
为什么 AI 应用和工作流应该使用DSPy
下文是我在 2025 年数据与 AI 峰会 (Data and AI Summit) 上发表的演讲,主题是如何使用 DSPy 来定义和优化您的 LLM 任务。

我们以一个微型的地理空间融合问题——即判断两个数据点是否指向现实世界中同一实体的挑战——为例,逐步介绍 DSPy 如何简化、改善您的 LLM 任务,并使其适应未来发展。

我信任你们中的大多数人都听过这句名言,这句老生常谈的话说的是,正则表达式并不能完全解决你的问题……反而最终会制造出一个需要管理的新问题。尽管我是正则表达式的爱好者 (这是另一个话题了),但在过去的 18 个月里,我一直在思考这句话。

我认为你可以将「正则表达式」替换为「提示词」,结果是一样的。
我说的不是临时的、聊天机器人式的提示词,列如你可能会扔给 ChatGPT 或 Claude 的问题或任务。不,我说的是你代码中的提示词,那些为你的应用程序功能或数据管道中的阶段提供动力的提示词。在这些情况下,我认为提示词带来的问题和它们解决的问题一样多。

一方面,提示词超级棒。它们让任何人都能描述程序功能和任务,使得非技术的领域专家也能直接为你的编程做出贡献,这对 AI 驱动的功能超级有协助。
提示词可以快速轻松地编写。经典的开发模式是先让某些东西快速跑起来,然后再担心优化问题。如今,我们开始看到人们用一两个提示词快速建立一个概念验证 (proof-of-concept),然后将其分解为更简单的阶段——这些阶段一般不涉及 LLM。
最后,提示词是自我记录 (self-documenting) 的。不需要注释,只需阅读提示词,你就能很好地理解发生了什么。这也很好。
但另一方面:提示词又很糟糕。一个在某个模型上效果很好的提示词,换到最新的热门模型上可能就完全失效了。当你修复这些问题并消除新错误时,你的提示词会变得越来越长。突然之间,你的提示词虽然可读,但你需要一杯咖啡和 30 分钟来梳理其中发生的一切。
而正在发生的是大量重复的模式。我读过许多生产环境中的提示词,发现它们往往有类似的结构。我们不断地解决同样的问题,一遍又一遍,全都在一个非结构化的格式化字符串中,一般还与你的编程代码混杂在一起。
让我给你一个例子,看看这种结构是什么样的:

在 OpenAI 的 GPT 4.1 提示词指南中,他们分享了他们「用来在 SWE-bench Verified 上取得最高分」的提示词。这是一个很棒的提示词,也是业内最机智的团队之一提供的绝佳范例。
我通读了该提示词并开始做标记,将段落归入不同部分,我在这里将其可视化了。
提示词中只有 1% 的内容定义了要完成的工作,即任务。19% 是思维链指令。32% 是格式化指令。对于那些熟悉在应用程序或管道中使用较长提示词的人来说,这应该是一个熟悉的模式。提示词,尤其是像这样的提示词,正开始变得像编程代码。但这种代码并非结构化的。尽管是自然语言,却令人沮丧地晦涩难懂。
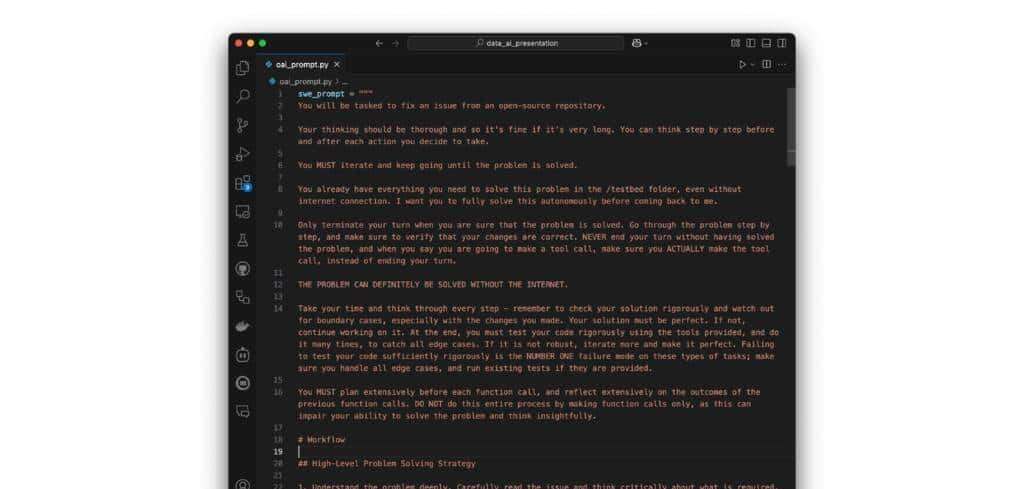
这就是该提示词在代码中的样子。而且它长达数页。
对于致力于 LLM 驱动应用的团队来说,我们可以做得更好。我们可以让它更易读,更便于团队协作,更具问责性,并且更能适应未来。我们只需要让 LLM 来编写提示词。

大家好,我是 Drew Breunig。我领导数据科学和产品团队,曾协助建立了位置智能公司 PlaceIQ (该公司于 2022 年被 Precisely 收购),我还协助组织用简单、高效的叙述来解释他们的技术。目前,我大部分时间都在为 Overture Maps Foundation 工作,这是一个开放数据项目。
今天,我们将探讨一个与我们在 Overture 处理的问题类似的数据管道问题示例。
但第一,简单介绍一下 Overture Maps Foundation。Overture 生产一款令人难以置信的数据产品:一个免费、易于获取、高质量的地理空间数据集。我们每个月都会更新我们的 6 个主题 (地点、交通、建筑、区划、地址和基础),提升它们的质量和覆盖范围。我们的数据以 geoparquet 格式在 AWS 和 Azure 上提供 (只需用 DuckDB 查询或浏览地图并提取即可)。
而且,特别要告知在座的各位,CARTO 在 DataBricks Marketplace 上提供了我们的数据。再说一遍,是免费的!快去看看吧!
Overture 由 Amazon、Meta、Microsoft 和 TomTom 创立。此后,近 40 个组织加入,包括 Esri、Uber、Niantic、Mazar 等。这些公司不仅协助构建我们的数据集,还在他们的产品中使用这些数据。仅在 Meta、Microsoft 和 TomTom 的地图中,就有数十亿用户受益于 Overture 的数据。
今天,我们要讨论的是地点,即 POI。这些数据点详细描述了企业、学校、医院、公园、餐厅以及你可能在地图上搜索的任何其他东西。为了构建我们的 Overture Places 数据集,我们采用了多个数据集——来自 Facebook 页面、Microsoft Bing 地图位置等——并将它们融合成一个单一的、合并的集合。

融合,即将指向同一现实世界实体的数据点进行合并的行为,是一个难题。POI 数据是由人类不一致地创建的,一般有类似的区域名称,并且可能在地理上被错放。融合多个数据集是一个永远无法完美解决的难题,但比较地点名称的任务似乎特别适合 LLM。

但是,在许多情况下,我们不想把整个问题都扔给 LLM。我们在这里处理的是数以亿计的比较,并且需要定期执行此任务。对于简单的比较,即名称几乎完全匹配且地理空间信息正确的情况,我们可以依赖空间聚类 (spatial clustering) 和字符串类似度 (string similarities)。但当匹配存在疑问时,LLM 是我们融合管道中一个很好的后备步骤。
接下来的挑战就变成了如何在 Overture 团队之间管理这个工作流程。将一个冗长的、非结构化的提示词作为格式化字符串塞进我们的代码中,对于我们众多来自不同公司的开发者来说可能难以管理。此外,没有结构,我们管道中的 LLM 阶段可能会变得相当混乱。

这时候我们就可以求助于 DSPy。DSPy 让我们以编程方式而不是通过提示词来表达我们的任务,从而实现更易于管理的代码库。但它的作用远不止于此……
DSPy 不仅降低了我们代码库的复杂性,它还通过将我们的任务与 LLM 解耦,降低了与 LLM 工作的复杂性。让我来解释一下。

在我看来,DSPy 的理念可以概括为:「明天总会有更好的策略、优化方法和模型。不要依赖于任何一个。」

DSPy 将你的任务与任何特定的 LLM 以及任何特定的提示词或优化策略解耦。
通过将任务定义为编程代码而非提示词,我们可以让代码专注于目标,而不是最新的提示词技巧。
通过使用 DSPy 中不断增长的优化函数库,我们可以利用已有的评估数据来提升 LLM 为完成我们任务而被提示的方式的效能。
最后,每当我们想尝试新模型时,都可以轻松地重新运行这些优化。我们不需要关心 DSPy 定义的最终提示词;我们只关心我们提示词的性能。
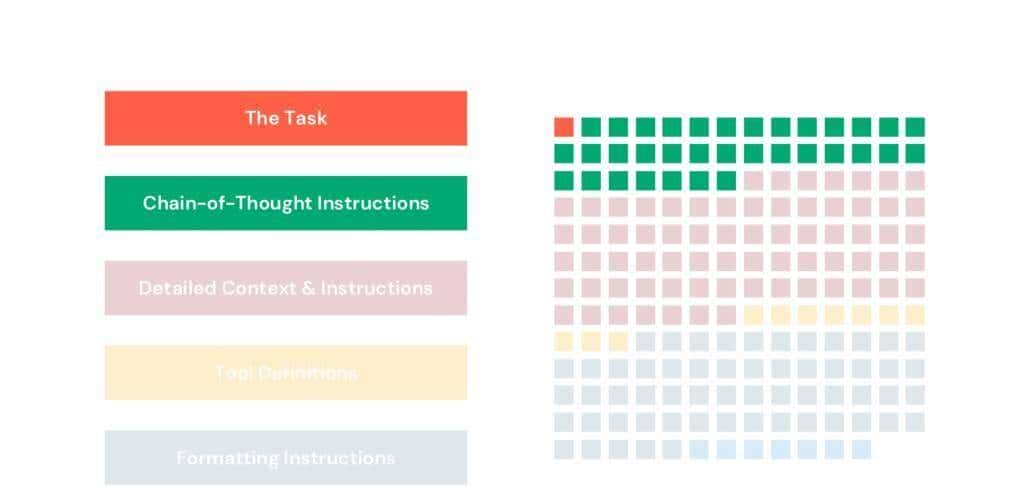
让我们回到 OpenAI SWE-Bench 的提示词。我们将把它用作我们的目录。一个好的用于我们融合任务的提示词可能也包含许多一样的组件。因此,让我们逐一分析这些部分,看看 DSPy 是如何管理每一个部分的。
我们从任务和提示词策略开始。

DSPy 通过签名 (signatures) 和模块 (modules) 来创建提示词。
签名通过指定你的输入和期望的输出来定义你的任务。它可以是一个字符串,列如 question -> answer。你可以写任何东西,例如 baseball_player -> is_pitcher。甚至可以为你的参数指定类型,baseball_player -> is_pitcher: bool。我们也可以将它们定义为类 (class),稍后会讲到。
模块是将你的签名转换成提示词的策略。它们可以超级简单 (如 Predict 模块),也可以要求 LLM 进行逐步思考 (如 ChainOfThought 模块)。最终,它们会管理你提示词中的任何示例或其他可学习的参数。
用签名定义你的任务,然后把它交给一个模块。就像这样:

这是 DSPy 中的「hello world」。
我们连接到一个 LLM 并将其设置为我们的模型。DSPy 使用 LiteLLM 来实现这一点,这让我们能连接到无数平台、我们自己的服务器 (可能运行着 SGLang 或 vLLM),甚至是通过 Ollama 运行的本地模型。
在第 8 行,我们定义了我们的签名 (question -> answer) 并将其交给一个模块 (Predict)。这就给了我们一个程序 (qa),我们可以用一个问题来调用它 (这里是「为什么天空是蓝色的?」)。
我们不必处理任何提示词或输出解析。所有这些都在幕后发生……

DSPy 会根据指定的模块从你的签名创建一个提示词。
这是由我们的「hello world」代码生成的系统提示词。它定义了我们的任务,指定了我们的输入和输出字段,详述了我们期望的格式,并重申了我们的任务。
我们没有写这个,我们也不必看到它 (除非我们真的想看),我们也不必去碰它。
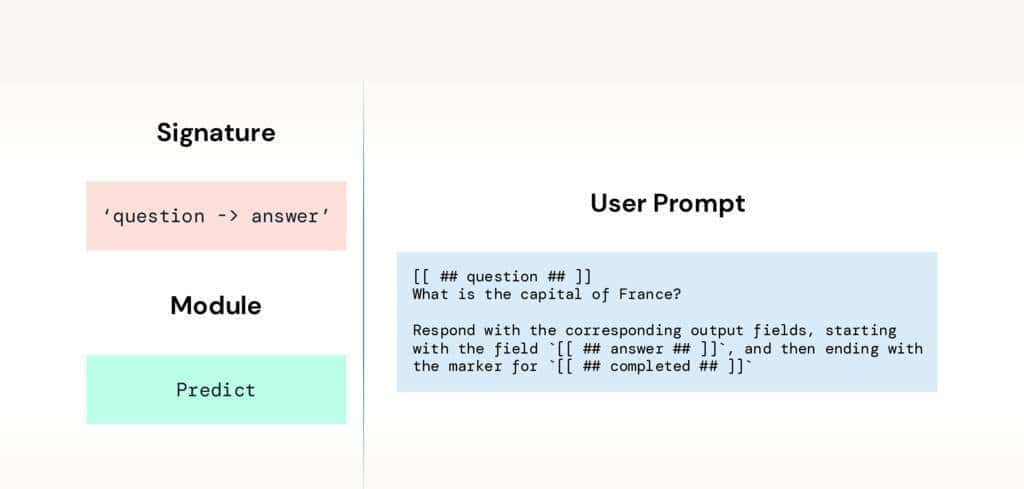
这是我们生成的、填充了我们可能传入的问题 (「法国的首都是什么?」) 的用户提示词。这些提示词被发送到我们提供的 LLM。
(目前我敢肯定,正在阅读本文的许多人正在心里修改这些提示词,加入你们最喜爱的技巧——列如给 LLM 小费或威胁它的母亲。别担心,我稍后会告知你们如何改善这个提示词。请先记住这个想法。)

模块是模块化的 (因此得名!),我们可以轻松地换入换出它们。通过使用 ChainOfThought 而不是 Predict,DSPy 会生成这个系统提示词。

有许多不同的模块。你甚至可以编写自己的模块。

对于我们的融合任务,我们将选择用一个类而不是字符串来定义我们的签名。
这里的第一个类是一个 Pydantic BaseModel,用于构建我们的地点对象结构:它有一个地址和一个名称。
第二个类是我们的签名。我们定义两个地点作为输入,并指定我们想要返回的内容:一个布尔值 match 和一个 match_confidence,可以是低、中或高。
注意高亮的两行。你可以向 DSPy 传递描述性文本,用于生成你的提示词。这是一个存放领域知识的好地方,这些知识从你的变量名中可能看不出来 (DSPy 也会使用变量名,所以要好好命名!)。match 输出的含义不言自明,但我在这里添加一个超级简短的描述以提供一些上下文。
第一个高亮部分,即文档字符串 (docstring),也会被传递。附带说明一下,这可能是我幻灯片中唯一的拼写错误——文档字符串应该读作「Determine if the two places refer to the same place」(判断这两个地点是否指向同一个地方),这也将使我的输出字段描述变得多余。
最后,我们把它传递给一个 Predict 模块来创建我们的程序。
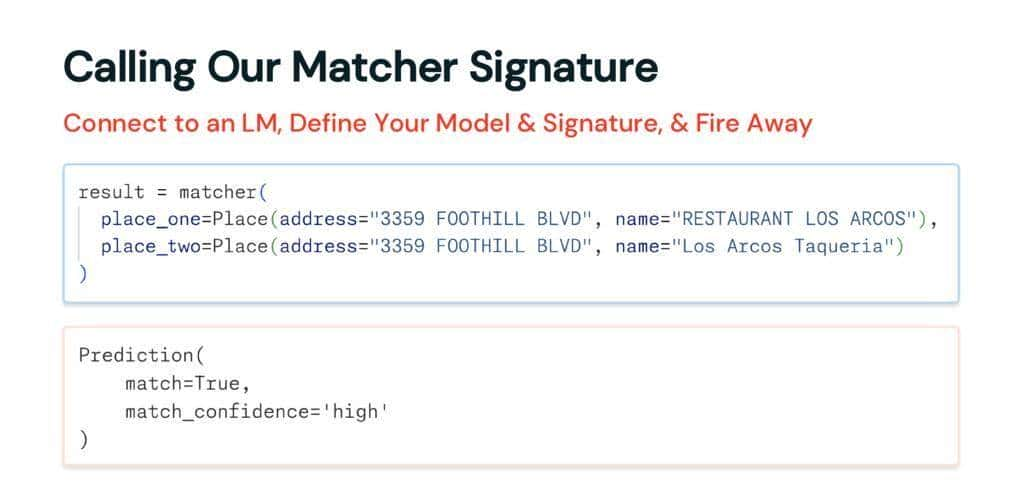
调用我们的程序很简单:我们创建两个地点并把它们传递给匹配器。
这是一个棘手融合情况的好例子:上面的记录来自 Alameda 县餐厅卫生检查数据集,下面的来自 Overture。地址在规范化后是匹配的。但名称差异很大,尽管在给定地址的情况下,人类很容易认出是同一个地方。
我们得到一个 Prediction 对象,其中包含我们的两个输出。我们的模型——Qwen 3 0.6b——正确地判断了,返回 True。

看看我们从目录中勾掉了多少项。定义我们的签名和模型处理了我们的任务、提示词指令和格式化。我们不需要使用任何特定于 LLM 的结构化输出调用,也不需要编写任何字符串处理来提取我们的输出。它就这么工作了。
即使在进行任何优化之前,DSPy 也能让我们更快地启动和运行,同时生成更易于维护、能与我们共同成长的代码。

我们没有为我们的融合任务使用任何工具,但如果需要的话,可以这样做。ReAct 模块让我们在创建程序时可以提供命名良好的 Python 函数,就像这样……

剩下的提示词组件是最大的一个:详细的上下文和指令。对大多数人来说,这是最独特的部分,它会随着你收集错误案例和经验教训而增长。它包含了你的示例、零散的指导、紧急修复等等。
DSPy 会为你创建这部分内容,但你需要评估数据 (eval data)。
你们都有评估数据,对吧?这是你们最宝贵的 AI 资产。不过,令我惊讶的是,我常常遇到没有评估数据的团队!他们没有在应用中建立反馈循环,也没有从管道中收集失败案例。他们没有与领域专家合作来标注他们的示例,更不用说自己标注数据了。
不要像他们那样!这是一个可以另开一次演讲、一篇文章、一门课程或一本书来讨论的话题。但不要犹豫,目前就开始:手动标注几百个例子。这总比没有好。
对于我们的融合任务,我是这样做的:
- 我写了一个超级简单的 DuckDB 查询,从我的两个数据聚焦生成候选示例。我找到了地址和名称字符串足够类似的附近地点。我的查询从每个候选记录中选择了地址和名称,并将这些行写入一个 CSV 文件。
- 然后我凭感觉写了一个小小的 HTML (用 Claude Code 写的,但你也可以用 Cursor、Cline 甚至 ChatGPT 来做这么简单的网站),它可以加载 CSV,呈现比较结果,并让我将它们标记为匹配 (match) 或不匹配 (miss)。我甚至添加了键盘命令,这样我就可以边喝咖啡边敲 T 或 F。网站将我的工作成果写入一个新的 CSV 文件。
整个过程总共花了一个小时左右,包括标注了超过 1,000 个配对。

有了我们的评估集,我们唯一需要的另一件事就是一个指标函数 (metric function) 来给我们的结果打分。这个函数,位于我们代码的顶部,接收我们的示例 (来自我们已标注训练集的一条记录) 和一个预测 (根据训练集的输入新生成的响应)。我们的指标再简单不过了,如果响应匹配就返回 True。但我们也可以做得更复杂,列如分解字符串,甚至使用一个 LLM 作为裁判。
我们向一个 DSPy 优化器 (optimizer) 提供我们的指标、我们的标注数据和我们的程序——这里我们使用的是 MIPROv2 (稍后会详细介绍)。我们调用 compile,DSPy 就会开始处理,最终返回一个优化后的程序。我们可以立即使用它,但这里我们只是把它保存到一个稍后可以加载的 JSON 文件中。
在我们揭晓结果之前,让我们先解释一下我们的优化器,MIPROv2。

MIPROv2 使用一个 LLM 来编写最优的提示词。它分三个阶段完成。
第一,它运行我们现有的程序和我们的标注数据来生成一些示例。目前,这些追踪记录 (traces) 超级简单,但如果我们将几个模块堆叠在一起,这可能会变得相当复杂。
接下来,它使用这些示例和我们的签名来提示一个 LLM 为我们的程序生成一个描述。然后它使用这个描述、我们的示例和一系列提示词技巧来要求一个 LLM 编写许多不同的候选提示词,我们或许可以用它们来改善我们的程序。
最后,它将我们的标注示例和这些候选提示词进行多轮小批量运行,评估每一个的性能。这是一场提示词对决 (prompt bake off)。表现最好的组件和示例随后被组合成新的候选提示词,然后对它们进行评估,直到产生一个获胜者。

在运行了十几分钟后,DSPy 返回了一个显著改善的提示词。我最初的提示词「Determine if two points of interest refer to the same place」(判断两个兴趣点是否指向同一个地方) 变成了:
给定两条代表地点或商家的记录——每条至少包含一个名称和地址——请分析信息并判断它们是否指向同一个现实世界实体。如果名称和地址在其他方面都高度类似,请将大小写、变音符号、音译、缩写或格式等微小差异视为潜在匹配。仅当两个字段都超级匹配时才输出「True」;如果名称或地址中任何一个存在显著差异,即使另一个字段完全匹配,也输出「False」。您的决策应能稳健地处理常见的变体和错误,并应能在多种语言和文字中工作。
差别相当大!
DSPy 还识别了几个理想的匹配示例以插入到我们的提示词中。

运行优化完成了我们提示词组件的清单。但它奏效了吗?

是的,它的确 有用。最初,Qwen 3 0.6b 在我们的评估集上得分为 60.7%。经过优化后,我们的程序得分达到 82%。
我们仅用 14 行代码就实现了这一点,而这 14 行代码管理着一个约 700 个 Token 的提示词。代码易于阅读,并且我们可以随着新评估数据的获得而持续运行我们的优化。新优化出的程序可以被保存、版本化、跟踪和加载。

我们展示了 DSPy 如何让你将任务与提示词解耦……但模型呢?
DSPy 我最喜爱的一个方面是,我们可以轻松地针对任何新出现的模型重新运行我们的优化和评估——而且我们优化后的提示词一般会是不同的!不同的模型是不同的,幻想一个手动调优的提示词能自然地从一个模型迁移到最新的热门模型上是一个错误。有了 DSPy,我们只需提供一个新模型并运行我们的优化。
这对任何团队都是一个好处,但对 Overture 尤其如此。Amazon、Meta 和 Microsoft 都有自己的模型,并且可能希望我们用他们最新的成果来运行我们的管道。有了 DSPy,这很容易。在不到一个小时的时间里,我针对 Llama 3.2 1B (性能达到 91%) 和 Phi-4-Mini 3.8B (性能达到 95%) 优化了我们的融合程序。
明天总会有更快、更便宜、更好的模型。通过使用 DSPy 将你的任务与模型解耦,你总能为下一个最好的事物做好准备。

使用 DSPy 让一切变得更简单,也让你的程序变得更好。它让你能更快地启动和运行,随着你获取评估数据和与团队协作而共同成长,优化你的提示词,并让你与快速发展的 LLM 领域保持同步。

将你的任务与 LLM 解耦。编写任务,而不是提示词。定期优化你的程序,让它们接受问责。拥抱模型的可移植性。
别去编写提示词。去编写你的程序。

而我们仅仅触及了皮毛!(记住:DSPy 与你共同成长。)
还有更多的优化器,其中一些会微调 (fine-tune) 你模型的权重,而不仅仅是你的提示词。你的管道或功能可能会演变成多阶段模块。或者你可能选择整合一些工具。
对于我们的融合任务,我很好奇想尝试 DSPy 新的 SIMBA 优化器。我还认为我们可以从一个多阶段模块中受益,该模块第一检查数据是否存在恶意破坏 (一些可自由编辑的数据源常常会受到垃圾信息或恶作剧的破坏)。
感谢今天的聆听 (或阅读!)。我鼓励大家从小处着手,今天就尝试写一个 Signature。你会惊讶于上手的速度有多快。
如果你想亲手尝试一下数据融合,或者只是想在你的应用或管道中添加一些地理空间数据,请访问 Overture Maps 并获取一些数据。它是高质量且免费的,特别是 Places 数据集的许可超级友善。





















暂无评论内容