
随着DeepSeek模型的爆火出圈,越来越多的用户希望能够在本地部署该模型,目前SER9 Pro已全系支持在本地部署DeepSeek大模型,并且可以调动核显运算,下面将演示如何在SER9 Pro快速本地部署Deepseek模型。
通过浏览器搜索“DeepSeek本地部署”时,会看到有许多通过Ollama进行大模型本地部署的方式。
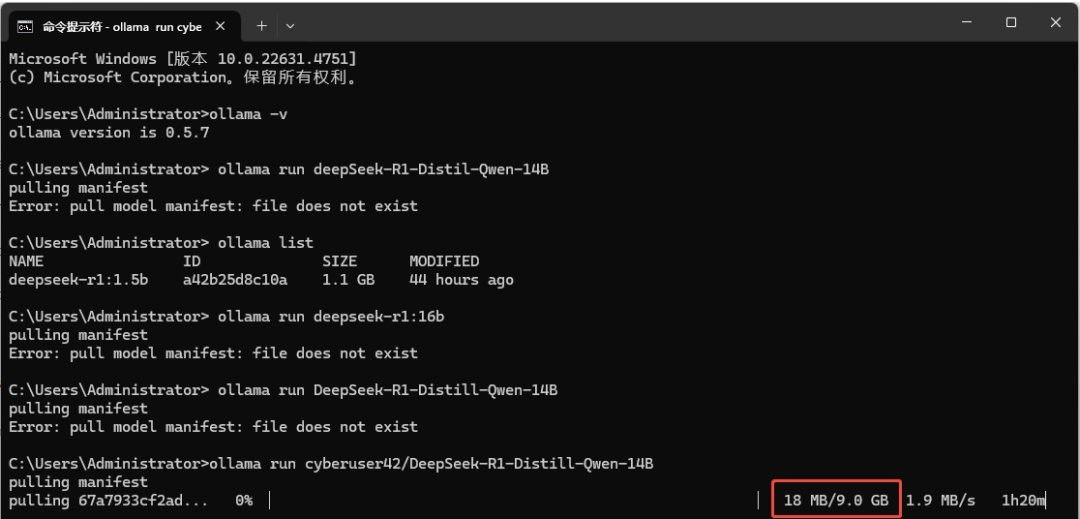
虽然可以实现本地部署大模型,但需要必定的代码基础,对初学者有必定难度,并且无法调用核显,我们可以通过LM Studio进行更为简单的完成部署。
使用硬件
SER9 Pro HX370(64GB 8000Mhz版本已上线),64GB内存的优势在于可以运行更大参数的AI模型。
第一划分更多内存作为专用显存:
1. 启动SER9 Pro,按住Delete键进入BIOS界面。
2. 使用键盘的左右键移动光标,依次选择:
Advanced → AMD CBS → NBIO Common Options → GFx Configuration → Dedicated Graphics Memory。
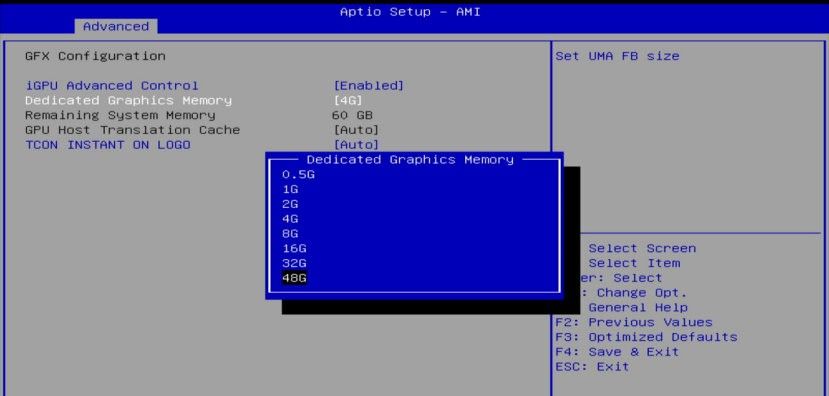
3. 选择需要设置的显存大小,根据官方推荐数据,GPU运行DeepSeek-14B模型时,至少需要7GB显存,因此一般提议设置为8-16GB显存,64G版本最大可以设置为48GB。
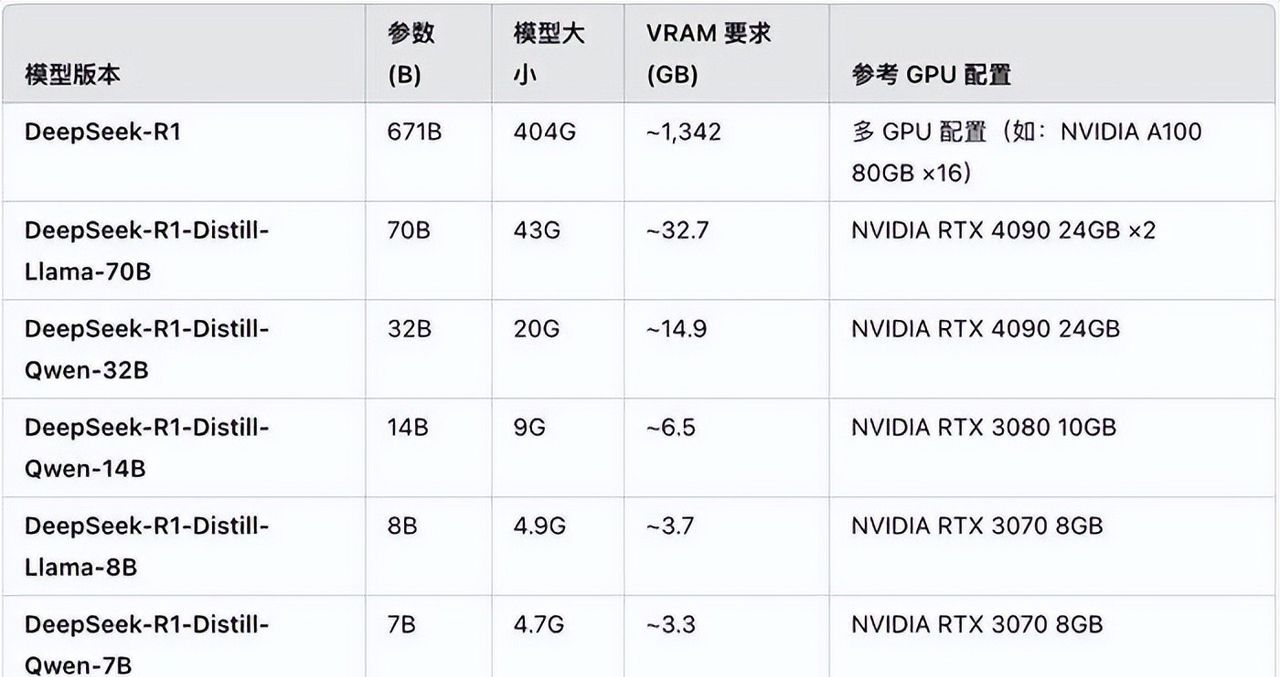
4. 按F4保存设置并重启。
配置检查
设置完成后,启动系统并进入任务管理器,查看GPU性能选项,可以看到,专用显存已设置为48GB,可以正常使用!

安装LM Studio
1. 下载LM Studio:
• 访问LM Studio官方网站[1],下载适配Windows的安装包。
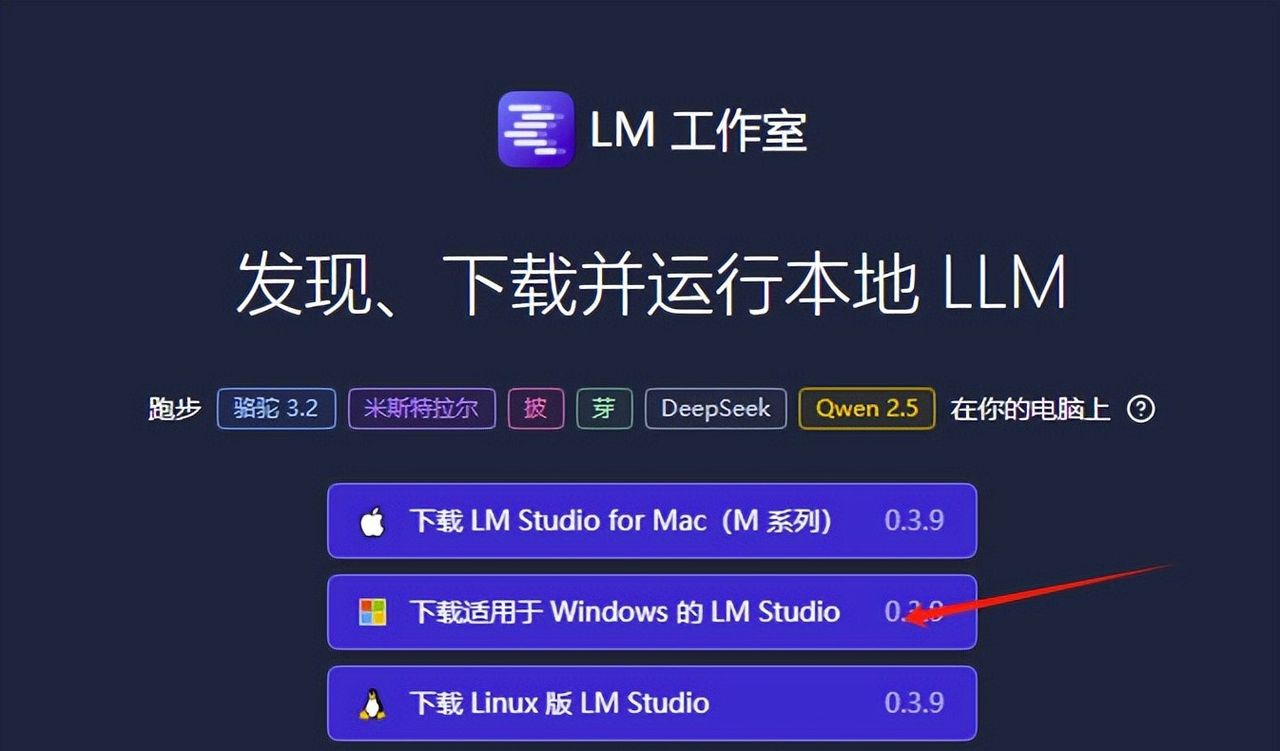
2. 安装LM Studio:
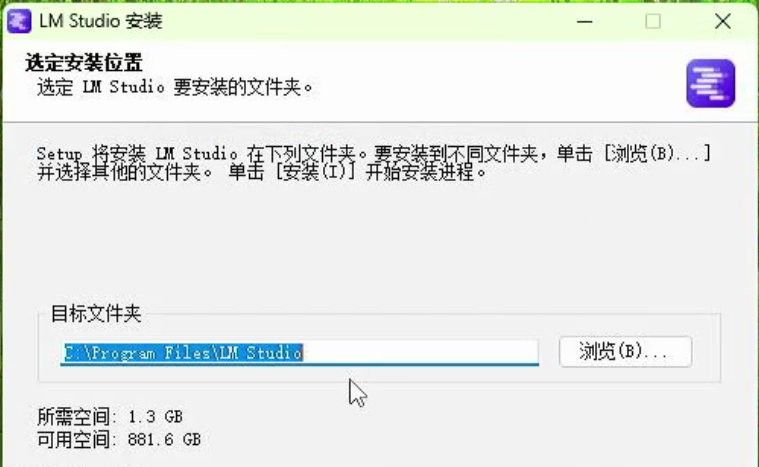
• 下载完成后,运行安装程序,并按照安装向导完成安装,选择合适的安装路径。
3. 设置语言环境:
• 启动LM Studio,首次启动时,选择跳过默认的大模型加载。
• 进入界面后,点击右下角齿轮按钮,进入设置,在Language选项中选择简体中文。
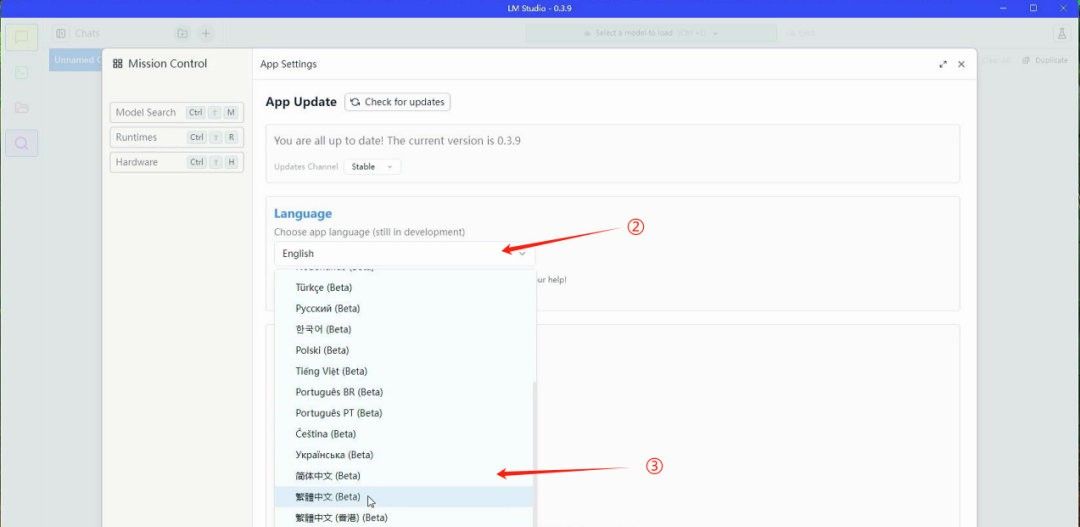
下载与配置DeepSeek模型
1. 搜索模型:
• 在LM Studio中,点击左上角的放大镜图标,搜索需要的模型,如DeepSeek。
• 默认需要科学上网才能下载模型文件,否则无法成功下载。
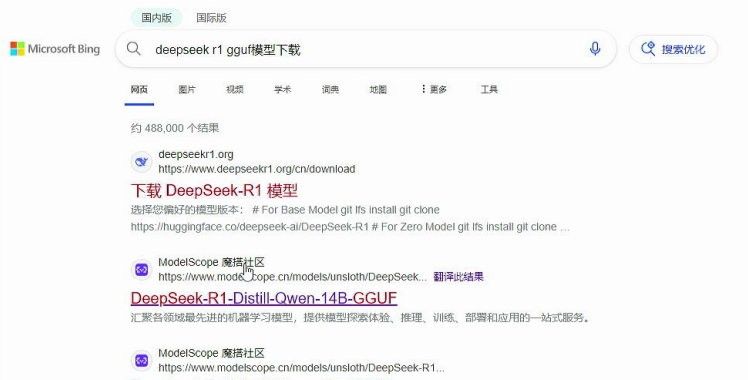
2. 下载模型:
• 由于网络问题和DeepSeek模型文件较大,提议直接从镜像站下载。在游览器搜索DeepSeek R1 GGUF模型下载,找到合适的镜像站(例如魔塔社区[2])进行下载。
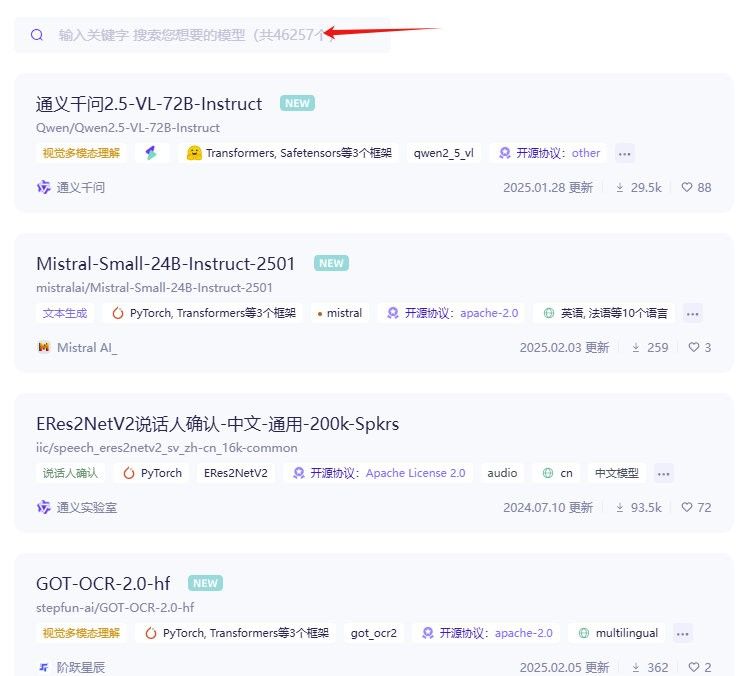
• 点击模型库,有超级多的模型可以选择,在搜索框中搜索你想要的模型,为了避免转换格式,我们选择后缀带有GGUF的模型,可以直接使用。
• GGUF:一种大模型文件格式,通过量化技术减少模型的大小和计算需求,使其在不同硬件上运行更快、更高效,让大模型更容易部署和使用。
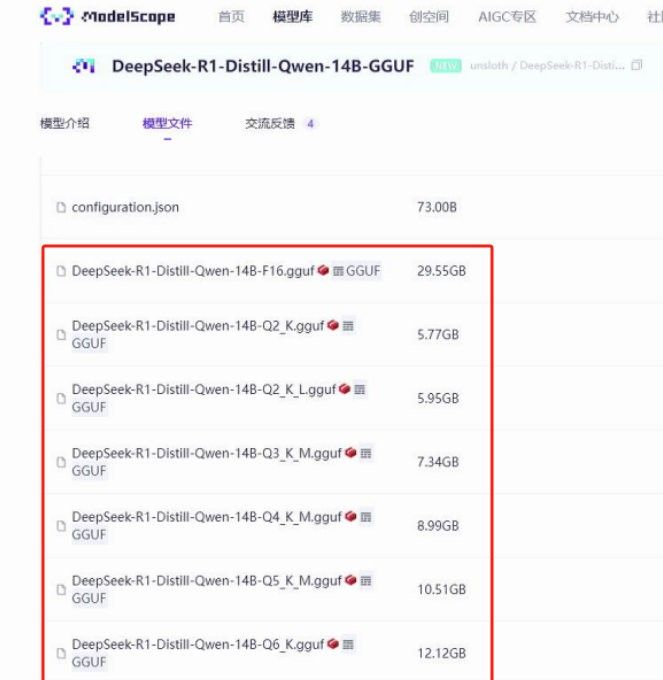
• 选择需要的模型版本,如
DeepSeek-R1-Distill-Qwen-14B-GGUF,下载时注意不同精度的差异:
• Q8精度:精度高,文件大。
• Q2精度:精度低,文件小。
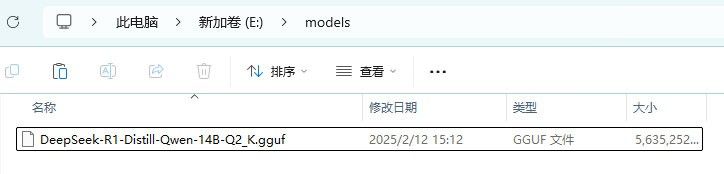
3. 模型存放目录:
• 下载完成后,将模型文件移动到LM Studio的本地模型文件目录中。例如:E:models。
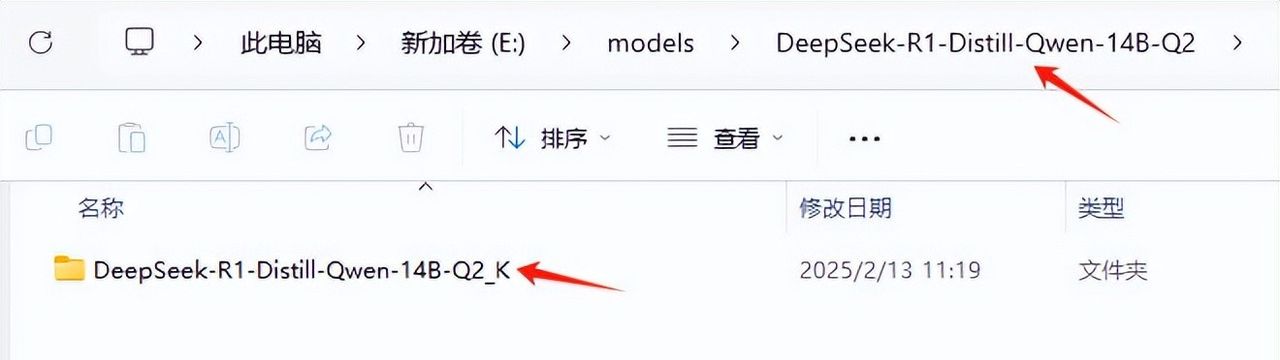
• 在模型目录下新建文件夹,命名为下载的模型型号,如
DeepSeek-R1-Distill-Qwen-14B-Q2,进入文件夹再新建模型全称
DeepSeek-R1-Distill-Qwen-14B-Q2_K文件夹,将下载的模型文件放入其中。
这样模型文件目录就搭建完毕,可以在LM Studio中读取到这个模型文件,如果有新增的模型,就继续在E:models 下新建模型文件目录。

加载与配置模型
1. 加载模型:
• 返回LM Studio聊天界面,点击选择要加载的本地模型。
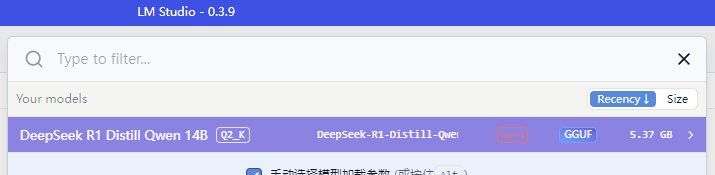
• 在弹出的窗口中,配置模型的运行参数,主要包括以下几个参数:
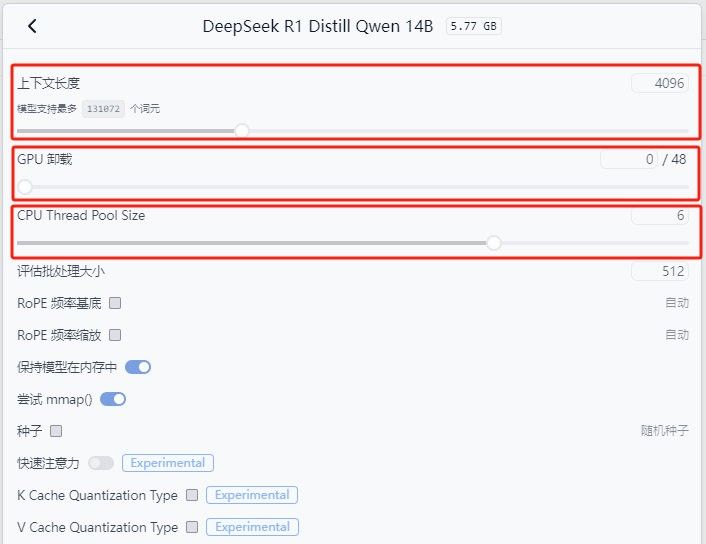
• 上下文长度:设置AI回复内容的最大字数,影响返回结果的长度。
• GPU卸载:控制显卡参与运算,优先使用显卡。
• CPU Thread Pool Size:设置CPU线程池大小,控制CPU参与运算。
2. 启动模型:
• 完成设置后,点击加载模型,即可开始与DeepSeek进行本地对话。
SER9 Pro支持本地快速搭建并运行DeepSeek大语言模型,通过以上步骤享受高效便捷的本地AI体验。
引用链接
[1] LM Studio官方网站: https://lmstudio.ai
[2] 魔塔社区:https://www.modelscope.cn
























- 最新
- 最热
只看作者