
【AI学习-comfyUI学习-简易加载器抠图工作流(替换抠图节点版)-各个部分学习-第七节】
1,前言2,说明1,整个工作流说明2,各个模块说明
3,流程(1)调用模块1)整个模块部分
(2)输出 提示词(3)模型加载(4)生成图片
4,模块介绍参数说明1️⃣ **#1 简易加载器 (LEOSAM HelloWorld 模型)**2️⃣ **#2 预采样参数(动态CFG)**3️⃣ **#3 简易采样器**
✂️ 二、图像分割阶段(节点 #4 SegmentAnything Ultra V2)4️⃣ **#4 SegmentAnything Ultra V2**
💾 三、结果输出阶段(节点 #5, #6, #7)5️⃣ **#5 预览图像**6️⃣ **#6 保存图像**7️⃣ **#7 保存原图**
5,细节部分6,使用的工作流7,总结
1,前言
最近,学习comfyUI,这也是AI的一部分,想将相关学习到的东西尽可能记录下来。
2,说明
1,整个工作流说明
ComfyUI 在这里扮演了“生成 + 抠图 + 分层”的一体化管道。
生成部分由 Stable Diffusion(LEOSAM 模型)负责;
分割部分由 SAM + GroundingDINO + ViTMatte 联合执行;
最终得到 可单独使用的头发层素材,方便在后续如“发型替换”“图层叠加”“风格迁移”等任务中使用。
2,各个模块说明
| 阶段 | 模块 | 功能说明 |
|---|---|---|
| 🟢 生成 | 模型加载器 + CFG 采样器 | 根据文本提示生成人物肖像 |
| 🔵 分割 | SegmentAnything Ultra V2 | 自动检测并提取“头发”区域 |
| 🔴 输出 | 保存节点 | 分别导出原图与头发层结果 |
3,流程
(1)调用模块
1)整个模块部分
这回整个模块都可以截截图下了
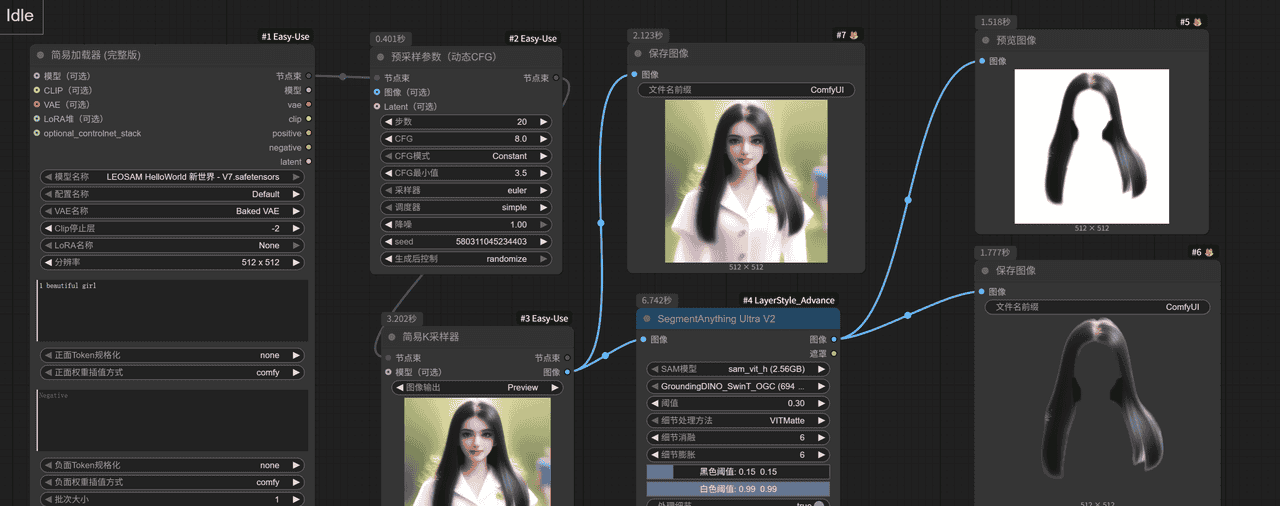
(2)输出 提示词
如下是输入提示词
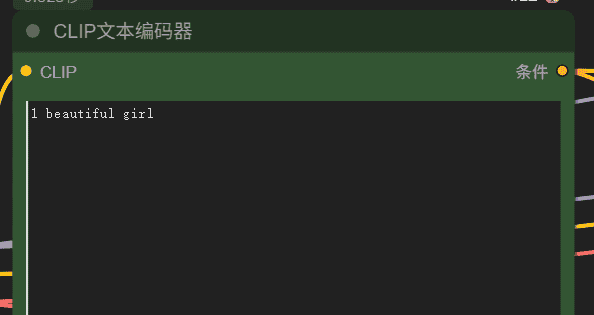
1 beautiful girl
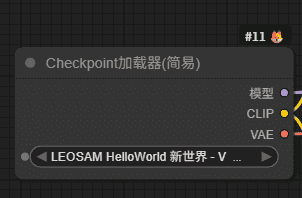
(3)模型加载
(4)生成图片
(1)生成图片

(2)扣出来的头发

4,模块介绍参数说明
1️⃣ #1 简易加载器 (LEOSAM HelloWorld 模型)
模型:LEOSAM HelloWorld V7.safetensors
功能:用于生成基础图像(此处是一张“beautiful girl”肖像)
输入:
文本提示词(Prompt):
beautiful girl
输出:潜空间 latent 图像 → 传递给下游节点
2️⃣ #2 预采样参数(动态CFG)
功能:定义生成过程的超参数,控制图像风格与一致性。
关键参数:
采样步数:20CFG 值:8.0(影响Prompt权重)调度器:
euler
1114022481631024
randomize
输出:采样设定 → 传入采样器
3️⃣ #3 简易采样器
功能:基于模型与参数生成最终图像
输入:模型输出 + CFG 参数
输出:
生成的最终图像(人物肖像)图像尺寸:512×512
✂️ 二、图像分割阶段(节点 #4 SegmentAnything Ultra V2)
4️⃣ #4 SegmentAnything Ultra V2
核心模块:实现基于语义的图像分割。
模型组合:
SAM 模型:
sam_vit_h (2.56GB)
SwinT_OCG (694MB)
关键设置:
提示词:
hair
ViTMatte
输出:
一张头发区域的 Mask(纯白背景)一张带透明通道的分割图(只保留头发)
💾 三、结果输出阶段(节点 #5, #6, #7)
5️⃣ #5 预览图像
预览结果:显示头发的分割 Mask(白底、黑发)
6️⃣ #6 保存图像
输出:带透明背景的头发 PNG 文件文件保存于 ComfyUI 输出目录
7️⃣ #7 保存原图
也保存了原始人物图像,用于后续合成或LayerStyle处理。
5,细节部分
无
6,使用的工作流
https://download.csdn.net/download/qq_22146161/92274794
7,总结
这也算各一个开始吧,我也在学习摸索中。





















暂无评论内容