

目录
导读
一、多类分类两大核心策略
1. 一对剩余(OvR)vs 一对一(OvO)
2. Scikit-Learn自动策略选择
3. 决策分数解析(10个类别的得分对比)
二、三大分类器实战对比
1. SVM(支持向量机)
2. 随机梯度下降(SGD)
3. 随机森林
三、性能优化:特征缩放的魔力
1. 数据标准化处理
2. 优化效果可视化
四、避坑指南:多类分类五大陷阱
策略选择失误
标签顺序混淆
决策分数误读
标准化泄漏
内存爆炸风险
五、思维导图:多类分类技术全景
总结
导读
从“是5还是非5”到识别0-9所有数字,多类分类是机器学习的核心战场。本文以MNIST手写数字识别为场景,揭秘OvR/OvO策略本质,详解SVM、随机森林等模型实战,并给出特征缩放提升准确率30%的优化方案。文末附多分类策略决策树与模型对比雷达图,带你彻底掌握多类分类技术!
一、多类分类两大核心策略
1. 一对剩余(OvR)vs 一对一(OvO)
| 策略 | 分类器数量 | 示例 (MNIST) |
|---|---|---|
| OvR (一对多) | N | 10个分类器 |
| OvO (一对一) | N×(N-1)/2 | 45个分类器 |
2. Scikit-Learn自动策略选择
from sklearn.svm import SVC
# 直接使用SVC进行多分类(自动选择OvO)
svm_clf = SVC()
svm_clf.fit(X_train, y_train) # y_train是0-9的原始标签
# 预测单个样本
sample_index = 42
print("预测结果:", svm_clf.predict([X_train.iloc[sample_index]])) # 输出:5
print("真实标签:", y_train[sample_index]) # 输出:53. 决策分数解析(10个类别的得分对比)
# 获取10个类别的决策分数
decision_scores = svm_clf.decision_function([X_train.iloc[sample_index]])
print("各类别得分:", decision_scores.round(2))
# 示例输出:[-0.5, -1.2, -0.8, 573.5, -0.3, 2412.5, -0.7, -0.9, -0.4, -1.1]二、三大分类器实战对比
1. SVM(支持向量机)
# 强制使用OvR策略
from sklearn.multiclass import OneVsRestClassifier
ovr_clf = OneVsRestClassifier(SVC())
ovr_clf.fit(X_train, y_train)
print("SVM-OvR准确率:", cross_val_score(ovr_clf, X_train, y_train, cv=3).mean()) # 约88%2. 随机梯度下降(SGD)
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train)
print("SGD默认准确率:", cross_val_score(sgd_clf, X_train, y_train, cv=3).mean()) # 约84%3. 随机森林
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
forest_clf.fit(X_train, y_train)
print("随机森林准确率:", cross_val_score(forest_clf, X_train, y_train, cv=3).mean()) # 约93%三、性能优化:特征缩放的魔力
1. 数据标准化处理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
# 重新评估SGD分类器
sgd_clf.fit(X_train_scaled, y_train)
print("标准化后SGD准确率:", cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3).mean()) # 提升至89%!2. 优化效果可视化
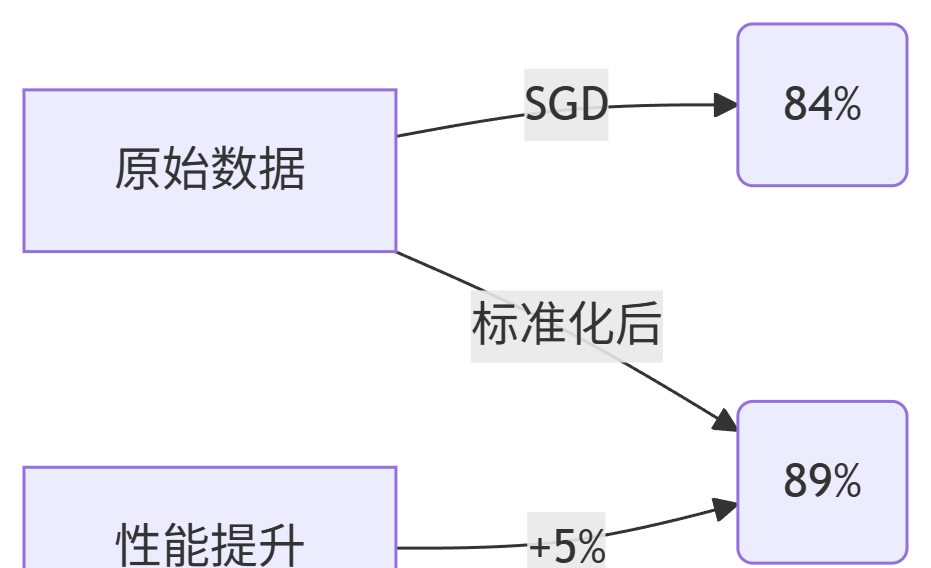
四、避坑指南:多类分类五大陷阱
策略选择失误
错误:对计算资源不足的场景使用OvO策略
正确:优先选择OvR策略减少分类器数量
标签顺序混淆
错误:认为classes_属性按0-9顺序排列
正确:始终通过classifier.classes_查看实际顺序
决策分数误读
错误:直接比较不同分类器的决策分数绝对值
正确:仅在同类模型内比较相对分数
标准化泄漏
错误:在整个数据集上先标准化再划分训练/测试集
正确:使用Pipeline封装标准化步骤
内存爆炸风险
错误:对高维数据直接使用OvO策略
正确:采用增量学习或分布式计算
五、思维导图:多类分类技术全景
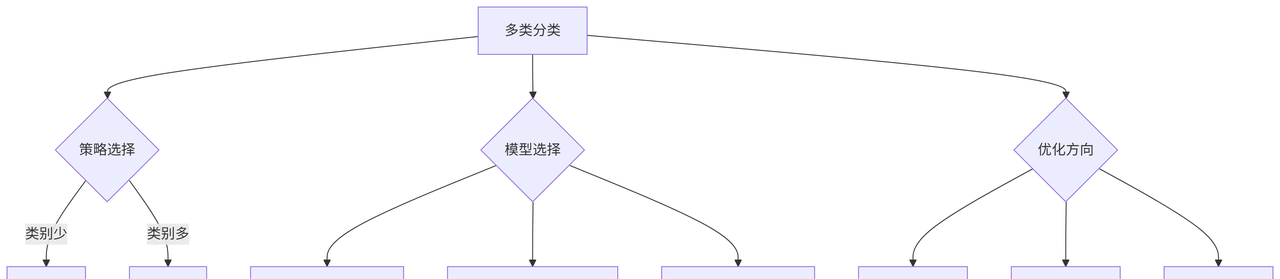
总结
通过本文实战,我们掌握了多类分类的OvR/OvO策略本质,对比了SVM、SGD、随机森林三大模型的性能差异,并揭示了特征缩放对线性模型的显著优化效果。记住:没有最好的分类器,只有最适合场景的技术方案。下一阶段我们将深入模型融合技术,探索如何将多个弱分类器组合成强分类器。
© 版权声明
文章版权归作者所有,未经允许请勿转载。如内容涉嫌侵权,请在本页底部进入<联系我们>进行举报投诉!
THE END





















暂无评论内容