
前段时间,deepseek API不稳定,于是萌生了自己搭个本地版模型来玩玩的想法。以下是本次(1)搭建模型,(2)通过open webUI提供给伙伴们日常玩耍,(3)配置API,供自己代码中调用的整个过程。超级简单!!!
第一,找了一台有固定IP的服务器(如果没有,自己电脑也可以,就是要看着IP变动)。
1.Ollama安装、下载deepseek-r1以及配置
Step 1: 通过curl添加ollama镜像源:
sudo curl -s https://packagecloud.io/install/repositories/jmorganca/ollama/script.deb.sh | bash安装ollama
sudo apt install ollamaStep 2:配置ollama,让它可以被其他IP侦听到,同时,设置API_KEY。
第一,通过以下命令,生成(或找到)配置文件
sudo systemctl edit ollama.service在打开的文件中设置加入如下命令
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
nvironment="OLLAMA_API_KEY=YOUR_API_KEY”这里面,OLLAMA_HOST中的端口为启动ollama服务时,设定的端口,API_KEY可以通过python的secrets包生成。
编辑好后运行
systemctl enable ollama.serviceStep 3: 下载并运行模型:
ollama run deepseek-r1:$version其中version是你想要部的版本(size),列如,1.5吧,7b, distill-Qwen-8b等,根据设置的内存大小选择。不过本人32G的内存,运行32B的模型,很慢,但是也运行的起来(感觉有用swap)。
原则上,运行这条命令后,ollama已经在运行了,如果需要暂停、重启等,可通过以下命令实现:
sudo systemctl start ollama.service
sudo systemctl stop ollama.service
sudo systemctl restart ollama.service2.安装 open webUI
Open WebUI 是可扩展、功能丰富好用的自托管 AI 平台(说人话,就是可以把各个LLM配置上去,配置好后,可以自动切换模型,进行聊天等)。它支持多种大型语言模型(LLM)运行器,如 Ollama 和 OpenAI 兼容的 API,并内置了推理引擎。Open webUI能自动检查本机中11434端口(ollama服务默认端口),如果这个端口在运行,它会自动连接模型。
open webUI有聚焦如下安装方法,
方法一:python 安装
运行如下两条命令就行
pip install open-webui
open-webui serve方法二:Docker安装
一条命令
docker run -d -p 3000:8080 --name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main以上是cpu允许的命令,如果想换成GPU运行,则运行
docker run -d -p 3000:8080 --gpus all --name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:cuda其中,3000是外部访问的端口,8080是默认端口,3000可改成任意可被外界访问的端口号,例如,我的服务器只有少数几个端口可被外部访问,5433是一个,于是,我把3000替换成5433
安装好之后,自己和其他人都能通过http:$your_ip: 5433访问open webUI,使用ollama安装的deepseek-r1模型进行对话。初次打开,需创建账号,创建后,进入如下界面
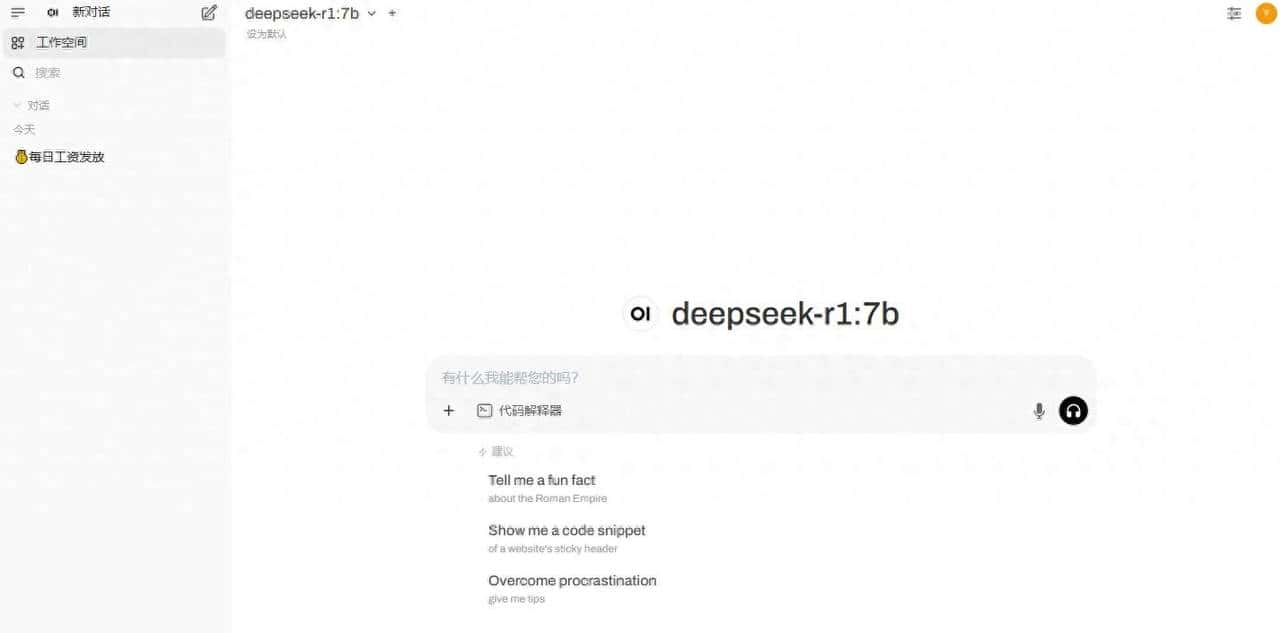
3.调用API
通过如下代码可在其他产品或者项目中调用API
import os
from ollama import Client
import json
# 获取 API 密钥
api_key = os.getenv("OLLAMA_API_KEY") #需提前在环境中设置环境变量OLLAMA_API_KEY
# 设置请求 URL 和头信息
client = Client(
host = "http://your_ip:your_port", # 如:http://127.0.0.1:3000
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
)
# 设置请求数据
response = client.chat(
model="deepseek-r1:7b",
messages = [
{
"role": "user",
"content": "Why is the sky blue?"
}
],
stream=True
)
for chunk in response:
print(chunk['message']['content'], end='', flush=True)至此,本地部署的deepseek-r1既可以在页面上直接使用,也可以在你的项目中调用了。




















- 最新
- 最热
只看作者