
requests模块是一个常用的html网页请求库,具有请求信息和返回信息的功能
import requests 导入模块
url=”https://www.baidu.com/” 这是网址,字符串数据类型
x = requests.get(url) 使用get()函数获取网址信息,包含整个网页数据,赋值给x
print(x.text)
输出为什么不是直接返回x,而是x.text,这里可以运行看一下,如果我们直接print(x)
返回的只是状态码200,这代表着网页可以正常访问,但没有其他数据,这显然不是我们想要的结果。
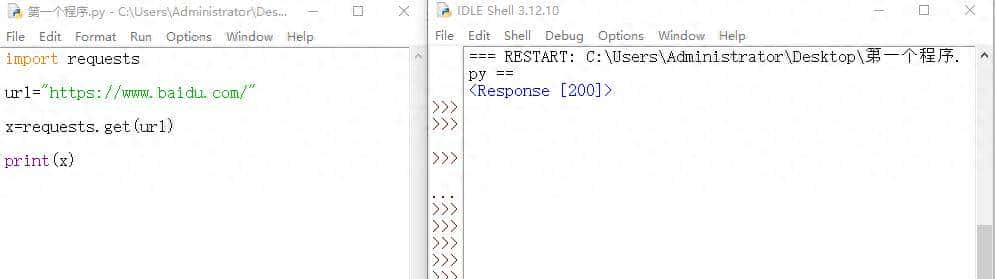
x.text的作用是让代码给我们网页信息,而不是只给我们返回状态码200。
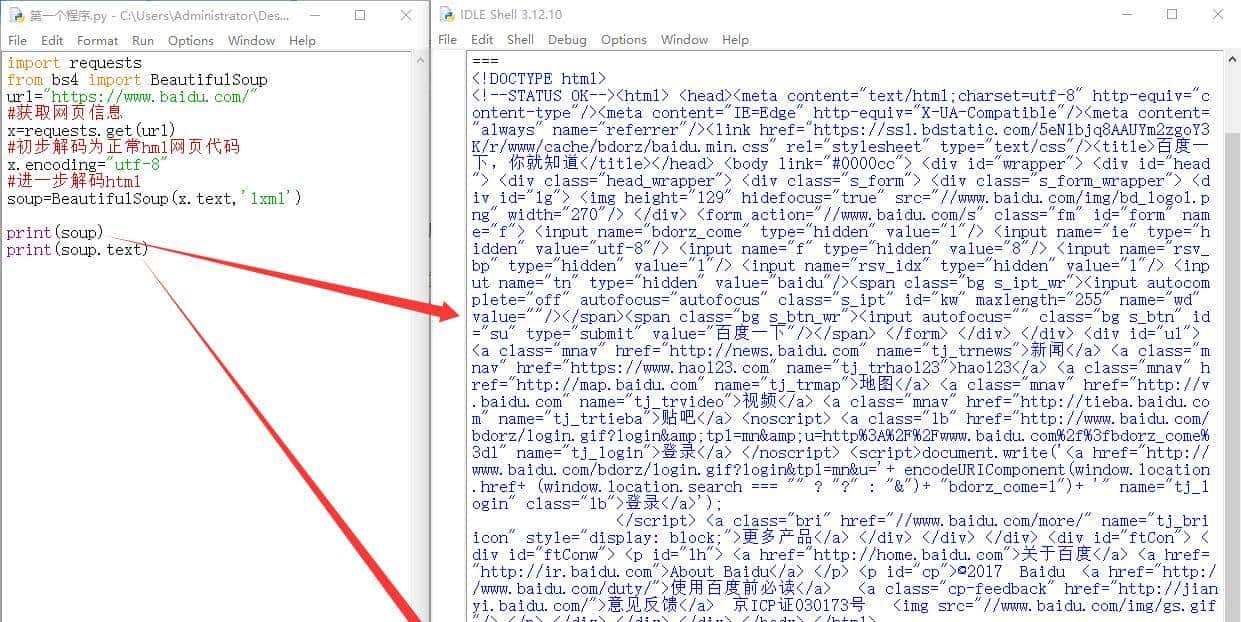
下面是文本化后的百度网页内容,有网页源码了,但有许多乱码,上面甚至看不到一个汉字。
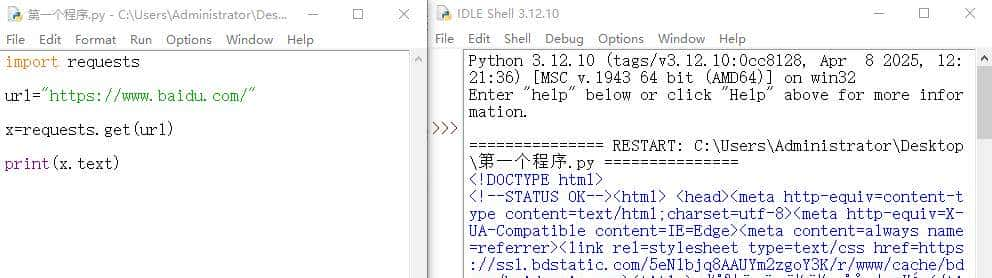
这时候,我们就需要一个解码工具,这是request模块自带的encoding解码方式,解码之后很明显,有百度一下等几个汉字。
这时候的网页就是一个正常的html网页
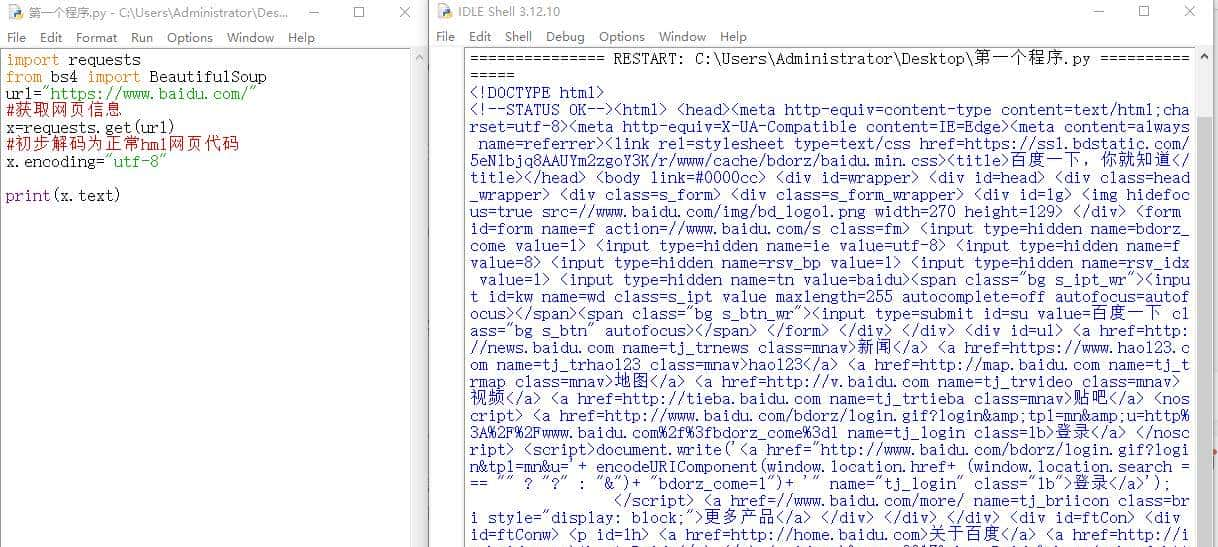
x.encoding=”utf-8″ 解释一下,这是让乱码的网页信息以utf-8的方式解码,将乱码还原成正常的网页编码,而utf-8是什么?简单来说,如果网页代码是英文的话,utf-8就是中英词典,将英文翻译成汉语。
除了常见的utf-8外,还有一种gbk编码方式,那我们如何确定网页的编码方式呢?
可以在网页按F12或者鼠标右键点开查看源码文件,一般在前一两行的网页代码中找到charset=”utf-8“,charset是字符集的意思,说明这整个网页是用utf-8的编码方式写的。
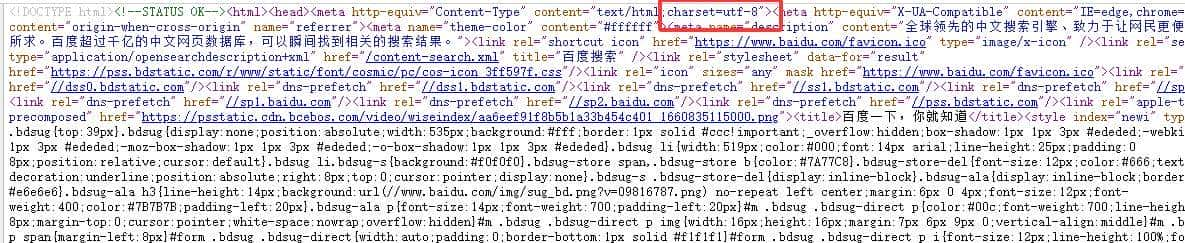
到这里为止,python新手所需要的requests模块知识点暂时足够了。
BeautifulSoup模块特别适用于解析 HTML 和 XML 文件,requests的encoding的解码能力恰好就是将乱码转为正常的HTML代码,所以接下来需要BeautifulSoup专门的解码模块来接手。
from bs4 import BeautifulSoup 这段代码是导入模块的意思,从bs4模块导入BeautifulSoup,这是导入模块的另一种常用写法。
bs4是BeautifulSoup4这个模块的简写,BeautifulSoup则是bs4这个完整模块的一部分,由于bs4整个模块比较大,全部导入没有必要,所以我们只导入BeautifulSoup这部分。
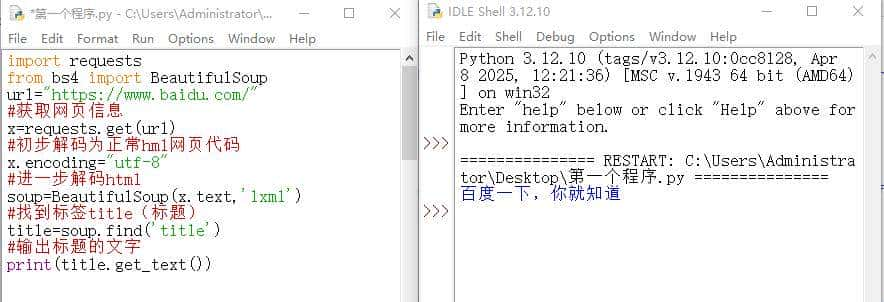
soup=BeautifulSoup(x.text,'lxml'),这里的lxml是一个解析器,python自带的解析器是html.parser,有时解码能力不够会乱码,所以最好选用lxml解析,它的解码能力更强。
lxml是需要另外安装的模块,在命令提示符的窗口安装,输入:pip install lxml后按回车
BeautifulSoup有几个很常用的函数,分别是find()、find_all()、get_text()
find():在网页代码中只找一个最先找到的标签
find_all():在网页代码中找到所有符合条件的标签
get_text():获取标签中的文本,也就是汉字
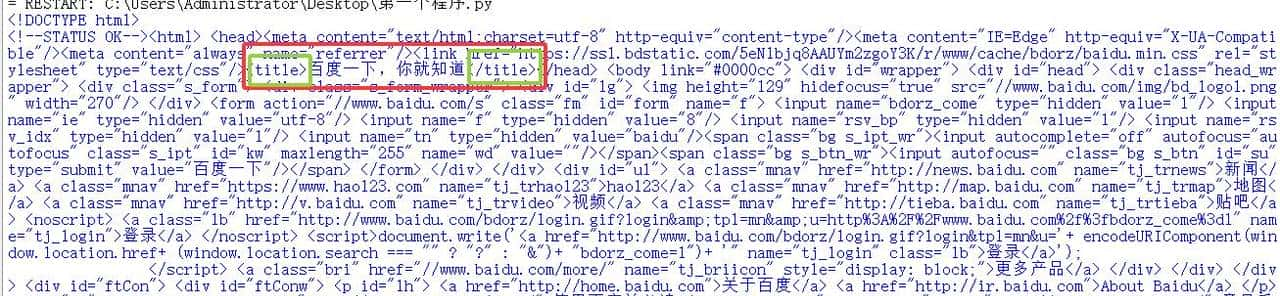
上面的代码同时使用了find()和get_text()两个函数,准确找到了'title'内的文字,title是标题的意思。
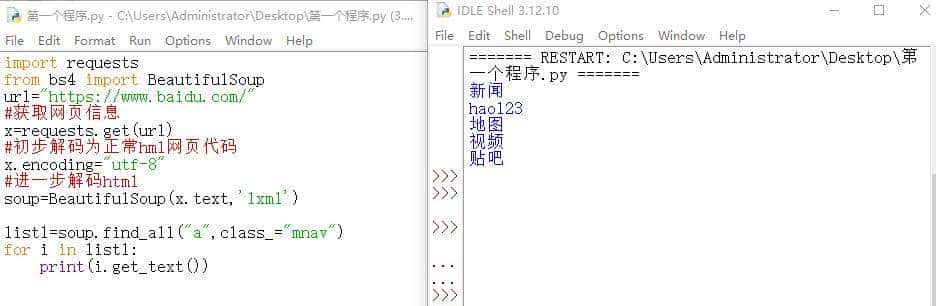
上面的代码同时使用了find_ll()、get_text()两个函数,准确找到了相关标签内的文字。
至于为什么要用for循环来输出,由于find_all找出来的数据是一个列表,每一个值都是包含汉字的长代码,需要遍历每一个值经过get_text()函数提取汉字。
find_all和for循环语句一般是连用的。
BeautifulSoup的重点就是BeautifulSoup(x.text,'lxml'),解析requests的HTML编码,
还有三个重大函数find()、find_all()、get_text()。
总结一下,本节主要是讲了requests模块如何获取网页信息并简单还原成html源代码,接着是BeautifulSoup将html原代码通过lxml解析器进一步解析,合理使用三个函数和for循环找到相应的文字并输出。
如果你看懂这章节,祝贺你,已经初步学会了python爬虫,可以尝试爬取其他网页的文字。




















暂无评论内容