
幂等场景
场景一:前端重复提交
用户注册,用户创建商品等操作,前端都会提交一些数据给后台服务,后台需要根据用户提交的数据在数据库中创建记录。如果用户不小心多点了几次,后端收到了好几次提交,这时就会在数据库中重复创建了多条记录。这就是接口没有幂等性带来的 bug。
场景二:黑客拦截重放
接口请求参数被黑客拦截,然后进行重放。
场景三:接口超时重试
对于给第三方调用的接口,有可能会由于网络缘由而调用失败,这时,一般在设计的时候会对接口调用加上失败重试的机制。如果第一次调用已经执行了一半时,发生了网络异常。这时再次调用时就会由于脏数据的存在而出现调用异常。
场景四:消息重复消费
在使用消息中间件来处理消息队列,且手动 ack 确认消息被正常消费时。如果消费者突然断开连接,那么已经执行了一半的消息会重新放回队列。当消息被其他消费者重新消费时,如果没有幂等性,就会导致消息重复消费时结果异常,如数据库重复数据,数据库数据冲突,资源重复等。
解决方案
Token机制实现
通过token机制实现接口的幂等性,这是一种比较通用性的实现方法。示意图如下:
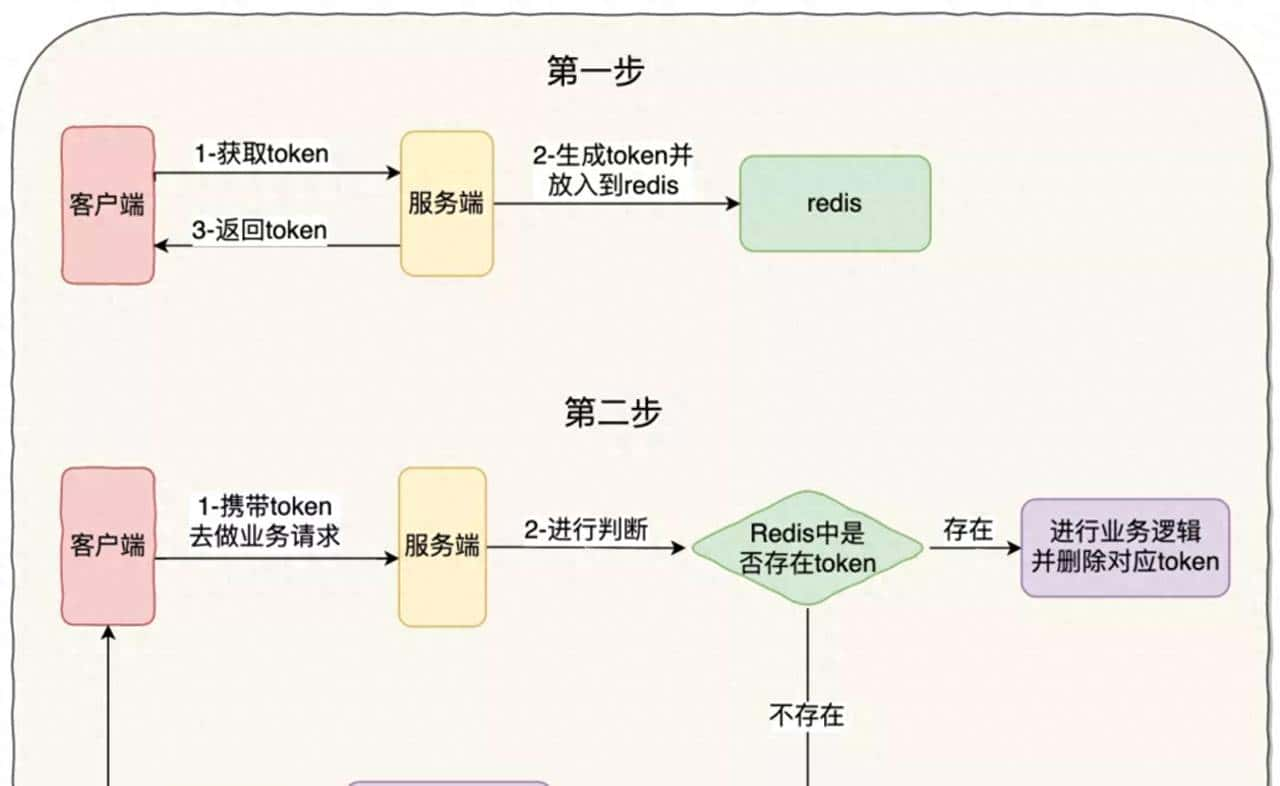
具体流程步骤:
- 客户端会先发送一个请求去获取 token,服务端会生成一个全局唯一的 ID 作为 token 保存在 redis 中,同时把这个 ID 返回给客户端
- 客户端第二次调用业务请求的时候必须携带这个 token
- 服务端会校验这个 token,如果校验成功,则执行业务,并删除 redis 中的 token
- 如果校验失败,说明 redis 中已经没有对应的 token,则表明重复操作,直接返回指定的结果给客户端
注意:
- 对 redis 中是否存在 token 以及删除的代码逻辑提议用 Lua 脚本实现,保证原子性
- 全局唯一 ID 可以思考用百度的 uid-generator、美团的 Leaf 去生成
设计Token
- 要申请,一次有效性,可以限流
- 使用删除操作来判断Token。删除成功代表校验通过
- 如果用 select+delete 来校验 Token,会存在并发问题,不提议使用,但可以用lua保证原子性
- 设置短期过期时间,如5分钟
基于MySQL实现
这种实现方式是利用 mysql 唯一索引的特性。示意图如下:
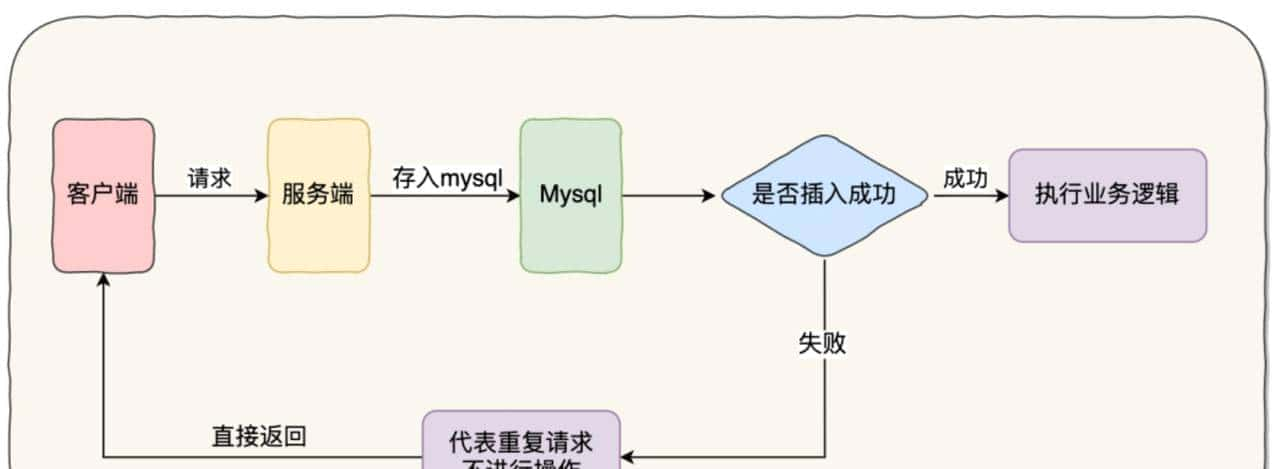
具体流程步骤:
- 建立一张去重表,其中某个字段需要建立唯一索引
- 客户端去请求服务端,服务端会将这次请求的一些信息插入这张去重表中
- 由于表中某个字段带有唯一索引,如果插入成功,证明表中没有这次请求的信息,则执行后续的业务逻辑
- 如果插入失败,则代表已经执行过当前请求,直接返回
基于Redis实现
这种实现方式是基于 SETNX 命令实现的 SETNX key value:将 key 的值设为 value ,当且仅当 key 不存在。若给定的 key 已经存在,则 SETNX 不做任何动作。该命令在设置成功时返回 1,设置失败时返回 0。示意图如下:
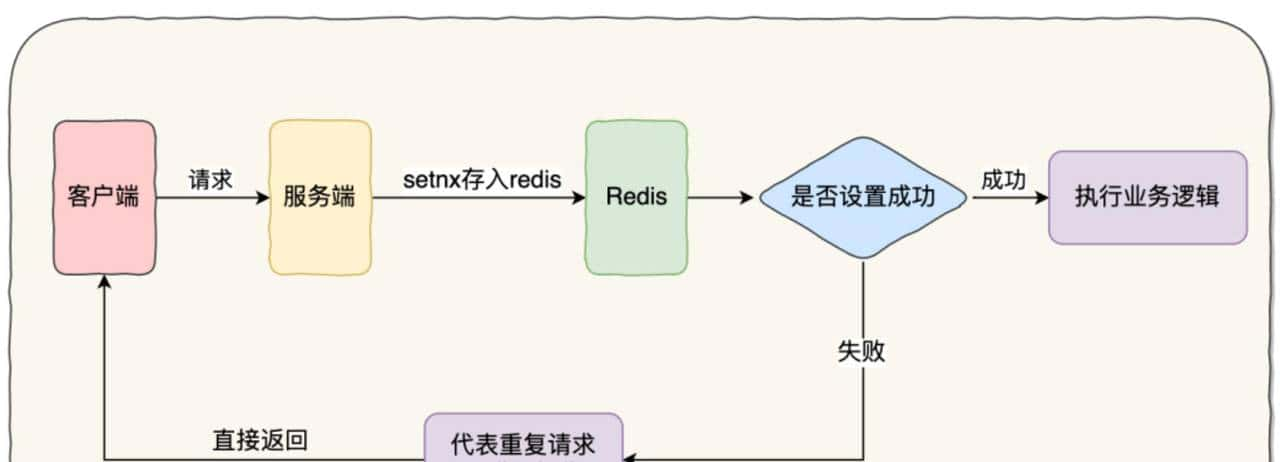
具体流程步骤:
- 客户端先请求服务端,会拿到一个能代表这次请求业务的唯一字段
- 将该字段以 SETNX 的方式存入 redis 中,并根据业务设置相应的超时时间
- 如果设置成功,证明这是第一次请求,则执行后续的业务逻辑
- 如果设置失败,则代表已经执行过当前请求,直接返回
基于业务参数实现
第一阶段:只要客户端请求有唯一的请求编号,那么就能借用Redis做这个去重:只要这个唯一请求编号在Redis存在,证明处理过,那么就认为是重复的。
第二阶段:但许多的场景下,请求并不会带这样的唯一编号。先思考简单的场景,假设请求参数只有一个字段reqParam,我们可以利用以下标识去判断这个请求是否重复:用户ID:接口名:请求参数 。
第三阶段:但我们的接口一般不是这么简单,参数一般是一个JSON。假设我们把请求参数(JSON)按KEY做升序排序,排序后拼成一个字符串作为KEY值,但这可能超级的长,所以可以思考对这个字符串求一个MD5作为参数的摘要,以这个摘要去取代reqParam的位置。
String KEY = "user_opt:U="+userId + "M=" + method + "P=" + reqParamMD5;第四阶段:上面的问题实则已经是一个很不错的解决方案了,但是实际投入使用的时候可能发现有些问题:某些请求用户短时间内重复的点击了(例如1000毫秒发送了三次请求),但绕过了上面的去重判断(不同的KEY值)。缘由是这些请求参数的字段里面,是带时间字段的,这个字段标记用户请求的时间,服务端可以借此丢弃掉一些老的请求(例如5秒前)。
总结
将业务参数(Query+Body)按KEY(排除时间字段和经纬度字段)做升序排序,排序后将按Query方式逐一拼接成参数字符串,然后将这个字符串进行MD5摘要计算,然后使用以下规则进行KEY值计算:
String KEY = "前缀标识:U=" + <用户唯一标识> + "M=" + <接口唯一标识> + "P=" + <业务参数MD5签名>;




















- 最新
- 最热
只看作者