
2016 年,随着 AlphaGo 在围棋比赛中击败李世石,“人工智能”、“神经网络”、“深度
学习”等字眼便越来越多的出现在大众眼前,智能化好像成为一种不可逆转的趋势,带给大家新奇感的同时也带来了一丝忧惧:在不远的未来,机器是否真的拥有思维和情感?《终结者》中天网大战人类的刻画是否会成为现实?我的工作会不会被程序代替?要不要现在就注册下美团骑手?美团也开始无人送餐了?众多打着人工智能和算法旗号的公司不断出现和上市,众多学校开始开设人工智能学院(比如我的母校,西南交通大学),而特斯拉等新能源企业的出现,将人工智能和无人驾驶联系起来,仿佛人类很快就可以进入那个梦幻的未来世界。迄今为止,我们所见识到大部分人工智能所实现的魔法都依赖于精心设计的神经网络,到底什么是神经网络,神经网络又是如何实现的,在这里我们对此进行简单的介绍。
1、神经网络简介
什么是神经网络(Neural Network)?神经网络又称人工神经网络(Artificial Neural Network,ANN)是机器学习(Machine Learning)中众多自适应优化算法的一种,其具有悠久的发展历史,最早可以追溯到上世纪40年代。神经网络通过搭建大量人工神经元并广泛连接形成网络,模拟生物神经系统对真实世界所作出的反应,以此为现实问题提出解决方案。那么什么是机器学习呢?机器学习是一大类自适应算法的统称,指从已知的数据中获取规律,并利用规律对未知数据进行预测的方法,包括但不限于贝叶斯估计、决策树、随机森林、支持向量机和深度学习等等,图1展示了机器学习、深度学习与神经网络三者的关系。
![图片[1] - 神经网络与计算机视觉 - 宋马](https://pic.songma.com/blogimg/20250429/3af3d85be2694e78bb699b5341874115.png)
神经网络由基础的神经元连接组成,其数学模型如下式所示:
output=f( Wx+b) (1)
式中,X为神经元的输入量,由x1…xn组成;W为输入量的权重(weight,也就是参数)向量矩阵,由w1…wn组成;b为神经元的偏置(bias,同样也是参数);f为激活函数,用来表示神经元的映射关系,一般为非线性函数,如tanh函数、sigmoid函数等,为算式提供了非线性能力。图2展现了神经元的计算过程。
![图片[2] - 神经网络与计算机视觉 - 宋马](https://pic.songma.com/blogimg/20250429/3a9391414dee4254978c1f4cbab2de75.png)
通过将大量神经元按一定顺序排列组合组成层级结构,组成输入层、隐藏层和输出层的结构,各层之间通过权重进行连接,即组成了神经网络,如图3所示。
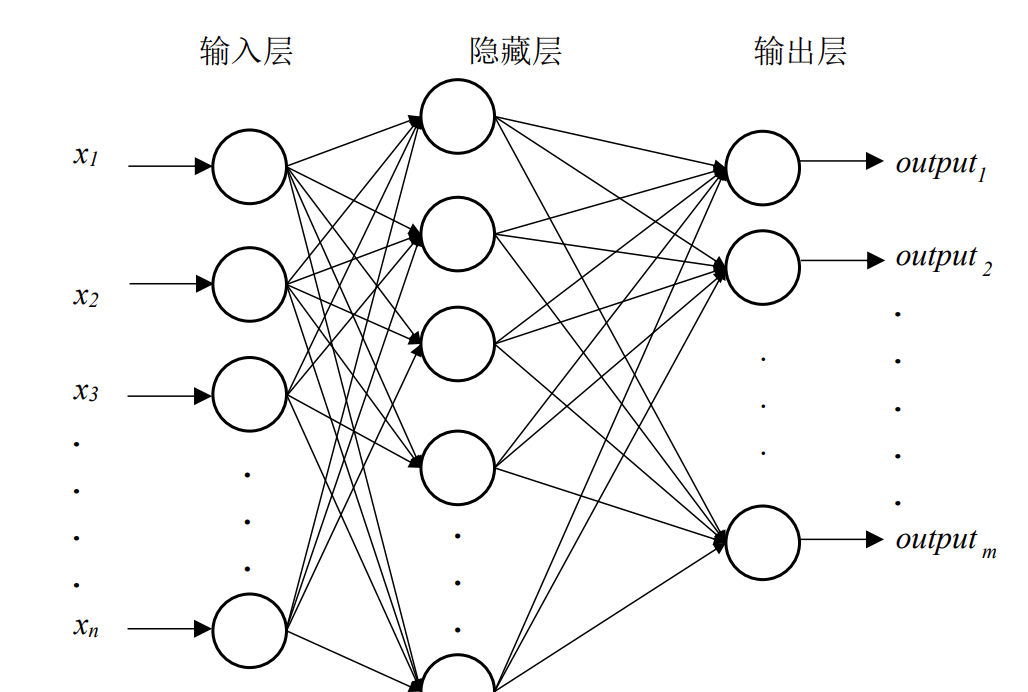
只有一层隐藏层的神经网络十分简单,通常只能用来解决较为简单和足够抽象的问题。随着计算机算力的不断增长,为解决更加复杂的现实问题,神经网络的隐藏层从单层神经元被扩展为多层,即组成了多层的神经网络。迄今为止,学界和工业界常使用的神经网络拥有多达几十至上百层的隐藏层,这也是深度学习“深度”的一词的来源。神经网络通常被认为可以拟合任何数学函数,造就了神经网络提取数据特征的潜力。
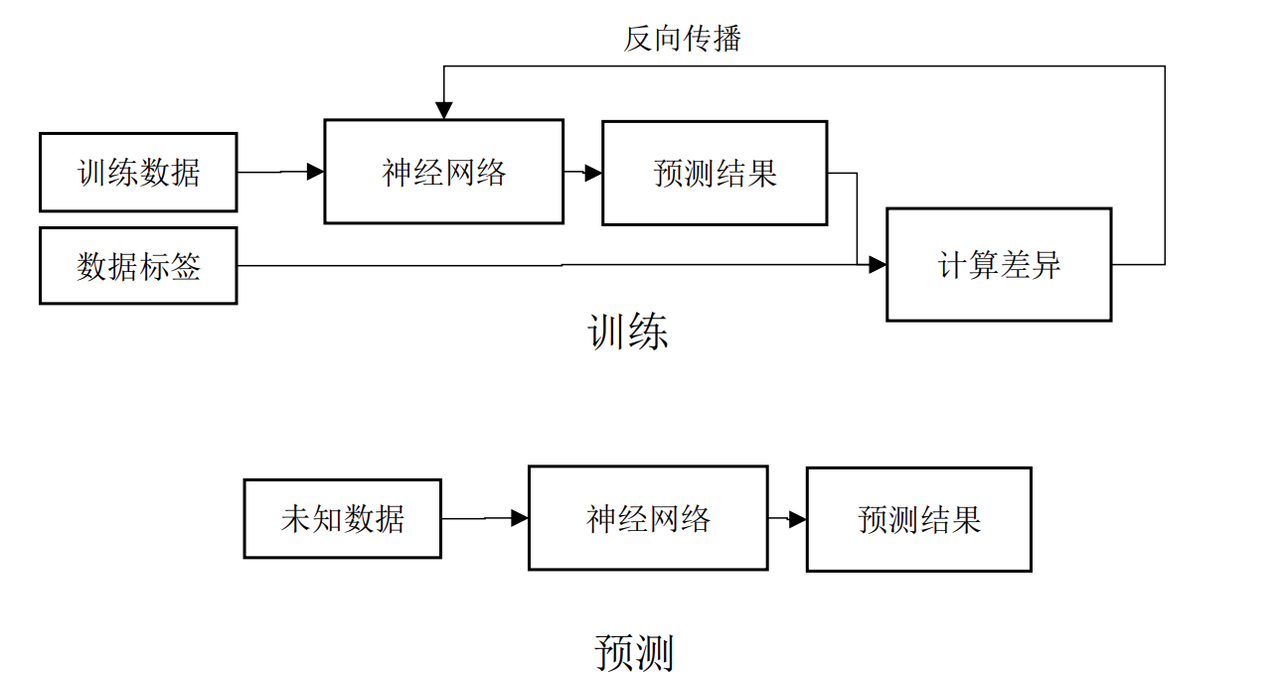
神经网络通常通过有监督学习(Supervised Learning)的方式来实现对自身的训练,如图4所示。具体而言,我们在利用神经网络实现预测前,需要自己准备一个数据集(Dataset)并对数据进行标注,然后将数据送入神经网络中并得到结果,然后将神经网络的结果同真实标签计算差异,我们将这个差异称为计算损失(Loss),随后将计算损失从输出层逐层向前传播,得到每个神经元的误差信号,再通过调整每层的连接权重和偏置以减小误差,这一过程被称之为反向传播(Back Propagation)。当误差减小到一定范围或不再下降之后,神经网络就已完成了训练,随后我们就可以利用神经网络来预测了。举个并不是非常恰当的例子:小明是一个初中生,小明的老师并不教他任何知识,只拿给他1000道选择题的练习册和对应的答案,让他对着答案自己练习,虽然一开始小明做的都是错的,但小明还是渐渐的都做对了,这时小明被老师派上场考试了,虽然考试的题和练习册的题并不一样可也都差不多类似,所以小明大部分题也都做对了,这就是有监督学习。除了有监督学习外,神经网络还有半监督学习(Semi-Supervised Learning)、无监督学习(Unsupervised Learning)、小样本学习(Few-shot Learning)等训练方法,大致可以分别对应于小明的练习册只有一部分有答案、练习册完全没有答案、练习册只有50道题的情况。当然,这些方法仍处于较快的更新迭代中,主流的还是通过有监督学习进行神经网络的训练。我们可以看到,和大多数机器学习相比,神经网络摒弃了人工构建特征的过程(大多数机器学习方法需要小明的老师去把知识点提取出来,例如支持向量机),让机器自己去提取特征并利用特征,在现实问题上还要强于大多数机器学习方法,这也是神经网络越来越广泛的取代机器学习方法的原因。同时,我们也应该意识到,神经网络根本上还是利用统计学原理,神经网络的训练数据应该与测试场景保持同一分布,就比如小明做的练习册和考试完全不相干,那么小明也会考的一塌糊涂。
2、卷积神经网络
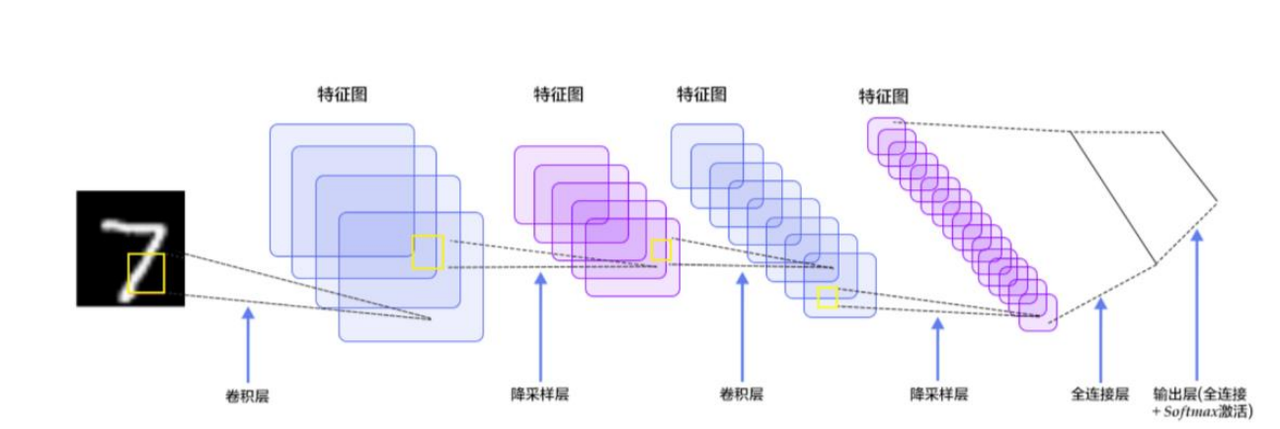
在计算机视觉中,卷积神经网络(Convolutional Neural Networks, CNN)一直占据着非常重要的位置。1988年,贝尔实验室的LeCun将相当于生物初级视皮层的卷积运算加入到多层神经网络中,提出了Lenet,如图5所示。Lenet在手写数字识别中得到了巨大的成功,可谓是将深度学习推向繁荣的一座里程碑。
2012年,Alex Krizhevsky等人提出的卷积神经网络AlexNet获得了ImageNet LSVRC比赛(一个非常大的1000类别的图像分类比赛)的冠军,超过第2名机器学习方法近10%的精度,引起了很大的轰动。AlexNet 可以说是具有历史意义的一个网络结构,在此之前,深度学习已经沉寂了很长时间,自2012年AlexNet诞生之后,后面的 ImageNet 冠军都是用卷积神经网络来做的,并且网络越来越深,逐渐超越了人类肉眼识别的结果,带来了深度学习的大爆发。
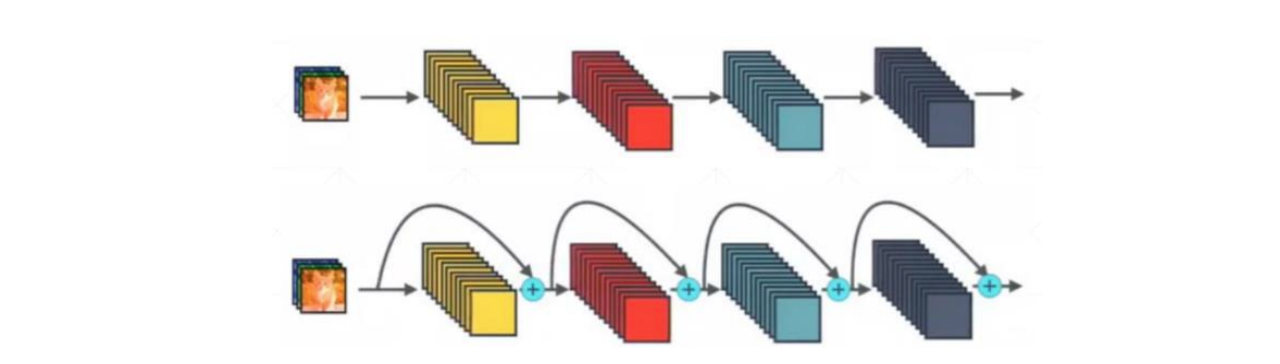
2015年,微软研究院的何恺明等人提出了卷积残差神经网络ResNet,ResNet获得了当年ImageNet LSVRC比赛的冠军。ResNet通过提出和使用批归一化(Batch Normalization)、残差结构等技术,极大的消除了深度过大的神经网络训练困难问题。神经网络的“深度”首次突破了100层、最大的神经网络甚至超过了1000层。至今,ResNet及其变体仍然作为大多数视觉任务的骨干网络。图像分类的问题基本上已被CNN攻破。
那么什么是卷积神经网络呢?卷积神经网络即是主要利用卷积层(Convolutional Layer)提取图像特征的一类神经网络的总称,具体的卷积运算我们可以看下图所示。具体而言,卷积运算在输入数据滑动一个卷积核。将各个位置上卷积核的权重和对应的输入数据相乘,然后再求和。然后,将这个结果保存到输出的对应位置。将这个过程在所有位置都进行一遍,就可以得到卷积运算的输出。
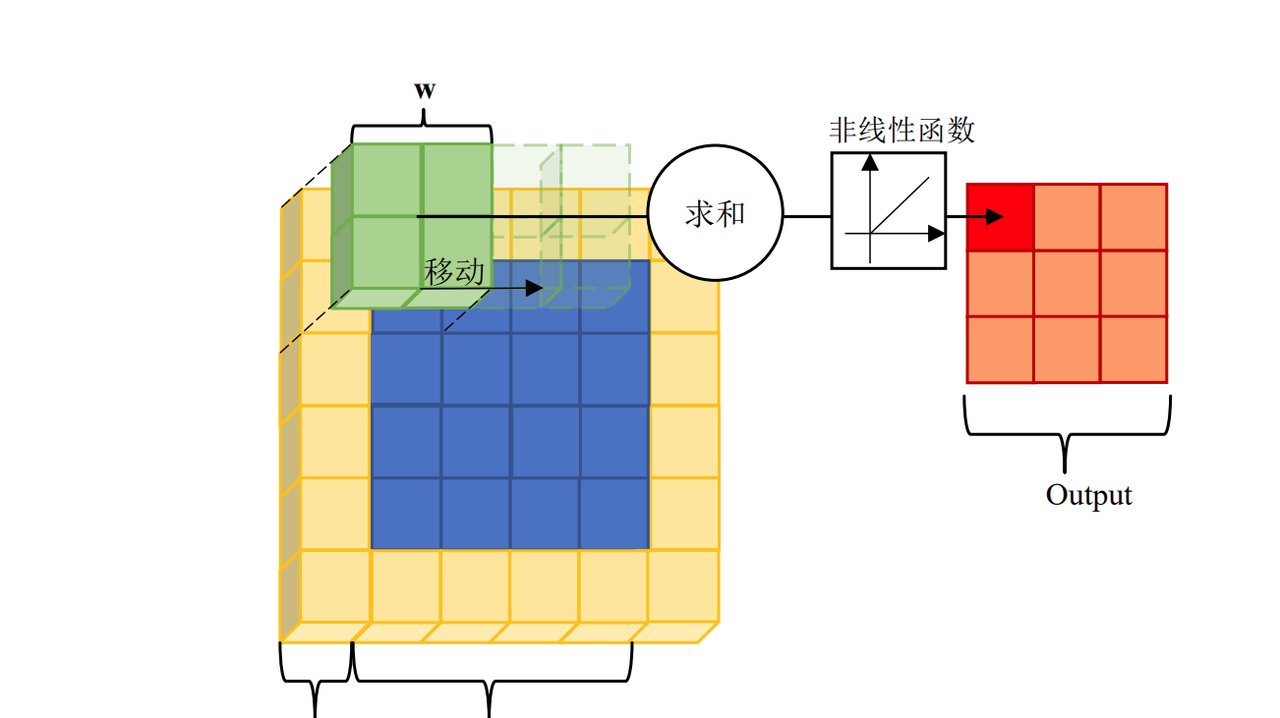
相较于图3所展示的普通的神经网络(也可以称之为全连接神经网络),卷积神经网络保留了输入图像的形状信息,并有着强烈的归纳偏置 (Inductive Bias),即认为相邻的像素区域一般有着相互关联的关系,这为CNN提供了较快的损失收敛速度。
当然,我们应该认识到CNN的成功不光取决于卷积层和网络结构——也就是算法层面上的创新,也同样伴随着半导体行业的发展所带来的计算机算力的大规模增长以及开源运动繁荣。至少在1988年,LeCun是根本无法训练alexnet的,那个时代的计算机内存仍未达到1MB的水平(难以想象,今天我们的手机的内存轻松突破了8GB),加载Alexnet的参数都可能造成死机。在这一过程中,英伟达公司(Nvidia)所生产的显卡以及设计的并行编程语言CUDA被广泛的应用于神经网络的训练和推理工作并被学界、业界所依赖,今天,英伟达公司几乎垄断了全世界所有数据中心的人工智能硬件和底层软件,拥有一张高性能显卡的可能不再是游戏玩家,也有可能是比特币矿工,更有可能是一个为了毕业而可怜工作的研究生。得益于开源运动,越来越多开源免费神经网络框架被开发出来用于简化神经网络的设计和训练,其中的佼佼者Tensorflow、Pytorch框架已经成了视觉算法工程师的标配。在今天,实现一个用于图像分类的神经网络已经和搭积木一样简单,不少从业者自嘲和被调侃为“调参侠”或“拼积木的”。
3、卷积神经网络与视觉任务
在图像分类任务之后,CNN被适用于越来越多的视觉任务:目标检测(Object Detection)、目标跟踪(Object Track)、语义分割(Semantic Segmentation)、关键点检测(Keypoint Detection)、实例分割(Instance Segmentation)、超分辨率重构(Super Resolution)、内容生成(AI Generated Content)等等,这些都是较为基础的视觉任务,智能驾驶、工业检测、安防等等工作都依赖于这些底层任务,在此我们分类进行简单的介绍:
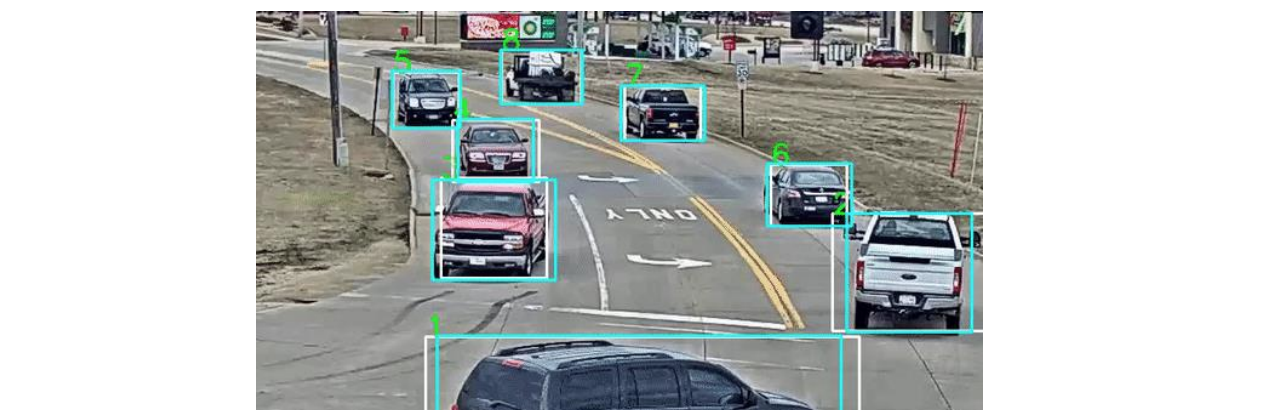
1、目标检测:相较于图像分类将整张图片分类为某一类别,目标检测关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而,检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示),如图8所示。目标检测算法被广泛的应用于智能驾驶、安防摄像头、工业上的裂纹污损检测等工作,较为经典的目标检测有何恺明等人提出的Faster RCNN、Joseph Redmon等人提出的YOLO系列以及Nicolas Carion等人提出的利用Transformer架构(一种更新更强大的神经网络范式,有可能取代CNN)的DETR。

2、目标跟踪:目标跟踪强调在连续帧跟踪目标的位置,被广泛的应用于智能驾驶、安防等工作,较为经典的目标跟踪网络一般由一个目标检测网络加跟踪器组成,即先对图像上的目标进行识别,随后和前一帧的目标进行二分匹配,并利用卡尔曼滤波预测目标在下一帧的位置,较为经典的目标跟踪算法有Deep Sort。
3、语义分割:语义分割侧重于图像上每一个像素的分类,要求分离开具有不同语义的图像部分,将图像中的每一个像素关联到一个类别标签上的过程,如图10所示。语义分割算法被广泛的应用于智能驾驶、医疗图像识别等工作,较为经典的语义分割算法有Olaf Ronneberger等人提出的UNet、Liang-Chieh Chen等人提出的DeepLab系列。
![图片[3] - 神经网络与计算机视觉 - 宋马](https://pic.songma.com/blogimg/20250429/fa6a2ef6bef148f8afc1d459905db096.png)
4、关键点检测:关键点检测包括人脸关键点、人体关键点、特定类别物体(如手骨)关键点检测等。关键点检测被应用于人体姿态估计、动作识别、人机交互等工作,较为经典的关键点检测算法有康奈尔大学曹哲等人提出的OpenPose、上海交通大学卢策吾团队提出的AlphaPose。

5、实例分割:实例分割是目标检测和语义分割的结合,实例分割需要在图像中将目标检测出来,然后对目标的每个像素打上标签,如图12所示。实例分割被应用于智能驾驶、医学影像识别等工作,较为经典的实例分割算法有何恺明等人提出的Mask RCNN、阿德莱德大学沈春华团队的SOLO等。
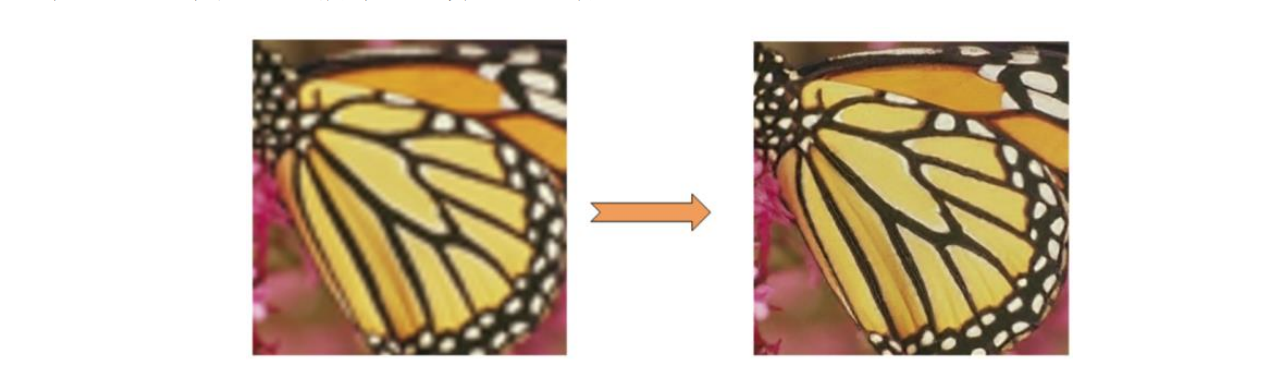
6、超分辨率重构:图像的超分辨率重建技术指的是将给定的低分辨率图像通过特定的算法恢复成相应的高分辨率图像,如图13所示。超分辨率重建算法被应用于游戏、视频播放等,较为经典的超分辨率重建算法有英伟达公司的DLSS。
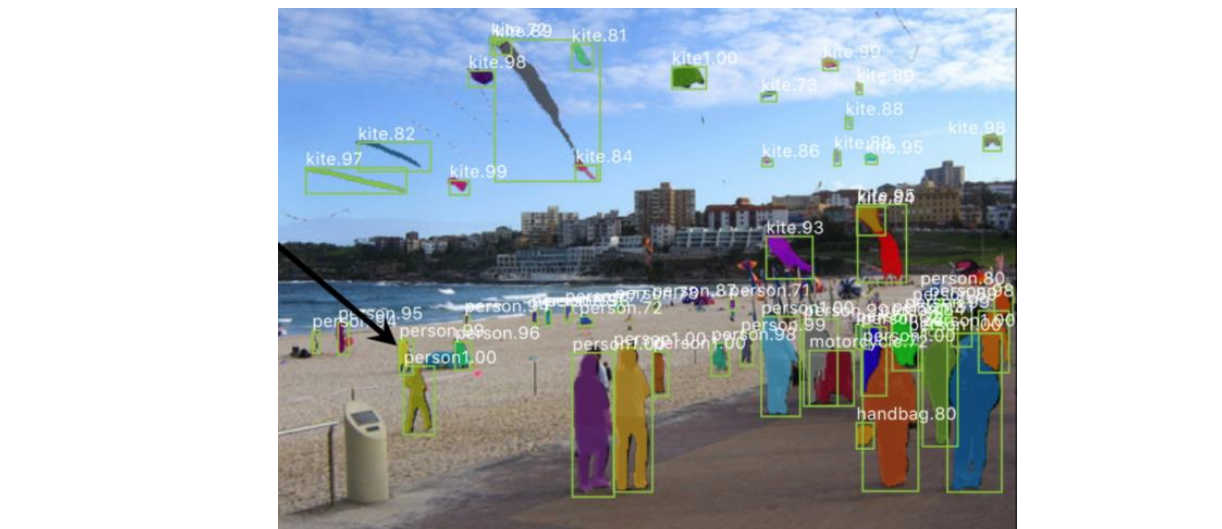
7、AI内容生成:AI内容生成指利用AI进行创意工作,在视觉上主要包括图像生成、风格迁移、视频生成等。2022年,文本与绘画交互的AI内容生成工作有了较为突破性的发展,stable diffusion、Dall-e、imagan等网络结构的诞生,让通常被认为最不可能被取代的艺术文化工作者也有了失业的隐忧。

4、神经网络的启示与隐忧
以上,我们简单介绍了神经网络和视觉任务,当然神经网络的原理和训练并不仅限于此,还包含线性代数、矩阵求解、信息论等等数学知识。近年来,神经网络、深度学习等技术不断介入我们的身边,不再局限于实验室和互联网大厂之中,相信随着编程的需求的增多,越来越多的行业依赖于软件处理,我相信我们很快就会进入一个全民编程的时代。神经网络的发展得益于开源社区的繁荣。我们通常都认为计算机或软件行业是一个非常内卷的行业,35岁失业的问题屡见不鲜。这一问题表面上来自于行业自身的开源精神,即越来越多的人和企业在Github中分享自己的作品和项目(我也在Github上开源了几个项目),而编程的难度也在被降低,导致了几乎任何人都是可以被取代的。在过去的很长时间里,程序员们的这种自我革新通常被限定于本行业内,而其他行业依然保持着“越老越吃香”的惯例。然而2022年,这一态势似乎起了变化,Stable diffusion、ChatGPT等AI内容生成任务的大发展似乎要将计算机行业的这一内卷之风刮到所有行业。不久之前,AI绘画遭到大批画师抵制,不少画师已将“禁止投放作品进入AI绘画系统”加入个人简介,显然AI内容生成已经威胁到了金字塔底部大部分画师的安全。最近的新闻中,一家生产新闻热点内容的美国公司BuzzFeed宣布和OpenAI合作,未来将使用ChatGPT帮助创作内容,而在不久之前BuzzFeed刚裁掉了10%的编辑。我想,在不久的将来,大部分行业的“越老越吃香”都会成为一句梦话,依靠积累经验的“手工作坊”们将会逐渐消失,成为我们眼中上世纪大下岗前国企员工的福利时代。然而,按马克思主义而言,计算机行业的开源协作是当今最接近共产主义的生产方式,作为核心生产资料的软件被开源和免费分发,在参与开源的过程中,“劳动不仅仅是谋生的手段”,更是一种发展自身的需要。实际上导致计算机行业失业危机并非开源协助,而是资本主义的残酷体制。我们应该意识到,资本主义的社会形态落后并威胁着这一生产方式。在这样一个动荡的时代,未来又会如何发展,生产方式和社会形态的对抗又会带给我们一个怎样的明天,这值得我们去思考。在这样的当下,保持终身学习,才是唯一的勇者之路。

















暂无评论内容