

这是一篇关于 NeurIPS 2025 最新录用论文《Gated Attention for Large Language Models》的深度技术解读。这篇论文由阿里巴巴 Qwen 团队主导,其核心发现已经被应用在下一代 Qwen 模型(Qwen3-Next)中。
核心看点:为什么在此刻,我们需要重新审视 Transformer 中最基础的组件?Qwen 团队发现,只需在注意力机制中增加一个简单的“门控(Gating)”,不仅能让训练更稳定、性能更强,还能意外地消除困扰业界已久的“注意力黑洞(Attention Sink)”现象。
01
想象一下,你正在阅读一本厚厚的百科全书。作为人类,你具备一种高级能力:略读。遇到无关紧要的废话,你的大脑会自动“关灯”,跳过不读。
但对于目前的 Transformer 大模型(LLM)来说,这却是件难事。
核心症结在于那个著名的 Softmax 函数。在标准的注意力机制(Attention)中,Softmax 强制要求所有的注意力分数加起来必须等于 1。
这就导致了一个尴尬的局面:即使当前的上下文完全是噪声或无关信息,模型也必须找个地方把这“1”的注意力分配出去。
这就好比一个强迫症患者,即使屋里没人,也必须盯着墙上的某个点看。
在 LLM 中,这个“墙上的点”一般是序列的第一个 Token(起始符)。由于无处安放的注意力被迫堆积在这里,导致第一个 Token 积累了巨大的、无实际意义的权重。学术界称之为**“注意力黑洞”(Attention Sink)**。
这不仅仅是个美学问题,它导致了模型内部出现 “巨量激活”(Massive Activation) ——某些神经元的数值异常巨大,极易引发训练不稳(Loss Spike),并限制了模型处理超长文本的能力。
Qwen 团队在 NeurIPS 2025 的这项研究,尝试用最简单的方式治好这个“强迫症”。
02
在提出解法前,论文精准地切中了现有标准注意力机制(Standard Softmax Attention)的两大病灶:
问题一:双层线性变换的“虚假繁荣”
在 Multi-Head Attention 的末端,一般是先做一个
(Value)投影,计算完注意力后,再做一个
(Output)投影。 从数学上看,两个连续的线性层(Linear Layer)如果没有非线性激活函数隔开,它们本质上等价于一个低秩的线性变换。
通俗理解:你装了两道门,但两道门中间没有墙,也没有锁,它们实际上就是一条更长的走廊。模型在这里浪费了参数,却没能增加表达能力的“深度”。
问题二:输入无关的“强制关注”
如前所述,Softmax 的归一化特性(总和为 1)剥夺了模型“不想看”的权利。它缺乏一种机制来根据输入内容的含金量,动态地调节输出信号的强弱。模型被迫时刻保持“高增益”状态,噪声一旦进入,就会被放大。
03. Gated Attention (GA)
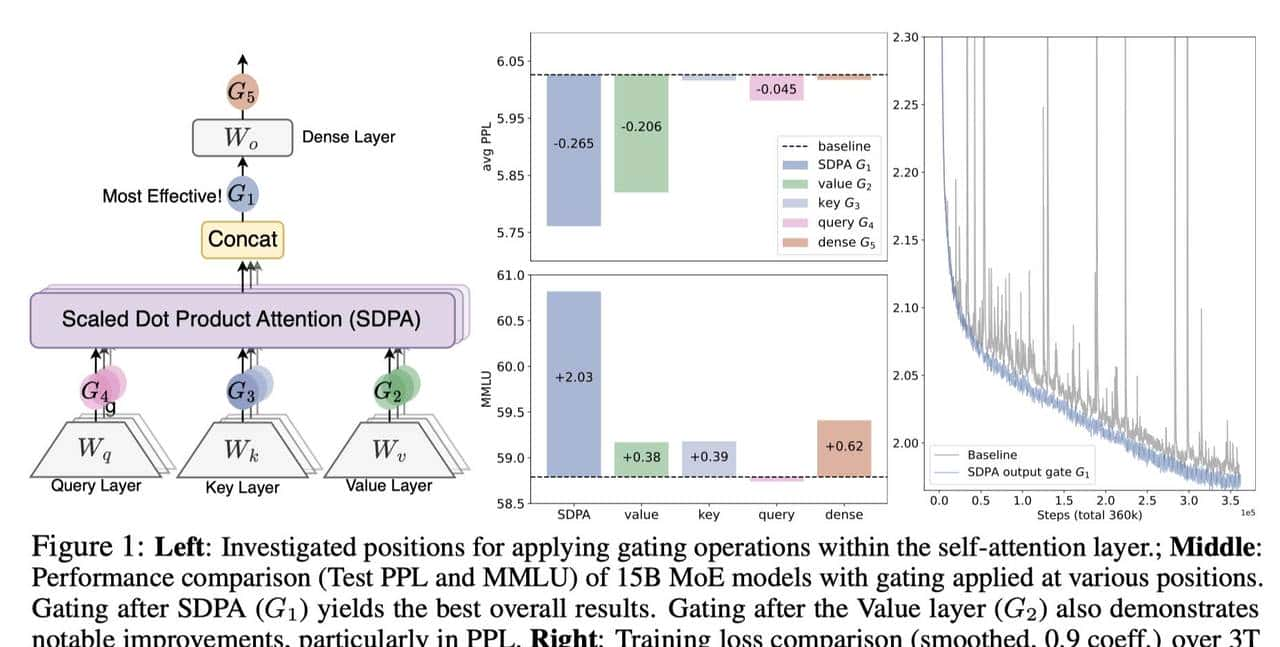
Qwen 团队的解决方案极其符合“奥卡姆剃刀”原则——加一个门(Gate)。
他们在注意力机制的输出端,引入了一个由 Sigmoid 函数控制的门控单元。这个改动虽然微小,却同时解决了上述两个病灶。
核心公式
原有的注意力输出
被修正为
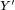
:
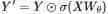
其中:
- 是标准的 Scaled Dot-Product Attention (SDPA) 的输出。
- 是当前的隐状态输入。
- 是 Sigmoid 激活函数(输出范围 0 到 1)。
- 代表逐元素相乘(Element-wise multiplication)。
关键细节 (The Secret Sauce)
为了达到最佳效果,论文通过大量消融实验确定了以下“黄金配置”:
- 位置最重大:门控必须加在 SDPA 输出之后(即注意力计算完,但在最终 Output 投影之前)。这是本文被称为 “SDPA Output Gating” 的缘由。
- 细粒度控制:采用 Head-Specific(特定头)的门控。每个注意力头(Attention Head)都有自己独立的门,而不是所有头共享一个门。
- 输入依赖性:门控的开闭完全取决于当前的输入 (Query-dependent)。这意味着模型可以根据“这句话重不重大”来决定“要不要让注意力流过”。
04. 实验与证据
Qwen 团队在 15B 参数的 MoE 模型和 1.7B 的 Dense 模型上,使用 3.5万亿(3.5T)Token 进行了验证。结果极具冲击力:
1. 彻底消灭“注意力黑洞” (The Sink Killer)
这是最令人兴奋的发现。在不加任何额外正则化手段的情况下,仅凭这个门控:
- Baseline:在标准模型中,平均 46.7% 的注意力分数被莫名其妙地分配给了第一个 Token(黑洞)。
- Gated Attention:引入门控后,这一比例暴跌至 4.8%。
这意味着模型终于学会了“无视”无关信息,而不是被迫盯着第一个词发呆。同时,模型内部的“巨量激活”现象也随之消失,数值分布变得更加健康。
2. 训练稳定性显著提升
在训练大模型时,Loss Spike(损失函数突然激增)是工程师的噩梦。
- 实验显示,使用了 Gated Attention 的模型,几乎完全消除了 Loss Spikes。
- 这带来了一个巨大的红利:工程师可以使用更大的学习率(Learning Rate) 和更大的 Batch Size 进行训练,直接提升了训练效率和模型收敛速度。
3. 长文本能力的自然涌现
得益于消除了“注意力黑洞”和噪声干扰,模型在长文本任务上表现更佳。
- 在 RULER Benchmark(长文本评测)中,将上下文扩展到 32k 甚至 128k 时,Gated Attention 模型的性能相比 Baseline 提升了 超过 10 个百分点。
- 它证明了:当模型不再依赖“黑洞”作为缓存区时,它的外推能力(Extrapolation)会显著增强。
05. 结论与展望
这篇论文的价值不在于提出了多么复杂的架构,而在于它揭示了 Transformer 现有设计中一个被忽视的缺陷:缺乏“拒绝”的能力。
通过引入非线性的 Sigmoid 门控,Qwen 团队实际上赋予了模型两个关键特性:
- 非线性增强:打破了 Value 投影和 Output 投影之间的低秩瓶颈。
- 动态稀疏性:让模型能够根据输入,动态地将无关信息的输出“关”到接近 0(Sigmoid 可以输出 0,而 Softmax 永远大于 0)。
这项技术已经被确认应用在 Qwen3-Next 模型中。它不仅让模型训练更省心(不怕 Loss Spike),更为未来的模型微调(Fine-tuning)和量化(Quantization)铺平了道路——由于没有了异常巨大的激活值,低精度量化将变得更加容易且损失更小。
















暂无评论内容