
你是否也遇到过这样的难题:
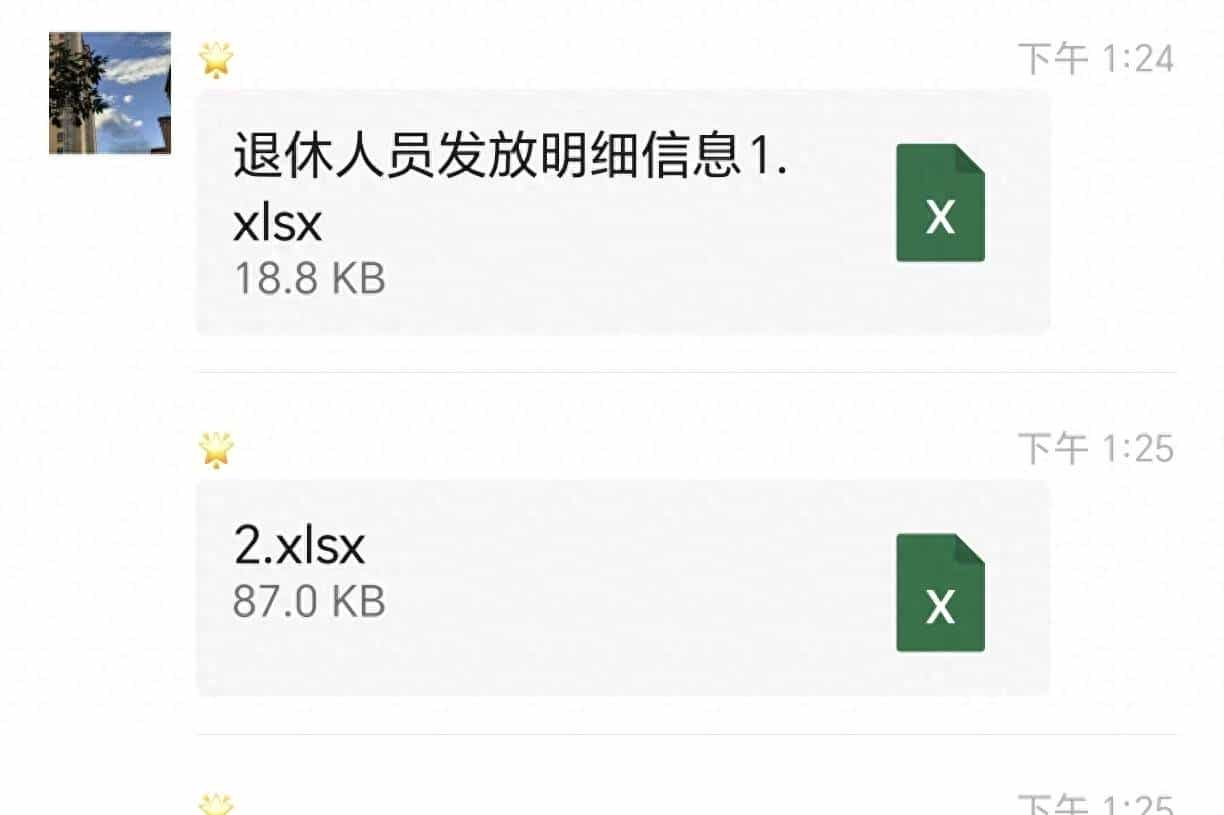
一份工作表为“退休人员发放明细信息1.xlsx”,工作表“Sheet1”(表一)中保存着退休人员的姓名、月份养老金明细等信息。样式如下:
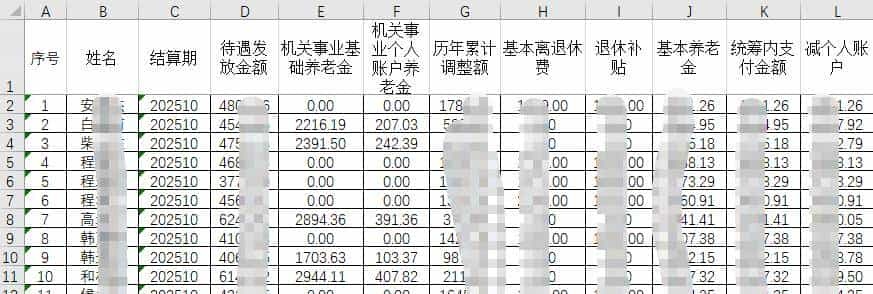
一份为“2.xlsx”的工作簿的“离退休人员信息”工作表(表二)中包含姓名、出生年月、性别、学历、证件类型、证件号码等个人基本信息。样式如下:
目前需要让表一的姓名列,完全按照表二的姓名列重新排序。
如果手动来完成,一般是先把退休人员发先在表一中找到表二中的第一个姓名,剪切粘贴到第一行,再找第二个、剪切粘贴到第二行……或者你对函数比较熟悉,先在表二中添加辅助列,然后按照数字从小到大顺序填充序列,再到表一中通过vlookup函数匹配表一中姓名在表二的序列号,再通过排序来完成。如果人少手动操作还可以应付,如果人数较多,且存在匹配不上的情况,很可能要多次核对。
实则用Python处理此类问题,只需要十几行代码就能轻松搞定,而且还能应对各种特殊情况 。今天就分享一下解决这个的问题方法。先上代码:
import pandas as pd
path1 = r"E:退休人员发放明细信息1.xlsx"
path2 = r"E:2.xlsx"
df1 = pd.read_excel(path1,sheet_name="Sheet1",header=0,skipfooter=1,index_col=0)
df2 = pd.read_excel(path2,sheet_name="离退休人员信息",header=1)
list = df2["姓名"].tolist()
list_other = [f for f in df1["姓名"].unique() if f not in list]
list = list+list_other
df1["姓名"] = pd.Categorical(df1["姓名"],categories=list,ordered=True)
df_sort= df1.sort_values("姓名")
df_sort.to_excel(r"E:退休人员发放明细信息_排序后11.xlsx",index=False)再来看代码解析
第1行:导入所需要的模块。pandas是专门用来处理数据的模块。它提供了大量的数据处理方法,能够协助我们快速、灵活地处理数据。
第3-4行:设置文件的路径。路径前的r可以有效防止括号内路径被转义。
第6-7行:读取数据。pandas支持导入多种外部数据。read_excel方法能够把excel数据导入到pandas中。sheet_name参数用于指定excel中哪个表格,默认为第一个表格。header参数用于指定表格的第几行为标题行,索引从0开始,默认为第一行为标题行。如果无标题行则设置为None。skipfooter参数用设置从文件末尾跳过的行数,如总计行。index_col参数用于指定第几列为索引列。
第8行:用tolist()方法把df2的姓名为转为列表。
第9-10行:找出df1里有,但df2里没有的姓名,放到list_other列表里。这样做目的是能够避免因表1中有表2中没有的姓名被漏掉。最后统一放到排序结果的末尾。
第12行:使用pd.Categorical把“姓名”列定义为分类类型,指定顺序为list列表。普通的排序是按字母或拼音顺序,pd.Categorical能让数据按照我们自定义的顺序来排列。
第13行:使用sor_values()方法按照姓名列进行排序。sor_values()的第二参数为ascenging用于是否按升序排序,默认为True。
第14行:保存结果。index=False表明不保存原索引到工作表。
结果对列如下:
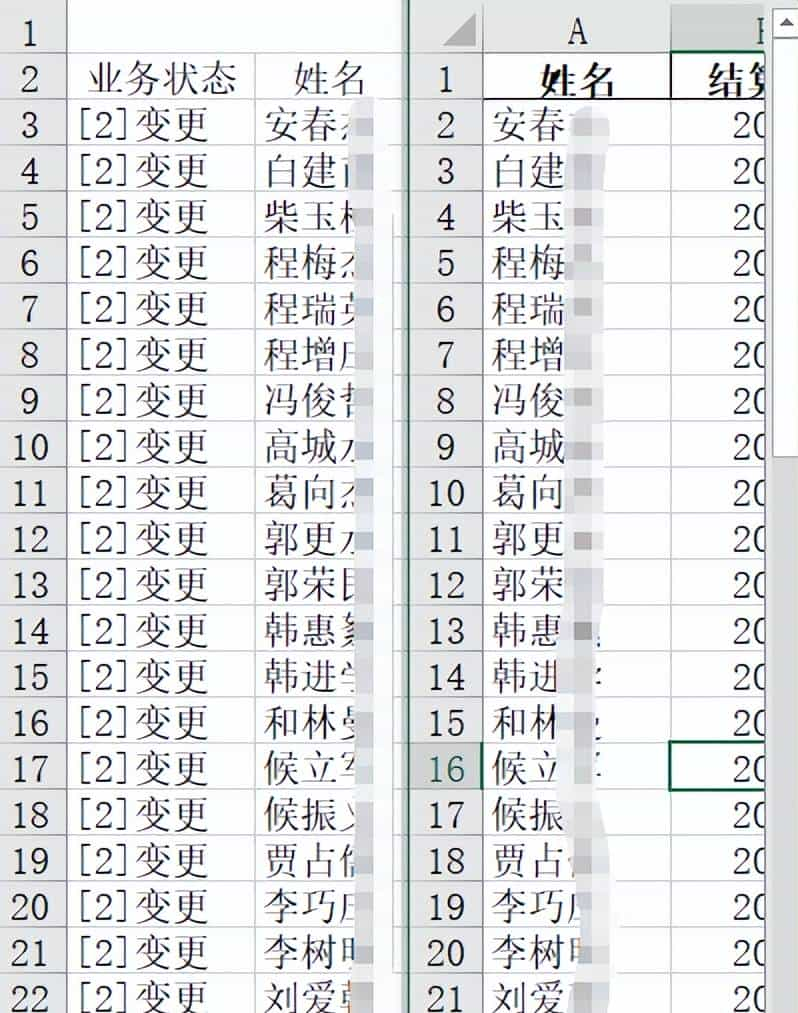
这是使用pd.Categorical函数的解决过程,它的核心思路是先定义好顺序,然后再按顺序排序。表2中没有姓名放到最后。代码可直接复制稍作修改即可使用。
实则还有一种方法,就是给每个姓名标上序号,再按序号排序,理解起来就好比添加了一个辅助列,再用vlookup查找这个序号再排序一样。这种方法更适合刚接触python的朋友
import pandas as pd
path1 = r"E:退休人员发放明细信息1.xlsx"
path2 = r"E:2.xlsx"
df1 = pd.read_excel(path1,header=0,skipfooter=1,index_col=0)
df2 = pd.read_excel(path2,header=1)
list = df2["姓名"].tolist()
orders = {name:i for i,name in enumerate(list)}
df1["排序"] = df1["姓名"].map(lambda x:orders.get(x,9999))
df_sort= df1.sort_values("排序").drop(columns=["排序"])
df_sort.to_excel(r"E:退休人员发放明细信息_排序后1.xlsx")第9行:使用推导式生成一个字典。字典的键为name,值为i的序列号。
第11行:给df1新增“排序”列,根据姓名查字典,没有的姓名号设为9999。orders.get(x, 9999)表明如果字典里没有这个姓名,就给它一个很大的序号9999,这样多余的姓名就会自动排在最后。
第12行:按排序列进行排序,再使用drop()方法删除排序列,这样可以保持与原表结构保持一致。
实则这两种方法效率都是很高的。你可以根据实际稍作修改就可以解决这个复杂的问题,无论是200行还是2000行、20000行,都不在话下。
如果这篇文件协助到了你,别忘了点赞+转发,让更多需要的人看到~~~





















- 最新
- 最热
只看作者