

在计算机程序运行的复杂世界中,内存管理无疑是核心且神秘的环节。本文将深入探讨计算机内存管理的奥秘,解析内存如何支撑程序的顺利运行。
一、内存管理的核心谜题
在之前的探讨中,内存读写的相关描述总是略显模糊。例如,ELF文件明确指定了数据加载的特定内存地址,但为何不同进程使用一样的内存地址却不会引发冲突?每个进程仿佛置身于独立的内存环境,这究竟是如何实现的?
再者,程序的启动过程也迷雾重重。我们已知execve系统调用会替换当前进程,但并未详细说明多个进程的启动过程,更无法解释计算机启动后首个程序的运行方式。这些谜题等待我们一一破解。
解开这些谜题,有助于我们完整地勾勒出计算机从开机到运行各类软件的全过程,深入理解计算机底层运行机制的核心环节。
二、虚拟内存:内存管理的基石
现代计算机内存管理的基石是虚拟内存。CPU执行读写内存操作时,并非直接与物理内存(RAM)交互,而是面向虚拟内存空间。
CPU与内存管理单元(MMU)协同工作,MMU如同一位精通多语言的翻译官,依据页表将虚拟内存地址转换为物理内存地址。例如,当CPU接收到从虚拟内存地址0xfffaf54834067fe2读取数据的指令时,会请求MMU进行地址转换。MMU在页表中查找匹配项,确定对应的物理地址为0x53a4b64a90179fe2,然后反馈给CPU。
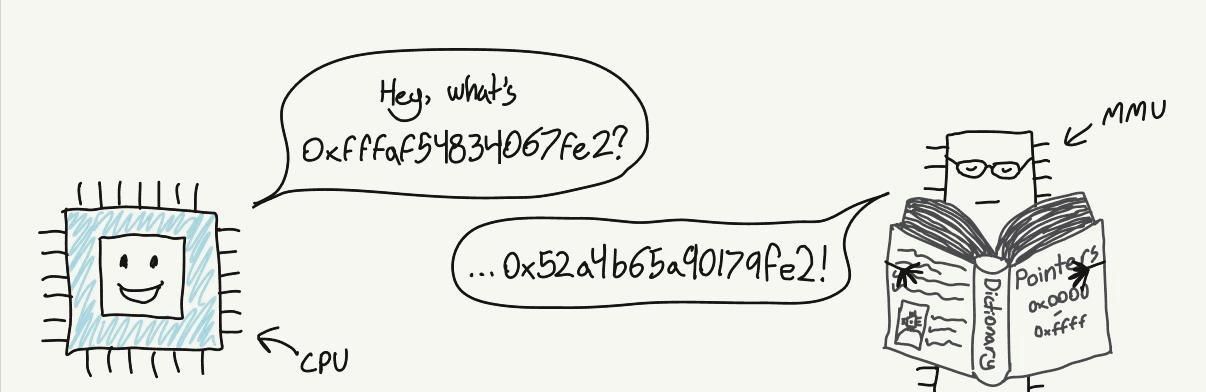
计算机开机时,内存访问直接指向物理RAM。但系统启动完成后,操作系统迅速构建页表,并指示CPU启用MMU,开启虚拟内存与物理内存之间的转换。
页表的基本单元是页,每个页代表虚拟内存特定块与物理内存的映射关系。不同处理器架构的页大小各异,x86-64架构的默认页大小为4KiB(4096字节)。这意味着每个页详细规定了长度为4096字节的虚拟内存块在物理内存中的映射位置。在4KiB页大小的设定下,虚拟内存地址的低12位在MMU转换前后保持一致。
x86-64架构还具备启用更大页(如2MiB或4GiB)的能力,以提升地址转换速度,但可能增加内存碎片和浪费空间的风险。

页表存储于RAM中,每个条目大小通常在几个字节级别,不会占用过多内存空间。在x86-64架构中,开机时内核在RAM内构建页表,将页表起始物理地址存入页表基址寄存器(PTBR,即控制寄存器3的高20位),并将控制寄存器0的第31位(PG,用于分页)设置为1,激活分页机制。
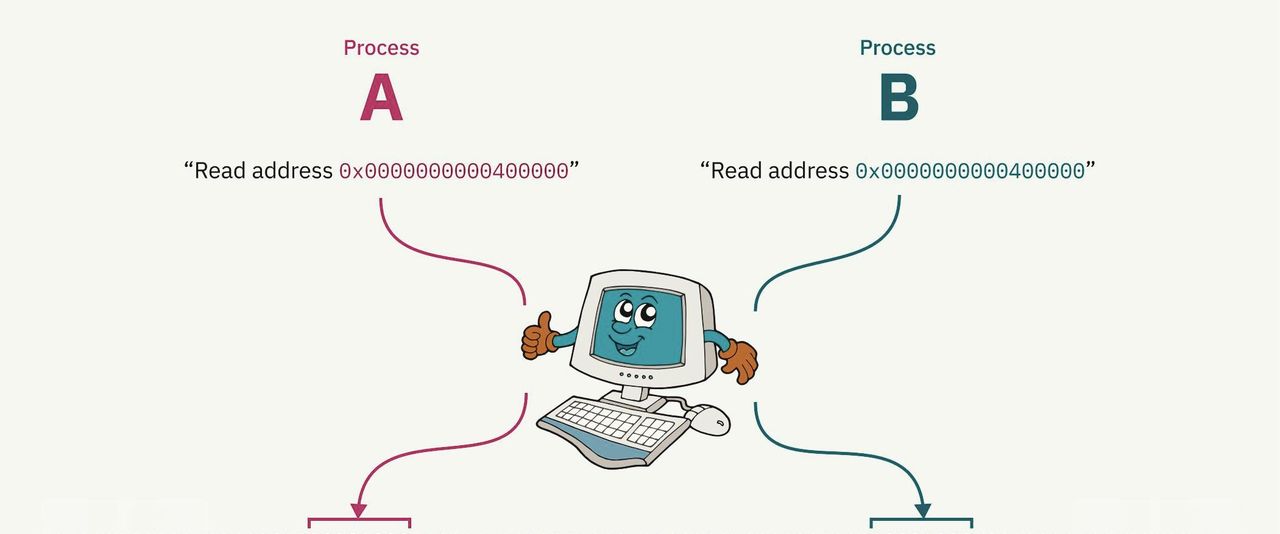
分页系统的动态性为进程隔离提供了坚实基础。操作系统在不同进程间进行上下文切换时,会重新映射虚拟内存空间,使其指向物理内存中的不同区域。例如,进程 A 和进程 B 可能都将代码和数据映射到虚拟内存地址 0x0000000000400000,但实际上它们在物理内存中的数据存储位置相隔甚远。内核在切换到相应进程时,会巧妙地构建映射关系,确保每个进程都仿佛拥有独立的内存空间,彼此互不干扰。
binfmt_elf在某些特殊场景下需要特殊内存映射。例如,为早期UNIX System V Release 4.0(SVr4)编写的程序依赖于空指针可读的特性,一些程序至今仍延续这种依赖。因此,binfmt_elf必须将内存的第一页映射为零,以确保这类程序的正常运行。这一设计曾让Linux内核开发者颇感困扰。
三、分页机制下的安全性保障
内存分页机制不仅实现了进程隔离,提升了程序编写与运行的便利性,更为系统安全筑牢了防线。进程之间无法访问彼此的内存空间,这解答了开篇的疑问:为何程序不能直接访问其他进程或内核的内存?
内核内存的管理与保护同样重大。内核存储大量数据,用于跟踪系统中所有运行的进程和管理页表等关键信息。每当硬件中断、软件中断或系统调用触发时,CPU切换至内核模式,内核代码必须能够访问这些内存数据。
Linux采用独特的内存布局策略,将虚拟内存空间的上半部分分配给内核,即“上半区内核”设计。Windows也运用类似理念,而macOS的内存管理架构更为复杂。

分页机制还引入了权限标志,每个页表条目都附带权限信息,包括读写权限和访问模式限制。通过设置特定标志,内核有效保护其内存空间。用户态进程因缺乏权限而无法访问内核空间,确保了内核空间的安全性与独立性。
页表本身存储于内核内存空间。当定时器芯片触发进程切换的硬件中断时,CPU切换至特权级别(内核模式),获得访问内核保护内存区域的权限,对页表进行写入操作,为新进程重新映射虚拟内存的下半部分。一旦内核完成进程切换且CPU恢复用户模式,它便立即失去对内核内存的访问权限。
几乎所有的内存访问都要经过MMU,包括中断描述符表的处理程序指针,这进一步体现了分页机制在内存管理与系统运行中的核心地位。
四、多级分页与优化策略
随着计算机技术迈向64位时代,内存地址长度扩展至64位,理论上64位虚拟内存空间的容量高达16艾字节(exbibyte)。不过,这一数字远超当前及未来短期内计算机实际能配备的内存容量。
若按照每4KiB虚拟内存部分对应一个页表条目的方式构建页表,所需的页表条目数量将极其庞大,所需内存远超现有计算机的内存容量。因此,CPU架构引入了多级分页机制。
在多级分页系统中,存在多个层级的页表,且各级页表的粒度逐渐细化。顶层页表条目覆盖较大的内存块,并指向粒度更小的下一级页表,依此类推,形成树形结构。叶节点条目用于实际内存映射。
x86-64架构历史上采用4级多级分页,通过地址的特定部分作为偏移量来查找页表条目。多级分页机制有效解决了页表空间占用过大的问题,提高了地址查找的效率,增强了页表管理的灵活性与安全性。
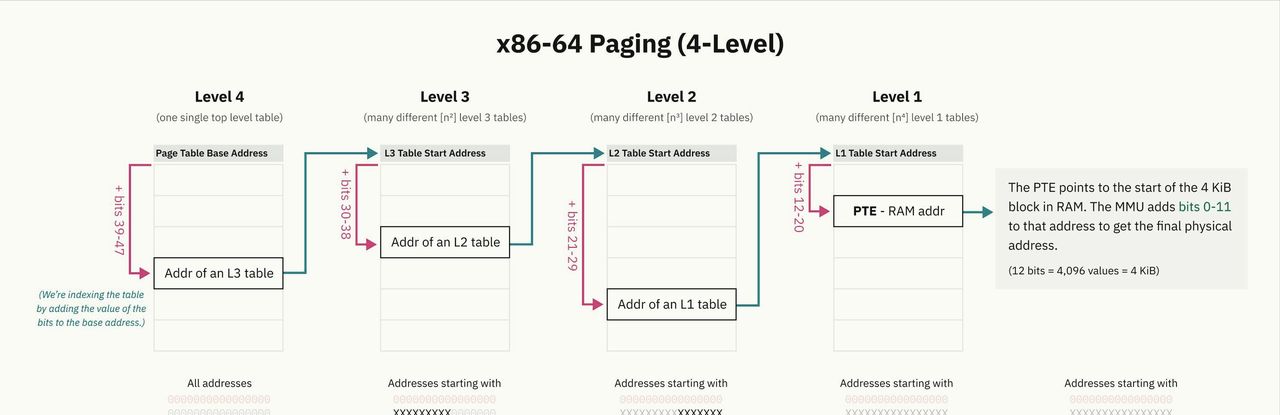
x86-64架构近期引入了5级分页机制,增加了一层间接寻址,提供了额外的寻址位,将地址空间扩展到128拍字节(PiB)。自2017年起,包括Linux在内的众多操作系统以及Windows 10和11的服务器版本都已支持5级分页。
在物理地址空间方面,x86-64 CPU实际使用的物理地址位数少于64位。在4级分页时,物理地址不超过46位,对应64太字节(TiB)的空间。随着5级分页的应用,物理地址位数扩展到52位,支持4拍字节(PiB)的空间。保持虚拟地址空间大于物理地址空间具有显著优势,为操作系统提供更丰富的内存管理策略与灵活性。
五、交换与按需分页技术
在内存访问过程中,可能会因多种缘由导致访问失败,如地址超出合法范围、未被页表映射或页表条目被标记为不存在。在这些情况下,MMU会触发缺页中断,将问题转交给内核处理。
当内存访问被判定为无效或禁止时,内核通常会以段错误为由终止相关程序的运行。不过,在某些场景下,内存访问的失败是有意为之,这涉及到按需分页技术。

操作系统可以将磁盘上的文件映射到虚拟内存中,但并不立即加载到物理内存(RAM)里。当CPU首次尝试访问该映射地址并引发缺页中断时,内核会将对应的文件数据从磁盘加载到物理内存中,实现数据的按需加载。
按需分页机制为系统带来了显著的灵活性与效率提升,支撑了诸如mmap等系统调用,使得将磁盘文件惰性地映射到虚拟内存成为可能。
按需分页技术还衍生出了“交换”(swapping)或“分页”(paging)技术。操作系统可以将暂时不使用的内存页面写入磁盘,然后从物理内存中移除它们(在虚拟内存中保留记录,将存在标志设为0),释放物理内存资源。当后续需要读取该虚拟内存时,操作系统再从磁盘将数据恢复到RAM中,并将存在标志重新设为1。
如果物理内存空间不足,操作系统可能需要选择将其他部分的内存页面交换到磁盘,为即将加载的内存腾出空间。由于磁盘读写速度较慢,操作系统会采用高效的页面置换算法来减少交换操作的发生频率,平衡内存使用与系统性能之间的关系。
在某些情况下,还可以利用页表的物理内存指针来存储物理存储中文件的位置信息。由于MMU检测到存在标志为负时会触发缺页中断,这些无效的内存地址不会对系统正常运行造成影响。这种做法展示了内存管理机制中的巧妙设计与灵活性。
结语
通过对计算机内存管理中虚拟内存、分页机制、多级分页、交换与按需分页等核心技术的深入剖析,我们揭开了计算机内存管理的神秘面纱。这些技术相互协作,共同构建了一个稳定、高效且安全的内存管理体系,为计算机系统流畅运行各类复杂软件提供了坚实基础。无论是对于计算机系统开发者还是普通技术爱好者,这些深入探究都具有重大意义与价值。
专栏
微服务治理指南
作者:SuperOps
14.99币
53人已购
查看










- 最新
- 最热
只看作者