数据集的压缩包3、Volsdf模型训练过程代码详解
3.1 exp_runner.py代码详解
该Python脚本是用于训练一个名为Volsdf的模型。
#导入sys模块,用于访问与python解释器交互的功能
import sys
#将上级目录中的code目录导入python解释器的搜索路径中,方便代码中引用code目录中的模块
sys.path.append('../code')
#导入argparse模块,用于解析命令行参数和选项
import argparse
#导入GPUtil模块,该模块是用于获取GPU信息库
import GPUtil
#从training库中导入volsdf_train模块的类VolSDFTrainRunner,实际是training目录下有一个名为volsdf_train的python文件,里面定义了一个名为VolSDFTrainRunner的类
from training.volsdf_train import VolSDFTrainRunner
#Python脚本的惯用手法,用于该python代码是直接执行还是被导入为模块(例如volsdf_train.py就不是直接被执行,而是被本代码导入为模块使用),如果是直接被执行,就运行如下代码。
if __name__ == '__main__':
#使用argparse.ArgumentParser()定义了一个名为parser的对象
parser = argparse.ArgumentParser()
#下列一系列的parser.add_argument用于定义可接受的命令行参数,以及默认值和帮助信息
#指定输入批次大小(神经网络一次性处理的mini-batch的个数),类型为整数型,默认值为1
parser.add_argument('--batch_size', type=int, default=1, help='input batch size')
#指定训练总轮次,类型为整数型,默认值为2000
parser.add_argument('--nepoch', type=int, default=2000, help='number of epochs to train for')
#指定配置文件路径,类型为字符型,默认配置文件为./confs/dtu.conf
parser.add_argument('--conf', type=str, default='./confs/dtu.conf')
#指定实验,类型为字符型,默认值为空字符
parser.add_argument('--expname', type=str, default='')
#指定实验结果存储文件,类型为字符型,默认存储在exps文件中
parser.add_argument("--exps_folder", type=str, default="exps")
#指定要使用的GPU,类型为字符型,默认值为auto,auto是指系统会自动选定一个可用的GPU
parser.add_argument('--gpu', type=str, default='auto', help='GPU to use [default: GPU auto]')
#如果命令行设置了这个参数则代表要从之前运行的结果中继续进行训练
parser.add_argument('--is_continue', default=False, action="store_true",
help='If set, indicates continuing from a previous run.')
#该设置是指先前运行结果的时间戳,方便从之前运行的结果中继续训练,默认值为latest,代表最近的时间戳
parser.add_argument('--timestamp', default='latest', type=str,
help='The timestamp of the run to be used in case of continuing from a previous run.')
#该设置是指先前运行结果的检查点,也就是先前运行结果模型的保存点,默认值为latest,代表最近的检查点
parser.add_argument('--checkpoint', default='latest', type=str,
help='The checkpoint epoch of the run to be used in case of continuing from a previous run.')
#该设置是扫描ID,指数据集中某个特定扫描或者是图像,默认值为-1
parser.add_argument('--scan_id', type=int, default=-1, help='If set, taken to be the scan id.')
#该设置是取消训练中间过程的可视化输出
parser.add_argument('--cancel_vis', default=False, action="store_true",
help='If set, cancel visualization in intermediate epochs.')
#将命令行的参数解析完之后放在opt对象中
opt = parser.parse_args()
#判定命令行中用户是否指定了使用的GPU,
#如果命令行中用户指定GPU为auto,则使用GPUtil.getAvailable函数获取GPU的信息,从中选取一个可用的GPU。如果用户指定了另外的GPU,则使用用户指定的GPU
if opt.gpu == "auto":
deviceIDs = GPUtil.getAvailable(order='memory', limit=1, maxLoad=0.5, maxMemory=0.5, includeNan=False,
excludeID=[], excludeUUID=[])
gpu = deviceIDs[0]
else:
gpu = opt.gpu
#创建一个类VolSDFTrainRunner的实例trainrunner,并传入解析好的命令行参数和其他参数
trainrunner = VolSDFTrainRunner(conf=opt.conf,
batch_size=opt.batch_size,
nepochs=opt.nepoch,
expname=opt.expname,
gpu_index=gpu,
exps_folder_name=opt.exps_folder,
is_continue=opt.is_continue,
timestamp=opt.timestamp,
checkpoint=opt.checkpoint,
scan_id=opt.scan_id,
do_vis=not opt.cancel_vis
)
#调用类VolSDFTrainRunner定义好的实例方法run去训练Volsdf模型
trainrunner.run()总的来说,该脚本是利用命令行参数来配置Volsdf的训练过程,包括训练批次、训练总轮次、配置文件路径等等,还可以从之前的训练结果中恢复。
运行上述代码文件时,命令如下:
cd ./code
python training/exp_runner.py --conf ./confs/dtu.conf --scan_id 24可见只传入了配置文件的路径,以及扫描ID。
3.2 volsdf_train.py代码详解
接下来我将详细解析exp_runner.py调用的代码文件volsdf_train.py。
volsdf_train.py文件位于目录volsdf/code/training/volsdf_train.py,该文件是exp_runner.py配置volsdf模型训练过程参数时调用的模块,利用该模块里面定义的类VolSDFTrainRunner来训练volsdf模型。以下是volsdf_train.py的代码详解:
#导入python的os模块,用于与操作系统进行交互,例如文件路径操作等
import os
#从datetime模块中导入类datetime,用于处理时间和日期
from datetime import datetime
#从pyhocon库中导入类ConfigFactory,用于HOCON格式的配置文件
from pyhocon import ConfigFactory
#导入python的sys模块,用于访问python解释器的功能
import sys
#导入python的pytorch模块,用于创建和训练神经网络
import torch
#从tqdm库中导入函数tqdm,用于显示循环过程中的进度条
from tqdm import tqdm
#下面引入的三个函数,均是自定义的工具函数,解析完该代码后,会对这三个函数的自定义代码进行解析
import utils.general as utils#自定义的通用工具函数
import utils.plots as plt#自定义的绘图函数
from utils import rend_util#自定义的渲染函数
#定义了一个名为VolSDFTrainRunner的类,用于处理训练过程的各种操作
class VolSDFTrainRunner():
#下述定义了一个类VolSDFTrainRunner的初始化方法,用于初始化对象的各种属性和设置,参数kwargs是一个字典,可以接受任意数量的关键字参数
def __init__(self,**kwargs):
#设置pytorch的默认数据类型为32位的字符型
torch.set_default_dtype(torch.float32)
#设置pytorch的线程数为1
torch.set_num_threads(1)
#接下来的系列与kwargs有关的代码,都是通过kwargs参数获取初始传入的各种配置信息和其他参数,并进行相应的设置和处理,包括解析配置文件、设置训练参数、创建实验目录等等
#获取初始从参数kwargs传入的配置文件,并使用ConfigFactory方法将配置文件解析为配置对象,存于self.conf中
self.conf = ConfigFactory.parse_file(kwargs['conf'])
#获取初始从参数kwargs传入的批次数量,存于self.batch_size中
self.batch_size = kwargs['batch_size']
#获取初始从参数kwargs传入的训练总轮次,存于self.nepochs中
self.nepochs = kwargs['nepochs']
#获取初始从kwargs传入的实验结果存储的文件夹名称,存于self.exps_folder_name中
self.exps_folder_name = kwargs['exps_folder_name']
#获取初始从参数kwargs传入的GPU索引,存于self.GPU_INDEX中
self.GPU_INDEX = kwargs['gpu_index']
#获取初始从参数kwargs传入的实验名称,并获取存于配置文件conf中的实验名称,并将两者结合,存于self.expname
self.expname = self.conf.get_string('train.expname') + kwargs['expname']获取初始从参数kwargs传入的扫描ID,并判断扫描ID是否为-1,如果不为-1则使用传入的扫描ID,如果为-1则使用配置文件中设置的默认的扫描ID
#获取初始从参数kwargs传入的扫描ID,并判断扫描ID是否为-1,如果不为-1则使用传入的扫描ID,如果为-1则使用配置文件中设置的默认的扫描ID
scan_id = kwargs['scan_id'] if kwargs['scan_id'] != -1 else self.conf.get_int('dataset.scan_id', default=-1)
#如果扫描ID不为-1,则将实验名称加上扫描ID
if scan_id != -1:
self.expname = self.expname + '_{0}'.format(scan_id)
#如果从kwargs传入的初始配置信息中设置了从先前的训练结果继续进行训练,并获取最近的时间戳,则就要检查最新的实验文件是否有内容,并获取最新的时间戳。如果没有则使用传入的时间戳
if kwargs['is_continue'] and kwargs['timestamp'] == 'latest':
if os.path.exists(os.path.join('../',kwargs['exps_folder_name'],self.expname)):
timestamps = os.listdir(os.path.join('../',kwargs['exps_folder_name'],self.expname))
if (len(timestamps)) == 0:
is_continue = False
timestamp = None
else:
timestamp = sorted(timestamps)[-1]
is_continue = True
else:
is_continue = False
timestamp = None
else:
timestamp = kwargs['timestamp']
is_continue = kwargs['is_continue']
#如下一段代码是用来创建实验目录,以及相应的文件夹的
#使用volsdf/code/utils目录下定义的方法mkdir_ifnotexists,首先回到上级目录,然后判断是否有存储实验结果的文件夹存在,如果没有则创建名为exp的用于存储实验结果的文件夹
utils.mkdir_ifnotexists(os.path.join('../',self.exps_folder_name))
#将目录'../实验结果目录/实验名称'存储于对象self.expdir中,用作实验目录
self.expdir = os.path.join('../', self.exps_folder_name, self.expname)
#使用方法mkdir_ifnotexists在没有实验目录的情况下,创建存储于对象self.expdir中的实验目录
utils.mkdir_ifnotexists(self.expdir)
#获取当前的时间,并将其化为字符串的形式,存于对象self.timestamp中,用作时间戳
self.timestamp = '{:%Y_%m_%d_%H_%M_%S}'.format(datetime.now())
#使用方法mkdir_ifnotexists在没有存储最新实验结果的文件的情况下,创建位于实验目录self.expdir下的以时间戳self.timestamp命名的子文件,该文件用于存储最新的实验结果,并以时间戳命名(例子volsdfexpsdtu_242024_2_3_21_45_27)
utils.mkdir_ifnotexists(os.path.join(self.expdir, self.timestamp))
#创建绘图子文件的目录存于对象self.plots_dir中,绘图子文件位于时间戳文件夹下,并且名为plots
self.plots_dir = os.path.join(self.expdir, self.timestamp, 'plots')
#使用方法mkdir_ifnotexists在没有绘图子文件的情况下,依照存于self.plots_dir的目录创建绘图子文件
utils.mkdir_ifnotexists(self.plots_dir)
# 以下一段代码用于设置模型训练过程中的一些配置和参数
#创建存储检查点(也就是存储先前运行结果模型的目录)的目录,该目录具体为实验目录/时间戳/checkpoints,该目录存储于对象self.checkpoints_path
self.checkpoints_path = os.path.join(self.expdir, self.timestamp, 'checkpoints')
#使用方法mkdir_ifnotexists在没有存储检查点的子文件的情况下,创建存储于对象self.checkpoints_path当中的目录
utils.mkdir_ifnotexists(self.checkpoints_path)
#创建存储模型参数的文件名为ModelParameters存于对象self.model_params_subdir中
self.model_params_subdir = "ModelParameters"
#创建存储优化器(梯度下降)参数的文件名为OptimizerParameters存于对象self.optimizer_params_subdir中
self.optimizer_params_subdir = "OptimizerParameters"
#创建存储学习率调度器参数的文件名为SchedulerParameters存于对象self.scheduler_params_subdir中
self.scheduler_params_subdir = "SchedulerParameters"
#将上述创建的模型参数、优化器参数和学习率调度器参数的文件名使用方法mkdir_ifnotexists创建在存储检查点的目录self.checkpoints_path下,这三个参数就是先前运行结果的模型参数
utils.mkdir_ifnotexists(os.path.join(self.checkpoints_path, self.model_params_subdir))
utils.mkdir_ifnotexists(os.path.join(self.checkpoints_path, self.optimizer_params_subdir))
utils.mkdir_ifnotexists(os.path.join(self.checkpoints_path, self.scheduler_params_subdir))
#将配置文件复制到实验目录下,并命名为runconf.conf
os.system("""cp -r {0} "{1}" """.format(kwargs['conf'], os.path.join(self.expdir, self.timestamp, 'runconf.conf')))
#如果GPU的索引不为ignore,则通过设置环境变量CUDA_VISIBLE_DEVICES来选择待定的GPU
if (not self.GPU_INDEX == 'ignore'):
os.environ["CUDA_VISIBLE_DEVICES"] = '{0}'.format(self.GPU_INDEX)
#打印该脚本命令行输入的参数
print('shell command : {0}'.format(' '.join(sys.argv)))
#打印'正在记载数据'的文本
print('Loading data ...')
#从配置文件中获取数据集的相关配置并存于对象dataset_conf中
dataset_conf = self.conf.get_config('dataset')
#如果命令行初始传入给参数kwargs的扫描ID不为-1,则将数据集相关配置对象dataset_conf中的扫描ID换为输入的ID
if kwargs['scan_id'] != -1:
dataset_conf['scan_id'] = kwargs['scan_id']
#通过获取配置文件中训练数据的类名和相关配置来创建训练数据对象self.train_dataset
self.train_dataset = utils.get_class(self.conf.get_string('train.dataset_class'))(**dataset_conf)
#获取训练数据的长度
self.ds_len = len(self.train_dataset)
#打印‘完成训练数据加载’的脚本,以及数据集的总长度
print('Finish loading data. Data-set size: {0}'.format(self.ds_len))
#如果扫描ID在合理的范围之类(0~24),则通过数据集的长度来重新制定训练的总轮次,并输出训练的总轮次
if scan_id < 24 and scan_id > 0: # BlendedMVS, running for 200k iterations
self.nepochs = int(200000 / self.ds_len)
print('RUNNING FOR {0}'.format(self.nepochs))
#创建训练数据加载对象,用于迭代训练数据
self.train_dataloader = torch.utils.data.DataLoader(self.train_dataset,
batch_size=self.batch_size,
shuffle=True,
collate_fn=self.train_dataset.collate_fn
)
#创建绘图数据加载对象,用于可视化训练过程
self.plot_dataloader = torch.utils.data.DataLoader(self.train_dataset,
batch_size=self.conf.get_int('plot.plot_nimgs'),
shuffle=True,
collate_fn=self.train_dataset.collate_fn
)
#从配置文件中获取模型的相关配置,并存于对象conf_model中
conf_model = self.conf.get_config('model')
#获取存储模型相关配置的对象conf_model中的训练模型的类名以及相关的配置创建训练模型对象self.model
self.model = utils.get_class(self.conf.get_string('train.model_class'))(conf=conf_model)
#如果GPU可用,则将模型移到可用的GPU上进行运算
if torch.cuda.is_available():
self.model.cuda()self.loss
#获取配置文件中的损失函数的类名已经相关配置创建损失函数对象self.loss
self.loss = utils.get_class(self.conf.get_string('train.loss_class'))(**self.conf.get_config('loss'))
#获取配置文件中的学习率,创建学习率对象self.lr
self.lr = self.conf.get_float('train.learning_rate')
#使用Adam优化器作为该模型的梯度下降优化器,创建优化器对象为self.optimizer
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=self.lr)
# 以下一段代码用于设置学习率衰减调度器的参数、恢复先前运行结果保存的模型状态、调试训练过程中其他配置和参数
#从配置文件中获取学习率衰减率,默认为0.1
decay_rate = self.conf.get_float('train.sched_decay_rate', default=0.1)
#计算学习率衰减步数,其值为训练总轮次数乘以训练数据集的长度
decay_steps = self.nepochs * len(self.train_dataset)
#创建学习率衰减调度器的对象,以优化器和学习率衰减率作为参数
self.scheduler = torch.optim.lr_scheduler.ExponentialLR(self.optimizer, decay_rate ** (1./decay_steps))
#将命令行初始传入参数kwargs的可视化变量do_vis转换为实例变量self.do_vis
self.do_vis = kwargs['do_vis']
#设置初始化训练开始时的周期数为0
self.start_epoch = 0
#如果设置继续训练的标志,则从检查点处恢复先前保存的模型、优化器和学习率调度器的状态,以便继续训练
if is_continue:
old_checkpnts_dir = os.path.join(self.expdir, timestamp, 'checkpoints')
saved_model_state = torch.load(
os.path.join(old_checkpnts_dir, 'ModelParameters', str(kwargs['checkpoint']) + ".pth"))
self.model.load_state_dict(saved_model_state["model_state_dict"])
self.start_epoch = saved_model_state['epoch']
data = torch.load(
os.path.join(old_checkpnts_dir, 'OptimizerParameters', str(kwargs['checkpoint']) + ".pth"))
self.optimizer.load_state_dict(data["optimizer_state_dict"])
data = torch.load(
os.path.join(old_checkpnts_dir, self.scheduler_params_subdir, str(kwargs['checkpoint']) + ".pth"))
self.scheduler.load_state_dict(data["scheduler_state_dict"])
#从配置文件中获取每张图像的像素数,并存于对象self.num_pixels中
self.num_pixels = self.conf.get_int('train.num_pixels')
#获取整个训练集图像的像素数,并存于对象self.total_pixels中
self.total_pixels = self.train_dataset.total_pixels
#获取训练集图像的分辨率,并存于对象self.img_res中
self.img_res = self.train_dataset.img_res
#获取训练数据加载器的批次,并存于对象self.n_batches中
self.n_batches = len(self.train_dataloader)
#获取绘图频率,也就是多少个周期绘制一次图,并存于对象self.plot_freq中
self.plot_freq = self.conf.get_int('train.plot_freq')
#获取保存检查点的频率,默认为每隔 100 个周期保存一次检查点,并存于对象self.checkpoint_freq中
self.checkpoint_freq = self.conf.get_int('train.checkpoint_freq', default=100)
#获取分割训练图像像素数,默认为10000,并存于对象self.split_n_pixels中
self.split_n_pixels = self.conf.get_int('train.split_n_pixels', default=10000)
#获取配置文件中绘图的相关配置,并存于对象self.plot_conf中
self.plot_conf = self.conf.get_config('plot')
#下面一段代码定义了一个名为save_checkpoints的函数,用于保存训练过程中的检查点,也就是每一个训练周期结束(100个轮次),就需要保存模型的状态、优化器状态和调度器状态,以便在训练过程中断之后能够继续从中断的地方进行训练。
#定义了一个名为save_checkpoints的函数,它接受的参数就是epoch,也就是训练周期数
def save_checkpoints(self, epoch):
#该段代码用于保存当前周期的模型状态,使用pytorch的torch.save函数来保存模型的状态,该函数将传入的字典作为保存的内容,即周期数和模型状态字典。保存的路径是检查点目录下的模型状态参数子文件,保存的文件名是轮次数加上.pth的后缀(如volsdfexpsdtu_242024_2_3_21_45_27checkpointsModelParameters.pth)
torch.save(
{"epoch": epoch, "model_state_dict": self.model.state_dict()},
os.path.join(self.checkpoints_path, self.model_params_subdir, str(epoch) + ".pth"))
#同时保存最新的模型状态,文件名为“latest.pth”
torch.save(
{"epoch": epoch, "model_state_dict": self.model.state_dict()},
os.path.join(self.checkpoints_path, self.model_params_subdir, "latest.pth"))
#该段代码用于保存当前周期的优化器状态,使用pytorch的torch.save函数来保存优化器的状态,该函数将传入的字典作为保存的内容,即周期数和优化器状态字典。保存的路径是检查点目录下的优化器状态参数子文件,保存的文件名是轮次数加上.pth的后缀(如volsdfexpsdtu_242024_2_3_21_45_27checkpointsOptimizerParameters.pth)
torch.save(
{"epoch": epoch, "optimizer_state_dict": self.optimizer.state_dict()},
os.path.join(self.checkpoints_path, self.optimizer_params_subdir, str(epoch) + ".pth"))
#同时保存最新的优化器状态,文件名为“latest.pth”
torch.save(
{"epoch": epoch, "optimizer_state_dict": self.optimizer.state_dict()},
os.path.join(self.checkpoints_path, self.optimizer_params_subdir, "latest.pth"))
#该段代码用于保存当前周期的学习率衰减调度器状态,使用pytorch的torch.save函数来保存学习率衰减调度器的状态,该函数将传入的字典作为保存的内容,即周期数和学习率衰减调度器状态字典。保存的路径是检查点目录下的调度器状态参数子文件,保存的文件名是轮次数加上.pth的后缀(如volsdfexpsdtu_242024_2_3_21_45_27checkpointsSchedulerParameters.pth)
torch.save(
{"epoch": epoch, "scheduler_state_dict": self.scheduler.state_dict()},
os.path.join(self.checkpoints_path, self.scheduler_params_subdir, str(epoch) + ".pth"))
#同时保存最新的学习率衰减调度器状态,文件名为“latest.pth”
torch.save(
{"epoch": epoch, "scheduler_state_dict": self.scheduler.state_dict()},
os.path.join(self.checkpoints_path, self.scheduler_params_subdir, "latest.pth"))
#下面一段代码定义了一个名为run的函数,是Volsdf模型整个训练过程的主要控制函数,包括控制模型的训练过程、参数的更新,以及特定周期保存检查点和生成可视化的结果
#定义了一个名为run的函数,没有任何参数
def run(self):
#打印‘训练……’的文本,表示训练开始
print("training...")
#用for循环迭代整个训练周期,从初始化训练周期self.start_epoch开始到总训练周期self.nepochs
for epoch in range(self.start_epoch, self.nepochs + 1):
#如果当前周期数正好是保存检查点的周期,则使用上一个函数save_checkpoints定义的方法保存模型、优化器和调度器的状态
if epoch % self.checkpoint_freq == 0:
self.save_checkpoints(epoch)
#如果当前的周期数正好是绘图周期,且需要生成可视化的结果,则要进行以下操作
if self.do_vis and epoch % self.plot_freq == 0:
#将模型调为评估模式
self.model.eval()
#从绘图数据加载器中获取一个批次的数据
self.train_dataset.change_sampling_idx(-1)
indices, model_input, ground_truth = next(iter(self.plot_dataloader))
#将模型输入的数据移到GPU上进行计算
model_input["intrinsics"] = model_input["intrinsics"].cuda()
model_input["uv"] = model_input["uv"].cuda()
model_input['pose'] = model_input['pose'].cuda()
#将模型输入的数据按照像素数进行分割,并使用模型进行推理
split = utils.split_input(model_input, self.total_pixels, n_pixels=self.split_n_pixels)
res = []
for s in tqdm(split):
out = self.model(s)
d = {'rgb_values': out['rgb_values'].detach(),
'normal_map': out['normal_map'].detach()}
res.append(d)
#将推理的结果合并形成绘图数据
batch_size = ground_truth['rgb'].shape[0]
model_outputs = utils.merge_output(res, self.total_pixels, batch_size)
plot_data = self.get_plot_data(model_outputs, model_input['pose'], ground_truth['rgb'])
#采用绘图函数plt.plot进行绘图
plt.plot(self.model.implicit_network,
indices,
plot_data,
self.plots_dir,
epoch,
self.img_res,
**self.plot_conf
)
#将模型设置为训练模式
self.model.train()
#在训练开始前,绘图结束后,调整训练数据的采样索引
self.train_dataset.change_sampling_idx(self.num_pixels)
#在每一个训练周期,都需要迭代训练数据加载器的每批次数据,并完成以下操作
for data_index, (indices, model_input, ground_truth) in enumerate(self.train_dataloader):
#将模型输入数据移到GPU上进行计算
model_input["intrinsics"] = model_input["intrinsics"].cuda()
model_input["uv"] = model_input["uv"].cuda()
model_input['pose'] = model_input['pose'].cuda()
#使用模型进行前向传播
model_outputs = self.model(model_input)
#计算损失函数的输出
loss_output = self.loss(model_outputs, ground_truth)
loss = loss_output['loss']
#归零优化器梯度
self.optimizer.zero_grad()
#反向传播并更新参数
loss.backward()
self.optimizer.step()
#打印并计算损失和其他指标
psnr = rend_util.get_psnr(model_outputs['rgb_values'],
ground_truth['rgb'].cuda().reshape(-1,3))
print(
'{0}_{1} [{2}] ({3}/{4}): loss = {5}, rgb_loss = {6}, eikonal_loss = {7}, psnr = {8}'
.format(self.expname, self.timestamp, epoch, data_index, self.n_batches, loss.item(),
loss_output['rgb_loss'].item(),
loss_output['eikonal_loss'].item(),
psnr.item()))
#调整训练数据的采样索引
self.train_dataset.change_sampling_idx(self.num_pixels)
#更新学习率
self.scheduler.step()
#每一个训练周期结束之后,都要采用save_checkpoints函数保存模型、优化器、调度器的状态
self.save_checkpoints(epoch)
#下面一段代码定义了一个名为get_plot_data的函数,用于从模型输出中获取绘图数据,并整理为一个字典,方便后续绘图使用
def get_plot_data(self, model_outputs, pose, rgb_gt):
#获取grand truth RGB数据的形状,其中batch_size表示批次大小,num_samples表示每个样本的采样数
batch_size, num_samples, _ = rgb_gt.shape
#从模型输出中获取评估的RGB数据,并将其重塑为指定的形状
rgb_eval = model_outputs['rgb_values'].reshape(batch_size, num_samples, 3)
#从模型输出中获取法向图,并将其重塑为指定的形状
normal_map = model_outputs['normal_map'].reshape(batch_size, num_samples, 3)
#归一化法向图的范围为[0,1],因为法向图的范围一般为[-1,1]
normal_map = (normal_map + 1.) / 2.
#构建一个字典plot_data,这个字典里面包括刚刚获取的所有的绘图数据,如 ground truth 的 RGB 数据、相机姿态、评估的 RGB 数据和归一化后的法线图。
plot_data = {
'rgb_gt': rgb_gt,
'pose': pose,
'rgb_eval': rgb_eval,
'normal_map': normal_map,
}
#返回含有绘图数据的字典plot_data
return plot_data3.3 自定义的通用工具函数general.py代码详解(路径为volsdfcodeutils)
脚本general.py定义了通用性的工具函数,包括文件操作、路径操作和数据处理等。
#导入os模块,用于访问与操作系统的交互功能,例如文件操作
import os
#导入glob模块中的glob函数,用于在文件系统中搜索指定文件,其主要函数glob()可以接受包含通配符的路径,然后返回与该通配符匹配的文件名列表
from glob import glob
#导入pytorch模块,用于构建和训练神经网络
import torch
#定义了一个名为mkdir_ifnotexist的函数,该函数在volsdf_train.py中多次被引用,它接受一个目录关键字,其作用就是检查传入目录是否真实存在,如果目录不存在则按照关键字创建目录
def mkdir_ifnotexists(directory):
if not os.path.exists(directory):
os.mkdir(directory)
#定义了一个名为get_class的函数,它用于返回类名字符串对应的类对象。首先它将传入的类名字符串分割为模块名和类名,利用import导入类名,然后在逐步获得类对象,
def get_class(kls):
parts = kls.split('.')
module = ".".join(parts[:-1])
m = __import__(module)
for comp in parts[1:]:
m = getattr(m, comp)
return m
#定义了一个名为glob_imgs的函数,它会根据给定的路径,查询常见的图片文件格式[.png, .jpg, .JPEG, .JPG],并返回查询的文件名列表
def glob_imgs(path):
imgs = []
for ext in ['*.png', '*.jpg', '*.JPEG', '*.JPG']:
imgs.extend(glob(os.path.join(path, ext)))
return imgs
#定义了一个名为split_inpu的函数,它的作用是将输入的数据划分为多为子集,以适应GPU的内存限制。它将输入的数据按照像素划分为多为子集,并在每个子集中选定对应的数据。
def split_input(model_input, total_pixels, n_pixels=10000):
split = []
for i, indx in enumerate(torch.split(torch.arange(total_pixels).cuda(), n_pixels, dim=0)):
data = model_input.copy()
data['uv'] = torch.index_select(model_input['uv'], 1, indx)
if 'object_mask' in data:
data['object_mask'] = torch.index_select(model_input['object_mask'], 1, indx)
split.append(data)
return split
#定义了一个名为merge_output的函数,它的作用是将每个子集的模型进行合并形成一个完整的输出,这个完整的输出来自于多个子集,按照像素进行合并重塑成完整的一个模型。
def merge_output(res, total_pixels, batch_size):
model_outputs = {}
for entry in res[0]:
if res[0][entry] is None:
continue
if len(res[0][entry].shape) == 1:
model_outputs[entry] = torch.cat([r[entry].reshape(batch_size, -1, 1) for r in res],
1).reshape(batch_size * total_pixels)
else:
model_outputs[entry] = torch.cat([r[entry].reshape(batch_size, -1, r[entry].shape[-1]) for r in res],
1).reshape(batch_size * total_pixels, -1)
return model_outputs
#定义了一个名为concat_home_dir的函数,它的作用是将给定的路径与主目录连接起来,用于获取完整的路径,对于路径操作很有用
def concat_home_dir(path):
return os.path.join(os.environ['HOME'],'data',path)3.4 自定义的绘图函数plots.py代码详解(路径为volsdfcodeutils)
脚本plots.py定义了与绘图相关的工具函数,包括生成和保存图像,可视化数据等。
#导入plotly.graph_objs模块,并命名为go,其作用是提供创建喝修改plotly图表的工具
import plotly.graph_objs as go
#导入plotly.offline模块,并命名为offline,其作用是提供在离线环境下创建plotly图表的工具
import plotly.offline as offline
#从plotly.subplots import库中导入make_subplots模块,其作用是可以生成含有多个子图plotly图表
from plotly.subplots import make_subplots
#导入numpy数学计算库,并命名为np,用于计算和处理数组和矩阵是数据
import numpy as np
#导入pytorch模块,用于创建和训练神经网络模型
import torch
#从skimage库中导入 measure模块,skimage库是用于处理图像和计算机视觉等任务的,其中的模块measure提供了测量功能
from skimage import measure
#导入torchvision模块,它是pytorch中为计算机视觉任务提供实用工具和预训练模型的模块,可用于图像处理、目标检测、图像识别和语义分割等
import torchvision
#导入trimesh库,用于处理三角网格
import trimesh
#从PIL库中导入Image模块,PIL是用于图像处理的库,常用于图像的裁剪、旋转、滤镜等操作,还可生成和输出图像,以及图像的预处理和可视化
from PIL import Image
#从utils库中导入自定义的rend_util模块,该模块提供了与渲染有关的工具函数,常用于处理计算机视觉和图像处理任务
from utils import rend_util
#定义了一个名为plot的函数,用于绘制三维场景的可视化效果。其中接受的关键字参数有①隐式函数网络,用于生成三维场景的隐式表示;②相机索引列表,用于表示相机的位置;③绘制数据字典,包括姿态、RGB评估图像、法向图、地面真实图像等;④绘制图像的保存路径;⑤训练轮次;⑥图像分辨率,是一个二元组,包括图像的高度和宽度;⑦需要绘制的图像数量;⑧场景表面网格的分辨率;⑨场景网格的边界范围;⑩等值面阈值
def plot(implicit_network, indices, plot_data, path, epoch, img_res, plot_nimgs, resolution, grid_boundary, level=0):
#该函数首先检查提供的绘图数据字典是否为空,如果不为空,则从其中获取相机位置和方向。并调用函数plot_images和plot_normal_maps绘制RGB评估图和法向图
if plot_data is not None:
cam_loc, cam_dir = rend_util.get_camera_for_plot(plot_data['pose'])
plot_images(plot_data['rgb_eval'], plot_data['rgb_gt'], path, epoch, plot_nimgs, img_res)
plot_normal_maps(plot_data['normal_map'], path, epoch, plot_nimgs, img_res)
data = []
# 利用函数get_surface_trace获得场景表面轨迹,也就是等值面轮廓。如果获取的轨迹不为空,则将其加入data字典中。
surface_traces = get_surface_trace(path=path,
epoch=epoch,
sdf=lambda x: implicit_network(x)[:, 0],
resolution=resolution,
grid_boundary=grid_boundary,
level=level
)
if surface_traces is not None:
data.append(surface_traces[0])
# 如果绘图数据字典不为空,则根据刚刚从绘图数据字典得到的相机位置和方向调用函数get_3D_quiver_trace绘制出相机的位置和方向
if plot_data is not None:
for i, loc, dir in zip(indices, cam_loc, cam_dir):
data.append(get_3D_quiver_trace(loc.unsqueeze(0), dir.unsqueeze(0), name='camera_{0}'.format(i)))
#最后通过plotly.graph_objs库创建了一个Figure对象,其参数是刚刚获取的场景表面轨迹。并调整坐标轴范围,设置高宽和是否显示图像分辨率。最后将Figure对象保存为HTML文件
fig = go.Figure(data=data)
scene_dict = dict(xaxis=dict(range=[-6, 6], autorange=False),
yaxis=dict(range=[-6, 6], autorange=False),
zaxis=dict(range=[-6, 6], autorange=False),
aspectratio=dict(x=1, y=1, z=1))
fig.update_layout(scene=scene_dict, width=1200, height=1200, showlegend=True)
filename = '{0}/surface_{1}.html'.format(path, epoch)
offline.plot(fig, filename=filename, auto_open=False)
#定义了一个名为get_3D_scatter_trace的函数,用于创建3D散点图轨迹对象。其参数有:①三维散点坐标数组,形状为[N,3],其中N为散点数量,3为x、y、z坐标;②轨迹名称;③散点大小;④每个点的标题(可选)
def get_3D_scatter_trace(points, name='', size=3, caption=None):
#首先进行了两个断言声明,保证输入的散点坐标数组的形状是正确的
assert points.shape[1] == 3, "3d scatter plot input points are not correctely shaped "
assert len(points.shape) == 2, "3d scatter plot input points are not correctely shaped "
#利用函数go.Scatter3d创建了一个散点轨迹对象
trace = go.Scatter3d(
#x、y、z是坐标,从points数组当中获得
x=points[:, 0].cpu(),
y=points[:, 1].cpu(),
z=points[:, 2].cpu(),
#mode是绘图模式,其中markers代表绘制散点图
mode='markers',
#轨迹名称
name=name,
#设置散点样式,包括大小,线条宽度和透明度,最后还有点标题
marker=dict(
size=size,
line=dict(
width=2,
),
opacity=1.0,
), text=caption)
#返回轨迹对象
return trace
#定义了一个名为get_3D_quiver_trace的函数,用于创建三维箭头图轨迹对象。其参数有:①三维箭头的起始点坐标数组,形状为[N,3],其中N为箭头的数量,3为xyz坐标;②三维箭头的方向向量数组,形状也为[N,3];③箭头的颜色,默认为#bd1540;④轨迹的名称
def get_3D_quiver_trace(points, directions, color='#bd1540', name=''):
#首先定义了四个断言,以保证三维箭头的起始点坐标数组和方向向量数组的形状是正确的
assert points.shape[1] == 3, "3d cone plot input points are not correctely shaped "
assert len(points.shape) == 2, "3d cone plot input points are not correctely shaped "
assert directions.shape[1] == 3, "3d cone plot input directions are not correctely shaped "
assert len(directions.shape) == 2, "3d cone plot input directions are not correctely shaped "
#利用go.Cone函数创建了一个三维箭头图轨迹对象
trace = go.Cone(
#轨迹名称
name=name,
#xyz是三维箭头起始点的坐标,从输入points中获取
x=points[:, 0].cpu(),
y=points[:, 1].cpu(),
z=points[:, 2].cpu(),
#uvw是方向向量xyz坐标的分量,从输入directions中获取
u=directions[:, 0].cpu(),
v=directions[:, 1].cpu(),
w=directions[:, 2].cpu(),
#箭头大小模式,设置为absolute,即使用绝对大小
sizemode='absolute',
#箭头大小是按照sizeref比例来确定的
sizeref=0.125,
#颜色进度条,其值为False意为不显示颜色进度条
showscale=False,
#箭头颜色设置
colorscale=[[0, color], [1, color]],
#箭头锚点设置,其值为tail,意为从箭头尾部绘制
anchor="tail"
)
return trace
#定义了一个名为get_surface_trace的函数,用于获取表面轨迹图像(等值面轮廓)或者说是曲面的三角网格,其参数有:①输出路径;②训练轮次;③隐式表面函数,接受三维点的输入并返回与表面的距离;④网格分辨率,默认为 100;⑤网格边界范围,默认为 [-2.0, 2.0];⑥是否返回曲面的三角网格对象,默认为 False;⑦曲面的等值面级别,默认为 0
def get_surface_trace(path, epoch, sdf, resolution=100, grid_boundary=[-2.0, 2.0], return_mesh=False, level=0):
#使用 get_grid_uniform 函数创建一个均匀的网格
grid = get_grid_uniform(resolution, grid_boundary)
#获取网格点的坐标
points = grid['grid_points']
#获取每个网格点的隐式表面函数值,并将结果存储在 z 数组中。
z = []
for i, pnts in enumerate(torch.split(points, 100000, dim=0)):
z.append(sdf(pnts).detach().cpu().numpy())
z = np.concatenate(z, axis=0)
#如果存有sdf值的数组z是在等面值阈值level范围之内,则执行以下代码,否则返回None
if (not (np.min(z) > level or np.max(z) < level)):
z = z.astype(np.float32)
#通过 measure.marching_cubes 函数根据网格点的值计算曲面的顶点、面和法线
verts, faces, normals, values = measure.marching_cubes(
volume=z.reshape(grid['xyz'][1].shape[0], grid['xyz'][0].shape[0],
grid['xyz'][2].shape[0]).transpose([1, 0, 2]),
level=level,
spacing=(grid['xyz'][0][2] - grid['xyz'][0][1],
grid['xyz'][0][2] - grid['xyz'][0][1],
grid['xyz'][0][2] - grid['xyz'][0][1]))
#将顶点坐标加上网格边界的偏移,并获取面的索引。
verts = verts + np.array([grid['xyz'][0][0], grid['xyz'][1][0], grid['xyz'][2][0]])
I, J, K = faces.transpose()
#创建一个 go.Mesh3d 对象,表示三维曲面。设置了该对象的一些属性,如名称、颜色、不透明度等。
traces = [go.Mesh3d(x=verts[:, 0], y=verts[:, 1], z=verts[:, 2],
i=I, j=J, k=K, name='implicit_surface',
color='#ffffff', opacity=1.0, flatshading=False,
lighting=dict(diffuse=1, ambient=0, specular=0),
lightposition=dict(x=0, y=0, z=-1), showlegend=True)]
#利用trimesh.Trimesh创建了一个三维网格对象
meshexport = trimesh.Trimesh(verts, faces, normals)
#将创建的三维网格对象设置为ply文件格式
meshexport.export('{0}/surface_{1}.ply'.format(path, epoch), 'ply')
#根据输入参数return_mesh确定本函数最后返回的是三维曲面对象,还是三维网格对象
if return_mesh:
return meshexport
return traces
return None
#定义了一个名为get_surface_high_res_mesh的函数,用于生成高分辨率的隐式曲面网格。其参数有隐式表面函数sdf、场景表面网格分辨率resolution、场景网格边界grid_boundary、等值面阈值 level,以及布尔值take_components,用于选择是否要在提取网格组件时保留最大网格组件
#get_surface_high_res_mesh的工作流程是首先通过低分辨率的网格来采样曲面点云,然后对采样得到的点云进行中心对齐和变换,最后根据变换后的点云再次进行Marching Cubes算法得到高分辨率的网格。
def get_surface_high_res_mesh(sdf, resolution=100, grid_boundary=[-2.0, 2.0], level=0, take_components=True):
# get low res mesh to sample point cloud
grid = get_grid_uniform(100, grid_boundary)
z = []
points = grid['grid_points']
for i, pnts in enumerate(torch.split(points, 100000, dim=0)):
z.append(sdf(pnts).detach().cpu().numpy())
z = np.concatenate(z, axis=0)
z = z.astype(np.float32)
verts, faces, normals, values = measure.marching_cubes(
volume=z.reshape(grid['xyz'][1].shape[0], grid['xyz'][0].shape[0],
grid['xyz'][2].shape[0]).transpose([1, 0, 2]),
level=level,
spacing=(grid['xyz'][0][2] - grid['xyz'][0][1],
grid['xyz'][0][2] - grid['xyz'][0][1],
grid['xyz'][0][2] - grid['xyz'][0][1]))
verts = verts + np.array([grid['xyz'][0][0], grid['xyz'][1][0], grid['xyz'][2][0]])
mesh_low_res = trimesh.Trimesh(verts, faces, normals)
if take_components:
components = mesh_low_res.split(only_watertight=False)
areas = np.array([c.area for c in components], dtype=np.float)
mesh_low_res = components[areas.argmax()]
recon_pc = trimesh.sample.sample_surface(mesh_low_res, 10000)[0]
recon_pc = torch.from_numpy(recon_pc).float().cuda()
# Center and align the recon pc
s_mean = recon_pc.mean(dim=0)
s_cov = recon_pc - s_mean
s_cov = torch.mm(s_cov.transpose(0, 1), s_cov)
vecs = torch.view_as_real(torch.linalg.eig(s_cov)[1].transpose(0, 1))[:, :, 0]
if torch.det(vecs) < 0:
vecs = torch.mm(torch.tensor([[1, 0, 0], [0, 0, 1], [0, 1, 0]]).cuda().float(), vecs)
helper = torch.bmm(vecs.unsqueeze(0).repeat(recon_pc.shape[0], 1, 1),
(recon_pc - s_mean).unsqueeze(-1)).squeeze()
grid_aligned = get_grid(helper.cpu(), resolution)
grid_points = grid_aligned['grid_points']
g = []
for i, pnts in enumerate(torch.split(grid_points, 100000, dim=0)):
g.append(torch.bmm(vecs.unsqueeze(0).repeat(pnts.shape[0], 1, 1).transpose(1, 2),
pnts.unsqueeze(-1)).squeeze() + s_mean)
grid_points = torch.cat(g, dim=0)
# MC to new grid
points = grid_points
z = []
for i, pnts in enumerate(torch.split(points, 100000, dim=0)):
z.append(sdf(pnts).detach().cpu().numpy())
z = np.concatenate(z, axis=0)
meshexport = None
if (not (np.min(z) > level or np.max(z) < level)):
z = z.astype(np.float32)
verts, faces, normals, values = measure.marching_cubes(
volume=z.reshape(grid_aligned['xyz'][1].shape[0], grid_aligned['xyz'][0].shape[0],
grid_aligned['xyz'][2].shape[0]).transpose([1, 0, 2]),
level=level,
spacing=(grid_aligned['xyz'][0][2] - grid_aligned['xyz'][0][1],
grid_aligned['xyz'][0][2] - grid_aligned['xyz'][0][1],
grid_aligned['xyz'][0][2] - grid_aligned['xyz'][0][1]))
verts = torch.from_numpy(verts).cuda().float()
verts = torch.bmm(vecs.unsqueeze(0).repeat(verts.shape[0], 1, 1).transpose(1, 2),
verts.unsqueeze(-1)).squeeze()
verts = (verts + grid_points[0]).cpu().numpy()
meshexport = trimesh.Trimesh(verts, faces, normals)
return meshexport
#定义了一个名为 get_surface_by_grid函数,用于根据网格参数和隐式函数生成隐式曲面的网格。其参数有网格参数grid_params、隐式表面函数sdf、场景表面网格分辨率resolution、场景网格边界grid_boundary、等值面阈值 level,以及布尔值higher_res,用于选择是否要用高分辨率的方式获取隐式曲面网格
#get_surface_by_grid的工作流程是根据给定的网格参数,生成规则的网格,然后通过隐式函数计算每个网格点的曲面高度,最后根据曲面高度和曲面水平值使用 Marching Cubes 算法得到曲面的网格表示。
def get_surface_by_grid(grid_params, sdf, resolution=100, level=0, higher_res=False):
grid_params = grid_params * [[1.5], [1.0]]
# params = PLOT_DICT[scan_id]
input_min = torch.tensor(grid_params[0]).float()
input_max = torch.tensor(grid_params[1]).float()
if higher_res:
# get low res mesh to sample point cloud
grid = get_grid(None, 100, input_min=input_min, input_max=input_max, eps=0.0)
z = []
points = grid['grid_points']
for i, pnts in enumerate(torch.split(points, 100000, dim=0)):
z.append(sdf(pnts).detach().cpu().numpy())
z = np.concatenate(z, axis=0)
z = z.astype(np.float32)
verts, faces, normals, values = measure.marching_cubes(
volume=z.reshape(grid['xyz'][1].shape[0], grid['xyz'][0].shape[0],
grid['xyz'][2].shape[0]).transpose([1, 0, 2]),
level=level,
spacing=(grid['xyz'][0][2] - grid['xyz'][0][1],
grid['xyz'][0][2] - grid['xyz'][0][1],
grid['xyz'][0][2] - grid['xyz'][0][1]))
verts = verts + np.array([grid['xyz'][0][0], grid['xyz'][1][0], grid['xyz'][2][0]])
mesh_low_res = trimesh.Trimesh(verts, faces, normals)
components = mesh_low_res.split(only_watertight=False)
areas = np.array([c.area for c in components], dtype=np.float)
mesh_low_res = components[areas.argmax()]
recon_pc = trimesh.sample.sample_surface(mesh_low_res, 10000)[0]
recon_pc = torch.from_numpy(recon_pc).float().cuda()
# Center and align the recon pc
s_mean = recon_pc.mean(dim=0)
s_cov = recon_pc - s_mean
s_cov = torch.mm(s_cov.transpose(0, 1), s_cov)
vecs = torch.view_as_real(torch.linalg.eig(s_cov)[1].transpose(0, 1))[:, :, 0]
if torch.det(vecs) < 0:
vecs = torch.mm(torch.tensor([[1, 0, 0], [0, 0, 1], [0, 1, 0]]).cuda().float(), vecs)
helper = torch.bmm(vecs.unsqueeze(0).repeat(recon_pc.shape[0], 1, 1),
(recon_pc - s_mean).unsqueeze(-1)).squeeze()
grid_aligned = get_grid(helper.cpu(), resolution, eps=0.01)
else:
grid_aligned = get_grid(None, resolution, input_min=input_min, input_max=input_max, eps=0.0)
grid_points = grid_aligned['grid_points']
if higher_res:
g = []
for i, pnts in enumerate(torch.split(grid_points, 100000, dim=0)):
g.append(torch.bmm(vecs.unsqueeze(0).repeat(pnts.shape[0], 1, 1).transpose(1, 2),
pnts.unsqueeze(-1)).squeeze() + s_mean)
grid_points = torch.cat(g, dim=0)
# MC to new grid
points = grid_points
z = []
for i, pnts in enumerate(torch.split(points, 100000, dim=0)):
z.append(sdf(pnts).detach().cpu().numpy())
z = np.concatenate(z, axis=0)
meshexport = None
if (not (np.min(z) > level or np.max(z) < level)):
z = z.astype(np.float32)
verts, faces, normals, values = measure.marching_cubes(
volume=z.reshape(grid_aligned['xyz'][1].shape[0], grid_aligned['xyz'][0].shape[0],
grid_aligned['xyz'][2].shape[0]).transpose([1, 0, 2]),
level=level,
spacing=(grid_aligned['xyz'][0][2] - grid_aligned['xyz'][0][1],
grid_aligned['xyz'][0][2] - grid_aligned['xyz'][0][1],
grid_aligned['xyz'][0][2] - grid_aligned['xyz'][0][1]))
if higher_res:
verts = torch.from_numpy(verts).cuda().float()
verts = torch.bmm(vecs.unsqueeze(0).repeat(verts.shape[0], 1, 1).transpose(1, 2),
verts.unsqueeze(-1)).squeeze()
verts = (verts + grid_points[0]).cpu().numpy()
else:
verts = verts + np.array([grid_aligned['xyz'][0][0], grid_aligned['xyz'][1][0], grid_aligned['xyz'][2][0]])
meshexport = trimesh.Trimesh(verts, faces, normals)
# CUTTING MESH ACCORDING TO THE BOUNDING BOX
if higher_res:
bb = grid_params
transformation = np.eye(4)
transformation[:3, 3] = (bb[1,:] + bb[0,:])/2.
bounding_box = trimesh.creation.box(extents=bb[1,:] - bb[0,:], transform=transformation)
meshexport = meshexport.slice_plane(bounding_box.facets_origin, -bounding_box.facets_normal)
return meshexport
#总的来说,get_surface_high_res_mesh函数主要用于生成高分辨率的曲面网格,并通过点云的采样和变换来优化网格质量;而get_surface_by_grid函数则更加通用,可以根据不同的网格参数来生成曲面网格,同时也支持使用高分辨率的方式来生成网格。
#定义了一个名为get_grid_uniform的函数,用于生成均匀分布的三维网格,其参数有场景表面网格分辨率喝场景网格边界范围。
def get_grid_uniform(resolution, grid_boundary=[-2.0, 2.0]):
#首先利用一个函数np.linspace来获取一维均匀分布的网格点坐标x
x = np.linspace(grid_boundary[0], grid_boundary[1], resolution)
#将x的值赋予y和z,因为最后得到的是一个均匀分布的三维网格,所以三个方向的坐标网格都一样
y = x
z = x
#通过函数np.meshgrid来获取三维网格,其中xx,yy,zz是三个维度的坐标网格
xx, yy, zz = np.meshgrid(x, y, z)
#利用函数torch.tensor将刚刚得到的三维网格转为pytorch张量,并转移到GPU上
grid_points = torch.tensor(np.vstack([xx.ravel(), yy.ravel(), zz.ravel()]).T, dtype=torch.float)
#最后返回一个字典,里面包括每个网格点的坐标、最短轴长度、最短轴索引、每个轴坐标范围
return {"grid_points": grid_points.cuda(),
"shortest_axis_length": 2.0,
"xyz": [x, y, z],
"shortest_axis_index": 0}
#定义了一个名为get_grid的函数,与之前的 get_grid_uniform 函数不同,它并不是生成均匀分布的网格,而是接受了一些输入点并根据这些点的分布生成网格。其参数为输入的点云points,可以是一个 PyTorch 张量、场景表面网格分辨率resolution 、输入点云的最小和最大坐标值input_min 和 input_max 、用于确保网格边界扩展的小量eps
def get_grid(points, resolution, input_min=None, input_max=None, eps=0.1):
#如果输入参数中国没有提供输入点云的最小和最大坐标值,则通过 torch.min 和 torch.max 函数计算出来这两个值,并将其转换为 NumPy 数组。
if input_min is None or input_max is None:
input_min = torch.min(points, dim=0)[0].squeeze().numpy()
input_max = torch.max(points, dim=0)[0].squeeze().numpy()
#将输入点云坐标的最大值和最小值相减得点云的边界框
bounding_box = input_max - input_min
#利用函数 np.argmin从点云边界框中找到最小边界框的维度,从而得到最短轴的值
shortest_axis = np.argmin(bounding_box)
#根据最短轴的不同,生成不同方向上的网格坐标 x、y、z。这些坐标分别在最小值减去 eps 和最大值加上 eps 的范围内均匀分布。
if (shortest_axis == 0):
x = np.linspace(input_min[shortest_axis] - eps,
input_max[shortest_axis] + eps, resolution)
length = np.max(x) - np.min(x)
y = np.arange(input_min[1] - eps, input_max[1] + length / (x.shape[0] - 1) + eps, length / (x.shape[0] - 1))
z = np.arange(input_min[2] - eps, input_max[2] + length / (x.shape[0] - 1) + eps, length / (x.shape[0] - 1))
elif (shortest_axis == 1):
y = np.linspace(input_min[shortest_axis] - eps,
input_max[shortest_axis] + eps, resolution)
length = np.max(y) - np.min(y)
x = np.arange(input_min[0] - eps, input_max[0] + length / (y.shape[0] - 1) + eps, length / (y.shape[0] - 1))
z = np.arange(input_min[2] - eps, input_max[2] + length / (y.shape[0] - 1) + eps, length / (y.shape[0] - 1))
elif (shortest_axis == 2):
z = np.linspace(input_min[shortest_axis] - eps,
input_max[shortest_axis] + eps, resolution)
length = np.max(z) - np.min(z)
x = np.arange(input_min[0] - eps, input_max[0] + length / (z.shape[0] - 1) + eps, length / (z.shape[0] - 1))
y = np.arange(input_min[1] - eps, input_max[1] + length / (z.shape[0] - 1) + eps, length / (z.shape[0] - 1))
#通过函数np.meshgrid来获取三维网格,其中xx,yy,zz是三个维度的坐标网格
xx, yy, zz = np.meshgrid(x, y, z)
##利用函数torch.tensor将刚刚得到的三维网格转为pytorch张量,并转移到GPU上
grid_points = torch.tensor(np.vstack([xx.ravel(), yy.ravel(), zz.ravel()]).T, dtype=torch.float).cuda()
#最后返回一个字典,里面包括每个网格点的坐标、最短轴长度、最短轴索引、每个轴坐标范围
return {"grid_points": grid_points,
"shortest_axis_length": length,
"xyz": [x, y, z],
"shortest_axis_index": shortest_axis}
#定义了一个名为plot_normal_maps的函数,用于将法向图转为图像,并保存为PNG格式。其参数有法向图normal_maps,保存图像路径 path,训练轮次epoch,在图像的每一行中显示法向图数量plot_nrow,法向图分辨率img_res
def plot_normal_maps(normal_maps, path, epoch, plot_nrow, img_res):
#利用函数lin2img将法向图转为图像
normal_maps_plot = lin2img(normal_maps, img_res)
#利用函数torchvision.utils.make_grid创建网格图像,将所有法向图都包含在一个图形内
tensor = torchvision.utils.make_grid(normal_maps_plot,
#不对每一个图进行独立缩放
scale_each=False,
#不对图像进行标准化处理
normalize=False,
#在图像的每一行中显示法向图的数量
nrow=plot_nrow).cpu().detach().numpy()#将Pytorch张量(法向图转换的图像)转换为numpy数组
tensor = tensor.transpose(1, 2, 0)
scale_factor = 255
tensor = (tensor * scale_factor).astype(np.uint8)
#利用函数Image.fromarray将numpy数组转换为PNG图像,每张图像的命名为normal_{epoch}.png,并保存在指定路径之下
img = Image.fromarray(tensor)
img.save('{0}/normal_{1}.png'.format(path, epoch))
#定义了一个名为plot_images的函数,用于将RGB图像与地面真实图像结合。其参数有输入的RGB图像rgb_points,输入的地面真实图像ground_true,保存图像的路径path,训练轮次epoch,图像每一行显示图像的数量plot_nrow,图像分辨率img_res
def plot_images(rgb_points, ground_true, path, epoch, plot_nrow, img_res):
#首先将输入的地面真实图像移到GPU上,便于与RGB图像结合
ground_true = ground_true.cuda()
#将RGB图像与地面真实图像沿着通道维度拼接
output_vs_gt = torch.cat((rgb_points, ground_true), dim=0)
#利用函数lin2img将拼接得到的图像转换为适用于函数make_grid的格式
output_vs_gt_plot = lin2img(output_vs_gt, img_res)
#利用函数torchvision.utils.make_grid创建网格图像,将所有拼接的图像包含在一个图像之内
tensor = torchvision.utils.make_grid(output_vs_gt_plot,
不对每一个图进行独立缩放
scale_each=False,
#不对图像进行标准化处理
normalize=False,
#在图像的每一行中显示图像的数量
nrow=plot_nrow).cpu().detach().numpy()
#将Pytorch张量(拼接的图像)转换为numpy数组
tensor = tensor.transpose(1, 2, 0)
scale_factor = 255
tensor = (tensor * scale_factor).astype(np.uint8)
#利用函数Image.fromarray将numpy数组转换为PNG图像,每张图像的命名为rendering_{epoch}.png,并保存在指定路径之下
img = Image.fromarray(tensor)
img.save('{0}/rendering_{1}.png'.format(path, epoch))
#定义了一个名为lin2img的函数,用于将一个张量重新排列为图像格式。其参数有:①输入的张量tensor,大小为 (batch_size, num_samples, channels) 的张量,其中 batch_size 表示批大小,num_samples 表示样本数量,channels 表示通道数;②输出图像的分辨率img_res,包含两个元素的列表,表示图像的高度和宽度。
def lin2img(tensor, img_res):
#获取输入张量的形状信息,包括批大小、样本数量和通道数。
batch_size, num_samples, channels = tensor.shape
#使用 permute 函数重新排列张量的维度,将通道维度移动到最后,以便转换为图像格式。接着,使用 view 函数将张量重新排列成图像格式,大小为 (batch_size, channels, img_res[0], img_res[1]),其中 img_res[0] 表示图像的高度,img_res[1] 表示图像的宽度。
return tensor.permute(0, 2, 1).view(batch_size, channels, img_res[0], img_res[1])3.5 自定义的渲染函数rend_uti.py代码详解(路径为volsdfcodeutils)
脚本rend_uti.py定义了与渲染相关的工具函数,用于图像处理和计算机视觉任务,包括计算PSNR、计算相机射线、根据投影矩阵得到相机内外参、加载RGB图像,以及一些辅助函数。
#导入numpy数学计算库,用于计算和处理数组和矩阵等数据
import numpy as np
#导入imageio模块,用于写入、读取和处理图像文件,完成图像处理任务
import imageio
#导入skimage模块,用于完成图像处理和计算机视觉任务,如图像滤波、加载图像和图像转换等
import skimage
#导入Opencv模块,用于完成图像处理和计算机视觉任务,并且可以根据投影矩阵获取相机内外参
import cv2
#导入Pytorch模块,用于创建和训练神经网络
import torch
#导入Pytorch模块中的functional模块,并命名为F,该模块中包含了很多与深度学习相关的函数,如损失函数、激活函数等
from torch.nn import functional as F
#定义了一个名为get_psnr的函数,用于计算模型的PSNR值
def get_psnr(img1, img2, normalize_rgb=False):
#如果normalize_rgb为Ture就将图像的值从-1到1设置为0到1。normalize_rgb是布尔类型的变量,其值如果为Ture就要对加载的图像进行归一化处理,否则不进行归一化处理
if normalize_rgb: # [-1,1] --> [0,1]
img1 = (img1 + 1.) / 2.
img2 = (img2 + 1. ) / 2.
#根据两张图像的均方误差MSE计算模型的PSNR值
mse = torch.mean((img1 - img2) ** 2)
psnr = -10. * torch.log(mse) / torch.log(torch.Tensor([10.]).cuda())
return psnr
#定义了一个名为load_rgb的函数,用于加载RGB图像
def load_rgb(path, normalize_rgb = False):
#根据指定路径加载RGB图像,并将图像类型改为32为浮点型
img = imageio.imread(path)
img = skimage.img_as_float32(img)
#如果normalize_rgb为Ture就将图像的值从-1到1设置为0到1
if normalize_rgb: # [-1,1] --> [0,1]
img -= 0.5
img *= 2.
img = img.transpose(2, 0, 1)
return img
#定义了一个名为load_K_Rt_from_P的函数,用于从投影矩阵中获取相机的内外惨。
def load_K_Rt_from_P(filename, P=None):
#如果投影矩阵P为空的话,就在文件系统中搜索出投影矩阵
if P is None:
lines = open(filename).read().splitlines()
if len(lines) == 4:
lines = lines[1:]
lines = [[x[0], x[1], x[2], x[3]] for x in (x.split(" ") for x in lines)]
P = np.asarray(lines).astype(np.float32).squeeze()
#利用Opencv库中定义的decomposeProjectionMatrix函数从投影矩阵中获取相机的内参矩阵、旋转矩阵和平移向量
out = cv2.decomposeProjectionMatrix(P)
K = out[0]
R = out[1]
t = out[2]
K = K/K[2,2]
intrinsics = np.eye(4)
intrinsics[:3, :3] = K
pose = np.eye(4, dtype=np.float32)
pose[:3, :3] = R.transpose()
pose[:3,3] = (t[:3] / t[3])[:,0]
return intrinsics, pose
#定义了一个名为get_camera_params的函数,用于计算相机的射线和位置
def get_camera_params(uv, pose, intrinsics):
#根据像素的坐标、位姿和相机的内参计算相机的射线和位置
if pose.shape[1] == 7: #In case of quaternion vector representation
cam_loc = pose[:, 4:]
R = quat_to_rot(pose[:,:4])
p = torch.eye(4).repeat(pose.shape[0],1,1).cuda().float()
p[:, :3, :3] = R
p[:, :3, 3] = cam_loc
else: # In case of pose matrix representation
cam_loc = pose[:, :3, 3]
p = pose
batch_size, num_samples, _ = uv.shape
depth = torch.ones((batch_size, num_samples)).cuda()
x_cam = uv[:, :, 0].view(batch_size, -1)
y_cam = uv[:, :, 1].view(batch_size, -1)
z_cam = depth.view(batch_size, -1)
pixel_points_cam = lift(x_cam, y_cam, z_cam, intrinsics=intrinsics)
# 将像素坐标的点映射到相机坐标系下,计算相机射线的方向和位置
pixel_points_cam = pixel_points_cam.permute(0, 2, 1)
world_coords = torch.bmm(p, pixel_points_cam).permute(0, 2, 1)[:, :, :3]
ray_dirs = world_coords - cam_loc[:, None, :]
ray_dirs = F.normalize(ray_dirs, dim=2)
return ray_dirs, cam_loc
#定义了一个名为get_camera_for_plot的函数,用于绘制相机位置
def get_camera_for_plot(pose):
#将像素坐标的射线映射到相机坐标,进而得到相机的位置和方向,从而为绘制相机姿态做准备
if pose.shape[1] == 7: #In case of quaternion vector representation
cam_loc = pose[:, 4:].detach()
R = quat_to_rot(pose[:,:4].detach())
else: # In case of pose matrix representation
cam_loc = pose[:, :3, 3]
R = pose[:, :3, :3]
cam_dir = R[:, :3, 2]
return cam_loc, cam_dir
#定义了一个名为lift的函数,用于像素坐标到相机坐标的映射
def lift(x, y, z, intrinsics):
# parse intrinsics
intrinsics = intrinsics.cuda()
fx = intrinsics[:, 0, 0]
fy = intrinsics[:, 1, 1]
cx = intrinsics[:, 0, 2]
cy = intrinsics[:, 1, 2]
sk = intrinsics[:, 0, 1]
x_lift = (x - cx.unsqueeze(-1) + cy.unsqueeze(-1)*sk.unsqueeze(-1)/fy.unsqueeze(-1) - sk.unsqueeze(-1)*y/fy.unsqueeze(-1)) / fx.unsqueeze(-1) * z
y_lift = (y - cy.unsqueeze(-1)) / fy.unsqueeze(-1) * z
# homogeneous
return torch.stack((x_lift, y_lift, z, torch.ones_like(z).cuda()), dim=-1)
#定义了一个名为quat_to_rot的函数,用于将四元数表示的旋转转换为旋转矩阵。四元数是一种用于表示三维空间中的旋转的数学工具。在深度学习中,常常使用四元数来表示旋转,因为它们在数值计算中具有一些优势。这个函数将输入的四元数张量转换为对应的旋转矩阵张量。
def quat_to_rot(q):
batch_size, _ = q.shape
q = F.normalize(q, dim=1)
R = torch.ones((batch_size, 3,3)).cuda()
qr=q[:,0]
qi = q[:, 1]
qj = q[:, 2]
qk = q[:, 3]
R[:, 0, 0]=1-2 * (qj**2 + qk**2)
R[:, 0, 1] = 2 * (qj *qi -qk*qr)
R[:, 0, 2] = 2 * (qi * qk + qr * qj)
R[:, 1, 0] = 2 * (qj * qi + qk * qr)
R[:, 1, 1] = 1-2 * (qi**2 + qk**2)
R[:, 1, 2] = 2*(qj*qk - qi*qr)
R[:, 2, 0] = 2 * (qk * qi-qj * qr)
R[:, 2, 1] = 2 * (qj*qk + qi*qr)
R[:, 2, 2] = 1-2 * (qi**2 + qj**2)
return R
#定义了一个名为quat_to_rot的函数,用于将旋转矩阵转换为四元数表示的旋转。这个函数的作用是与quat_to_rot相反。
def rot_to_quat(R):
batch_size, _,_ = R.shape
q = torch.ones((batch_size, 4)).cuda()
R00 = R[:, 0,0]
R01 = R[:, 0, 1]
R02 = R[:, 0, 2]
R10 = R[:, 1, 0]
R11 = R[:, 1, 1]
R12 = R[:, 1, 2]
R20 = R[:, 2, 0]
R21 = R[:, 2, 1]
R22 = R[:, 2, 2]
q[:,0]=torch.sqrt(1.0+R00+R11+R22)/2
q[:, 1]=(R21-R12)/(4*q[:,0])
q[:, 2] = (R02 - R20) / (4 * q[:, 0])
q[:, 3] = (R10 - R01) / (4 * q[:, 0])
return q
#定义了一个名为get_sphere_intersections的函数,用于计算相机射线到单位球面的交点。
#在三维计算机图形学中,相机通常被建模为位于三维空间中的一个点,它发出多条射线,代表从相机位置向场景中各个方向的视线。这些射线在场景中与不同的几何体相交,这些交点用于确定场景中的可见部分以及渲染图像。
#单位球面通常被用来表示场景的边界或限制相机的运动范围。
#计算相机射线与单位球面的交点可以用于以下几种情况:①碰撞检测:用于检测相机是否与单位球面相交,从而限制相机的移动范围,避免相机穿过场景边界。②视锥剔除:用于确定相机视锥与单位球面的交点,以确定哪些场景对象位于相机的视野内,进而进行渲染。③遮挡剔除:用于确定相机射线与球面的交点,以确定场景中的遮挡物体,从而减少不可见部分的渲染成本。
def get_sphere_intersections(cam_loc, ray_directions, r = 1.0):
# Input: n_rays x 3 ; n_rays x 3
# Output: n_rays x 1, n_rays x 1 (close and far)
ray_cam_dot = torch.bmm(ray_directions.view(-1, 1, 3),
cam_loc.view(-1, 3, 1)).squeeze(-1)
under_sqrt = ray_cam_dot ** 2 - (cam_loc.norm(2, 1, keepdim=True) ** 2 - r ** 2)
# sanity check
if (under_sqrt <= 0).sum() > 0:
print('BOUNDING SPHERE PROBLEM!')
exit()
sphere_intersections = torch.sqrt(under_sqrt) * torch.Tensor([-1, 1]).cuda().float() - ray_cam_dot
sphere_intersections = sphere_intersections.clamp_min(0.0)
return sphere_intersections4、Volsdf模型评估过程代码详解
4.1 eval.py代码详解
下面的代码是eval.py里面的脚本,该脚本主要用于评估模型性能,其总体框架包括命令行参数分析、模型和数据加载、评估和渲染等步骤。
#导入sys模块,用于访问与python解释器交互的功能
import sys
#将上级目录中的code目录加入python解释器的搜索路径中,以便该脚本可以引用code目录下自定义的模块
sys.path.append('../code')
#导入argparse模块,用于解析命令行参数
import argparse
#导入GPUtil模块,用于获取GPU相关信息
import GPUtil
#导入os模块,用于访问与操作系统交互的功能
import os
#导入pyhocon库中的ConfigFactory类,用于解析HOCON格式的配置文件
from pyhocon import ConfigFactory
#导入pytorch深度学习框架,用于构建和训练神经网络
import torch
#导入numpy数学计算库,用于计算和处理数组和矩阵数据
import numpy as np
#导入PIL库中的Image模块,用于图像的处理和操作
from PIL import Image
#从tqdm库中导入tqdm函数,用于显示训练过程中的进度条
from tqdm import tqdm
#导入pandas库,用于数据的处理和分析
import pandas as pd
#以下三个导入的模块,是volsdfcodeutils目录下自定义的模块
#导入自定义的general模块,别名为utils,定义了一些通用工具函数
import utils.general as utils
#导入自定义的plots模块,别名为plt,定义了一些绘图工具函数
import utils.plots as plt
#导入自定义的rend_util模块,定义了一些渲染工具函数
from utils import rend_util
#以下一段代码定义了一个名为evaluate的函数,用于评估模型性能
#定义了一个名为evaluate的函数,其可接受的参数为**kwargs,该参数**kwargs用于接受任意数量的关键字参数
def evaluate(**kwargs):
#定义pytorch的默认数据类型为32为浮点数
torch.set_default_dtype(torch.float32)
#定义pytorch的线程数为1,这样可以提高计算效率
torch.set_num_threads(1)
#使用ConfigFactory解析初始传入参数kwargs的指定配置文件,并将解析后的配置信息存储在变量conf中
conf = ConfigFactory.parse_file(kwargs['conf'])
#获取初始传入参数kwargs的实验文件名称,并存于变量exps_folder_name
exps_folder_name = kwargs['exps_folder_name']
#获取初始传入参数kwargs的评估文件名称,并存于变量evals_folder_name
evals_folder_name = kwargs['evals_folder_name']
#获取初始传入参数kwargs的渲染文件名称,并存于变量eval_rendering
eval_rendering = kwargs['eval_rendering']
#从配置文件中获取训练过程的实验文件名称,并获取初始传入参数kwargs的实验文件名称,将两者组合形成评估过程的实验文件名称,存于变量expname中
expname = conf.get_string('train.expname') + kwargs['expname']
#判断初始传入参数kwargs的扫描ID的值是否为-1,如果不是就将获取到的值存于变量scan_id中,如果是就获取配置文件中默认的扫描ID的值存于变量scan_id中
scan_id = kwargs['scan_id'] if kwargs['scan_id'] != -1 else conf.get_int('dataset.scan_id', default=-1)
#如果扫描ID不为-1,则将评估过程中存储实验结果的文件夹名称加上扫面ID,如dtu_24
if scan_id != -1:
expname = expname + '_{0}'.format(scan_id)
#如果扫描ID为-1,则从配置文件中取出数据集对象的值作为扫描ID的值
else:
scan_id = conf.get_string('dataset.object', default='')
#如果命令行初始化时传递给参数kwargs的时间戳timestamp为latest,则执行以下代码。
if kwargs['timestamp'] == 'latest':
#如果训练过程中存储实验结果的文件夹存在,则获取训练实验文件夹中所有的时间戳列表,并存于变量timestamps。紧接着又判断变量timestamps的长度是否为0
if os.path.exists(os.path.join('../', kwargs['exps_folder_name'], expname)):
timestamps = os.listdir(os.path.join('../', kwargs['exps_folder_name'], expname))
#如果变量timestamps的长度为0,则打印训练实验文件警告的文本,并利用exit退出代码运行过程。
if (len(timestamps)) == 0:
print('WRONG EXP FOLDER')
exit()
#如果变量timestamps(训练实验文件夹的时间戳列表)的长度不为0,则初始化变量timestamp(命令行中的传入的时间戳)为None。
timestamp = None
#利用for循环遍历排列好的时间戳列表
for t in sorted(timestamps):
#如果存在着符合条件的时间戳t,则t赋值给变量timestamp
if os.path.exists(os.path.join('../', kwargs['exps_folder_name'], expname, t, 'checkpoints',
'ModelParameters', str(kwargs['checkpoint']) + ".pth")):
timestamp = t
#如果循环完整个时间戳列表timestamps后,都没有一个合适的时间戳赋值给变量timestamp,则打印没有好的时间戳,并利用exit退出程序运行。
if timestamp is None:
print('NO GOOD TIMSTAMP')
exit()
#如果训练过程中存储实验结果的文件夹不存在,则输出训练实验文件警告的文本,并利用exit退出代码运行过程。
else:
print('WRONG EXP FOLDER')
exit()
#如果命令行初始化时传递给参数kwargs的时间戳不为latest,则将参数kwargs中的时间戳的值保存在评估过程定义的变量timestamp中
else:
timestamp = kwargs['timestamp']
#检查是否存在存储评估过程实验结果的目录evals,如果不存在则使用utils目录下定义的方法mkdir_ifnotexists创建目录evals,其目录为volsdfevals
utils.mkdir_ifnotexists(os.path.join('../', evals_folder_name))
#创建训练过程存储实验结果的路径,如volsdfexpsdtu_24,,并存储在变量expdir中
expdir = os.path.join('../', exps_folder_name, expname)
#创建评估过程存储实验结果的路径,如volsdfevalsdtu_24,并存储在变量evaldir中
evaldir = os.path.join('../', evals_folder_name, expname)
#如果不存在评估过程存储实验结果的路径evaldir,使用utils目录下定义的方法mkdir_ifnotexists创建路径evaldir
utils.mkdir_ifnotexists(evaldir)
#从配置文件中获取数据集的配置,并存储于列表dataset_conf中
dataset_conf = conf.get_config('dataset')
#如果命令行初始化时传递给参数kwargs的扫描ID不为-1,则将数据集配置列表中的扫描ID的值设置为参数kwargs的扫描ID
if kwargs['scan_id'] != -1:
dataset_conf['scan_id'] = kwargs['scan_id']
#获取配置文件中指定的数据集类别和配置来创建评估数据集对象
eval_dataset = utils.get_class(conf.get_string('train.dataset_class'))(**dataset_conf)
#获取配置文件中模型的配置信息,并存储于列表conf_model中
conf_model = conf.get_config('model')
#获取配置文件中指定的模型类别和配置来创建模型对象
model = utils.get_class(conf.get_string('train.model_class'))(conf=conf_model)
#如果GPU可用的话,将模型移动到GPU上进行运算
if torch.cuda.is_available():
model.cuda()
#以下一段代码是对于相机优化的设置
#获取相机优化比例矩阵,存于变量scale_mat
scale_mat = eval_dataset.get_scale_mat()
#如果需要评估渲染效果,则创建数据集加载器,用于加载评估数据集,每次只加载一个样本
if eval_rendering:
eval_dataloader = torch.utils.data.DataLoader(eval_dataset,
batch_size=1,
shuffle=False,
collate_fn=eval_dataset.collate_fn
)
#获取评估数据集的总像素数,存于变量scale_mat
total_pixels = eval_dataset.total_pixels
#获取评估数据集的图像分辨率,存于变量img_res
img_res = eval_dataset.img_res
#获取配置文件中用于分割输入的像素数,存于变量split_n_pixels
split_n_pixels = conf.get_int('train.split_n_pixels', 10000)
#创建存于训练过程实验文件exps中检查点的路径,并存于变量old_checkpnts_dir中,便于恢复模型参数
old_checkpnts_dir = os.path.join(expdir, timestamp, 'checkpoints')
#加载保存于训练过程检查点的模型参数
saved_model_state = torch.load(os.path.join(old_checkpnts_dir, 'ModelParameters', str(kwargs['checkpoint']) + ".pth"))
#将加载的模型参数用于模型对象上
model.load_state_dict(saved_model_state["model_state_dict"])
#获取加载模型参数中的训练轮次,存于变量epoch中
epoch = saved_model_state['epoch']
####################################################################################################################
#下面一段代码用于对模型进行评估,并生成可视化的结果
#打印评估开始的文本
print("evaluating...")
#将模型调为评估模式,目的是防止dropout正则化和batch normalization正则化的影响
model.eval()
#利用with循环来生成可视化的网格表面,并且利用torch.no_grad()上下文管理器保证在评估过程中不计算梯度,节省内存和计算资源
with torch.no_grad():
#检查扫描ID的大小,根据扫描ID的值来确定使用哪种模式进行渲染评估
#如果扫描ID的值小于24(不包括等于24),则采用Blended MVS模式来进行渲染评估
if scan_id < 24: # Blended MVS
#利用plt.get_surface_high_res_mesh方法获得高分辨率的网格表面
mesh = plt.get_surface_high_res_mesh(
sdf=lambda x: model.implicit_network(x)[:, 0],
resolution=kwargs['resolution'],
grid_boundary=conf.get_list('plot.grid_boundary'),
level=conf.get_int('plot.level', default=0),
take_components = type(scan_id) is not str
)
#如果扫描ID的值大于等于24,则采用DTU模式来进行渲染评估
else: # DTU
bb_dict = np.load('../data/DTU/bbs.npz')
grid_params = bb_dict[str(scan_id)]
#利用plt.get_surface_by_grid方法将获得的网格参数来生成表面
mesh = plt.get_surface_by_grid(
grid_params=grid_params,
sdf=lambda x: model.implicit_network(x)[:, 0],
resolution=kwargs['resolution'],
level=conf.get_int('plot.level', default=0),
higher_res=True
)
# 将网格表面转到世界坐标系下
mesh.apply_transform(scale_mat)
# 将网格表面划分为多个组件
components = mesh.split(only_watertight=False)
#计算每个组件的表面积
areas = np.array([c.area for c in components], dtype=np.float32)
#将表面积最大的组件作为最终的网格
mesh_clean = components[areas.argmax()]
#创建存储网格文件夹的路径,如volsdfevalsdtu_242000,其中2000代表着2000次的训练轮次,将路径存于变量mesh_folder
mesh_folder = '{0}/{1}'.format(evaldir, epoch)
#若变量mesh_folder存储的路径不存在,则使用mkdir_ifnotexists方法创建该路径
utils.mkdir_ifnotexists(mesh_folder)
#将最终的网格导出为ply文件,并存于路径mesh_folder中
mesh_clean.export('{0}/scan{1}.ply'.format(mesh_folder, scan_id), 'ply')
#如果要评估渲染结果,则执行以下代码块
if eval_rendering:
#构建存储渲染图片的文件夹路径,里面包括评估过程的实验文件路径以及训练轮次,如volsdfevalsdtu_24
endering_2000
images_dir = '{0}/rendering_{1}'.format(evaldir, epoch)
#如果没有存储存储渲染图片的文件夹路径,则利用方法mkdir_ifnotexists创建该路径
utils.mkdir_ifnotexists(images_dir)
#将PSNR(峰值信噪比)列表初始化为空,该列表用于存储每张渲染图像的评估结果
psnrs = []
#利用for循环迭代评估过程数据加载器的每一个数据
for data_index, (indices, model_input, ground_truth) in enumerate(eval_dataloader):
#将评估过程数据加载器中的相机内参、像素坐标和相机位姿等数据移动到GPU上进行计算
model_input["intrinsics"] = model_input["intrinsics"].cuda()
model_input["uv"] = model_input["uv"].cuda()
model_input['pose'] = model_input['pose'].cuda()
#将模型输入的数据进行分割,形成多个批次的数据,以便于适用模型的计算
split = utils.split_input(model_input, total_pixels, n_pixels=split_n_pixels)
#将存储每个批次数据渲染结果的列表初始化为空
res = []
#利用for循环遍历所有批次的数据
for s in tqdm(split):
#手动释放GPU的内存,以便提高计算效率
torch.cuda.empty_cache()
#利用模型进行推断,得到渲染图像
out = model(s)
#将每个批次数据得到的渲染结果都存于结果列表res中
res.append({
'rgb_values': out['rgb_values'].detach(),
})
#获取整个数据集RGB图像的数量
batch_size = ground_truth['rgb'].shape[0]
#将分割的渲染效果进行合并,得到整个渲染结果
model_outputs = utils.merge_output(res, total_pixels, batch_size)
#获取输出模型的RGB值
rgb_eval = model_outputs['rgb_values']
#对最终的渲染效果的形状重新塑形
rgb_eval = rgb_eval.reshape(batch_size, total_pixels, 3)
#将线值转为图像像素值,并将渲染结果转移到cpu上
rgb_eval = plt.lin2img(rgb_eval, img_res).detach().cpu().numpy()[0]
#将图像数据从PyTorch张量格式转换为常见的图像格式
rgb_eval = rgb_eval.transpose(1, 2, 0)
#创建渲染图像的PIL图像对象
img = Image.fromarray((rgb_eval * 255).astype(np.uint8))
#将得到的渲染图像转为PNG格式
img.save('{0}/eval_{1}.png'.format(images_dir,'%03d' % indices[0]))
#计算每个图像的峰值信噪比 psnr,并存于列表psnrs中
psnr = rend_util.get_psnr(model_outputs['rgb_values'],
ground_truth['rgb'].cuda().reshape(-1, 3)).item()
psnrs.append(psnr)
#将列表psnrs转为numpy数组,并令数据类型为float64
psnrs = np.array(psnrs).astype(np.float64)
#输出渲染评估结果的平均psnr和标准差
print("RENDERING EVALUATION {2}: psnr mean = {0} ; psnr std = {1}".format("%.2f" % psnrs.mean(), "%.2f" % psnrs.std(), scan_id))
#将psnr列表与平均psnr值和标准差组合形成新的numpy数组
psnrs = np.concatenate([psnrs, psnrs.mean()[None], psnrs.std()[None]])
#将最终的psnrs列表转为csv文件格式
pd.DataFrame(psnrs).to_csv('{0}/psnr_{1}.csv'.format(evaldir, epoch))
#下面一段代码是评估模型脚本eval.py的主函数,主要是用于解析命令行参数,并调用evaluate()函数评估模型,有点类似于训练过程中的exp_runner.py脚本
#下面一行代码是pytorch的典型用法,也就是假如eval.py这个脚本是被直接运行而不是被当作模块被调用时,则作为本脚本的主函数执行以下代码,否则不执行以下代码
if __name__ == '__main__':
#利用ArgumentParser()方法创建参数解析器对象parser,用于解析命令行参数
parser = argparse.ArgumentParser()
#定义一系列命令行参数,如指定配置文件,实验名称等等
parser.add_argument('--conf', type=str, default='./confs/dtu.conf')
parser.add_argument('--expname', type=str, default='', help='The experiment name to be evaluated.')
parser.add_argument('--exps_folder', type=str, default='exps', help='The experiments folder name.')
parser.add_argument('--evals_folder', type=str, default='evals', help='The evaluation folder name.')
parser.add_argument('--gpu', type=str, default='auto', help='GPU to use [default: GPU auto]')
parser.add_argument('--timestamp', default='latest', type=str, help='The experiemnt timestamp to test.')
parser.add_argument('--checkpoint', default='latest',type=str,help='The trained model checkpoint to test')
parser.add_argument('--scan_id', type=int, default=-1, help='If set, taken to be the scan id.')
parser.add_argument('--resolution', default=512, type=int, help='Grid resolution for marching cube')
parser.add_argument('--eval_rendering', default=False, action="store_true", help='If set, evaluate rendering quality.')
#解析命令行参数,并将解析的结果保存于对象opt中
opt = parser.parse_args()
#根据命令行参数的--gpu选项设置可见的CUDA设备
if opt.gpu == "auto":
deviceIDs = GPUtil.getAvailable(order='memory', limit=1, maxLoad=0.5, maxMemory=0.5, includeNan=False, excludeID=[], excludeUUID=[])
gpu = deviceIDs[0]
else:
gpu = opt.gpu
if (not gpu == 'ignore'):
os.environ["CUDA_VISIBLE_DEVICES"] = '{0}'.format(gpu)
#调用evaluate()函数,将命令行参数转为关键字参数,用于评估模型
evaluate(conf=opt.conf,
expname=opt.expname,
exps_folder_name=opt.exps_folder,
evals_folder_name=opt.evals_folder,
timestamp=opt.timestamp,
checkpoint=opt.checkpoint,
scan_id=opt.scan_id,
resolution=opt.resolution,
eval_rendering=opt.eval_rendering,
)5、Volsdf算法部分的代码详解
5.1 density.py(Volsdf模型的密度函数,网格提取优化算法的代码)
density.py这个脚本的作用就是定义了一系列计算密度的函数,里面定义了volsdf模型中基于拉普拉斯概率分布的密度函数,还定义了Nerf和Nerf++中计算密度的方法(定义后面两种计算密度的方法应该是想和volsdf模型计算密度的方法进行对比)。
#引入了Pytorch当中的torch.nn模块,并命名为nn,该模块里面包含了大量用于训练神经网络的类和函数,以及操作Pytorch张量的函数和类
import torch.nn as nn
#引入Pytorch库,用于构建和训练神经网络模型
import torch
#在Pytorch当中想要自定义一个神经网络模块,或者是类,都要继承torch.nn模块当中的nn.Module类,因为该类中包含了大量用于自定义模型的函数和方法,可以直接调用,这样自定义神经网络模型就会方便很多
#定义了一个名为Density的类,是nn.Module的子类,用于计算空间采样点的密度
class Density(nn.Module):
#__init__是类Density的构造函数,用于初始化该类。其接受的参数有字典params_init={},该字典里面包含了初始化的所有参数以及初始值
def __init__(self, params_init={}):
#构造函数内部首先调用父类nn.Module的构造函数super().__init__(),因为只有父类被构造了,子类才能顺利构造
super().__init__()
#定义了一个for循环,用于遍历字典params_init中的每一个初始化参数
for p in params_init:
#利用函数nn.Parameter获取位于字典params_init中每一个初始化参数的初始值,并赋值于param
param = nn.Parameter(torch.tensor(params_init[p]))
#调用Pytorch当中的内置函数setattr为类Density的实例对象设置属性,也就是将字典params_init中的初始化参数的名称p和初始值param都传递给类Density的实例对象
setattr(self, p, param)
#定义了一个名为forward的函数,是一个前向传播函数,用于计算密度值。其参数有sdf符号距离函数的值和β拉普拉斯概率分布的方差值
def forward(self, sdf, beta=None):
#调用函数self.density_func,并向该函数传入sdf符号距离函数的值和β拉普拉斯概率分布的方差值,该函数就可以计算出空间采样点的密度值,并返回这个密度值。至于self.density_func在后面有定义。
return self.density_func(sdf, beta=beta)
#定义了一个名为LaplaceDensity的类,是Density的子类,用于定义基于拉普拉斯概率分布的密度函数公式,从而方便父类Density的调用
class LaplaceDensity(Density): # alpha * Laplace(loc=0, scale=beta).cdf(-sdf)
#__init__是类LaplaceDensity的构造函数,用于初始化该类。其接受的参数有字典params_init={},该字典里面包含了初始化的所有参数以及初始值,默认为空。除此之外还有一个可选参数beta_min,它是指拉普拉斯概率分布方差值的最小值,默认为0.0001.
def __init__(self, params_init={}, beta_min=0.0001):
#构造函数内部首先调用父类Density的构造函数super().__init__(),因为只有父类被构造了,子类才能顺利构造
super().__init__(params_init=params_init)
#为LaplaceDensity类的实例对象新创建了一个beta_min属性,其值为torch.tensor(beta_min).cuda(),意思是先用函数torch.tensor将传入的参数beta_min转为Pytorch张量,并移到cuda上,保证在cuda上计算张量,这样会快一点。
self.beta_min = torch.tensor(beta_min).cuda()
#定义了一个名为density_func函数,该函数给出了基于拉普拉斯概率分布的密度计算公式,其接受的参数有符号距离函数值sdf和拉普拉斯概率分布方差值β
def density_func(self, sdf, beta=None):
#如果传入的β值为空,则调用self.get_beta函数获取β值,函数self.get_beta在后面有定义
if beta is None:
beta = self.get_beta()
#定义α的值为β的导数
alpha = 1 / beta
#下面就是Volsdf论文当中计算的原公式,在该脚本后面有相关计算的详细介绍
return alpha * (0.5 + 0.5 * sdf.sign() * torch.expm1(-sdf.abs() / beta))
#定义了一个名为get_beta的函数,用于在beta的值为none的时候获取β值
def get_beta(self):
#如果berta的值为空,就会调用该函数get_beta,使得beta的值为beta值的绝对值加上传入参数的最小β的值(0.0001),目的是为了使得beta的值不为空。
beta = self.beta.abs() + self.beta_min
return beta
#定义了一个名为AbsDensity的类,是Density的子类,用于定义Nerf++的密度函数公式,从而方便父类Density的调用
class AbsDensity(Density): # like NeRF++
#该类无构造函数
#定义了一个名为density_func的函数,作用是定义NeRF++的密度计算方法,其接受的参数有符号距离函数值sdf和拉普拉斯概率分布方差值β
def density_func(self, sdf, beta=None):
#这个函数定义的密度计算公式相对来说是比较简单的,直接返回的是sdf值的绝对值
return torch.abs(sdf)
#定义了一个名为SimpleDensity的类,是Density的子类,用于定义NeRF的密度函数公式,适用于在噪声环境下的密度计算
class SimpleDensity(Density): # like NeRF
#__init__是类SimpleDensity的构造函数,用于初始化该类。其接受的参数有字典params_init={},该字典里面包含了初始化的所有参数以及初始值,默认为空。除此之外还有一个可选参数noise_std,它是指噪声标准差,默认为1.0。
def __init__(self, params_init={}, noise_std=1.0):
super().__init__(params_init=params_init)
#为SimpleDensity类的实例对象新创建了一个noise_std属性,其值为传入的参数noise_std的值。
self.noise_std = noise_std
#定义了一个名为density_func的函数,该函数给出了Nerf的密度计算公式,其接受的参数有符号距离函数值sdf和拉普拉斯概率分布方差值β
def density_func(self, sdf, beta=None):
#如果在训练模式下,并且类SimpleDensity实例的噪声标准差大于0,则创建一个类似于sdf值形状的噪声标准差,并将其加到原始的sdf值,中
if self.training and self.noise_std > 0.0:
noise = torch.randn(sdf.shape).cuda() * self.noise_std
sdf = sdf + noise
#最后调用Relu这个非线性激活函数对最终的sdf值进行处理,我认为目的是使得最后的值非负,并且减少噪声的影响
return torch.relu(sdf)对于基于拉普拉斯概率分布的密度函数公式,我有如下详解。

5.2 loss.py(Volsdf的损失函数计算脚本)
#引入Pytorch库,用于构建和训练神经网络模型
import torch
#引入了Pytorch当中的torch.nn模块,并命名为nn,该模块里面包含了大量用于训练神经网络的类和函数,以及操作Pytorch张量的函数和类
from torch import nn
##导入自定义的general模块,别名为utils,定义了一些通用工具函数
import utils.general as utils
#在Pytorch当中想要自定义一个神经网络模块,或者是类,都要继承torch.nn模块当中的nn.Module类,因为该类中包含了大量用于自定义模型的函数和方法,可以直接调用,这样自定义神经网络模型就会方便很多
#定义了一个名为VolSDFLoss的类,是nn.Module的子类,用于计算Volsdf模型的损失值
class VolSDFLoss(nn.Module):
#__init__是类VolSDFLoss的构造函数,其参数有rgb_loss,它是一个记录RGB损失值的类名字符串,还有参数eikonal_weight,它是volsdf模型损失函数中的λ值,用来定义用来控制SDF函数的导数的范数误差对整体误差所占的权重。
def __init__(self, rgb_loss, eikonal_weight):
#构造函数内部首先调用父类nn.Module的构造函数super().__init__(),因为只有父类被构造了,子类才能顺利构造
super().__init__()
#创建类VolSDFLoss实例对象的属性eikonal_weight,并将传入参数eikonal_weight的值赋予给它
self.eikonal_weight = eikonal_weight
#创建类VolSDFLoss实例对象的属性self.rgb_loss,其值为利用general.py定义的函数get_class来获取类名字符串rgb_loss对应的类对象,并传入参数reduction='mean'到该类对象,从而得到self.rgb_loss的值
self.rgb_loss = utils.get_class(rgb_loss)(reduction='mean')
#定义了一个名为get_rgb_loss的函数,用于获取RGB图像的损失值,传入的参数为模型输出的RGB图像值rgb_values和真实的RGB图像值rgb_gt
def get_rgb_loss(self,rgb_values, rgb_gt):
#重塑真实的RGB图像值的形状为(-1, 3)
rgb_gt = rgb_gt.reshape(-1, 3)
#利用刚刚在构造函数里面创建的属性self.rgb_loss,传入rgb_values, rgb_gt计算RGB图像的损失值
rgb_loss = self.rgb_loss(rgb_values, rgb_gt)
return rgb_loss
#定义了一个名为get_eikonal_loss的函数,用于计算重建表面光滑性的误差,传入的参数sdf函数的导数值grad_theta
def get_eikonal_loss(self, grad_theta):
#这个式子与Volsdf论文中计算重建表面是否光滑的误差一样,在该脚本后有详细的解析
eikonal_loss = ((grad_theta.norm(2, dim=1) - 1) ** 2).mean()
return eikonal_loss
#定义了一个名为forward的函数,用于计算最终的损失值,也就是将RGB图像的损失值与重建表面光滑性的误差相加,并用λ控制重建表面光滑性的误差在总损失值中占据的比重。传入的参数有模型的输出参数列表model_outputs和真实数据列表ground_truth
def forward(self, model_outputs, ground_truth):
#从真实数据列表ground_truth中获取真实的RGB图像值,并将其移到GPU上进行计算
rgb_gt = ground_truth['rgb'].cuda()
#直接调用刚刚定义的函数get_rgb_loss,并输入参数模型输出的RGB图像值model_outputs['rgb_values']和真实RGB图像值,来计算RGB图像的损失值
rgb_loss = self.get_rgb_loss(model_outputs['rgb_values'], rgb_gt)
#接下来计算重建表面光滑性的误差,首先判断模型输出列表model_outputs中是否有sdf函数的导数值grad_theta,如果有,直接调用刚刚定义的函数self.get_eikonal_loss计算重建表面光滑性的误差
if 'grad_theta' in model_outputs:
eikonal_loss = self.get_eikonal_loss(model_outputs['grad_theta'])
#如果模型输出列表model_outputs中没有sdf函数的导数值grad_theta,则利用torch.tenso函数将浮点数0.0转换为Pytorch张量,并将其类型定义为浮点型,然后将这个张量的值传给重建表面光滑性的误差eikonal_loss
else:
eikonal_loss = torch.tensor(0.0).cuda().float()
#下面一个式子就将RGB图像的损失值与重建表面光滑性的误差相加,并用λ控制重建表面光滑性的误差在总损失值中占据的比重
loss = rgb_loss +
self.eikonal_weight * eikonal_loss
#将刚刚计算得到的Volsdf模型的损失值、RGB图像的损失值,以及重建表面光滑性的误差都存储到列表output中,并最后返回这个列表
output = {
'loss': loss,
'rgb_loss': rgb_loss,
'eikonal_loss': eikonal_loss,
}
return output
5.3 ray_sampler.py(Volsdf模型采样方法脚本,采样方法优化算法的代码)
ray_sampler.py这个脚本定义和实现了与射线采样相关的类和方法,用于在光线追踪算法中生成射线上的采样点,并计算这些采样点的深度,用于体积渲染和场景重建中。
Volsdf模型对于Nerf的改进有两个,其关键算法也全部包含在这个两个改进中,刚刚已经在density.py中谈及了第一个改进,也就是网格提取方法的优化,定义了获取密度的新算法。那么ray_sampler.py脚本中就是谈及的第二个改进,对于采样方法的改进,根据对不透明度的精度要求,去设置拉普拉斯概率分布的方差值和采样点的个数,从而控制在射线上的采样。
5.3.1 RaySampler抽象基类
在ray_sampler.py中定义了三个类,简要的进行分析,首先是第一个类RaySampler,它是一个抽象基类。所谓的抽象基类是面向对象编程过程中的一个概念,是一个抽象的类,不能直接实例化,但是可以作为其他类继承的父类。抽象基类简称是ABC,它是由abc模型引入的,继承于父类abc.ABC,在该类中至少定义一种抽象方法,如@abc.abstractmethod,抽象方法没有实际的定义,只需要在子类中重写以提及具体的实现。如下述的抽象基类RaySampler里面定义的抽象方法就是get_z_vals,需要所有继承RaySampler的子类都给出抽象方法get_z_val的具体实现。
抽象基类RaySampler定义了射线采样的接口规范,指定在该规范里面必须实现方法get_z_vals,该方法的作用是获取射线的深度值,也就是射线与场景中物体交点的深度。
#RaySampler是继承于abc.ABCMeta的抽象基类
class RaySampler(metaclass=abc.ABCMeta):
#类RaySampler的初始化构造函数,接受参数near和far是射线采样的最近和最远距离
def __init__(self,near, far):
self.near = near
self.far = far
#@abc.abstractmethod是一个装饰器,定义了一个get_z_vals的抽象方法,没有给出该方法的具体实现,要求在子类中给出该方法的具体实现,也就是根据射线方向ray_dirs,相机位置cam_loc和模型model参数计算射线的深度
@abc.abstractmethod
def get_z_vals(self, ray_dirs, cam_loc, model):
pass5.3.2 均匀采样器UniformSampler
定义了一个名为UniformSampler的类,是RaySampler的子类,它实现了一个基于均匀采样的射线采样器,会根据给定的参数在射线上进行一定数量的采样,并计算这些采样点的深度。
#UniformSampler类是RaySampler的一个具体子类,它实现了 RaySampler 中定义的抽象方法get_z_vals,并提供了自己的构造函数__init__。
class UniformSampler(RaySampler):
#__init__方法用于初始化UniformSampler实例。它接受一系列参数,包括场景包围球的半径scene_bounding_sphere、采样的最近距离near、采样数量N_samples、是否考虑球体交点take_sphere_intersection,以及采样的最远距离far。根据这些参数。
def __init__(self, scene_bounding_sphere, near, N_samples, take_sphere_intersection=False, far=-1):
#调用了父类RaySampler的构造函数super().__init__进行初始化,其中采样的最远距离far等于场景包围球的半径的两倍
super().__init__(near, 2.0 * scene_bounding_sphere if far == -1 else far) # default far is 2*R
#设置了类UniformSampler的属性。
self.N_samples = N_samples
self.scene_bounding_sphere = scene_bounding_sphere
self.take_sphere_intersection = take_sphere_intersection
#get_z_vals方法是实现了父类抽象方法RaySampler.get_z_vals。它接受射线方向 ray_dirs、摄像机位置 cam_loc 和模型 model 作为参数。
def get_z_vals(self, ray_dirs, cam_loc, model):
#根据是否考虑球体交点,它计算并返回一组射线的深度值z_vals(射线与场景物体交点的深度)。
if not self.take_sphere_intersection:
near, far = self.near * torch.ones(ray_dirs.shape[0], 1).cuda(), self.far * torch.ones(ray_dirs.shape[0], 1).cuda()
else:
sphere_intersections = rend_util.get_sphere_intersections(cam_loc, ray_dirs, r=self.scene_bounding_sphere)
near = self.near * torch.ones(ray_dirs.shape[0], 1).cuda()
far = sphere_intersections[:,1:]
t_vals = torch.linspace(0., 1., steps=self.N_samples).cuda()
z_vals = near * (1. - t_vals) + far * (t_vals)
#如果在训练模式下,它会在深度值之间进行均匀采样,以提高采样的质量。
if model.training:
# get intervals between samples
mids = .5 * (z_vals[..., 1:] + z_vals[..., :-1])
upper = torch.cat([mids, z_vals[..., -1:]], -1)
lower = torch.cat([z_vals[..., :1], mids], -1)
# stratified samples in those intervals
t_rand = torch.rand(z_vals.shape).cuda()
z_vals = lower + (upper - lower) * t_rand
#返回获得的射线深度列表
return z_vals5.3.3 误差边界采样器ErrorBoundSampler
定义了一个名为ErrorBoundSampler的类,是RaySampler的子类。用于根据误差边界进行采样,会根据给定的误差边界和参数在射线上进行一定数量的采样,并且会根据误差边界不断的调整采样的密度,以提高采样点分布的质量。
误差边界采样器ErrorBoundSampler才是Volsdf模型的采样器,根据给定的不透明度误差去调整采样的密度,从而得到更加准确的采样点,在该类ErrorBoundSampler中定义了不透明度误差的推算公式,以及方差β的限制范围公式,以及volsdf模型的体积渲染公式,我将对该类中有关算法的代码进行分析,而不逐行分析。
#ErrorBoundSampler类是RaySampler的另一个具体子类,它也实现了 RaySampler 中定义的抽象方法get_z_vals。这个类的作用是根据误差边界进行采样,以更有效地计算射线与场景中物体的交点(射线深度)。
class ErrorBoundSampler(RaySampler):
#__init__方法用于初始化 ErrorBoundSampler 实例。它接受了一系列参数,包括场景包围球的半径scene_bounding_sphere、采样最近距离near、总采样数量N_samples、评估采样数量N_samples_eval、额外采样数量N_samples_extra、误差阈值eps、beta 迭代次数beta_iters、最大总迭代次数max_total_iters、是否考虑逆球背景inverse_sphere_bg、逆球采样数量 N_samples_inverse_sphere 和一个微小值 add_tiny。
def __init__(self, scene_bounding_sphere, near, N_samples, N_samples_eval, N_samples_extra,
eps, beta_iters, max_total_iters,
inverse_sphere_bg=False, N_samples_inverse_sphere=0, add_tiny=0.0):
#在初始化过程中,它调用了父类RaySampler的构造函数super().__init__进行初始化,并设置了类的属性
super().__init__(near, 2.0 * scene_bounding_sphere)
self.N_samples = N_samples
.......
#如果考虑逆球背景,则会创建一个额外的 UniformSampler 实例用于逆球采样
if inverse_sphere_bg:
self.inverse_sphere_sampler = UniformSampler(1.0, 0.0, N_samples_inverse_sphere, False, far=1.0)
#get_z_vals 方法实现了父类抽象方法 RaySampler.get_z_vals。它接受射线方向 ray_dirs、摄像机位置 cam_loc 和模型 model 作为参数。根据误差边界和评估采样数量,它计算并返回一组射线的深度值 z_vals。在计算过程中,它会使用 UniformSampler 实例进行采样,并根据误差边界进行动态调整。
def get_z_vals(self, ray_dirs, cam_loc, model):
beta0 = model.density.get_beta().detach()
# 先均匀采样器采集射线的深度值,并将结果存储在samples中。同时,samples_idx表示存储采样的索引,被设置为None,表示采样还未进行排序。
z_vals = self.uniform_sampler.get_z_vals(ray_dirs, cam_loc, model)
samples, samples_idx = z_vals, None 下面这一段代码用于从上界中获取拉普拉斯概率分布方差β的最大值,也就是从采样优化算法中推论出来的下述公式:
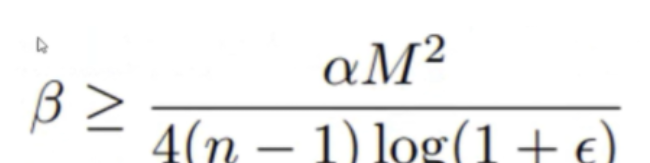
dists = z_vals[:, 1:] - z_vals[:, :-1]
bound = (1.0 / (4.0 * torch.log(torch.tensor(self.eps + 1.0)))) * (dists ** 2.).sum(-1)
beta = torch.sqrt(bound)
total_iters, not_converge = 0, True # 算法一
while not_converge and total_iters < self.max_total_iters:
......
#仅计算新采样点的SDF值
with torch.no_grad():
...... ’
’

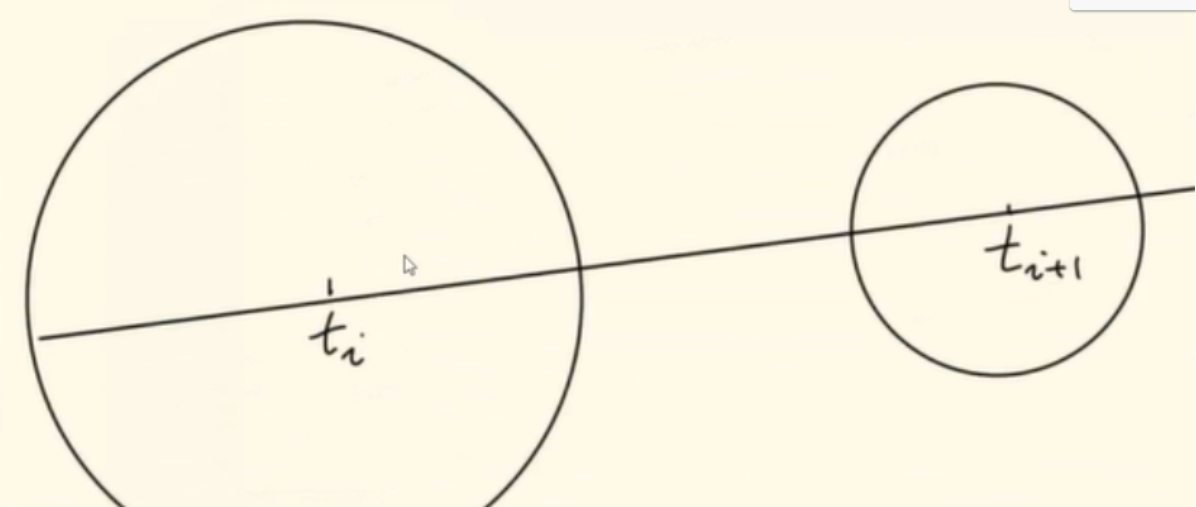
#将SDF的值d重新排列成与存储射线深度z_vals相同的形状,以便进行逐元素操作。
d = sdf.reshape(z_vals.shape)
#dists是计算相邻采样点之间的距离
dists = z_vals[:, 1:] - z_vals[:, :-1]
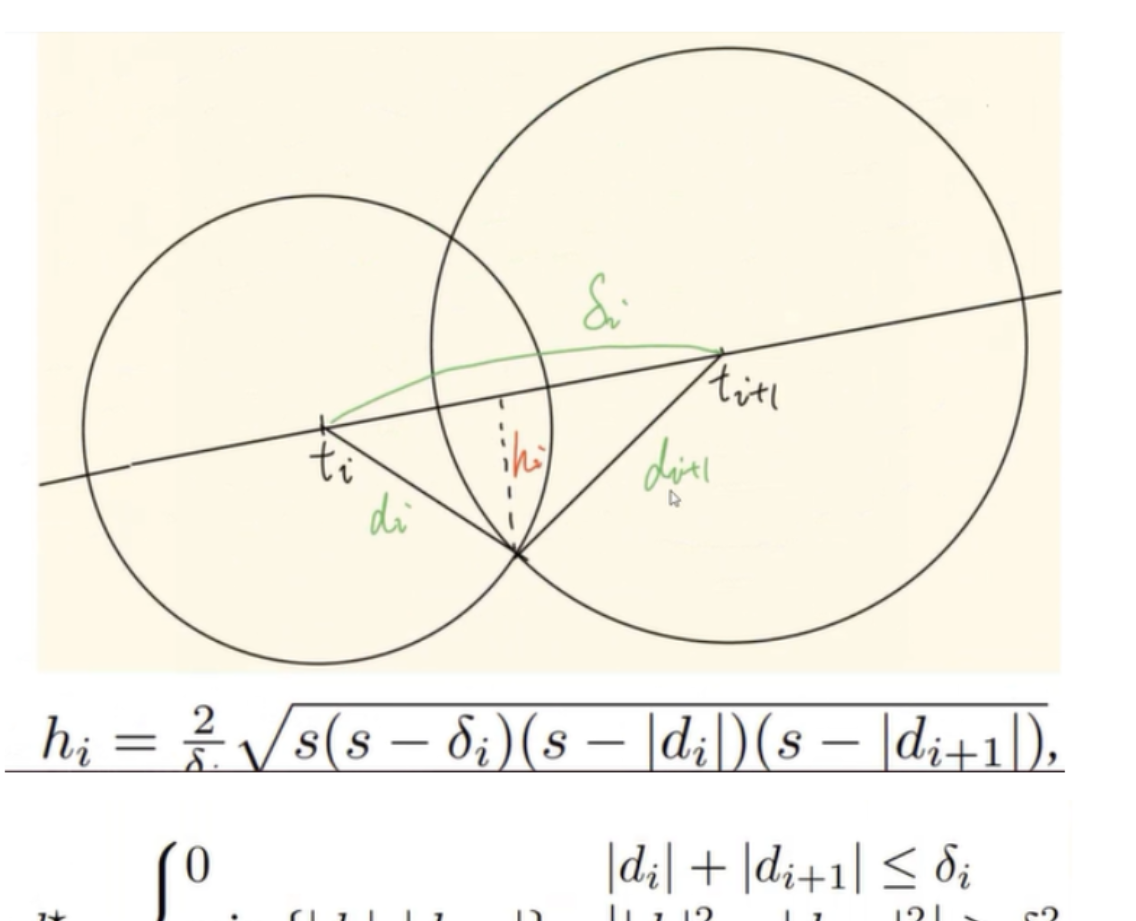
#定义三个变量a、b和c,分别表示相邻采样点之间的距离dists(也就是上图中的区间的长度&)、d(sdf值)的绝对值(也就是上图的di),以及d右侧相邻采样点的绝对值(也就是上图的di+1)。
a, b, c = dists, d[:, :-1].abs(), d[:, 1:].abs()
#a平方+b平方≤c平方
first_cond = a.pow(2) + b.pow(2) <= c.pow(2)
#a平方+c平方≤b平方
second_cond = a.pow(2) + c.pow(2) <= b.pow(2)
#下述代码是描述的上图中d*的第一种情况,这时d*=0
d_star = torch.zeros(z_vals.shape[0], z_vals.shape[1] - 1).cuda()
#下述代码是描述的上图中d*的第二种情况,这时d*就等于两个区间端点到曲面最近距离比较小的那个
d_star[first_cond] = b[first_cond]
d_star[second_cond] = c[second_cond]
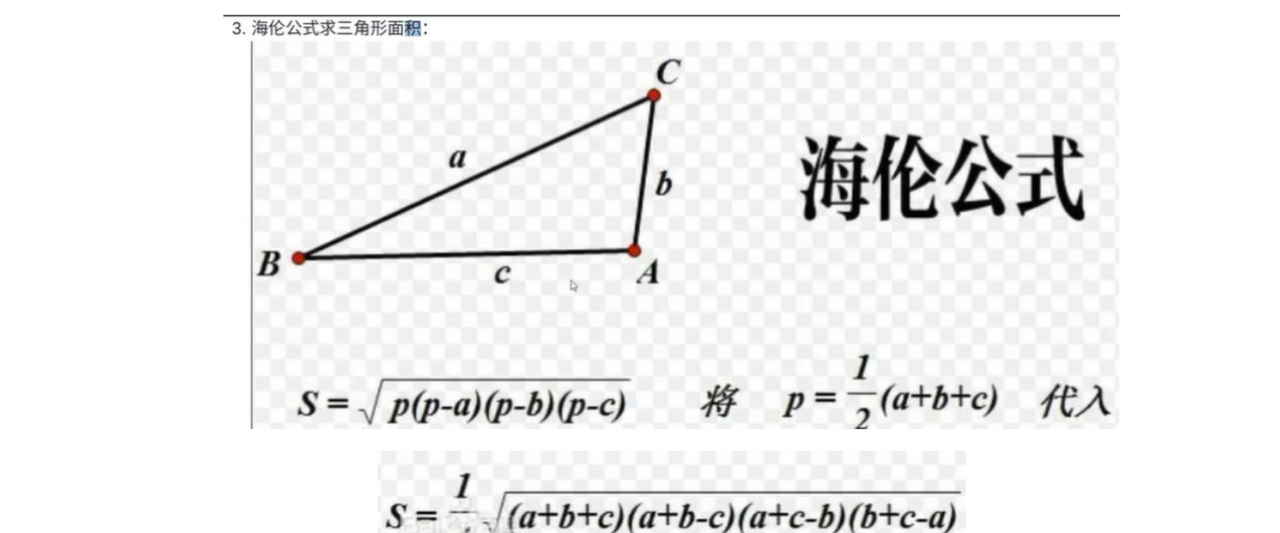
#下述代码是描述的上图中d*的第三种情况,这时d*用计算三角形面积的海伦公式计算
s = (a + b + c) / 2.0
area_before_sqrt = s * (s - a) * (s - b) * (s - c)
mask = ~first_cond & ~second_cond & (b + c - a > 0)
d_star[mask] = (2.0 * torch.sqrt(area_before_sqrt[mask])) / (a[mask])
d_star = (d[:, 1:].sign() * d[:, :-1].sign() == 1) * d_star # Fixing the sign #这段代码执行了一个线性搜索来更新参数β,以确保误差边界符合指定的阈值 ϵ。也就是更新刚刚提及的拉普拉斯概率分布方差β
#函数get_error_bound在该类定义的最后一个函数,在该脚本的最后
curr_error = self.get_error_bound(beta0, model, sdf, z_vals, dists, d_star)
......
#以下一段代码用于采样更多的采样点
density = model.density(sdf.reshape(z_vals.shape), beta=beta.unsqueeze(-1))
......
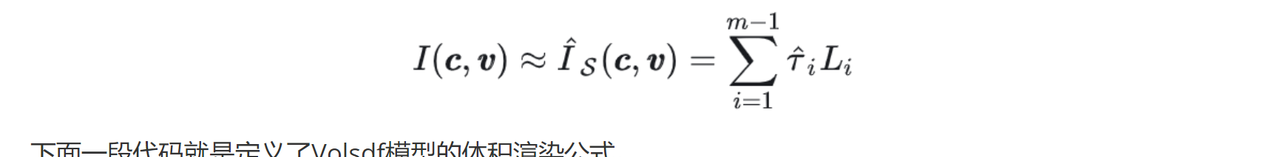
# 以下一段代码根据当前误差边界(error bound)的大小,决定是否继续采样更多的点。
total_iters += 1
not_converge = beta.max() > beta0
if not_converge and total_iters < self.max_total_iters:
''' Sample more points proportional to the current error bound'''
N = self.N_samples_eval
bins = z_vals
error_per_section = torch.exp(-d_star / beta.unsqueeze(-1)) * (dists[:,:-1] ** 2.) / (4 * beta.unsqueeze(-1) ** 2)
error_integral = torch.cumsum(error_per_section, dim=-1)
bound_opacity = (torch.clamp(torch.exp(error_integral),max=1.e6) - 1.0) * transmittance[:,:-1]
pdf = bound_opacity + self.add_tiny
pdf = pdf / torch.sum(pdf, -1, keepdim=True)
cdf = torch.cumsum(pdf, -1)
cdf = torch.cat([torch.zeros_like(cdf[..., :1]), cdf], -1)
else:
''' Sample the final sample set to be used in the volume rendering integral '''
N = self.N_samples
bins = z_vals
pdf = weights[..., :-1]
pdf = pdf + 1e-5 # prevent nans
pdf = pdf / torch.sum(pdf, -1, keepdim=True)
cdf = torch.cumsum(pdf, -1)
cdf = torch.cat([torch.zeros_like(cdf[..., :1]), cdf], -1) # (batch, len(bins))
# Invert CDF
if (not_converge and total_iters < self.max_total_iters) or (not model.training):
u = torch.linspace(0., 1., steps=N).cuda().unsqueeze(0).repeat(cdf.shape[0], 1)
else:
u = torch.rand(list(cdf.shape[:-1]) + [N]).cuda()
u = u.contiguous()
inds = torch.searchsorted(cdf, u, right=True)
below = torch.max(torch.zeros_like(inds - 1), inds - 1)
above = torch.min((cdf.shape[-1] - 1) * torch.ones_like(inds), inds)
inds_g = torch.stack([below, above], -1) # (batch, N_samples, 2)
matched_shape = [inds_g.shape[0], inds_g.shape[1], cdf.shape[-1]]
cdf_g = torch.gather(cdf.unsqueeze(1).expand(matched_shape), 2, inds_g)
bins_g = torch.gather(bins.unsqueeze(1).expand(matched_shape), 2, inds_g)
denom = (cdf_g[..., 1] - cdf_g[..., 0])
denom = torch.where(denom < 1e-5, torch.ones_like(denom), denom)
t = (u - cdf_g[..., 0]) / denom
samples = bins_g[..., 0] + t * (bins_g[..., 1] - bins_g[..., 0]) # 以下一段代码是Volsdf体渲染的后处理部分,用于结果未收敛,继续增加采样点
if not_converge and total_iters < self.max_total_iters:
z_vals, samples_idx = torch.sort(torch.cat([z_vals, samples], -1), -1)
......
# 以下一段代码用于在体积渲染中添加一些表面附近的额外采样点,以及在需要时添加反向球背景的采样点。
idx = torch.randint(z_vals.shape[-1], (z_vals.shape[0],)).cuda()
......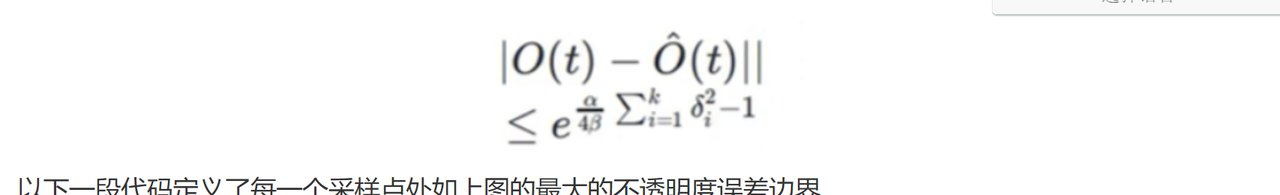
def get_error_bound(self, beta, model, sdf, z_vals, dists, d_star):
density = model.density(sdf.reshape(z_vals.shape), beta=beta)
shifted_free_energy = torch.cat([torch.zeros(dists.shape[0], 1).cuda(), dists * density[:, :-1]], dim=-1)
integral_estimation = torch.cumsum(shifted_free_energy, dim=-1)
error_per_section = torch.exp(-d_star / beta) * (dists ** 2.) / (4 * beta ** 2)
error_integral = torch.cumsum(error_per_section, dim=-1)
bound_opacity = (torch.clamp(torch.exp(error_integral), max=1.e6) - 1.0) * torch.exp(-integral_estimation[:, :-1])
return bound_opacity.max(-1)[0]




















暂无评论内容