

📄 摘要:
异构图神经网络(HGNNs)具有强大的能力,能够将异构图中丰富的结构和语义信息嵌入到节点表示中。现有的 HGNN 方法继承了许多为同构图设计的图神经网络(GNN)中的机制,尤其是注意力机制和多层结构。这些机制带来了过多的复杂性,但目前鲜有工作研究这些机制在异构图中是否真正有效。
在本文中,我们对这些机制进行了深入而详尽的研究,并提出了一种简单高效的异构图神经网络(SeHGNN)。
为了更容易地捕捉结构信息,SeHGNN 预先使用轻量级的平均聚合器计算邻居聚合,这通过移除过度使用的邻居注意力机制以及避免在每个训练轮次中重复聚合邻居,降低了计算复杂性。为了更好地利用语义信息,SeHGNN 采用了单层结构并使用较长的元路径来扩展感受野,同时引入一个基于 Transformer 的语义融合模块,用于融合来自不同元路径的特征。因此,SeHGNN 具有网络结构简单、预测精度高和训练速度快的特点。在五个真实世界的异构图上进行的大量实验表明,SeHGNN 在预测准确率和训练速度方面都优于现有最先进的方法。
📄 Introduction
近年来,图神经网络(GNNs)在提升图表示学习性能方面呈现爆炸式增长(Wu 等人,2020;Liu 等人,2022b;Lin 等人,2022)。图神经网络主要是为同构图设计的,这类图仅包含单一类型的节点和边,它们遵循邻居聚合策略来捕捉图的结构信息。在这种策略中,每个节点的表示是通过递归聚合其邻居节点的特征来计算的(Kipf 和 Welling,2017)。
然而,GNNs 并不足以处理异构图,因为异构图除了结构信息之外,还包含丰富的语义信息(Shi 等人,2016)。
现实世界中许多复杂系统的数据自然可以表示为异构图,其中多种类型的实体和它们之间的关系分别通过不同类型的节点和边来体现。例如,如图 1 所示,引用网络 ACM 包含多种类型的节点:论文(Paper,P)、作者(Author,A)和学科(Subject,S),以及许多具有不同语义含义的关系,例如:作者→撰写→论文(Author writes→Paper)、论文→引用→论文(Paper cites→Paper)、论文→属于→学科(Paper belongs to→Subject)。这些关系可以彼此组合,形成高级语义关系,它们被表示为元路径(Sun 等人,2011;Sun 和 Han,2012)。例如,2跳元路径 Author-Paper-Author(APA)表示合作者关系,而 4跳元路径 Author-Paper-Subject-Paper-Author(APSPA)则描述了两个作者参与相同学科研究的关系。异构图包含更全面的信息和丰富的语义,因此需要专门设计的模型来进行建模。
各种异构图神经网络(HGNNs)已被提出以捕捉语义信息,在异构图表示学习方面取得了显著性能(Dong 等人,2020;Yang 等人,2020;Wang 等人,2020;Zheng 等人,2022;Yan 等人,2022)。因此,HGNN 成为了广泛应用领域的核心技术,如社交网络分析(Liu 等人,2018)、推荐系统(Fan 等人,2019;Niu 等人,2020)以及知识图谱推理(Bansal 等人,2019;Vashishth 等人,2020;Wang 等人,2021a)。图 1 展示了 HGNN 的两种主要类别。基于元路径的方法(Schlichtkrull 等人,2018;Zhang 等人,2019;Wang 等人,2019;Fu 等人,2020)首先捕捉相同语义下的结构信息,然后融合不同的语义信息。这些模型首先在每一条元路径范围内聚合邻居特征,生成语义向量,然后将这些语义向量融合,得到最终的嵌入表示。非元路径方法(Zhu 等人,2019;Hong 等人,2020;Hu 等人,2020b;Lv 等人,2021)则是同时捕捉结构和语义信息。这些模型类似于传统 GNNs,从一个节点的局部邻域中聚合消息,但使用额外的模块(例如注意力机制)将语义信息(如节点类型和边类型)嵌入到传播的消息中。
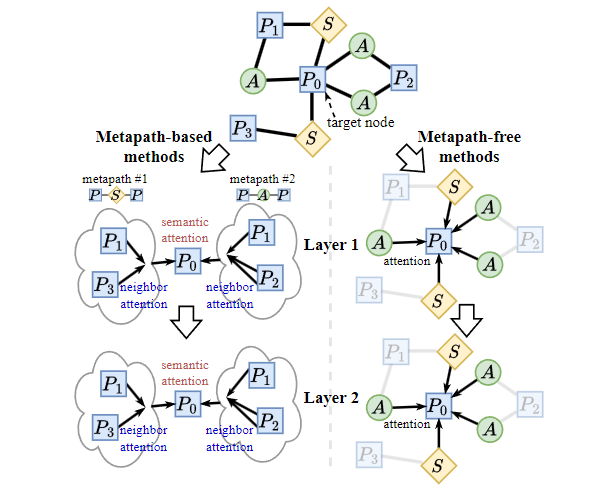
现有的 HGNN 方法继承了许多来自同构图上的 GNN 的机制,尤其是注意力机制和多层结构,如图 1 所示,
但很少有工作研究这些机制在异构图上是否真正有效。此外,多层网络中的层级注意力计算以及每一轮训练中重复的邻居聚合带来了过多的复杂性和计算开销。例如,在基于元路径的模型 HAN(Wang 等人,2019)和非元路径模型 HGB(Lv 等人,2021)中,包含注意力模块的邻居聚合过程占据了总时间的 85% 以上,这已成为 HGNN 应用于大规模异构图时的速度瓶颈。
本文对这些机制进行了深入而详细的研究,并得出两个发现:
(1)语义注意力是必要的,而邻居注意力则不是必需的;
(2)具有单层结构和较长元路径的模型,其性能优于采用多层结构和较短元路径的模型。
这些发现表明,邻居注意力和多层结构不仅引入了不必要的复杂性,而且还阻碍了模型取得更好的性能。
为此,我们提出了一种新的基于元路径的方法,命名为 SeHGNN。SeHGNN 使用平均聚合器(Hamilton、Ying 和 Leskovec,2017)来简化邻居聚合,采用带有长元路径的单层结构以扩展感受野,并利用基于 Transformer 的语义融合模块来学习语义对之间的互注意力。
此外,由于 SeHGNN 中简化的邻居聚合不含参数且仅涉及线性运算,因此有机会将邻居聚合仅在预处理步骤中执行一次。因此,SeHGNN 不仅表现出更好的性能,还避免了在每个训练轮次中反复进行邻居聚合,
从而显著提升了训练速度。
我们在 HGB 基准测试(Lv 等人,2021)中的四个广泛使用的数据集,以及一个来自 OGB 挑战赛的大规模数据集(Hu 等人,2020a)上进行了实验。实验结果表明,SeHGNN 在异构图的节点分类任务中表现优于现有最先进的方法。
本工作的主要贡献总结如下:
我们对 HGNN 中的注意力机制和网络结构进行了深入研究,并得出了两个重要发现: 邻居注意力并非必要,采用单层结构和长元路径具有更优表现。
受上述发现启发,我们提出了一种简单且有效的 HGNN 架构——SeHGNN。 为了更容易捕捉结构信息,SeHGNN 在预处理阶段使用轻量级平均聚合器预计算邻居聚合,去除了过度使用的邻居注意力,并避免了在每一轮训练中重复的邻居聚合。为了更好地利用语义信息,SeHGNN 采用带长元路径的单层结构来扩展感受野,并引入了基于 Transformer 的语义融合模块以融合来自不同元路径的特征。
在五个广泛使用的数据集上的实验表明,SeHGNN 相较于现有最先进方法具有明显优势,即更高的预测准确率和更快的训练速度。
以下是你提供内容中**Preliminaries(预备知识)**部分的逐句中文翻译,保持术语严谨、原文顺序不变:
🧩 预备知识(Preliminaries)
定义 1:异构图(Heterogeneous graphs)
一个异构图被定义为 G = { V , E , T v , T e } G = {V, E, T^v, T^e} G={
V,E,Tv,Te},其中:
V V V 是节点集合,并带有节点类型映射函数 ϕ : V → T v phi: V
ightarrow T^v ϕ:V→Tv;
E E E 是边的集合,并带有边类型映射函数 ψ : E → T e psi: E
ightarrow T^e ψ:E→Te。
每个节点 v i ∈ V v_i in V vi∈V 都关联一个节点类型 c i = ϕ ( v i ) ∈ T v c_i = phi(v_i) in T^v ci=ϕ(vi)∈Tv。
每条边 e t ← s ∈ E e_t leftarrow s in E et←s∈E(简写为 e t s e_{ts} ets)都关联一个关系类型 r c t ← c s = ψ ( e t s ) ∈ T e r_{c_t leftarrow c_s} = psi(e_{ts}) in T^e rct←cs=ψ(ets)∈Te(简写为 r c t c s r_{c_tc_s} rctcs),其方向为从源节点 s s s 指向目标节点 t t t。
当 ∣ T v ∣ = ∣ T e ∣ = 1 |T^v| = |T^e| = 1 ∣Tv∣=∣Te∣=1 时,该图简化为同构图。
图 G G G 的结构可以用一组邻接矩阵 { A r : r ∈ T e } {A^r : r in T^e} {
Ar:r∈Te} 表示。
对于每个关系类型 r c t c s ∈ T e r_{c_tc_s} in T^e rctcs∈Te,对应的邻接矩阵为 A c t c s ∈ R ∣ V c t ∣ × ∣ V c s ∣ A_{c_tc_s} in mathbb{R}^{|V_{c_t}| imes |V_{c_s}|} Actcs∈R∣Vct∣×∣Vcs∣,
其非零值表示当前关系 E c t c s E_{c_tc_s} Ectcs 中边的位置。
定义 2:元路径(Metapaths)
元路径定义了一种由多个边类型组成的复合关系,表示为:
P ≜ c 1 ← c 2 ← ⋯ ← c l ( 简写为 P = c 1 c 2 … c l ) P riangleq c_1 leftarrow c_2 leftarrow dots leftarrow c_l quad ( ext{简写为 } P = c_1 c_2 dots c_l) P≜c1←c2←⋯←cl(简写为 P=c1c2…cl)
给定元路径 P P P,一个元路径实例 p p p 是一个符合路径结构的节点序列,表示为:
p ( v 1 , v l ) = { v 1 , e 12 , v 2 , … , v l − 1 , e ( l − 1 ) l , v l : v i ∈ V c i , e i ( i + 1 ) ∈ E c i c i + 1 } p(v_1, v_l) = {v_1, e_{12}, v_2, dots, v_{l-1}, e_{(l-1)l}, v_l : v_i in V_{c_i}, e_{i(i+1)} in E_{c_ic_{i+1}} } p(v1,vl)={
v1,e12,v2,…,vl−1,e(l−1)l,vl:vi∈Vci, ei(i+1)∈Ecici+1}
特别地, p ( v 1 , v l ) p(v_1, v_l) p(v1,vl) 表示 ( l − 1 ) (l-1) (l−1)-跳的邻居关系,其中 v 1 v_1 v1 是目标节点,
而 v l v_l vl 是基于元路径从 v 1 v_1 v1 出发可达的邻居节点之一。
给定一个元路径 P P P,其两端节点类型为 c 1 , c l c_1, c_l c1,cl,可以从原图 G G G 构造一个元路径邻居图 G P = { V c 1 ∪ V c l , E P } G_P = {V_{c_1} cup V_{c_l}, E_P} GP={
Vc1∪Vcl,EP},
其中,当且仅当在 G G G 中存在元路径实例 p ( v i , v j ) p(v_i, v_j) p(vi,vj) 时,元路径图 G P G_P GP 中才存在边 e i j ∈ E P e_{ij} in E_P eij∈EP,
满足 ϕ ( i ) = c 1 phi(i) = c_1 ϕ(i)=c1, ϕ ( j ) = c l phi(j) = c_l ϕ(j)=cl。
📄相关工作(Related Work)
对于同构图,图神经网络(GNNs)被广泛用于从图结构中学习节点表示。开创性的 GCN(Kipf 和 Welling,2017)提出了一种多层网络,遵循逐层传播规则,其中第 l l l 层通过聚合每个节点 v ∈ V v in V v∈V 的 1 跳邻居集合 N v N_v Nv 中的特征 { h u ( l ) : u ∈ N v } {h^{(l)}_u : u in N_v} {
hu(l):u∈Nv},来学习其嵌入向量 h v ( l + 1 ) h^{(l+1)}_v hv(l+1)。GraphSAGE(Hamilton、Ying 和 Leskovec,2017)通过引入小批量训练和邻居采样(Liu 等人,2022a)来提高模型在大图上的可扩展性。GAT(Veličković 等人,2018)引入了注意力机制,使模型能够更加已关注邻居中最重要的部分。SGC(Wu 等人,2019)去除了连续图卷积层之间的非线性操作,这带来了显著的加速效果,同时对模型性能没有负面影响。
异构图除了结构信息之外,还包含丰富的语义信息,这些信息通过多种类型的节点和边体现出来。
根据处理不同语义信息的方式,异构图神经网络(HGNNs)可分为基于元路径的方法和非元路径的方法。
基于元路径的 HGNN 方法首先聚合相同语义下的邻居特征,然后融合不同的语义信息。RGCN(Schlichtkrull 等人,2018)是第一个根据边类型将 1 跳邻居聚合过程进行区分的方法。HetGNN(Zhang 等人,2019)利用了不同跳数的邻居,它通过随机游走收集不同距离的邻居,然后对相同节点类型的邻居进行聚合。HAN(Wang 等人,2019)利用元路径来区分不同语义,在邻居聚合阶段,它在每个元路径邻居图中使用邻居注意力机制来聚合结构信息,在语义融合阶段,再通过语义注意力将不同子图的输出聚合为每个节点的最终表示。
MAGNN(Fu 等人,2020)进一步利用了元路径实例中所有节点的信息,而不是仅依赖于元路径两端的节点。
非元路径的 HGNN 方法(Metapath-free HGNNs)在局部的 1 跳邻域内,像传统 GNN 一样,同时从所有类型节点的邻居中聚合信息,但引入了额外的模块(如注意力机制)来将节点类型和边类型等语义信息编码到传播的消息中。RSHN(Zhu 等人,2019)构建了粗化的线图(coarsened line graph)来获取不同边类型的全局嵌入表示,随后在每一层中通过邻居特征与边类型嵌入的组合进行特征聚合。HetSANN(Hong 等人,2020)采用了多层的 GAT 网络,并结合类型特定的评分函数(type-specific score functions)来为不同关系生成注意力权重。
HGT(Hu 等人,2020b)提出了一种基于 Transformer(Vaswani 等人,2017)设计的新型异构互注意力机制(heterogeneous mutual attention mechanism),为不同类型的节点和边引入类型特定的可训练参数。HGB(Lv 等人,2021)以多层 GAT 网络为骨干,融合节点特征和可学习的边类型嵌入来生成注意力值。
除了上述两大类 HGNN 方法之外,基于 SGC 的一些工作(如 NARS(Yu 等人,2020)、SAGN(Sun、Gu 和 Hu,2021)以及 GAMLP(Zhang 等人,2022))在异构图上也展现出令人印象深刻的表现,
但这些方法将所有类型节点的特征混合在一起进行聚合,并未明确地区分不同的语义信息。
📄动机(Motivation)
现有的 HGNN 方法继承了许多 GNN 的机制,但并未对其效果进行系统分析。在本节中,我们对 HGNN 中广泛使用的机制进行了深入细致的研究,主要包括:注意力机制和多层结构。
通过实验,我们得出两个重要的发现,为我们设计 SeHGNN 的架构提供了指导。本节中呈现的所有实验结果均为 在 20 次不同数据划分下的平均值,以减弱随机噪声的影响。
关于注意力机制的研究(Study on attentions)
如图 1 所示,HGNN 使用了多种注意力机制,这些注意力是通过不同的模块或参数计算得到的。这些注意力可分为两类:
邻居注意力(neighbor attention):在相同关系的邻居之间计算;
语义注意力(semantic attention):在不同关系之间计算。
基于元路径的方法(如 HAN)分别在邻居聚合步骤和语义融合步骤中引入了这两种注意力。而非元路径的方法(如 HGB)则通过关系特定的嵌入来计算 1 跳邻居的注意力权重。尽管在非元路径方法中很难明确区分这两类注意力,但我们可以通过额外的计算来人为去除其中一种注意力的影响。
具体地,对于每个节点邻居的注意力值,我们可以采用以下方式:
对每种关系内部的邻居注意力取平均值:这相当于去除了邻居注意力;
对每种关系的注意力进行归一化,使每种关系贡献相等:这等价于去除了语义注意力。
在 HGB 上重新实现的实验表明:经过良好训练的 HGB 模型倾向于在每种关系内部分配相似的注意力值,
这促使我们进一步探究不同类型注意力机制的必要性。
我们在 HAN 和 HGB 上进行了实验,其中:
“*” 表示移除邻居注意力(neighbor attention),
“†” 表示移除语义注意力(semantic attention)。
表 1 中的结果表明:移除语义注意力的模型效果下降,
而移除邻居注意力的模型效果并未下降,据此我们得出第一个发现:
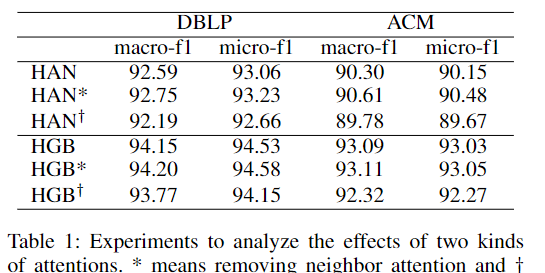
发现 1:语义注意力是必不可少的,而邻居注意力则不是必须的。
这个发现是合理的,因为语义注意力能够衡量不同语义信息的重要性;
而关于邻居注意力,已有多项基于 SGC 的工作(Wu 等人,2019;Rossi 等人,2020;Zhang 等人,2022)已经证明:简单的平均聚合在效果上可以与使用注意力模块的聚合方式相当。
关于多层结构的研究(Study on multi-layer structure)
在没有邻居注意力的情况下,非元路径方法实际上等价于:首先在每种关系内对邻居特征进行平均,
然后再融合不同关系的输出。因此,这类方法可以转换为一种具有多层结构、并在每一层仅使用1 跳元路径的元路径方法。因此,在接下来的实验中,我们将重点研究元路径方法中,网络层数与元路径设计对模型性能的影响。
我们在 HAN 上进行了实验,并使用一个数字列表来表示每个变体的网络结构:
例如,在 ACM 数据集上,结构 (1,1,1,1) 表示一个 4 层网络,每一层都使用 1 跳元路径(如 PA、PS);
而结构 (4) 表示一个单层网络,但包含了所有不超过 4 跳的元路径,例如:PA、PS、PAP、PSP、PAPAP、PSPSP 等。
这些列表也反映了感受野的大小(即每个节点可聚合的信息范围):
比如结构 (1,1,1,1)、(2,2) 和 (4) 拥有相同的感受野大小——它们都涉及到 4 跳的邻居。
基于表 2 中的实验结果,我们得出第二个发现。
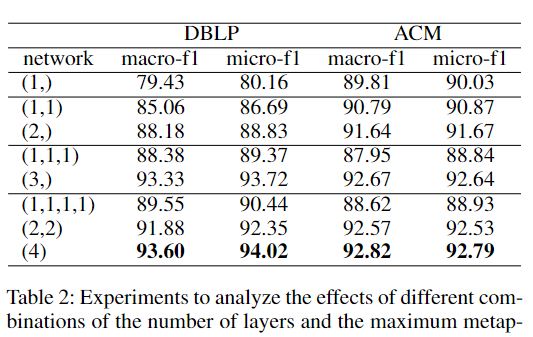
发现 2:具有单层结构和较长元路径的模型优于具有多层结构和较短元路径的模型。
如表 2 所示,在相同感受野大小的前提下,使用单层结构和长元路径的模型表现更佳。
我们认为这是因为:多层网络在每一层就进行语义融合,导致难以区分高阶语义。
举例来说,在结构为 (4) 的模型中,使用多跳元路径使我们能够区分不同的高阶语义关系,比如:
PAP:由同一作者撰写的论文;
PAPAP:由彼此熟悉的作者撰写的论文。
而在结构为 (1,1,1,1) 的四层网络中,由于每层之间的中间表示都是不同语义的混合,因此这些高阶语义的细微差别就无法被有效捕捉。此外,增加元路径的最大长度还能引入更多具有不同语义的元路径,从而进一步提升模型的性能。
SeHGNN 的提出。 受前面两个发现的启发,一方面,我们可以通过在每条元路径的范围内使用平均聚合(mean aggregation)来避免冗余的邻居注意力机制,而不会影响模型效果;另一方面,我们可以通过简化为单层网络结构,同时引入更多且更长的元路径来扩大感受野,从而获得更优的性能。此外,由于不使用注意力机制的邻居聚合过程仅涉及线性操作,且不含可训练参数,这使得邻居聚合可以在预处理阶段执行一次,而不需要在每个训练轮次都重复执行,这大大减少了训练时间。总的来说,这些优化简化了网络结构并提高了效率,而这正是 SeHGNN 的关键设计理念。
方法论
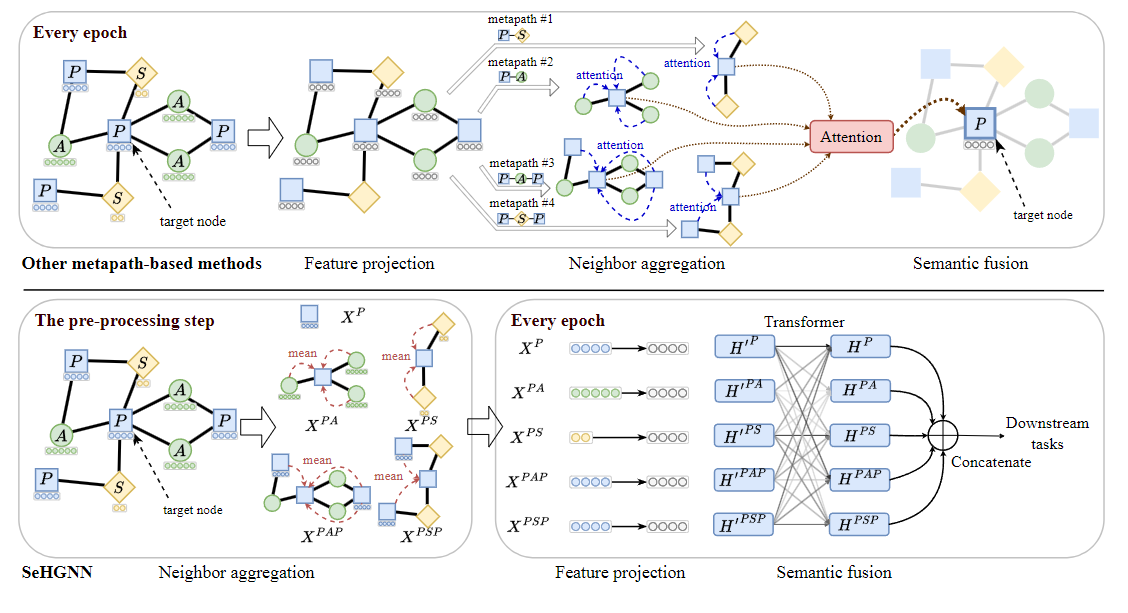
本节正式提出了 简单高效的异构图神经网络(SeHGNN)。如图 2 所示,SeHGNN 的架构包括三个主要组成部分:
简化的邻居聚合(simplified neighbor aggregation),
多层特征投影(multi-layer feature projection),
基于 Transformer 的语义融合(transformer-based semantic fusion)。
图 2 还展示了 SeHGNN 与其他基于元路径的异构图神经网络的区别:SeHGNN 在预处理阶段就预计算了邻居聚合结果,从而避免了在每一轮训练中重复进行邻居聚合所带来的过高复杂度。
算法 1 给出了整体的训练流程。
简化的邻居聚合(Simplified Neighbor Aggregation)
简化的邻居聚合仅在预处理阶段执行一次,并为所有给定的元路径集合 Φ X Phi_X ΦX 生成一组具有不同语义的特征矩阵 M = { X P : P ∈ Φ X } M = {X^P : P in Phi_X } M={
XP:P∈ΦX}。通常,对于每个节点 v i v_i vi,该过程使用平均聚合(mean aggregation),从每条元路径对应的邻居中聚合特征,并输出一组语义特征向量,表示为:
m i = { z i P = 1 ∣ S P ∣ ∑ p ( i , j ) ∈ S P x j : P ∈ Φ X } m_i = { z^P_i = frac{1}{|S^P|} sum_{p(i,j) in S^P} x_j : P in Phi_X } mi={
ziP=∣SP∣1p(i,j)∈SP∑xj:P∈ΦX}
其中:
S P S^P SP 表示所有与元路径 P P P 相对应的元路径实例的集合,
p ( i , j ) p(i, j) p(i,j) 表示一个元路径实例,其目标节点为 i i i,源节点为 j j j,
x j x_j xj 是源节点 j j j 的特征向量。
我们提出了一种简化基于元路径的邻居收集的新方法。现有的基于元路径的方法(如 HAN)通过构建元路径邻居图来枚举每条元路径的所有邻居节点,但随着元路径长度的增加,元路径实例数量呈指数增长,从而带来极高的计算开销。受 GCN 层级传播机制的启发,我们使用邻接矩阵的乘积来计算每个节点对目标节点的最终贡献权重,避免显式枚举元路径实例。
具体而言,设:
X c = { x 0 c T ; x 1 c T ; … ; x ∣ V c ∣ − 1 c T } ∈ R ∣ V c ∣ × d c X^c = {x^{cT}_0; x^{cT}_1; dots; x^{cT}_{|V^c|-1}} in mathbb{R}^{|V^c| imes d^c} Xc={
x0cT;x1cT;…;x∣Vc∣−1cT}∈R∣Vc∣×dc 为类型 c c c 的所有节点的原始特征矩阵, d c d^c dc 是特征维度,
那么简化的邻居聚合过程可以表示为:
X P = A ^ c , c 1 A ^ c 1 , c 2 … A ^ c l − 1 , c l X c l X^P = hat{A}_{c, c_1} hat{A}_{c_1, c_2} dots hat{A}_{c_{l-1}, c_l} X^{c_l} XP=A^c,c1A^c1,c2…A^cl−1,clXcl
其中:
P = c c 1 c 2 … c l P = c,c_1,c_2,dots,c_l P=cc1c2…cl 表示一条 l l l-跳的元路径,
A ^ c i , c i + 1 hat{A}_{c_i, c_{i+1}} A^ci,ci+1 是节点类型 c i c_i ci 和 c i + 1 c_{i+1} ci+1 之间邻接矩阵的行归一化版本。
请注意:
短元路径的聚合结果可以作为长元路径的中间计算结果重用。
例如,在 ACM 数据集中,给定两个元路径:PAP 和 PPAP,我们可以先计算:
X P A P X^{PAP} XPAP
然后再计算:
X P P A P = A ^ P P X P A P X^{PPAP} = hat{A}_{PP} X^{PAP} XPPAP=A^PPXPAP
这样可以减少重复计算,提升效率。
此外,已有研究(Wang and Leskovec 2020;Wang 等,2021b;Shi 等,2021)表明,将标签作为附加输入引入模型中可以提升性能。为了利用这一点,我们采用类似于原始特征聚合的方法,将标签表示为 one-hot 格式,并通过多个元路径进行传播。
该过程生成一组矩阵 { Y P : P ∈ Φ Y } {Y^P : P in Phi_Y} {
YP:P∈ΦY},它们反映了对应元路径邻居图中的标签分布。
请注意,任何属于 Φ Y Phi_Y ΦY 的元路径 P P P 的两个端点都应为节点分类任务中目标节点的类型 c c c。
给定一个元路径 P = c c 1 c 2 … c l − 1 c ∈ Φ Y P = c,c_1,c_2,dots,c_{l-1},c in Phi_Y P=cc1c2…cl−1c∈ΦY,标签传播过程可表示为:
Y P = rm_diag ( A ^ P ) Y c Y^P = ext{rm\_diag}(hat{A}^P) Y^c YP=rm_diag(A^P)Yc
其中:
A ^ P = A ^ c , c 1 A ^ c 1 , c 2 … A ^ c l − 1 , c hat{A}^P = hat{A}_{c,c_1} hat{A}_{c_1,c_2} dots hat{A}_{c_{l-1},c} A^P=A^c,c1A^c1,c2…A^cl−1,c:表示该元路径的归一化邻接矩阵乘积。
Y c Y^c Yc:原始标签矩阵,其中训练集中节点的行被赋予 one-hot 格式的标签值,其余节点对应的行填充为 0。
rm_diag ( A ^ P ) ext{rm\_diag}(hat{A}^P) rm_diag(A^P):用于去除乘积结果中的对角线元素,以避免标签泄露,确保每个节点不会接收到自身的真实标签信息。
标签传播同样在邻居聚合阶段执行,并生成一组语义矩阵,作为后续训练的额外输入。
多层特征映射(Multi-layer Feature Projection)
特征映射步骤的作用是将**不同语义路径(metapath)生成的语义向量投影到相同的数据空间**,因为来自不同 metapath 的语义向量可能具有不同的维度,或者分布在不同的特征空间中。
这里的路径的始末节点不一样吗?因为作者说维度不同,本文应该不是聚合路径上的所有特征,本文的路径到底长什么样?—在图2中找到答案!
一般来说,对于每一个 metapath P P P,会定义一个对应的语义特定变换矩阵 W P W^P WP,并计算:
H ′ P = W P X P H'^P = W^P X^P H′P=WPXP
为了提升表示能力,我们为每个 metapath P P P 使用一个多层感知机块(MLPP, Multi-Layer Perceptron Block),它在两个线性层之间插入了归一化层(Normalization)、非线性激活层(Non-linear Layer)和 Dropout 层。最终,这一过程可以表示为:
H ′ P = M L P P ( X P ) H'^P = {MLP_{P}}(X^P) H′P=MLPP(XP)
即:每条 metapath 的语义表示经过一个独立的 MLP 网络进行特征变换,使它们可以在后续步骤中有效融合。
基于 Transformer 的语义融合
语义融合步骤的目的是将多个语义特征向量融合起来,为每个节点生成最终的嵌入向量。与传统的简单加权求和方式不同,我们提出了一种基于 Transformer(Vaswani et al., 2017)的语义融合模块,用于进一步挖掘不同语义对之间的相互关系。
该基于 Transformer 的语义融合模块旨在学习每对语义向量之间的相互注意力(mutual attention)。设定预定义的元路径列表为 Φ = {P₁, …, Pₖ},对于每个节点,给定投影后的语义向量 {h′ₚ₁, …, h′ₚₖ}。
对于每个语义向量 h′ₚᵢ,模块会将其映射为:
查询向量:qₚᵢ = W_Q · h′ₚᵢ
键向量:kₚᵢ = W_K · h′ₚᵢ
值向量:vₚᵢ = W_V · h′ₚᵢ
然后计算语义 Pi 和 Pj 之间的注意力权重:
α ( P i , P j ) = exp ( q P i ⋅ k P j T ) ∑ P t ∈ Φ exp ( q P i ⋅ k P t T ) α(Pᵢ, Pⱼ) = frac{exp(q_{Pᵢ} · k_{Pⱼ}^T)}{sum_{Pₜ ∈ Φ} exp(q_{Pᵢ} · k_{Pₜ}^T)} α(Pi,Pj)=∑Pt∈Φexp(qPi⋅kPtT)exp(qPi⋅kPjT)
即 softmax 归一化后的点积结果。
最后,语义 Pi 的输出向量 hₚᵢ 是所有值向量 vₚⱼ 的加权和(按注意力加权),再加上一个残差连接(residual connection):
h P i = β ∑ P j ∈ Φ α ( P i , P j ) v P j + h ′ P i h_{Pᵢ} = β sum_{Pⱼ ∈ Φ} α(Pᵢ, Pⱼ) v_{Pⱼ} + h′_{Pᵢ} hPi=βPj∈Φ∑α(Pi,Pj)vPj+h′Pi
其中,W_Q、W_K、W_V 和 β 是对所有 metapath 共享的可训练参数。
最终,每个节点的嵌入向量是所有语义输出向量的拼接:
Final Representation = [ h P 1 ∣ ∣ h P 2 ∣ ∣ … ∣ ∣ h P ∣ Φ ∣ ] ext{Final Representation} = [h_{P₁} || h_{P₂} || ldots || h_{P_{|Phi|}}] Final Representation=[hP1∣∣hP2∣∣…∣∣hP∣Φ∣]
对于下游任务(如节点分类),再通过一个 MLP 网络对拼接后的表示进行预测:
Pred = MLP ( [ h P 1 ∣ ∣ h P 2 ∣ ∣ … ∣ ∣ h P ∣ Φ ∣ ] ) ext{Pred} = ext{MLP}([h_{P₁} || h_{P₂} || ldots || h_{P_{|Phi|}}]) Pred=MLP([hP1∣∣hP2∣∣…∣∣hP∣Φ∣])

2行Calculate aggregation of raw features for each P ∈ Φ_X
=> 通过邻接矩阵乘法,沿元路径聚合原始特征【因此没有聚合中间节点】
3行Calculate aggregation of labels for each P ∈ Φ_Y
=> 类似上面,但输入是标签矩阵;rm_diag 是移除对角线,防止标签泄露【???】
4行Collect all semantic matrices
=> M 是语义特征集合,包含特征和标签两种来源【正文没见写,这两个竟然拼接在一起?】
7行H’_Pᵢ = MLP_Pᵢ(M_Pᵢ)
=> 对每个语义特征 M_P 通过对应的 MLP 投影到统一空间【这里要统一维度,那特征也得去掉自环,要不怎么完成第二行,我现在能感知的是路径的终点和起点可能不是一种节点类型】
11行对每条语义向量加权求和并加residual 残差连接。
实验(Experiment)
我们在四个广泛使用的异构图上进行了实验,包括来自 HGB 基准测试(Lv 等,2021)的 DBLP、ACM、IMDB 和 Freebase,以及一个来自 OGB 挑战赛(Hu 等,2021)的大规模数据集 ogbn-mag。所有实验设置和网络配置的详细信息记录在附录 1 中。
HGB 基准上的实验结果
表 3 展示了 SeHGNN 在四个数据集上的表现,并与 HGB 基准中的若干基线方法进行了比较,包括四种基于元路径的方法(第一个模块)和四种非元路径方法(第二个模块)。结果表明,SeHGNN 的有效性显著:在所有这些基线上,SeHGNN 均获得了最优性能,除了在 Freebase 数据集上的 micro-f1 准确率为第二高。
此外,我们还进行了全面的消融实验,用以验证“动机”部分中提出的两个发现,并评估其他模块的重要性。表 3 中第四个模块显示了 SeHGNN 的四个变体的结果。
变体 #1:在邻居聚合步骤中像 HAN 一样对每条元路径使用 GAT。
变体 #2:使用两层结构,每层都具有独立的邻居聚合和语义融合步骤;但每层中元路径的最大跳数仅为 SeHGNN 的一半,以保证 SeHGNN 和其变体 #2 拥有相同的感受野大小。
SeHGNN 与这两个变体之间的性能差距,证明了这两个发现在 SeHGNN 中同样适用。
变体#3未将标签作为额外输入,变体#4则将基于Transformer的语义融合替换为类似于HAN的加权求和融合方式。值得注意的是,尽管性能略逊于SeHGNN,变体#3已经超过了除Freebase数据集上micro-F1指标以外的大多数基线模型。这些结果表明,引入标签传播机制和基于Transformer的语义融合模块,确实能够提升模型性能。
在 Ogbn-mag 数据集上的结果
Ogbn-mag 数据集带来了两个额外的挑战:(1)某些类型的节点缺乏原始特征;(2)目标类型的节点按年份划分,导致训练集和测试集的节点数据分布不同。现有方法通常通过以下方式应对这些挑战:(1)使用无监督表示学习算法(如 ComplEx(Trouillon 等,2016))生成额外的嵌入(emb 的缩写);(2)采用多阶段学习(ms 的缩写),即在上一个训练阶段中选择置信度较高的测试节点,将这些节点添加到训练集中,并在新阶段重新训练模型(Li, Han 和 Wu 2018;Sun, Lin 和 Zhu 2020;Yang 等,2021)。
为了提供全面的对比,我们在是否使用这些技巧的条件下分别进行比较。对于不使用嵌入(emb)的方法,我们采用随机初始化的原始特征向量。表 4 展示了 SeHGNN 与 OGB 排行榜上的基线方法在大规模数据集 ogbn-mag 上的对比结果。结果显示,在相同条件下,SeHGNN 的表现优于其他方法。值得注意的是,即使在仅使用随机初始化特征的情况下,SeHGNN 的表现也优于那些使用额外表示学习算法训练出的高质量嵌入的方法,这说明 SeHGNN 能够从图结构中学习到更多有用的信息。
时间分析
首先,我们从理论上分析了 SeHGNN 相对于 HAN 和 HGB 的时间复杂度,具体如表 5 所示。我们假设 SeHGNN 和 HAN 都采用单层结构、使用 k k k 条元路径(metapath),而 HGB 采用 l l l 层结构,且元路径的最大跳数也为 l l l,以确保它们具有相同的感受野大小。目标类型节点的数量为 n n n,输入和隐藏向量的维度为 d d d。在 HAN 中的元路径邻居图中,平均邻居数量为 e 1 e_1 e1;在 HGB 的多层聚合中,涉及的平均邻居数量为 e 2 e_2 e2。
请注意, e 1 e_1 e1 和 e 2 e_2 e2 都会随着元路径长度或层数 l l l 的增加呈指数增长。对于文中使用的五个数据集来说,我们最多使用几十条元路径,但当 l ≥ 3 l ≥ 3 l≥3 时,每个节点平均从数千个邻居中聚合信息。一般而言,有 e 1 ≫ k 2 e_1 gg k^2 e1≫k2, e 2 ≫ k 2 e_2 gg k^2 e2≫k2,因此 SeHGNN 的理论复杂度远低于 HAN 和 HGB。
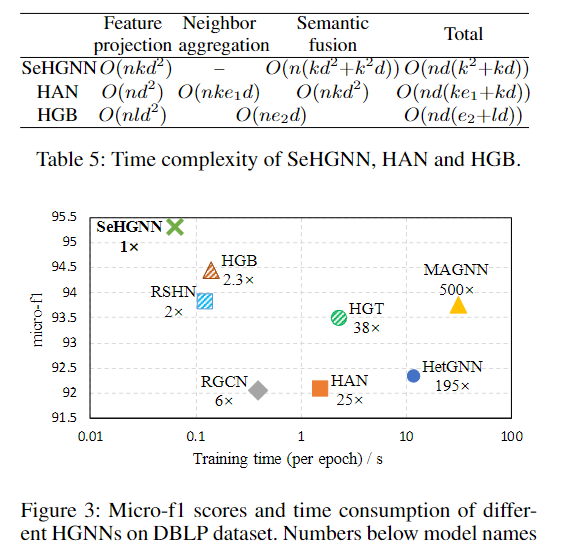
为了验证这一理论分析,我们进行了实验,比较 SeHGNN 与现有 HGNN 的训练耗时。图 3 展示了这些模型达到一定 micro-F1 分数时,每个训练 epoch 的平均时间消耗。实验结果进一步表明:SeHGNN 在训练速度和模型效果上都具有显著优势。
![图片[1] - Simple and Efficient Heterogeneous Graph Neural Network(AAAI 2023)译文 - 宋马](https://pic.songma.com/blogimg/20250610/ba9e65e4a2bc4827b2b56383ccec61f8.png)
![图片[2] - Simple and Efficient Heterogeneous Graph Neural Network(AAAI 2023)译文 - 宋马](https://pic.songma.com/blogimg/20250610/e4b46bc5b4674efbbb9ae988d78e01b3.png)
结论
本文提出了一种新颖的异构图表示学习方法——SeHGNN(Simple and Efficient Heterogeneous Graph Neural Network),该方法基于对注意力机制和网络结构的两个关键发现。SeHGNN 采用轻量级的均值聚合器,在预处理阶段预先完成邻居特征聚合,有效捕捉结构信息的同时,避免了对邻居注意力机制的过度依赖和每轮训练中重复的邻居聚合操作。
此外,SeHGNN 使用单层结构并结合长元路径(metapath)来扩展感受野,同时引入基于 Transformer 的语义融合模块,以更好地利用异构图中的语义信息,从而显著提升了模型的表示能力和效果。
在五个常用数据集上的实验结果表明,SeHGNN 在准确率和训练速度两个方面均优于现有最先进的方法,验证了其优越性和实用价值。
附录:
对 HGB 模型的观察
元路径无关方法 HGB(Lv 等,2021)通过连接边两端节点的嵌入向量和边类型的嵌入向量,来计算每条边的注意力值,公式如下所示:
α i j = exp ( LeakyReLU ( a T [ W h i ∣ ∣ W h j ∣ ∣ W r r i j ] ) ) ∑ k ∈ N i exp ( LeakyReLU ( a T [ W h i ∣ ∣ W h k ∣ ∣ W r r i k ] ) ) alpha_{ij} = frac{exp( ext{LeakyReLU}(a^T [W h_i || W h_j || W_r r_{ij}]))}{sum_{k in N_i} exp( ext{LeakyReLU}(a^T [W h_i || W h_k || W_r r_{ik}]))} αij=∑k∈Niexp(LeakyReLU(aT[Whi∣∣Whk∣∣Wrrik]))exp(LeakyReLU(aT[Whi∣∣Whj∣∣Wrrij]))
在我们对 HGB 的复现实验中发现,注意力值主要受到边类型嵌入的主导。这一点通过如下现象得以体现:在同一种关系内部的注意力值非常接近,而在不同关系之间的注意力值差异显著。
图 4(a) 展示了这一观察结果,图 4(b) 则展示了在 ACM 数据集上,每个目标节点在同一关系内和所有关系间的注意力值标准差的统计情况。
![图片[3] - Simple and Efficient Heterogeneous Graph Neural Network(AAAI 2023)译文 - 宋马](https://pic.songma.com/blogimg/20250610/c8f04d1a38e7459fa993e38cf82550c7.png)
这一观察促使我们进一步探究在异构图神经网络(HGNNs)中,在每种关系内的邻居注意力以及不同语义关系之间的语义注意力的必要性。
现有元路径方法的框架
在现有的元路径方法中,每一层的计算通常可以分为三个主要步骤:特征投影、邻居聚合和语义融合,如表6所示。
特征投影(Feature Projection):这一阶段的目标是将不同类型节点的原始特征向量映射到相同的数据空间,通常使用一个线性投影层来实现。
邻居聚合(Neighbor Aggregation):该步骤根据每种语义范围(例如,RGCN 中的每种关系(可视为1阶元路径),HetGNN 中的每种节点类型,或 HAN 和 MAGNN 中的每条元路径)对邻居的特征向量进行聚合。
语义融合(Semantic Fusion):该步骤将上述不同语义下的向量进行融合,并输出每个节点的最终嵌入表示。
在移除邻居注意力之后,由于特征投影和邻居聚合这两个步骤都不包含非线性函数,因此这两个步骤的顺序是可以交换的。进一步地,由于邻居聚合步骤不涉及任何可训练参数,它可以提前到预处理阶段进行,并且其结果可以在所有训练轮次中共享使用。
在后续实验中我们发现:对于特征投影,使用一个多层感知机(MLP)模块要比使用单层线性层效果更好。因此,SeHGNN 在特征投影步骤中为每条元路径使用 MLP 块,而不是单一线性层。
实验设置
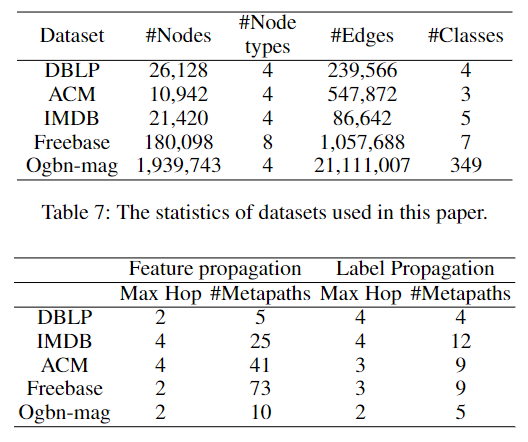
SeHGNN 的评估使用了来自 HGB 基准测试(Lv et al. 2021)的四个中等规模数据集,以及来自 OGB 挑战(Hu et al. 2021)的一个大规模数据集 ogbn-mag。表7总结了这些异构图的统计信息。
对于中等规模的数据集,我们遵循 HGB 基准的配置要求。具体来说,目标类型节点被划分为:30%用于本地训练,70%用于在线测试,测试节点的标签不公开,研究人员必须将预测结果提交至 HGB 基准官网进行在线评估。对于本地训练,我们将这30%节点随机划分为 24% 用于训练,6% 用于验证。
我们将 SeHGNN 的结果与 HGB 论文中报告的基线分数进行比较,所有分数均为 5 次不同本地数据划分的平均值。
对于 ogbn-mag 数据集,我们遵循官方的数据划分方案:将2018年前发表的论文作为训练集,2018年发表的作为验证集,2019年及之后的作为测试集。我们将模型结果与 OGB 排行榜上的分数进行比较,所有分数均为 10 次独立训练的平均值。
我们采用了一种简单的元路径选择方法:预设一个最大的跳数(hop),然后使用所有跳数不超过该上限的可用元路径。我们测试了不同的原始特征传播和标签传播的最大跳数组合,最终的选择列于图8中。
在所有实验中,SeHGNN 在特征投影阶段为每条元路径采用两层的 MLP,其隐藏向量的维度为 512。
在基于 Transformer 的语义融合模块中,查询(query)和键(key)向量的维度为隐藏向量的四分之一,值(value)向量的维度等于隐藏向量的维度,注意力头数为 1。
SeHGNN 在训练过程中使用 Adam 优化器(Kingma 和 Ba,2015)。在 Freebase 数据集上,学习率设为 0.0003,权重衰减设为 0.0001;在其他数据集上,学习率为 0.001,权重衰减为 0。
进一步分析时间复杂度
HAN 和 HGB 方法的计算复杂度难以准确估计,因为它们涉及多种类型的节点,并且在邻居聚合步骤中重复使用了邻居节点的投影特征。为了进行直接的对比,表 5 中仅包含了 HAN 和 HGB 针对目标类型节点(target type nodes)的线性投影的复杂度,而忽略了其他类型节点的相关计算。
如表 9 所示,我们在此基础上增加了其他类型节点的计算复杂度,假设每个训练批次中涉及的这些节点数量为 m m m。这些增加的复杂度包括特征投影阶段的线性投影,以及邻居聚合阶段的邻居注意力计算。
在全批次(full-batch)训练模式下, n n n 和 m m m 分别表示异构图中目标类型节点和其他类型节点的总数。如果 n n n 和 m m m 数量级相近,即 O ( n ) = O ( m ) O(n) = O(m) O(n)=O(m),那么表 9 中的复杂度就可以简化为表 5 中的估计。
然而在小批次(mini-batch)训练中,每个批次中 m m m 可能远大于 n n n。特别是当批次大小较小时,且无法复用投影后的邻居节点特征时, m m m 会随着元路径长度或层数呈指数增长:
对于 HAN: O ( m ) = O ( n k e 1 ) O(m) = O(nk e_1) O(m)=O(nke1)
对于 HGB: O ( m ) = O ( n e 2 ) O(m) = O(n e_2) O(m)=O(ne2)
在这种情形下,表 5 中对 HAN 和 HGB 的复杂度估计就显著偏低了。
相比之下,SeHGNN 的计算复杂度估计则简单得多。由于邻居聚合在预处理步骤中完成,不再涉及每个训练批次中其他类型节点的计算,因此避免了上述复杂性问题。
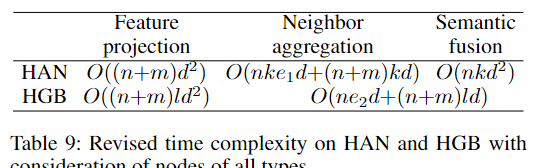




















暂无评论内容