
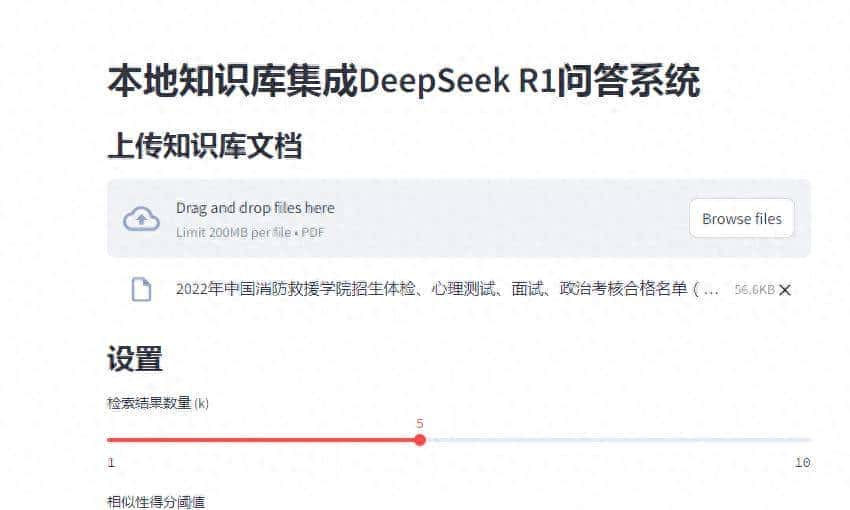
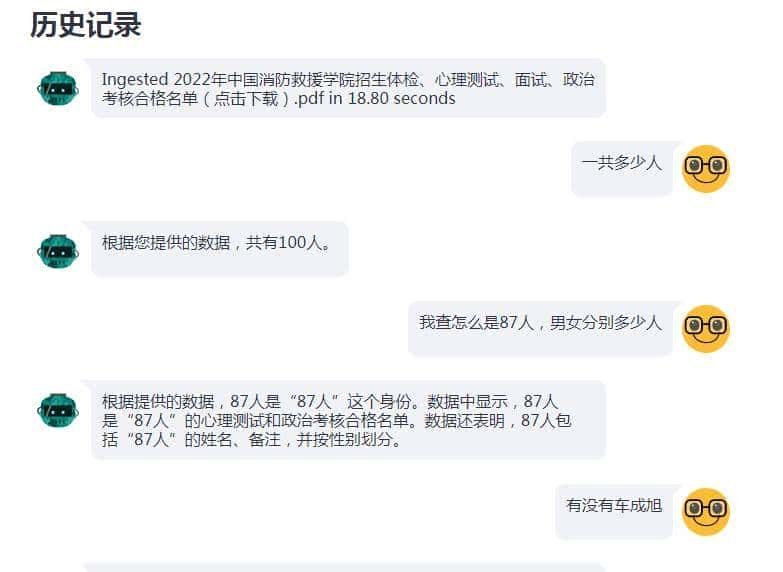
刚刚,我测试了下,效果超出想像!起个名,叫微智能问答吧,第一上传一个PDF文件做为本地知识库,再配置好deepseek大模型,开始提问:
RAG 基于 PDF 的问答系统分析
实现了基于 RAG (检索增强生成) 的 PDF 文档问答系统。以下是主要组件的分析:
- 使用 Ollama 提供的大语言模型(默认: deepseek)和嵌入模型(默认: mxbai-embed-large)
- 设置文本分割器(RecursiveCharacterTextSplitter)
- 定义了中文提示模板,用于生成简洁的回答
- 关键方法:
- ingest(): 加载PDF、分割文本、过滤元数据,并将嵌入存储到ChromaDB
- ask(): 检索相关上下文并使用RAG流程生成答案
- clear(): 重置向量存储
- 特点:
- 可配置的类似度分数阈值和检索数量
- 对缺失文档的错误处理
- 调试日志记录
界面
- UI组件:
- PDF文档上传器
- 检索参数调整滑块
- 带历史记录的聊天界面
- 清除聊天按钮
- 会话状态管理:
- 维护聊天历史和助手实例
- 处理文件摄取并显示进度指示器
- 在交互间保留设置
- 用户体验:
- 处理时显示思考指示器
- 显示文件处理时间反馈
- 对缺失文档显示明确的错误信息
改善提议
- 错误处理:
- 为不同类型的PDF解析问题添加更具体的错误处理
- 思考添加文件大小限制以防止内存问题
- 性能优化:
- 为ChromaDB添加缓存以避免重复处理一样文件
- 思考对大文档使用异步处理
- UI增强:
- 添加聊天历史下载按钮
- 加入文档预览功能
- 支持更多文件类型(如Word、Excel等)
- RAG改善:
- 尝试不同的文本分块策略
- 添加混合搜索(结合语义搜索和关键词搜索)
- 思考添加来源段落引用功能
该应用程序为基于文档的问答系统提供了坚实的基础,可以轻松扩展更多功能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。如内容涉嫌侵权,请在本页底部进入<联系我们>进行举报投诉!
THE END


















- 最新
- 最热
只看作者