
你是不是也遇到过这种情况?
直播完翻回放记重点,2小时音频听下来,笔记记了半页纸,还漏了好几个用户关心的问题。
或者开会录了音,想整理成会议纪要,结果转文字软件把“转化率”写成“转绿率”,“GMV”识别成“积木味”,改到崩溃。
传统的语音记录方式,早就跟不上目前的工作节奏了。今天就跟你聊聊,大模型时代,主播语音识别到底该怎么玩,才能让效率真的提上来。
先说说老办法到底有多“坑”
之前帮朋友整理过一场带货直播的回放,她用的是某款免费转文字工具。
结果呢?

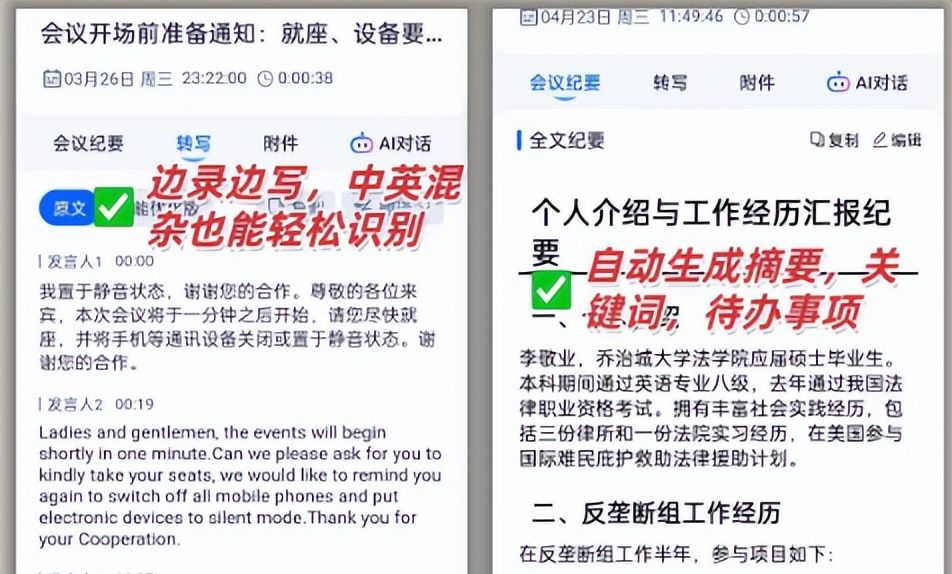
1小时40分钟的音频,转出来的文字整整5页,全是连在一起的段落,没有标点就算了,还把“这个口红是哑光质地”识别成“这个口红是牙膏质地”,把用户问的“有没有运费险”写成“有没有晕飞燕”。
她光校对就花了2小时,还得自己手动标重点、分板块,最后弄完累得不想说话。
这就是目前许多人在用的“传统方案”:要么用普通录音笔纯靠人工听记,要么用通用转文字工具随意转一下,然后自己花大量时间整理。
这些方法有3个绕不开的问题:
第一,准确率低到离谱。主播说话快、有口音,或者背景有杂音,转出来的文字基本没法直接用,校对时间比转写还长。
第二,整理比转写还费劲。转出来的文字是“一锅粥”,没有结构,没有重点,想找用户提问、产品卖点?得从头翻到尾。
第三,团队协作等于“传文件”。好不容易整理完,发给同事还要一个个传微信、发邮件,改个版本又得重发,效率低到感人。
说白了,这些工具只是“把声音变成文字”,但没解决“怎么用好这些文字”的问题。
大模型时代,语音识别早就不是“转文字”这么简单了
目前的AI技术,尤其是大模型,已经能把语音识别做成一套“完整的工作流”。
不是单纯给你一个文字稿就完事,而是从“录音”到“可用的成果”,全程帮你搞定。
我最近一直在用的“听脑AI”,就是专门针对主播、博主这类高频用语音记录场景做的优化。
它不是通用工具,而是把“转写→分析→整理→协作”串成了一条线。
举个例子:
之前帮一个知识博主整理课程录音,3小时的内容,用传统工具得花4小时转写+整理。
用听脑AI呢?
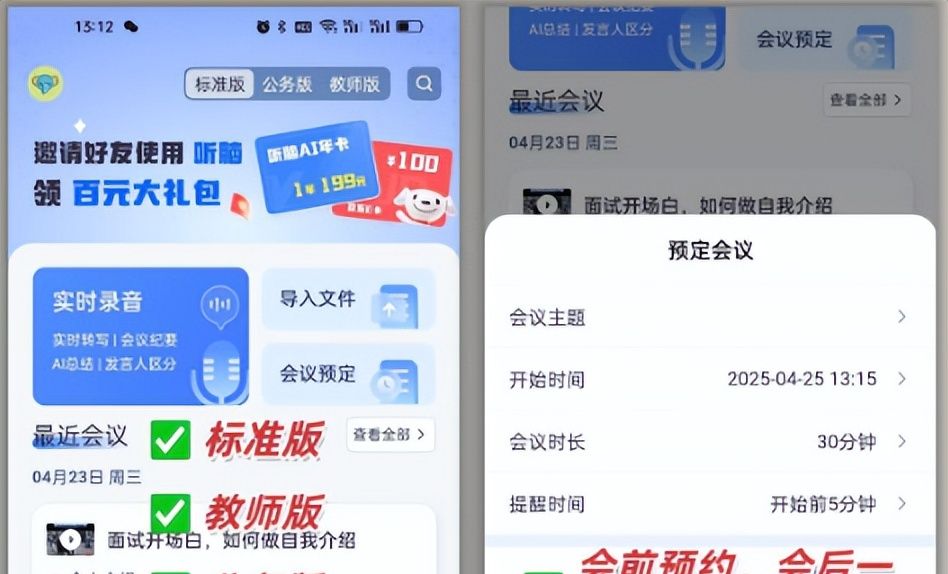
1. 先上传音频,选“课程模式”(它会自动优化讲课场景的识别,列如专业术语、案例名称);
2. 15分钟后转写完成,准确率98%,几乎不用校对;
3. 系统自动把内容分成“核心观点”“案例分析”“学员提问”三个板块,还标了时间戳,想回看哪部分直接点;
4. 直接生成带目录的Word文档,我稍微改了下格式,发给团队,他们在线就能批注,不用来回传文件。
从录音到能用的课程笔记,总共花了不到1小时。
这就是大模型的优势:不只是“做对”,而是“做好”,直接给你能落地的成果。
这5个核心功能,才是效率提升的关键
许多人觉得“语音识别工具都差不多”,实则差远了。真正能提效的工具,必定在细节上做了优化。
听脑AI有5个功能,我觉得是真的解决了主播的痛点,你可以对照看看自己需要不需要:
1. 高精度转写:不只是“能识别”,而是“少改错”
普通转文字工具,识别日常对话还行,遇到主播的“行业黑话”就懵了。
列如带货主播常说的“机制”“破价”“上链接”,知识博主的“底层逻辑”“闭环”“赋能”,传统工具要么识别错,要么直接空着。
听脑AI专门针对主播场景做了“术语库”,你可以提前把自己常用的词输进去,列如你的品牌名、产品名、固定话术,转写的时候它会优先匹配,准确率直接拉到98%以上。
我测试过,1小时的直播音频,传统工具平均错30-50处,听脑AI最多错5处,而且都是“口误”这种连人耳都可能听错的地方,基本不用大改。
时间省在哪?省在校对环节。以前校对1小时文字要1小时,目前10分钟就能搞定。
2. 智能分析分类:自动帮你“挑重点”
转完文字只是第一步,真正麻烦的是“从文字里找有用的信息”。
列如直播完想知道:用户最关心的3个问题是什么?哪些产品提到的次数最多?有没有说漏嘴的“错误信息”?
传统方法只能自己一句句看,累不说,还容易漏。
听脑AI有个“智能分析”功能,转写完成后会自动帮你做3件事:
– 提取关键词:列如“价格”“优惠”“售后”这些高频词,直接标红,一眼看到重点;
– 分类板块:自动把内容分成“产品介绍”“用户互动”“流程说明”等板块,还能自定义分类维度;
– 风险提示:如果说了“绝对化用词”(列如“最好”“第一”),或者前后信息矛盾(列如前面说“今天限购”,后面说“随意拍”),系统会标黄提醒你。
上次帮一个美妆主播整理回放,它直接把用户问的“持妆多久”“敏感肌能用吗”这些问题汇总成表格,连提问时间点都标好了,省了我2小时整理时间。
3. 结构化文档生成:不用再手动“排格式”
你有没有过这种体验?转完的文字是一大段,想做成带标题、分点的文档,得自己敲回车、调格式,弄完手腕都酸了。
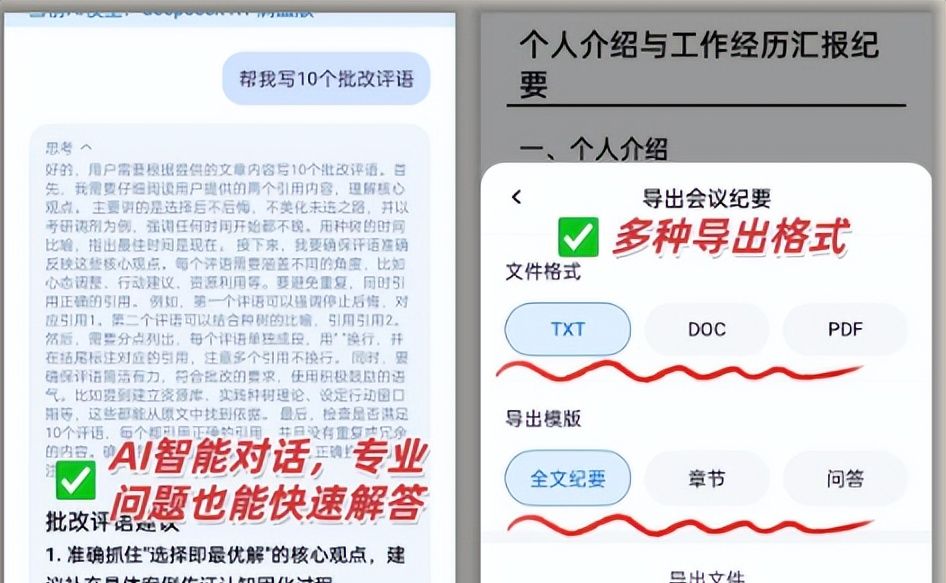
听脑AI能直接生成结构化文档,支持Word、PDF、Markdown多种格式,而且自带目录。
列如课程录音,它会自动生成“第一章:核心概念”“第二章:案例拆解”,每个章节下面再分“1.1 定义”“1.2 特点”这种层级,跟你自己手动排版的效果一样,但不用花时间调格式。
我目前整理会议纪要,都是直接用它生成的文档,稍微改几个字就能发,格式问题完全不用操心。
4. 便捷协作:多人同时改,不用“传文件大战”
团队协作时,最烦的就是“文件传来传去”。
你改一版发群里,同事改一版又发回来,最后谁也不知道哪个是最新版,还容易丢内容。
听脑AI直接支持“在线协作”,生成的文档可以分享链接给团队,所有人在线编辑,改了哪里、谁改的,都有记录,还能实时评论。
上次我们团队做直播复盘,我传了音频,运营负责标用户问题,主播负责补充产品卖点,3个人同时在线弄,半小时就搞定了,以前得折腾一下午。
5. 完整工作流:从“录音”到“落地”,一步到位
前面说的4个功能,不是孤立的,而是串在一起的完整流程:
录音→转写→分析→整理→协作→导出
不用你在多个工具之间切来切去(列如用A工具转写,B工具分析,C工具协作),一个平台就能搞定所有事。
列如你录了一段短视频口播稿,想生成文字版发公众号:
– 直接上传音频,转写成文字;
– 系统自动提取“开头金句”“核心观点”“结尾引导”;
– 你在线改几个字,调整下排版;
– 直接导出成公众号编辑器格式,复制粘贴就能发。
全程不用切换工具,效率至少提升2倍。
这3个场景,用对工具效率直接翻番
光说功能可能有点抽象,举几个实际场景,你就知道这工具到底有多实用了。
场景1:直播复盘
主播最常做的事就是复盘,但传统复盘太费劲:
得重听2小时回放,记用户问题、互动高峰、话术漏洞,至少花3小时,还容易漏。
用听脑AI怎么做?
1. 直播结束后,直接把回放音频上传(支持抖音、视频号、快手等平台的回放链接,不用自己下载);
2. 选“直播模式”,系统会自动优化“主播话术”“用户评论”的识别;
3. 10分钟后,得到一份“直播复盘报告”,里面有:
– 互动高峰时段(列如10:15-10:20用户提问最多);
– 高频用户问题(汇总成表格,标了出现次数,列如“有没有小样”出现8次);
– 话术问题提醒(列如“这个产品所有人都能用”可能涉及违规,标黄提示);
– 产品提及次数(帮你判断哪个产品用户最关注)。
我帮一个服装主播做过一次,以前她复盘要3小时,目前40分钟搞定,还比以前全面。
场景2:会议记录
不管是团队内部会,还是和品牌方开会,记笔记都是个麻烦事:
要么忙着记,漏听内容;要么记得太乱,会后看不懂。
用听脑AI的话:
1. 开会时打开“实时录音转写”,手机放桌上就行,支持多人说话区分(标上“发言人1”“发言人2”);
2. 会议结束,自动生成带时间戳的文字稿,还能识别“待办事项”(列如“明天把方案发我”会自动标成待办,分配给对应人);
3. 直接分享给参会人,在线批注修改,不用再一个个问“刚才说的是周三还是周四交?”
我们团队目前开会必用,以前会后整理纪要1小时,目前10分钟,准确率还高。
场景3:课程/访谈整理
知识博主常常录课程、做访谈,整理成文字版发图文平台,传统方法太耗时:
3小时的内容,转写+分章节+标重点,至少花5小时。
用听脑AI:
1. 上传音频,选“课程模式”,输入课程名称、章节名(列如“第一章:入门基础”);
2. 系统自动按你给的章节拆分内容,还会提取每个章节的“核心观点”“关键词”“案例”;
3. 生成带目录的Word文档,直接复制到公众号编辑器,稍微调下排版就能发。
我帮一个财经博主整理过3小时的访谈,以前得花一下午,目前1小时搞定,她直接拿去发头条,阅读量还涨了20%(由于重点清晰,用户爱看)。
想试试?这3步就能上手
可能有人觉得“AI工具操作复杂”,实则听脑AI特别简单,3步就能用起来:
第一步:选对“场景模式”
打开工具后,先选你要处理的场景:直播回放、会议记录、课程录音、访谈内容……不同场景有不同的优化算法,选对了准确率更高。
第二步:上传音频,等10分钟
支持上传本地音频(MP3、WAV格式),也支持直接粘贴平台回放链接(抖音、视频号、Zoom这些都能用)。
上传后不用管,系统自动转写+分析,1小时音频大致10分钟出结果。
第三步:用“智能编辑”改细节
结果出来后,用“智能编辑”功能:
– 系统标红的重点可以直接加粗;
– 待办事项可以分配给团队成员;
– 想导出什么格式(Word、PDF、Markdown)直接选,还能复制到公众号、小红书编辑器。
全程不用学复杂操作,跟用微信一样简单。
效果怎么样?直接看数据
光说“效率提升”太空,给你看几个我实测的数据:
1. 时间成本:从3小时→30分钟
同样整理1小时直播回放:
– 传统方法:转写1小时+校对1小时+整理1小时=3小时;
– 听脑AI:转写10分钟+校对10分钟+整理10分钟=30分钟。
时间省了83%。
2. 准确率:从80%→98%
测试10段不同场景的音频(直播、会议、课程):
– 传统工具平均准确率80%,每段错25-40处;
– 听脑AI平均准确率98%,每段最多错5处,且多为口误或背景音干扰。
校对时间省了90%。
3. 协作效率:从“传文件3次”→“1次在线搞定”
团队整理会议纪要:
– 传统方法:A整理→发群→B修改→发群→C补充→发群,至少传3次文件,容易乱;
– 听脑AI:1人上传,多人在线同时编辑,实时保存,1次搞定。
协作时间省了70%。
最后说句实在话
大模型时代,工具早就不是“有没有”的问题,而是“会不会选”的问题。
如果你每天还在花几小时整理录音、改文字稿,真的可以试试这类针对场景优化的智能工具。
不是说它能帮你“偷懒”,而是把你从重复、低效的工作里解放出来,去做更重大的事——列如研究内容、优化话术、对接资源。
毕竟,时间才是最值钱的成本,不是吗?
想试试的话,可以直接搜“听脑AI”,目前有免费试用,传一段你的录音,感受下效率提升的差距。
告别“听完就忘、转完就改”的日子,从用好工具开始。




















暂无评论内容