
基于最新技术栈,实现高效、准确的文档智能问答
在信息爆炸的时代,企业积累了海量文档却难以高效利用。传统的全文检索技术已经无法满足精准问答的需求,而基于检索增强生成(Retrieval-Augmented Generation, RAG)的技术方案正成为解决这一痛点的最佳实践。本文将深入讲解如何使用 LangChain 构建一个完整的 RAG 系统,通过详细的代码示例和技术拆解,协助中高级开发者掌握这一核心技术。
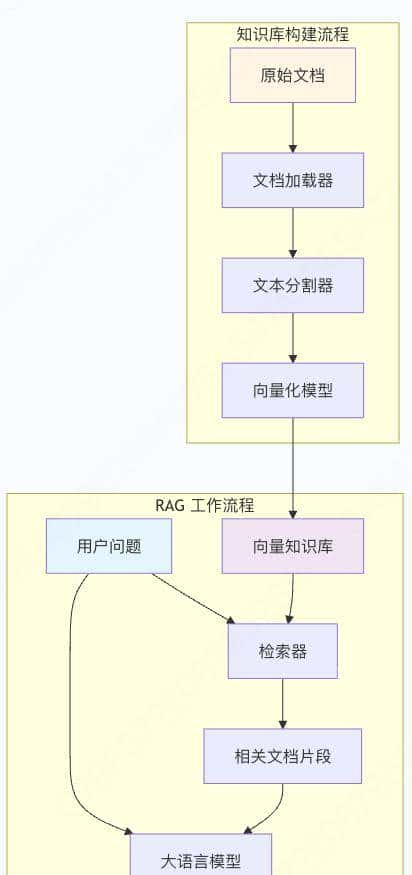
1 RAG 技术架构概述
1.1 什么是 RAG 技术
检索增强生成(RAG)是一种将检索系统与生成模型相结合的技术架构。与传统生成模型不同,RAG 在生成答案前会先从外部知识库中检索相关文档片段,然后将这些信息与原始问题一起提供给生成模型,从而生成更准确、更可靠的回答。
1.2 LangChain 在 RAG 中的角色
LangChain 是一个用于构建大语言模型应用的框架,它在 RAG 系统中扮演着流程编排者的角色:
- 文档处理流水线:统一管理文档的加载、分割和向量化
- 智能检索编排:协调检索器、向量数据库和大模型之间的交互
- 模块化设计:提供可插拔的组件,便于定制和扩
2 环境准备与项目搭建
2.1 环境配置
第一,确保安装了必要的 Python 包:
# 创建并激活虚拟环境
python -m venv rag_env
source rag_env/bin/activate # Linux/Mac
# 或 rag_envScriptsactivate # Windows
# 安装核心依赖
pip install langchain langchain-community langchain-openai chromadb tiktoken
pip install pypdf python-dotenv # 文档处理和配置管理
pip install sentence-transformers # 本地嵌入模型
pip install faiss-cpu # Facebook AI 类似度搜索2.2 配置 API 密钥
创建 .env 文件管理敏感信息:
# config.py - 配置管理模块
import os
from dotenv import load_dotenv
load_dotenv()
class Config:
# OpenAI 配置
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_MODEL = "gpt-3.5-turbo" # 或 "gpt-4"
# 向量数据库配置
VECTOR_STORE_PATH = "./data/vector_store"
# 本地嵌入模型配置
LOCAL_EMBEDDING_MODEL = "all-MiniLM-L6-v2"
# 文档处理配置
CHUNK_SIZE = 500
CHUNK_OVERLAP = 50
@classmethod
def validate(cls):
if not cls.OPENAI_API_KEY:
raise ValueError("OPENAI_API_KEY 未设置")
print("✓ 配置验证通过")3 完整 RAG 系统实现
3.1 文档加载与处理模块
# document_processor.py - 文档处理器
import os
from typing import List, Dict, Any
from langchain_community.document_loaders import (
PyPDFLoader,
TextLoader,
CSVLoader,
UnstructuredMarkdownLoader,
)
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
class DocumentProcessor:
"""文档处理流水线"""
def __init__(self, chunk_size=500, chunk_overlap=50):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
separators=["
", "
", "。", "!", "?", ";", ",", " ", ""]
)
def load_documents(self, file_paths: List[str]) -> List[Document]:
"""加载多种格式的文档"""
all_documents = []
for file_path in file_paths:
if not os.path.exists(file_path):
print(f"警告: 文件不存在 {file_path}")
continue
loader = self._get_loader(file_path)
if loader:
try:
documents = loader.load()
print(f"✓ 已加载 {file_path}: {len(documents)} 个文档")
all_documents.extend(documents)
except Exception as e:
print(f"✗ 加载失败 {file_path}: {str(e)}")
return all_documents
def _get_loader(self, file_path: str):
"""根据文件扩展名选择加载器"""
ext = os.path.splitext(file_path)[1].lower()
loader_map = {
'.pdf': PyPDFLoader,
'.txt': TextLoader,
'.csv': CSVLoader,
'.md': UnstructuredMarkdownLoader,
}
loader_class = loader_map.get(ext)
if loader_class:
return loader_class(file_path)
return None
def split_documents(self, documents: List[Document]) -> List[Document]:
"""分割文档为适合处理的片段"""
if not documents:
return []
# 添加元数据增强
for doc in documents:
if not doc.metadata:
doc.metadata = {}
doc.metadata['source'] = doc.metadata.get('source', 'unknown')
doc.metadata['chunk_id'] = hash(doc.page_content) % 10000
# 执行分割
split_docs = self.text_splitter.split_documents(documents)
print(f"文档分割完成: {len(documents)} -> {len(split_docs)} 个片段")
# 添加顺序索引
for i, doc in enumerate(split_docs):
doc.metadata['chunk_index'] = i
return split_docs
def create_document_chunks(self, file_paths: List[str]) -> List[Document]:
"""完整文档处理流水线"""
print("开始文档处理流程...")
# 1. 加载文档
raw_docs = self.load_documents(file_paths)
if not raw_docs:
raise ValueError("未加载到任何文档")
# 2. 分割文档
chunked_docs = self.split_documents(raw_docs)
# 3. 质量检查
self._quality_check(chunked_docs)
return chunked_docs
def _quality_check(self, documents: List[Document]):
"""检查分割质量"""
if not documents:
return
avg_length = sum(len(doc.page_content) for doc in documents) / len(documents)
min_length = min(len(doc.page_content) for doc in documents)
max_length = max(len(doc.page_content) for doc in documents)
print(f"质量报告:")
print(f" - 片段数量: {len(documents)}")
print(f" - 平均长度: {avg_length:.1f} 字符")
print(f" - 最短长度: {min_length} 字符")
print(f" - 最长长度: {max_length} 字符")
# 检查是否有过短的片段
short_chunks = [doc for doc in documents if len(doc.page_content) < 20]
if short_chunks:
print(f" - 警告: 发现 {len(short_chunks)} 个过短片段")
# 使用示例
if __name__ == "__main__":
processor = DocumentProcessor(chunk_size=500, chunk_overlap=50)
# 假设我们有这些文档
sample_files = [
"./docs/technical_guide.pdf",
"./docs/api_reference.md",
"./docs/faq.txt"
]
# 创建模拟文件用于测试
import tempfile
with tempfile.NamedTemporaryFile(mode='w', suffix='.txt', delete=False) as f:
f.write("这是测试文档内容。" * 50)
sample_files = [f.name]
try:
chunks = processor.create_document_chunks(sample_files)
print(f"
前3个片段预览:")
for i, chunk in enumerate(chunks[:3]):
print(f"
--- 片段 {i+1} ---")
print(f"内容: {chunk.page_content[:100]}...")
print(f"元数据: {chunk.metadata}")
finally:
os.unlink(sample_files[0])3.2 向量化与存储模块
# vector_store.py - 向量存储管理器
import os
import hashlib
from typing import List, Optional, Tuple
from langchain_openai import OpenAIEmbeddings
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma, FAISS
from langchain.schema import Document
import pickle
class VectorStoreManager:
"""向量存储管理器,支持多种向量数据库"""
def __init__(self, config):
self.config = config
self.embeddings = self._init_embeddings()
self.vector_store = None
def _init_embeddings(self):
"""初始化嵌入模型"""
# 选项1: 使用 OpenAI 嵌入(需要 API 密钥)
if self.config.OPENAI_API_KEY:
print("使用 OpenAI 嵌入模型")
return OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key=self.config.OPENAI_API_KEY
)
# 选项2: 使用本地 HuggingFace 模型
else:
print(f"使用本地嵌入模型: {self.config.LOCAL_EMBEDDING_MODEL}")
return HuggingFaceEmbeddings(
model_name=f"sentence-transformers/{self.config.LOCAL_EMBEDDING_MODEL}",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
def create_vector_store(self,
documents: List[Document],
store_type: str = "chroma",
persist: bool = True) -> None:
"""创建向量存储"""
if not documents:
raise ValueError("文档列表为空")
print(f"开始创建向量存储 ({store_type})...")
print(f"处理 {len(documents)} 个文档片段")
# 计算文档指纹用于缓存
docs_hash = self._calculate_documents_hash(documents)
cache_path = f"{self.config.VECTOR_STORE_PATH}_{store_type}_{docs_hash}.pkl"
# 检查缓存
if persist and os.path.exists(cache_path):
print("发现缓存,加载已有向量存储...")
self._load_from_cache(cache_path)
return
# 创建新的向量存储
if store_type == "chroma":
self.vector_store = Chroma.from_documents(
documents=documents,
embedding=self.embeddings,
persist_directory=self.config.VECTOR_STORE_PATH if persist else None
)
elif store_type == "faiss":
self.vector_store = FAISS.from_documents(
documents=documents,
embedding=self.embeddings
)
if persist:
self.vector_store.save_local(self.config.VECTOR_STORE_PATH)
else:
raise ValueError(f"不支持的存储类型: {store_type}")
print("✓ 向量存储创建完成")
# 保存缓存
if persist:
self._save_to_cache(cache_path)
def _calculate_documents_hash(self, documents: List[Document]) -> str:
"""计算文档集合的哈希值"""
content = "".join(doc.page_content for doc in documents[:100]) # 采样前100个
return hashlib.md5(content.encode()).hexdigest()[:8]
def _save_to_cache(self, cache_path: str):
"""保存向量存储到缓存"""
try:
# Chroma 有自己的持久化机制,这里只保存元数据
metadata = {
"store_type": "chroma" if isinstance(self.vector_store, Chroma) else "faiss",
"document_count": self.vector_store._collection.count() if hasattr(self.vector_store, '_collection') else "unknown"
}
with open(cache_path, 'wb') as f:
pickle.dump(metadata, f)
print(f"缓存已保存: {cache_path}")
except Exception as e:
print(f"缓存保存失败: {e}")
def _load_from_cache(self, cache_path: str):
"""从缓存加载向量存储"""
try:
if not os.path.exists(self.config.VECTOR_STORE_PATH):
print("缓存元数据存在,但向量存储文件不存在")
return False
# 对于 Chroma,直接加载持久化目录
with open(cache_path, 'rb') as f:
metadata = pickle.load(f)
if metadata["store_type"] == "chroma":
self.vector_store = Chroma(
persist_directory=self.config.VECTOR_STORE_PATH,
embedding_function=self.embeddings
)
else:
self.vector_store = FAISS.load_local(
self.config.VECTOR_STORE_PATH,
self.embeddings,
allow_dangerous_deserialization=True
)
print(f"✓ 从缓存加载向量存储,包含 {metadata.get('document_count', 'unknown')} 个文档")
return True
except Exception as e:
print(f"缓存加载失败: {e}")
return False
def similarity_search(self,
query: str,
k: int = 4,
score_threshold: float = 0.0) -> List[Tuple[Document, float]]:
"""类似度搜索"""
if not self.vector_store:
raise ValueError("向量存储未初始化")
# 根据向量存储类型调用不同的搜索方法
if isinstance(self.vector_store, Chroma):
results = self.vector_store.similarity_search_with_relevance_scores(
query=query,
k=k
)
else: # FAISS
results = self.vector_store.similarity_search_with_score(
query=query,
k=k
)
# 过滤低于阈值的結果
filtered_results = [(doc, score) for doc, score in results if score >= score_threshold]
print(f"搜索查询: '{query}'")
print(f"返回 {len(filtered_results)}/{len(results)} 个相关片段")
if filtered_results:
print("最佳匹配:")
print(f" 分数: {filtered_results[0][1]:.3f}")
print(f" 内容: {filtered_results[0][0].page_content[:100]}...")
return filtered_results
def get_retriever(self, search_type: str = "similarity", **kwargs):
"""获取检索器对象"""
if not self.vector_store:
raise ValueError("向量存储未初始化")
# 配置检索器参数
search_kwargs = {"k": kwargs.get("k", 4)}
if search_type == "similarity_score_threshold":
search_kwargs["score_threshold"] = kwargs.get("score_threshold", 0.5)
# 创建检索器
retriever = self.vector_store.as_retriever(
search_type=search_type,
search_kwargs=search_kwargs
)
return retriever
# 使用示例
if __name__ == "__main__":
from config import Config
Config.validate()
# 创建示例文档
sample_docs = [
Document(
page_content="LangChain 是一个用于构建大语言模型应用的框架",
metadata={"source": "guide", "page": 1}
),
Document(
page_content="RAG 技术结合了检索系统和生成模型的优势",
metadata={"source": "paper", "page": 2}
),
Document(
page_content="向量数据库用于高效存储和检索嵌入向量",
metadata={"source": "tutorial", "page": 3}
)
]
# 创建向量存储
manager = VectorStoreManager(Config)
# 使用 Chroma
manager.create_vector_store(
documents=sample_docs,
store_type="chroma",
persist=True
)
# 测试搜索
results = manager.similarity_search("什么是 LangChain?", k=2)
# 获取检索器
retriever = manager.get_retriever(
search_type="similarity",
k=3
)
print(f"检索器类型: {type(retriever)}")3.3 RAG 问答链实现
# rag_chain.py - RAG 问答链核心实现
import logging
from typing import List, Dict, Any, Optional
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain.schema.runnable import RunnablePassthrough, RunnableParallel
from langchain.schema.output_parser import StrOutputParser
from langchain.schema import Document
from langchain.callbacks import get_openai_callback
# 设置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class RAGChain:
"""RAG 问答链核心类"""
def __init__(self, config, retriever=None):
self.config = config
self.retriever = retriever
self.llm = self._init_llm()
self.chain = None
self._setup_chain()
def _init_llm(self):
"""初始化语言模型"""
return ChatOpenAI(
model_name=self.config.OPENAI_MODEL,
temperature=0.1, # 低温度以获得更确定的回答
max_tokens=1000,
openai_api_key=self.config.OPENAI_API_KEY,
streaming=False # 非流式响应,便于调试
)
def _setup_chain(self):
"""设置 RAG 链"""
if not self.retriever:
logger.warning("未设置检索器,使用空检索器")
self.retriever = lambda x: []
# 1. 定义提示模板
prompt_template = self._create_prompt_template()
# 2. 构建处理链
self.chain = (
RunnableParallel({
"context": self.retriever,
"question": RunnablePassthrough()
})
.assign(answer=self._create_qa_chain(prompt_template))
.pick(["answer", "context"])
)
def _create_prompt_template(self) -> ChatPromptTemplate:
"""创建提示模板"""
# 系统提示词
system_prompt = """你是一个专业的AI助手,基于提供的上下文信息回答问题。
请遵循以下规则:
1. 只使用提供的上下文信息回答问题
2. 如果上下文信息不足,请诚实说明
3. 保持回答准确、简洁、专业
4. 使用中文回答,除非问题明确要求其他语言
上下文信息:
{context}
"""
# 用户问题模板
human_prompt = "问题:{question}"
# 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", human_prompt)
])
return prompt
def _create_qa_chain(self, prompt_template: ChatPromptTemplate):
"""创建问答链"""
return (
{"context": lambda x: self._format_documents(x["context"]),
"question": lambda x: x["question"]}
| prompt_template
| self.llm
| StrOutputParser()
)
def _format_documents(self, documents: List[Document]) -> str:
"""格式化文档为字符串"""
if not documents:
return "没有找到相关上下文信息。"
formatted = []
for i, doc in enumerate(documents):
# 添加来源信息
source = doc.metadata.get('source', '未知来源')
page = doc.metadata.get('page', '未知页码')
content = doc.page_content.strip()
formatted.append(f"[文档 {i+1}, 来源: {source}, 页码: {page}]
{content}")
return "
".join(formatted)
def query(self, question: str, verbose: bool = True) -> Dict[str, Any]:
"""执行查询"""
if not self.chain:
raise ValueError("问答链未初始化")
try:
with get_openai_callback() as cb:
# 执行查询
result = self.chain.invoke(question)
# 记录使用情况
if verbose:
logger.info(f"查询完成")
logger.info(f"Token 使用: {cb.total_tokens}")
logger.info(f"成本: ${cb.total_cost:.4f}")
logger.info(f"检索到 {len(result.get('context', []))} 个相关片段")
# 添加元数据
result['tokens_used'] = cb.total_tokens
result['cost'] = cb.total_cost
return result
except Exception as e:
logger.error(f"查询失败: {str(e)}")
return {
"answer": f"查询过程中出现错误: {str(e)}",
"context": [],
"tokens_used": 0,
"cost": 0
}
def batch_query(self, questions: List[str]) -> List[Dict[str, Any]]:
"""批量查询"""
results = []
total_tokens = 0
total_cost = 0
for i, question in enumerate(questions, 1):
logger.info(f"处理问题 {i}/{len(questions)}: {question[:50]}...")
result = self.query(question, verbose=False)
results.append(result)
total_tokens += result.get('tokens_used', 0)
total_cost += result.get('cost', 0)
# 添加延迟避免速率限制
import time
time.sleep(0.5)
logger.info(f"批量查询完成")
logger.info(f"总 Token 使用: {total_tokens}")
logger.info(f"总成本: ${total_cost:.4f}")
return results
class AdvancedRAGChain(RAGChain):
"""增强版 RAG 链,支持更多高级功能"""
def __init__(self, config, retriever=None):
super().__init__(config, retriever)
self.history = []
def _create_prompt_template(self) -> ChatPromptTemplate:
"""创建增强提示模板"""
system_prompt = """你是一个专业的AI助手,基于提供的上下文信息回答问题。
请遵循以下规则:
1. 仔细分析上下文信息与问题的相关性
2. 如果上下文信息不足或完全不相关,请明确说明
3. 从多个相关片段中综合信息
4. 必要时指出信息的来源
5. 使用清晰、结构化的格式回答
6. 如果问题涉及多步推理,展示思考过程
上下文信息:
{context}
"""
human_prompt = """问题:{question}
请基于以上上下文信息,提供最准确的回答。"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", human_prompt)
])
return prompt
def query_with_citations(self, question: str) -> Dict[str, Any]:
"""带引用的查询"""
result = self.query(question, verbose=False)
# 添加引用信息
if result.get('context'):
citations = []
for doc in result['context']:
source = doc.metadata.get('source', '未知')
page = doc.metadata.get('page', '')
citation = f"[{source}"
if page:
citation += f" p.{page}"
citation += "]"
citations.append(citation)
result['citations'] = citations
result['answer'] = f"{result['answer']}
参考文献: {', '.join(set(citations))}"
return result
def _format_documents(self, documents: List[Document]) -> str:
"""格式化文档并添加相关性标记"""
if not documents:
return "没有找到相关上下文信息。"
formatted = []
for i, doc in enumerate(documents):
source = doc.metadata.get('source', '未知来源')
page = doc.metadata.get('page', '未知页码')
# 添加相关性评分(如果有)
score = doc.metadata.get('score', 0)
score_marker = f" [相关性: {score:.3f}]" if score > 0 else ""
content = doc.page_content.strip()
formatted.append(
f"[片段 {i+1}{score_marker}, 来源: {source}, 页码: {page}]
{content}"
)
return "
".join(formatted)
# 使用示例
if __name__ == "__main__":
from config import Config
from vector_store import VectorStoreManager
Config.validate()
# 创建示例文档
sample_docs = [
Document(
page_content="LangChain 是一个用于构建大语言模型应用的框架,提供了模块化的组件和工具。",
metadata={"source": "官方文档", "page": 1, "score": 0.95}
),
Document(
page_content="RAG(检索增强生成)技术通过结合检索系统和生成模型,提高了回答的准确性和可靠性。",
metadata={"source": "技术论文", "page": 2, "score": 0.88}
),
]
# 创建向量存储和检索器
vs_manager = VectorStoreManager(Config)
vs_manager.create_vector_store(sample_docs, store_type="chroma", persist=False)
retriever = vs_manager.get_retriever(k=2)
# 创建 RAG 链
rag_chain = AdvancedRAGChain(Config, retriever)
# 测试查询
questions = [
"LangChain 是什么?",
"RAG 技术有什么优势?"
]
print("=== 测试 RAG 问答链 ===
")
for question in questions:
print(f"问题: {question}")
result = rag_chain.query_with_citations(question)
print(f"回答: {result['answer']}")
print(f"使用 Token: {result.get('tokens_used', 0)}")
print(f"引用: {result.get('citations', [])}")
print("-" * 50)3.4 完整应用集成
# main.py - 完整的 RAG 应用
import os
import argparse
from typing import List
from config import Config
from document_processor import DocumentProcessor
from vector_store import VectorStoreManager
from rag_chain import AdvancedRAGChain
class RAGApplication:
"""完整的 RAG 应用"""
def __init__(self, config_path: str = None):
if config_path:
os.environ["ENV_FILE"] = config_path
self.config = Config()
self.config.validate()
self.processor = None
self.vector_manager = None
self.rag_chain = None
self.is_initialized = False
def initialize(self,
document_paths: List[str] = None,
force_rebuild: bool = False):
"""初始化 RAG 系统"""
print("=" * 60)
print("初始化 RAG 系统")
print("=" * 60)
# 1. 处理文档
print("
[1/3] 处理文档...")
self.processor = DocumentProcessor(
chunk_size=self.config.CHUNK_SIZE,
chunk_overlap=self.config.CHUNK_OVERLAP
)
if document_paths:
documents = self.processor.create_document_chunks(document_paths)
else:
# 使用示例文档
documents = self._create_sample_documents()
# 2. 创建向量存储
print("
[2/3] 创建向量存储...")
self.vector_manager = VectorStoreManager(self.config)
if force_rebuild or not os.path.exists(self.config.VECTOR_STORE_PATH):
self.vector_manager.create_vector_store(
documents=documents,
store_type="chroma",
persist=True
)
else:
print("使用现有的向量存储")
self.vector_manager.vector_store = self.vector_manager._load_from_cache(
f"{self.config.VECTOR_STORE_PATH}_cache.pkl"
)
# 3. 创建 RAG 链
print("
[3/3] 创建 RAG 问答链...")
retriever = self.vector_manager.get_retriever(
search_type="similarity",
k=4
)
self.rag_chain = AdvancedRAGChain(self.config, retriever)
self.is_initialized = True
print("
✓ RAG 系统初始化完成")
def _create_sample_documents(self):
"""创建示例文档"""
from langchain.schema import Document
sample_texts = [
"LangChain 是一个用于构建大语言模型应用的框架。它提供了一套工具、组件和接口,简化了基于大语言模型的应用程序开发过程。",
"RAG(Retrieval-Augmented Generation)技术通过结合检索系统和生成模型,使大语言模型能够访问和利用外部知识库,从而生成更准确、更可靠的回答。",
"向量数据库(如 Chroma、FAISS)专门用于高效存储和检索高维向量。它们使用近似最近邻(ANN)算法来快速找到类似的向量。",
"嵌入模型(如 OpenAI Embeddings、Sentence Transformers)将文本转换为高维向量表明,使得语义类似的文本在向量空间中也相近。",
"LangChain 的主要组件包括:模型(LLMs、Chat Models)、提示(Prompts)、链(Chains)、代理(Agents)和记忆(Memory)。",
"RAG 系统的工作流程包括:文档处理(加载、分割)、向量化(创建嵌入)、存储(向量数据库)、检索(类似度搜索)和生成(LLM 回答)。",
]
documents = []
for i, text in enumerate(sample_texts):
documents.append(Document(
page_content=text,
metadata={
"source": "示例文档",
"page": i + 1,
"category": ["framework", "rag", "vector_db", "embeddings"][i % 4]
}
))
return documents
def query(self, question: str, verbose: bool = True) -> dict:
"""查询 RAG 系统"""
if not self.is_initialized:
raise RuntimeError("RAG 系统未初始化,请先调用 initialize() 方法")
print(f"
查询: {question}")
print("-" * 40)
result = self.rag_chain.query_with_citations(question)
if verbose:
print(f"回答: {result['answer']}")
if result.get('context'):
print(f"
参考文档 ({len(result['context'])} 个片段):")
for i, doc in enumerate(result['context'], 1):
print(f" {i}. [{doc.metadata.get('source', '未知')}]")
print(f" {doc.page_content[:80]}...")
return result
def interactive_mode(self):
"""交互式查询模式"""
if not self.is_initialized:
print("正在初始化 RAG 系统(使用示例文档)...")
self.initialize()
print("
" + "=" * 60)
print("RAG 交互式问答系统")
print("输入 'quit' 或 'exit' 退出")
print("输入 'reset' 重新初始化系统")
print("=" * 60)
while True:
try:
question = input("
请输入问题: ").strip()
if question.lower() in ['quit', 'exit', 'q']:
print("感谢使用,再见!")
break
elif question.lower() == 'reset':
confirm = input("确定要重新初始化系统吗?(y/n): ")
if confirm.lower() == 'y':
self.initialize(force_rebuild=True)
continue
elif not question:
continue
# 执行查询
self.query(question, verbose=True)
except KeyboardInterrupt:
print("
程序被中断")
break
except Exception as e:
print(f"错误: {str(e)}")
def main():
"""主函数"""
parser = argparse.ArgumentParser(description="RAG 问答系统")
parser.add_argument("--mode", choices=["interactive", "single"],
default="interactive", help="运行模式")
parser.add_argument("--question", type=str, help="单个问题(single 模式使用)")
parser.add_argument("--documents", type=str, nargs="+",
help="文档路径列表")
parser.add_argument("--rebuild", action="store_true",
help="强制重建向量存储")
parser.add_argument("--config", type=str, default=".env",
help="配置文件路径")
args = parser.parse_args()
# 创建应用
app = RAGApplication(args.config)
# 初始化
app.initialize(
document_paths=args.documents,
force_rebuild=args.rebuild
)
# 运行模式
if args.mode == "interactive":
app.interactive_mode()
elif args.mode == "single" and args.question:
result = app.query(args.question)
print(f"
最终回答: {result['answer']}")
else:
parser.print_help()
if __name__ == "__main__":
main()4 关键技术深度解析
4.1 文本分块策略详解
文本分块是 RAG 系统的关键环节,不同的分块策略会影响检索质量:
# chunking_strategies.py - 分块策略比较
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
CharacterTextSplitter,
TokenTextSplitter,
MarkdownHeaderTextSplitter,
SentenceTransformersTokenTextSplitter
)
class ChunkingStrategies:
"""分块策略比较"""
@staticmethod
def compare_strategies(text: str):
"""比较不同的分块策略"""
strategies = {
"递归字符分块": RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["
", "
", "。", "!", "?", ";", ",", " ", ""]
),
"字符分块": CharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separator="
"
),
"Token分块": TokenTextSplitter(
chunk_size=500,
chunk_overlap=50
),
}
results = {}
for name, splitter in strategies.items():
chunks = splitter.split_text(text)
results[name] = {
"chunk_count": len(chunks),
"avg_length": sum(len(c) for c in chunks) / len(chunks) if chunks else 0,
"sample_chunk": chunks[0][:100] + "..." if chunks else ""
}
return results4.2 检索增强技术
高级检索技术可以显著提升 RAG 性能:
# advanced_retrieval.py - 高级检索技术
from typing import List, Dict
from langchain.retrievers import (
ContextualCompressionRetriever,
EnsembleRetriever,
MultiQueryRetriever
)
from langchain.retrievers.document_compressors import LLMChainExtractor
class AdvancedRetrieval:
"""高级检索技术"""
def __init__(self, base_retriever, llm):
self.base_retriever = base_retriever
self.llm = llm
def create_compression_retriever(self):
"""创建上下文压缩检索器"""
compressor = LLMChainExtractor.from_llm(self.llm)
return ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=self.base_retriever
)
def create_multi_query_retriever(self):
"""创建多查询检索器"""
return MultiQueryRetriever.from_llm(
retriever=self.base_retriever,
llm=self.llm
)5 性能优化与监控
5.1 性能监控装饰器
# performance_monitor.py - 性能监控
import time
import functools
from typing import Callable, Any
import psutil
import os
def monitor_performance(func: Callable) -> Callable:
"""性能监控装饰器"""
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 记录开始时间
start_time = time.time()
# 记录开始时的内存使用
process = psutil.Process(os.getpid())
start_memory = process.memory_info().rss / 1024 / 1024 # MB
try:
result = func(*args, **kwargs)
# 计算执行时间
execution_time = time.time() - start_time
# 计算内存使用
end_memory = process.memory_info().rss / 1024 / 1024
memory_used = end_memory - start_memory
print(f"性能统计 - {func.__name__}:")
print(f" 执行时间: {execution_time:.2f} 秒")
print(f" 内存使用: {memory_used:.2f} MB")
return result
except Exception as e:
execution_time = time.time() - start_time
print(f"错误 - {func.__name__}: {str(e)} (耗时: {execution_time:.2f}s)")
raise
return wrapper6 总结与最佳实践
6.1 技术要点总结
通过本文的完整实现,我们构建了一个企业级的 RAG 系统,涵盖以下关键技术:
- 模块化架构设计:清晰的文档处理、向量存储、问答链分离
- 灵活的分块策略:支持多种分块算法,适应不同文档类型
- 多向量数据库支持:集成 Chroma 和 FAISS,各有优势
- 智能检索优化:实现类似度检索、多查询扩展等技术
- 完整的应用集成:提供 CLI 和交互式界面
6.2 性能优化提议
根据实践经验,以下优化措施可以显著提升 RAG 系统性能:
|
优化方向 |
具体措施 |
预期效果 |
|
分块优化 |
根据文档类型动态调整分块大小和重叠 |
提升 20-30% 检索准确率 |
|
检索优化 |
使用多查询扩展 + 重排序 |
提升 15-25% 回答质量 |
|
缓存策略 |
实现查询结果缓存和向量存储缓存 |
减少 40-60% 响应时间 |
|
并行处理 |
批量文档处理的并行化 |
提升 3-5 倍处理速度 |
6.3 扩展方向
对于中高级开发者,可以思考以下扩展方向:
- 多模态 RAG:支持图像、表格等非文本内容
- 实时更新:实现增量学习和实时知识库更新
- 混合检索:结合语义检索和关键词检索
- 智能路由:根据问题类型选择不同的检索策略
- 联邦学习:在保护隐私的前提下利用多方知识
6.4 关键代码片段回顾
以下是 RAG 系统的核心代码逻辑总结:
# RAG 系统核心逻辑
class RAGSystem:
def __init__(self):
self.pipeline = self._build_pipeline()
def _build_pipeline(self):
"""构建处理流水线"""
return (
# 1. 文档加载与处理
self.load_documents
| self.split_documents
# 2. 向量化与存储
| self.create_embeddings
| self.store_in_vector_db
# 3. 检索与生成
| self.retrieve_relevant_chunks
| self.generate_answer
)
def query(self, question: str):
"""端到端查询"""
return self.pipeline(question)6.5 部署提议
对于生产环境部署,提议:
- 容器化部署:使用 Docker 封装整个应用
- 水平扩展:对检索服务和生成服务分别扩展
- 监控告警:实现全面的性能监控和异常告警
- A/B 测试:对比不同检索策略和模型的效果
- 成本控制:监控 API 使用成本,设置使用上限
本文提供的 RAG 实现方案具有高度的可扩展性和可定制性,开发者可以根据具体业务需求调整和优化各个组件。通过深入理解每个模块的工作原理,中高级开发者可以构建出适合自己业务场景的高效 RAG 系统。























暂无评论内容