
一、Dpdk的架构
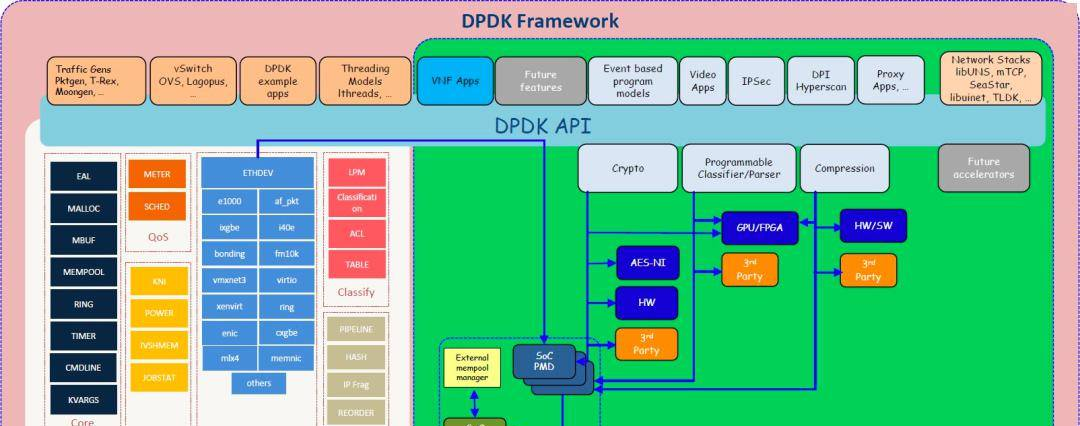
DPDK使用轮询,降低了开销。这是由轮询模式驱动程序 ( PMD ) 执行的。另一个重要的优化是零拷贝;
代码结构:

Dpdk对于数据包处理的模型:
# Run-to-Completion
CPU内核处理数据包的接收、处理和传输。可以使用多个内核,每个内核与专用端口关联。通过接收端扩展 ( RSS ),到达单端口的流量可分配到多CORE。
# Pipeline
每个内核专用于特定的工作负载。例如,一个CORE可能处理数据包的接收/传输,而其他内核则负责应用程序处理。数据包通过memory rings在内核之间传递。
二、Dpdk内存相关的内容
1、基础
|
Dpdk管理内存的方式 |
实现了无锁队列ring,内存池mempool,内存堆heap |
|
调rte_malloc |
在大页内存上申请空间,一般用于申请小的内存空间 |
|
内存池(提高性能) |
在大页内存上申请空间,用于大的缓冲区,所以一次申请 |
问题1:为什么内存池的方式可以提高性能,调rte_malloc的性能会低一些?
答:在内存池中,预先分配内存块,使用时,直接从内存池中获取一个空闲的内存块,避免频繁系统调用,减少内存分配和释放的开销。
rte_malloc进行内存分配,每次分配都调用系统函数malloc,导致额外的开销。
问题2:这里都是大页内存上申请的空间,那大页的内存来自哪里?怎么从硬件到大页的内存联系起来??
答:使用大页进行内存管理(传统是4KB的方式进行内存管理),大页内存大小通常为2MB或1GB减少页表个数,降低TLB失效次数(Translation Lookaside Buffer),从而提升应用访问内存的效率;
大页内存的来源可以是物理内存或者交换空间。当系统需要更多大页内存,操作系统会从物理内存中分配一部分空间作为大页内存。如果物理内存不足,操作系统还可以将部分内存页交换到磁盘上的交换空间,以释放物理内存供大页使用。
硬件与大页内存的联系在于,硬件通过内存管理单元(MMU)来处理虚拟地址到物理地址的转换。当程序请求一个大页内存时,操作系统会分配一个物理地址给这个大页,并将其映射到虚拟地址空间。这样,程序就可以通过虚拟地址访问这个大页内存。

Dpdk的内存模式

Dpdk的内存管理实现
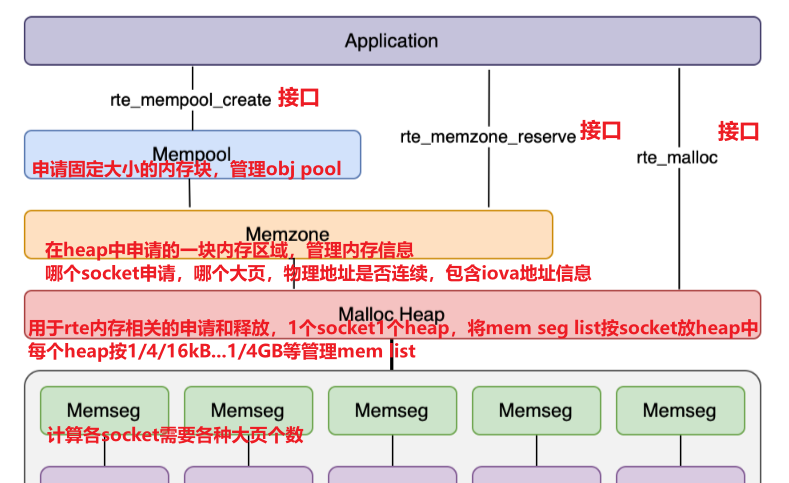
大页进行内存管理的原理:
DPDK的内存初始化,可以简单类比linux内存的初始化(buddy系统和slab系统),包括如下几个过程:
大页信息初始化
dpdk buddy初始化(memzone,memseg list初始化&memseg 映射)
dpdk slab初始化(heap初始化)
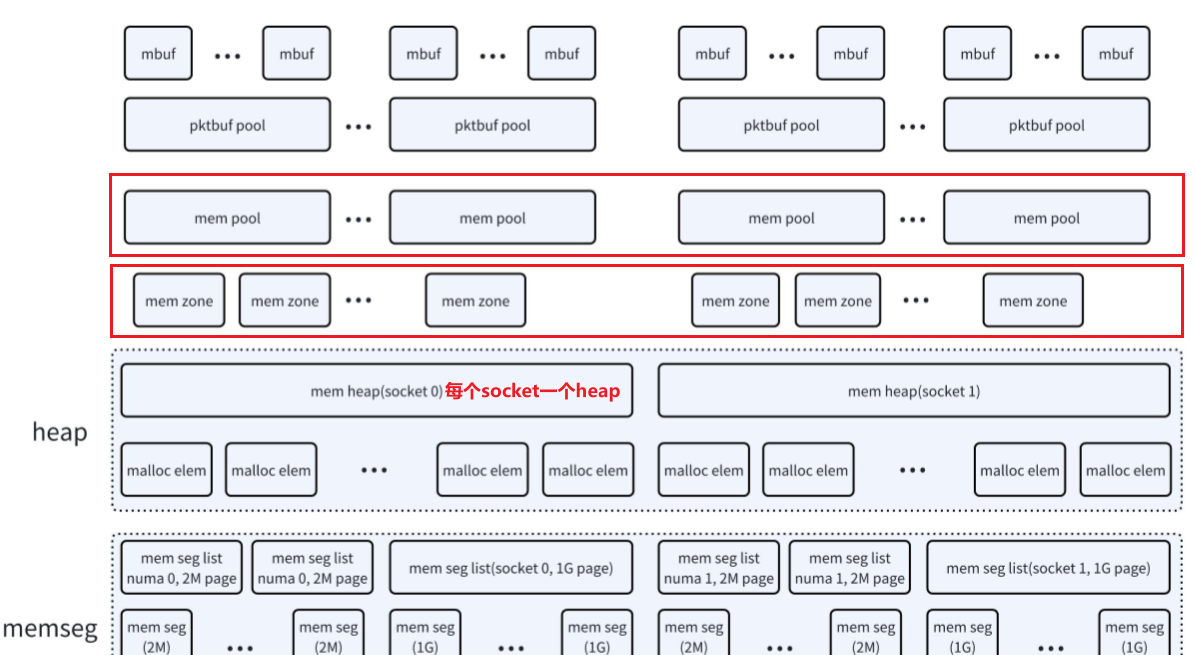
先上一张图, DPDK完成初始化后内存的顶层示意图,大页映射到挂载点下的文件,内部通过多个memseg list来管理大页:
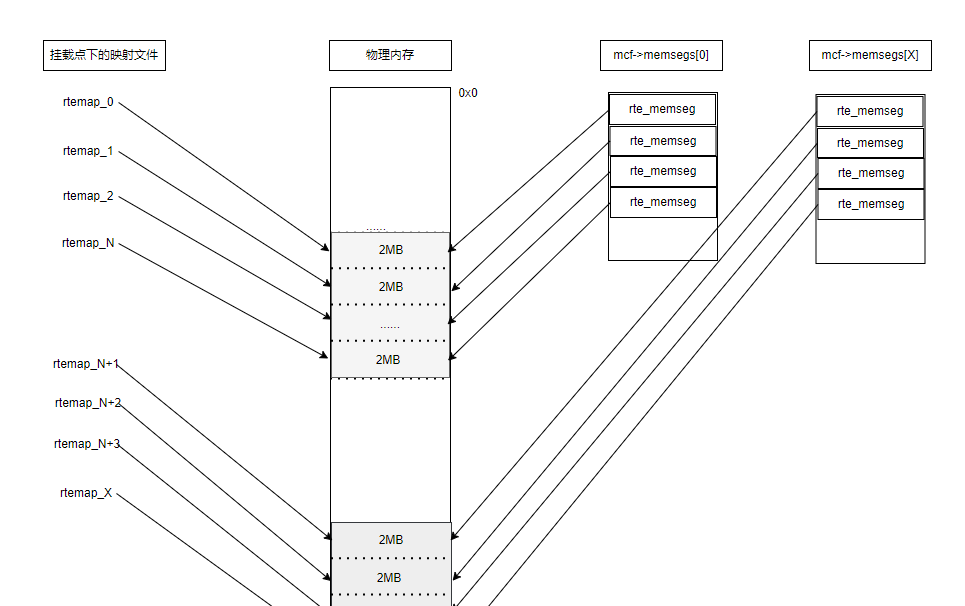
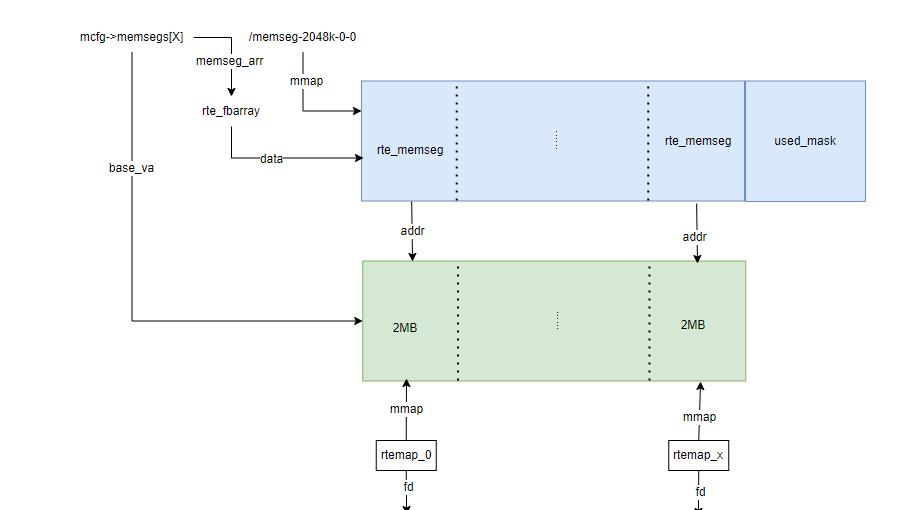
dpdk在memseg list的基础上,实现了malloc_heap来管理内存,最后提供rte_malloc,mempool等给dpdk应用使用,每个numa节点一个堆,通过双向链表链接各元素,每个堆有一个空闲链表数组,初始时由于每个memseg list都空闲,每个堆元素指向第一个memseg,并包含这个memseg list所有的memseg,连续空间很大,所以都挂接在最后的空闲链表上,每个堆元素有一个头。
2、实现原理
dpdk进一步提供了rte_malloc,rte_mempool,rte_ring, rte_mbuf。spdk主要使用了rte_malloc,rte_mempool,rte_ring,它们的关系如下:
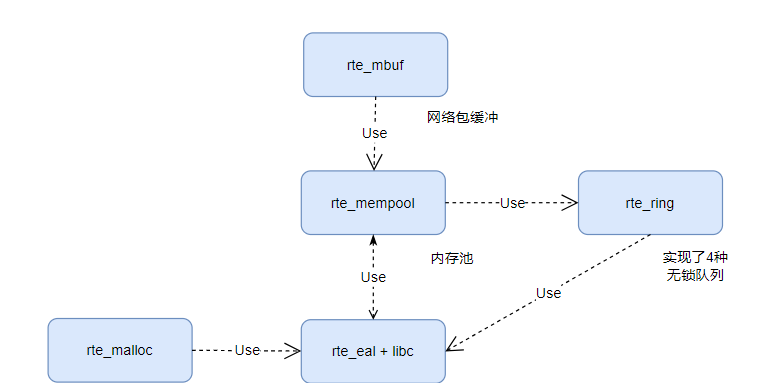
malloc的实现相对简单 – 直接操作heap分配内存
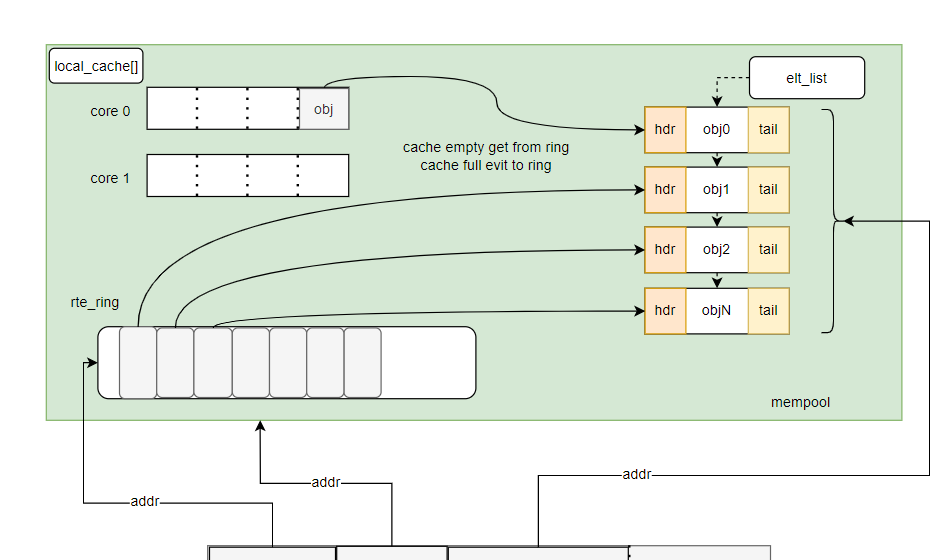
介绍下mempool,减少内存碎片,将相同类型对象用内存池来管理,mempool用环形缓冲区ring来保存内存对象。多核CPU访问同一个内存池或者同一个环形缓存区时,因为每次读写时都要进行Compare-and-Set操作来保证期间数据未被其他核心修改,所以存取效率较低为。为了减少多核访问冲突,mempool中实现了local_cache,在每个核上有一个(pre-core)。至于ring,根据生产者和消费者模型,dpdk实现了4种,每种都定义了自己的操作集,mempool,local cache, ring的关系示意图如下:
3、内存池相关的接口
|
内存API |
接口含义 |
|
rte_mempool_create |
创建内存池,用大页中一块连续缓冲区 |
|
rte_mempool_get(消费者) |
从内存池中获取一个对象元素mbuf |
|
rte_mempool_put(生产者) |
不用内存需要回收,以免造成内存泄漏 |
|
rte_mempool_in_use_count |
查看池中已经使用的元素个数 |
|
rte_mempool_avail_count |
查看池中可用的元素个数 |
|
rte_mempool_dump |
查看内存池的状态 |
|
rte_mempool_full |
查看内存池是否满 |
|
rte_mempool_free |
释放内存池 |
4、内存池相关的内容:
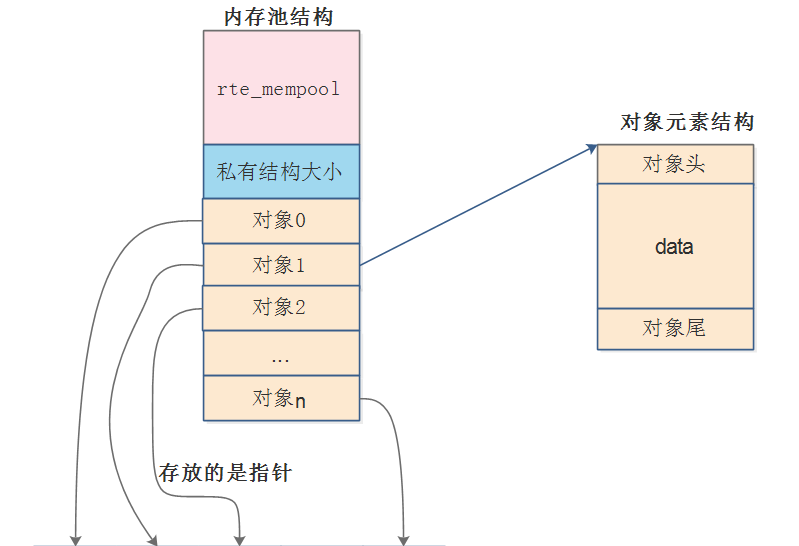
这里的ring的作用是:用来管理内存池中的每个对象元素,记录内存池中哪些对象使用,哪些对象没有被使用;

5、内存池如何使用
(1)大页在哪里设置的,如何查看
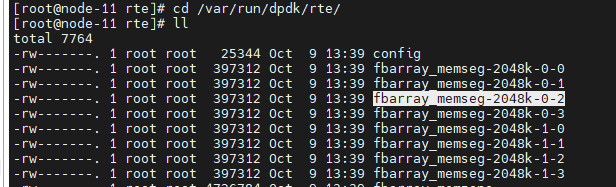
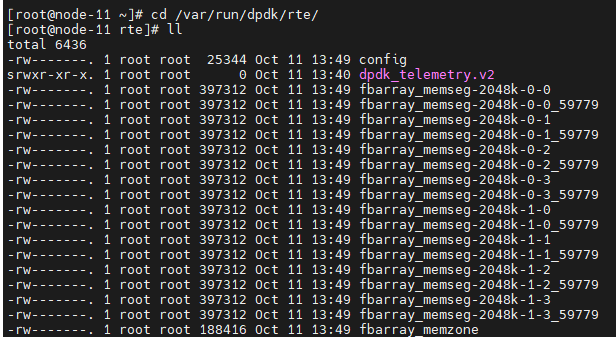
(2)/var/run/dpdk/rte目录下的文件如何理解,以前这里存放的是spdk的socket文件
执行dpdk的初始化函数rte_eal_init后,对应的目录下会产生下面的文件
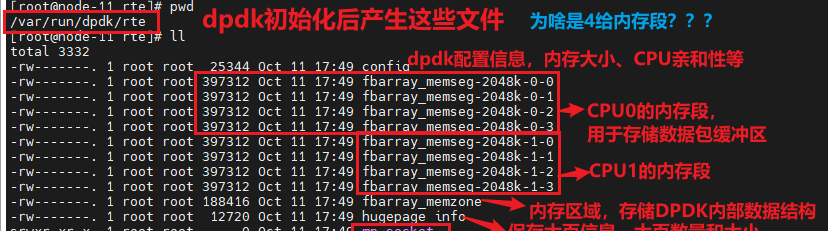

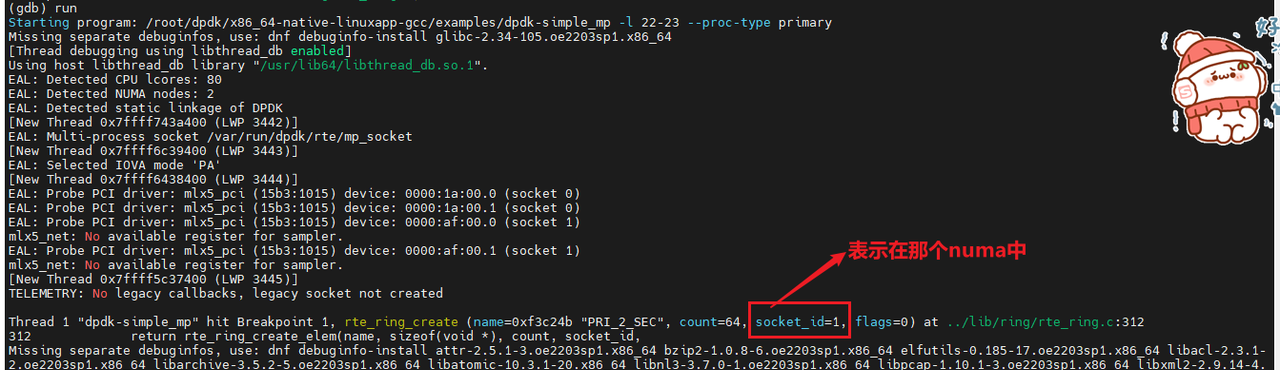
断点打到rte_ring_create的时候,也就表示查看CORE处于哪个CPU的流程完成后,就会产生多一个文件dpdk_telemetry.v2,这个文件的作用是什么???
答:这也是一个socket文件,用于DPDK应用程序与用户空间工具间通信,作用是收集性能指标处理速率、延迟、丢包率、查询DPDK当前的状态、内存池的使用情况和端口状态,还有当某些事件发生端口状态变更,错误发生,可以通过这个套接字发送通知给用户空间。
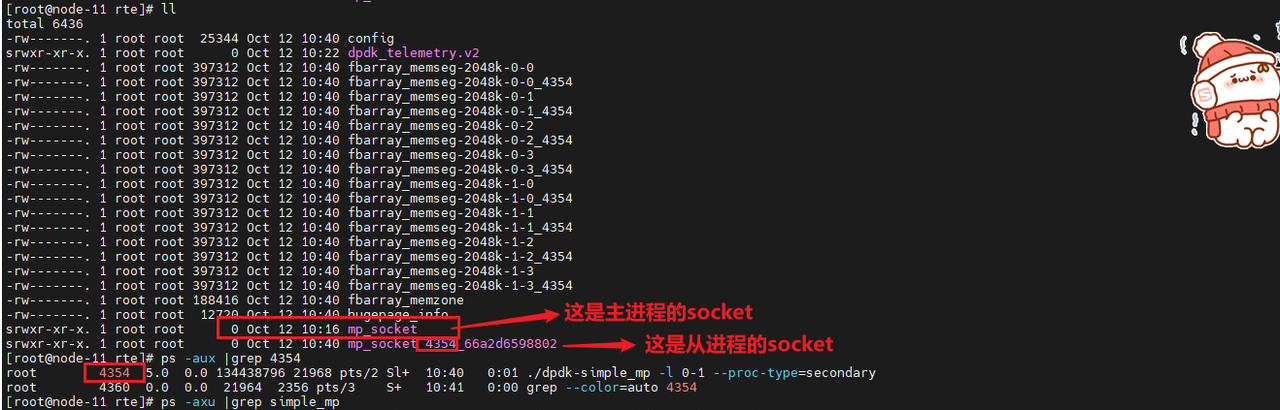
(1)查看一下初始化dpdk的时候是否使用了大页,使用了多少大页内存,作用是什么?
答:初始化dpdk的时候并没有使用大页内存,只是初始化dpdk的一些管理流,没有实际使用;
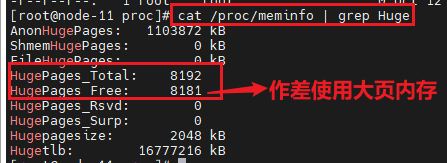
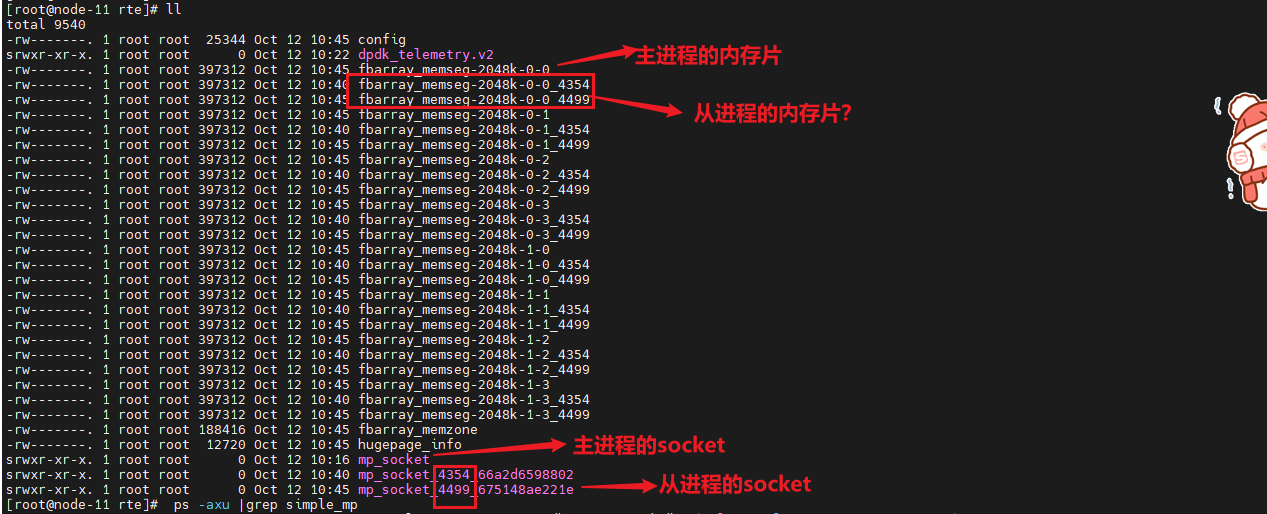
执行完rte_socket_id函数后,大页就被占用了11个,并且其中的线程也被释放了,如下图:
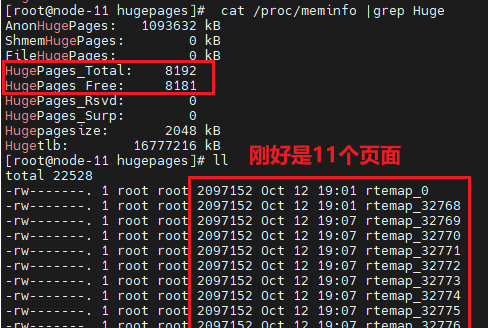
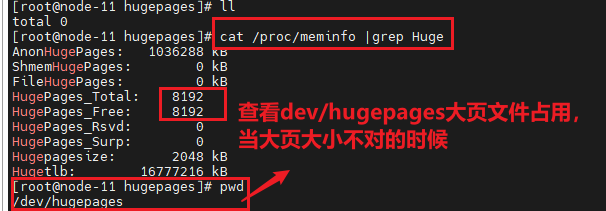
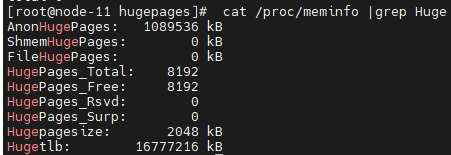
初始化dpdk的时候没有使用大页内存,调试运行rte_eal_init完后,对应内存大小如下
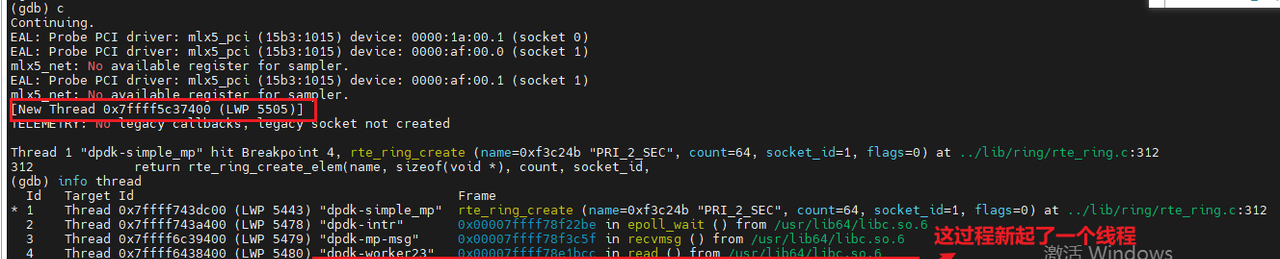
(2)查看一下创建内存池的流程
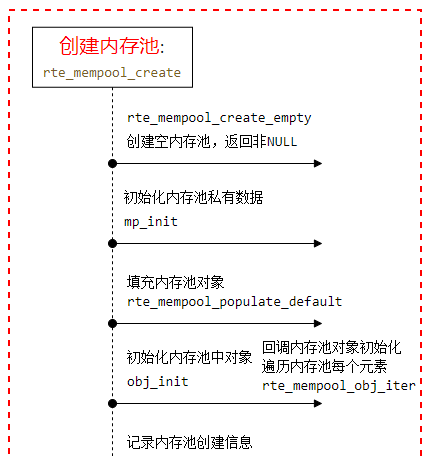

下面是dpdk的一些疑问待处理:
内存还是后面新创建的大页内存,在哪里配置,在创建内存池的流程中是否有体现?
dpdk启动时,大页内存的预留方式是怎样的呢?
如何保证远端的内存不被重复使用?
内存的管理是怎么计算的,从obj—>最终的大页?
内存管理的多dpdk应用程序大页冲突的问题,如何防止?
每个内存的层级,各对象的最大值默认为多少(dpdk初始化流程rte_eal_init)?
内存池是怎么通知我们,是不是像spdk写监听?
三、Dpdk的主从模式(共享内存的应用)
1、概念
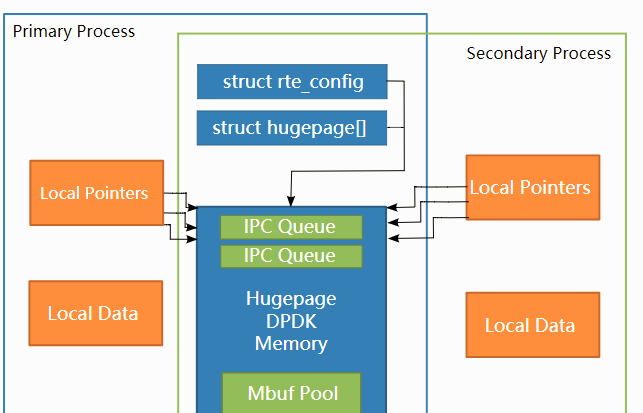
DPDK多进程的关键是内存资源在进程间正确共享,那么进程间通信(IPC)的问题就变得简单得多。
在primary processes启动时,DPDK向内存映射文件中记录其使用的内存配置的详细信息(包括正使用的hugepages,映射的虚拟地址,存在的内存通道数等。)
当secondary processes启动时,这些文件被读取,并且EAL在secondary processes中重新创建相同的内存配置,所有内存在进程间共享,所有指向该内存指针都有效,并且指向相同的对象。
2、实现原理
3、操作
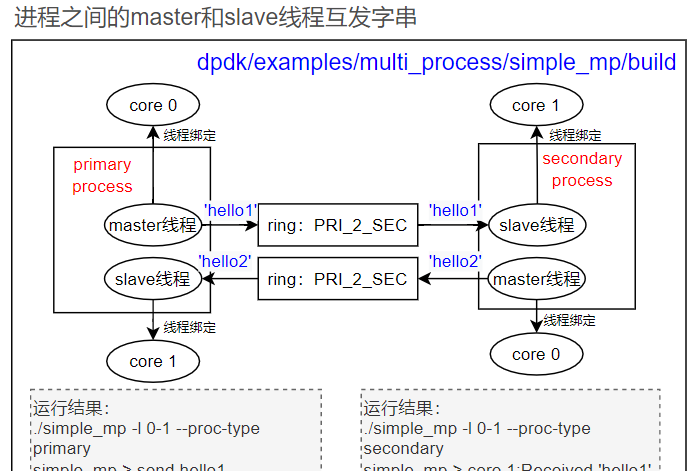
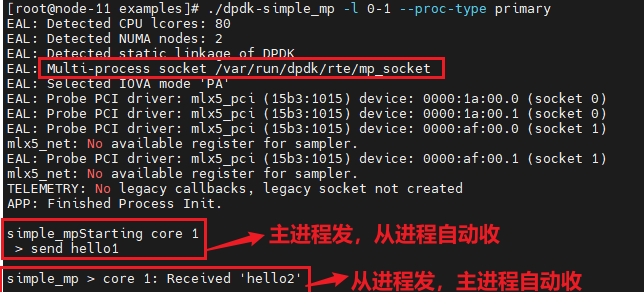
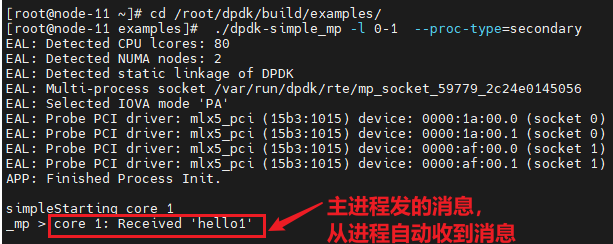
上图中的主进程的master线程发,slave线程收,从进程的处理也是一样,所以每个进程必须至少2个线程。注意只能起一个主进程,可以起多个从进程,从进程的core个数至少为2.
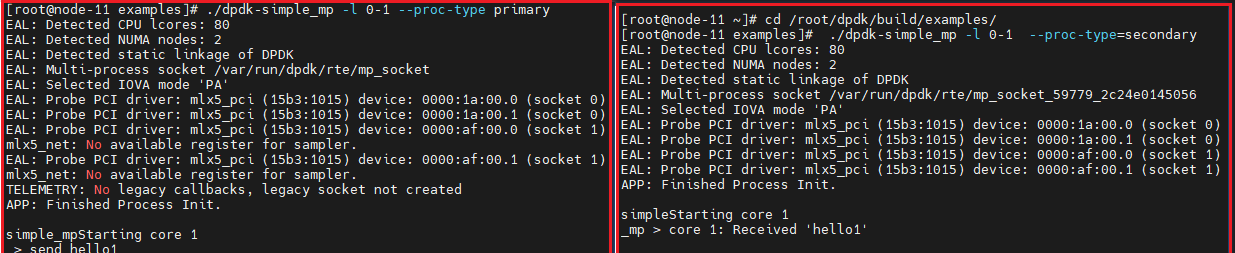
测试的结果如下:
应用场景
|
Dpdk的多进程应用场景 |
|
|
基本多进程 Basic Multi-process |
DPDK进程间通过ring)、内存池和队列来进行信息交换。 适用于不同进程间高效传递数据 |
|
对称多进程示例 Symmetric Multi-process |
副进程除了不参与资源初始化,其数据包处理方式与主进程相同。每个进程执行相同的工作负载。 |
|
客户端-服务器多进程 Client-Server Multi-process |
主进程负责初始化资源+接收所有数据包,并将它们轮询分发给副进程处理。这种模式适合于需要集中管理和分配任务的应用场景 |
|
主从多进程 Master-slave Multi-process |
此模式强调进程间的依赖关系; 适合那些需要严格协调和控制的复杂系统 |




















暂无评论内容