
【AI学习-comfyUI学习-SDXL 风格化提示词节点包(Style Prompt Node Pack) 工作流-各个部分学习-第四节】
1,前言2,说明1,SDXL 风格化提示词节点包(Style Prompt Node Pack) 工作流2,整体功能3,节点说明
3,流程(1)调用模块1)整个模块部分
(2)输出 提示词(3)模型加载(4)生成图片
4,模块介绍1,CLIP文本编码SDXL2,ComfyUI 的核心采样器节点3,SDXL风格化提示词(高级)
5,细节部分6,使用的工作流7,总结
1,前言
最近,学习comfyUI,这也是AI的一部分,想将相关学习到的东西尽可能记录下来。
2,说明
1,SDXL 风格化提示词节点包(Style Prompt Node Pack) 工作流
使用 SDXL 模型(如 Juggernaut XL),通过“风格化提示词节点”快速生成特定风格(如赛博朋克、复古、写实等)的图像。
2,整体功能
本身是一个 文生图(text-to-image) 工作流,用 SDXL 模型 Juggernaut 来生成图片。
在这个例子里,prompt 是「beautiful scenery nature glass bottle landscape, purple galaxy bottle」,
所以整个流程的任务是——
生成一张装有紫色银河的玻璃瓶、风景场景风格的图片。
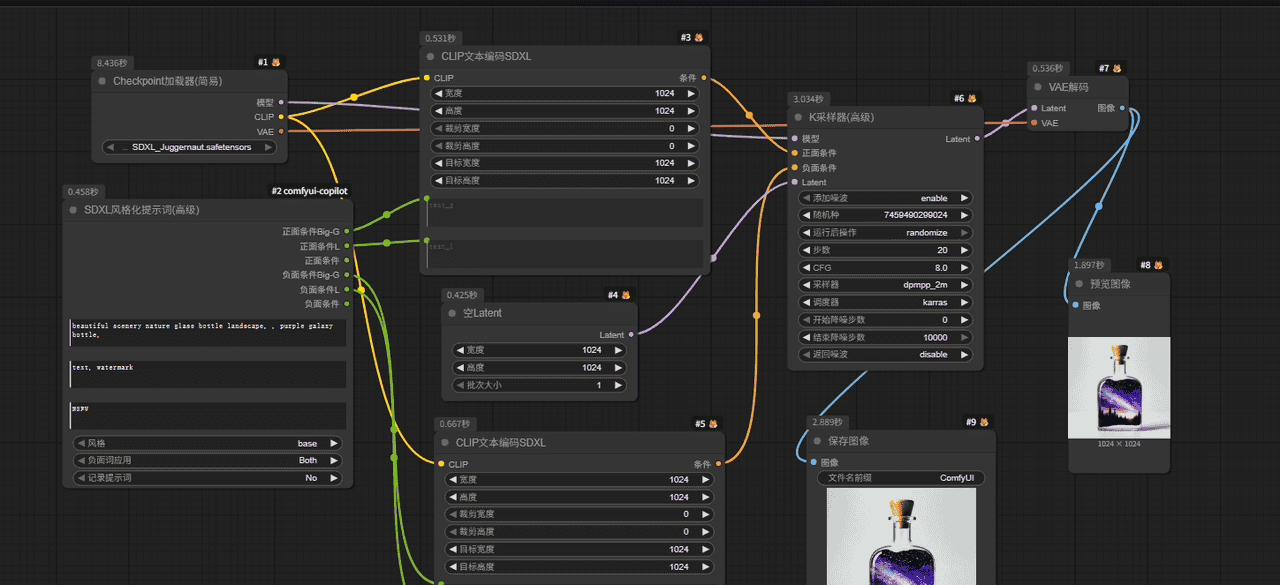
3,节点说明
| 区域 | 节点名 | 作用 |
|---|---|---|
| ① Checkpoint加载器 #1 | |
加载主模型(高质量 SDXL 写实风格)。 |
| ② SDXL风格化提示词节点 #2 | |
管理正负提示词、风格选项;你目前的风格设为 |
| ③ CLIP文本编码节点 #3 #5 | |
把文字提示转换成语义向量,供模型理解。 |
| ④ 空Latent #4 | 定义潜空间(图像尺寸 1024×1024),相当于生成的“画布”。 | |
| ⑤ K采样器 #6 | 执行采样过程,生成潜空间图像。参数如步数 20、CFG 8 控制细节与风格强度。 | |
| ⑥ VAE解码 #7 | 把潜空间图解码成可视图像。 | |
| ⑦ 预览与保存 #8 #9 | 预览输出并保存最终结果。 |
3,流程
(1)调用模块
1)整个模块部分
这回整个模块都可以截截图下了
(2)输出 提示词
如下是输入提示词
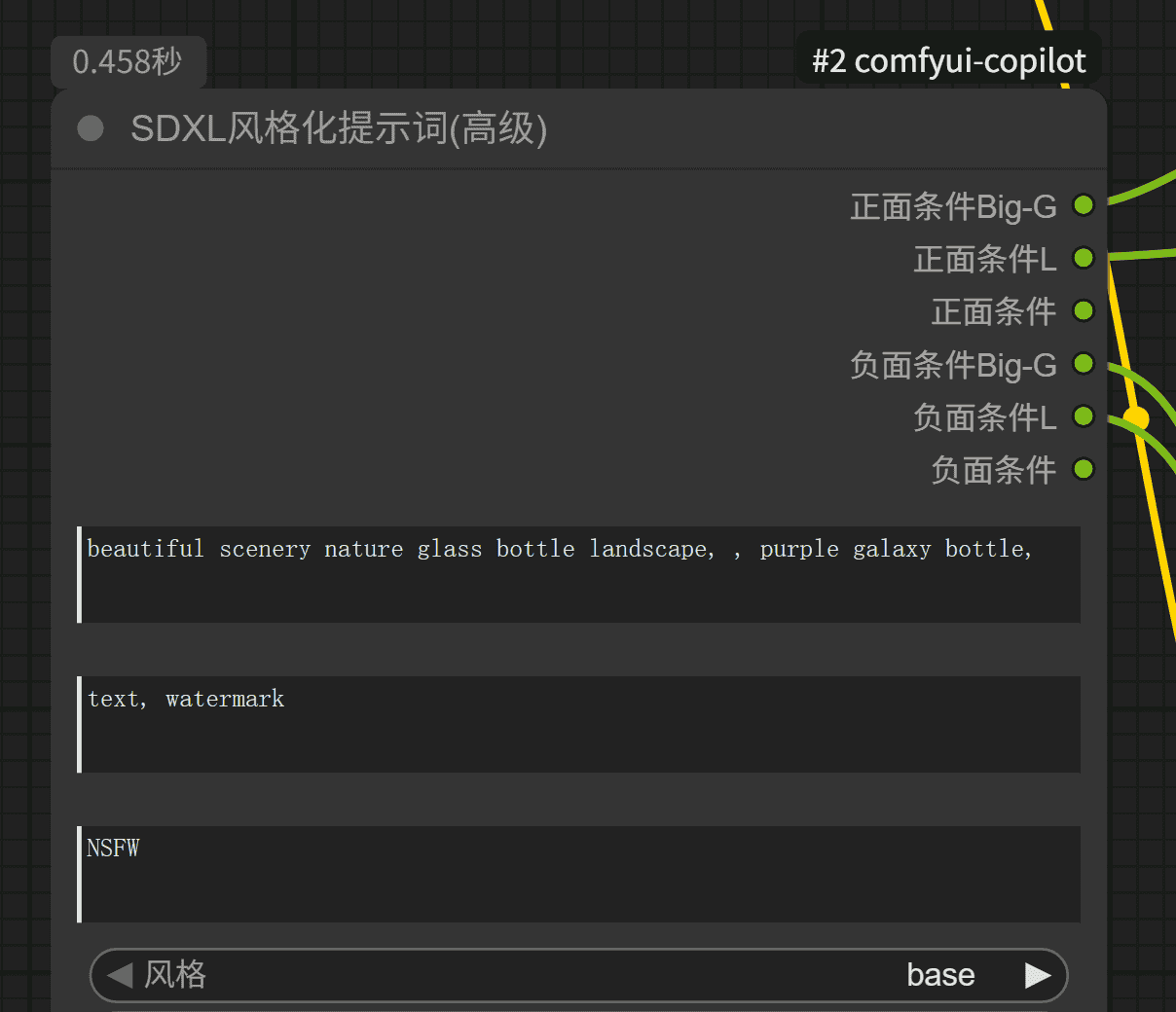
beautiful scenery nature glass bottle landscape, , purple galaxy bottle,
(3)模型加载
![图片[1] - 【AI学习-comfyUI学习-SDXL 风格化提示词节点包(Style Prompt Node Pack) 工作流-各个部分学习-第四节】 - 宋马](https://pic.songma.com/blogimg/20251113/1f51122353964c869b9917dba24f6a62.png)

(4)生成图片

4,模块介绍
1,CLIP文本编码SDXL
![图片[2] - 【AI学习-comfyUI学习-SDXL 风格化提示词节点包(Style Prompt Node Pack) 工作流-各个部分学习-第四节】 - 宋马](https://pic.songma.com/blogimg/20251113/f69b92dfb7b648268779499df3e7e1a4.png)
这个节点的功能是:
把输入的提示词(prompt / text)转化成模型能理解的语义向量。
换句话说,它是“文字 → 向量”的翻译器。
在 SDXL 模型中,这一步比 SD1.5 复杂得多,因为 SDXL 使用了 双 CLIP 编码器结构(CLIP-G + CLIP-L),以便更精细地理解文字、构图和风格。
| 参数名 | 默认值 | 含义 | 详细说明 |
|---|---|---|---|
| 宽度(width) | 1024 | 图像生成宽度 | CLIP 在 SDXL 中需要知道目标图像的分辨率,以便对构图相关词(如“wide view”“portrait”)进行空间语义编码。建议与生成分辨率一致。 |
| 高度(height) | 1024 | 图像生成高度 | 同理,CLIP-L(Large)会用此信息调整构图理解,比如横构图 vs 竖构图。 |
| 裁剪宽度(crop_w) | 0 | 图像裁剪偏移(水平) | 如果要让模型生成“局部视角”或裁剪效果,可以调整这项。例如设为 256 表示偏右裁剪。一般保持 0。 |
| 裁剪高度(crop_h) | 0 | 图像裁剪偏移(垂直) | 控制垂直方向的裁剪中心。默认 0 即居中。 |
| 目标宽度(target_w) | 1024 | 输出目标宽度 | 与“宽度”含义相近,供第二层 CLIP-L 模块使用;建议保持与生成分辨率一致。 |
| 目标高度(target_h) | 1024 | 输出目标高度 | 与“高度”一致,保持匹配即可。 |
| text_g(正向提示词输入口) | — | 输入文字给 CLIP-G 编码器 | CLIP-G 是 SDXL 的全局语义理解模块,负责把整体风格、主题、内容编码进 latent。 |
| text_l(正向提示词输入口) | — | 输入文字给 CLIP-L 编码器 | CLIP-L 是局部细节理解模块,强化具体对象(如“细节”“光影”“背景”)。 |
2,ComfyUI 的核心采样器节点
![图片[3] - 【AI学习-comfyUI学习-SDXL 风格化提示词节点包(Style Prompt Node Pack) 工作流-各个部分学习-第四节】 - 宋马](https://pic.songma.com/blogimg/20251113/b33eb2805f554deda72f7045feeb91b0.png)
K采样器(高级)(即 KSampler Advanced)。
这是整个 图像生成的主引擎,决定画面的清晰度、风格强度、随机性和一致性。
下面我给你讲得非常系统(适合你这种懂得在调节点的用户)。
简单说:
它是 Stable Diffusion 模型在“降噪还原图像”的过程中控制“采样步数、随机性、提示影响力”等的模块。
一句话解释:
🌀 它控制 AI 绘画过程的“速度、方向和信念”。
| 参数名 | 默认值 | 含义 | 调整建议 |
|---|---|---|---|
| 模型(Model) | — | 接入模型(来自 Checkpoint) | 一定要接同体系的模型(SD1.5 / SDXL / Flux) |
| 正面条件(Positive Cond) | — | 正向提示词向量 | 通常来自 CLIP 编码器(描述想要的画面) |
| 负面条件(Negative Cond) | — | 负向提示词向量 | 压制不希望出现的内容(模糊、畸形等) |
| Latent | — | 初始潜空间(通常来自“空Latent”或“VAE编码”) | 控制生成尺寸与初始结构 |
3,SDXL风格化提示词(高级)
![图片[4] - 【AI学习-comfyUI学习-SDXL 风格化提示词节点包(Style Prompt Node Pack) 工作流-各个部分学习-第四节】 - 宋马](https://pic.songma.com/blogimg/20251113/5db8c05e20a64537a54d318f25ef6ad5.png)
这是一个对 SDXL 模型的 Prompt 进行自动结构化、风格融合的“智能提示词节点”,
也是目前 最强的文字输入控制节点之一,比单纯的 CLIP 文本编码器更灵活。
简单理解:
它帮你把提示词(Prompt)分配给 SDXL 的双 CLIP 通道(Big-G / L),
同时自动加上风格标签(Style)、负面词和结构化控制。
也就是说,这个节点相当于一个“Prompt 管理器 + 风格模板器”,
让你可以一边输入词,一边自动匹配适合 SDXL 的语义结构。
| 区域 | 参数 / 插口 | 作用 | 说明 |
|---|---|---|---|
| 🟢 正面条件 Big-G / L | 输出端 | 连接到 “CLIP文本编码SDXL” 的输入端 | 生成 正向提示向量(G:全局风格;L:局部细节) |
| 🟢 负面条件 Big-G / L | 输出端 | 同上 | 生成 负向提示向量(控制不要出现的元素) |
5,细节部分
暂无
6,使用的工作流
https://download.csdn.net/download/qq_22146161/92260138
7,总结
这也算各一个开始吧,我也在学习摸索中。























暂无评论内容