
能在三维图里把上千万篇论文的分布一眼看清,并能点进去拿到结构化摘要,这是这个工具带来的直接效果。后面我把这东西怎么来的、能怎么用、安装跑起来需要注意什么、优缺点都说清楚,别跑偏,都是干货。

说白了,这玩意叫 Aella Science Dataset Explorer。它展示的不是论文原文全文,而是从 LAION 那堆大规模语料里挑出来的一部分——大致接近一亿篇科研文章中,经过 Inference.net 抽取出的“结构化摘要”和语义向量。换句话说,背后有海量原文做支撑,但前端看到的是已经提炼好的关键信息,用来快速判断一篇文章值不值得深入读。
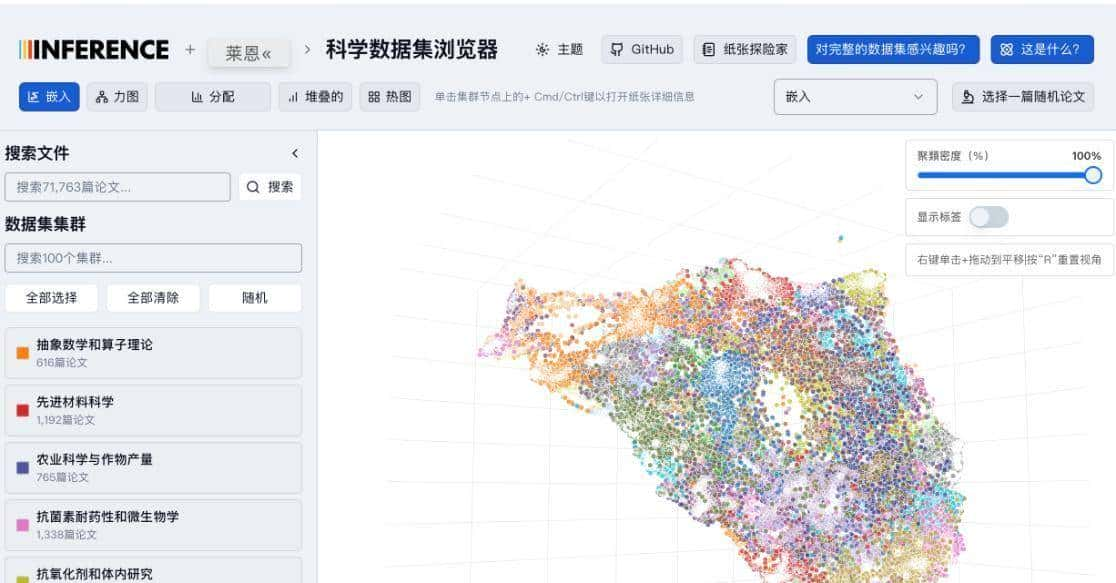
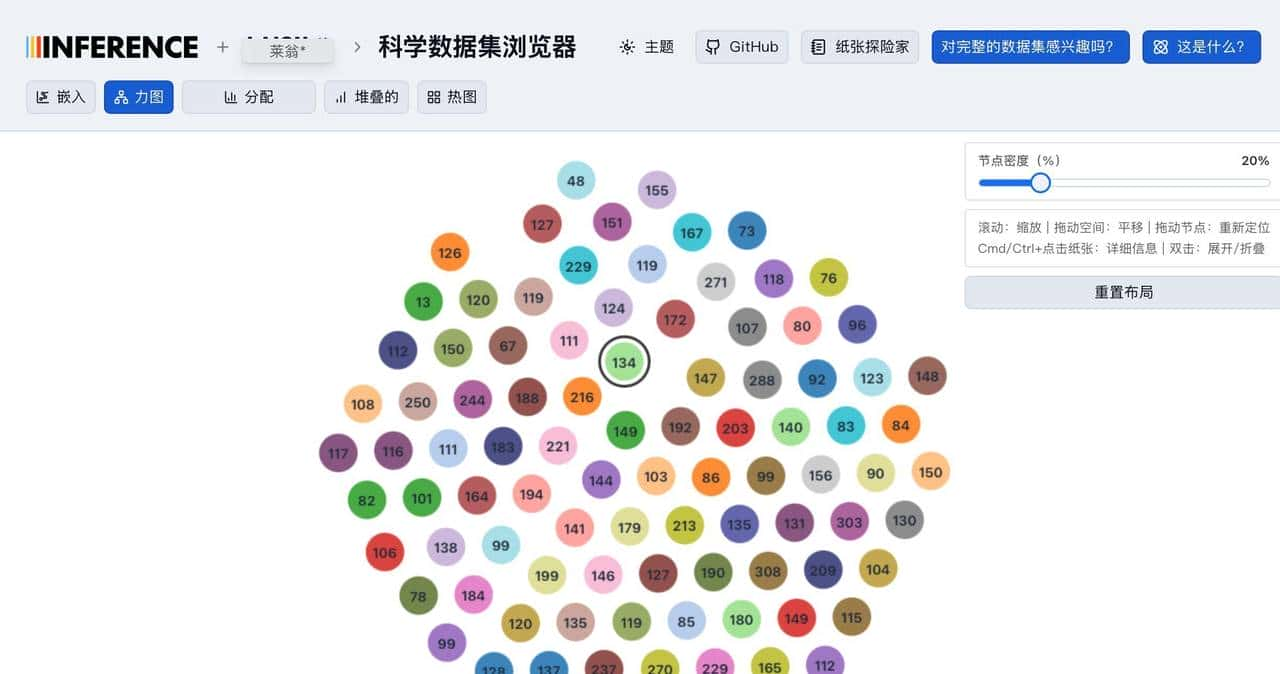
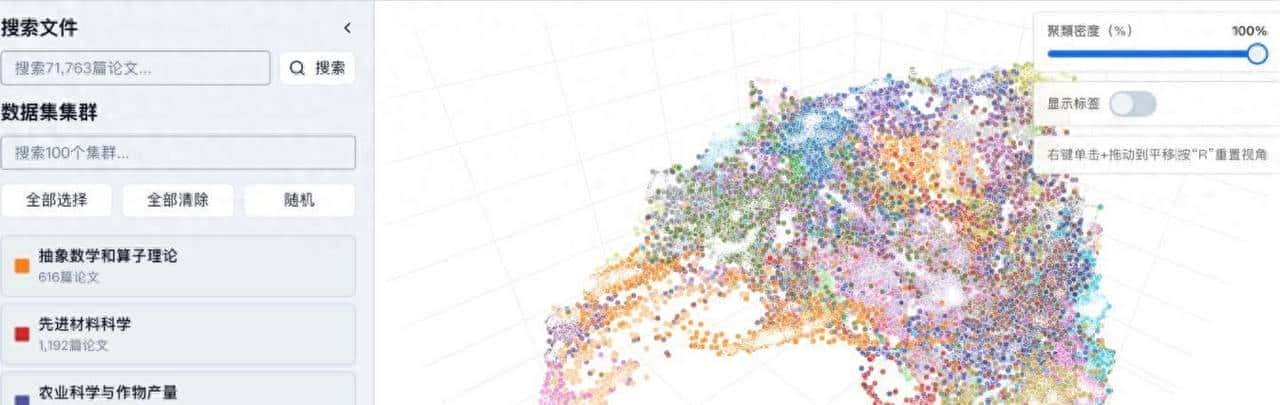
界面给人的第一印象就是顺手好玩。默认是一个三维散点图,论文按语义聚到一起,点成簇。你可以拖动视角、放大某个区域、缩小回全局;滚轮一滚就能钻进某个主题里细看;鼠标移上去会弹类目名,点下去会看到模型抽出的结构化摘要:标题、研究问题、方法要点、实验结果、结论方向这些条目都比较清楚。左侧有筛选面板,按领域或关键词把视图收窄。图不是死的散点图,还能换成力导向图、柱状图、堆叠图或热力图,适合不同的观察需求。简单说,它把一堆文本变成图形,让你用眼睛先把方向找出来,再去啃原文。
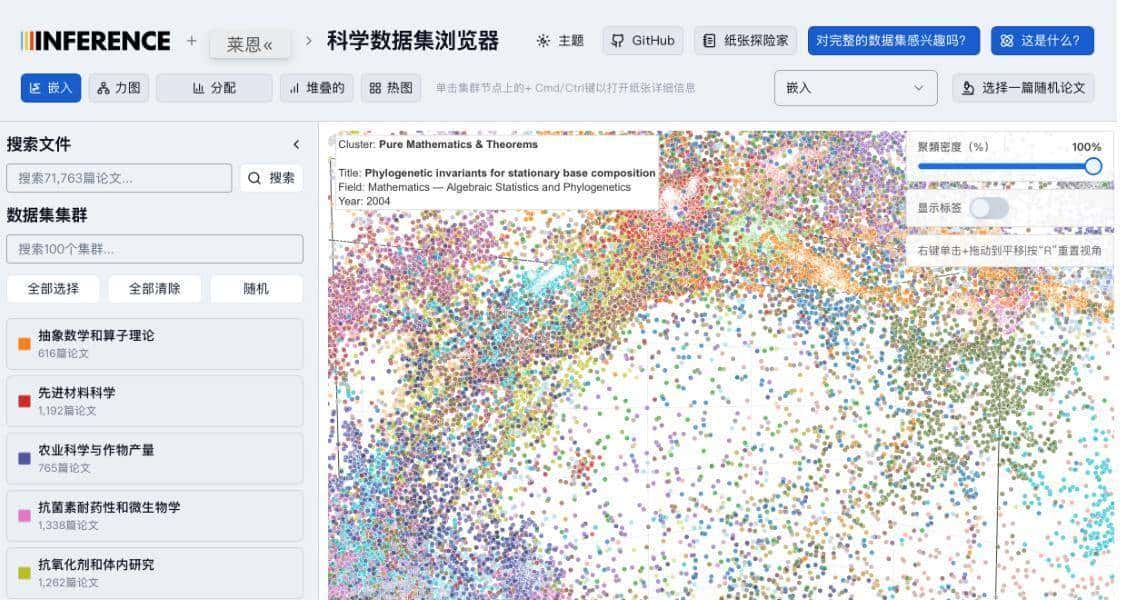
底层技术也不复杂但接地气。前端用了 React + TypeScript + Vite,渲染跟交互主要靠 D3.js。后端是一套 Python 的 FastAPI 服务,开发环境用 SQLite,生产提议上 Cloudflare D1 存向量和元数据,R2 用来放大文件或原始文档。数据来源链路是 LAION 的原始文本和元数据,Inference.net 在这基础上做了微调,把论文关键信息抽成结构化字段并生成语义嵌入,Aella 取这套结果的一个子集做可视化和查询。
要把它跑起来,流程也挺常见,基本就是拉代码、起前端、起后端,按仓库里的说明去做就行。一个常见的开发流程参考如下(以仓库实际说明为准):
– git clone 到本地。
– 前端:cd web;pnpm install 或 npm install;pnpm dev(Vite 默认端口一般是 5173)。
– 后端:cd api;python -m venv .venv;source .venv/bin/activate(Windows 用 .venvScriptsactivate);pip install -r requirements.txt;uvicorn main:app –reload(默认端口 8000)。
– 打开浏览器访问前端地址,前端会连后端拉取可视化所需的数据切片。
进了界面后来怎么用,举个靠谱的场景,比较好上手。假设你正在搞一个神经网络架构的小改善,想快速知道这个子领域的文献脉络:
– 先在左侧把领域限定到“计算机视觉”或“机器学习”,把噪音过滤掉。
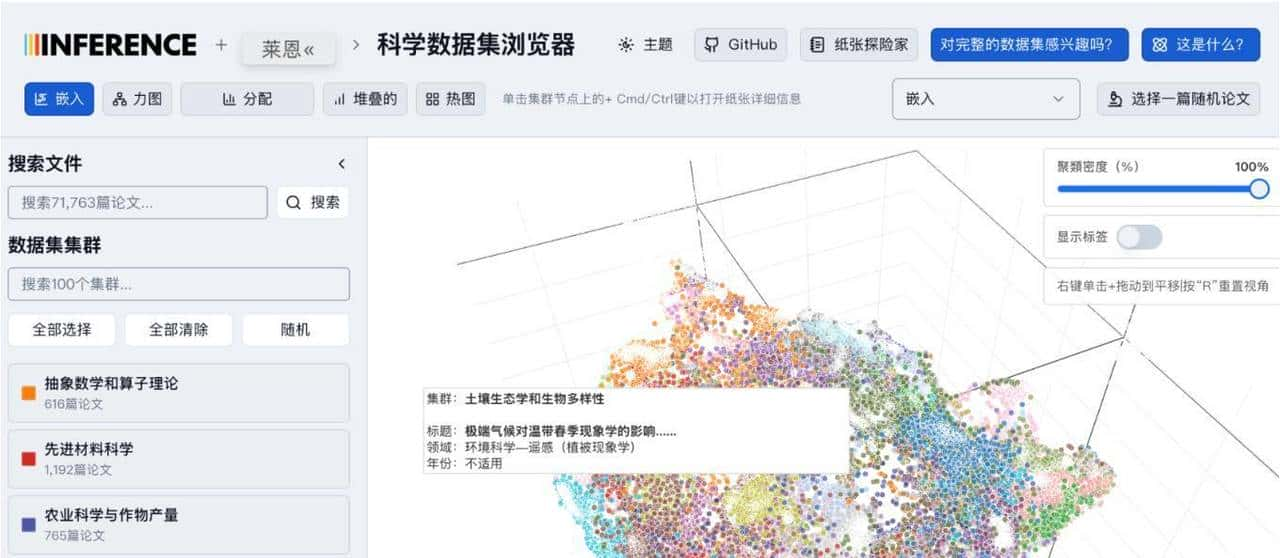
– 在搜索框里输入几串关键词,系统会把匹配的点高亮,并以语义距离把类似论文拉在一起。
– 把视角拉近,检查那些堆得很紧的簇,点开结构化摘要扫一遍方法和结果,哪篇值得深读一目了然。
– 看到一篇相关度很高的论文,顺着类似链再点进去,系统会把语义上紧邻的论文串起来,方便你沿着思路找上下游的工作。
这种流程的好处是速度感很强。跟传统全文搜索比,visual-first 的方式更擅长帮你构建领域地图,找到主题的边界和热度聚焦区。就像你在地图上先圈出一个感兴趣的区域,再去街区里挨家看门牌,省时省力。
当然,这玩意也不是完美无缺。结构化摘要是模型抽取的,偶尔会有要点缺失或表述不够严谨的地方;前端展示海量点时会做分片加载,浏览器端性能和网络会影响响应,复杂筛选或大范围漫游时可能会有卡顿。实务上还是要结合原文去核验关键信息。我的用法更偏“侦查式”:先用 Aella 把目标圈出来,再去下载原文把细节啃下去。这叫先画地图再打地基,比直接在全文堆里翻更省力。
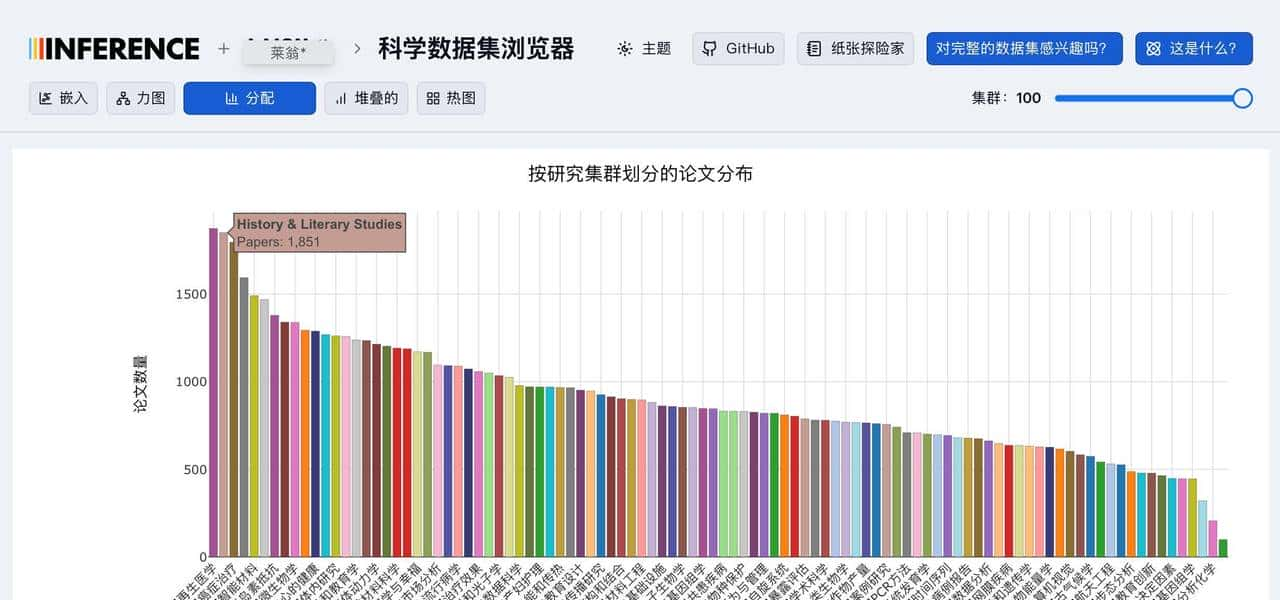
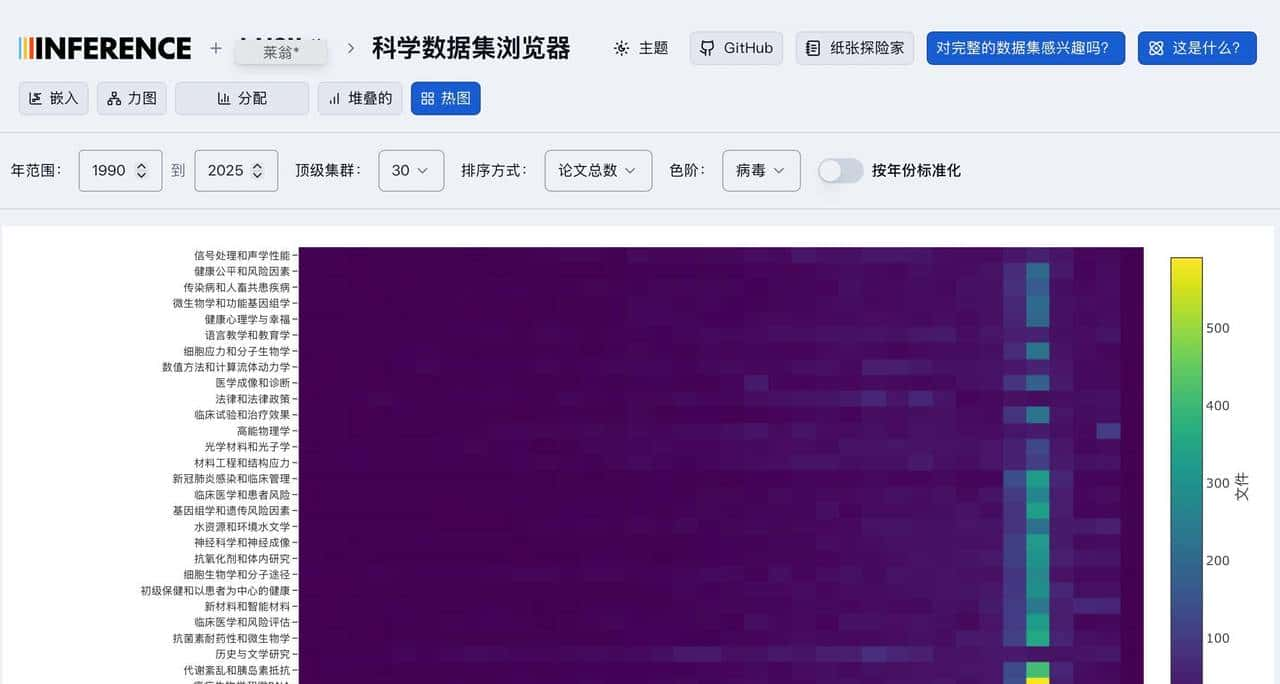
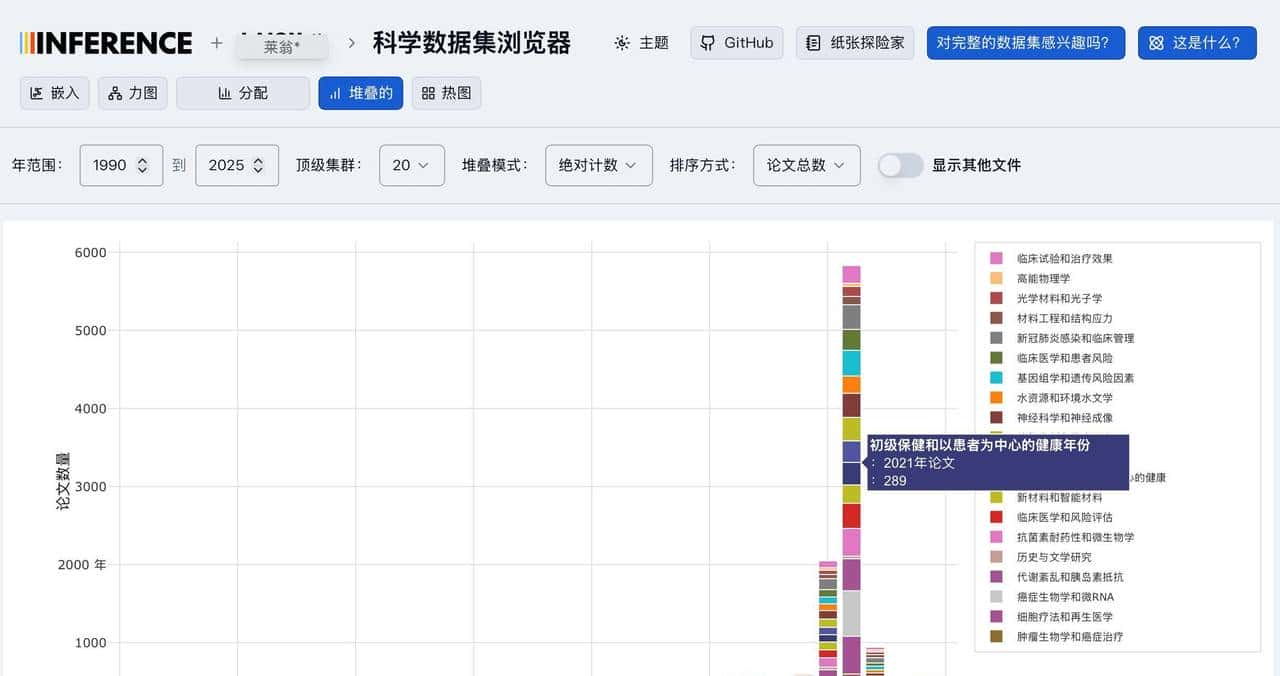
在交互细节上有些贴心的小点子值得注意。列如把鼠标放在聚簇里会高亮同类,点开某条记录还能看到模型抽取出的多段摘要项,查方法跳到方法项,查结果看结果项,这样你不必把全文拆来拆去去寻找一句话。换视图能发现不同的信息:力导向图更适合看主题间关系,柱状图适合做年发文量对比,热力图则能直观看出某些主题的密集区。界面还能把视角锁定并导出截图,便于把发现存档。
从数据和处理链路讲清楚来头也重大。LAION 提供了文本和元数据,规模级别接近一亿篇文章。Inference.net 在这批数据上做了抽取和向量化,目标是把论文的要点变成结构化字段和语义嵌入向量。Aella 取这套结果的一个子集,先做降维和聚类,再把结果提供给前端做可视化查询。生产部署上,向量索引和元数据推荐用 Cloudflare D1,R2 放大文件;前后端通过 FastAPI 对接,保证查询速度体感还不错。
说到使用提议,给几条实操经验:
– 把它当成“方向性侦查”工具,别指望摘要里每个细节都靠谱;
– 先在图上圈出你想要的主题,再按链路沿着类似论文点进去,效率比从关键词捕捞要高;
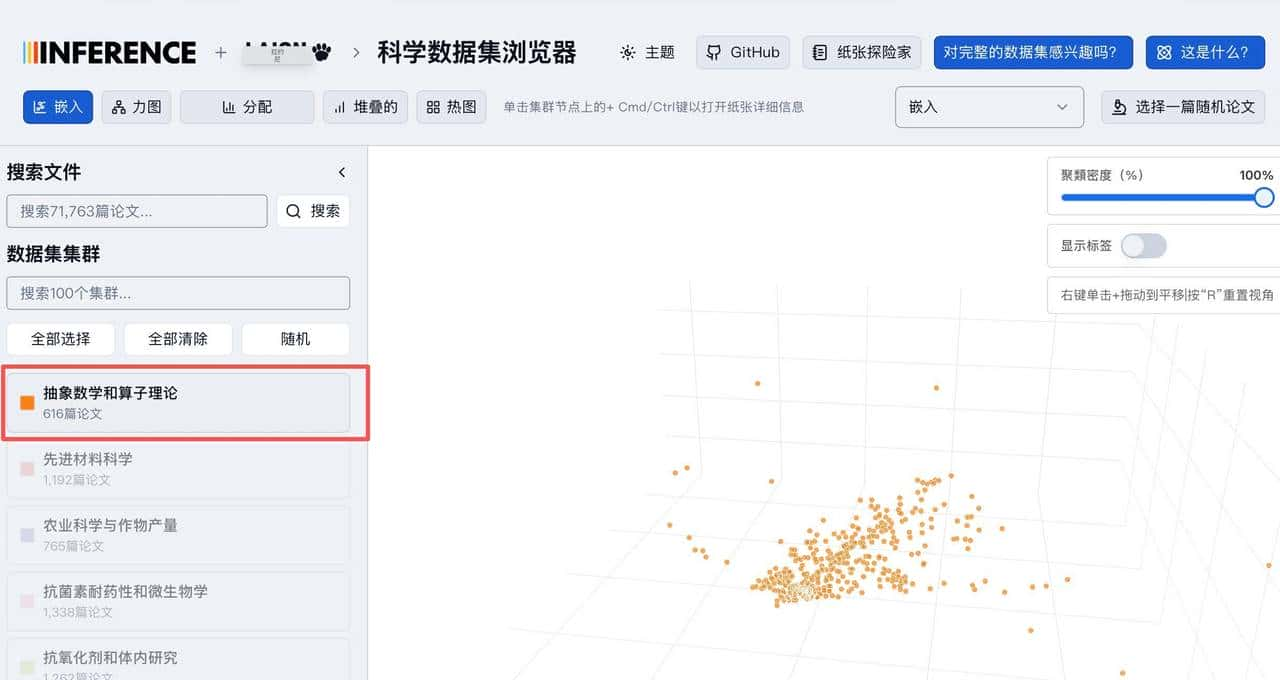
– 当发现一个密集簇时,优先看簇内代表性节点的结构化摘要,一般能迅速判断研究方法和结果的大致轮廓;
– 遇到关键实验数据或实现细节,必定回原文核对,别直接引用摘要里的断章取义。
从设计思路上看,这项目尝试解决两件事:把海量文本转成更容易处理的结构化信息;把探索门槛通过可视化降下来。技术实现也很务实:前端交互尽量轻量,后端以 FastAPI 保持响应,数据库选型兼顾开发便捷和生产扩展。把这些零件拼起来后,得到的是一个能帮你在短时间内把科研领域版图画出来的工具。


















- 最新
- 最热
只看作者