
本账号致力于探索和传播 AI Python:用AI编写Python程序,由Python程序反过来调用AI并增强AI的功能,形成 “AI-Python-AI” 互动环,释放AI潜力。欢迎已关注!
学习者可零基础入门,只要学会如何开启AI-Python互动环,就有望获得AI自由,徜徉于新科技革命下的海阔天空。
目录
1.背景
2.案例引入
3.具体方法:
4.安装ffmpeg
5.deepseek编程提示词
(1)第一问
1)使用专业视频转文本工具
2)通过语音识别软件(免费方案)
3)利用在线服务(需上传视频)
(2)第二问
(3)第三问
6.基础作业(人人应能够完成)
7.进阶作业(不强制)
8.附录代码
8.1音视频字幕的自动转写及翻译(改变语种参数)
8.2视频字幕的自动上载
8.3音视频格式转换
(1)音视频格式基本转换函数
(2)常见转换场景
1)视频格式转换
2)音频格式转换
3)提取音频
4)调整视频分辨率
5)调整视频码率
6)使用示例
(3)高级用法
1)添加进度条
2)批量转换
(4)注意事项
8.4视频-图片互转
(1)视频转图片序列(拆帧)
1)基本功能实现
2)使用示例
(2)图片序列转视频
1)基本功能实现
2)使用示例
(3)高级功能
1)提取特定时间段的帧
2)创建延时摄影视频
3)添加音频到图片生成的视频
(4)综合使用示例
(5)注意事项
1.背景
音视频字幕的转写、翻译和上载既是影视加工的必备程序,也是教师录制、转播多媒体教学材料的日常需要,还是当今自媒体时代短视频制作、搬运、译入、译出的常规操作。
目前常见的处理方法有两种:(1)使用字幕处理软件;(2)短视频平台自动转写和翻译。
这两种方法都有一些缺陷:前者自动化程度低,但过于繁琐;后者自动化程度高,但不可控(常有错误,但无法编辑、修改)。
本文将推荐由AI Python实现的第三种方法:Python+Whisper。在实现高自动化的同时,结果可控——可以编辑转写出来的字幕或修改AI生成的译文。
2.案例引入
小吴是自媒体创业者,他既想创作短视频,发布在国内外平台,又想搬运短视频,将高热度的国外视频引入国内平台。但他的创业计划遇到了技术障碍:如何高效地完成视频字幕的转写、多语种翻译和上载呢?
本案例主要使用AI +Jupyter Notebook作为代码生成和调试的开发工具(新读者请点击这里查阅前文,做好相应准备再来学习本文)。
目的是帮助学习者更好地体验AI Python的运作机制,观摩、学习AI写出的Python代码,进而掌握Python基础和AI Python基础。
之后,学习者再转向Vibe Coding(氛围编程)使用Cursor或Trae等高度AI集成的开发工具时,将会更加得心应手。
3.具体方法:
1)首先安装ffmpeg,具体安装方法见下文(这里只演示Windows系统下的安装方法,其他操作系统下的ffmpeg安装请自行百度或者请教AI);
2)打开deepseek的官网窗口,输入本文第5节提供的deepseek编程提示词,deepseek会为我们实现Python编程(由于每次生成结果可能有所不同,但一般都能够成功运行。如果你没有生成理想的代码,本文最后会附上经过调试、验证的代码);
3)将deepseek编写的代码复制粘贴到Jupyter Notebook(新已关注的读者可点击这里查看往日贴文中的“3.运行代码”学习代码的调试、执行方法);
4)将待处理的视频的路径填入 video_path = r”” 中的引号内(引号必须保留);
5)最后点击Jupyter Notebook上的“运行”,然后观察运行结果,如果没有报错,耐心等待一会儿转写、翻译和上载任务就全部完成了。
6)注意事项:
如果出现类似报错信息
“ModuleNotFoundError: No module named ‘xxx’”,直接使用 pip install xxx安装所缺模块即可。如提示找不到openai-whisper和pydub,则在jupyter notebook的空白代码框中输入 pip install openai-whisper pydub 然后点击运行,等待安装完成后,再把光标移入前面处理视频字幕的代码框,再次点击运行即可。
如果第一次运行代码,会自动下载安装Whisper模型,需要多等待一段时间。
下面先讲解ffmpeg的安装,然后再提供提示词和代码。
4.安装ffmpeg
从 FFmpeg 官网https://ffmpeg.org/,下载 ffmpeg-git-full.7z,详见图1-3。

图1 登录下载页面
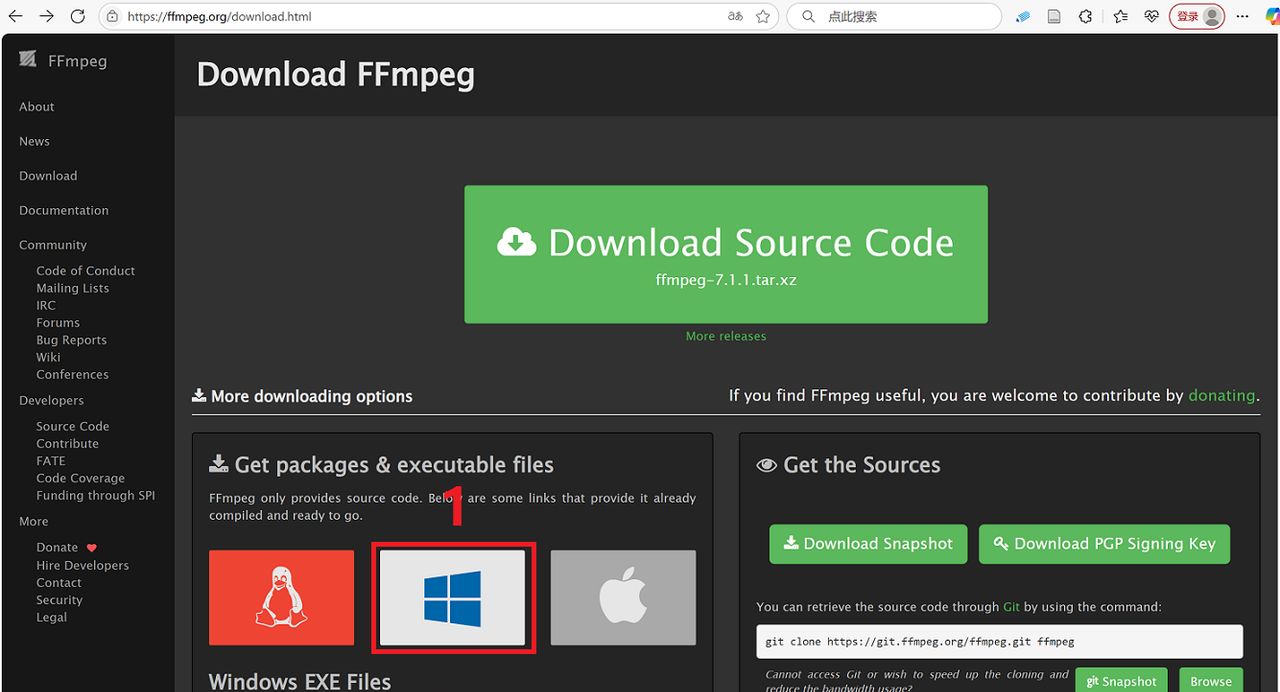
图2 选择适合自身操作系统的版本
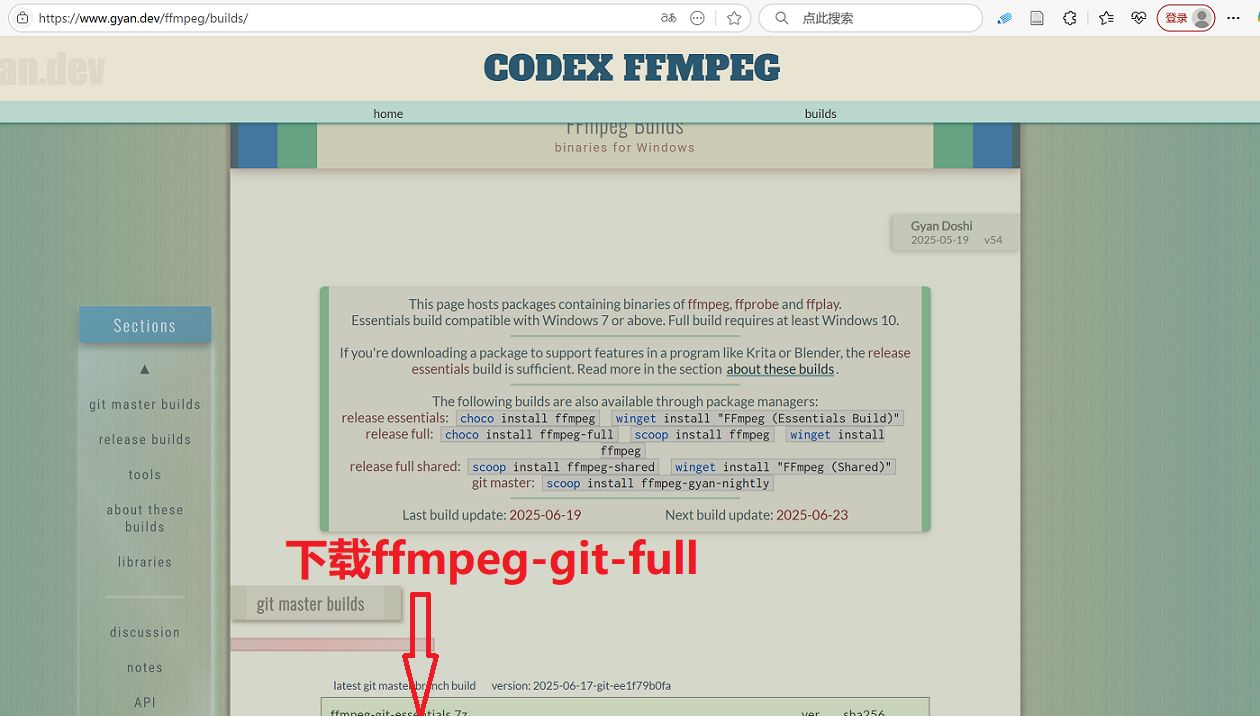
图3 下载ffmpeg-git-full.7z
解压后,将 bin 文件夹路径(如 C:ffmpegin)添加到系统环境变量 PATH中,详见图4-6。
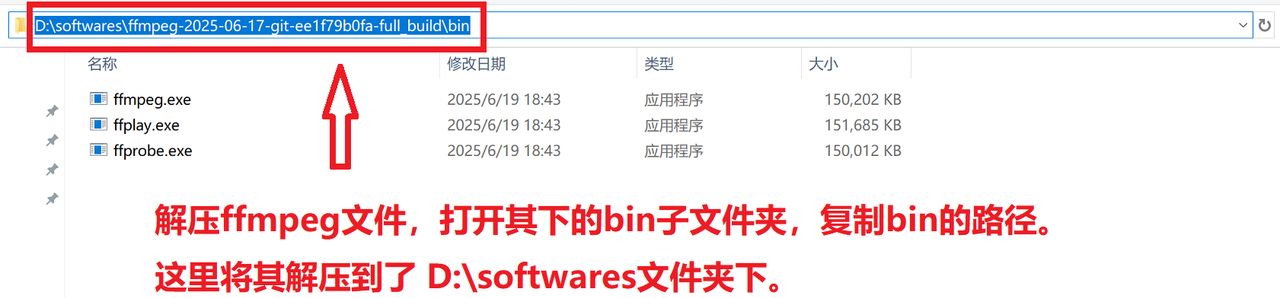
图4 解压并复制路径
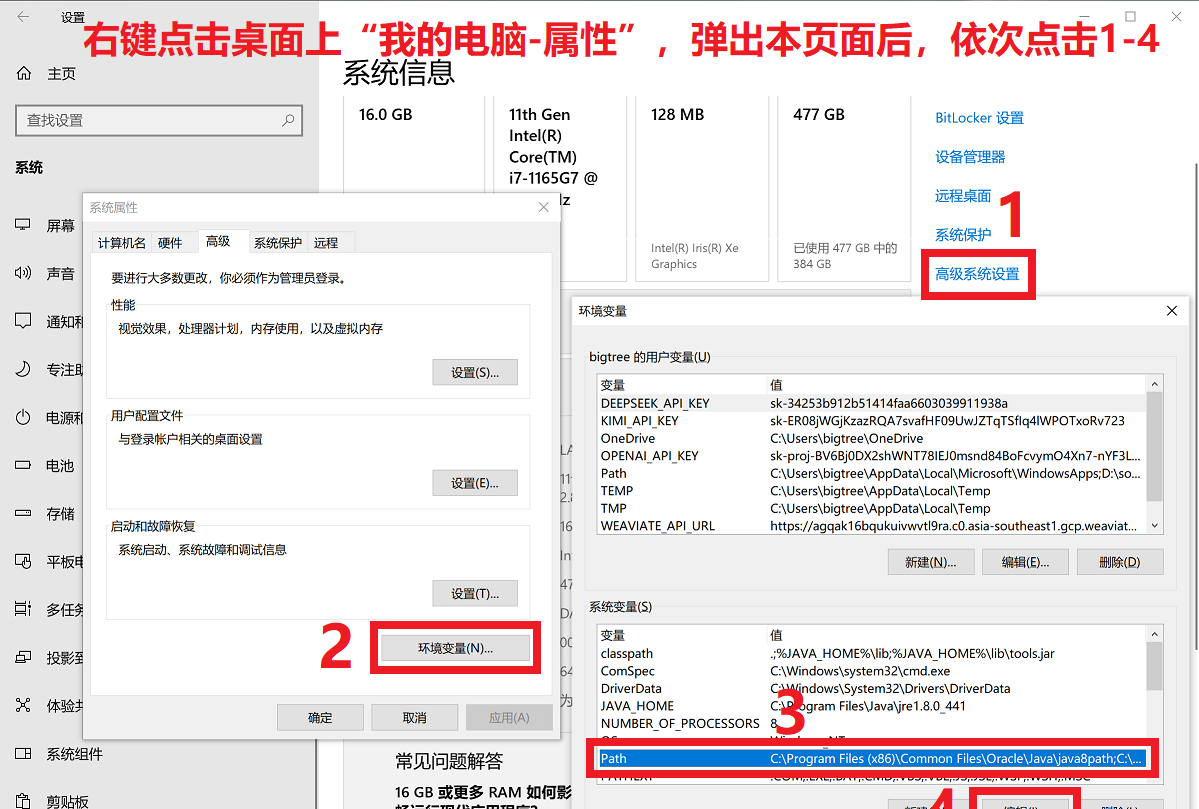
图5 设置环境变量
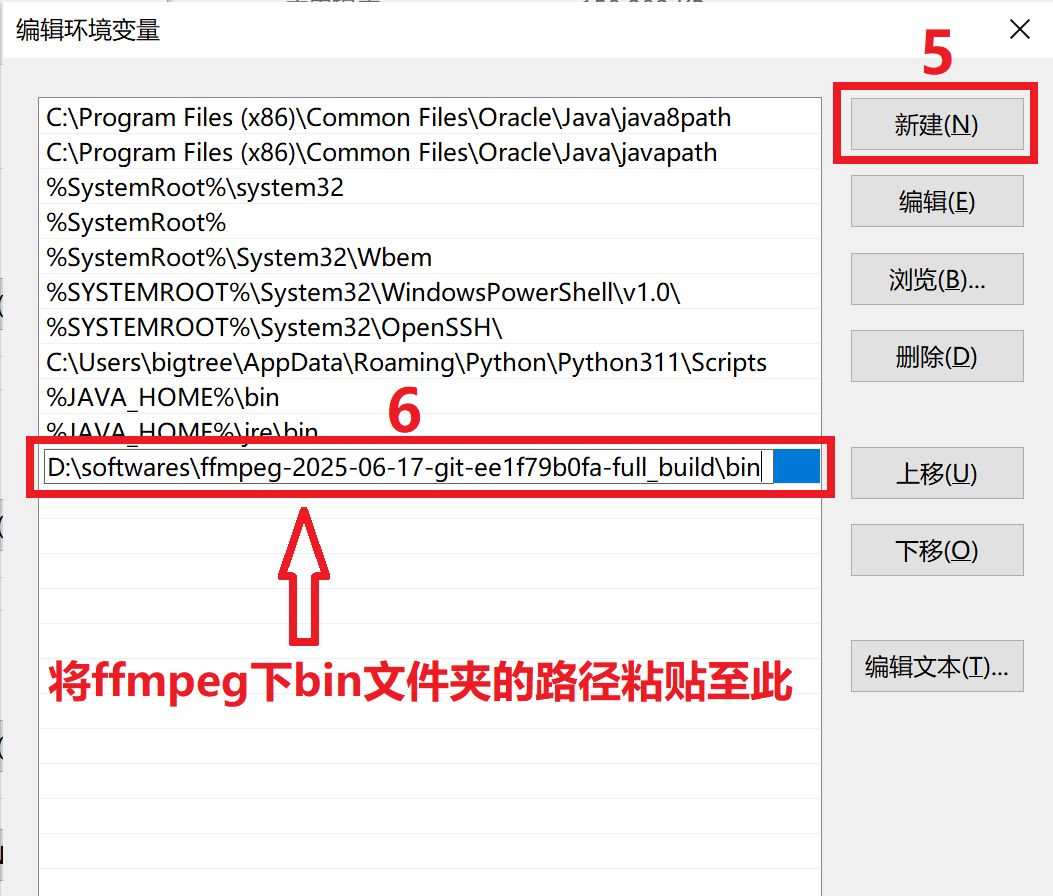
图6 把复制的路径写入系统变量
安装完毕后,可以通过以下cmd命令检查是否安装成功:
ffmpeg -version
使用方法:同时按住键盘上的“windows图标+字母R”,在弹出来的“运行”对话框中输入“cmd”,接着点击“确定”,打开cmd终端后,输入以上代码,按键盘上的回车即可。
5.deepseek编程提示词
本次提示词跟以往有所不同,以往目标直接,都是一步到位的。本案例我们调整一下策略,假设此前我们对视频自动转文本的方法一无所知,我们将通过询问deepseek来逐步找到解决方案。
(1)第一问
请问怎样将我本地电脑上的视频自动转写成文本?
deepseek给出了以下多种方法供参考:
1)使用专业视频转文本工具
Descript
支持导入视频后自动生成字幕/文本,编辑功能强大,适合专业用户。
官网:https://www.descript.com
Otter.ai
支持实时转录和视频文件上传,准确率高,适合会议记录或访谈视频。
官网:https://otter.ai
Rev.com
提供付费的精准转录服务(人工校对),适合对准确性要求高的场景。
官网:https://www.rev.com
2)通过语音识别软件(免费方案)
Whisper(OpenAI开源模型)
支持多语言,高准确率,可离线运行(需配置Python环境)。
地址:https://github.com/openai/whisper
Vosk
离线开源工具,支持多种语言,适合隐私敏感场景。
官网:https://alphacephei.com/vosk
3)利用在线服务(需上传视频)
腾讯云/阿里云语音识别
提供API接口,适合批量处理,需付费。
腾讯云文档:
https://cloud.tencent.com/product/asr
Google Cloud Speech-to-Text
高精度,支持长音频。
官网:https://cloud.google.com/speech-to-text
注意事项:
在线服务需上传视频到云端,隐私敏感内容慎用。
部分平台提供免费额度(如Google Cloud前60分钟免费)。
推荐方案总结
| 需求场景 | 推荐工具 |
|---|---|
| 高精度+专业编辑 | Descript、Rev.com |
| 免费+离线 | Whisper(Python) |
| 在线快速处理 | Otter.ai、腾讯云ASR |
| 批量自动化 | Vosk、Google Cloud API |
综合考虑费用和安全之后,我们从以上推荐中选取Whisper来转写字幕。
怎样进一步操作?接着问DeepSeek。
(2)第二问
请使用Python语言调用Whisper
接收到提示词后,deepseek会迅速生成Python代码调用Whisper。
在代码备注中可见对Whisper转写语言的要求,只需要修改language参数即可。
转写为英文language = ‘en’,转写为中文language = ‘zh’。
其他语种,俄日法德西依次为ru/ja/fr/de/es。
同时,字幕翻译也无需额外的代码,只需要改写语种参数即可。
调试、执行
将调用Whisper的代码粘贴进Jupyter Notebook,并运行代码(新读者可点击这里参见链接贴文中的“3.运行代码”,代码详见附录)。
运行结果及报错信息处理可参考图7中的说明。
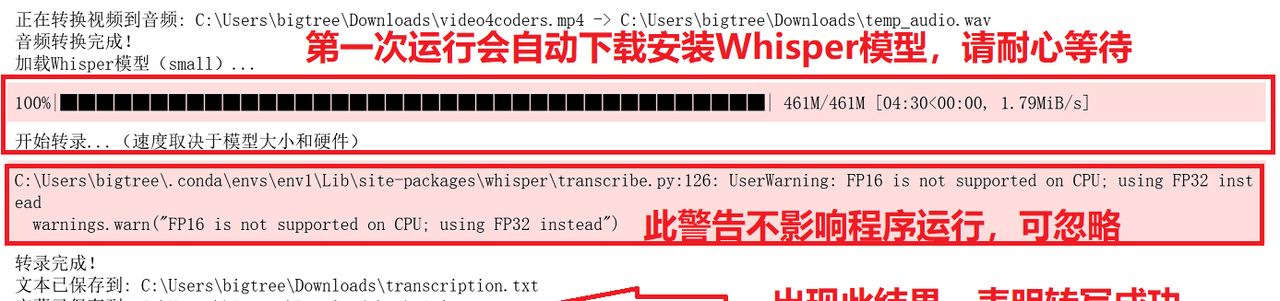
图7 运行状态及结果
(3)第三问
利用python怎样把转写的字幕自动上载到视频中去?
调试、执行
将调用Whisper的代码粘贴进Jupyter Notebook,并运行代码(新读者可点击这里参见链接贴文中的“3.运行代码”,代码详见附录)。
如果出现以下报错,则说明字幕文件的路径输入有误
Unable to parse option value "xxxxxxxx.srt" as image size
Error applying option 'original_size' to filter 'subtitles': Invalid argument
Error opening output file D:xxxxxx.mp4.
Error opening output files: Invalid argument
处理失败,请检查错误信息
该报错信息再次喂给deepseek反复出错,改用豆包、ChatGPT等其他AI模型,也无法给出正确答案,因此需要人工排障。经过审查发现,ffmpeg命令下的字幕文件路径有特殊的格式要求。否则,无法找到文件。假设我们的srt字幕文件存放在 D:字幕本案例字幕.srt 该路径在ffmpeg字幕路径中需要改成 subtitles = ‘D:/字幕/本案例字幕.srt’ 才能成功运行。
请注意:大家在使用本文附录的Python代码时,无需担心此问题,直接按照常规输入字幕的文件路径即可。因为我们已将自动修改程序写入了附录中的Python代码。
这里特别提出这一问题,是为了让大家从头做起遇到障碍时,能够快速地发现解决办法。
6.基础作业(人人应能够完成)
学会实际应用本案例调试的代码(具体代码见文末附录):1)能够先用音视频转写程序转写出字幕;2)能够人工检查、修改字幕中的错误;3)能够将修改后的高质量字幕上载到视频中去。
7.进阶作业(不强制)
本文初步测试发现Whisper不改变原文语种时的转写,正确率较高,改变语种时的转写虽然相当于完成了字幕翻译,但失误率较高。请尝试提出获得更高质量译文的解决办法。比如:1)尝试调用其他大语言模型把字幕再翻译一遍;2)探索视频字幕翻译质量测控方法;3)探索视频字幕翻译译后编辑策略。等等。
8.附录代码
为了便于编辑、修改字幕错误以及便于进行译后编辑,本文主体代码分成了两段,分别运行,第一段是字幕的转写和翻译(见8.1),第二段是编辑后的字幕上载(见8.2)。这样,对转写或翻译的质量不满意时,可以人工介入,然后再调用第二段代码上载处理后的优质字幕。此外,本节还附上音视频的其他常用操作,包括:音视频不同格式间的转换、提取音频、调整分辨率和码率(见8.3),以及“视频-图片”相互转换的方法(见8.4)。
8.1音视频字幕的自动转写及翻译(改变语种参数)
注意:本节代码的“字幕翻译”仅提供了“改变Whisper模型语种参数”这一种方案,其他方案,请根据进阶作业的提醒,自行探索。
(1)第一步先安装openai的whishper模型和pydub库
pip install openai-whisper pydub
(2)然后使用以下代码
import whisper
from pydub import AudioSegment
import os
import sys
def video_to_audio(video_path, audio_path=r"D: emp_audio.wav"):
"""将视频文件转换为音频文件(WAV格式)"""
try:
print(f"正在转换视频到音频: {
video_path} -> {
audio_path}")
audio = AudioSegment.from_file(video_path)
audio.export(audio_path, format="wav")
print("音频转换完成!")
return True
except Exception as e:
print(f"视频转换失败: {
e}")
return False
def transcribe_audio(audio_path, model_size="small", language="zh"):
"""使用Whisper转录音频文件"""
try:
print(f"加载Whisper模型({
model_size})...")
model = whisper.load_model(model_size)
print("开始转录...(速度取决于模型大小和硬件)")
result = model.transcribe(audio_path, language=language)
print("转录完成!")
return result
except Exception as e:
print(f"转录失败: {
e}")
return None
def save_results(result, txt_path="output.txt", srt_path=None):
"""保存转录结果到文本和字幕文件"""
try:
# 保存纯文本
with open(txt_path, "w", encoding="utf-8") as f:
f.write(result["text"])
print(f"文本已保存到: {
txt_path}")
# 保存字幕(如果指定路径)
if srt_path:
segments = result["segments"]
with open(srt_path, "w", encoding="utf-8") as f:
for i, seg in enumerate(segments, 1):
start = seg["start"]
end = seg["end"]
text = seg["text"]
f.write(f"{
i}
")
f.write(f"{
int(start//3600):02d}:{
int((start%3600)//60):02d}:{
start%60:.3f} --> "
f"{
int(end//3600):02d}:{
int((end%3600)//60):02d}:{
end%60:.3f}
")
f.write(f"{
text}
")
print(f"字幕已保存到: {
srt_path}")
return True
except Exception as e:
print(f"保存结果失败: {
e}")
return False
def clean_temp_files(audio_path):
"""清理临时音频文件"""
try:
if os.path.exists(audio_path):
os.remove(audio_path)
print(f"已清理临时文件: {
audio_path}")
except Exception as e:
print(f"清理临时文件失败: {
e}")
def main(video_path, model_size="small", language="zh",
txt_path="output.txt", srt_path="subtitle.srt", keep_audio=False):
"""
主函数:视频转文本全流程
参数:
video_path: 输入视频路径
model_size: Whisper模型大小(tiny/base/small/medium/large)
language: 语言代码(如"zh"中文,"en"英文)
txt_path: 文本输出路径
srt_path: 字幕输出路径(None则不生成)
keep_audio: 是否保留临时音频文件
"""
# 1. 视频转音频
audio_path = r"D: emp_audio.wav"
if not video_to_audio(video_path, audio_path):
return
# 2. 音频转录
result = transcribe_audio(audio_path, model_size, language)
if not result:
clean_temp_files(audio_path)
return
# 3. 保存结果
save_results(result, txt_path, srt_path)
# 4. 清理临时文件
if not keep_audio:
clean_temp_files(audio_path)
if __name__ == "__main__":
# 使用示例
video_path = r"这里填入你的视频路径" # 替换为你的视频路径字母r和引号保留
txt_path=os.path.join(os.path.dirname(video_path),os.path.splitext(os.path.split(video_path)[1])[0]+".txt")
srt_path=os.path.join(os.path.dirname(video_path),os.path.splitext(os.path.split(video_path)[1])[0]+".srt")
main(
video_path=video_path,
model_size="small", # 中文推荐small/medium
language="zh", #不改变原文语种转写结果正确率高,改变语种(如原文英文转录为中文),则正确率大大降低,需译后编辑
txt_path=txt_path,
srt_path=srt_path,
keep_audio=False
)
8.2视频字幕的自动上载
视频字幕有硬字幕和软字幕之分。软字幕有控制开关,字幕可显示或隐藏,但硬字幕无控制开关,只能一直显示。
(1)硬字幕上载(永久字幕)
运行以下代码后,需要稍等一会儿,成功后会出现“硬字幕烧录成功!”,“处理完成!”之类的提醒。
import subprocess
from pathlib import Path
import shlex
def embed_hard_subtitle(video_path, srt_path, output_path=None):
"""
烧录硬字幕到视频(永久嵌入,字幕颜色为黑色 + 白色描边)
"""
try:
video_path = Path(video_path).resolve()
srt_path = Path(srt_path).resolve()
output_path = Path(output_path).resolve() if output_path else video_path.with_name(video_path.stem + "_hardsub.mp4")
if not video_path.exists():
raise FileNotFoundError(f"视频文件不存在: {
video_path}")
if not srt_path.exists():
raise FileNotFoundError(f"字幕文件不存在: {
srt_path}")
srt_posix = srt_path.as_posix()
srt_posix = srt_posix.replace(':',':') # 非常重要,把字幕路径改为“D:/video2txt/video4test-zh.srt”的形式才能成功运行
print(srt_posix)
# 构建字幕滤镜字符串(无多余转义)
vf_filter = (
f"subtitles='{
srt_posix}':force_style="
f"'FontName=Microsoft YaHei,FontSize=24,"
f"PrimaryColour=&H000000&,OutlineColour=&HFFFFFF&,"
f"Outline=1,Shadow=0'"
)
cmd = [
'ffmpeg',
'-i', str(video_path),
'-vf', vf_filter, # 必须是字符串
'-c:v', 'libx264',
'-c:a', 'copy',
'-y',
str(output_path)
]
# 打印调试命令
print("执行命令:")
print(' '.join(shlex.quote(arg) for arg in cmd))
result = subprocess.run(cmd, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
print("硬字幕烧录成功!")
print(f"输出文件: {
output_path}")
return True
except subprocess.CalledProcessError as e:
print(f"FFmpeg 执行失败(错误码 {
e.returncode}):")
print("标准输出:", e.stdout)
print("错误输出:", e.stderr)
return False
except Exception as e:
print(f"其他错误: {
str(e)}")
return False
if __name__ == "__main__":
success = embed_hard_subtitle(
video_path=r"这里的汉字替换为你的视频路径",
srt_path=r"这里的汉字替换为你srt格式的字幕路径"
)
print("处理完成!" if success else "处理失败,请检查错误信息")
(2)软字幕上载(字幕可隐藏)
运行以下代码,成功后会出现“软字幕添加成功!”,“处理完成!播放时请开启字幕”之类的提醒。
#上载软字幕
import subprocess
from pathlib import Path
def embed_soft_subtitle(video_path, srt_path):
"""
使用FFmpeg添加软字幕(可开关的字幕轨道)
参数:
video_path: 输入视频路径(如 r"D:video2txtvideo4test-zh.mp4")
srt_path: 字幕文件路径(如 r"D:video2txtvideo4test-zh.srt")
返回:
bool: 是否成功
"""
try:
# 转换为绝对路径并标准化(确保路径存在)
video_path = Path(video_path).resolve()
srt_path = Path(srt_path).resolve()
output_path = video_path.with_name(video_path.stem + "_softsub.mp4")
# 检查输入文件是否存在
if not Path(video_path).exists():
raise FileNotFoundError(f"视频文件不存在: {
video_path}")
if not Path(srt_path).exists():
raise FileNotFoundError(f"字幕文件不存在: {
srt_path}")
# 构建FFmpeg命令(严格按您要求的格式)
cmd = [
'ffmpeg',
'-i', str(video_path), #输入的视频文件
'-i', str(srt_path), #输入的字幕文件
'-c','copy',
# '-c:v', 'copy', # 视频流直接复制
# '-c:a', 'copy', # 音频流直接复制
'-c:s', 'mov_text', # 字幕编码格式(适用于.mp4 格式)
# '-y', # 覆盖输出文件
str(output_path) #添加字幕后的视频文件
]
# 打印实际执行的命令(调试用)
print("执行命令:", ' '.join(cmd))
# 运行命令(捕获输出以便调试)
result = subprocess.run(cmd, check=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True)
print(f"软字幕添加成功!输出文件: {
output_path}")
return True
except subprocess.CalledProcessError as e:
print(f"FFmpeg执行失败(错误码 {
e.returncode}):")
print("错误输出:", e.stderr)
return False
except Exception as e:
print(f"其他错误: {
str(e)}")
return False
# 使用示例(直接调用您指定的路径)
if __name__ == "__main__":
success = embed_soft_subtitle(
video_path=r"这里填写你的视频文件路径", #不可删除引号和前面的字母r
srt_path=r"这里填写你的字幕文件路径" #不可删除引号和前面的字母r
)
if success:
print("处理完成!播放时请开启字幕")
print("开启方法:点击播放器左下角四方形字幕图标,根据提示选择srt字幕文件")
else:
print("处理失败,请检查错误信息")
8.3音视频格式转换
FFmpeg是一个强大的多媒体处理工具,Python可以通过subprocess模块调用FFmpeg命令行工具来进行音视频格式转换。以下是几种常见的音视频转换场景的实现方法。
(1)音视频格式基本转换函数
import subprocess
def convert_media(input_file, output_file, audio_codec=None, video_codec=None):
"""
基本音视频转换函数
:param input_file: 输入文件路径
:param output_file: 输出文件路径
:param audio_codec: 音频编码器 (如 'aac', 'mp3', 'libopus'等)
:param video_codec: 视频编码器 (如 'libx264', 'libvpx', 'h265'等)
"""
cmd = ['ffmpeg', '-i', input_file]
if video_codec:
cmd.extend(['-c:v', video_codec])
else:
cmd.extend(['-c:v', 'copy']) # 如果不指定视频编码器,则直接复制
if audio_codec:
cmd.extend(['-c:a', audio_codec])
else:
cmd.extend(['-c:a', 'copy']) # 如果不指定音频编码器,则直接复制
cmd.append(output_file)
try:
subprocess.run(cmd, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print(f"转换成功: {
input_file} -> {
output_file}")
except subprocess.CalledProcessError as e:
print(f"转换失败: {
e.stderr.decode('utf-8')}")
(2)常见转换场景
1)视频格式转换
def convert_video_format(input_file, output_file, output_format='mp4'):
"""
视频格式转换
:param input_file: 输入视频文件
:param output_file: 输出视频文件
:param output_format: 输出格式 (如 'mp4', 'avi', 'mov', 'mkv'等)
"""
if not output_file.endswith(output_format):
output_file = f"{
output_file.rsplit('.', 1)[0]}.{
output_format}"
# 对于MP4使用H.264编码,MOV使用原始编码
video_codec = 'libx264' if output_format == 'mp4' else 'copy'
convert_media(input_file, output_file, audio_codec='aac', video_codec=video_codec)
2)音频格式转换
def convert_audio_format(input_file, output_file, output_format='mp3'):
"""
音频格式转换
:param input_file: 输入音频文件
:param output_file: 输出音频文件
:param output_format: 输出格式 (如 'mp3', 'wav', 'aac', 'flac'等)
"""
if not output_file.endswith(output_format):
output_file = f"{
output_file.rsplit('.', 1)[0]}.{
output_format}"
audio_codec = {
'mp3': 'libmp3lame',
'wav': 'pcm_s16le',
'aac': 'aac',
'flac': 'flac',
'ogg': 'libvorbis'
}.get(output_format, 'copy')
convert_media(input_file, output_file, audio_codec=audio_codec, video_codec=None)
3)提取音频
def extract_audio(input_file, output_file, audio_format='mp3'):
"""
从视频中提取音频
:param input_file: 输入视频文件
:param output_file: 输出音频文件
:param audio_format: 输出音频格式
"""
if not output_file.endswith(audio_format):
output_file = f"{
output_file.rsplit('.', 1)[0]}.{
audio_format}"
audio_codec = {
'mp3': 'libmp3lame',
'wav': 'pcm_s16le',
'aac': 'aac',
'flac': 'flac'
}.get(audio_format, 'copy')
cmd = [
'ffmpeg',
'-i', input_file,
'-vn', # 禁用视频
'-c:a', audio_codec,
'-y', # 覆盖输出文件
output_file
]
try:
subprocess.run(cmd, check=True)
print(f"音频提取成功: {
input_file} -> {
output_file}")
except subprocess.CalledProcessError as e:
print(f"音频提取失败: {
e.stderr.decode('utf-8')}")
4)调整视频分辨率
def resize_video(input_file, output_file, width=None, height=None):
"""
调整视频分辨率
:param input_file: 输入视频文件
:param output_file: 输出视频文件
:param width: 目标宽度 (像素)
:param height: 目标高度 (像素)
"""
cmd = ['ffmpeg', '-i', input_file]
if width and height:
cmd.extend(['-vf', f'scale={
width}:{
height}'])
elif width:
cmd.extend(['-vf', f'scale={
width}:-1'])
elif height:
cmd.extend(['-vf', f'scale=-1:{
height}'])
cmd.extend(['-c:a', 'copy', output_file])
try:
subprocess.run(cmd, check=True)
print(f"分辨率调整成功: {
input_file} -> {
output_file}")
except subprocess.CalledProcessError as e:
print(f"分辨率调整失败: {
e.stderr.decode('utf-8')}")
5)调整视频码率
def change_video_bitrate(input_file, output_file, video_bitrate='2000k'):
"""
调整视频码率
:param input_file: 输入视频文件
:param output_file: 输出视频文件
:param video_bitrate: 目标视频码率 (如 '2000k', '1M'等)
"""
cmd = [
'ffmpeg',
'-i', input_file,
'-b:v', video_bitrate,
'-c:a', 'copy',
output_file
]
try:
subprocess.run(cmd, check=True)
print(f"码率调整成功: {
input_file} -> {
output_file}")
except subprocess.CalledProcessError as e:
print(f"码率调整失败: {
e.stderr.decode('utf-8')}")
6)使用示例
if __name__ == "__main__":
# 视频格式转换示例
convert_video_format('input.avi', 'output.mp4')
# 音频格式转换示例
convert_audio_format('input.wav', 'output.mp3')
# 提取音频示例
extract_audio('input.mp4', 'output.mp3')
# 调整分辨率示例
resize_video('input.mp4', 'output_resized.mp4', width=640, height=480)
# 调整码率示例
change_video_bitrate('input.mp4', 'output_low_bitrate.mp4', '1000k')
(3)高级用法
1)添加进度条
可以使用ffmpeg-progress-yield库来获取转换进度:
from ffmpeg_progress_yield import FfmpegProgress
def convert_with_progress(input_file, output_file):
cmd = [
'ffmpeg',
'-i', input_file,
'-c:v', 'libx264',
'-c:a', 'aac',
output_file
]
ff = FfmpegProgress(cmd)
for progress in ff.run_command_with_progress():
print(f"转换进度: {
progress}%")
2)批量转换
import os
def batch_convert(input_folder, output_folder, output_format='mp4'):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for filename in os.listdir(input_folder):
if filename.lower().endswith(('.mp4', '.avi', '.mov', '.mkv')):
input_file = os.path.join(input_folder, filename)
output_file = os.path.join(output_folder, f"{
os.path.splitext(filename)[0]}.{
output_format}")
convert_video_format(input_file, output_file, output_format)
(4)注意事项
FFmpeg命令参数顺序很重要,错误的顺序可能导致意外结果
对于生产环境,建议添加更多的错误处理和日志记录
某些编码器可能需要额外的参数或特定的FFmpeg编译选项
处理大型文件时,考虑内存和CPU使用情况
以上代码提供了Python调用FFmpeg进行音视频格式转换的基本框架,可以根据实际需求进行修改和扩展。
8.4视频-图片互转
下面介绍如何使用Python调用FFmpeg实现视频转图片序列(视频拆帧)和图片序列转视频的功能。
(1)视频转图片序列(拆帧)
1)基本功能实现
import subprocess
import os
def video_to_images(input_video, output_folder, frame_rate=None, image_format='jpg', quality=None):
"""
将视频转换为图片序列
:param input_video: 输入视频文件路径
:param output_folder: 输出图片保存目录
:param frame_rate: 提取帧率 (如 '1'表示每秒1帧,'1/5'表示每5秒1帧)
:param image_format: 图片格式 (jpg/png等)
:param quality: 图片质量 (1-31对于jpg,1表示最高质量)
"""
if not os.path.exists(output_folder):
os.makedirs(output_folder)
output_pattern = os.path.join(output_folder, f"frame_%05d.{
image_format}")
cmd = ['ffmpeg', '-i', input_video]
if frame_rate:
cmd.extend(['-r', str(frame_rate)])
if image_format.lower() == 'jpg' and quality:
cmd.extend(['-qscale:v', str(quality)])
elif image_format.lower() == 'png':
# PNG默认是无损压缩
pass
cmd.extend(['-f', 'image2', output_pattern])
try:
subprocess.run(cmd, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print(f"视频拆帧成功: {
input_video} -> {
output_folder}")
except subprocess.CalledProcessError as e:
print(f"视频拆帧失败: {
e.stderr.decode('utf-8')}")
2)使用示例
# 提取视频所有帧
video_to_images('input.mp4', 'output_frames', image_format='png')
# 每秒提取1帧
video_to_images('input.mp4', 'output_frames_1fps', frame_rate=1, image_format='jpg', quality=2)
# 每5秒提取1帧
video_to_images('input.mp4', 'output_frames_5s', frame_rate='1/5', image_format='jpg')
(2)图片序列转视频
1)基本功能实现
def images_to_video(input_folder, output_video, frame_rate=24, image_format='jpg',
video_codec='libx264', crf=23, preset='medium', pix_fmt='yuv420p'):
"""
将图片序列转换为视频
:param input_folder: 包含图片序列的目录
:param output_video: 输出视频文件路径
:param frame_rate: 输出视频帧率
:param image_format: 输入图片格式
:param video_codec: 视频编码器
:param crf: 质量参数 (0-51,越小质量越高)
:param preset: 编码速度与压缩率的平衡 (ultrafast, superfast, veryfast, faster, fast, medium, slow, slower, veryslow)
:param pix_fmt: 像素格式
"""
input_pattern = os.path.join(input_folder, f"*.{
image_format}")
cmd = [
'ffmpeg',
'-framerate', str(frame_rate),
'-pattern_type', 'glob',
'-i', input_pattern,
'-c:v', video_codec,
'-crf', str(crf),
'-preset', preset,
'-pix_fmt', pix_fmt,
'-y', # 覆盖输出文件
output_video
]
try:
subprocess.run(cmd, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print(f"图片合成视频成功: {
input_folder} -> {
output_video}")
except subprocess.CalledProcessError as e:
print(f"图片合成视频失败: {
e.stderr.decode('utf-8')}")
2)使用示例
# 将PNG图片序列转为视频
images_to_video('input_frames', 'output.mp4', frame_rate=30, image_format='png')
# 高质量H.265编码
images_to_video('input_frames', 'output_h265.mp4', video_codec='libx265', crf=18)
# 快速编码但文件较大
images_to_video('input_frames', 'output_fast.mp4', preset='ultrafast')
(3)高级功能
1)提取特定时间段的帧
def extract_frames_by_time(input_video, output_folder, start_time=None, duration=None, frame_rate=None):
"""
提取视频特定时间段的帧
:param start_time: 开始时间 (格式: HH:MM:SS 或 秒数)
:param duration: 持续时间 (格式同上)
"""
if not os.path.exists(output_folder):
os.makedirs(output_folder)
output_pattern = os.path.join(output_folder, "frame_%05d.jpg")
cmd = ['ffmpeg']
if start_time:
cmd.extend(['-ss', str(start_time)])
if duration:
cmd.extend(['-t', str(duration)])
cmd.extend(['-i', input_video])
if frame_rate:
cmd.extend(['-r', str(frame_rate)])
cmd.extend(['-f', 'image2', output_pattern])
try:
subprocess.run(cmd, check=True)
print(f"成功提取时间段帧: {
start_time} - {
duration} -> {
output_folder}")
except subprocess.CalledProcessError as e:
print(f"提取失败: {
e.stderr.decode('utf-8')}")
2)创建延时摄影视频
def create_timelapse(input_folder, output_video, input_frame_rate=1, output_frame_rate=24):
"""
创建延时摄影视频
:param input_frame_rate: 输入图片的帧率 (如每张图片代表1秒)
:param output_frame_rate: 输出视频的帧率
"""
input_pattern = os.path.join(input_folder, "*.jpg")
cmd = [
'ffmpeg',
'-framerate', str(input_frame_rate),
'-pattern_type', 'glob',
'-i', input_pattern,
'-c:v', 'libx264',
'-r', str(output_frame_rate),
'-pix_fmt', 'yuv420p',
'-y',
output_video
]
try:
subprocess.run(cmd, check=True)
print(f"延时摄影视频创建成功: {
output_video}")
except subprocess.CalledProcessError as e:
print(f"创建失败: {
e.stderr.decode('utf-8')}")
3)添加音频到图片生成的视频
def add_audio_to_slideshow(image_folder, audio_file, output_video, duration_per_image=5):
"""
为图片生成的视频添加音频
:param duration_per_image: 每张图片显示的秒数
"""
input_pattern = os.path.join(image_folder, "*.jpg")
# 首先计算需要的帧率
frame_rate = 1 / duration_per_image
cmd = [
'ffmpeg',
'-framerate', str(frame_rate),
'-pattern_type', 'glob',
'-i', input_pattern,
'-i', audio_file,
'-c:v', 'libx264',
'-r', '30', # 输出视频帧率
'-pix_fmt', 'yuv420p',
'-shortest', # 以音频长度为准
'-y',
output_video
]
try:
subprocess.run(cmd, check=True)
print(f"成功创建带音频的幻灯片视频: {
output_video}")
except subprocess.CalledProcessError as e:
print(f"创建失败: {
e.stderr.decode('utf-8')}")
(4)综合使用示例
if __name__ == "__main__":
# 1. 提取视频中的关键帧
video_to_images('wedding.mp4', 'wedding_frames', frame_rate='1/5', image_format='jpg', quality=2)
# 2. 从提取的帧创建延时摄影
create_timelapse('wedding_frames', 'wedding_timelapse.mp4', input_frame_rate=5, output_frame_rate=30)
# 3. 为延时摄影添加背景音乐
add_audio_to_slideshow('wedding_frames', 'background_music.mp3', 'wedding_timelapse_with_music.mp4', duration_per_image=0.5)
# 4. 提取视频前10秒的帧
extract_frames_by_time('wedding.mp4', 'wedding_first_10s', start_time=0, duration=10, frame_rate=1)
(5)注意事项
文件名顺序:图片序列转视频时,确保文件名按顺序排列(如frame_00001.jpg, frame_00002.jpg)
图片格式:
JPEG是有损压缩,适合存储空间有限的情况
PNG是无损压缩,适合需要高质量帧的情况
性能考虑:
处理高分辨率视频时可能需要大量磁盘空间
可以调整-preset参数平衡编码速度和质量
像素格式:大多数播放器需要yuv420p像素格式,这是默认值
错误处理:实际应用中应添加更完善的错误处理和日志记录
这些功能组合使用可以实现视频编辑、分析、延时摄影等多种应用场景。根据具体需求调整参数即可获得最佳效果。
**
欢迎转发,引用、转载、改写请注明出处,谢谢!
**






















暂无评论内容