
#创作灵感#
高校人工智能专业课程实训项目
个人项目实践知识总结
最近高校邀请我去做学校的课程实训项目,要求我出个项目,不过因为我只会软件类的,因此选择使用python调用字节跳动旗下的语音及大模型接口来实现一个语音智能聊天机器人,有点类似微信的语音消息聊天。
思路与架构:
实现思路
调用录音接口->生成语音文件
将语音文件内容识别成文字
将识别后的文字请求到聊天大模型进行返回消息
将聊天大模型返回的文字内容,进行语音合成
播放语音合成的语音文件
原理参考火山引擎的语音实时通话-青青这个实践应用,只不过我这里设计的不是实时通话,而是语音消息的发送,类似于微信的发送语音消息,而这里的类似于语音电话。

架构图
这是官方应用广场青青的架构图,我这里参考它的架构图的原理实现。
![图片[1] - python调用火山引擎大模型实现人工智能语音聊天机器人 - 宋马](https://pic.songma.com/blogimg/20250607/588c7abe1427461f946e3f99ed17f623.png)
简单解释下这个架构图:
这个应用使用的是web的b/s架构,通过在线语音录制后,通过API网关将语音通过websocket长连接协议进行实时传输,传递给后台的Dobao-流式语音识别接口,识别出文字结果后,将识别结果给到后端的SSE(火山引擎中的 SSE(Server-Side Encryption) 是对象存储服务 TOS(Torch Object Storage)提供的一项服务器端加密功能),然后通过SSE服务将文本结果给到Dobao-pro-32k的语言大模型,大模型会进行分析处理和回答,将回答的消息通过websocket长连接协议再转发给Dobao-语音合成接口,最后将合成后的结果通过websocket长连接协议进行流式播放,得到一个完整的语音聊天智能应用。
python+火山引擎实现语音对话功能
(1)语音录入
先进行语音录入,只不过不需要websocket长连接,因为我不需要实时通话。
录音参考脚本:Python Audio 库 详解-腾讯云开发者社区-腾讯云

(2)语音识别(ASR)
录入完成后,需进行语音识别,底层就会调用对应的语音识别接口,只不过我不使用流式语音识别,我这里使用一句话识别。
使用火山引擎的流式语音识别 API 将用户的语音输入转换为文本。
配置 ASR 的相关参数,如 AppId、AccessToken 等。
2.1 使用火山引擎的语音技术的语音识别功能

2.1.1 创建应用

2.1.2 填写应用名称和简介,选择你需要的服务,这里需要选择通用中文服务

2.1.3 应用创建后,则需要点击语音识别功能里的一句话识别,用于聊天,点击试用开通此服务

2.1.4 点击接入文档,下拉到最后,点击python的demo进行下载

2.1.5 将脚本拖入项目中,修改对应的参数,填充参数值
appid,token,cluster的值对应从下图找

audio_path参数填写你自己刚才录制的音频文件的路径,如果跟音频文件在同一个目录下,则只需要填写音频文件名即可,如果不在同一个路径需要指定正确的路径。
核心代码修改:
#省略前面部分
# ....
def voice_to_txt(audio_path):
result = execute_one(
{
'id': 1,
'path': audio_path
},
cluster=cluster,
appid=appid,
token=token,
format=audio_format,
)
return result['result']['payload_msg']['result'][0]['text'](3)大模型处理
将 ASR 转换后的文本发送到大模型服务进行处理。
可以在大模型的配置中设置角色预设指令、历史对话轮数等参数。
3.1 调用python版本的大模型对话API

下面就是官方提供的python版本的对话API接口
import os
from volcenginesdkarkruntime import Ark
client = Ark(api_key=os.environ.get("ARK_API_KEY"))
completion = client.chat.completions.create(
model="doubao-1.5-pro-32k-250115",
messages=[
{"role": "user", "content": "You are a helpful assistant."}
]
)
print(completion.choices[0].message)这里需要我们填写你的API_KEY,api_key可以在火山方舟的系统管理界面进行添加,如下所示:
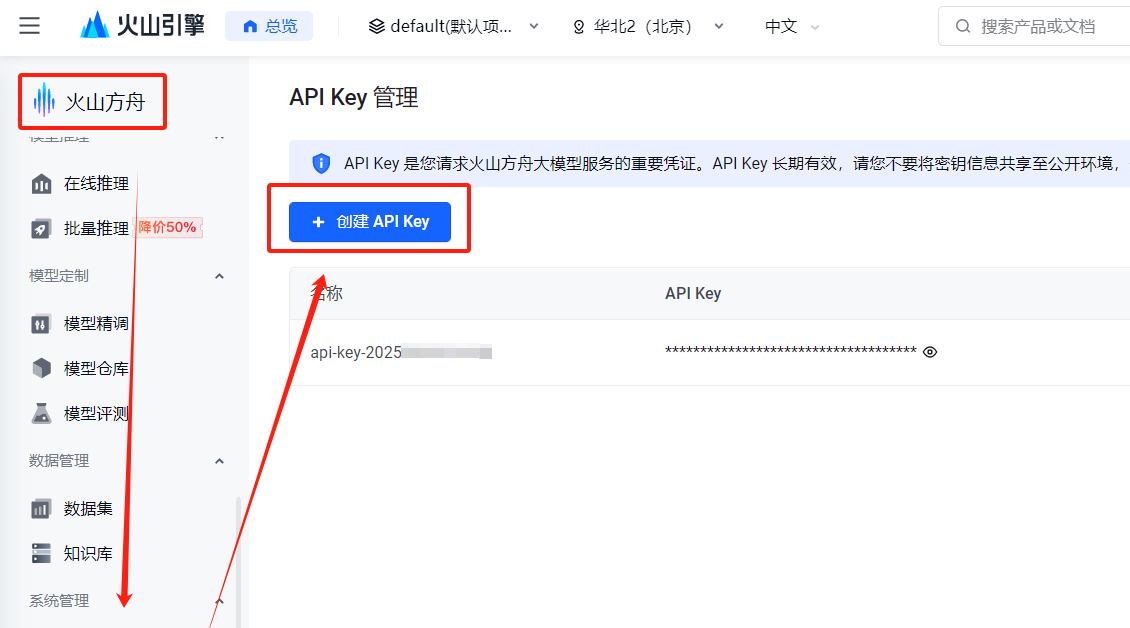
代码还需要添加AI的系统角色,这样有便于我们更好的跟人工只能模型进行聊天沟通。修改后的脚本如下,API-KEY改成具体的内容,而不是从环境变量获取,添加system的role角色,内容提示词个人可以自定义指定,说白了就是你想要怎样的一种人格角色的聊天机器人,我这里以女友的口吻聊天。用户的聊天请求内容,通过设置成变量传递给大模型进行调用,就可以实现动态变更聊天内容。
修改后的接口:
from volcenginesdkarkruntime import Ark
def AI_chat(message):
client = Ark(api_key="这里填写你自己的API-KEY")
# message = input("请输入聊天内容:")
completion = client.chat.completions.create(
model="doubao-1.5-pro-32k-250115",
messages=[
{"role": "user", "content": message},
{"role": "system", "content": "你是AI智能聊天助手,以女友的口吻进行聊天,要求对话简短"}
]
)
return completion.choices[0].message.content最后将聊天结果文字进行返回就可以了
(4)语音合成(TTS)
使用火山引擎的语音合成 API 将大模型生成的文本转换为语音。
配置 TTS 的相关参数,如音色、语速、音量等。
4.1 语音合成接口的调用

接口文档地址:HTTP接口(一次性合成-非流式)–语音技术-火山引擎
当然也可以使用websocket协议的地址,但是我在测试过程中发现调用是异步的,导入调试的时候调用不成功,换成http接口的没有问题,这个你们有能力的可以自行解决
拿到脚本后我们需要自行修改,比如需要将文本消息,录音文件,音色类型这几个参数设置成变量传递过去给函数。
import base64
import json
import uuid
import requests
appid = ""
access_token = ""
cluster = ""
voice_type = ""
host = "openspeech.bytedance.com"
api_url = f"https://{host}/api/v1/tts"
header = {"Authorization": f"Bearer;{access_token}"}
def txt_to_voice(text_msg, filename,voice_type):
request_json = {
"app": {
"appid": appid,
"token": "access_token",
"cluster": cluster
},
"user": {
"uid": "388808087185088"
},
"audio": {
"voice_type": voice_type,
"encoding": "wav",
"speed_ratio": 1.0,
"volume_ratio": 1.0,
"pitch_ratio": 1.0,
},
"request": {
"reqid": str(uuid.uuid4()),
"text": text_msg,
"text_type": "plain",
"operation": "query",
"with_frontend": 1,
"frontend_type": "unitTson"
}
}
try:
resp = requests.post(api_url, json.dumps(request_json), headers=header)
# print(f"resp body:
{resp.json()}")
if "data" in resp.json():
data = resp.json()["data"]
file_to_save = open(filename, "wb")
file_to_save.write(base64.b64decode(data))
except Exception as e:
e.with_traceback()
if __name__ == '__main__':
message = input("请输入聊天内容")
txt_to_voice(message, 'test.wav', 'ICL_zh_female_nuanxinxuejie_tob')4.2 语音合成带音色版
当然默认的语音合成只有两个通用音色,比较单调,如果用户想多些音色,

开通后就会有对应的语音音色了

点击接入文档大模型语音合成API–语音技术-火山引擎
官方默认又一个websocket的协议demo,这里我们使用Http的,http

http版本的语音合成脚本跟4.1的一样,只需要替换对应服务的参数即可。这里不做赘述。
(5)语音播放
语音播放参考脚本:Python Audio 库 详解-腾讯云开发者社区-腾讯云

注意事项
语音录入和语音识别的音频文件必须是一个,同时需要注意路径问题,我这里都是放置到跟脚本的同一个目录下,因此不能乱,同时语音合成的语音文件和播放的文件也必须是一个文件,同时语音文件的格式都必须是一个格式,比如都是wav或者都是mp3,否则就会出现问题。当前也可以把所有音频文件设置成一个文件名,这样也可以。
另外,这些服务只提供一些免费的额度tokens调用,如果调用超过额度,则会收取一些费用,费用不高,一般个人使用者也就几毛一块的就够用了,企业级的应用费用较高,所以个人使用者适当需要已关注下自己的账户余额。

终极调用
这里是我写的最终脚本调用,ttt是我项目的一个目录

所以你们导入时候需要注意自己引入的脚本是否是自己脚本,注意自己的脚本路径问题
from tttt.ai_chat import AI_chat
from tttt.play_voice import play_audio
from tttt.record_voice import record_audio
from tttt.streaming_asr_demo import test_one
from tttt.voice_generate import txt_to_voice
# 综合脚本
# 1、调用录音接口:生成语音文件
# 2、将语音文件内容识别成文字
# 3、将识别后的文字请求到聊天大模型进行返回消息
# 4、将聊天大模型返回的文字内容,进行语音合成
# 5、播放语音合成内容
filename = 'voice.wav'
voice_type = 'ICL_zh_female_nuanxinxuejie_tob'
# 调用录制语音接口脚本
record_audio(filename, 5)
# 语音识别接口调用
user_message = test_one(filename)
print("我:"+user_message)
# 调用聊天大模型
ai_message = AI_chat(user_message)
print("女友:"+ai_message)
# 调用语音合成接口
txt_to_voice(ai_message, filename, voice_type)
# 调用语音播放脚本
play_audio(filename)
最终测试
这里会进行录音,然后录音结束后会进行语音识别,并输出语音识别文字的内容,再通过AI模型聊天接口返回文本,这里做返回输出,并进行语音合成后进行播放。

GUI扩展
可以通过添加一些GUI界面来实现可视化窗口的运行,这里我不做介绍了,大家自行百度研究。























暂无评论内容