
0、前言:
在linux中,默认一切都是文件,所以文件操作就显得很重要了,包括linux中用户态读写文件,内核态处理用户态调用对应字符设备文件的操作,这些都需要c语言中的文件操作函数,因此有必要进行总结和学习探究。这篇文章重点是搞清楚更通用、跨平台的标准库文件操作。对于linux系统调用文件操作,了解主要函数的主要功能即可。
补充:
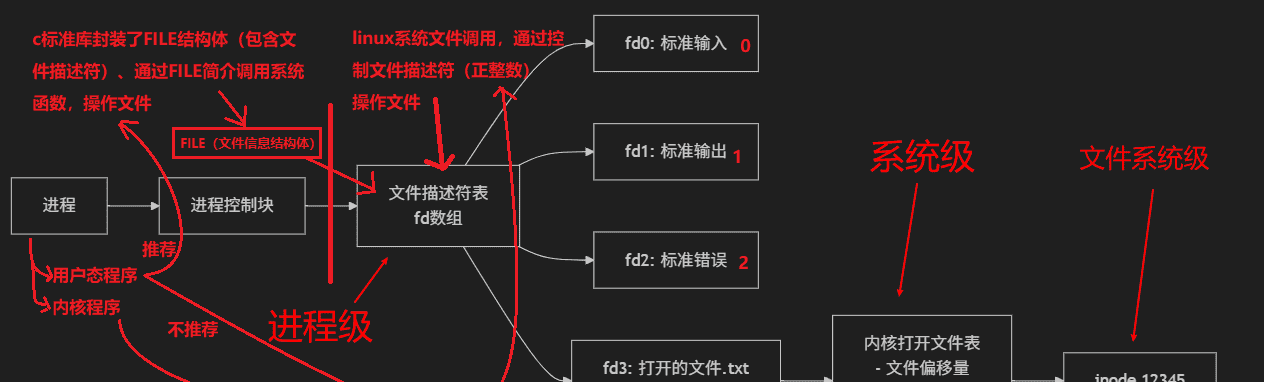
add_操作系统中如何管理文件
进程级:文件描述符表(每个进程独立)系统级:打开文件表(全局,记录当前打开文件状态)文件系统级:inode表(持久化存储元数据)下面的图结合linux内核模块程序、普通用户态程序对文件操作进行了细致说明:
add_缓冲区类型:
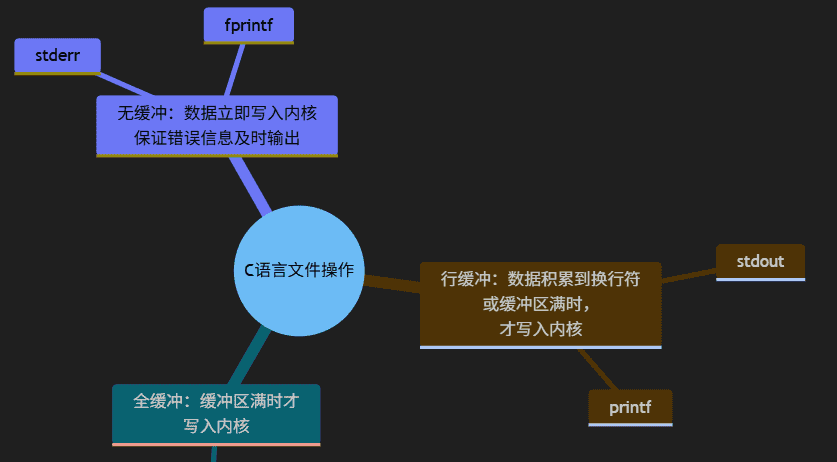
c语言的标准库文件操作,操作对象是FILE* 流对象(见下文2.1fopen的返回值),所有操作 FILE* 流对象的函数都共享同一个内置缓冲区,这是标准库的核心设计。c语言的标准库文件操作函数中,有的函数是全缓冲区(fread/fwrite)、有的是行缓冲区(fgets/fputs)、有的无缓冲区(stderr)。
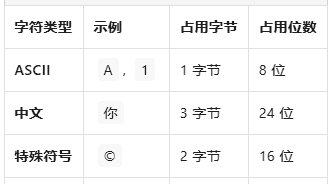
add_一个字符 等于 一个字节?
现代计算机统一采用 8位 = 1字节(1 Byte = 8 bits)ASCII 字符:1字符 = 1字节 = 8位 ✅Unicode 字符,情况就复杂了,以 UTF-8 编码为例,中文/日文等(UTF-8) 1字符 = 2-4字节,简单示例如下:
add_c和c++中字符串数组
尾部自带 ‘’ 是C/C++语言标准强制规定的;以:char a[] = “这是写入的数据”; 为例子,在栈中存放内容如下:
| 这 | 是 | 写 | 入 | 的 | 数 | 据 | |
1、基础概念:
C 语言的文件操作函数分为两大核心层级:标准库文件操作(FILE* 封装层) 和 Linux 系统调用(直接操作文件描述符 FD)。前者跨平台、带缓冲,适合常规开发;后者底层、无缓冲、效率高,贴合 Linux 系统特性(与之前讲的文件描述符强关联)。
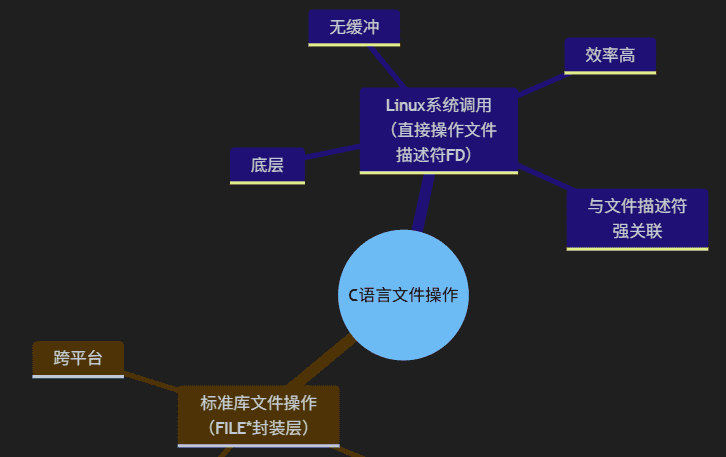
1.1、标准库文件操作
需要引入#include <stdio.h>C 标准库(<stdio.h>)提供的文件操作函数基于 FILE 结构体(用户态封装),底层会调用 Linux 系统调用(如 open/read),但增加了缓冲机制(减少系统调用次数,提升效率),是跨平台开发的首选。FILE 是封装了:文件描述符(_fileno 成员)、缓冲数据、文件状态(读写模式、偏移量等)的结构体(不同系统实现略有差异,但接口统一)。FILE 结构体的关键内容(对用户不透明,但逻辑上包含):
struct _IO_FILE {
int _fileno; // 底层的文件描述符 fd(如 3, 4, 5...)
char* _IO_buf_base; // 缓冲区起始地址
char* _IO_buf_end; // 缓冲区结束地址
int _IO_read_ptr; // 当前读位置
int _IO_write_ptr; // 当前写位置
// ... 其他状态标志
};
标准库文件操作有哪些函数
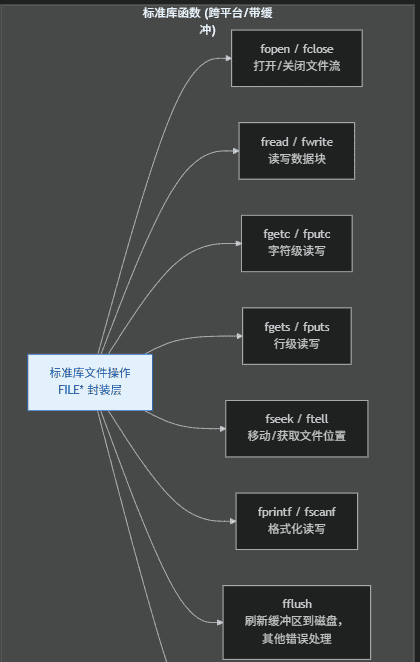
1.2、Linux 系统调用文件操作
需要引入的头文件根据对应的函数而不同,标准库文件操作只需要一个头文件,这也是linux系统调用文件操作和标准库文件操作的区别之一。Linux 系统调用(<unistd.h>/<fcntl.h>)直接操作文件描述符(FD),无缓冲机制,效率更高,是底层开发(如服务器、驱动)的核心,与之前讲的文件描述符底层机制强关联。linux文件操作都有哪些函数:
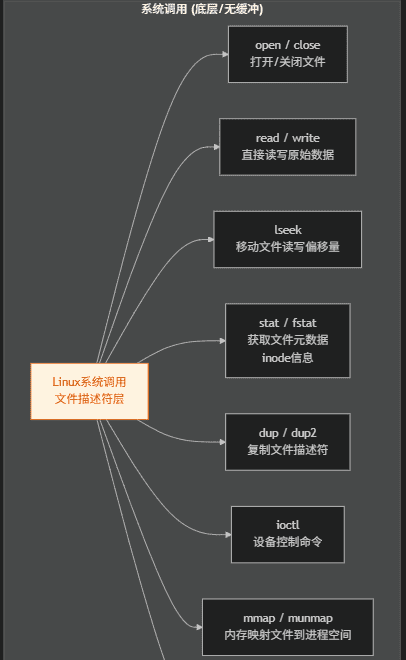
★★★2、标准库文件操作常用函数总结:
标准库文件操作是通用性很强的文件操作方式,必须掌握;
2.1.1、文件打开 / 关闭:fopen / fclose
需要用到的头文件:
#include <fcntl.h> // ✅ 核心头文件:open() 和 flags 定义
#include <sys/types.h> // mode_t 类型定义
#include <sys/stat.h> // 权限模式常量(如 S_IRUSR)
#include <unistd.h> // creat() 函数(历史上在此定义)函数模板
FILE* fopen(const char* path, const char* mode); // 打开文件,返回FILE*指针,返回值可以理解为是一个包含“文件信息的结构体”
int fclose(FILE* stream); // 关闭文件,成功返回0,失败EOF
mode参数可选类型:【下面的模式,本质而言就是访问文件的方式(权限)】
**
特点:
1、r读、w覆盖写、a追加(a是特殊写操作),b是二进制,加号读写分主次(谁主导文件不存在就按谁的特性处理);
2、r文件不存在报错,a和w文件不存在会创建;
3、任何模式读写指针都是共用的;
4、读写指针是否有效要看当前模式是否允许读写,a模式写操作时,读写指针失效,读操作时读写指针有效,a模式写操作必须是末尾;**】
![图片[1] - ARM《13》_★★★c语言中的文件操作函数 - 宋马](https://pic.songma.com/blogimg/20251129/62dbc3248689472fad7c965a68969d9c.png)
![图片[2] - ARM《13》_★★★c语言中的文件操作函数 - 宋马](https://pic.songma.com/blogimg/20251129/a076c92c40194ef3b2bcebb0f6d679fb.png)
![图片[3] - ARM《13》_★★★c语言中的文件操作函数 - 宋马](https://pic.songma.com/blogimg/20251129/e308150e19024f9186df97b5a3eae259.png)
a+b:二进制追加写和可读;(有的编译器不认识ab+)
2.1.2、★不同模式下读写指针的作用
1、读模式:r和rb都是从文件开头开始读,不可写,读指针可以自由移动,r+和rb+读写位置在文件开头,读写指针都可以自由移动,但读写指针共享,要注意切换操作时移动;【文件不存在,返回NULL】
2、写模式:w和wb从文件开头开始写,不可读,写指针可以自由移动,w+和wb+读写位置在文件开头,读写指针都可以自由移动,但读写指针共享,要注意切换操作时移动;【文件不存在,创建;文件存在,写操作会清空之前内容】
★3、追加模式【特殊写模式】:a和ab不可读,因此读写指针失效,写操作在文件尾部;a+和a+b(ab+)读位置在文件开头,写位置在文件末尾,其中只有读写指针只对读操作有用,对写操作失效,写操作强制锁定在末尾【文件不存在,创建;文件存在,写操作会在原内容后面追加】
2.2、主流文件读写函数:fread/fwrite(二进制 / 文本通用)、fscanf(用gets替代)/fprintf(文本专用)
在c标准库中文件读写函数含有很多,这里只介绍主流的,fscanf由于在读取实际数据前,会跳过所有前导的空白字符(空格、 、
、
、v、f),不检查目标缓冲区大小,攻击者可轻松构造输入导致栈溢出,执行恶意代码,安全性也不好,所以不推荐使用,推荐gets代替fscanf执行文本读取。函数模板
/**
* @brief 从文件流读取指定数量的元素到缓冲区
* @param ptr 接收数据的缓冲区指针(需确保足够大:size × nmemb 字节)
* @param size 每个元素的字节大小(例如:int 是 4 字节)
* @param nmemb 要读取的元素个数
* @param stream 目标文件流指针(需已成功打开)
* @return size_t 成功读取的「元素个数」(无符号类型,≥0):
* - 返回 nmemb:完全成功,读满所有请求的元素;
* - 返回 0 < ret < nmemb:部分成功,未读满(如文件尾、数据不足);
* - 返回 0:两种可能——① 已到文件尾(feof(stream) 为真);② 读取错误(ferror(stream) 为真),需结合这两个函数判断。
*/
size_t fread(void* ptr, size_t size, size_t nmemb, FILE* stream);
/**
* @brief 从缓冲区写入指定数量的元素到文件流
* @param ptr 存放待写入数据的缓冲区指针
* @param size 每个元素的字节大小
* @param nmemb 要写入的元素个数
* @param stream 目标文件流指针(需已成功打开且有写入权限)
* @return size_t 成功写入的「元素个数」(无符号类型,≥0):
* - 返回 nmemb:完全成功,写满所有请求的元素;
* - 返回 0 < ret < nmemb:部分成功,未写满(如磁盘空间不足、网络中断);
* - 返回 0:写入错误(如文件指针无效、无写入权限、磁盘满),需用 ferror(stream) 确认。
*/
size_t fwrite(const void* ptr, size_t size, size_t nmemb, FILE* stream);
// --------------------------------------------------
// 从stream按format格式读取数据到变量,返回值是成功读取并赋值的输入项数量,失败返回EOF
int fscanf(FILE* stream, const char* format, ...);
// fgets从指定的文件流中读取一行文本(最多读取 n-1 个字符),并在末尾自动添加 作为字符串结束符。str是目标缓存区,n是最大读取字符数,stream是文件流指针,成功返回str指针,失败返回NULL。【fgets也只能用于文本读】
char *fgets(char *str, int n, FILE *stream);
// 按format格式将变量数据写入stream,返回成功写入的字符数,失败返回-1;
int fprintf(FILE* stream, const char* format, ...);
帮助记忆:为什么fprintf是从程序缓冲区到内存的文件中,为什么fscanf是从内存的文件到程序的缓冲区?printf本身是把程序的内容打印到屏幕上,scanf是把键盘输入传递到程序当中,把文件看作是外部,只要分析是从外部到进程当中来就是“读取”得用fscanf,从进程到外部就是“写入”得用fprintf;
2.3、★二进制模式和文本模式都可以使用的读写函数:fgetc/fputc
// fgetc - 读取一个字符,成功:返回读取的字符(作为 unsigned char 转换为 int),失败/文件结束:返回 EOF(通常定义为 -1)
int fgetc(FILE *stream);
// fputc - 写入一个字符,成功:返回写入的字符,失败:返回 EOF
int fputc(int char, FILE *stream);
![图片[4] - ARM《13》_★★★c语言中的文件操作函数 - 宋马](https://pic.songma.com/blogimg/20251129/4b43b4b09c954703b5b4f626993aa81c.png)
注意:
= Return to line beginning(回到行首)、
= New line(新行)
Windows:
(先回车,再换行)
Linux/macOS:
(只换行,隐含回车)
旧Mac系统:
(只回车)
2.4、文件定位:fseek/ftell/rewind
函数模板
// 将stream的读写指针移动到offset位置,whence指定基准(SEEK_CUR、SEEK_END、SEEK_SET),成功返回0,失败返回非0;
int fseek(FILE* stream, long int offset, int whence);
// 返回stream当前读写指针相对于文件开头的偏移量(字节数)
long int ftell(FILE* stream);
// 将stream的读写指针重置到文件开头(等价于fseek(stream, 0, SEEK_SET))
void rewind(FILE* stream);
2.5、缓冲刷新与错误处理:fflush/ferror/feof
fflush(stream):强制刷新输出缓冲区。【fflush的应用场景很多,下面就举个简单例子】
// 场景:银行转账日志
fprintf(log_fp, "转账: 用户A -> 用户B 金额: 10000元
");
fflush(log_fp); // ✅ 必须立即刷新,否则崩溃会丢失记录
ferror(stream):返回非 0 表示文件操作发生错误(需结合 perror 打印错误信息)。feof(stream):返回非 0 表示已到达文件末尾(EOF)。
3、标准库文件操作常用函数练习:
下面练习是在windows的vscode中跑的,所以需要设置代码执行时的文字编码规范是utf-8、设置中断暂停等待;
练习1
下面用一个「学生信息写入 + 读取」的完整实例,串联所有常用函数,实现:
1、定义学生结构体(模拟真实数据);
2、以「读写模式」打开文件(不存在则创建);
3、用 fwrite 写入二进制数据(结构体)、fprintf 写入文本数据;
4、用 rewind/fseek 移动文件指针;
5、用 fread/fscanf 读取数据并验证;
6、全程错误处理(避免崩溃)。
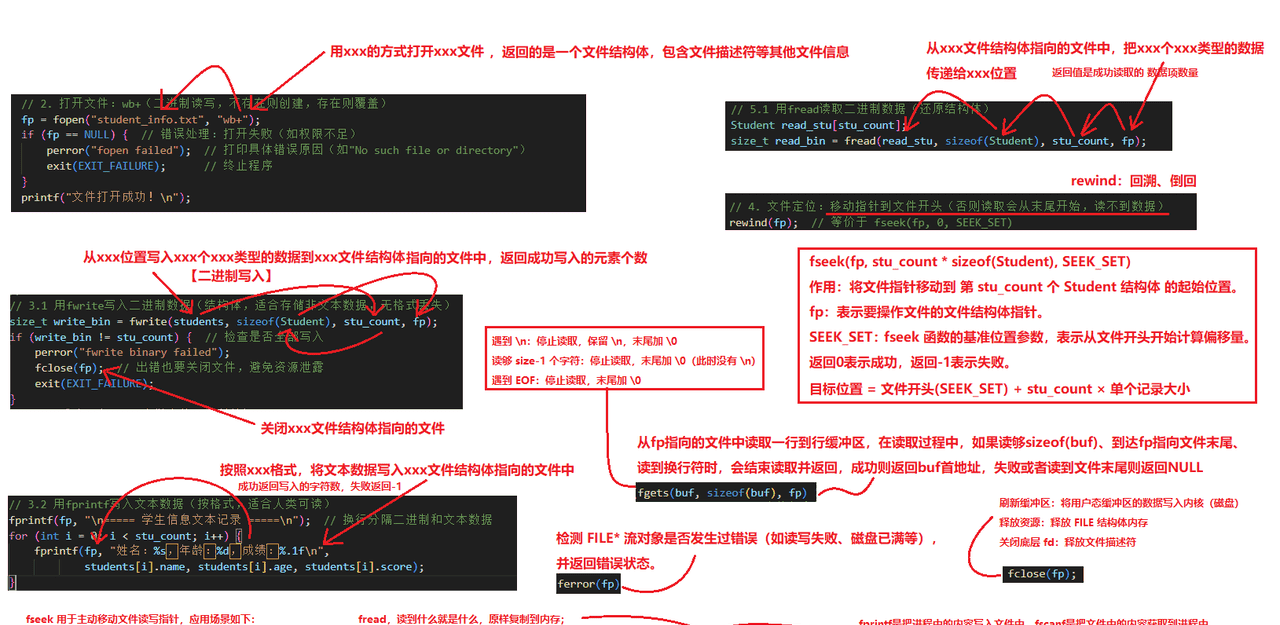
#include <stdio.h> // 标准文件操作函数
#include <stdlib.h> // 提供通用工具函数
#include <string.h> // 提供字符串操作函数
// 定义学生结构体(模拟需要存储的数据)
typedef struct {
char name[20]; // 姓名
int age; // 年龄
float score; // 成绩
} Student;
int main() {
system("chcp 65001 > nul"); // 以utf-8格式编码
// 1. 准备数据(2个学生)
Student students[] = {
{"Li Hua", 18, 92.5},
{"Zhang Wei", 19, 88.0}
};
int stu_count = sizeof(students) / sizeof(Student); // 学生数量:2
FILE* fp = NULL;
// 2. 打开文件:wb+(二进制读写,不存在则创建,存在则覆盖)
fp = fopen("student_info.txt", "wb+");
if (fp == NULL) { // 错误处理:打开失败(如权限不足)
perror("fopen failed"); // 打印具体错误原因(如"No such file or directory")
exit(EXIT_FAILURE); // 终止程序
}
printf("文件打开成功!
");
// 3. 写入数据:二进制+文本双模式(演示不同读写场景)
// 3.1 用fwrite写入二进制数据(结构体,适合存储非文本数据,无格式丢失)
size_t write_bin = fwrite(students, sizeof(Student), stu_count, fp);
if (write_bin != stu_count) { // 检查是否全部写入
perror("fwrite binary failed");
fclose(fp); // 出错也要关闭文件,避免资源泄露
exit(EXIT_FAILURE);
}
printf("成功写入 %zu 个学生的二进制数据
", write_bin);
// 3.2 用fprintf写入文本数据(按格式,适合人类可读)
fprintf(fp, "
===== 学生信息文本记录 =====
"); // 换行分隔二进制和文本数据
for (int i = 0; i < stu_count; i++) {
fprintf(fp, "姓名:%s,年龄:%d,成绩:%.1f
",
students[i].name, students[i].age, students[i].score);
}
fflush(fp); // 强制刷新缓冲区(确保文本数据立即写入文件,避免残留)
/*
1、fflush(fp) 只对输出(写)缓冲区有效;
2、将缓冲区中的待写入数据强制写入磁盘/设备;
*/
printf("成功写入文本格式数据
");
// 4. 文件定位:移动指针到文件开头(否则读取会从末尾开始,读不到数据)
rewind(fp); // 等价于 fseek(fp, 0, SEEK_SET)
printf("
开始读取文件数据...
");
// 5. 读取数据:先读二进制,再读文本
// 5.1 用fread读取二进制数据(还原结构体)
Student read_stu[stu_count];
size_t read_bin = fread(read_stu, sizeof(Student), stu_count, fp);
if (read_bin != stu_count) {
perror("fread binary failed");
fclose(fp);
exit(EXIT_FAILURE);
}
// 打印读取的二进制数据
printf("
【二进制读取结果】
");
for (int i = 0; i < read_bin; i++) {
printf("第%d个学生:姓名=%s,年龄=%d,成绩=%.1f
",
i+1, read_stu[i].name, read_stu[i].age, read_stu[i].score);
}
// 5.2 用fseek移动指针到文本数据开头(跳过二进制数据)
// 计算二进制数据总长度:stu_count * sizeof(Student),移动到该位置
if (fseek(fp, stu_count * sizeof(Student), SEEK_SET) != 0) {
perror("fseek failed");
fclose(fp);
exit(EXIT_FAILURE);
}
// 5.3 用fscanf读取文本数据(按格式解析)
char buf[1024]; // 存储文本行数据
printf("
【文本读取结果】
");
// 循环读取每一行,直到文件末尾(feof判断EOF)
while (fgets(buf, sizeof(buf), fp) != NULL) { // fgets读取一行(含换行符)
printf("%s", buf); // 直接打印读取的文本行
}
// 6. 错误与EOF检查(避免读取过程中出现隐藏错误)
if (ferror(fp)) { // 检查是否有读取错误(如文件损坏)
perror("file read error");
fclose(fp);
exit(EXIT_FAILURE);
} else if (feof(fp)) { // 正常到达文件末尾
printf("
文件读取完成(已到达末尾)
");
}
// 7. 关闭文件(自动刷新缓冲区,释放FILE*资源)
if (fclose(fp) != 0) {
perror("fclose failed");
exit(EXIT_FAILURE);
}
printf("文件关闭成功!
");
system("pause"); // 让终端暂停显示
return 0;
}
总结:
案例中用到的函数总结,需要掌握下面函数的用法
 通过对第一个案例的学习,对上面函数的使用有一个概览
通过对第一个案例的学习,对上面函数的使用有一个概览
练习2
1、创建文本文件 scores.txt,写入 3 名学生的姓名和成绩
2、读取并显示所有学生信息
3、追加一名新学生
4、再次读取验证追加成功
#include<stdio.h>
#include <stdlib.h>
struct student
{
char name[10];
int math_score;
int chinese_score;
};
int main()
{
system("chcp 65001 > nul"); // 65001 = UTF-8, > nul 隐藏输出
// 定义三个学生对象:
struct student n3[3] =
{
{"xiao_1",81,90},
{"xiao_2",82,91},
{"xiao_3",83,92}
};
size_t ct = sizeof(n3)/sizeof(n3[0]);
struct student c = {"xiao_4",100,100};
// 创建文件【因为是追加模式,创建之前先手动删除之前的文件】
FILE* fp = fopen("scores.txt","a+b"); //这里是二进制,读写用fread和fwrite
if(fp == NULL)
{
printf("文件创建失败
");
system("pause");
return 0;
}
// 向文件中写入学生内容
size_t wct = fwrite(n3,sizeof(n3[0]),ct,fp);
if(wct==0)
{
printf("第一次数据写入失败
");
system("pause");
return 0;
}
// 先移动读文件指针:
rewind(fp);
// 从文件中读取内容
struct student buff[3];
size_t rct = fread(buff,sizeof(n3[0]),ct,fp);
if(rct != ct)
{
printf("读取数据失败
");
system("pause");
return 0;
}
else
{
for(int i = 0;i<ct;i++)
{
printf("第%d个同学叫%s,数学成绩是%d,语文成绩是%d
",i,buff[i].name,buff[i].math_score,buff[i].chinese_score);
}
}
// 追加写入一条
fseek(fp,sizeof(n3),SEEK_SET); // 文件权限是二进程的读和写和可追加
wct = fwrite(&c,sizeof(c),1,fp);
if(wct==0)
{
printf("第二次数据写入失败
");
system("pause");
return 0;
}
// 重新从文件中读取
struct student buff2;
// 先移动读文件指针:
fseek(fp,sizeof(n3),SEEK_SET);
printf("接下来打印新添加的第四条信息
");
rct = fread(&buff2,sizeof(c),1,fp);
if(rct == 0)
{
printf("读取数据失败
");
system("pause");
return 0;
}
else{
printf("追加的第四条信息:姓名:%s,数学成绩:%d,语文成绩:%d
",buff2.name,buff2.chinese_score,buff2.math_score);
}
// 检查文件操作过程中是否有错误记录
if(ferror(fp))
{
printf("文件操作过程中有错误记录
");
system("pause");
return 0;
}
else
{
if(fflush(fp)==0) fclose(fp);
}
system("pause");
return 0;
}
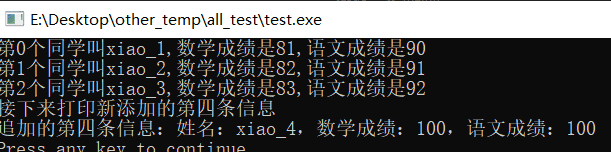
总结:
上面案例中踩坑的点:
1、如果是设置追加模式a打开文件,要主要两个问题,第一个是每次打开文件时,文件是否已经存在;第二个问题就是每次读或者写的时候要通过fseek或者rewind确定读写指针的位置;
2、在操作一个文件之前,设置好打开文件是通过那种模式打开非常重要,这些信息会记录在打开文件的“文件信息结构体”当中,在之后进行读写操作的时候,有时候是普通文本读写模式打开的,使用了二进制的读写函数就会犯错;
3、不同读模式,读入的内容是不同的,有的时候需要把文件当中的一些特殊符号也读进去,比如
,等;
练习3
通过一个练习,搞明白,不同文件读写模式下,读操作的区别、写操作的区别;二进制读写模式下,读操作 和 文本读写模式下,读操作文本读写模式下,写操作 和 文本读写模式下,写操作
#include<stdio.h>
#include <stdlib.h>
int main()
{
system("chcp 65001 > nul"); // 65001 = UTF-8, > nul 隐藏输出
// 通过文本追加读写打开已存在的a.txt文件,写内容再读取内容
printf("==============文本追加读写==============
");
FILE* fp = fopen("a.txt","a+");
if (fp == NULL) {
perror("fopen a.txt failed"); // 打印具体错误原因(如权限不足)
system("pause");
return 1;
}
// rewind(fp); 多余,fprintf在追加模式下,必定会从尾部添加;
size_t wc = fprintf(fp,"
%s
","这是文本追加写");
// fflush(fp);
if(wc < 0)
{
printf("文本追加写失败
");
system("pause");
return 0;
}
char a[1024];
rewind(fp);
while(fscanf(fp,"%s
",a)!=EOF)
{
printf("%s",a);
}
fclose(fp);
// 通过二进制追加读写打开a.txt文件,写内容再读取内容
printf("
==============二进制追加读写==============
");
FILE* fp1 = fopen("a.txt","a+b");
if (fp == NULL) {
perror("fopen a.txt failed"); // 打印具体错误原因(如权限不足)
system("pause");
return 1;
}
char a1[] = "12345";
// rewind(fp1); 多余,fprintf在追加模式下,必定会从尾部添加;
size_t ac = fwrite(a1,sizeof(a1),1,fp1);
if(ac == 0)
{
printf("二进制追加写失败
");
system("pause");
return 0;
}
// 获取文件中内容所占字节数
fseek(fp1,0,SEEK_END);
long file_size = ftell(fp1);
fseek(fp1,0,SEEK_SET);
// 从文件中读取
// char buf[file_size]; file_size是运行时才能知道的,导致变长数组(VLA)+ 栈溢出风险
char *buf = (char*)malloc(file_size + 1); // +1 留位置存 ''(用于打印)
size_t read_len = fread(buf,1,file_size,fp1);
if (read_len != file_size)
{
printf("二进制读取不完整,实际读取 %zu 字节
", read_len);
system("pause");
return 0;
}
buf[read_len] = ''; // buf读取之后没有终止符
printf("%s",buf);
fclose(fp1);
system("pause");
return 0;
}
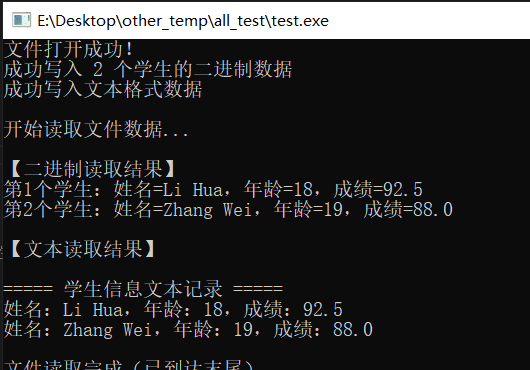
测试结果
![图片[5] - ARM《13》_★★★c语言中的文件操作函数 - 宋马](https://pic.songma.com/blogimg/20251129/f93de2619dea45cfb61c7c041673b3b5.png)
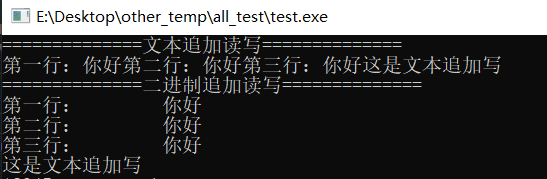
总结:
fscanf(fp,“%s
”,a)的缺点在例子中已经暴露,它在读取的时候跳过了所有空白字符;用fgets代替fscanf,修改了二进制追加内容“12345”结果如下:
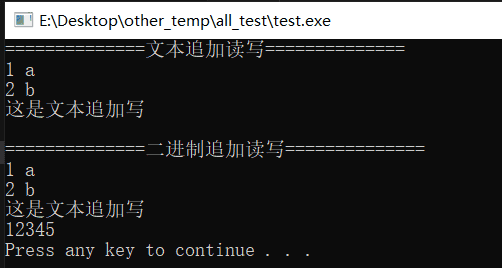
在调用fopen后,必须检查“文件是否正确接收”;
追加模式下,只要是写入操作,不论是否设置读写指针,都从文件末尾进行;
数组大小不能设置为变量;
测试1、★如何获取一个文本的文本长度(包含所有符号)
如下所示是要读取的文本内容:
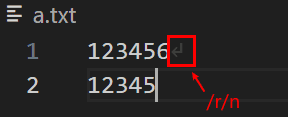 代码:
代码:
#include<stdio.h>
#include <stdlib.h>
int main()
{
system("chcp 65001 > nul"); // 65001 = UTF-8, > nul 隐藏输出
FILE* fp = fopen("./a.txt","a+b");
if(fp == NULL)
{
printf("打开文件失败!");
system("pause");
return 0;
}
// ****************计算文本长度核心代码****************
fseek(fp,0,SEEK_END);
long int len = ftell(fp);
printf("文本长度是6+2(r和n换行符)+5=%d
",len); // 文本长度是6+2(r和n换行符)+5=13
// ****************计算文本长度核心代码****************
fclose(fp);
system("pause");
return 0;
}
测试2:二进制读取时,读取n个大小为m的数据和读取m个大小为n的数据时,返回值的区别:
a.txt内容如下:
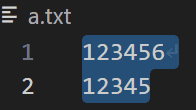 读取n个大小为m的数据:
读取n个大小为m的数据:
#include<stdio.h>
#include <stdlib.h>
int main()
{
system("chcp 65001 > nul"); // 65001 = UTF-8, > nul 隐藏输出
FILE* fp = fopen("./a.txt","rb");
if(fp == NULL)
{
printf("打开文件失败!");
system("pause");
return 0;
}
rewind(fp);
char a[100];
size_t cnum = fread(a,sizeof(a),1,fp); //这里表示要读取1个大小为sizeof(a)的内容,cnum只能是0或者1
printf("a中已经读取的内容:
%s
",a);
while(cnum>0)
{
printf("
===============
");
printf("返回值生效:
");
printf("成功读取:%d字节
",cnum);
printf("%s",a);
printf("
===============
");
cnum = fread(a,sizeof(a),1,fp);
}
fclose(fp);
system("pause");
return 0;
}

读取n个大小为m的数据:
#include<stdio.h>
#include <stdlib.h>
int main()
{
system("chcp 65001 > nul"); // 65001 = UTF-8, > nul 隐藏输出
FILE* fp = fopen("./a.txt","rb");
if(fp == NULL)
{
printf("打开文件失败!");
system("pause");
return 0;
}
// 测试2进制读取后,有没有读到终止符号
rewind(fp);
char a[100];
size_t cnum = fread(a,sizeof(a),1,fp);
printf("a中已经读取的内容:
%s
",a);
while(cnum>0)
{
printf("
===============
");
printf("返回值生效:
");
printf("成功读取:%d字节
",cnum);
printf("%s",a);
printf("
===============
");
cnum = fread(a,sizeof(a),1,fp);
}
fclose(fp);
system("pause");
return 0;
}

两种情况的区别:第一种情况,要读取1个大小为100字节的内容,返回值没有生效(因为a.txt只有13个字节),所以fread返回值为0,但是所有内容都读取到缓冲区了;第二种情况,要读取100个大小为1字节的内容,返回值是13,所以进入了while循环中。通过测试结果来看,fread读取时,会读取指定大小的内容,包含文本当中的换行符等特殊符号;
测试3:★以二进制读取为例,制作可以不断读取文件内容的模板
测试1的情况虽然可以正确读取,但是a没有加结束符号””,下面就制作一个可以不断读取文件的模板用于测试的文本内容:
/*
文件读取测试文本 - 多场景验证用
本文件专为文件读取功能测试设计,包含多种文本特征与边界情况,可验证读取完整性、换行符处理、编码识别等核心功能。
第一段落:基础文本与数字混合
测试文本应当包含123、456.78这样的数字序列,以及ASCII字符如abcdEFGH。当前时间为2024-11-27 14:30:00,版本号v3.2.1。特别注意:邮箱地址test@example.com和网址https://github.com需要完整读取。百分比数据如99.9%、温度值-15.5°C、坐标(118.7,32.1)都是常见格式。行尾包含CRLF
和LF
两种换行符,用于跨平台兼容性测试。
第二段落:长行文本与缓冲区边界
本行设计为超长文本,目的是测试读取函数在处理超过缓冲区默认大小的行时是否能够正确完整地获取所有内容而不会出现截断或数据丢失的情况。当一行文本包含超过512个字符时,许多简单的读取实现可能会遇到问题,因此这里特意构造了一个包含大量中文汉字和English words混合的段落,确保测试覆盖到各种边缘场景。文本中特意重复多次:abcdefghijklmnopqrsguvwxyz,配合数字1234567890,制造足够的长度。
第三段落:特殊符号与空白字符
!@#$%^&*()_+-=[]{}|;':",./<>?这些特殊符号必须被准确读取。制表符 测试:姓名 年龄 性别 地址。空行测试:
(上下为空行)
空格测试:行尾5个空格
缩进测试: (两个制表符缩进)本行以制表符开头。
第四段落:短行与频繁换行
短行1
短行2
短行3
单行一个字符:a
单行一个数字:7
混合:X
混合:Y
混合:Z
结束标记。
第五段落:Unicode扩展与编码验证
扩展字符测试:①②③ ㈠㈡㈢ ⅠⅡⅢ 中文标点:,。!?;:()《》「」【】。Emoji测试:😀😁😂🤣😃😄😅😆😉😊😋😎😍😘🥰😗。数学符号:∑∫∮∝∞∟∠∣∥∧∨∩∪。货币符号:¥$€£₨₩₪₫៛₭₮₯₹。
第六段落:边界情况与重复模式
0000000000111111111122222222223333333333444444444455555555556666666666777777777788888888889999999999
AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDDEEEEEEEEEEFFFFFFFFFFGGGGGGGGGGHHHHHHHHHHIIIIIIIIIIJJJJJJJJJJ
重复1024次:a
最后一行:文件结束,不应有额外内容。
*/
代码:
#include <stdio.h>
#include <stdlib.h>
#define BUFFER_SIZE 4096 // 4KB缓冲区,减少文件读取的次数
int main() {
system("chcp 65001 > nul");
FILE* fp = fopen("./a.txt", "rb");
if (fp == NULL) {
printf("打开文件失败!
");
system("pause");
return 1; // 建议返回1表示错误
}
char a[BUFFER_SIZE];
size_t cnum;
while ((cnum = fread(a, 1, BUFFER_SIZE - 1, fp)) > 0) {
a[cnum] = '';
printf("%s", a);
fflush(stdout); // 确保立即显示
}
fclose(fp);
system("pause");
return 0;
}
4、Linux 系统调用文件操作常用函数概览:
linux系统调用文件操作,直到每个函数的使用方法即可,用到了可以查找相关函数,因为它操作是底层调用,需要的函数多,头文件也很杂,参数更复杂;
4.1、文件打开 / 创建:open/creat
函数模板
// 打开/创建文件,返回新FD(失败返回-1)
int open(const char* pathname, int flags, mode_t mode);
// 等价于 open(pathname, O_WRONLY | O_CREAT | O_TRUNC, mode)
int creat(const char* pathname, mode_t mode);
4.2、文件关闭:close
函数模板
// 关闭FD,成功返回0,失败返回-1(FD标记为未使用)
int close(int fd);
4.3、文件读写:read/write
函数模板
// 从fd读取count字节到buf,返回实际读取字节数(0=EOF,-1=错误)
ssize_t read(int fd, void* buf, size_t count);
// 从buf写入count字节到fd,返回实际写入字节数(-1=错误)
ssize_t write(int fd, const void* buf, size_t count);
4.4、文件定位:lseek
函数模板
// 移动fd对应的文件指针,返回新的偏移量(失败返回-1)
off_t lseek(int fd, off_t offset, int whence);
4.5、文件描述符复制:dup/dup2
dup(oldfd):复制 oldfd,返回最小未使用的新 FD(新 FD 与 oldfd 指向同一打开文件表项)。dup2(oldfd, newfd):将 newfd 重定向到 oldfd(若 newfd 已打开,先关闭;若 oldfd 无效,newfd 不关闭),返回 newfd(失败返回 – 1)。核心用途:实现重定向(如 stdout 重定向到文件)。
总结:
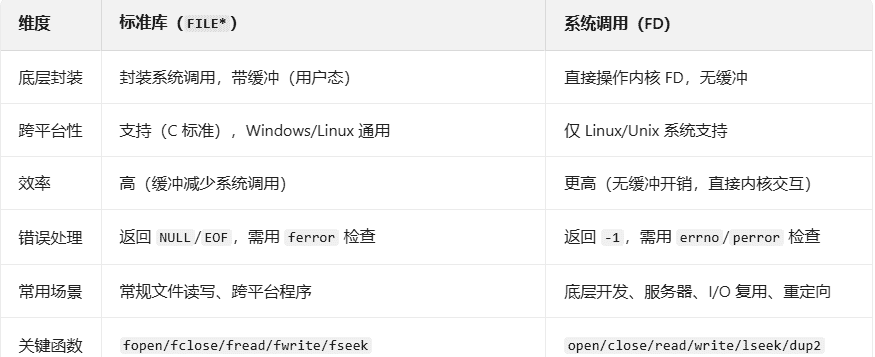
1、标准库文件操作和系统调用文件操作对比
2、如何选择
标准库是用户态封装,核心优势是跨平台和缓冲;系统调用是内核提供的底层接口,无缓冲、效率高,适合 Linux 特定场景(如服务器开发)。实际开发中,常规场景用标准库,需要精细控制(如非阻塞 I/O、重定向)时用系统调用。
















暂无评论内容