
Hadoop的本质是同时解决大数据量存储和计算问题的分布式计算框架,其核心目标是通过分布式架构实现海量数据的高效存储与并行处理。
一、通过HDFS文件系统解决海量数据存储问题
分块存储【默认每个文件大小128MB】与容错性【复制多个副本存储在不同节点】
横向扩展能力【可线性扩展PB级别、适合处理非结构化和半结构化数据】
高吞吐量访问【计算节点优先处理本地存储的数据,减少网络传输开销】
二、并行处理框架(MapReduce和YARN)
MapReduce编程模型【支持并行计算、分类、聚合】
资源调度与管理YARN【统一管理集群资源、支持多任务共享集群】
与生态工具的结合【HiveSparkHBase、扩展计算场景、离线分析到实时处理全链路】
三、分布式集群
主从架构设计【HDFS采用NameNodeDataNode主从结构、YARN通过ResourceManagerNodeManager实现资源调度、高可用】
经济性与灵活性【普通硬件集群、降低硬件成本、支持动态扩展】
容错与自动恢复 【数据副本机制、任务重试策略、自动处理故障节点】
首先,需要安装部署hadoop
环境准备
|
节点IP |
主机名 |
资源 |
核心角色 |
辅助角色 |
|
192.168.8.210 |
hadoop-node1 |
cpu:8core mem:32GB disk:200GB |
NameNode (HDFS主节点) |
ResourceManager(YARN主节点) |
|
192.168.8.211 |
hadoop-node2 |
cpu:8core mem:32GB disk:200GB |
DataNode(数据存储) |
NodeManager(资源管理) |
|
192.168.8.212 |
hadoop-node3 |
cpu:8core mem:32GB disk:200GB |
DataNode(数据存储) |
NodeManager(资源管理) |
#关闭防火墙(三个节点执行)
systemctl stop firewalld
systemctl disable firewalld
#时间同步(主节点执行、其他节点同步)
yum install ntp -y
systemctl start ntpd
systemctl enable ntpd
#主机名与host映射(三个节点执行)
#修改主机名
hostnamectl set-hostname hadoop-node1 # 各节点按实际IP修改
vi /etc/hosts
192.168.8.210 hadoop-node1
192.168.8.211 hadoop-node2
192.168.8.212 hadoop-node3
终端重新登录生效
groupadd hadoop
useradd -m -g hadoop -d /home/hadoop hadoop
passwd hadoop
加入wheel组具备sudo权限
usermod -aG wheel hadoop
su – hadoop
#SSH免密登录(主节点生成,分发到其他节点)
ssh-keygen -t rsa -P “” -f ~/.ssh/id_rsa
ssh-copy-id hadoop-node1
ssh-copy-id hadoop-node2
ssh-copy-id hadoop-node3

安装JDK (三个节点)
yum install java-1.8.0-openjdk-devel -y
Hadoop组件安装
下载并解压hadoop
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
或者
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
mkdir /soft (每个节点执行)
将介质上传到主节点/soft ,在主节点执行如下命令:
scp /soft/hadoop-3.3.6.tar.gz 192.168.8.211:/soft
scp /soft/hadoop-3.3.6.tar.gz 192.168.8.212:/soft
mkdir /apps
tar -zxvf /soft/hadoop-3.3.6.tar.gz -C /apps
chown -R hadoop:hadoop /apps/hadoop-3.3.6
环境变量设置
在三个节点执行,
su – hadoop
vi ~/.bashrc
export HADOOP_HOME=/apps/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
核心配置文件修改(所有节点执行)
core-site.xml
vi /apps/hadoop-3.3.6/etc/hadoop/core-site.xml
添加如下信息
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoo/tmp</value>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hadoop.security.authentication</name>
<value>simple</value>
</property>
<property>
<name>ipc.client.connect.timeout</name>
<value>10000</value>
</property>
<property>
<name>ipc.client.socket.timeout</name>
<value>60000</value>
</property>
<property>
<name>hadoop.rpc.protection</name>
<value>authentication</value>
</property>
</configuration>fs.defaultFS 指定hdfs的默认访问地址
hadoop.tmp.dir 指定Hadoop存储临时文件的目录
hadoop.security.authorization 是否启用Hadoop的权限检查
hadoop.security.authentication 指定Hadoop的身份验证方式(simplekerberos)
ipc.client.connect.timeout 客户端尝试连接服务端的Socket超时时间,单位毫秒
ipc.client.socket.timeout 客户端与服务端之间Socket连接超时时间,单位毫秒
hadoop.rpc.protection 集群中节点间RPC通信的保护级别(authenticationintegrityprivacy)
hdfs-site.xml
注:如果hadoop-node1只做namenode,不要配置dfs.datanode.data.dir参数
vi /apps/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
添加如下信息:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop-node1:50070</value>
</property>
<property>
<name>dfs.namenode.https-address</name>
<value>hadoop-node1:50470</value>
</property>
</configuration>mapred-site.xml
vi /apps/hadoop-3.3.6/etc/hadoop/mapred-site.xml
添加如下信息:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
vi /apps/hadoop-3.3.6/etc/hadoop/yarn-site.xml
添加如下信息:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> <!-- 启用MapReduce -->
</property>
</configuration>
hadoop-env.sh
vi /apps/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
添加如下行:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
export HADOOP_DATANODE_SETPRIORITY=false
在三个节点执行
su – hadoop
echo $HADOOP_HOME
/apps/hadoop-3.3.6
echo “hadoop-node2” >> $HADOOP_HOME/etc/hadoop/workers
echo “hadoop-node3” >> $HADOOP_HOME/etc/hadoop/workers
cat workers
仅仅看到如下信息:
hadoop-node2
hadoop-node3
scp -r /apps/hadoop-3.3.6/etc/hadoop/* hadoop-node2://apps/hadoop-3.3.6/etc/hadoop/
scp -r /apps/hadoop-3.3.6/etc/hadoop/* hadoop-node3://apps/hadoop-3.3.6/etc/hadoop/
服务启动与验证
三个节点执行
mkdir -p /apps/hadoop-3.3.6/logs
chown -R hadoop:hadoop /apps/hadoop-3.3.6/logs
mkdir -p /data/hadoop/tmp
mkdir -p /data/hdfs/namenode
mkdir -p /data/hdfs/datanode
chown -R hadoop:hadoop /data/hadoop/tmp
chown -R hadoop:hadoop /data/hdfs/namenode
chown -R hadoop:hadoop /data/hdfs/datanode
格式化HDFS(在主节点执行,仅执行一次)
su – hadoop
hdfs namenode -format
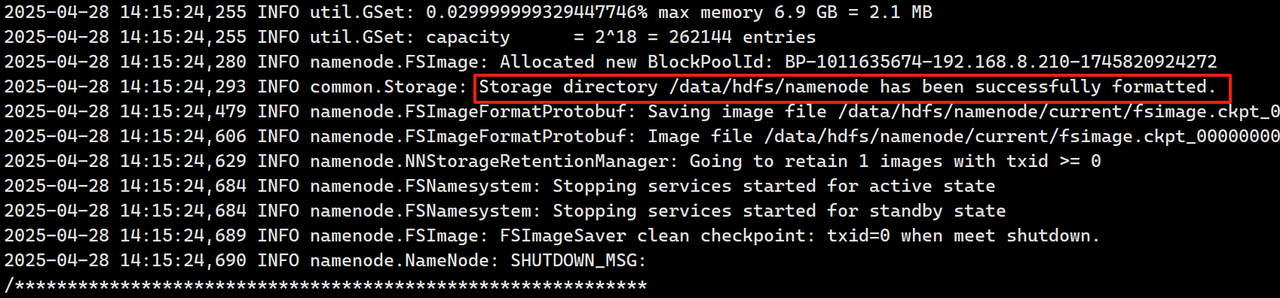
在主节点执行
[hadoop@hadoop-node1 ~]$ start-dfs.sh
Starting namenodes on [hadoop-node1]
Starting datanodes
Starting secondary namenodes [hadoop-node1]
[hadoop@hadoop-node1 ~]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[hadoop@hadoop-node1 ~]$ jps
[hadoop@hadoop-node1 ~]$ jps
4804 ResourceManager
7252 NameNode
4936 NodeManager
7386 DataNode
7627 SecondaryNameNode
7771 Jps
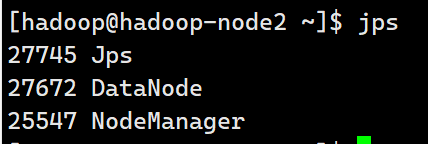
数据节点执行
[hadoop@hadoop-node2 ~]$ jps
26098 DataNode
26181 Jps
25547 NodeManager
[hadoop@hadoop-node3 ~]$ jps
25969 Jps
25894 DataNode
25367 NodeManager
如果namenode节点不显示DataNode进程和NodeManager进程,namenode节点需要修改如下配置文件
vi /apps/hadoop-3.3.6/etc/hadoop/hdfs-site.xml 去掉dfs.datanode.data.dir参数
然后重启dfs, stop-dfs.sh && stop-yarn.sh
jps 查看进程停止情况,如果还存在进程,可以使用kill -9 pid杀掉
start-dfs.sh && start-yarn.sh
再通过jps查看进程显示正常
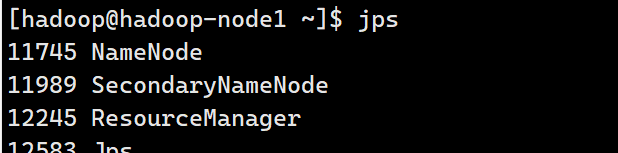
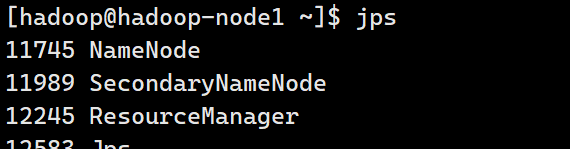
Hadoop命令行工具
#查看进程状态
jps #包括:NameNode/SecondaryNameNode/DataNode/ResourceManager/NodeManager
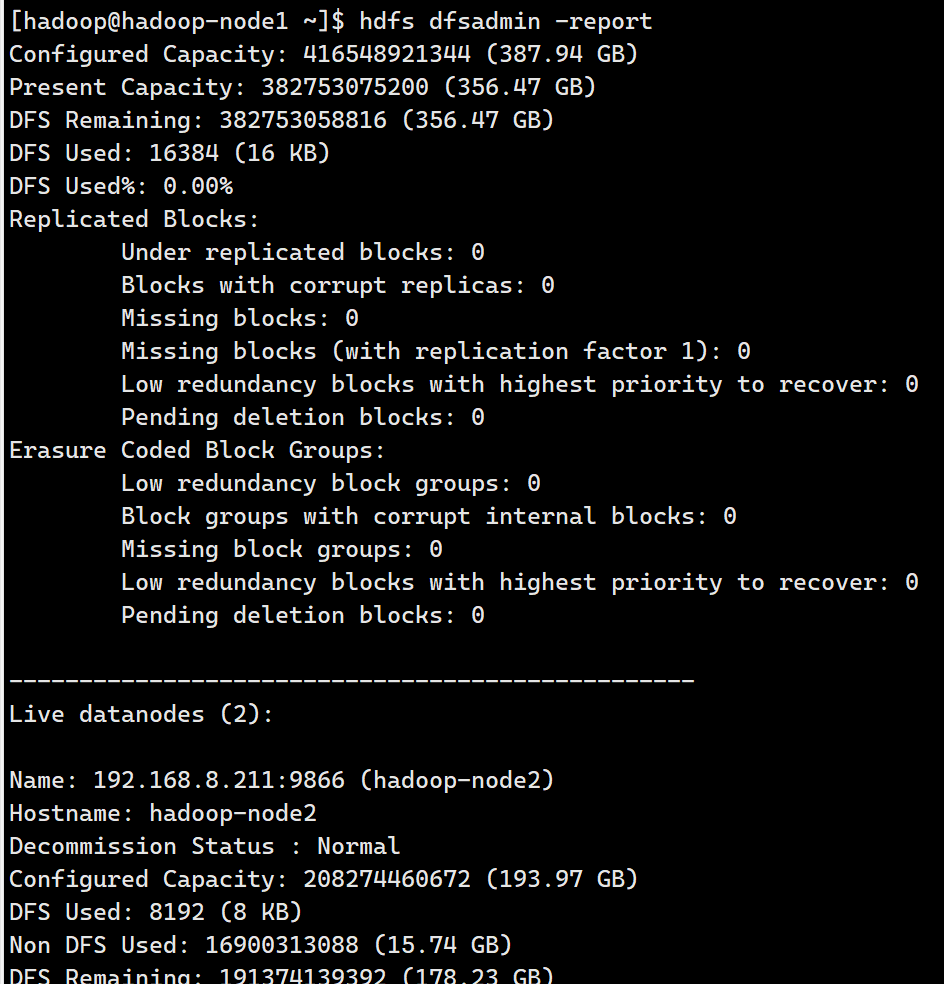
HDFS集群报告
hdfs dfsadmin -report #查看集群整体状态,节点健康情况、磁盘使用等
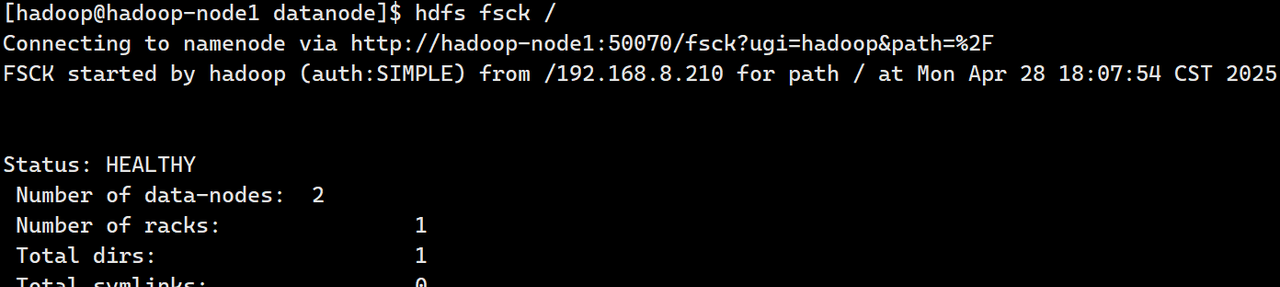
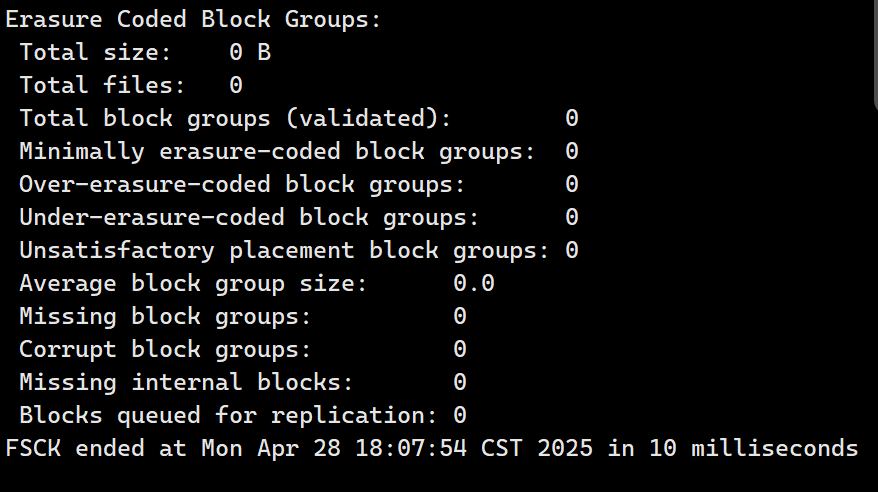
hdfs fsck / #检查HDFS文件系统损坏情况
yarn node -list #查看所有NodeManager节点状态

yarn application -list #查看运行的应用

日志监控
主要看$HADOOP_HOME/logs下面的*namenode*.log*datanode*.log*resourcemanager*.log*nodemanager*.log
第三方监控工具【后续发布…】
1. Ganglia(分布式监控系统)
用于监控集群节点的硬件指标(CPU、内存、磁盘 I/O、网络等)和 Hadoop 组件指标。
2. Zabbix(企业级监控平台)
支持监控 Hadoop 集群的各项指标,并提供报警功能。
3. Prometheus + Grafana(云原生监控)
适合容器化或分布式集群的监控,支持灵活的指标查询和可视化。






















暂无评论内容