

一文读懂大数据领域数据架构的底层逻辑:从数据产生到价值落地的全链路解析
副标题:涵盖批处理、流处理、存储与计算分离、湖仓一体等核心架构模式
摘要/引言
问题陈述
在数字经济时代,数据已成为企业最核心的生产要素之一。根据IDC预测,到2025年全球数据圈将增长至175ZB,如此规模的数据量背后,隐藏着巨大的商业价值与技术挑战。然而,许多企业在大数据实践中面临着共同的困境:数据孤岛严重、处理效率低下、实时性与一致性难以平衡、存储成本失控、数据价值提取困难……这些问题的根源,往往在于对数据架构底层逻辑的理解不足。
传统数据架构(如基于关系型数据库的集中式架构)在面对”3V”(Volume、Velocity、Variety)甚至”5V”(加上Veracity、Value)特性的数据时,暴露出明显局限性:单机存储容量瓶颈、处理能力不足、扩展性受限、难以支持非结构化数据等。如何构建一套能够从容应对海量、高速、多样数据的架构体系,成为企业数字化转型的关键命题。
核心方案
本文将从”底层逻辑”视角出发,系统解析大数据领域数据架构的设计原理与演进脉络。我们将沿着数据从产生到价值落地的全生命周期(数据采集→存储→处理→分析→应用),逐一剖析各环节的核心挑战、技术选型与架构设计思想。内容涵盖:
数据架构的本质与核心目标
数据生命周期各阶段的关键技术组件
主流架构模式(批处理、流处理、Lambda、Kappa、湖仓一体等)的底层逻辑与适用场景
存储与计算分离、弹性扩展等关键设计原则的实现机制
数据治理在架构中的角色与实践方法
主要成果/价值
通过本文,你将获得以下收获:
建立数据架构的全局认知:理解数据架构不是孤立组件的堆砌,而是各环节协同的有机整体
掌握核心技术选型的判断依据:不再盲目追随技术潮流,而是基于业务场景选择合适的工具与架构
洞悉架构演进的内在逻辑:从Hadoop到云原生,从数据仓库到数据湖,理解技术变革的驱动力
规避常见架构设计陷阱:如过度设计、技术债累积、扩展性瓶颈等问题的预防与解决思路
获得可落地的架构设计方法论:一套从需求分析到架构落地的完整思考框架
文章导览
本文将分为四个部分展开:
第一部分:基础认知 — 解析数据架构的定义、目标与核心挑战
第二部分:核心组件与逻辑 — 深入数据生命周期各环节的技术原理与架构设计
第三部分:架构模式与实践 — 对比主流架构模式的优缺点及落地案例
第四部分:演进趋势与最佳实践 — 探讨数据架构的未来方向与企业落地建议
目标读者与前置知识
目标读者
本文适合以下人群阅读:
数据工程师:希望系统理解数据架构设计原理,提升架构设计能力
后端/全栈开发者:需要对接大数据系统,或参与数据平台建设的工程师
技术管理者:负责数据平台规划、技术选型与团队建设的技术负责人
数据分析师/科学家:希望了解数据处理链路,更好地与工程团队协作
对大数据感兴趣的初学者:希望建立系统的大数据技术认知体系
前置知识
阅读本文建议具备以下基础知识:
计算机基础:了解操作系统、网络原理、数据库基本概念(如SQL、表、索引)
编程基础:熟悉至少一种编程语言(Java/Python/Scala均可),理解基本的数据结构与算法
分布式系统入门:了解分布式系统的基本概念(如节点、集群、副本、一致性)
数据处理概念:知道批处理、实时处理的基本区别,了解ETL/ELT的含义
如果你对上述某些概念不太熟悉,无需担心——本文会在涉及相关内容时进行必要的解释,帮助你逐步建立认知。
文章目录
第一部分:基础认知
1.1 数据架构的本质:从”数据问题”到”架构解决方案”
1.2 大数据时代的数据特性与架构挑战(3V到5V的深化理解)
1.3 数据架构的核心目标:可用性、可靠性、扩展性、性能与成本的平衡
第二部分:数据生命周期与核心组件
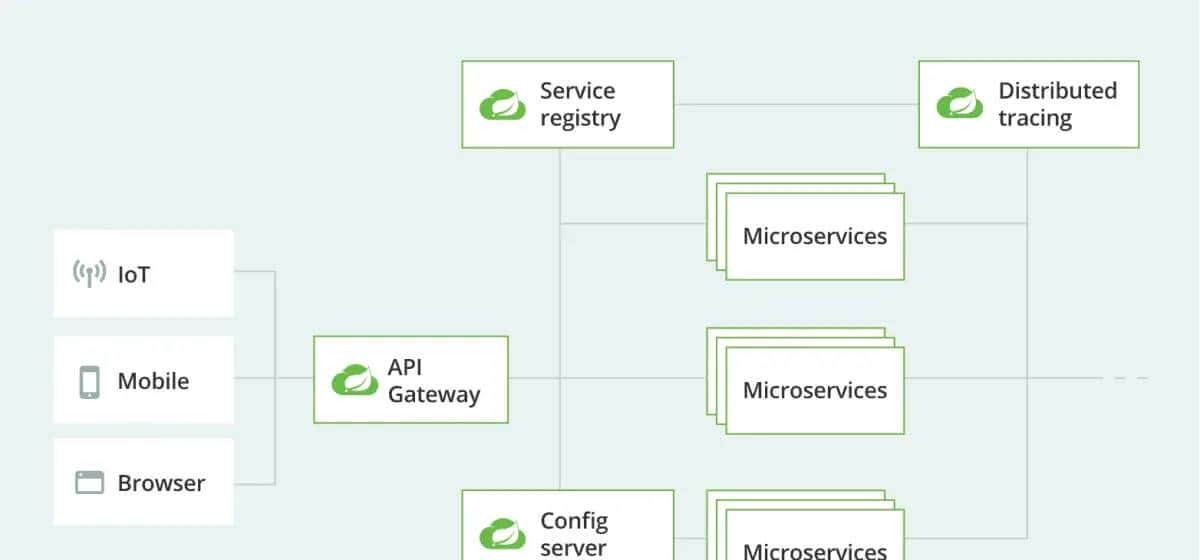
2.1 数据采集层:从数据源到统一接入的架构设计
2.1.1 数据源类型与接入策略(日志、数据库、消息队列、API等)
2.1.2 采集工具对比:Flume vs Logstash vs Filebeat vs Kafka Connect
2.1.3 采集层架构设计要点:高吞吐、低延迟、可靠性保障
2.2 数据存储层:存储系统的选型逻辑与架构设计
2.2.1 存储系统的核心指标:容量、吞吐量、延迟、成本、一致性
2.2.2 结构化存储:关系型数据库、数据仓库(Redshift/BigQuery)
2.2.3 半结构化/非结构化存储:HDFS、对象存储(S3/OSS)、NoSQL数据库
2.2.4 存储分层策略:热数据、温数据、冷数据的存储方案
2.3 数据计算层:批处理与流处理的底层逻辑
2.3.1 批处理引擎:MapReduce、Spark的架构原理与适用场景
2.3.2 流处理引擎:Storm、Flink、Spark Streaming的技术差异
2.3.3 批流一体:从Lambda到Kappa再到实时数仓的演进逻辑
2.3.4 计算优化技术:数据本地化、资源调度、并行度调整
2.4 数据服务层:从数据到价值的桥梁
2.4.1 数据服务化的核心模式:API服务、OLAP分析、数据订阅
2.4.2 实时查询引擎:Presto、Impala、ClickHouse的架构对比
2.4.3 数据可视化与BI工具的集成策略
2.5 数据治理层:架构稳定性与数据质量的保障
2.5.1 元数据管理:数据血缘、数据字典、资产目录
2.5.2 数据质量监控:完整性、准确性、一致性、及时性
2.5.3 数据安全与合规:权限控制、脱敏、审计、GDPR/CCPA合规
第三部分:主流架构模式深度解析
3.1 传统数据仓库架构(EDW):原理、优缺点与适用场景
3.2 数据湖架构:从Hadoop到云原生对象存储的演进
3.3 湖仓一体架构:数据湖与数据仓库的融合逻辑
3.4 Lambda架构:批处理与流处理的双轨制设计
3.5 Kappa架构:单一流处理管道的简化方案
3.6 实时数仓架构:从T+1到实时的数据价值提速
3.7 云原生数据架构:弹性扩展与按需付费的实现机制
第四部分:架构设计实践与演进
4.1 数据架构设计方法论:从需求到落地的完整流程
4.2 典型行业数据架构案例解析
4.2.1 互联网行业:高吞吐、高并发场景下的架构设计
4.2.2 金融行业:强一致性、高安全场景下的架构实践
4.2.3 制造业:工业数据湖与实时监控平台架构
4.3 架构演进中的常见问题与解决方案
4.3.1 技术债累积与架构重构策略
4.3.2 数据孤岛的打破与数据集成方案
4.3.3 成本优化:存储、计算与网络资源的合理配置
4.4 未来趋势:AI原生数据架构、实时湖仓、Serverless数据处理等
4.5 总结:构建面向未来的数据架构能力
第一部分:基础认知
1.1 数据架构的本质:从”数据问题”到”架构解决方案”
1.1.1 数据架构的定义
数据架构(Data Architecture)是指对数据资产的组织、存储、处理、流转与使用进行系统性设计的框架。它不是单一的技术或工具,而是一套指导数据全生命周期管理的原则、策略与技术选型的集合。
从更宏观的视角看,数据架构是企业IT架构的重要组成部分,与应用架构、基础设施架构共同构成企业技术体系的三大支柱:
应用架构:已关注业务功能的实现(如电商系统、CRM系统)
基础设施架构:已关注计算、网络、存储等底层资源的管理
数据架构:已关注数据的产生、存储、流转与价值提取
1.1.2 数据架构的核心价值
数据架构的核心价值在于解决数据从”量”到”质”再到”价值”的转化问题。具体体现在:
打破数据孤岛:通过统一的数据模型与集成策略,实现跨系统数据的互联互通
提升数据质量:通过标准化的数据采集、清洗与治理流程,确保数据的准确性与一致性
加速价值交付:减少数据处理链路,降低分析门槛,让数据价值更快落地到业务
支撑业务创新:如用户画像、推荐系统、风控模型等数据驱动应用的基础
降低总体拥有成本(TCO):通过合理的存储分层、计算资源调度,优化数据平台的建设与



















暂无评论内容