
智能体古诗词合集:一键自动生成古诗词视频AI智能体
一键自动生成古诗词视频AI智能体
一、整体介绍
1、最终实现功能
用户只需要在智能体交互页面输入古诗词名称,智能体自动完成相关视频制作。
2、成片展示:
待完成后补充
3、所涉及功能模块及用途:
所有相关的功能模块名字可自己命名,方便自己识别就行
(一)智能体名称:一键自动生成古诗词视频(提供用户交互入口)
(二)工作流1:gushici_shujusouji(实现对古诗词文案处理及生成视频素材)
(三)工作流2:huoqu_zhipu_shipin_zhuangtai,本工作流用于查询视频生成情况,不实际在智能体中调用。(大部分插件特别是生成视频这类插件属于异步处理,完成执行工作需要一定的等待时间如海螺AI生成一个视频可能需要等1-2个小时,可通过本工作流随时查询视频生成结果,目前比较好用的是智谱图生视频插件,新用户送500token,而且出视频快,基本10分钟以内就能出)
(四)数据库:gushici(用于存储处理后的古诗词相关数据)提供给工作流1**:gushici_shujusouji调用。**
(五)工作流3**:shici_shipin_shengcheng_zhipu(我这里调用的是智谱的图生视频查询**插件,实现将存入数据库的表内容进行提取并通过剪映小助手等插件进行视频合成并保存到剪映草稿)
4、本工作流需要用到的插件及软件:
(一)软件剪映、剪映小助手客户端
剪映破解版下载地址:https://pan.baidu.com/s/1k9KZCaQUcAbGM0VmOoB5lg?pwd=zgh2提取码:zgh2
剪映小助手下载地址:https://www.51aigc.cc/#/home?user_id=244358
剪映小助手使用手册及常见问题:常见问题
(二)智谱插件:
官网注册地址:
https://www.bigmodel.cn/invite?icode=iowsYtQtQ4vfy7JeS2eFLkjPr3uHog9F4g5tjuOUqno%3D
二、工作流整体设计
(一)工作流1:gushici_shujusouji整体预览
根据自己使用的插件进行对照设置。只需要更换循环体内的图生视频插件即可。这里优先推荐”智谱“
1.图生视频海螺插件如下图

2.图生视频智谱插件如下图

(二)工作流2:huoqu_zhipu_shipin_zhuangtai整体预览
以下用智谱演示,如果用海螺自己换查询插件就行。

(三)工作流3:shici_shipin_shengcheng_zhipu 整体预览

三、实操步骤:
1、创建智能体,并调用工作流。
(一)新建智能体
01.扣子主页点“+”,选择创建智能体。

02.输入名称,介绍(可以按自己想输的写),选择图标。也可以自己上传。完成后点确认。
编辑智能体


(二)输入提示词及添加工作流
01.在人设与回复逻辑中输入:“根据输入的诗名称给我生成视频,需要调用XXX工作流”,点右上角智能优化提示词。

02.优化后点击替换即可。
编排 豆包·1.5·Prc


03.待整体完整后补充
2、设计工作流
(一)思路拆解:

(1)对作品进行分析
首先我们对成品中视频内容进行分析视频有哪些要素,在本作品(如上图截图)中主要元素包含:诗词内容的提取、名称、作者、朝代、主体内容、抖音注释、及音频、背景音、视频、动画、效果等。
(2)实现思路
01.通过大模型查询对应古诗词的相关内容如诗的名称、作者、朝代、主体内容,并对内容按数组格式进行处理。02.使用业务逻辑中的“循环”功能将处理过的每一句诗内容生成图片提示词及生成对应的图片。
03.一首诗有多句内容,在工作流中我们需要使用“批处理”同时将生成的图片通过视频生成插件生成对应的视频。
04.另由于视频插件大部分是异步处理,需要一定的等待时间,因此我们把内容提取后(名称、作者、朝代、主体内容、抖音注释、视频ID)存到云端数据库。
05.通过数据库查询得到数据再通过剪辑插件"剪映小助手"进行合成完整的视频。
PS:过程中需要使用大模型、提示词的提取生成图片、图片视频、剪映小助手、音频的合成、循环、批处理、数据库
(二)节点设计工作流1:gushici_shujusouji:
(1)“开始”节点:
01.输入主题的变量名称,变量类型为默认,用于接收用户输入的诗名
02.变量名称的命名根据自己的习惯来便于自己识别就行,只支持英文字母。

(2)”1号员工:诗词内容提取"节点
通过大模型提取对应诗名的内容:作者、朝代、诗句、拼音。

输入变量值:
01.大模型可自己选择合适的,如豆包、Kimi、deepseek等。
02.输入变量选择开始节点的"shiming"

提示词:
01.通过系统提示词让大模型帮我们提取相关的内容,并设定对应内容的变量名。与输出变量名要一致。
02.系统提示词中已经引用输入变量"shiming”,所以用户提示词中可写可不写。

系统提示词
根据输入的诗名称{{shiming}}给我提取诗的相关信息。
诗的作者给变量zuozhe
诗的朝代给变量chaodai
诗的主体内容给变量neirong
诗的拼音注释给变量pinyin
用户提示词
用户提示词,可以使用{{变量名}}、{{变量名.子变量名}}、{{变量名[数组索引]}}的方式引用输入参数中的变7158 ThunderSoft 量
输出变量值:
01.把需要的内容提取后要作为输出变量提供给下个节点使用。对应系统提示词里的四个内容设定。
02.变更类型都是文字。使用默认的字符串"string"类型即可。
系统提示词:
根据输入的诗名称{{shiming}}给我提取诗的相关信息。
诗的作者给变量zuozhe
诗的朝代给变量 chaodai
诗的主体内容给变量neirong
诗的拼音注释给变量 pinyin

(3)”2号员工:数据整理/数据组合"节点
通过大模型将提取的内容按数组格式进行数据处理,并将整理后的数据输出给下一节点引用。

输入变量值:
01.大模型可自行选择。
02.设置四个输入字段:作者、朝代、内容、拼音,分别引用”1号员工:诗词内容提取“节点的输出对应的字段。

提示词:
系统提示词:
1.将{{zuozhe}}和{{chaodai}}合并起来,中间用空格隔开。然后输入到数组的第一个。
2.再将{{neirong}}通过标点符号分割,输出到新的数组里

输入变量值:
01.可自行给输出变量命名,如这里输入”shuzu“。
02.变量类型一定要选择”array“,否则会出错。

(4)”3号经理:提示词/图片的生成“节点:业务逻辑”循环“
”2号员工“整理后的数据提供给”3号经理“,诗中有多句诗句,需要每句都生成对应的图片,需要使用”循环“功能。
01.添加循环节点,命名”3号经理:提示词/图片的生成“,也可自己改。

02.在循环体中增加两个节点,实现通过系统提示词去生成图片。

03.循环体内节点分别为”图像处理-提示词优化“命名为:”3号员工_1:提示词生成“,本节点功能是将”3号经理“得到的提示词进行提示词优化,并将优化后的结果以输出的变量传给”3号员工_2:图像生成“进行相关图片生成。
添加节点选择“提示词优化”,命名为:”3号员工_1:提示词生成“

04.添加节点选择”图像处理-图像生成“,命名为:“3号员工_2:生成图片"。”3号员工_1:提示词生成“节点优化后的提示词提供给本节点,本节点处理后将图片数据返回给”3号经理“。

输入变量:(”03号经理“)
01.把”2号员工“得出的输(”03号经理“)出传给本节点,作为本节点输入值。类型默认。
02.”循环类型“选择”使用数组循环“。
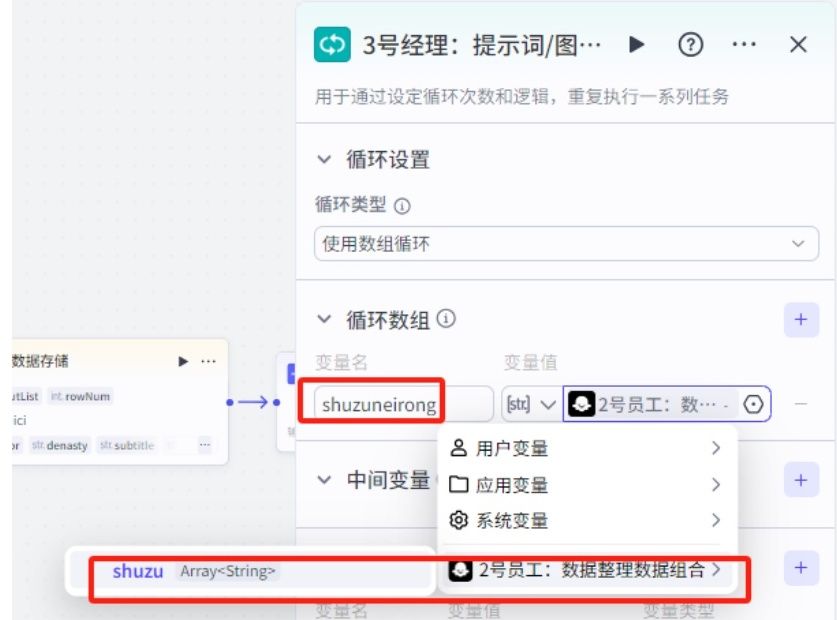
输出变量:(”03号经理“)
01.”03号员工_2“输出的结果返回给”03号经理“作为结果输出。
02.”循环类型“选择”使用数组循环“

输入变量:(”03号员工_1“)
01.”03号经理“获取到的数据传给给本节点输入值。

输出变量:(”03号员工_1“)
默认即可。
输入变量:(”03号员工2″)
01.模型选择”通用-pro“.
02.比例选择"9:16"
03.输入变量选择"03号员工_1:提示词生成"中的data。

提示词:(”03号员工_2“)
通过正反向提示词明确告诉系统图片内容要求及以不能出现哪些元素
正向提示词:
{
{data}}
画面有2到41个5岁左右的小孩,有2个男孩,2个女孩,其中一个小孩固定为5岁Q版3D动浸小女孩,头身比例2:1,圆脸杏眼,双鬟红绳,身穿改良汉元素连衣裙,幼儿启蒙风格,精致的脸,细腻光影,高分辨率,8k,艺术品
反向提示词:
Text, Sketch, Tattoo, Beard, EasyNegative, Bad Hand, Teeth, Worst quality, Low quality, Normal Quality, Reduced, Normal Quality, Face, Look, Text, Errors,
redundant numbers, Fewer Numbers, Cropping, jpeg Artifacts, Signatures,Watermarks, usernames, Blur, Skin Spots, Acne, Skin blemishes, Bad Anatomy,Fat, bad feet, cuts, badly drawn hands, badly drawn faces, mutated, deformed,tilted heads. Bad anatomy. Bad hands, more fingers, less fingers. Extra limbs.Extra arms, extra legs, deformed limbs. Fused fingers. Too many fingers, long neck, opposite eyes, mutated hands, bad body, bad proportions, thick proportions,words, mistakes, missing fingers, missing arms, missing legs, too many fingers,too many arms, too many legs, too many feet, too few fingers,

输出变量:(”03号员工_2“)
默认即可。
试运行结果:(”03号员工_2“)
输出有数组里有5个值,分别从0-4,每个数组里的内容对应生成一张图。效果如下图:

(5)”4号经理:生成视频”:业务逻辑”批处理“
01.添加业务逻辑节点”批处理“,命名为:”4号经理**:**生成视频”,用于同时处理多个视频生成。

一、使用海螺插件:
在批处理体内添加节点“海螺图生视频:st_creat_task_list”插件,命名为”04号员工:生成视频“。大部分图生视频都是需要收费。而且很贵,找了海螺这个相对便宜些,调用一次大概0.2元左右,如果你有找到合适的插件替换。
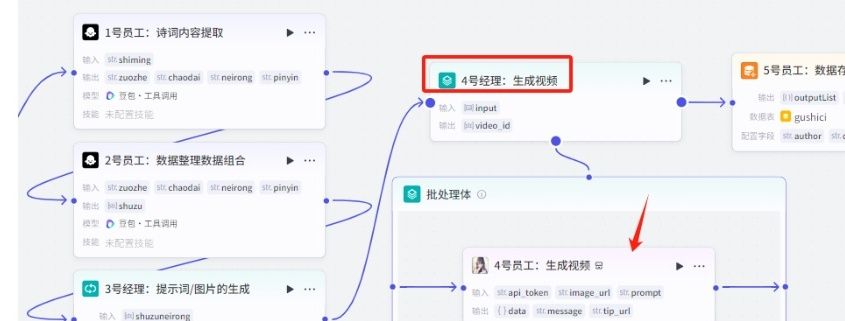
添加节点,选择插件

搜索“海螺”,把下方插件添加进来即可。

输入变量:(”04号经理“)
01.将"03号经理"输出的结果作为本节点的输入值。
2.并行运行数量及批处理上限可自己修改,建议可分别设为“2”,“10”。

二、使用智谱插件:
添加方式都一样,把批处理内的图生插件换成”智谱“的”zhipu_gen_video“,api_key只需要输入智谱官网提供的key即可。
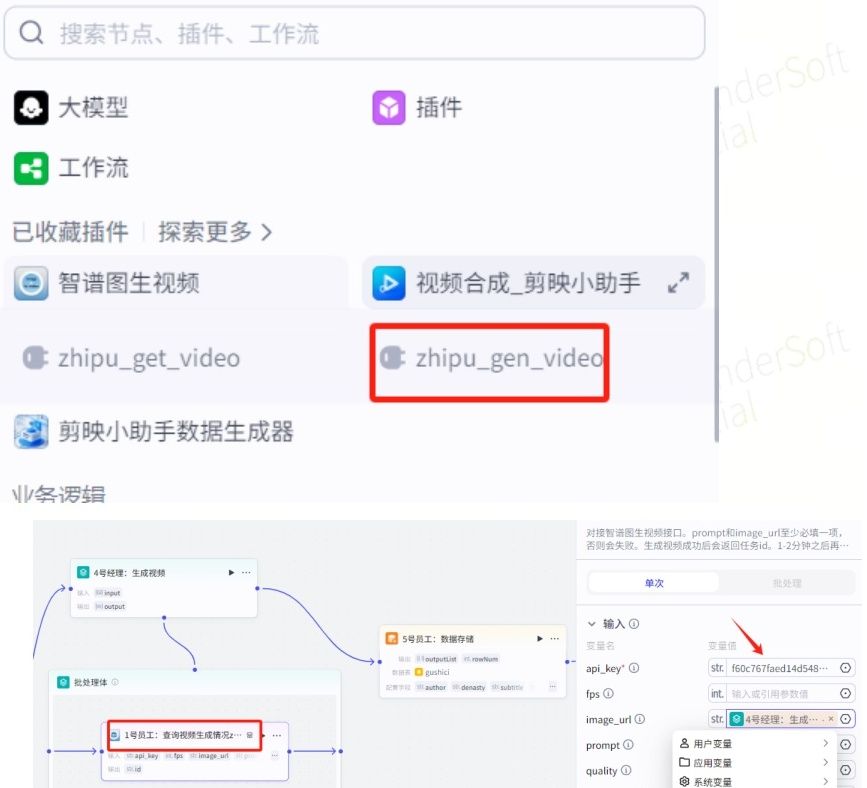
输出变量:(”04号经理“)
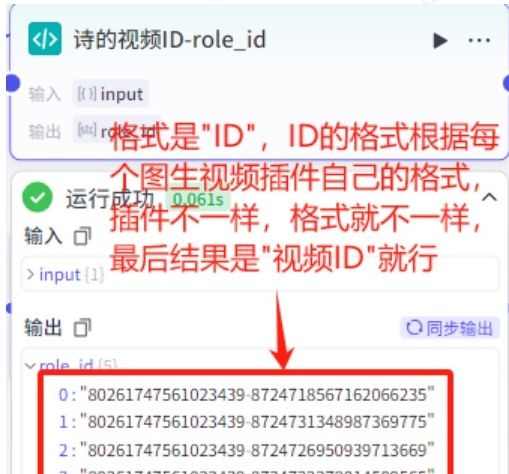
01.输出变量名“video_id”。变量值引用“4号员工:视频生成”输出结果的"ID"字段。
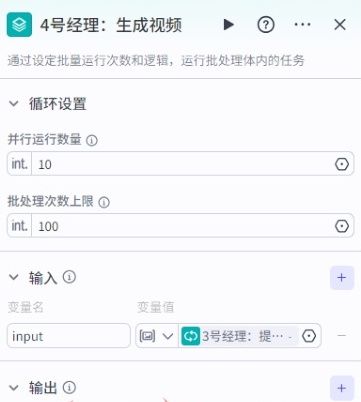

02.由于视频生成是异步行为,完成视频生成有一定的等待期,如海螺AI正常需要1-2个小时,我们将“视频ID”作为结果保存下来,以备后续查看生成结果。

输入变量:(”04号员工:“)
01.api_token填写插件的“插件API秘钥”
02.image_url获取“4号经理”的"item"值

海螺api_token如何获取:
01.通过插件详情可查看该插件相关信息。点击插件详情
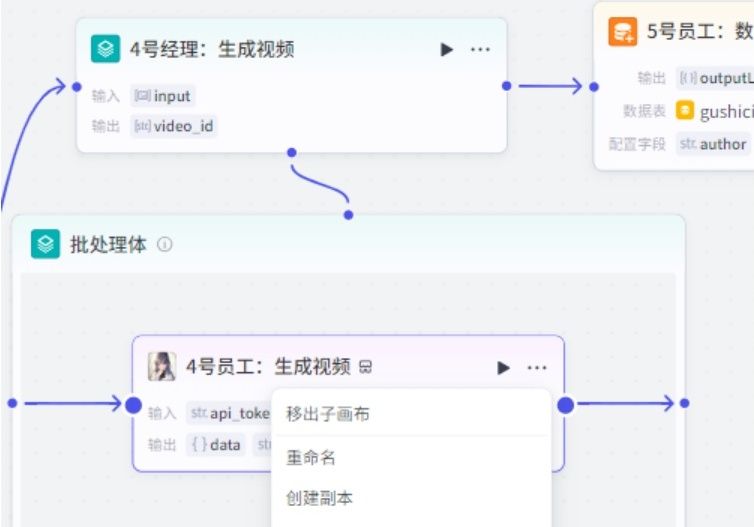
02.点击我们使用的插件,通过插件取得插件官方地址:https://ts.fyshark.com/#/userlnfo

03.打开官方地址。通过个人中心,点击复制,粘贴到节点api_token即可。插件需要付费才能用,可以先充值个10元。

智谱插件api_key获取:
01.通过下方链接(智谱官方平台)进入按步骤进行注册并实名,新号赠送500token,生成视频免费。(后续收费情况自己看,也可以自己找一些其他好用的插件,主要能生成视频跟获取就行。)
https://www.bigmodel.cn/invite?icode=iowsYtQtQ4vfy7JeS2eFLkjPr3uHog9F4g5tjuOUqno%3D
02.添加一个api_key:

名称随便写,点确定即可。

03.如何正确复制key:

输出变量:(”04号员工“)
默认即可:
运行效果:(”04号员工“)
生成5段对应的视频内容,每个都可看到调用插件返回的值。如下图。

(6)”5号员工:数据存储“节点:数据库
将最后得到的视频ID及诗相关的字段值上传到云端数据库,后续通过数据库查询相关内容进行剪辑合成完整视频。
01.点击加数据库中“新增数据”,命名为“05号员工:数据存储”

02.选中节点。在右边配置点"+”,选择”新建数据表“-“自定义数据表”
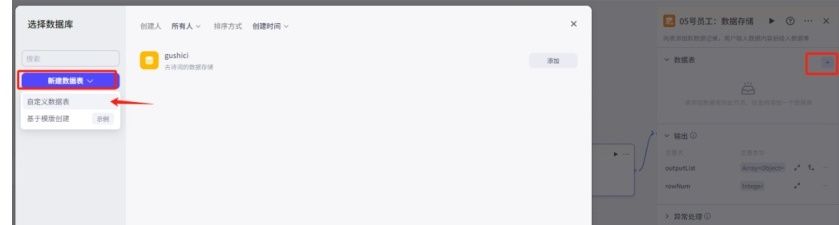
03.输入表名称及数据表描述,点确认。

04.输入要保存的字段名称及描述并选择对应的数据类型,点保存。

取消 保存
05.新建完成后点“+”将数据库添加进来

06.添加数据表后,在“选择并设置字段”将所有字段添加进来。

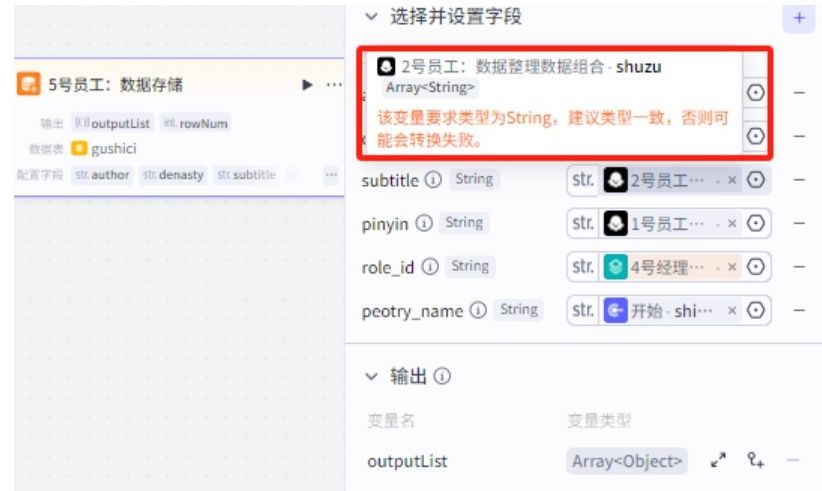
07.为添加进来的字段都设置对应的值。

author对应“1号员工:诗词提取”的zuozhe
![图片[1] - 智能体古诗词合集:一键自动生成古诗词视频AI智能体 - 宋马](https://pic.songma.com/blogimg/20250623/fc69c4a68e7e4153952039138c06d9d8.jpeg)
denasty对应“1号员工:诗词提取”的chaodai

subtitle对应“2号员工:数据整理/数据组合”的输出“shuzu”,

pinyin对应“1号员工:诗词提取”的pinyin
![图片[2] - 智能体古诗词合集:一键自动生成古诗词视频AI智能体 - 宋马](https://pic.songma.com/blogimg/20250623/db0ca9884c794edaa6d2eb10b875c2c6.jpeg)
role_id对应“4号经理:生成视频”的video_id

peotry_name对应“开始”的shiming

PS:subtitle和role_id这两个变更引用的值类型会提示错误,由于这里输出的是数组类型:["李白唐代","床前明月光","疑是地上霜","举头望明月",“低头思故乡"]这种类型,而字段是字符号。这部分错误不用管。因为我们需要的值的格式就是数组格式,数据库字段值”string“格式是能支持带有符合的数组格式内容写入,所以不用管。
输入变量:
无
输出变量:
默认即可。
试运行后效果:(数据库表)
写成成功数据库表内容如下:
gushici 0 单户式

(7)”结束“节点:
输出变量:
选择”5号员工“的输出值"outputlist"

(三)节点设计工作流2:huoqu_zhipu_shipin_zhuangtai 本工作流用于查询视频生成情况,不实际在智能体中调用。
(1)”开始”:节点
输入变量**:**
默认即可。

(2)”1号员工:查询视频生成情况”节点:智谱插件“zhipu_gen_video"
01.添加插件节点,命名为:”1号员工:查询视频生成情况”。

输入变量:
选择开始节点的输入。
(3)”结束”:节点
输出变量:
选择1号员工输出的结果。

本工作流调试方法:
01.数据存储在数据库"gushici"中,打开数据库表

02.选择要查看的行点操作,去查看并复制存到数据库表中的视频ID编号

03.复制ID

04.复制到工作流2huoqu_hailuo_shipin_zhuangtai中的试运行界面查询结果

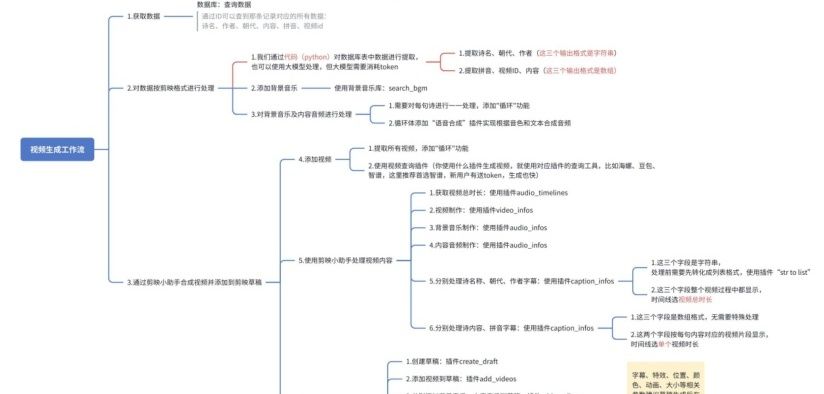
(四)节点设计工作流3:shici_shipin_shengcheng_zhipu
本工作流设计逻辑详见下面脑图:
(1)“开始”节点:
01.输入变量名:“shuji_id”,用于接收传入的数据库表中的ID号如:7505765218857926690。
02.变量类型选择"integer"
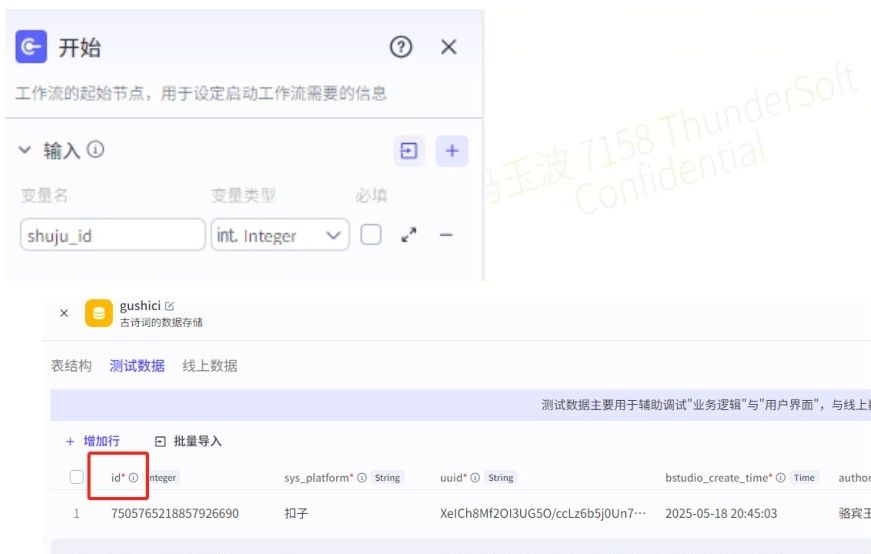
(2)“1号员工:查询数据”节点:
本节点将上个工作流存储的古诗词相关内容提取出来。供后续节点进行处理。
01.添加节点,选择“新增数据”,并命名为:“1号员工:查询数据”

02.把我们要用的数据库表添加进来。

03.把要用的字段都添加进来。

04.查询条件设置:填入id,选择“=”,变量值选择开始节点“shuju_id”

(3)“2号员工:背景音乐”节点:背景音乐库插件,search_bgm 添加背景音乐插件
输入变量值:
01.直接输入想要的背景音乐风格名就行如:古筝

(4)“诗名、朝代、作者、内容、拼音、视频ID”节点:
我们需要通过代码(python)对数据库表中数据进行提取,也可以使用大模型处理,但大模型需要消耗token。
01.添加分别添加诗名、朝代、作者、内容、拼音、视频ID这六个代码节点。
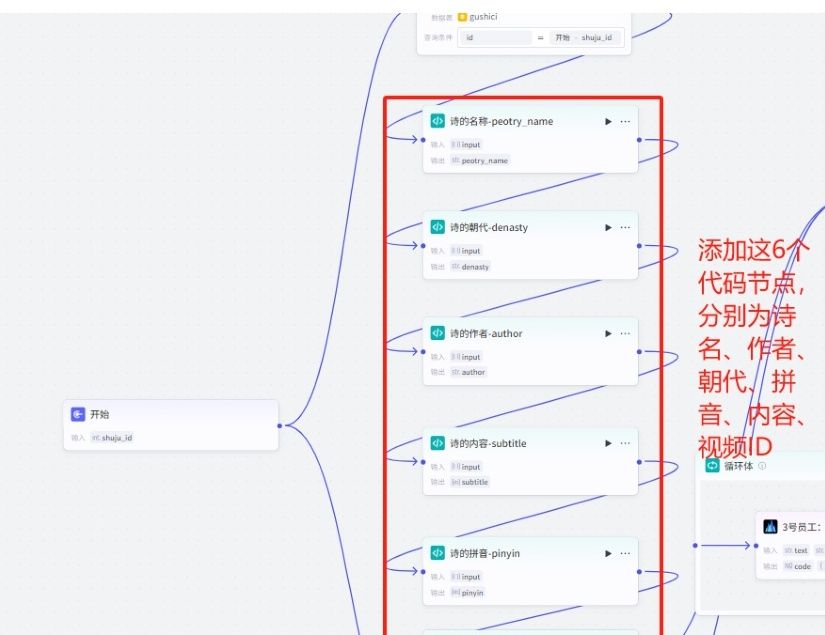
02.诗名、朝代、作者(这三个输出格式是字符串),


相关代码块如下,里面参数变量按节点对应的变量名进行替换,代码语言一定记得选择python类型。
如下图:

相应代码块如下:
async def main(args: Args) -> Output:
params = args.params
input_value = params.get('input', [])
# 从 input 的 0 索引位置提取 peotry_name
if isinstance(input_value, list) and len(input_value) > 0:
peotry_name = input_value[0].get('peotry_name', None)
else:
peotry_name = None
# 构建输出对象
ret: Output = {
"peotry_name":peotry_name
}
return ret
复制代码格式错误如何处理
1.如果出现这种错误,把代码全选

2.点最下面的ctrl+l

3.在AI提示框里输入:检查代码格式。
4.AI检查后点接受即可

5.接受完显示这样就正确了:

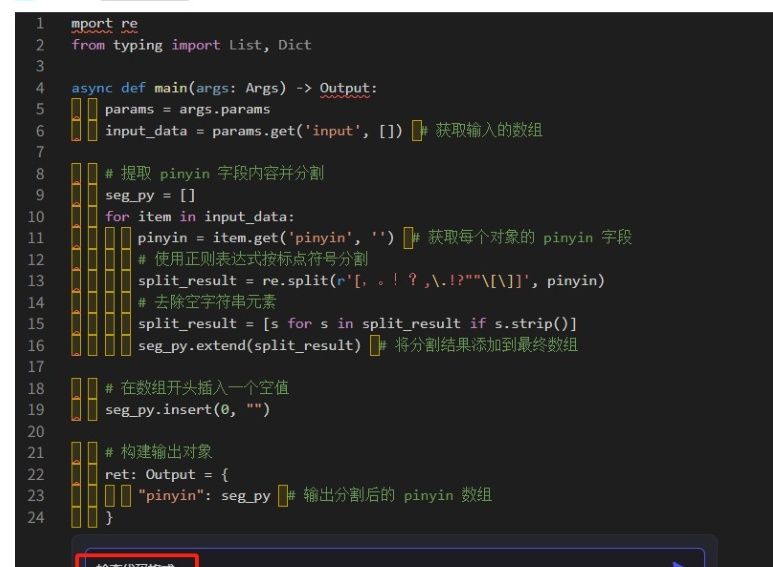
03.提取拼音、视频ID、内容(这三个输出格式是数组)。
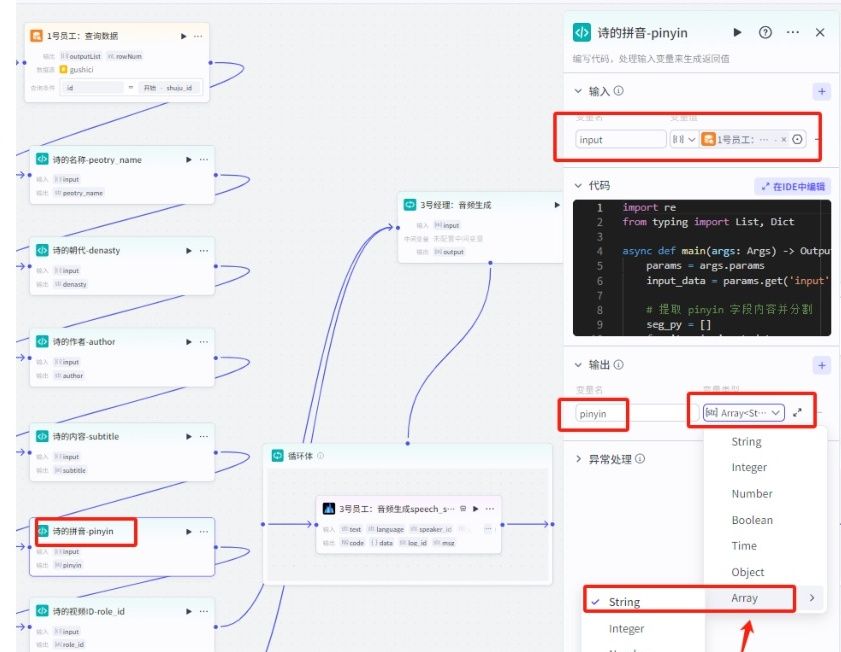
相关代码块如下,里面参数变量按节点对应的变量名进行替换,代码语言一定记得选择python类型。
关键:代码里的字段要跟变量名一样,同时也要跟数据库字段名完全一致,否则查询不到数据。因为拼音只有4句,内容跟视频均有5个,为了跟字幕匹配上,pinyin节点代码里需要增加下面这行。内容跟视频ID不需要加这行代码
Plain Text
#在数组开头插入一个空值
seg_py.insert(0,“”)
如下图:

相应代码块如下:
备注:只有pinyin这个节点需增加去除空格那两行代码,内容与视频ID这两个节点不需要
import re
from typing import List, Dict
async def main(args: Args) -> Output:
params = args.params
input_data = params.get('input', []) # 获取输入的数组
# 提取 pinyin 字段内容并分割
seg_py = []
for item in input_data:
pinyin = item.get('pinyin', '') # 获取每个对象的 pinyin 字段
# 使用正则表达式按标点符号分割
split_result = re.split(r'[,。!?,.!?""[]]', pinyin)
# 去除空字符串元素
split_result = [s for s in split_result if s.strip()]
seg_py.extend(split_result) # 将分割结果添加到最终数组
# 在数组开头插入一个空值,此处只有拼音这个节点保留。
seg_py.insert(0, "")
# 构建输出对象
ret: Output = {
"pinyin": seg_py # 输出分割后的 pinyin 数组
}
return ret
(5)“3号经理:生成音频”节点:循环
通过本对点对诗的内容进行语音生成。使用循环功能对每一句诗进行处理
01.添加节点选择“循环”并命名为:“3号经理:生成音频”,循环体内节点添加“语音合成”插件。

输入变量值:(3号经理)
01.选择代码节点“诗的内容”的输出作为本节点的变量值

输出变量值:(3号经理)
01.输出选择循环体内的3号员工的输出内容“[link]*n"
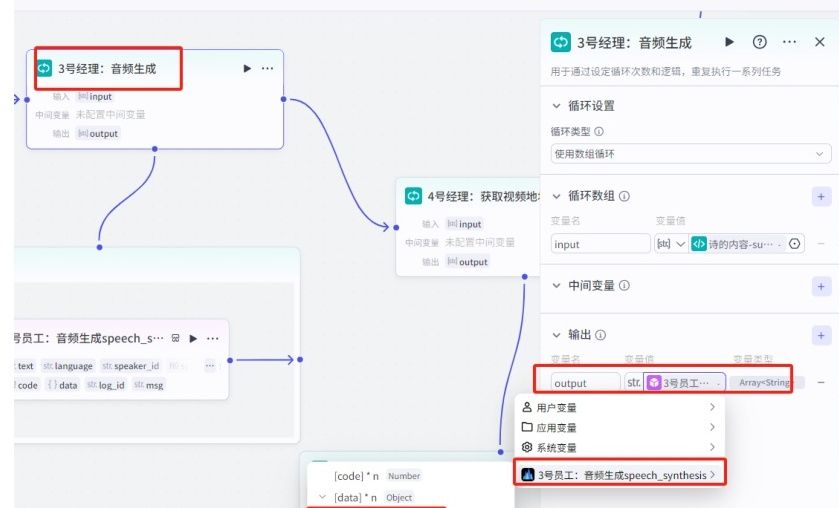
循环体内节点添加“语音合成”插件
01.添加节点,选择插件:

02.搜索“语音合成”,选择“speech_synthesis”这个插件,点添加

03.添加后给他命名为:“3号员工:音频生成speech_synthesis”,并把两边连线连起来。

输入变量值:(3号员工)
01.输入变量选择3号经理:音频生成的输出项“item”这个。
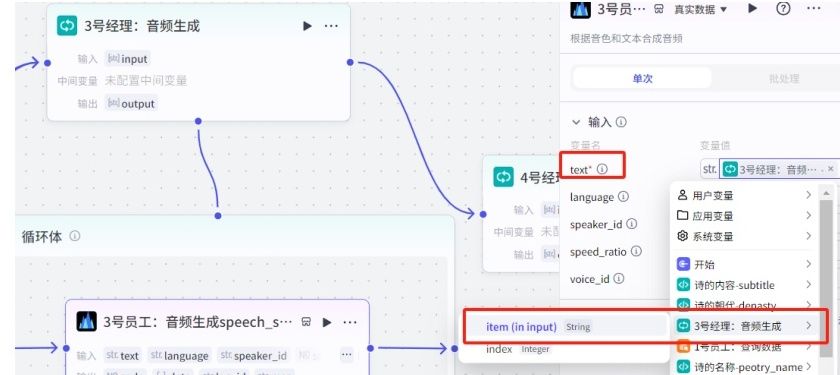
02.语带可根据自己需要填写对应数字。

03.可以通过“选择音色”进去选择合适的音色并点添加即可。


(6)“4号经理:获取视频地址”节点:使用循环
通过本节点获取每个生成的视频的地址,使用循环功能,取得每个视频的链接。

01.添加节点选择“循环”并命名为:“3号经理:生成音频”,循环体内节点添加“语音合成”插件(这里我用的是智谱的插件)。

输入变量值:(4号经理)
01.选择代码节点“诗的视频ID”的输出“role_id”作为本节点的变量值
02.循环类型选择“使用数组循环”

输出变量值:(4号经理)
*01.输出选择循环体内的输出“zhipu_get_video”的内容“[video_url]n"

循环体内节点添加“zhipu_get_video”插件,通过这个插件查询视频内容。
01.添加节点,选择插件:

02.搜索“智谱”,选择“zhipu_get_video”这个插件,点添加

03.添加后并把两边连线连起来。

输入变量值:(zhipu_get_video)
01.需要输入智谱插件的api_key。
02.输入变量选择4号经理:音频生成的输出项“item”这个。、
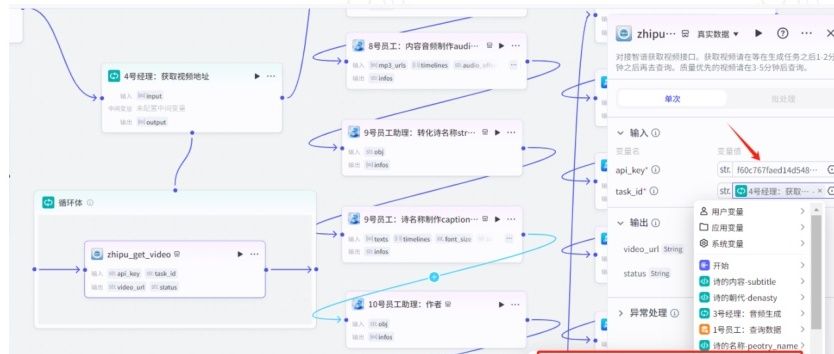
输出变量值:(zhipu_get_video)
选择4号经理的输出item。

(7)“5号员工:获取视频时长audio_timelines”节点:
本节点通过获取内容音频的时长决定整个视频的时长。
01.添加剪映小助手-audio_timelines插件,可以通过插件搜。也可以把插件收藏,点开可以直接选择。。

如何收藏插件
01.搜索你自己查收藏的插件。如这里我要收藏“剪映小助手”,点插件边上的箭头。


03.反回添加节点页面,就能展开插件选择底下任意插件。

输入变量值:
通过3号经理:音频生成的结果作为本节点的输入。

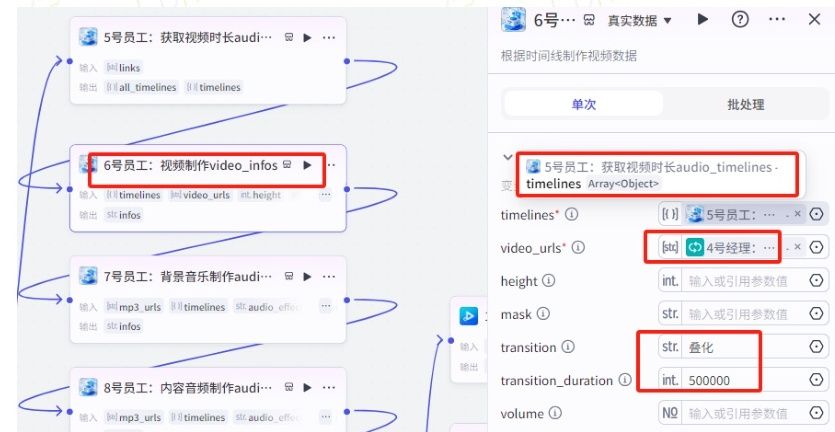
(8)“6号员工:视频制作video_infos”节点:
01.添加小助手:video_infos插件,命名“6号员工:视频制作video_infos”

输入变量值:
01.特效可以按自己需要的选择,如这里转场选择"叠化”,时长500000。(所有的节点的特效、字体、位置、大小等参数建议视频生成添加到剪映草稿后再回来对照填写,否则容易输入错导致剪映打开会闪退等情况。)
02.timelines 变量值选择"5号员工:获取视频时长的"timelines"注意是选择单个时长 timelines 不是 All timelines.
(9)“7号员工:背景音乐制作audio_infos”节点:
01.添加小助手:audio_infos插件,命名“7号员工:背景音乐制作audio_infos”

输入变量值:
01.mp3:urls选择“2号员工:背景音乐”点的的输出值bgm_urls。
02.音量按自己需要设,这里设0.5

03.背景音乐整个视频都需要,所以timelines变量值选择"5号员工:获取视频时长的"all timelines”
(10)“8号员工:内容音频制作audio_infos”节点:
01.添加小助手:audio_infos插件,命名“8号员工:内容音频制作audio_infos”

输入变量值:
01.mp3:urls选择“3号员工:音频生成”节点的的输出值output。
02.音量按自己需要设,这里设7
03.内容音频按每一句内容输出,所以timelines变量值选择"5号员工:获取视频时长的单个时长"timelines"

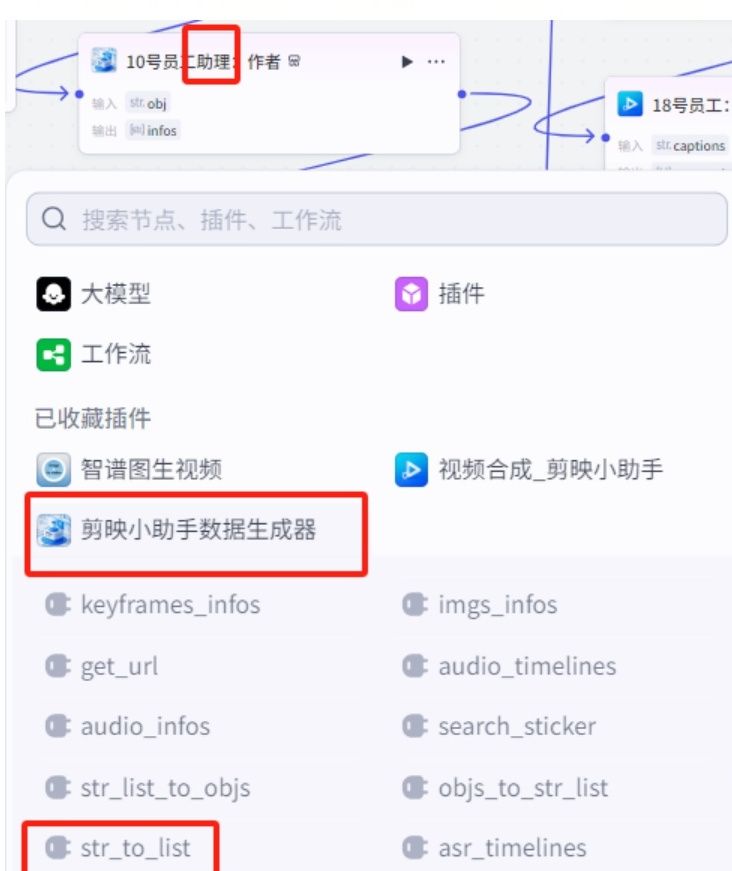
(11)“诗名、作者、朝代”各节点:
01.由于这三个字段是string类型,要转化成剪映能识别的类型。使用剪映小助手的"str to list"插件分别进行处理。分别为“9号员工助理:转化诗名称stroist”、“10号员工助理:作者处理str_to_list"、、“11号员工助理:朝代str_to_list”。处理后再分别提供给对应的节点。如“9号员工助理:转化诗名称str_to_list”提供给9号员工:诗名制作”这个节点。

02.助理节点剪映小助手的"strto list"插件
03.9号员工、10号员工、11号员工节点添加剪映小助手的"caption_infos"插件
各节点输入变量值:




(12)“12号员工:制作拼音 caption_infos:
添加剪映小助手的"caption_infos"插件

输入变量值:
01.texts变量值直接选择“诗的拼音”这个代码节点,因为这个节点本身就是数组输出,所以不需要再进行转化。
02.timelines变量值选择"5号员工:获取视频时长的单个时长"timelines"
03.特效按自己喜欢的设置。(建议在剪映调完再设置对应参数)

(13)13号员工:制作拼音caption_infos:
添加剪映小助手的"caption_infos"插件

输入变量值:
01.texts变量值直接选择“诗的内容”这个代码节点,因为这个节点本身就是数组输出,所以不需要再进行转化。
02.timelines 变量值选择"5号员工:获取视频时长的单个时长"timelines"
03.特效按自己喜欢的设置。(建议在剪映调完再设置对应参数)

(14)“14号员工:创建草稿create_draft“节点:
添加视频合成-剪映小助手的"create_draft"插件,用于创建草稿。创建草稿后把合成过的音频、视频、需要的字幕等都添加到草稿。
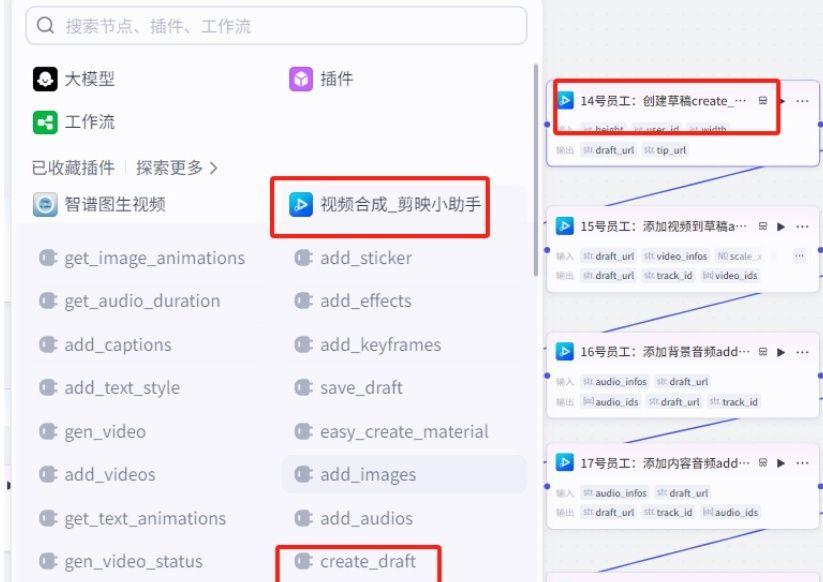
输入变量值:
变量值不用设。

(15)“15号员工:添加视频到草稿add_videos“节点:
添加视频合成-剪映小助手的"add_videos"插件,用于把视频添加到草稿中
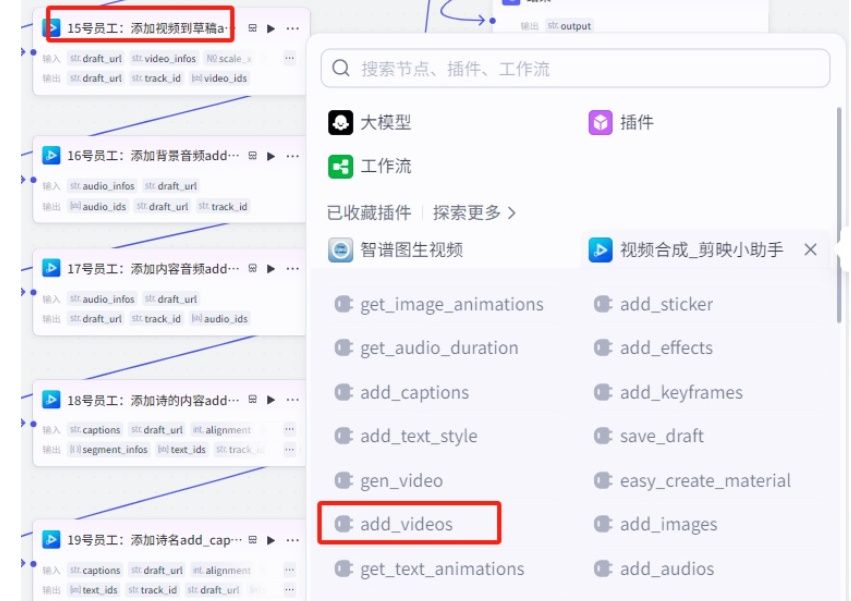
输入变量值:
01.”draft_url"选择14号员工的草稿地址”draft_url“这个值


分别添加“16号员工:添加背景音频add_audios“节点、“17号员工:添加内容音频add_audios“节点:添加视频合成-剪映小助手的”add_audios”插件,用于把视频添加到草稿中

输入变量值(“17号员工:添加内容音频add_audios“节点):
01.”draft_url"选择14号员工的草稿地址"draft_url“这个值

02.video_infos选择7号员工的输出值。

输入变量值(“17号员工:添加背景音频add_audios“节点):
01.”draft_url"选择14号员工的草稿地址"draft_url“这个值
02.video_infos选择8号员工的输出值。

(17)分别添加诗名、内容、作者、朝代、拼音字幕节点**:”add_caption“插件**
分别对应“18号员工:添加诗内容add_caption”、”19号员工:添加诗名add_caption”、“20号员工:添加诗作者add_caption”、“21号员工:添加诗朝代add_caption”、”22号员工:添加诗拼音add_caption”、::
添加剪映小助手的"add_caption"插件

参数配置如下:

(18)添加“23号员工:保存草稿save_draft“节点:
添加到草稿后需要对草稿进行保存,才能通地剪映小助手运行。

(19)“结束“节点:

(20)各重要节点的正确输出格式如下图示: ntial 冯玉波7158
1.诗名、内容、朝代、拼音、作者、视频ID
![图片[3] - 智能体古诗词合集:一键自动生成古诗词视频AI智能体 - 宋马](https://pic.songma.com/blogimg/20250623/3914537780954be0b6231e73659870b0.png)




玉波7158 ThunderSoft Confidential
压波7158 ThunderSoft
Confidential
2.音频生成

3.视频生成
各个插件的字段跟task_id格式不一样,能正确显示就行,以下以智谱例。

4.保存草稿后的地址

(21)如何使用剪映小助手一键添加到剪映草稿
打开剪映小助手客户端,需要先设置草稿路径,注意这里的路径一定需要和剪映的草稿路径一模一样,添加后才能在剪映的草稿里找到。
01.查看剪映的草稿路径,点右上角设置-全局设置

查看草稿位置,可以点右边那个文件夹进去看具体位置。(PS:默认在C盘,最好不要放C 盘。可以自己在其他盘建一个草稿文件夹)
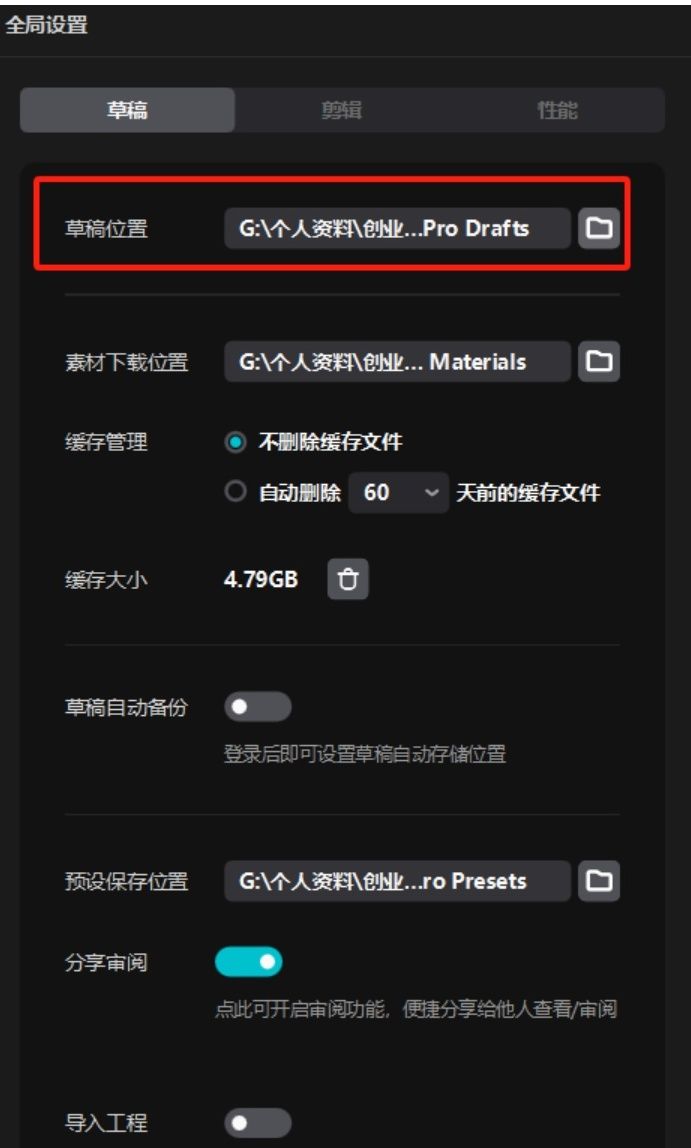
02.设置小助手设置的草稿路径。(通过上面查看剪映的草稿路径,小助手这里设置跟它一模一样的路径)

03.将工作流运行输出的结果进行复制如下图:(下面的json是运行其他智能体。方法都一样。)
PS:一定注意不要把双引号”“也复制进去。

把复制的那串链接粘贴到剪映小助手,并运行。就会自动添加到剪映草稿。

04.点创建剪映草稿运行成功后会提示如下,同时在剪映草稿就能看到:
像这样不出现红色的失败字样,全部显示绿色的代表成功
PS:即使小助手日志里全部显示成功,添加到剪映有的也会出现闪退。看小助手这里不准确,小助手只能告诉你添加到草稿的流程是不是正确,你要添加的元素是不是都有执行。但工作流元素的设置是不是正确、节点调用是不是正确,他检测不到。出现这种可以在工作流上每个节点开”运行结果“看下是否都有输出数据。
常错的可以参考下:四、实操避坑指南”07.添加到剪映草稿失败或闪退“

05.打开剪映,在草稿箱位置就能看到视频,第一次是黑色的。需要点进去加载一次就正常了。
(22)字体、特效、位置等参数调整
01.运行完成后添加到剪映草稿后的视频,打开视频进行字体大小、位置、特效、动画、视频转场等参数调整。
如下图,将诗名、作者、朝代、内容、拼音按你喜欢的进行调整
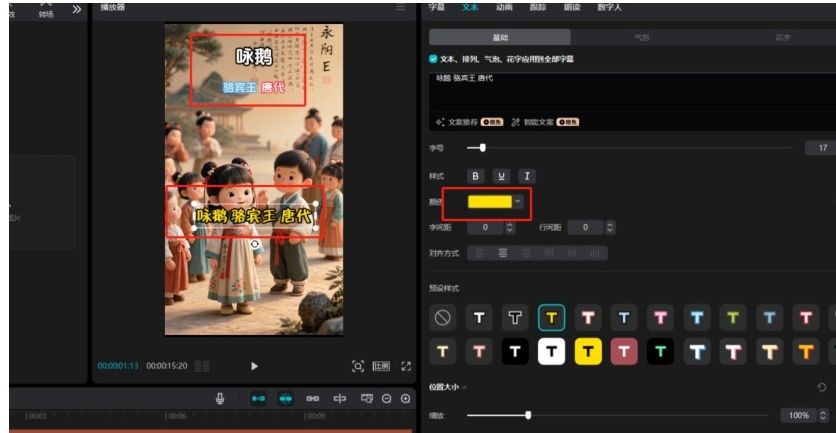
02.比如对内容字体样式进行设置,选择好你想要的样式。

点颜色,并复制颜色编号填到扣子对应的”内容“节点字体颜色参数格中,比如这里选的样式,需要分别复制文本颜色和边框颜色填写到扣子对应的参数:text_color、border_color


0:00:18:24
|00:15
同样点开边框复制颜色编号:


03.其他的参数按自己需要的设置对应填入即可。
重点:
字体名字一定要写对(比如”随机打字机“写成”随机打字“),
颜色不能使用大写字母,出现剪映识别不了的会出现打开闪退。
输入①

3、发布智能体及演示
(一)发布:
待补充
智能体调试运行没问题可发布到扣子商店中。选择左上角“发布”按钮即可以发布
(二)演示:
待补充
四、实操避坑指南及小技巧
01.建议每添加一个节点后调试下运行是否正确,避免全部添加完不好排查问题点及浪费资源点数,特点是在生成图片及视频这类节点中。调试方法:直接将要调式的节点直接连接到“结束”节点,再试运行即可。如下图:

02.图片生成一张消耗资源点多,且使用海螺生成视频只要有调用就需要0.2元,为节点钱,可按以下方式修改。再进行调试,确认没问题再把提示词加上。

)
03.图生视频跟查询视频插件用反。
04.海螺生成的视频用智谱查询插件查,导致查不到视频。
05.节点设置没选对。
06.代码用错。
如字符型的用数组的代码。数组的代码用字符型的。或者语言没选python。
07.添加到剪映草稿失败或闪退
(一)从日志可以看见创建的过程,是全成功还是失败。正常如果所有生成视频、音频或添加到草稿的内容都正常,会全部显示下载完成。像下图如果某个下载失败的。就反回去工作流重新看下为什么失败(有时候插件运行也会失败,特别是图生视频)。

虽然部分下载失败,但最后结果也会成功添加到草稿,不过打开会出现文件丢失。如下图这种就是下载失败,剪映里就会显示媒体丢失。这种情况就去排查下哪里有问题。重新运行一次。
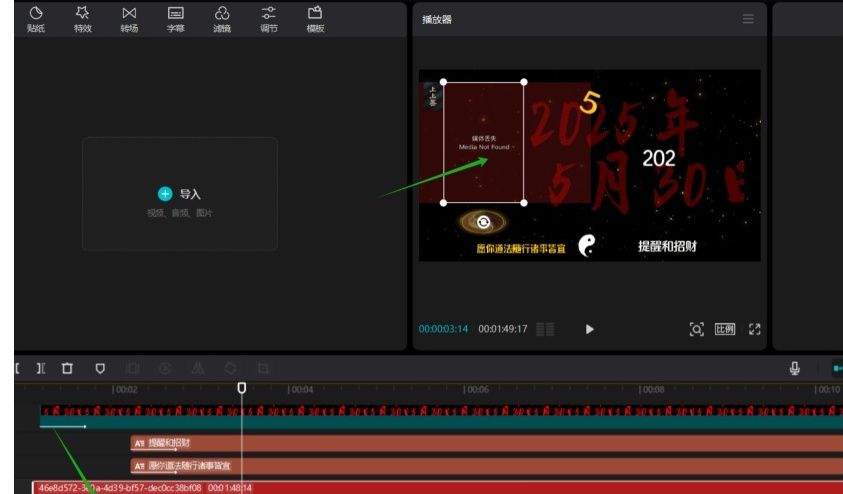
(二)闪退
很多人添加到剪映,支持小助手也全部提示下载成功,但就是闪退。
出现这种先处理把前面失败的草稿都删除。如果还是不行说明工作流设计上还是存在问题。通常排查方法以,一是看下代码节点设计有没有错、二是看其他节点变量是否选错。三是剪映特效是不是有写错。具体需要自己细致排查



















暂无评论内容