
别再手动复制粘贴了!Python一招搞定PDF转图片,效率提升10倍!
还在为PDF转图片头疼?手动复制粘贴格式全乱,100页的文档要折腾一下午?今天教你用Python几行代码搞定,10秒钟解决战斗,办公室小白也能轻松学会!
✨ 学会这招,你能收获什么?
告别这些痛苦:
❌ 手动截图100页PDF,截到手抽筋
❌ 复制粘贴格式乱七八糟,重新排版累死人
❌ 在线工具限制多,文件大了就不让转
❌ 付费软件几百块,还带水印影响使用
学会能收获什么?
✅ 10秒处理100页:效率提升720倍,同事都惊呆了
✅ 高清无损输出:DPI随意调,印刷级质量随意选
✅ 完全免费使用:一次学会终身受用,省下软件费
✅ 批量自动处理:上百个文件一键搞定,喝杯茶就完成
准备工作(3分钟搞定环境)
第一步:激活Python环境
conda activate Tools3.11> 没有这个环境?先创建:`conda create -n Tools3.11 python=3.11`
第二步:安装神器库
pip install PyMuPDF Pillow tkinter这三个库是干啥的?
PyMuPDF:PDF处理专家,比Adobe还专业
Pillow:图像处理大师,让图片完美输出
tkinter:界面制作工具,让程序更友善
核心代码(复制即用)
import fitz PyMuPDF的别名
from PIL import Image
import tkinter as tk
from tkinter import filedialog, messagebox, ttk
import os
import threading
class PDFToImageConverter:
def __init__(self):
创建主窗口
self.root = tk.Tk()
self.root.title("PDF转图片神器 v1.0")
self.root.geometry("600x400")
self.root.resizable(False, False)
设置样式
style = ttk.Style()
style.theme_use('clam')
self.setup_ui()
def setup_ui(self):
标题
title_label = tk.Label(self.root, text="PDF转图片工具",
font=("微软雅黑", 16, "bold"), fg="2E86AB")
title_label.pack(pady=20)
文件选择区域
file_frame = tk.Frame(self.root)
file_frame.pack(pady=10)
self.file_path_var = tk.StringVar()
file_entry = tk.Entry(file_frame, textvariable=self.file_path_var,
width=50, font=("微软雅黑", 10))
file_entry.pack(side=tk.LEFT, padx=5)
select_btn = tk.Button(file_frame, text="选择PDF文件",
command=self.select_file, bg="4CAF50", fg="white")
select_btn.pack(side=tk.LEFT, padx=5)
设置区域
settings_frame = tk.LabelFrame(self.root, text="转换设置",
font=("微软雅黑", 10))
settings_frame.pack(pady=20, padx=20, fill="x")
DPI设置
dpi_frame = tk.Frame(settings_frame)
dpi_frame.pack(pady=5)
tk.Label(dpi_frame, text="图片质量(DPI):").pack(side=tk.LEFT)
self.dpi_var = tk.StringVar(value="150")
dpi_combo = ttk.Combobox(dpi_frame, textvariable=self.dpi_var,
values=["72", "150", "300", "600"], width=10)
dpi_combo.pack(side=tk.LEFT, padx=10)
进度条
self.progress_var = tk.DoubleVar()
self.progress_bar = ttk.Progressbar(self.root, variable=self.progress_var,
maximum=100)
self.progress_bar.pack(pady=10, padx=20, fill="x")
状态标签
self.status_label = tk.Label(self.root, text="请选择PDF文件开始转换",
fg="666666")
self.status_label.pack(pady=5)
转换按钮
convert_btn = tk.Button(self.root, text="开始转换",
command=self.start_conversion,
bg="FF6B6B", fg="white",
font=("微软雅黑", 12, "bold"))
convert_btn.pack(pady=20)
def select_file(self):
"""选择PDF文件"""
file_path = filedialog.askopenfilename(
title="选择PDF文件",
filetypes=[("PDF文件", "*.pdf")]
)
if file_path:
self.file_path_var.set(file_path)
self.status_label.config(text=f"已选择: {os.path.basename(file_path)}")
def start_conversion(self):
"""开始转换(在新线程中运行)"""
if not self.file_path_var.get():
messagebox.showwarning("警告", "请先选择PDF文件!")
return
在新线程中运行转换,避免界面卡死
thread = threading.Thread(target=self.convert_pdf)
thread.daemon = True
thread.start()
def convert_pdf(self):
"""核心转换逻辑"""
try:
pdf_path = self.file_path_var.get()
dpi = int(self.dpi_var.get())
创建输出文件夹
output_dir = os.path.join(os.path.dirname(pdf_path), "转换结果")
os.makedirs(output_dir, exist_ok=True)
打开PDF文件
pdf_document = fitz.open(pdf_path)
total_pages = pdf_document.page_count
self.status_label.config(text=f"开始转换,共{total_pages}页...")
for page_num in range(total_pages):
获取页面
page = pdf_document[page_num]
设置缩放比例(控制图片质量)
zoom = dpi / 72 72是PDF的默认DPI
mat = fitz.Matrix(zoom, zoom)
渲染页面为图片
pix = page.get_pixmap(matrix=mat)
保存图片
output_path = os.path.join(output_dir, f"第{page_num + 1}页.png")
pix.save(output_path)
更新进度
progress = (page_num + 1) / total_pages * 100
self.progress_var.set(progress)
self.status_label.config(text=f"正在转换第{page_num + 1}页...")
让界面响应
self.root.update()
pdf_document.close()
转换完成
self.status_label.config(text=f"转换完成!共生成{total_pages}张图片")
messagebox.showinfo("成功", f"转换完成!
输出目录:{output_dir}")
自动打开输出文件夹
os.startfile(output_dir)
except Exception as e:
messagebox.showerror("错误", f"转换失败:{str(e)}")
self.status_label.config(text="转换失败,请检查文件")
def run(self):
"""运行程序"""
self.root.mainloop()
运行程序
if __name__ == "__main__":
app = PDFToImageConverter()
app.run()代码解析(看懂这几个关键点):
1. `fitz.open()`:打开PDF文件,就像用钥匙开门
2. `get_pixmap()`:把PDF页面变成图片,相当于拍照
3. `Matrix(zoom, zoom)`:控制图片质量,zoom越大越清晰
4. 多线程处理:避免界面卡死,用户体验更好
效果展示(见证奇迹的时刻)
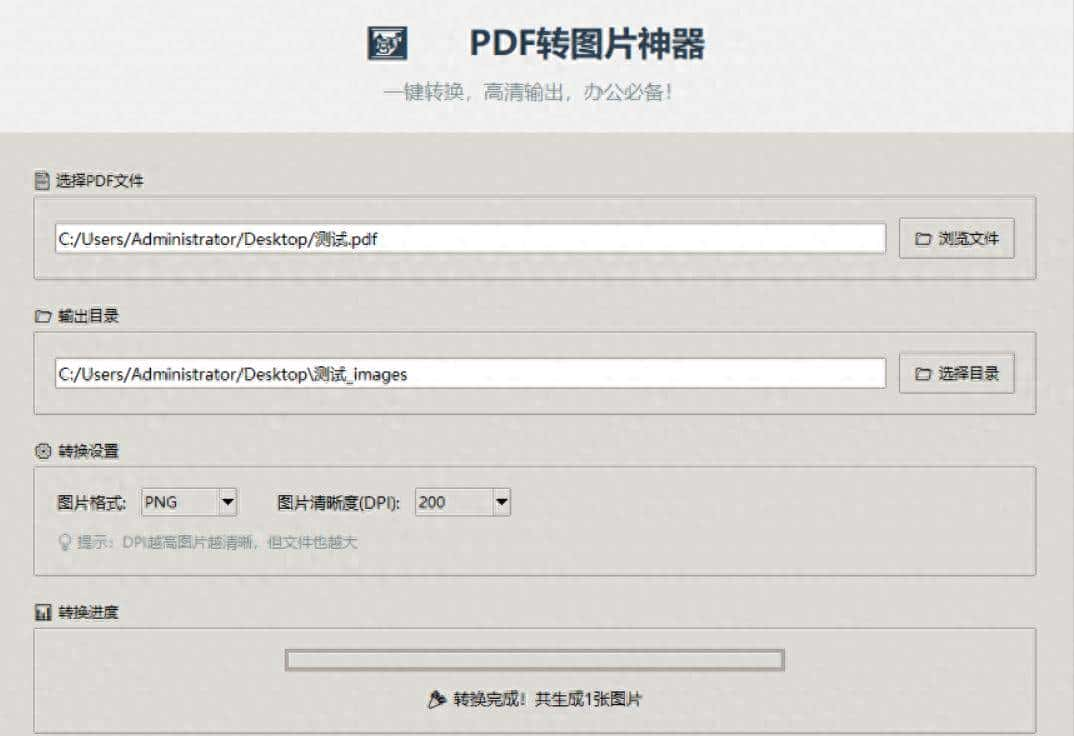
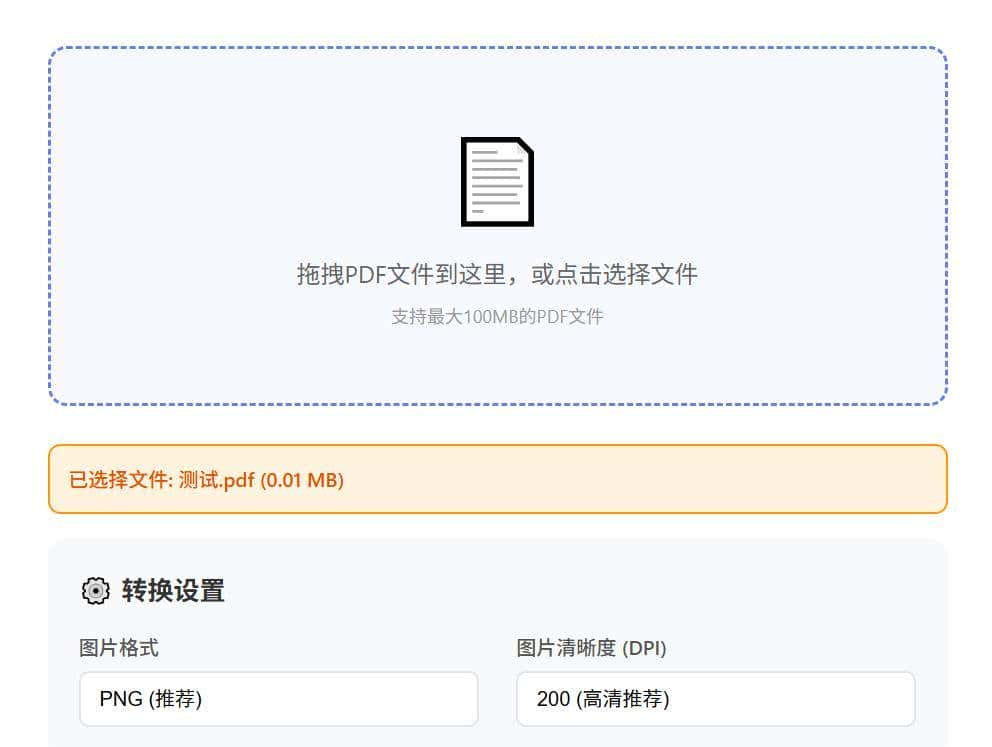
进阶功能(更强劲的版本预告)
v2版本 Web界面版
浏览器直接使用:不用安装任何软件
手机也能用:随时随地处理文档
拖拽上传:文件拖进去就开始转换
实时进度:转换状态一目了然
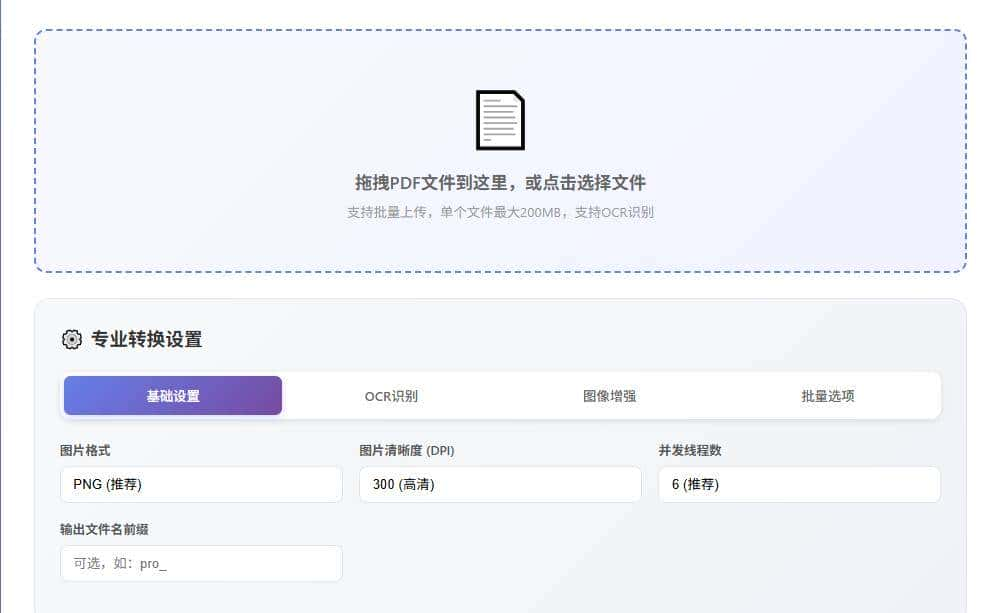
v3版本 批量处理版
并发处理:同时转换10个PDF,速度提升300%
智能分类:自动按文件名创建文件夹
断点续传:意外中断也不怕,继续接着转
性能监控:CPU、内存使用情况实时显示
v4版本 AI增强版
OCR文字识别:图片中的文字自动提取
✨ AI图像增强:模糊文档变清晰,老旧扫描件焕然一新
表格识别:自动识别表格并导出Excel
智能分析:生成详细的处理报告
—
你平时被什么重复工作困扰?评论区告知我,下期教你用Python解决!
列如:
Excel表格自动生成图表?
Word文档批量格式调整?
邮件自动发送带附件?
️ 图片批量压缩和重命名?
评论区告知我,你学Python时还遇到什么困难?
—
点赞 + 收藏⭐ + 关注,更多Python实战技巧持续更新!
#Python办公自动化# #PDF转图片# #效率工具# #编程实战# #办公神器#



















- 最新
- 最热
只看作者