
在数据库系统的实际应用中,读写分离是一种非常重要的技术手段,它能够显著提升数据库的性能和可用性。在本章中,我们将聚焦于数据库中间件的读写分离,深入探讨其原理和具体的实践操作。通过学习这部分内容,你不仅能够理解读写分离的原理,还能在实际项目中运用数据库中间件实现数据库的读写分离。
目录
数据库中间件实现读写分离的原理什么是读写分离读写分离的工作机制数据库中间件的作用
数据库中间件实现读写分离的配置方法选择合适的数据库中间件配置主从数据库配置数据库中间件
用 MySQL 和数据库中间件实现读写分离代码示例项目环境搭建配置数据源和读写分离规则编写数据库操作代码测试读写分离功能
解决读写分离过程中的主从同步延迟问题主从同步延迟的原因解决主从同步延迟的方法
总结
数据库中间件实现读写分离的原理
什么是读写分离
读写分离是一种将数据库的读操作和写操作分离到不同数据库服务器上的技术。简单来说,就是把对数据库的查询操作(读操作)和插入、更新、删除操作(写操作)分别分配到不同的数据库实例上执行。这样做的好处是可以充分利用多个数据库服务器的资源,提高系统的并发处理能力和性能。
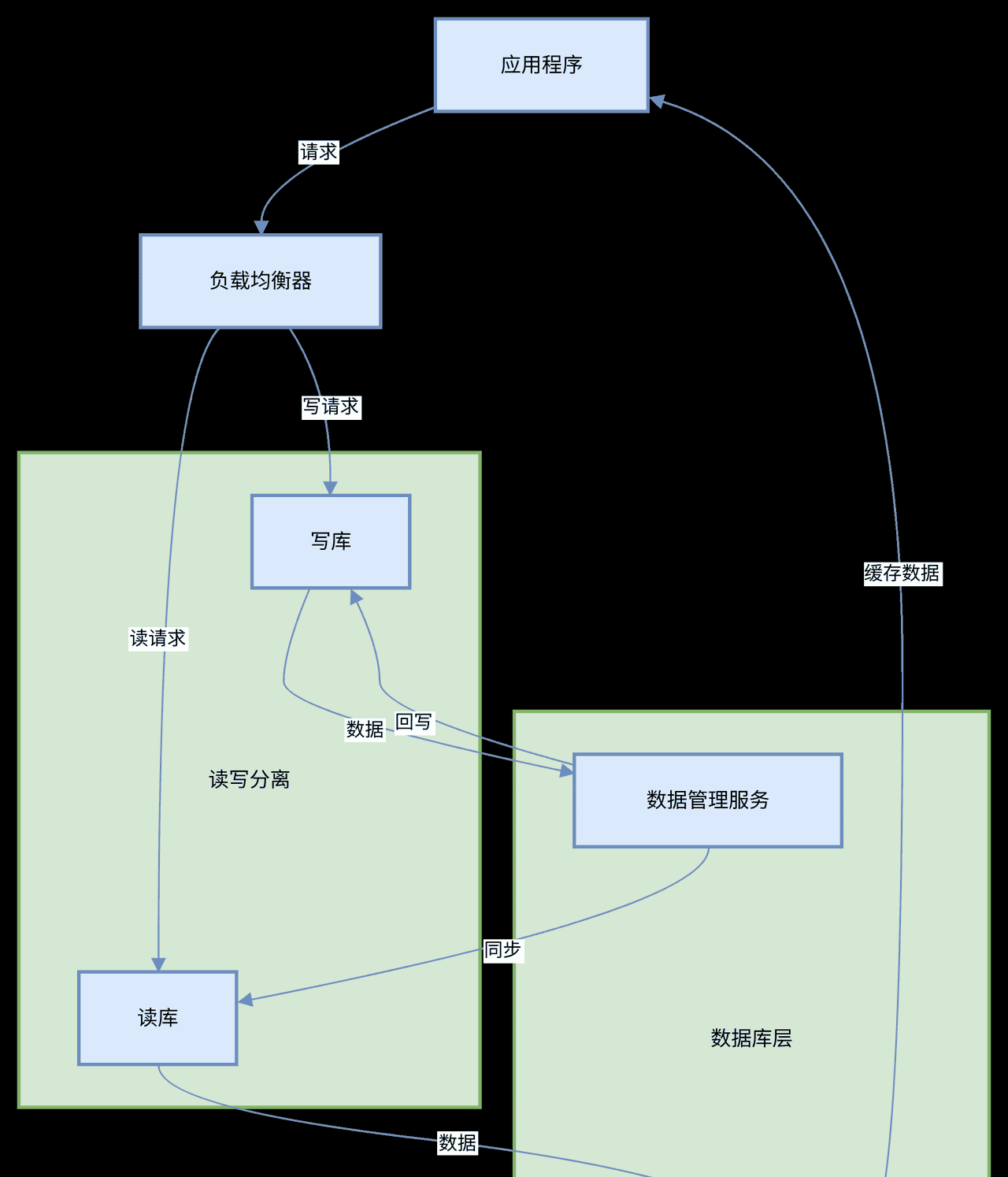
例如,在一个电商网站中,用户的商品浏览、搜索等操作属于读操作,而用户的下单、评论等操作属于写操作。如果将这些操作都集中在一个数据库服务器上,随着用户量的增加,服务器的负载会越来越高,性能也会受到影响。而采用读写分离技术,将读操作和写操作分别分配到不同的服务器上,就可以减轻单个服务器的负担,提高系统的响应速度。
读写分离的工作机制
数据库中间件在读写分离中扮演着重要的角色。它就像是一个中间桥梁,负责接收客户端的数据库请求,并根据请求的类型(读操作或写操作)将其转发到相应的数据库服务器上。
当客户端发起一个数据库请求时,数据库中间件会首先判断这个请求是读操作还是写操作。如果是读操作,中间件会将请求转发到只读数据库服务器上;如果是写操作,中间件会将请求转发到主数据库服务器上。主数据库服务器负责处理所有的写操作,并将数据的变更同步到从数据库服务器上。
例如,在一个分布式系统中,应用程序通过数据库中间件与数据库进行交互。当应用程序需要查询商品信息时,数据库中间件会将查询请求转发到从数据库服务器上;当应用程序需要更新商品库存时,数据库中间件会将更新请求转发到主数据库服务器上。
数据库中间件的作用
数据库中间件在读写分离中起到了关键的协调和管理作用。它不仅能够自动识别请求的类型并进行转发,还能实现负载均衡、故障转移等功能。
负载均衡是指数据库中间件可以将读请求均匀地分配到多个从数据库服务器上,避免某个从服务器负载过高。例如,在一个拥有多个从数据库服务器的系统中,数据库中间件可以根据每个服务器的负载情况,动态地将读请求分配到不同的服务器上,从而提高系统的整体性能。
故障转移是指当某个数据库服务器出现故障时,数据库中间件可以自动将请求转移到其他正常的服务器上,保证系统的可用性。例如,当主数据库服务器出现故障时,数据库中间件可以将写请求临时转移到备用的主数据库服务器上,确保系统的写操作能够正常进行。
数据库中间件实现读写分离的配置方法
选择合适的数据库中间件
目前市场上有很多种数据库中间件可供选择,如 MyCat、ShardingSphere 等。在选择数据库中间件时,需要考虑以下几个因素:
功能特性:不同的数据库中间件具有不同的功能特性,如支持的数据库类型、读写分离策略、负载均衡算法等。需要根据项目的实际需求选择具有相应功能的中间件。性能:数据库中间件的性能直接影响到系统的整体性能。需要选择性能稳定、处理速度快的中间件。社区活跃度:选择社区活跃度高的数据库中间件,意味着可以获得更多的技术支持和更新维护。
例如,如果项目使用的是 MySQL 数据库,并且对读写分离的性能要求较高,可以选择 ShardingSphere,它对 MySQL 的支持非常好,并且具有高性能的读写分离功能。
配置主从数据库
在实现读写分离之前,需要先配置主从数据库。以 MySQL 为例,配置主从数据库的步骤如下:
配置主数据库:在主数据库的配置文件中,需要开启二进制日志功能,以便将数据的变更记录下来。同时,需要创建一个用于主从复制的用户,并授予相应的权限。配置从数据库:在从数据库的配置文件中,需要指定主数据库的信息,如主数据库的 IP 地址、端口号、用户名、密码等。然后启动从数据库的复制进程,使其开始从主数据库同步数据。
例如,在主数据库的配置文件
my.cnf
[mysqld]
log-bin=mysql-bin
server-id=1
在从数据库的配置文件
my.cnf
[mysqld]
server-id=2
然后在从数据库中执行以下命令启动复制进程:
CHANGE MASTER TO
MASTER_HOST='主数据库IP地址',
MASTER_USER='复制用户',
MASTER_PASSWORD='复制用户密码',
MASTER_LOG_FILE='主数据库二进制日志文件名',
MASTER_LOG_POS=主数据库二进制日志位置;
START SLAVE;
配置数据库中间件
配置好主从数据库后,接下来需要配置数据库中间件。以 ShardingSphere 为例,配置步骤如下:
引入依赖:在项目的
pom.xml
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.3.2</version>
</dependency>
配置数据源:在配置文件中配置主从数据库的数据源信息。
dataSources:
master_ds:
url: jdbc:mysql://主数据库IP地址:3306/数据库名
username: 用户名
password: 密码
driverClassName: com.mysql.cj.jdbc.Driver
slave_ds_0:
url: jdbc:mysql://从数据库IP地址:3306/数据库名
username: 用户名
password: 密码
driverClassName: com.mysql.cj.jdbc.Driver
配置读写分离规则:在配置文件中配置读写分离规则,指定主数据源和从数据源的映射关系以及负载均衡算法。
rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
staticStrategy:
writeDataSourceName: master_ds
readDataSourceNames:
- slave_ds_0
loadBalanceAlgorithmName: round_robin
loadBalanceAlgorithms:
round_robin:
type: ROUND_ROBIN
用 MySQL 和数据库中间件实现读写分离代码示例
项目环境搭建
首先,我们需要搭建一个基于 Spring Boot 的项目,并引入 ShardingSphere 的依赖。在
pom.xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.3.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
配置数据源和读写分离规则
在
application.yml
编写数据库操作代码
创建一个
User
UserRepository
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private Integer age;
// 省略 getter 和 setter 方法
}
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Long> {
}
创建一个
UserService
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User saveUser(User user) {
return userRepository.save(user);
}
public List<User> getAllUsers() {
return userRepository.findAll();
}
}
创建一个
UserController
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
private UserService userService;
@PostMapping
public User saveUser(@RequestBody User user) {
return userService.saveUser(user);
}
@GetMapping
public List<User> getAllUsers() {
return userService.getAllUsers();
}
}
测试读写分离功能
启动项目后,可以使用 Postman 等工具发送请求进行测试。发送一个 POST 请求到
/users
/users
解决读写分离过程中的主从同步延迟问题
主从同步延迟的原因
主从同步延迟是指从数据库服务器上的数据与主数据库服务器上的数据存在一定的时间差。主从同步延迟的原因主要有以下几个方面:
网络延迟:主从数据库服务器之间的网络延迟会影响数据的同步速度。如果网络带宽不足或网络不稳定,数据的同步就会受到影响。主数据库负载过高:如果主数据库服务器的负载过高,处理写操作的速度会变慢,从而导致数据的同步延迟。从数据库性能不足:如果从数据库服务器的性能不足,无法及时处理主数据库同步过来的数据,也会导致同步延迟。
解决主从同步延迟的方法
为了解决主从同步延迟问题,可以采取以下几种方法:
优化网络环境:确保主从数据库服务器之间的网络带宽充足,网络稳定。可以通过增加网络带宽、优化网络拓扑结构等方式来提高网络性能。优化主数据库性能:通过优化主数据库的配置、索引等方式,提高主数据库的处理能力,减少写操作的处理时间。增加从数据库服务器:增加从数据库服务器的数量,将读请求分散到多个从服务器上,减轻单个从服务器的负载,提高数据同步的速度。使用缓存:在应用程序中使用缓存,如 Redis 等,将一些经常访问的数据缓存起来,减少对数据库的读请求。这样可以在一定程度上缓解主从同步延迟带来的影响。
例如,在应用程序中使用 Redis 缓存用户信息,当用户查询用户信息时,首先从 Redis 缓存中获取数据,如果缓存中没有数据,再从数据库中获取数据,并将数据存入 Redis 缓存中。这样可以减少对数据库的读请求,提高系统的响应速度。
总结
通过学习本节内容,我们深入了解了数据库中间件实现读写分离的原理和配置方法,并通过代码示例实践了如何使用 MySQL 和数据库中间件实现读写分离。同时,我们还探讨了如何解决读写分离过程中的主从同步延迟问题。掌握了这些内容后,你可以在实际项目中运用数据库中间件实现数据库的读写分离,提高系统的性能和可用性。
下一节我们将深入学习数据库中间件的其他功能,如分库分表等,进一步完善对本章数据库中间件实战主题的认知。
读者导航
上一篇:ShardingSphere数据库中间件:入门与使用
专栏目录:深入浅出中间件


















暂无评论内容