
《人工智能AI之机器学习基石》系列⑥
引言:我们画的“那条线”,遇到了新麻烦
在之前的旅程中,我们教会了机器两项核心技能:用线性回归画出一条“预测之线”,用逻辑回归画出一条优雅转弯的“分类之线”。无论是预测房价,还是判断肿瘤,它们都试图用一个统一、连续的数学公式来描绘整个世界。
这很强大,但现实世界,远比一条线复杂。
想象一下,你是一位经验丰富的医生,在诊断一位病人。你会用一个复杂的公式计算所有指标,得出一个“73.5分”的诊断分吗?
不,你更可能会这样做:
“如果体温高于38.5度,并且咳嗽,那么很可能是病毒感染。”
“如果体温正常,但某个血液指标异常,那么需要做进一步检查。”
这是一种完全不同的思维方式——它不是在寻找一条“普适”的线,而是在构建一套层层递进、条理分明的决策规则。这套“如果…那么…”(If-Then)的逻辑,根植于我们每个人的直觉深处。
当机器厌倦了用一条线去“一刀切”地解决所有问题时,它开始向人类最古老、最强大的决策智慧学习。
于是,决策树(Decision Tree)应运而生。今天,让我们一起探索,当机器学会了像专家一样思考,并进一步组建起一支“专家梦之队”——随机森林(Random Forest)时,我们眼中的世界,将被如何深刻地重塑。
一、 决策树:像顶级专家一样思考,把世界“切”成一块块
决策树,顾名思义,就是一种树状的决策模型。但这个比喻还不够生动。
让我们把它想象成一场经典的“20个问题”游戏。你的朋友心里想好了一个物体(比如“大象”),你的目标是通过问不超过20个“是/否”问题来猜出它。
你会怎么问?
错误示范:“它是‘大象’吗?”——信息量太低,纯属瞎猜。
专家级提问:“它是活的吗?” -> “是” -> “是动物吗?” -> “是” -> “是哺乳动物吗?” -> “是” -> “它的体型很大吗?” -> “是”…
你看,每一个好的问题,都能将可能性范围大幅缩小,让你离答案越来越近。决策树的核心思想,正是如此:通过一系列“最有效率”的问题,将混乱复杂的数据集,一步步划分成纯净、清晰的区域。
1.1 决策树的解剖学
一棵典型的决策树,由三个核心部件构成,我们可以用“医生诊断”的例子来理解:
根节点 (Root Node): 整棵树的起点,代表第一个、也是最关键的那个问题。比如,医生首先会问:“你最主要的症状是什么?” 这对应着数据集中最重要的那个特征。
内部节点 (Internal Node): 树干和树枝,代表后续的每一个决策问题。比如,“体温超过38.5度吗?”、“咳嗽吗?”。每个内部节点都是对一个特征的判断。
叶子节点 (Leaf Node): 树的终点,代表最终的结论。比如,“诊断为:普通感冒”、“建议:住院观察”。在分类任务中,叶子节点就是一个类别;在回归任务中,它是一个具体的数值。
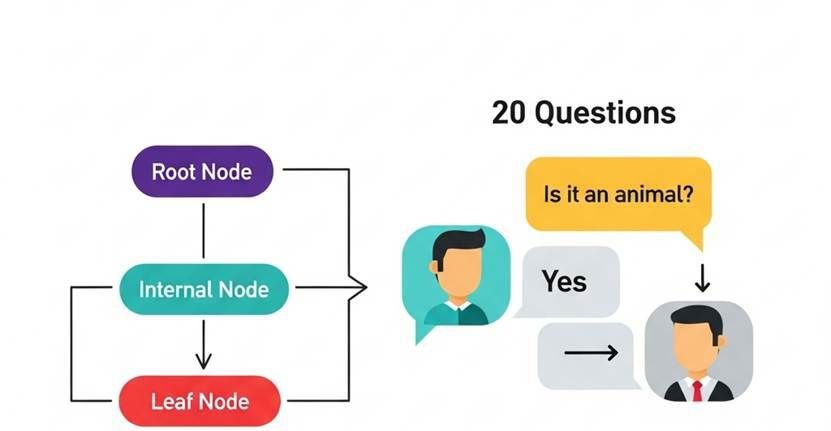
决策树的解剖学与“20问游戏”类比
20问游戏
(图注:决策树的结构,就像一场高效的“20问游戏”,每个问题都为了最快锁定答案)
二、 决策树的灵魂:如何提出“最关键的问题”?
我们已经知道决策树是通过提问来划分数据。但成千上万个特征,先问哪个?后问哪个?顺序错了,可能问了几十个问题还在原地打转。
决策树的“智能”之处,就在于它有一套精密的数学方法,来保证每一次提问,都是当下最高效、最能“澄清事实”的那个问题。这个过程,我们称之为“追求纯度” (Purity Seeking)。
想象两筐水果,一筐里只有苹果,我们称之为“纯的”;另一筐里苹果、香蕉、橘子混在一起,我们称之为“不纯的”或“混乱的”。决策树的目标,就是通过一次次划分,让每个小筐里的水果种类尽可能单一。
为了衡量这种“纯度”,科学家们发明了两个著名的指标:信息熵 (Entropy) 和 基尼不纯度 (Gini Impurity)。
2.1 信息熵:消除世界的不确定性
“熵”,源自热力学,衡量一个系统的混乱程度。在信息论中,它被引申为信息的不确定性程度。
高熵: 代表高度不确定、高度混乱。比如,一个包含50个流失用户和50个留存用户的集合,熵很高。你随便抓一个,完全没把握猜对他/她是否会流失。
低熵: 代表高度确定、高度纯净。比如,一个包含100个流失用户的集合,熵为0。你闭着眼睛都知道下一个是流失用户。
决策树在选择分裂特征时,会计算一个叫做“信息增益 (Information Gain)”的指标。它的逻辑很简单:
信息增益 = 分裂前的熵 – 分裂后的熵
哪个特征分裂后,使得总体的“熵”下降得最多(也就是不确定性减少得最多),哪个特征就是当下“最关键的问题”。这就像在“20问游戏”里,问“是不是活的?”比问“是不是红色的?”能排除掉更多错误答案,信息增益自然更高。
2.2 基尼不纯度:一个更快的“纯度检测器”
信息熵的计算涉及到对数,略显复杂。于是,另一位天才数学家提出了一个更简洁、计算更快的指标——基尼不纯度。
它的含义是:从一个数据集中随机抽取两个样本,它们类别不一致的概率。
高基尼不纯度: 集合很混乱,抽到两个不同类别样本的概率很高。
低基尼不纯度: 集合很纯净,抽到两个不同类别样本的概率很低。
在构建决策树时(特别是著名的CART算法),模型会选择那个能让基尼不纯度下降最快的特征进行分裂。

信息熵与基尼不纯度的生动比喻
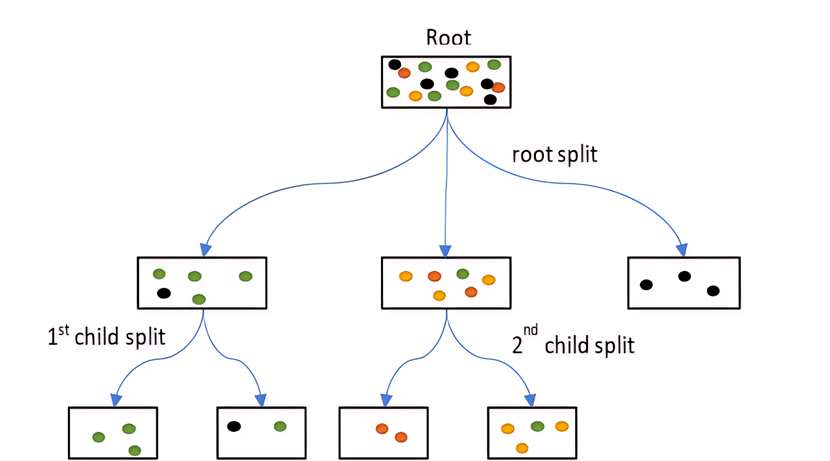
(图注:决策树选择分裂特征,就像把一罐五颜六色的豆子,分成几罐颜色更纯的豆子)
小结一下: 无论是信息熵还是基尼不纯度,它们都是决策树用来量化“问题好坏”的标尺,确保这棵树的每一次生长,都朝着最快“理清头绪”的方向前进。
三、 天才的“阿喀琉斯之踵”:过拟合与剪枝
决策树有一个致命的诱惑:它可以永无止境地生长下去,直到每个叶子节点只包含一个样本。这样的树,在训练数据上的表现将是完美的(100%正确率),因为它相当于“背下了所有答案”。
但这恰恰是它的“阿喀琉斯之踵”。
一个背下了所有考题答案的学生,在面对一套全新的考卷时,往往会一败涂地。这种现象,我们称之为过拟合 (Overfitting)。这棵“完美”的树,学到的可能不是普适的规律,而是训练数据中独有的噪声和巧合。
如何防止决策树变成一个只会“死记硬背”的书呆子?答案是剪枝 (Pruning)。
剪枝分为两种:
预剪枝 (Pre-pruning): 在树的生长过程中就设定一些规则,提前终止它。比如:
限制树的最大深度。
要求每个叶子节点至少包含N个样本。
要求每次分裂带来的“信息增益”必须大于某个阈值。
这就像给学生定规矩:“这道题太偏了,不许花时间去记!”
后剪枝 (Post-pruning): 先让树尽情生长,长成一棵“完美”的大树。然后,再从下往上,像园丁修剪树枝一样,逐一考察每个分支。如果剪掉某个分支能让模型在独立的验证数据集上表现更好,那就果断剪掉。
这就像学生考完试后复盘:“这个知识点太细碎,对整体理解没帮助,以后可以忽略。”
剪枝的本质,是一种权衡。 是在模型的“复杂度”与“泛化能力”之间寻找最佳平衡点。一棵经过精心修剪的树,才是真正兼具智慧与稳重的“专家”。
四、 从“一棵树”到“一片森林”:随机森林的集体智慧
决策树很棒,它直观、可解释性强,就像一位逻辑清晰的专家。但它也有专家的通病:观点可能存在偏见,且不够稳定。 稍微换一批数据(比如换一批病人案例),它可能就会长成一棵完全不同的树,给出截然不同的诊断逻辑。
这在需要高度稳定性的金融风控、医疗诊断等领域是难以接受的。
如何解决这个问题?古老的智慧告诉我们:三个臭皮匠,顶个诸葛亮。
如果一位专家的判断不可靠,那就组建一个“专家委员会”,让大家集体投票决策。这就是随机森林 (Random Forest) 的核心思想。
随机森林,并非简单地把一堆决策树放在一起。它的强大,源于一个核心原则:保证委员会成员的“多样性”。如果所有专家背景、思路都一模一样,那投票就失去了意义。
随机森林通过两大“法宝”来创造多样性:
4.1 法宝一:样本随机 (Bagging)
Bagging是Bootstrap Aggregating的缩写。它的操作是:假设我们有1000个原始样本,要训练100棵树。
对于第一棵树,我们从1000个样本中有放回地随机抽取1000个样本来训练它。(“有放回”意味着同一个样本可能被抽中多次,也可能一次都抽不中)。
对于第二棵树,我们再次从原始的1000个样本中,有放回地随机抽取1000个……
……以此类推,为每一棵树都提供一份“略有不同”的训练餐。
这就像让每个专家看的病历库都略有差异,从而让他们形成各自独特的经验和视角。
4.2 法宝二:特征随机
光是训练数据不同还不够。如果数据中某个特征特别强势(比如“体温”),那可能所有专家都会优先已关注它,导致思路趋同。
为了打破这种局面,随机森林规定:
在每一棵树的每一个节点进行分裂时,不再是从全部N个特征中寻找最优解,而是从随机抽取的k个(k < N)特征中,寻找最优解。
这相当于强制每位专家在做决策时,不能查看全部资料,只能随机参考一部分。有的专家这次看到了“血压”和“心率”,下次可能就只能看“血氧”和“白细胞计数”。这逼迫每一棵树都去发掘不同特征的潜力,进一步增加了“专家委员会”的多样性。

随机森林——多元化的专家委员会
(图注:随机森林通过样本和特征的“双重随机”,打造了一支各有所长、优势互补的专家梦之队)
当一个新的病人到来,随机森林会让委员会里的每一棵树(每一位专家)都独立给出诊断,最后通过“投票”(分类问题)或“取平均值”(回归问题)的方式,得出最终的、更稳健、更准确的结论。
五、 当“规则”遇见“集体”:应用、权衡与洞察
现在,我们武器库里有了三员大将:逻辑回归、决策树、随机森林。它们各自代表了不同的解题哲学,适用于不同的战场。

一个关键洞察:特征重要性
随机森林虽然牺牲了单次决策的可解释性,但它却提供了一个无与伦比的“宏观洞察”——特征重要性 (Feature Importance)。
它是如何做到的?很简单,模型会去统计:在森林里的所有树中,某个特征(比如“历史逾期次数”)平均而言,在多大程度上贡献了“信息增益”或“基尼不纯度下降”。贡献越大的特征,自然就越重要。
这在商业上价值巨大。比如,一个电商公司可以通过随机森林发现,“用户最近一次购买间隔”比“用户年龄”对流失的预测重要得多。那么,运营策略就应该聚焦于如何缩短用户的购买间隔,而不是在年龄上做文章。
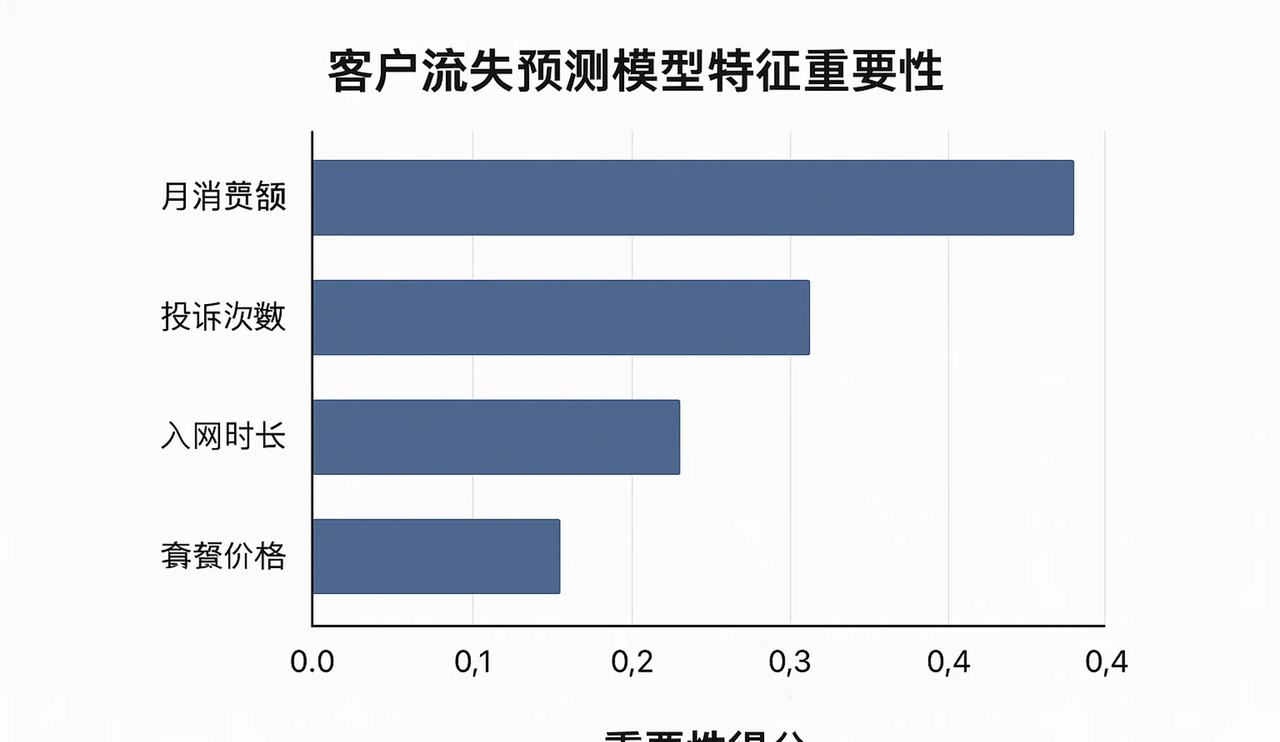
特征重要性条形图
(图注:随机森林能告诉我们,在成百上千个因素中,哪些才是决定结果的“关键先生”)
结语:从一条线到一个世界观
回顾我们的旅程,从线性回归到逻辑回归,我们教会了机器用数学的“线”去拟合和分割世界。这是一种优雅、简洁的“一元论”世界观。
而今天,决策树与随机森林为我们打开了一扇全新的大门。它们不再执着于寻找那条唯一的“完美之线”,而是通过“如果…那么…”的规则,将复杂的世界解构成一个个可以理解的、清晰的子空间。这是一种更贴近人类直觉的“结构化”世界观。
决策树,是AI世界里的“规则大师”和“透明判官”。它让我们相信,复杂的决策,可以被拆解为简单的逻辑。
随机森林,则是AI世界里的“智慧委员会”。它告诉我们,个体的偏见可以通过集体的智慧来中和与超越,稳定性和准确性可以兼得。
掌握了它们,你不仅掌握了两种强大的机器学习工具,更重要的是,你理解了一种全新的、用规则和结构来理解数据的思维范式。这,将是你未来在数据科学道路上披荆斩棘的又一柄利器。
🔭 下一篇预告:支持向量机(SVM)——在数据旷野中,划出最宽的“安全边界”
我们已经学会了用“线”和“树”来分类。但还有一种更极致的哲学:分类,不仅仅是分开,更是要“以最大间距”分开。
如何找到那条与两类样本都保持最远距离、最“老死不相往来”的“安全边界”?当数据线性不可分时,又该如何施展“升维打击”,在更高维度上轻松划线?
下一篇,让我们一同走进支持向量机(SVM)的精妙世界,感受“最大间隔”带来的极致分类美学。
💬 互动思考(欢迎在评论区留下你的洞见):
在你看来,医院的“分诊台”护士的工作流程,更像是一个决策树模型,还是一个逻辑回归模型?为什么?
随机森林通过“随机”来提升模型的准确性,这是否与你“越精确、越好”的直觉相悖?你是如何理解这种“以退为进”的智慧的?
如果一个金融风控模型,决策树给出的结果是“拒绝”,随机森林是“通过”,而逻辑回归给出的通过概率是51%,作为决策者,你该相信谁?为什么?
期待在评论区看到你的精彩思考,我们下一篇再会!



















暂无评论内容