
n8n 使用 Merge 节点进行数据聚合
Merge节点:n8n中最实用的节点之一
一、保留A中与B匹配的数据项(类似SQL内连接)
场景说明:筛选库存中存在的食材
SQL对应操作
实操
二、用B的数据丰富A的数据(类似SQL左连接)
场景说明:为食谱食材补充库存数量
SQL对应操作
实操
三、将B的数据追加到A的下方(类似SQL全连接)
场景说明:合并两个乐队的歌曲列表
SQL对应操作
实操
操作指南
实际应用价值

Merge节点:n8n中最实用的节点之一
n8n是一个开源的工作流自动化工具,允许用户通过节点化的方式构建数据处理流程。在n8n的节点体系中,Merge节点堪称数据处理的核心工具之一,它能够将来自不同数据源的数据进行高效整合,类似于SQL中的表连接操作。本文将通过三个典型场景,展示Merge节点的三种常用操作方式。
一、保留A中与B匹配的数据项(类似SQL内连接)
场景说明:筛选库存中存在的食材
通过此操作,可以仅保留A数据源中与B数据源存在匹配项的数据。例如:
A数据源:食谱中的所需食材列表
B数据源:库存中的现有食材列表
结果:仅显示当前库存中包含的食材
SQL对应操作
这与SQL中的**内连接(Inner Join)**类似,仅输出两个数据源的交集部分。
实操
创建一个 Code 节点,
JavaScript:
return [
{
"Name": "Flour",
},
{
"Name": "Eggs",
},
{
"Name": "Milk",
},
{
"Name": "Lemon",
},
{
"Name": "Sugar",
},
];
![图片[1] - n8n 使用 Merge 节点进行数据聚合 - 宋马](https://pic.songma.com/blogimg/20250515/f24c920bc5434deeb2177e98e04e1a27.png)
再创建另外一个 Code 节点,
JavaScript:
return [
{
"Name": "Eggs",
},
{
"Name": "Lemon",
},
{
"Name": "Sugar",
},
];
![图片[2] - n8n 使用 Merge 节点进行数据聚合 - 宋马](https://pic.songma.com/blogimg/20250515/8277bf20d71c4a0b8e830e30d2b783c8.png)
创建一个 Merge 节点,

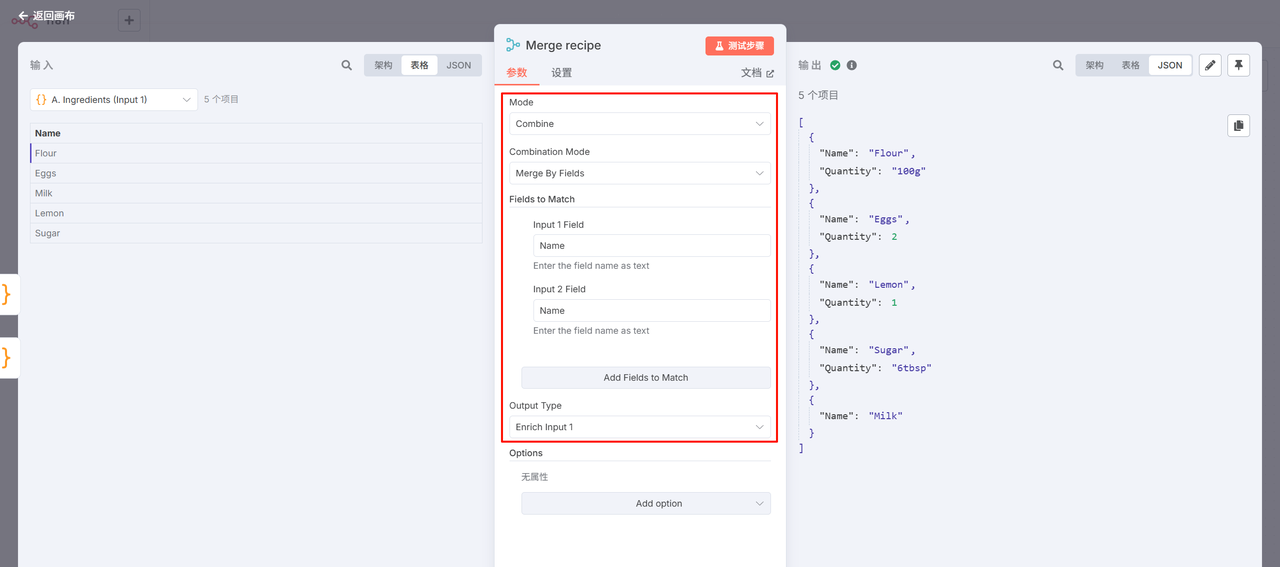
二、用B的数据丰富A的数据(类似SQL左连接)
场景说明:为食谱食材补充库存数量
此操作会将B数据源中匹配的数据合并到A数据源的每一项中。例如:
A数据源:食谱中的食材清单
B数据源:库存中的食材数量
结果:每个食谱食材项都会附带其在库存中的可用数量
SQL对应操作
这与SQL中的**左连接(Left Join)**类似,保留A中所有数据,并将B中匹配的字段补充到结果中。
实操
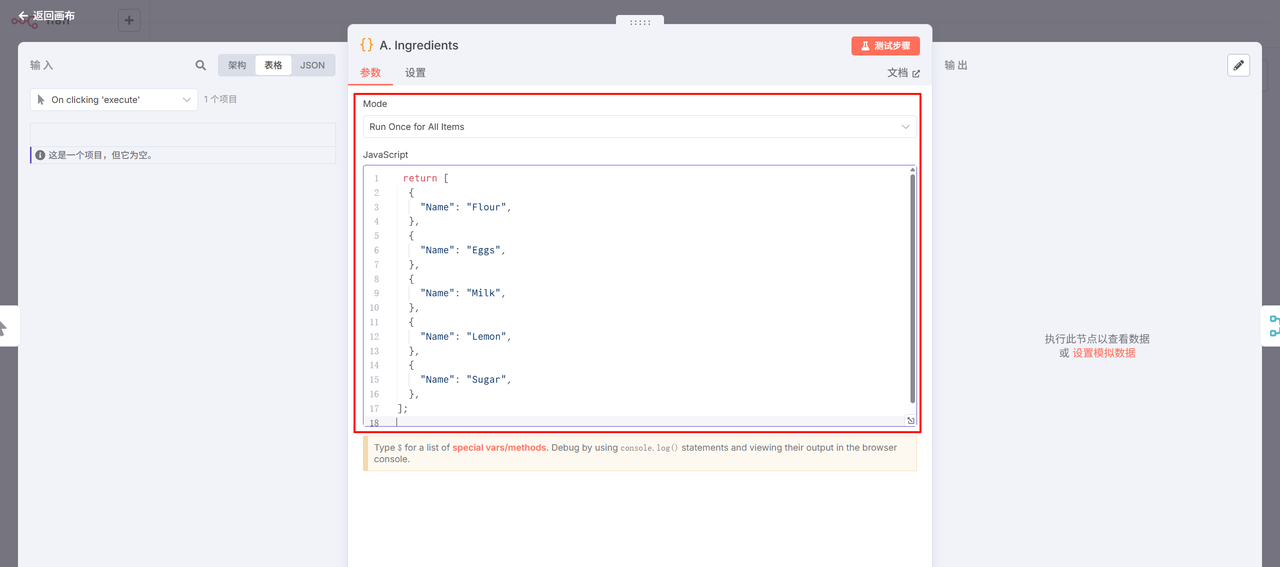
创建一个 Code 节点,
JavaScript:
return [
{
"Name": "Flour",
},
{
"Name": "Eggs",
},
{
"Name": "Milk",
},
{
"Name": "Lemon",
},
{
"Name": "Sugar",
},
];
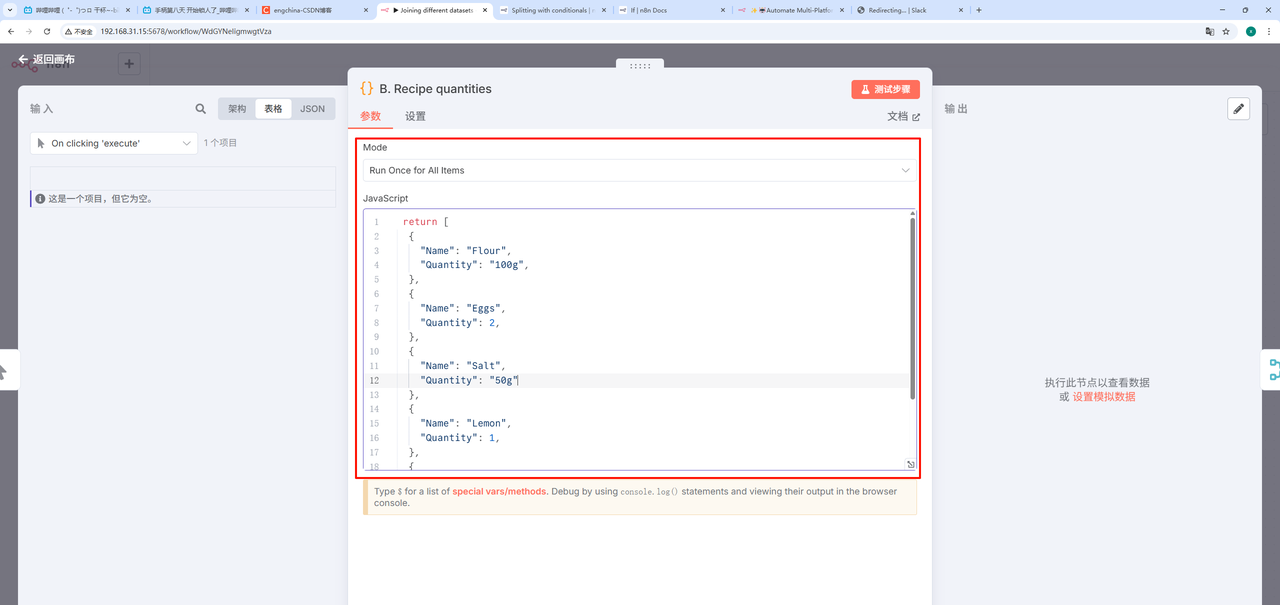
再创建另外一个 Code 节点,
JavaScript:
return [
{
"Name": "Flour",
"Quantity": "100g",
},
{
"Name": "Eggs",
"Quantity": 2,
},
{
"Name": "Salt",
"Quantity": "50g"
},
{
"Name": "Lemon",
"Quantity": 1,
},
{
"Name": "Sugar",
"Quantity": "6tbsp",
},
];
创建一个 Merge 节点,
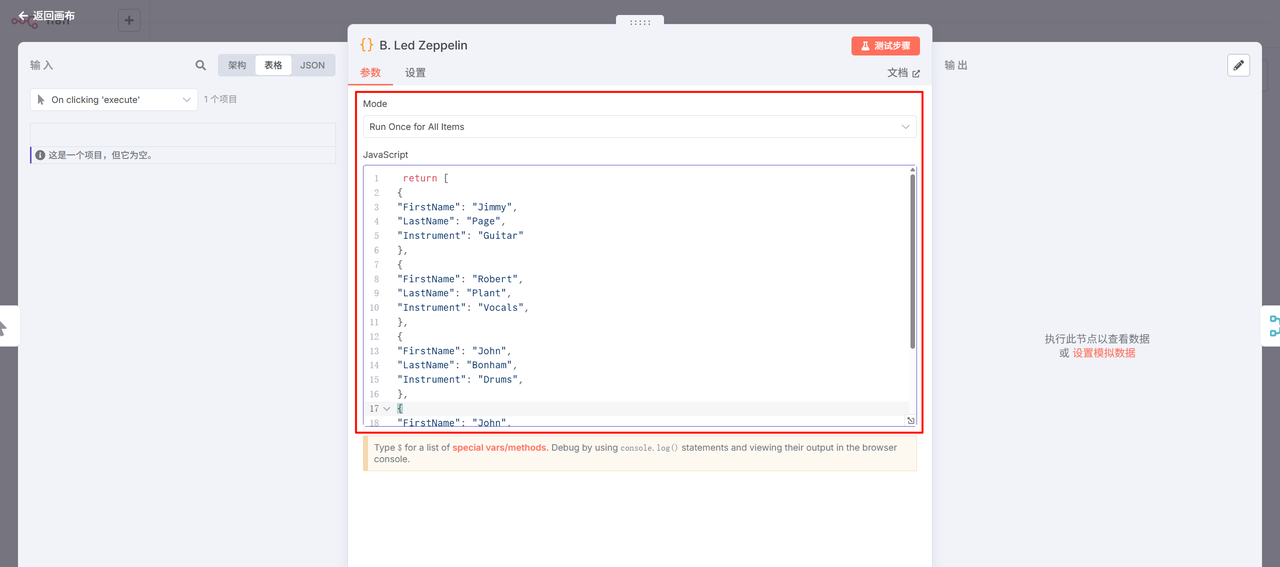
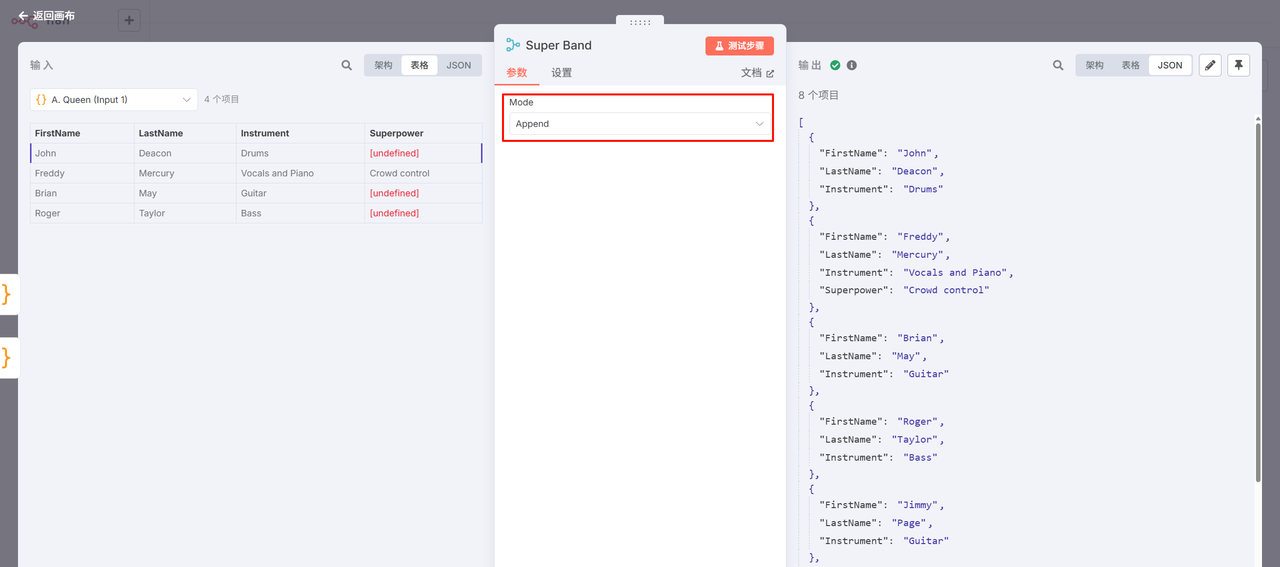
三、将B的数据追加到A的下方(类似SQL全连接)
场景说明:合并两个乐队的歌曲列表
此操作会将B数据源的所有数据项直接追加到A数据源的末尾。例如:
A数据源:皇后乐队(Queen)的歌曲列表
B数据源:Led Zeppelin的歌曲列表
结果:生成一个包含两个乐队全部歌曲的”超级乐队”列表
SQL对应操作
这与SQL中的**全连接(Union All)**类似,但具有更高的灵活性——不要求两个数据源的字段完全一致,适合处理结构差异较大的数据集。
实操
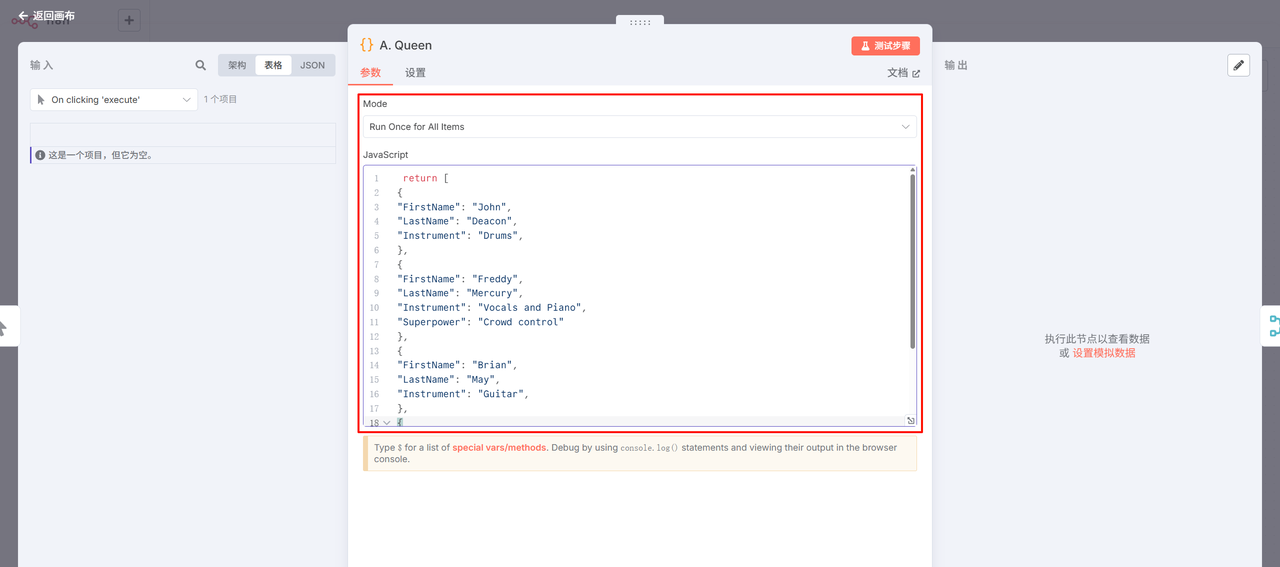
创建一个 Code 节点,
JavaScript:
return [
{
"FirstName": "John",
"LastName": "Deacon",
"Instrument": "Drums",
},
{
"FirstName": "Freddy",
"LastName": "Mercury",
"Instrument": "Vocals and Piano",
"Superpower": "Crowd control"
},
{
"FirstName": "Brian",
"LastName": "May",
"Instrument": "Guitar",
},
{
"FirstName": "Roger",
"LastName": "Taylor",
"Instrument": "Bass",
}
];
再创建另外一个 Code 节点,
JavaScript:
return [
{
"FirstName": "Jimmy",
"LastName": "Page",
"Instrument": "Guitar"
},
{
"FirstName": "Robert",
"LastName": "Plant",
"Instrument": "Vocals",
},
{
"FirstName": "John",
"LastName": "Bonham",
"Instrument": "Drums",
},
{
"FirstName": "John",
"LastName": "Paul Jones",
"Instrument": "Bass",
"Second Instrument": "Keyboard",
}
];
创建一个 Merge 节点,
操作指南
在n8n工作流中添加Merge节点
配置两个数据源(A和B)
根据需求选择匹配模式(保留匹配项/丰富数据/追加数据)
点击执行工作流按钮查看结果
双击Merge节点可实时查看输入输出数据项
📌 更多高级用法请参考官方文档:Merge节点官方文档
实际应用价值
Merge节点的三种操作模式覆盖了数据处理的常见需求:
精准匹配:用于过滤有效数据
数据补充:实现多源数据关联
数据合并:构建统一的数据视图
通过灵活配置,可以轻松完成类似SQL的复杂数据操作,同时避免传统数据库连接的字段限制,特别适合处理JSON等非结构化数据。在实际开发中,这种节点化操作能显著提升数据处理效率,是n8n工作流设计的重要工具。




















暂无评论内容