
MQ 消息队列 📡
首先我们人的精力是有限的,从投入产出来说,深入学习一种消息队列就够了,因为消息队列的使用都是相通的,只要你掌握了其中一种消息队列,你就可以说你会消息队列了,这就如同你无论掌握Java还是Go或者其它语言,你都可以说自己会写代码了
事实确实这般如此,那么不管是学习一门语言还是组件的时候,我们首先要明白其本质和作用
Kafka 是最主流的消息队列之一,被国内外大厂广泛使用,是经过验证的明星项目,也是学习消息队列的首选,所以本次的深入讲解就使用 Kafka 作为学习 MQ 的🌰,进行 MQ 的打怪升级之路吧!
1. 消息队列入门篇🚗
消息队列是什么
消息队列,顾名思义即传递消息的队列,有先入先出的性质,同时,消息队列具备可靠性、高性能等特点
小王在写下这篇 blog 的时候,也是作为学生身份,我们不免也会说自己使用过各种各样的消息队列的情况,例如 Kafka(这个是小王比较常用的)、RocketMQ、RabbitMQ (多种 MQ 的组件的特点一会也会进行比较)and so on ,确实在当下容器化部署中间件环境的时代,我们在那些之前跟着教程所去实现的一个个项目中,使用了一个消息队列的中间件来去提升我们项目的亮点无可厚非,但是到头来似乎只是为了用而去使用,只看到了那些表面测试的 TPS/QPS 数据得到了所谓的提升,但是在业务开发的场景下,我们是否真的需要引入比较消耗资源的消息对列中间件呢,这似乎还是个谜题
那么废话不多说,即刻发车,开始 MQ 的打怪之路 , 嘟嘟嘟~~~
消息队列是大型分布式系统不可缺少的中间件,一般用于异步流程、消息分发、流量削峰等问题
可以通过消息队列实现高性能、高可用、高扩展的架构

正图中所示,消息队列的目的就是为了消息之间的中转和存储
消息队列重点
在学习消息队列之前,小王认为,消息队列是实践类的技术,会应用大于懂原理,在工作中一般而言只要能使用消息队列优化架构就完全够了,所以在本章节中,针对于消息队列的实践进行详解和优化,对于 Kafka 的源码理解,后续也会发文进行详细介绍
在这里也贴上一个 Kafka 的源码的地址,需要的同学可以进行深入https://github.com/apache/kafka.git
要学多少种消息队列
这个问题也是对于初学者比较想进行发问的
业界比较出名的消息队列有ActiveMQ、RabbitMQ、ZeroMQ、Kafka、MetaMQ、RocketMQ。
PS:但是对于业界使用最多的还是追求高性能的 Kafka,当然小王对阿里巴巴旗下的 RocketMQ 也是十分的看好哦
消息队列解决什么问题
消息队列本质上就是解决消息传递的问题,对于现在的其他场景就是后续因为业务需求进行拓展的

**PS:**贴一张图,这就是消息队列的本质的解决问题的场景嘛
消息队列的应用场景
解耦
解耦其本质就是解除耦合,比如我们当前存在两个业务服务A and B,A如果需要等待B的返回,已关注返回的结果和数据,或者就是单纯要B服务处理了,A才能给更前端回包,这就是耦合
比如在我们的日常的消息推送过程中,SvrA发送给SvrB,B发给客户,在理想的状态下A只管去进行发送给B,而B也只是去进行消息的推送即可,如果还需要他们之间进行相互的等待时,那么实在是太浪费时间了,性能削减,也没有必要去已关注其他进行的运行结果喽
PS:这个地方不知道大家是否可以去联想计算机网络中常见的数据传输方式 :电路交换和分组交换⚛️
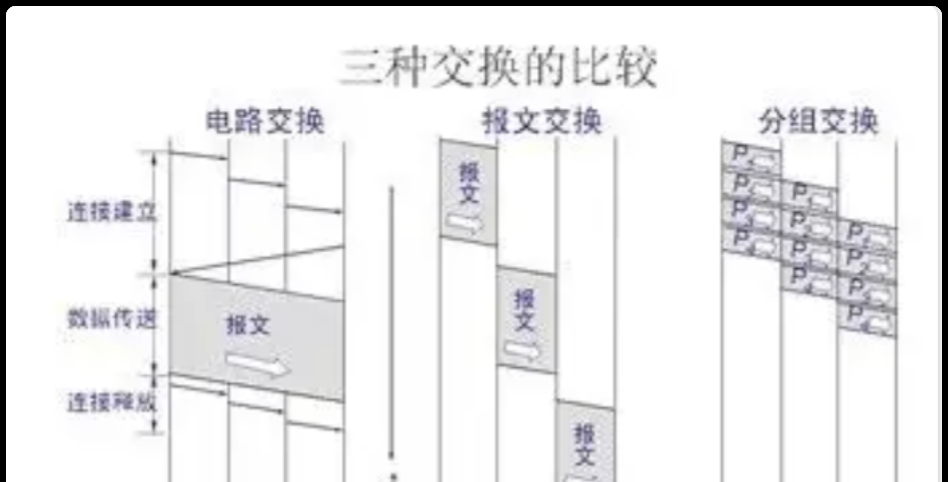
如果就像是电路交换之间的进程时刻保持通路占据资源,那么大名鼎鼎的MQ的作用也就不复存在了
所以,如果业务上可以去除这种依赖,那么就会获得性能、可靠性等的提升

异步
在从事爬虫、视频渲染、模型训练的很多同学都深有感触,用户很难通过同步接口长时间等待结果,那就应该做成异步,先扔进消息队列,后续再进行消费,和解耦一样可以收获更高的性能,以及获得更好的可靠性
异步和解耦最大的区别在于,解耦是业务上本身就不需要依赖,异步是可能还是需要已关注结果,但是不一定干等,可以回头再找
这里使用Go语言写一个异步任务的实例供大家理解
|
消息分发
MQ的本质就是基于对消息进行相应的处理,所以对消息分发的支持更是不言而喻
给大家讲一个小故事
假设我们在实现了一个消息推送和分发的任务场景🎬
这个时候存在了一个SvrA的服务提供方,和多个服务接收方
刚开始由于项目的初步启动并不完善,部门的业务大佬决定让小王先去使用 Redis 的 stream 去实现消息队列
当然这样轻量级的MQ,小王在忙碌了一段时间之后不出意外的很快就搭建好
随着业务体量的不断增大,并发量的不断增多,大佬发现Redis的作用不足以支持这般排山倒海的压力
这个时候由于业务大佬更加熟悉 Kafka 这个消息中间件就对其进行了业务方案的使用⌨️

当然左右两张图片也就生动的体现了消息队列起到的基本作用辽~~~
削峰
举个🌰:每天要被人打48拳,1小时之内打完48拳可能人就挺不过去了,但是分散到24小时,1小时两拳,就能存活,这就是削峰
有原本陡峭的曲线让其变得平滑稳定
其实在架构上,削峰和上面的异步场景是相同的架构,都是将请求扔入队列中,再慢慢消费
但要注意异步场景更偏向于单个请求,本身处理时间很长
削峰针对是单个请求ok,但是流量突发扛不住的场景
这就是异步和削峰在本质上的区别
消息队列的安装
作为后端开发,其实进入公司之后一般是不需要你来安装Kafka的,要么就是有专门的运维,要么就是直接使用一些云厂商提供的消息队列,但是我们平常做实验的时候,最好还是得安装一下,这里选择最简单的方式来安装单机版的Kafka,目的就是做实验
Docker 安装(推荐)
docker安装kafka单机版直接参考这篇文章,亲测可行:
使用Docker部署Kafka单机版 – Ken的杂谈
安装完成之后,这个命令可以进入kafka容器:
|
小王这个地方使用的MacbookPro所以更加倾向于使用docker进行中间件的部署
当然这个地方也是可以使用单机版进行操作的,毕竟就是练手,所以不管是怎么进行操作都是没有问题的
PS:Docker Desktop 在用户本地电脑的进行安装部署实在是太沉重,小王在进行开发的过程中更加倾向于轻量级的软件进行使用
所以也给大家推荐MacBook上可以使用的orbstack,贴下链接🔗
2. 消息队列场景篇🚕
消息队列解耦
场景
模块A不用等模块B把事情做完,只用将信息传递到一个中转站,B从中转站感知到这件事,再自己去做就可以了,这个中转站,就是消息队列,可以起到解耦的作用
发送短信场景,模块A发送消息给B,模块B发送短信给客户,A不需要得到回应,对于A而言只需要触达B就行了
工作流场景,比如审批,组长审批之后审批流程传递给总监,总监审批之后传递给总经理,而更后面的上级是不需要审批完之后再汇报给下级的,比如总监审批完之后他是不用通知组长的
业务代码
解耦的好处有很多,这里我们可以先已关注响应时间。
解耦前:
|
|
返回结果
|
解耦后:
|
没有直接计算,而是把消息传递给了kafka,由kafka消费者来处理:
|
返回结果
|
这里有同学会有疑惑,整体处理时间并没有变短,为何说性能提升了?这里主要是要站在调用方A的角度。
比如A服务调用了B服务做一件事,这个事情要20s,现在异步化了,先丢进Kafka,这个同步接口的时间是不是缩短到非常低了,就几十ms。这就可以说,在同步调用环节,减少了接口响应时间。
甚至,考虑这种情况,A本来就不用关心结果,比如B是一个消息推送,类似于B可以发消息给微信、企业微信等等,A只用把消息传递给B,B再推送给哪个第三方,推送给几个第三方,都是B的事,这种情况,就可以说对于A而言,丢给Kafka之后,后续流程它就不关心了,也就意味着站在A的角度,整个流程的时间缩短了。
消息队列削峰
场景
一个模块A接受一波流量,收到之后,立刻调用另一个模块B,那么此时B承担了基本相同的流程,举个例子,模块A一瞬间收到100个请求,那么B基本也是一瞬间收到100个请求,如果B的承压能力非常差,或者B有什么资源限制,那么这100个请求下来,B可能就挂了或者报错了
面对这种下游扛不住的场景,我们还可以有第二种流程:
模块A不用一次性把消息打给B,而是只用将信息传递到一个中转站,B按自身的消费能力从中转站拉取消息,再自己去做就可以了,这个中转站,就是消息队列,可以起到削峰的作用

业务代码
削峰前
|
收到请求后,countService会打印”flow arrived!!!”表示流量已经到达。
现在我们要向这个接口连续发送10次调用,来观察流量到达情况,具体测试流程:
需要把下方脚本保存成peak_clip_many_with_mq.sh文件
然后sh peak_clip_many_with_mq.sh,注意,需要是linux或者mac环境下





















暂无评论内容