

摘要:
随着医疗人工智能(AI)的飞速发展,其应用场景正从云端数据中心向资源受限的边缘设备(如便携式超声仪、内窥镜探头、智能监护仪)迁移。2025年预印本论文《BiTMedViT》提出的“三元量化ViT”模型(https://arxiv.org/abs/2510.13760),在实现极致轻量化和低延迟推理的同时,也标志着医疗AI编程范式的根本性转变:从追求极致精度的“大模型训练”,转向兼顾效率、成本与实时性的“模型压缩、量化与边缘优化”。然而,这种部署在边缘的轻量化模型,由于其参数空间的简化,对现实世界中持续发生的数据分布漂移和概念漂移更为敏感,导致性能衰减问题愈发突出。本文旨在深入剖析医疗AI模型在边缘环境下的性能衰减机理,并系统性地设计一套集“实时监控-智能诊断-自动微调-安全部署”于一体的闭环自适应机制。报告首先从理论与实践层面梳理了模型性能衰减的根源,并特别分析了量化技术(如BiTMedViT所采用的三元量化)对模型鲁棒性的影响。随后,本文重点构建了一个多层次的性能监控体系,涵盖数据层、特征层和决策层,并提出了一种基于因果推断的漂移根因分析方法。核心部分,本文设计了一套策略化的自动微调编程框架,该框架能根据监测到的衰减类型(如数据漂移或概念漂移)和模型特性(如量化精度),自动选择最优的微调策略(如冻结部分层的增量学习、量化感知微调、知识蒸馏等),并结合超参数自动化和联邦学习技术,解决边缘场景下数据稀缺与隐私保护的难题。最后,通过在模拟边缘环境下的BiTMedViT模型上进行案例研究,验证了所提机制在抑制性能衰减、保障模型长期有效性方面的优越性。本研究为构建能够在复杂多变的真实医疗环境中长期、可靠、自主运行的边缘医疗AI系统提供了理论指导和实践蓝图。
关键词: 医疗AI;边缘计算;模型性能衰减;持续学习;自动微调;模型量化;Vision Transformer;稳健性
第一章:绪论
1.1 研究背景与意义:医疗AI的“边缘革命”
人工智能技术,特别是深度学习,已在医学影像分析、疾病风险预测、辅助诊断等领域取得了突破性进展。早期,这些模型大多部署在强大的云端服务器上,遵循“数据上传-云端推理-结果返回”的模式。然而,这种模式在临床实践中暴露出诸多弊端:网络延迟影响实时性、数据传输存在隐私泄露风险、对网络连接依赖性高,以及高昂的云端计算成本。
在此背景下,“边缘计算”作为一种新兴的计算范式应运而生。它主张将计算任务从云端下沉到靠近数据源的边缘设备上,实现本地化的数据处理和分析。对于医疗AI而言,这意味着将智能直接嵌入到医疗设备中,如内置AI芯片的听诊器、实时分析心电图的可穿戴设备、或能即时识别病变的内窥镜系统。这种模式不仅能提供毫秒级的响应速度,满足急诊、术中导航等高时效性场景的需求,还能将敏感的患者数据保留在本地,显著提升隐私安全水平。
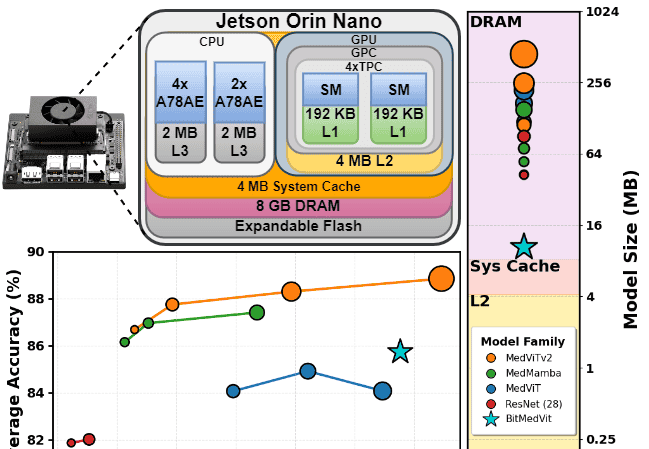
BiTMedViT正是这场“边缘革命”的缩影。它通过对Vision Transformer(ViT)这一先进但庞大的模型进行三元量化,实现了在NVIDIA Jetson Orin Nano这类高性能嵌入式设备上的实时推理。其“模型体积缩小约43倍、内存流量减少约39倍、效率提升约41×”的成果,清晰地表明:医疗AI的编程任务已不再是单一的“模型训练”,而是扩展为一个覆盖“算法设计-模型压缩-性能优化-嵌入式开发-持续运维”的全生命周期工程。 这要求AI工程师不仅要懂算法,更要懂硬件、懂系统、懂部署。因此,研究如何保障这些已部署、高度优化的边缘AI模型能够长期稳定地工作,具有重大的理论价值和紧迫的临床需求。
1.2 核心挑战:边缘环境下的模型性能衰减
将一个在实验室环境下达到高精度的模型部署到真实的边缘场景后,其性能往往会随着时间的推移而逐渐下降,这一现象被称为“模型性能衰减”。对于医疗AI而言,这可能意味着诊断准确率的降低、假阳性/假阴性率的上升,直接关系到患者的生命安全。边缘环境下的性能衰减问题尤为严峻,其主要根源可归结为以下几个方面:
数据漂移:输入数据的统计特征发生了变化。例如,新的CT扫描仪投入使用导致图像的噪声分布和分辨率改变;不同医院、不同操作手法的超声图像风格各异;患者群体的人口统计学特征(如年龄、地域分布)随时间迁移。对于BiTMedViT这类经过量化的模型,其对输入数据微小变化的容忍度更低,数据漂移更容易导致其推理结果偏离预期。概念漂移:数据特征与标签之间的关系(即P(y|x))发生了改变。例如,医学界对某种疾病的诊断标准更新了;出现了一种新的疾病亚型,其影像学表现与旧有认知不同;某种疾病因环境或生活习惯改变,其高危人群特征发生了变化。这要求模型不仅要适应新的数据分布,更要更新其内部的“知识”。边缘硬件与环境的异构性:边缘设备的计算资源、传感器精度、运行环境(温度、电磁干扰)都存在差异和波动,可能对模型的推理过程产生细微但持续的累积性影响。“遗忘”效应:若采用简单的持续学习方法,模型在学习新知识时可能会覆盖或破坏掉已学到的旧知识,导致在旧任务上的性能下降,即“灾难性遗忘”。
这些挑战共同构成了一个核心问题:如何构建一个能够自主感知环境变化、诊断自身性能衰退、并采取有效措施进行自我修复的“自适应”医疗AI系统?
1.3 研究动机与本文核心思想
BiTMedViT的成功,让我们看到了医疗AI在边缘端广阔的应用前景。但它也像一枚硬币的两面,带来了新的问题:极致的压缩和量化,在提升效率的同时,是否会以牺牲模型的“鲁棒性”和“适应性”为代价?答案是肯定的。一个被“压缩”到极限的模型,其决策边界往往更加“僵硬”,面对未曾见过或略有偏差的数据时,更容易做出错误判断。
因此,本研究的核心动机是:为以BiTMedViT为代表的轻量化边缘医疗AI模型,构建一个配套的“免疫系统”和“学习系统”。 这个系统需要具备两大核心能力:
免疫监控能力:能够实时、低开销地监测模型运行状态,精确识别性能衰减的早期信号,并诊断其成因。自适应学习与修复能力:在检测到衰减后,能够自动触发一个安全、高效、隐私保护的微调流程,对模型进行“升级”,使其恢复甚至超越原有性能,并能更好地适应未来的变化。
本文的核心思想是,将医疗边缘AI视为一个动态演化的生命体,而非一个静态部署的工具。我们主张通过编程构建一个**“监控-诊断-治疗-康复”**的全自动闭环运维机制。这套机制不仅关注模型的“初生”(训练与部署),更关注其“成长与健康”(持续的适应与优化)。本文将深入分析这一机制的每一个环节,从理论推导到算法设计,再到编程实现,最终通过一个基于BiTMedViT的模拟案例,验证其完整性和有效性。
1.4 本文主要研究内容与结构安排
为实现上述目标,本文将分为六个章节展开:
第一章:绪论。 阐述研究背景、核心问题、研究动机,并介绍全文的结构。第二章:理论基础与相关技术综述。 系统梳理模型性能衰减的理论根源、模型轻量化技术(重点分析量化)、边缘计算平台,以及持续学习、增量学习等自动微调的理论基础。第三章:面向医疗边缘AI的性能衰减监控体系设计。 提出一个多维度、轻量化的监控架构,包括数据层、特征层和决策层的监控指标,并设计基于漂移检测算法的智能诊断模块。第四章:自动化微调编程机制设计与实现。 本章是核心。将设计一个策略化的自动微调框架,包括微调触发机制、策略选择器、增量学习与遗忘缓解算法,以及包含超参数优化和安全部署的完整编程流水线。第五章:基于BiTMedViT模型的实证分析与案例研究。 搭建模拟边缘实验环境,人为引入性能衰减,验证所设计的监控与自动微调机制的有效性,并与传统方法进行对比分析。第六章:挑战、未来方向与结论。 总结全文,探讨当前研究面临的伦理、技术和工程挑战,并对未来发展方向进行展望,如与联邦学习、因果AI的深度融合。
第二章:理论基础与相关技术综述
2.1 医疗AI模型性能衰减的理论根源
性能衰减在机器学习领域通常被归因于“数据漂移”和“概念漂移”两大类别。在医疗领域,这两种漂移表现得尤为复杂和隐蔽。
2.1.1 数据漂移
定义:P(X)发生变化,即输入数据的边缘概率分布发生改变,但P(Y|X)保持不变。换言之,数据的“外观”变了,但判断逻辑没变。医疗场景实例:
设备升级/替换:医院从一代MRI设备升级到二代,图像的噪声模型、对比度、伪影类型完全改变。例如,旧设备图像信噪比低,模型学会了在噪声中识别病灶;新设备图像清晰,模型可能因“不习惯”而失效。操作者习惯:不同医师操作超声探头时,角度、压力、频率各异,导致图像的切面、亮度、组织纹理呈现系统性差异。人群统计变化:某社区医院服务的老年人口比例逐年上升,导致输入的胸部X光片中,与年龄相关的退化性病变(如肺气肿、心脏肥大)的基线患病率上升。
对量化模型(如BiTMedViT)的影响:量化过程(特别是三元量化{-1, 0, +1})会平滑参数空间的细节。这意味着模型依赖于在训练数据中学习到的非常特定的、粗粒度的特征模式。当输入数据的统计特征(如像素值的均值、方差)发生偏移,这些粗粒度特征可能无法正确匹配,导致后续Transformer层的激活值发生巨大偏差,最终输出错误的分类结果。其容错“边界”比FP32模型窄得多。
2.1.2 概念漂移
定义:P(Y|X)发生变化,即给定输入特征,其对应的输出标签的条件概率分布发生改变。这通常意味着世界的底层规律变了。医疗场景实例:
诊疗规范更新:美国糖尿病协会(ADA)下调了糖尿病的诊断血糖阈值。过去被认为是“糖耐量异常”的血糖值,现在被诊断为“糖尿病”。对于预测糖尿病风险的模型,其P(Y|X)的决策边界必须移动。新疾病/亚型出现:一种新的病毒株出现,其在CT影像上的表现与已知病毒株有细微但关键的区别。模型必须学习这些新特征,才能正确诊断。治疗手段影响:某种新药被广泛应用,改变了特定疾病的典型病程和影像学表现。例如,靶向药可能使肿瘤在影像上从“块状”变为“弥散性”。
对量化模型的影响:概念漂移要求模型更新其内部的“知识图谱”,即改变不同特征与最终决策之间的权重关系。对于量化模型,其权重被限制在几个离散值上,这极大地限制了其表达能力。简单地用新数据微调,可能无法找到一组新的、有效的离散权重组合来适应新的概念,微调过程甚至可能“卡住”,无法收敛。
2.2 模型轻量化技术:效率与鲁棒性的权衡
以BiTMedViT为代表的轻量化技术是边缘AI的基石,但它们是一把双刃剑。
2.2.1 量化
原理:将模型中通常用32位浮点数(FP32)表示的权重和激活值,用低位宽的整数或定点数(如INT8, INT4)来近似表示。分类:
训练后量化(PTQ):模型训练完成后,通过校准集确定量化参数(如scale, zero_point)。过程简单快速,但精度损失相对较大。量化感知训练(QAT):在训练过程中就“模拟”量化的影响,在反向传播时对量化操作进行梯度近似。通常能得到比PTQ更高的精度。
三元量化:一种极端的量化形式,将权重或激活值映射为{-1, 0, +1}。其优势是巨大的:乘法运算被加/减法替代,存储和计算开销极低,非常适合低端FPGA或ASIC。但劣势同样明显:信息损失严重,模型表达能力大幅下降,鲁棒性成为最大挑战。BiTMedViT能保持86%的准确率,说明其训练策略非常精妙,但这不改变其内在的脆弱性。编程要点:量化后的模型部署通常使用专门优化的推理引擎,如NVIDIA TensorRT。编程时需要生成ONNX等中间表示,并进行校准,以生成最终的TensorRT引擎。对微调后的模型进行量化(或量化微调)是一个关键且复杂的环节。
2.2.2 剪枝
原理:移除神经网络中“不重要”的连接(权重)或整个通道/滤波器。影响:减少了模型的计算量(FLOPs)和参数量。但如果剪枝不当,可能破坏模型学习到的关键特征,尤其是在应对漂移时,那些看似“不重要”的连接可能在识别新样本时起到关键作用。
2.2.3 知识蒸馏
原理:用一个大的、精确的“教师模型”来指导一个小的、轻量的“学生模型”学习。学生模型不仅要学习硬标签(ground truth),还要学习教师模型输出的软标签(logits的概率分布),从而继承教师模型的“知识”。在抗漂移中的应用:在发生漂移后,可以用在旧数据上表现良好的模型作为教师,用新数据微调出的模型作为学生,通过蒸馏的方式,让学生模型在适应新环境的同时,不忘掉旧知识,缓解灾难性遗忘。
2.3 边缘计算平台与部署框架
硬件平台:NVIDIA Jetson系列(Nano, Xavier, Orin)是目前最主流的边缘AI计算平台,集成了GPU、CPU、DLA(深度学习加速器),提供了强大的端到端AI性能。编程时需要利用其硬件特性,如使用Tensor cores、利用多线程和异步处理。软件框架:
TensorRT:NVIDIA官方的高性能推理引擎。它能对模型进行层融合、精度校准、内核自动调优,最大化发挥硬件性能。部署BiTMedViT这类量化模型,TensorRT是必经之路。编程API涉及C++和Python,需要对模型结构有深入理解。ONNX Runtime:一个跨平台的推理引擎,支持多种硬件后端,具有较好的通用性。TVM(Tensor Virtual Machine):一个更底端的、端到端的深度学习编译框架,灵活性极高,可以针对各种异构硬件生成最优化的代码,但学习曲线较陡峭。
2.4 持续学习与增量学习:自动微调的理论基石
持续学习:目标是让模型能够像人一样,持续地从新的数据流中学习新知识,同时不遗忘旧知识。增量学习:持续学习的一个子领域,通常指有新类别出现时的学习任务,如旧系统识别10种疾病,现在要新增第11种。核心算法:
基于正则化的方法:如EWC(Elastic Weight Consolidation),通过计算权重对旧任务的重要性,在微调时对重要权重施加惩罚,使其变化不大。这很适合用于防止BiTMedViT这类量化模型在微调时“跑偏”。基于回放的方法:维护一个小的“记忆缓冲区”,存储一部分有代表性的旧数据。在微调时,将新旧数据混合训练。直接回放会带来隐私和存储问题,因此生成式回放(用GAN或VAE生成旧数据)是边缘场景下的一个研究方向。基于参数隔离的方法:为每个新任务分配一部分独立的网络参数,或动态扩展网络结构。这在资源受限的边缘设备上难以实现。
这些理论和技术,共同构成了我们设计“自动微调编程机制”的工具箱。接下来的章节,我们将基于这些工具,搭建整个系统。
第三章:面向医疗边缘AI的性能衰减监控体系设计
一个无法被有效度量的系统,是无法被有效控制的。因此,一个低开销、高灵敏度的监控体系是构建自适应机制的前提。考虑到边缘设备的资源限制,监控本身也必须是轻量化的。
3.1 监控体系总体架构
我们设计一个分层、分阶段的监控架构,将监控任务按复杂度和计算需求分布在边缘设备、边缘服务器和云端。
Level 1: 边缘设备(实时、低开销监控)
职责:对每一个或每一小批推理请求进行实时监控,计算轻量级指标,进行初步的异常检测。部署:直接运行在Jetson Orin Nano等设备上,与模型推理进程并行。使用高效的C++/CUDA代码实现。数据:仅利用模型推理过程中自然产生的数据,如输入图像、模型输出的logits、中间层激活值,无需额外计算。
Level 2: 边缘服务器/网关(中期、分析型监控)
职责:汇聚来自多个边缘设备的监控数据,进行更复杂的统计分析、漂移检测,并作出初步的“诊断”。部署:部署在局域网内的边缘服务器上,如NVIDIA Jetson AGX Orin或小型服务器。数据:接收Level 1上报的统计摘要、抽样数据等。
Level 3: 云端(长期、全局监控)
职责:存储和分析来自所有边缘设备的长期历史数据,进行全局性的趋势分析、模型版本管理,并协调整个微调与分发流程。部署:云端数据中心。数据:接收Level 2上报的关键事件报告、模型性能指标等。
3.2 数据层面的监控指标
这是最直接的监控,关注输入数据X的分布P(X)是否发生偏移。
3.2.1 简单统计特征
指标:图像的均值、方差、亮度、对比度、直方图等。实现:计算成本极低。在边缘设备上对新流入的每个样本计算,并与一个滑动窗口内的历史基线进行比较(如使用t检验或简单的阈值判断)。局限性:无法捕捉更复杂的分布变化。
3.2.2 分布对齐检验
指标:Kolmogorov-Smirnov (KS)检验、Chi-squared检验、Wasserstein距离。实现:将最近一批数据的特征(可以是像素值,也可以是浅层CNN提取的通用特征)与基线数据集的特征进行比较,计算上述统计量。计算量适中,可在Level 2(边缘服务器)执行。挑战:需要维护一个基线数据集的特征表示。
3.2.3 基于深度特征的漂移检测
核心思想:直接在原始像素空间比较分布不敏感。更好的方法是使用一个预训练的强大模型(或在ViT的浅层)提取高维语义特征,然后在特征空间比较分布。方法:
选择一个鲁棒的“特征提取器”,可以是一个在ImageNet上预训练好的ResNet,甚至是BiTMedViT本身的前几层。对新来的数据流和基线数据,分别提取特征向量。使用Maximum Mean Discrepancy (MMD)或基于分类器的漂移检测器(训练一个二分类器来区分新旧数据,如果分类器性能好,说明漂移显著)来比较两个特征分布。
对BiTMedViT的特殊意义:由于BiTMedViT被量化,其深层特征可能已失真。因此,使用一个独立的、全精度的特征提取器进行漂移检测,可能更为可靠。
3.3 模型层面的监控指标
这类指标关注模型内部的“状态”和最终的“决策”,直接反映性能。
3.3.1 预测置信度
指标:模型输出logits的熵值,或最大概率值。逻辑:当一个模型遇到它不熟悉的样本时,其预测往往会趋于“犹豫”,即各类别的概率比较平均,导致熵值增高。实现:计算成本极低,只需一个
softmax
3.3.2 错误率/准确率
指标:这是黄金标准。挑战:在现实场景中,大部分流入的数据是没有真实标签的。直接计算错误率不可行。解决方案:
主动学习:当模型置信度低时,系统自动将该样本标记为“待审核”,推送给人类专家进行标注。这样可以用最小的标注成本,获取一部分真实的错误率估计。一致性检查:对于同一样本,通过数据增强(如旋转、裁剪)生成多个版本,如果模型对这些高度相似的样本给出不一致的预测,说明模型在该样本附近决策不稳定,可能发生了性能衰减。
3.3.3 中间激活值的漂移
指标:模型某些关键中间层(如ViT的Transformer块输出)激活值的统计分布。逻辑:如果输入数据分布发生改变,会像涟漪一样层层传递,导致内部激活值分布也发生偏移。监控这些“内部信号”,可以比监控最终输出更早地发现问题。实现:在部署模型时,利用TensorRT的API或自定义算子,hook出特定层的输出。在Level 1计算这些输出的均值、方差,并与基线比较。计算量适中,需权衡监控层数和开销。
3.4 轻量化监控机制的实现与编程考量
多线程与异步处理:在Jetson Orin Nano上,监控逻辑必须与模型推理并行运行,以避免增加延迟。可以使用多线程,一个线程负责推理,另一个线程负责接收推理结果并计算监控指标。内存管理:存储基线统计量和滑动窗口数据需要占用内存。设计时需优化数据结构,使用环形缓冲区等高效的数据结构。上报策略:并非所有指标都需要实时上报。可以设计一个事件驱动的上报机制:只有当Level 1的轻量级指标(如熵值)触发阈值时,才将更详细的数据(如特征向量、激活值)打包上报给Level 2进行分析。
通过这套分层、多指标的监控体系,我们能够像心电图一样,实时描绘出边缘医疗AI模型的“健康状态”,为下一步的“自动诊断和治疗”提供可靠依据。
第四章:自动化微调编程机制设计与实现
当监控系统发出“警报”后,自动微调机制就应被触发。本章将设计一个智能、高效、安全的微调流水线,它不是一个简单的“
model.fit(new_data)
4.1 自动化微调触发机制
微调不是免费的午餐,它会消耗计算资源、需要标注数据,并且带有风险(可能微调失败)。因此,必须设计一个审慎的触发机制。
事件聚合与决策:
输入:来自Level 1和Level 2的多个监控信号(如:数据漂移KS检验p值 < 0.01,且平均预测熵持续1小时高于阈值T1,且主动学习获取的10个样本中错误率达到30%)。决策引擎:可以是一个基于规则的专家系统,也可以是一个轻量级的机器学习模型(如逻辑回归),它根据这些聚合信号,输出一个“微调必要性”的概率得分。阈值与审批:当得分高于某个高阈值(如0.9)时,自动触发微调。当得分在一个中间范围(如0.7-0.9)时,可以向系统管理员发送“建议微调”的请求,等待人工确认。
伪代码示例:
class TuningTrigger:
def __init__(self, thresholds):
self.entropy_threshold = thresholds['entropy']
self.drift_pvalue_threshold = thresholds['drift_pvalue']
self.error_rate_threshold = thresholds['error_rate']
self.decision_model = self._load_decision_model()
def evaluate(self, monitoring_report):
# monitoring_report is a dict containing all metrics from a time window
features = self._extract_features(monitoring_report)
trigger_score = self.decision_model.predict_proba([features])[0][1] # Probability of needing tuning
if trigger_score > 0.9:
return 'AUTO_TRIGGER'
elif trigger_score > 0.7:
return 'MANUAL_REVIEW_REQUIRED'
else:
return 'NO_ACTION'






















暂无评论内容