

📋 目录
引言:智能运维的时代背景
AIOps技术体系概述
传统运维向智能运维的演进
AIOps核心技术栈
数据采集与预处理
异常检测与根因分析
智能告警与降噪
预测性运维
自动化修复与自愈系统
AIOps平台架构设计
实施路径与最佳实践
案例研究与效果评估
挑战与解决方案
未来发展趋势
引言
随着云计算、微服务架构和DevOps文化的快速发展,现代IT系统变得前所未有的复杂。传统的人工运维方式已经无法应对数以千计的服务实例、海量的监控数据和快速变化的业务需求。AIOps(Artificial Intelligence for IT Operations) 作为人工智能与IT运维的深度融合,为解决这些挑战提供了革命性的解决方案。
AIOps通过机器学习、大数据分析和自动化技术,将被动的故障响应转变为主动的预测性维护,从繁重的人工操作演进为智能的自愈系统。本文将深入探讨AIOps的技术体系、实施路径和最佳实践,帮助企业构建面向未来的智能运维体系。
AIOps技术体系概述
AIOps定义与核心价值
AIOps是指运用人工智能技术来增强和部分替代IT运维工作的方法论和技术栈。它通过整合多源数据、智能分析和自动化执行,实现IT运维的数字化转型。
核心价值主张: – 提升效率:自动化处理重复性运维任务 – 降低风险:预测性维护减少故障发生 – 优化成本:智能资源调度和容量规划 – 增强体验:更快的故障恢复和更高的系统可用性
AIOps能力成熟度模型
AIOps技术架构全景
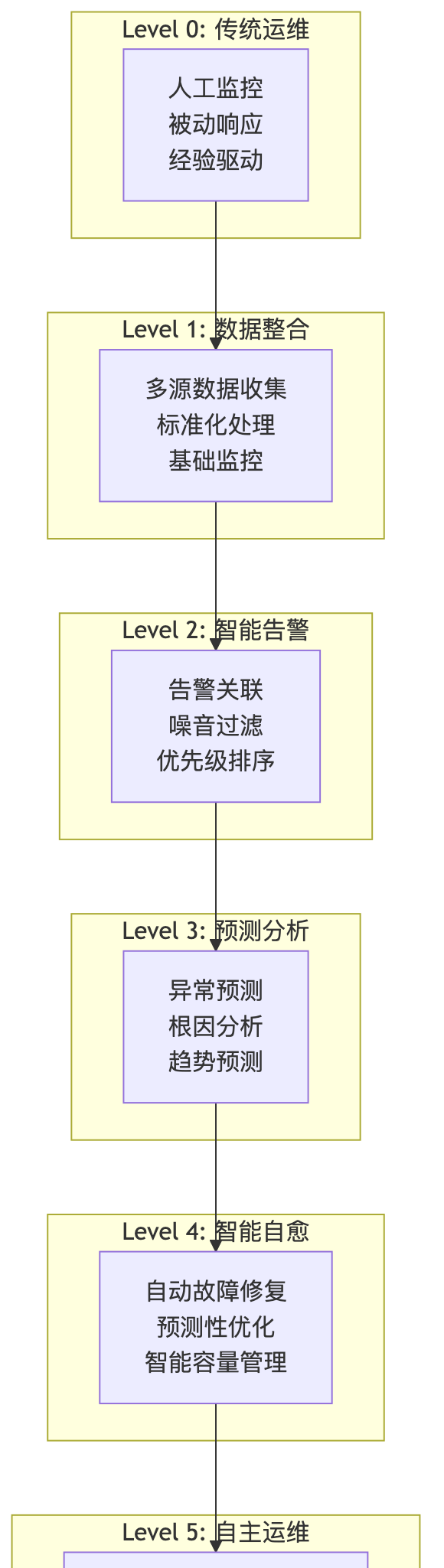
传统运维向智能运维的演进
运维模式演进历程
第一阶段:人工运维时代(2000年以前) – 特点:完全依赖人工操作和经验判断 – 工具:基础的系统命令和简单脚本 – 挑战:效率低、易出错、难以规模化
第二阶段:工具化运维(2000-2010年) – 特点:引入专业监控工具和自动化脚本 – 工具:Nagios、Zabbix、Cacti等监控系统 – 改进:提升了监控覆盖度和响应速度
第三阶段:平台化运维(2010-2015年) – 特点:构建统一的运维平台和标准化流程 – 工具:CMDB、工单系统、自动化部署平台 – 价值:提高了运维标准化程度和协作效率
第四阶段:DevOps运维(2015-2020年) – 特点:开发与运维深度融合,持续交付 – 工具:Jenkins、Docker、Kubernetes、Prometheus – 突破:实现了快速迭代和敏捷交付
第五阶段:智能化运维(2020年至今) – 特点:AI技术深度融合,智能决策和自动执行 – 工具:机器学习平台、AIOps解决方案 – 愿景:实现自主运维和业务价值最大化
传统运维面临的挑战
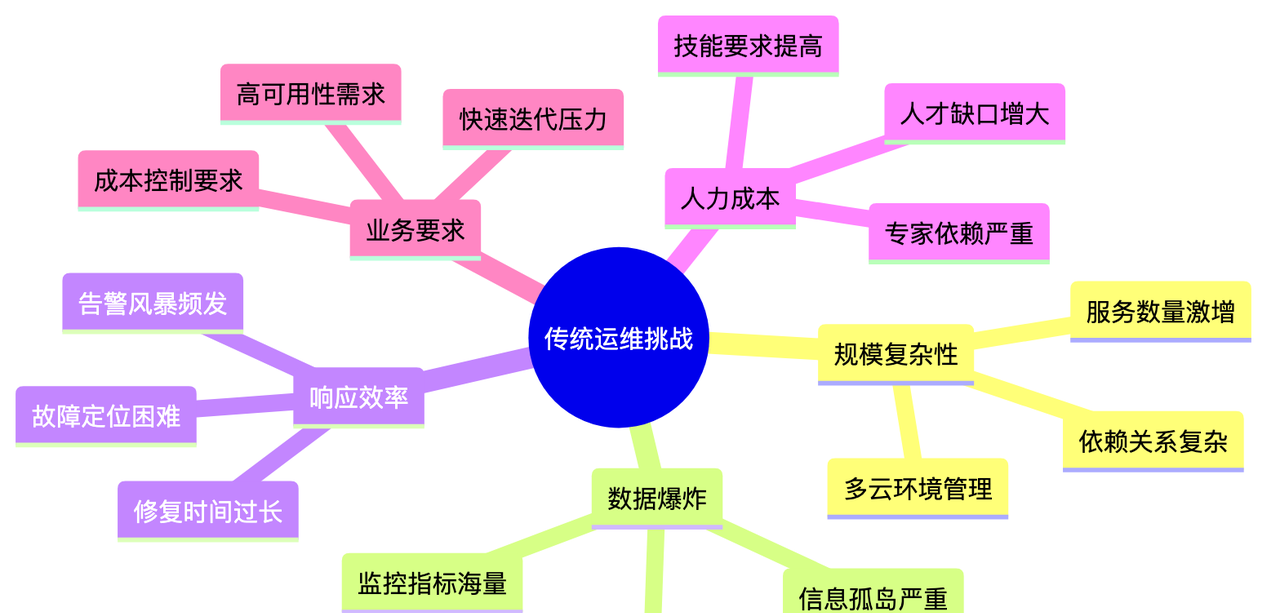
AIOps解决方案价值
| 传统运维痛点 | AIOps解决方案 | 价值提升 |
|---|---|---|
| 告警风暴 | 智能告警降噪 | 减少90%无效告警 |
| 故障定位慢 | 自动根因分析 | 定位时间缩短80% |
| 被动响应 | 预测性维护 | 故障预防率提升70% |
| 重复劳动 | 自动化修复 | 人工介入减少60% |
| 经验依赖 | 知识图谱化 | 新人上手时间减半 |
| 容量规划难 | AI驱动预测 | 资源利用率提升30% |
AIOps核心技术栈
机器学习算法体系
1. 无监督学习算法
# 异常检测算法实现示例
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
class AnomalyDetectionEngine:
def __init__(self):
self.isolation_forest = IsolationForest(contamination=0.1, random_state=42)
self.dbscan = DBSCAN(eps=0.5, min_samples=5)
self.scaler = StandardScaler()
def detect_outliers(self, metrics_data):
"""使用Isolation Forest检测异常"""
# 数据标准化
normalized_data = self.scaler.fit_transform(metrics_data)
# 异常检测
anomaly_labels = self.isolation_forest.fit_predict(normalized_data)
anomaly_scores = self.isolation_forest.decision_function(normalized_data)
return {
'anomalies': anomaly_labels == -1,
'scores': anomaly_scores,
'threshold': np.percentile(anomaly_scores, 10)
}
def cluster_analysis(self, metrics_data):
"""使用DBSCAN进行聚类分析"""
normalized_data = self.scaler.fit_transform(metrics_data)
cluster_labels = self.dbscan.fit_predict(normalized_data)
# 识别噪音点(异常)
noise_points = cluster_labels == -1
return {
'clusters': cluster_labels,
'noise_points': noise_points,
'n_clusters': len(set(cluster_labels)) - (1 if -1 in cluster_labels else 0)
}
# 时间序列异常检测
from statsmodels.tsa.seasonal import seasonal_decompose
from scipy import stats
class TimeSeriesAnomalyDetector:
def __init__(self, window_size=24):
self.window_size = window_size
def detect_seasonal_anomalies(self, timeseries_data, period=24):
"""检测季节性时间序列异常"""
# 季节性分解
decomposition = seasonal_decompose(
timeseries_data,
model='additive',
period=period
)
# 基于残差的异常检测
residuals = decomposition.resid.dropna()
z_scores = np.abs(stats.zscore(residuals))
threshold = 3 # 3-sigma规则
anomalies = z_scores > threshold
return {
'anomalies': anomalies,
'residuals': residuals,
'trend': decomposition.trend,
'seasonal': decomposition.seasonal,
'anomaly_indices': np.where(anomalies)[0]
}2. 监督学习算法
# 故障预测模型
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.model_selection import TimeSeriesSplit
from sklearn.metrics import classification_report, roc_auc_score
import xgboost as xgb
class FailurePredictionModel:
def __init__(self):
self.models = {
'random_forest': RandomForestClassifier(n_estimators=100, random_state=42),
'gradient_boosting': GradientBoostingClassifier(random_state=42),
'xgboost': xgb.XGBClassifier(random_state=42)
}
self.best_model = None
self.feature_importance = None
def prepare_features(self, metrics_data):
"""特征工程"""
features = metrics_data.copy()
# 滚动统计特征
for window in [5, 10, 30]:
features[f'cpu_mean_{window}'] = features['cpu_usage'].rolling(window).mean()
features[f'memory_std_{window}'] = features['memory_usage'].rolling(window).std()
features[f'response_time_max_{window}'] = features['response_time'].rolling(window).max()
# 变化率特征
features['cpu_change'] = features['cpu_usage'].pct_change()
features['memory_change'] = features['memory_usage'].pct_change()
# 交互特征
features['cpu_memory_ratio'] = features['cpu_usage'] / (features['memory_usage'] + 1e-6)
features['load_factor'] = features['request_rate'] * features['response_time']
return features.fillna(0)
def train_ensemble(self, X_train, y_train):
"""训练集成模型"""
model_scores = {}
# 时间序列交叉验证
tscv = TimeSeriesSplit(n_splits=5)
for name, model in self.models.items():
scores = []
for train_idx, val_idx in tscv.split(X_train):
X_fold_train, X_fold_val = X_train.iloc[train_idx], X_train.iloc[val_idx]
y_fold_train, y_fold_val = y_train.iloc[train_idx], y_train.iloc[val_idx]
model.fit(X_fold_train, y_fold_train)
y_pred_proba = model.predict_proba(X_fold_val)[:, 1]
score = roc_auc_score(y_fold_val, y_pred_proba)
scores.append(score)
model_scores[name] = np.mean(scores)
# 选择最佳模型
best_model_name = max(model_scores, key=model_scores.get)
self.best_model = self.models[best_model_name]
# 在全量数据上重新训练
self.best_model.fit(X_train, y_train)
# 获取特征重要性
if hasattr(self.best_model, 'feature_importances_'):
self.feature_importance = dict(zip(X_train.columns, self.best_model.feature_importances_))
return {
'best_model': best_model_name,
'model_scores': model_scores,
'feature_importance': self.feature_importance
}
def predict_failure_probability(self, current_metrics):
"""预测故障概率"""
if self.best_model is None:
raise ValueError("模型未训练,请先调用train_ensemble方法")
features = self.prepare_features(current_metrics)
failure_probability = self.best_model.predict_proba(features)[:, 1]
return {
'failure_probability': failure_probability,
'risk_level': self.categorize_risk(failure_probability),
'contributing_factors': self.get_contributing_factors(features)
}
def categorize_risk(self, probability):
"""风险等级分类"""
if probability < 0.2:
return 'low'
elif probability < 0.5:
return 'medium'
elif probability < 0.8:
return 'high'
else:
return 'critical'深度学习在AIOps中的应用
1. 序列到序列模型用于日志分析
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertModel
import numpy as np
class LogAnalysisModel(nn.Module):
def __init__(self, vocab_size, embedding_dim=128, hidden_dim=256, num_classes=5):
super(LogAnalysisModel, self).__init__()
# BERT预训练模型用于日志语义理解
self.bert = BertModel.from_pretrained('bert-base-uncased')
self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 自定义分类层
self.classifier = nn.Sequential(
nn.Linear(self.bert.config.hidden_size, hidden_dim),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(hidden_dim, num_classes)
)
# LSTM用于时序分析
self.lstm = nn.LSTM(
self.bert.config.hidden_size,
hidden_dim,
batch_first=True,
bidirectional=True
)
def forward(self, log_texts, attention_mask=None):
# BERT编码
outputs = self.bert(input_ids=log_texts, attention_mask=attention_mask)
sequence_output = outputs.last_hidden_state
pooled_output = outputs.pooler_output
# LSTM时序分析
lstm_output, (hidden, cell) = self.lstm(sequence_output)
# 分类预测
classification_logits = self.classifier(pooled_output)
return {
'classification_logits': classification_logits,
'sequence_features': lstm_output,
'pooled_features': pooled_output
}
class LogAnomalyDetector:
def __init__(self):
self.model = LogAnalysisModel()
self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def preprocess_logs(self, log_entries):
"""预处理日志数据"""
processed_logs = []
for log_entry in log_entries:
# 提取关键信息
clean_log = self.clean_log_text(log_entry['message'])
# 添加时间和级别信息
enhanced_log = f"[{log_entry['level']}] {log_entry['timestamp']} {clean_log}"
processed_logs.append(enhanced_log)
# 分词和编码
encoded = self.tokenizer(
processed_logs,
padding=True,
truncation=True,
max_length=512,
return_tensors='pt'
)
return encoded
def detect_anomalies(self, log_entries):
"""检测日志异常"""
self.model.eval()
with torch.no_grad():
encoded_logs = self.preprocess_logs(log_entries)
outputs = self.model(
encoded_logs['input_ids'].to(self.device),
encoded_logs['attention_mask'].to(self.device)
)
# 异常分类
anomaly_probs = torch.softmax(outputs['classification_logits'], dim=-1)
# 序列异常检测
sequence_features = outputs['sequence_features']
sequence_anomalies = self.detect_sequence_anomalies(sequence_features)
return {
'anomaly_probabilities': anomaly_probs.cpu().numpy(),
'sequence_anomalies': sequence_anomalies,
'anomaly_logs': self.extract_anomaly_logs(log_entries, anomaly_probs)
}2. 图神经网络用于依赖关系分析
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv, GATConv
from torch_geometric.data import Data, DataLoader
class ServiceDependencyGNN(nn.Module):
def __init__(self, num_features, hidden_dim=64, num_classes=3):
super(ServiceDependencyGNN, self).__init__()
# 图注意力网络层
self.gat1 = GATConv(num_features, hidden_dim, heads=8, dropout=0.3)
self.gat2 = GATConv(hidden_dim * 8, hidden_dim, heads=1, dropout=0.3)
# 图卷积网络层
self.gcn1 = GCNConv(num_features, hidden_dim)
self.gcn2 = GCNConv(hidden_dim, hidden_dim)
# 分类层
self.classifier = nn.Linear(hidden_dim * 2, num_classes)
self.dropout = nn.Dropout(0.5)
def forward(self, x, edge_index, batch=None):
# GAT路径
gat_x = F.dropout(x, p=0.3, training=self.training)
gat_x = F.elu(self.gat1(gat_x, edge_index))
gat_x = F.dropout(gat_x, p=0.3, training=self.training)
gat_x = self.gat2(gat_x, edge_index)
# GCN路径
gcn_x = F.relu(self.gcn1(x, edge_index))
gcn_x = F.dropout(gcn_x, p=0.3, training=self.training)
gcn_x = self.gcn2(gcn_x, edge_index)
# 特征融合
combined_x = torch.cat([gat_x, gcn_x], dim=1)
# 分类
output = self.classifier(combined_x)
return F.log_softmax(output, dim=1)
class ServiceImpactAnalyzer:
def __init__(self):
self.gnn_model = ServiceDependencyGNN(num_features=20)
self.service_graph = None
def build_service_graph(self, services_data, dependencies):
"""构建服务依赖图"""
# 节点特征:CPU、内存、响应时间等指标
node_features = []
node_mapping = {}
for i, service in enumerate(services_data):
node_mapping[service['name']] = i
features = [
service['cpu_usage'],
service['memory_usage'],
service['response_time'],
service['error_rate'],
service['throughput'],
# ... 其他特征
]
node_features.append(features)
# 边:服务依赖关系
edge_indices = []
for dep in dependencies:
if dep['from'] in node_mapping and dep['to'] in node_mapping:
edge_indices.append([
node_mapping[dep['from']],
node_mapping[dep['to']]
])
# 构建PyTorch Geometric数据对象
self.service_graph = Data(
x=torch.FloatTensor(node_features),
edge_index=torch.LongTensor(edge_indices).t().contiguous()
)
return self.service_graph
def predict_impact_propagation(self, failed_service):
"""预测故障影响传播"""
if self.service_graph is None:
raise ValueError("服务图未构建")
self.gnn_model.eval()
with torch.no_grad():
# 设置故障服务的特征
modified_features = self.service_graph.x.clone()
failed_idx = self.get_service_index(failed_service)
modified_features[failed_idx] = self.simulate_failure_state(
modified_features[failed_idx]
)
# GNN推理
impact_predictions = self.gnn_model(
modified_features,
self.service_graph.edge_index
)
# 计算影响概率
impact_probs = F.softmax(impact_predictions, dim=1)
return {
'impact_probabilities': impact_probs.numpy(),
'high_risk_services': self.identify_high_risk_services(impact_probs),
'propagation_path': self.trace_propagation_path(failed_service, impact_probs)
}数据采集与预处理
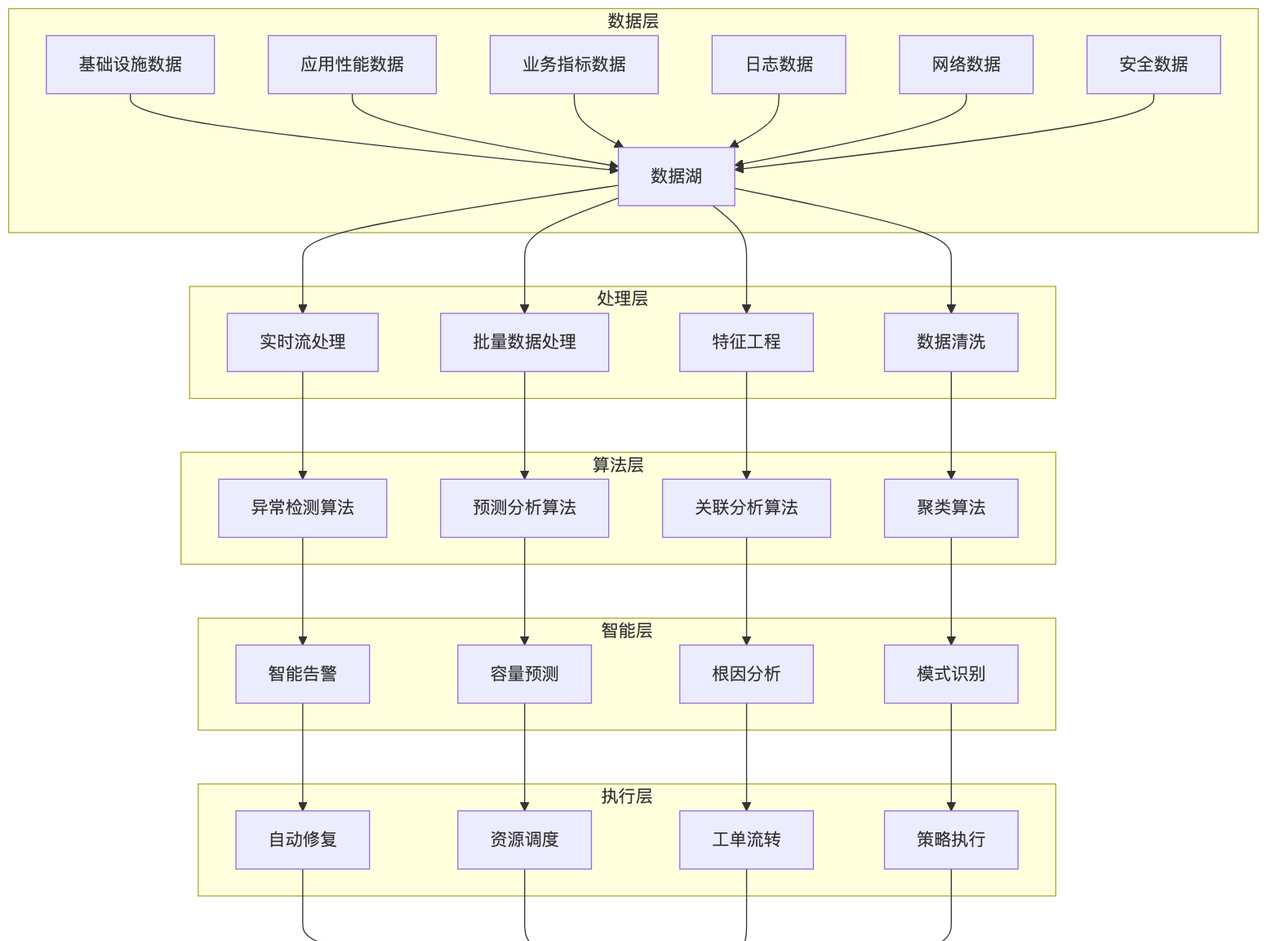
多源数据融合架构
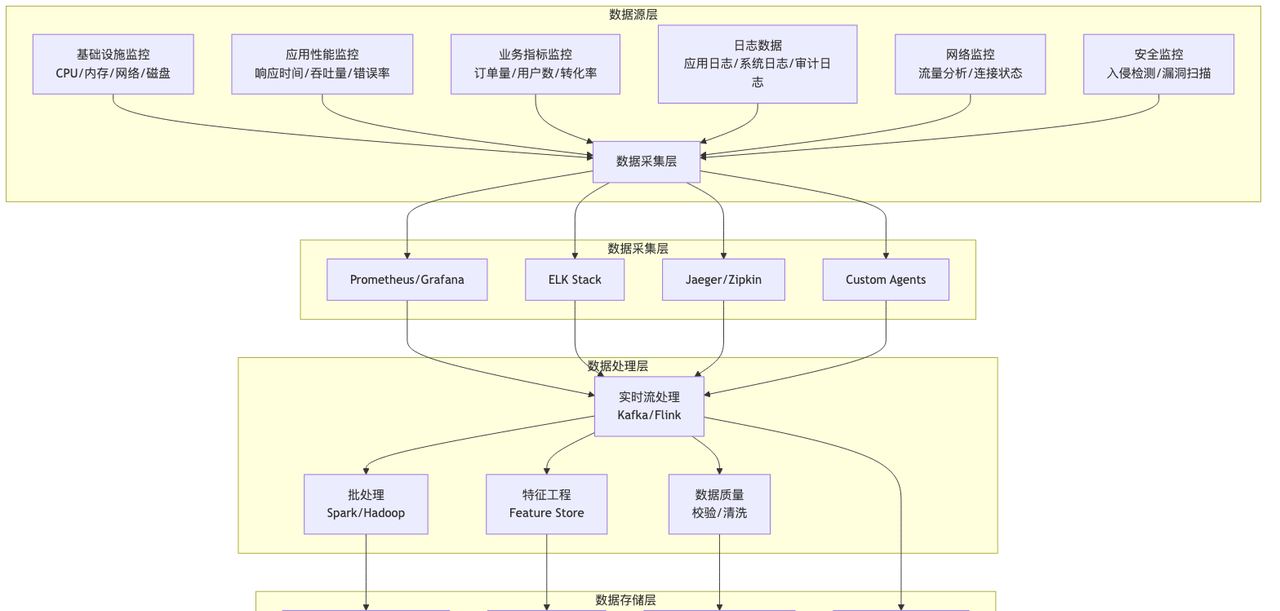
数据质量保障体系
from dataclasses import dataclass
from typing import List, Dict, Any
import pandas as pd
import numpy as np
from scipy import stats
@dataclass
class DataQualityRule:
name: str
rule_type: str # completeness, accuracy, consistency, timeliness
expression: str
threshold: float
severity: str # low, medium, high, critical
class DataQualityChecker:
def __init__(self):
self.rules = self.initialize_default_rules()
self.quality_metrics = {}
def initialize_default_rules(self):
"""初始化默认数据质量规则"""
return [
DataQualityRule(
name="metric_completeness",
rule_type="completeness",
expression="missing_ratio < threshold",
threshold=0.05, # 缺失率小于5%
severity="high"
),
DataQualityRule(
name="metric_range_check",
rule_type="accuracy",
expression="value_in_range",
threshold=0.95, # 95%的值在合理范围内
severity="medium"
),
DataQualityRule(
name="timestamp_consistency",
rule_type="consistency",
expression="timestamp_order_correct",
threshold=0.99, # 99%的时间戳顺序正确
severity="high"
),
DataQualityRule(
name="data_freshness",
rule_type="timeliness",
expression="data_delay < threshold",
threshold=300, # 数据延迟小于5分钟
severity="critical"
)
]
def check_data_quality(self, dataframe: pd.DataFrame, metadata: Dict[str, Any]):
"""检查数据质量"""
quality_report = {
'overall_score': 0.0,
'rule_results': [],
'issues': [],
'recommendations': []
}
total_score = 0
total_weight = 0
for rule in self.rules:
result = self.execute_quality_rule(dataframe, rule, metadata)
quality_report['rule_results'].append(result)
# 计算加权分数
weight = self.get_rule_weight(rule.severity)
total_score += result['score'] * weight
total_weight += weight
# 收集问题和建议
if not result['passed']:
quality_report['issues'].append(result['issue_description'])
quality_report['recommendations'].extend(result['recommendations'])
quality_report['overall_score'] = total_score / total_weight if total_weight > 0 else 0
return quality_report
def execute_quality_rule(self, df: pd.DataFrame, rule: DataQualityRule, metadata: Dict):
"""执行数据质量规则"""
result = {
'rule_name': rule.name,
'passed': False,
'score': 0.0,
'details': {},
'issue_description': '',
'recommendations': []
}
try:
if rule.rule_type == "completeness":
result = self.check_completeness(df, rule, result)
elif rule.rule_type == "accuracy":
result = self.check_accuracy(df, rule, result, metadata)
elif rule.rule_type == "consistency":
result = self.check_consistency(df, rule, result)
elif rule.rule_type == "timeliness":
result = self.check_timeliness(df, rule, result)
except Exception as e:
result['issue_description'] = f"规则执行失败: {str(e)}"
result['score'] = 0.0
return result
def check_completeness(self, df: pd.DataFrame, rule: DataQualityRule, result: Dict):
"""检查数据完整性"""
missing_ratio = df.isnull().sum().sum() / (df.shape[0] * df.shape[1])
result['details']['missing_ratio'] = missing_ratio
result['passed'] = missing_ratio < rule.threshold
result['score'] = max(0, 1 - missing_ratio / rule.threshold)
if not result['passed']:
result['issue_description'] = f"数据缺失率{missing_ratio:.2%}超过阈值{rule.threshold:.2%}"
result['recommendations'] = [
"检查数据采集配置",
"验证数据传输链路",
"增加数据补偿机制"
]
return result
def check_accuracy(self, df: pd.DataFrame, rule: DataQualityRule, result: Dict, metadata: Dict):
"""检查数据准确性"""
accuracy_issues = 0
total_checks = 0
# 检查数值范围
for column in df.select_dtypes(include=[np.number]).columns:
if column in metadata.get('expected_ranges', {}):
expected_range = metadata['expected_ranges'][column]
out_of_range = (
(df[column] < expected_range['min']) |
(df[column] > expected_range['max'])
).sum()
accuracy_issues += out_of_range
total_checks += len(df)
# 检查异常值
for column in df.select_dtypes(include=[np.number]).columns:
z_scores = np.abs(stats.zscore(df[column].dropna()))
outliers = (z_scores > 3).sum() # 3-sigma规则
accuracy_issues += outliers
total_checks += len(df[column].dropna())
accuracy_rate = 1 - (accuracy_issues / total_checks) if total_checks > 0 else 1
result['details']['accuracy_rate'] = accuracy_rate
result['details']['issues_found'] = accuracy_issues
result['passed'] = accuracy_rate >= rule.threshold
result['score'] = min(1, accuracy_rate / rule.threshold)
if not result['passed']:
result['issue_description'] = f"数据准确率{accuracy_rate:.2%}低于阈值{rule.threshold:.2%}"
result['recommendations'] = [
"检查数据采集精度",
"验证传感器校准",
"增加数据验证规则"
]
return result
def check_consistency(self, df: pd.DataFrame, rule: DataQualityRule, result: Dict):
"""检查数据一致性"""
consistency_issues = 0
# 检查时间戳顺序
if 'timestamp' in df.columns:
df['timestamp'] = pd.to_datetime(df['timestamp'])
df = df.sort_values('timestamp')
# 实时数据处理管道
class RealTimeDataProcessor:
def __init__(self):
self.processors = {
'metrics': MetricsProcessor(),
'logs': LogProcessor(),
'traces': TraceProcessor(),
'events': EventProcessor()
}
self.quality_checker = DataQualityChecker()
def process_stream(self, data_stream):
"""处理实时数据流"""
processed_data = {}
for data_type, data_batch in data_stream.items():
if data_type in self.processors:
# 数据预处理
cleaned_data = self.processors[data_type].clean(data_batch)
# 质量检查
quality_report = self.quality_checker.check_data_quality(
cleaned_data,
self.get_metadata(data_type)
)
# 特征提取
features = self.processors[data_type].extract_features(cleaned_data)
# 数据增强
enriched_data = self.processors[data_type].enrich(features)
processed_data[data_type] = {
'data': enriched_data,
'quality': quality_report,
'timestamp': pd.Timestamp.now(),
'metadata': self.get_metadata(data_type)
}
return processed_data异常检测与根因分析
多维度异常检测框架
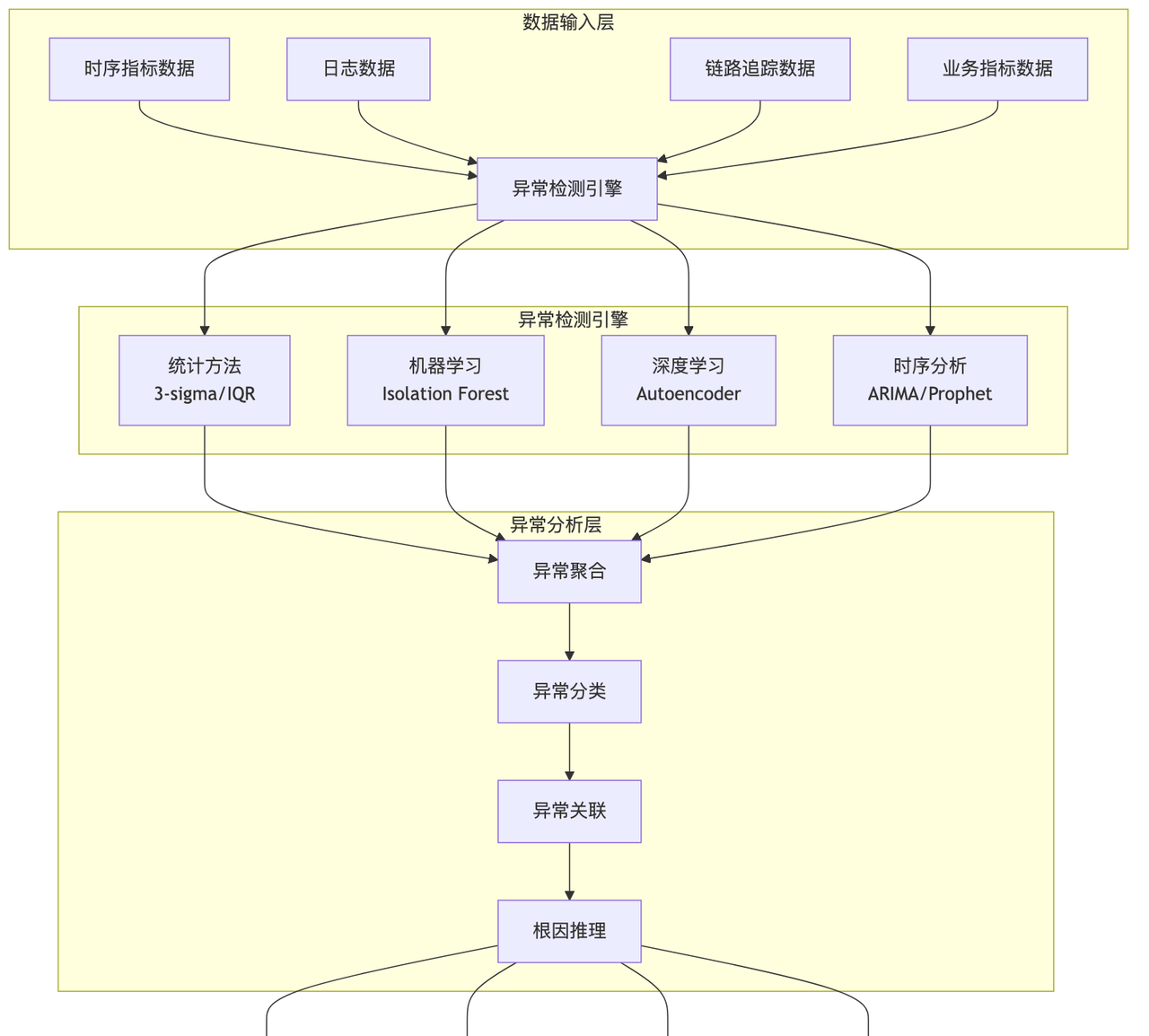
根因分析算法实现
import networkx as nx
from collections import defaultdict, deque
import pandas as pd
from typing import List, Dict, Tuple
class RootCauseAnalyzer:
def __init__(self):
self.dependency_graph = nx.DiGraph()
self.correlation_matrix = None
self.historical_patterns = {}
def build_dependency_graph(self, services_config, dependencies):
"""构建服务依赖图"""
# 添加服务节点
for service in services_config:
self.dependency_graph.add_node(
service['name'],
**service['metadata']
)
# 添加依赖边
for dep in dependencies:
self.dependency_graph.add_edge(
dep['upstream'],
dep['downstream'],
weight=dep.get('weight', 1.0),
latency=dep.get('latency', 0),
error_propagation_rate=dep.get('error_propagation_rate', 0.1)
)
def detect_anomalies_with_context(self, metrics_data, time_window='5min'):
"""带上下文的异常检测"""
anomalies = {}
for service_name, service_metrics in metrics_data.items():
service_anomalies = []
# 单指标异常检测
for metric_name, metric_values in service_metrics.items():
anomaly_result = self.detect_metric_anomaly(
metric_values,
metric_name,
service_name
)
if anomaly_result['is_anomaly']:
service_anomalies.append(anomaly_result)
# 多指标关联异常检测
if len(service_anomalies) > 1:
correlation_anomaly = self.detect_correlation_anomaly(
service_metrics,
service_name
)
if correlation_anomaly:
service_anomalies.append(correlation_anomaly)
if service_anomalies:
anomalies[service_name] = service_anomalies
return anomalies
def analyze_root_cause(self, anomalies, timeline_data):
"""根因分析主函数"""
# 1. 构建异常传播图
anomaly_graph = self.build_anomaly_propagation_graph(anomalies, timeline_data)
# 2. 时序因果分析
causal_relationships = self.analyze_temporal_causality(timeline_data)
# 3. 依赖关系分析
dependency_impact = self.analyze_dependency_impact(anomalies)
# 4. 历史模式匹配
pattern_matches = self.match_historical_patterns(anomalies)
# 5. 综合推理
root_cause_candidates = self.infer_root_causes(
anomaly_graph,
causal_relationships,
dependency_impact,
pattern_matches
)
# 6. 置信度评分
scored_candidates = self.score_root_cause_candidates(root_cause_candidates)
return {
'root_causes': scored_candidates,
'analysis_details': {
'anomaly_graph': anomaly_graph,
'causal_relationships': causal_relationships,
'dependency_impact': dependency_impact,
'pattern_matches': pattern_matches
},
'confidence_metrics': self.calculate_confidence_metrics(scored_candidates)
}
def analyze_temporal_causality(self, timeline_data):
"""时序因果关系分析"""
causal_relationships = []
# 对事件按时间排序
sorted_events = sorted(timeline_data, key=lambda x: x['timestamp'])
# 滑动窗口因果分析
window_size = 10 # 分析窗口大小
for i in range(len(sorted_events) - window_size + 1):
window_events = sorted_events[i:i + window_size]
# 在窗口内查找因果关系
for j, event_a in enumerate(window_events[:-1]):
for event_b in window_events[j+1:]:
# 计算时间延迟
time_delay = (event_b['timestamp'] - event_a['timestamp']).total_seconds()
# 检查是否在合理的因果时间范围内
if 0 < time_delay <= 300: # 5分钟内
causality_score = self.calculate_causality_score(
event_a, event_b, time_delay
)
if causality_score > 0.7: # 因果关系阈值
causal_relationships.append({
'cause': event_a,
'effect': event_b,
'time_delay': time_delay,
'causality_score': causality_score
})
return causal_relationships
def calculate_causality_score(self, event_a, event_b, time_delay):
"""计算因果关系得分"""
score = 0.0
# 1. 依赖关系得分
if self.dependency_graph.has_edge(event_a['service'], event_b['service']):
score += 0.4
# 2. 时间延迟得分(越近越可能有因果关系)
time_score = max(0, 1 - time_delay / 300) # 5分钟内线性衰减
score += 0.3 * time_score
# 3. 错误传播得分
if event_a['type'] == 'error' and event_b['type'] == 'error':
score += 0.2
# 4. 历史模式得分
pattern_key = f"{event_a['service']}-{event_b['service']}"
if pattern_key in self.historical_patterns:
historical_frequency = self.historical_patterns[pattern_key]['frequency']
score += 0.1 * min(1.0, historical_frequency / 10)
return min(1.0, score)
def infer_root_causes(self, anomaly_graph, causal_relationships,
dependency_impact, pattern_matches):
"""综合推理根本原因"""
candidates = defaultdict(lambda: {
'evidence': [],
'supporting_factors': [],
'confidence_factors': []
})
# 1. 从异常传播图中找根节点
for node in anomaly_graph.nodes():
if anomaly_graph.in_degree(node) == 0: # 入度为0的节点
candidates[node]['evidence'].append('anomaly_origin')
candidates[node]['supporting_factors'].append(
f"异常传播起始点: {node}"
)
# 2. 从因果关系中找根源
cause_counts = defaultdict(int)
for rel in causal_relationships:
cause_counts[rel['cause']['service']] += rel['causality_score']
# 高频原因候选
for service, score in cause_counts.items():
if score > 2.0: # 阈值
candidates[service]['evidence'].append('causal_analysis')
candidates[service]['supporting_factors'].append(
f"因果分析高分: {score:.2f}"
)
# 3. 从依赖影响分析中找关键节点
for service, impact in dependency_impact.items():
if impact['downstream_affected'] > 5: # 影响下游服务超过5个
candidates[service]['evidence'].append('dependency_impact')
candidates[service]['supporting_factors'].append(
f"影响下游服务数: {impact['downstream_affected']}"
)
# 4. 历史模式匹配
for pattern in pattern_matches:
if pattern['confidence'] > 0.8:
root_service = pattern['historical_root_cause']
candidates[root_service]['evidence'].append('historical_pattern')
candidates[root_service]['supporting_factors'].append(
f"历史模式匹配: {pattern['pattern_name']}"
)
return dict(candidates)
def score_root_cause_candidates(self, candidates):
"""为根因候选打分"""
# 定义证据类型权重
evidence_type_weight = {
'anomaly_origin': 0.5,
'causal_analysis': 0.4,
'dependency_impact': 0.3,
'historical_pattern': 0.2
}
scored_candidates = []
for service, candidate_info in candidates.items():
score = 0.0
# 证据类型评分
for evidence_type in candidate_info['evidence']:
score += evidence_type_weight.get(evidence_type, 0)
# 考虑支持因子数量
score += len(candidate_info['supporting_factors']) * 0.1
# 置信度因子
confidence_factors = candidate_info['confidence_factors']
if confidence_factors:
confidence_score = sum(confidence_factors) / len(confidence_factors)
score += confidence_score * 0.2
# 综合得分
candidate_info['score'] = score
scored_candidates.append(candidate_info)
# 按得分降序排序
scored_candidates.sort(key=lambda x: x['score'], reverse=True)
return scored_candidates智能告警与降噪
告警降噪算法
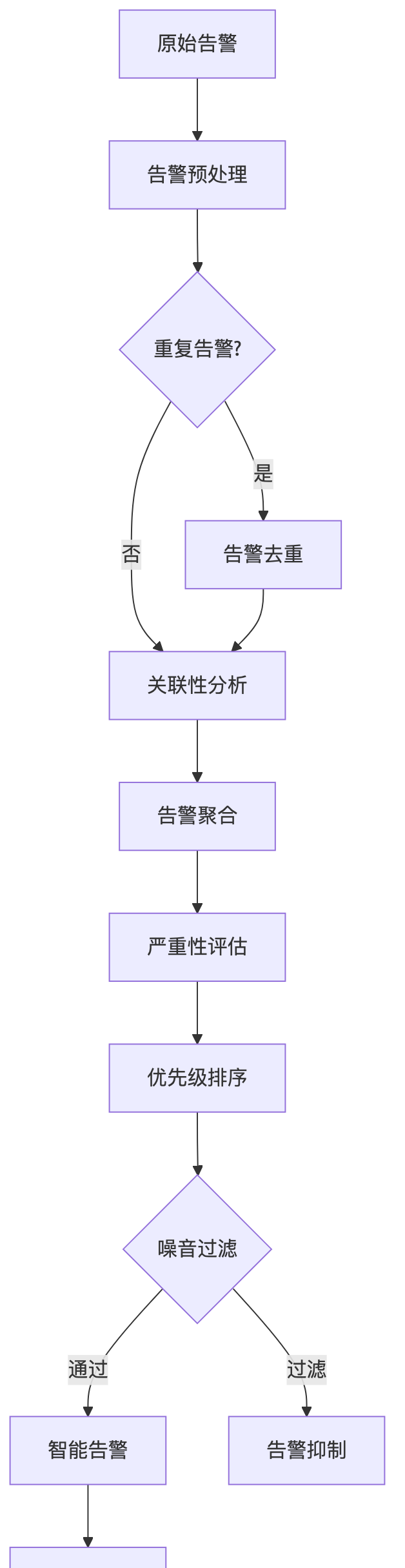
智能告警系统实现
from dataclasses import dataclass
from enum import Enum
from typing import List, Dict, Optional
import hashlib
from datetime import datetime, timedelta
class AlertSeverity(Enum):
CRITICAL = 1
HIGH = 2
MEDIUM = 3
LOW = 4
INFO = 5
class AlertStatus(Enum):
FIRING = "firing"
RESOLVED = "resolved"
SUPPRESSED = "suppressed"
ACKNOWLEDGED = "acknowledged"
@dataclass
class Alert:
id: str
service: str
metric: str
value: float
threshold: float
severity: AlertSeverity
status: AlertStatus
timestamp: datetime
labels: Dict[str, str]
annotations: Dict[str, str]
fingerprint: str = None
def __post_init__(self):
if not self.fingerprint:
self.fingerprint = self.generate_fingerprint()
def generate_fingerprint(self):
"""生成告警指纹用于去重"""
content = f"{self.service}_{self.metric}_{self.labels.get('instance', '')}"
return hashlib.md5(content.encode()).hexdigest()
class IntelligentAlertManager:
def __init__(self):
self.alert_history = {}
self.suppression_rules = []
self.correlation_rules = []
self.noise_patterns = {}
def process_alerts(self, incoming_alerts: List[Alert]) -> List[Alert]:
"""处理告警流水线"""
# 1. 预处理和验证
valid_alerts = self.preprocess_alerts(incoming_alerts)
# 2. 告警去重
deduplicated_alerts = self.deduplicate_alerts(valid_alerts)
# 3. 关联性分析
correlated_groups = self.correlate_alerts(deduplicated_alerts)
# 4. 告警聚合
aggregated_alerts = self.aggregate_alerts(correlated_groups)
# 5. 噪音过滤
filtered_alerts = self.filter_noise(aggregated_alerts)
# 6. 严重性重新评估
prioritized_alerts = self.reprioritize_alerts(filtered_alerts)
# 7. 抑制规则应用
final_alerts = self.apply_suppression_rules(prioritized_alerts)
return final_alerts
def deduplicate_alerts(self, alerts: List[Alert]) -> List[Alert]:
"""告警去重"""
unique_alerts = {}
for alert in alerts:
fingerprint = alert.fingerprint
if fingerprint in unique_alerts:
# 更新已存在的告警
existing_alert = unique_alerts[fingerprint]
if alert.timestamp > existing_alert.timestamp:
# 保留最新的告警,但合并信息
existing_alert.value = alert.value
existing_alert.timestamp = alert.timestamp
existing_alert.annotations.update(alert.annotations)
else:
unique_alerts[fingerprint] = alert
return list(unique_alerts.values())
def correlate_alerts(self, alerts: List[Alert]) -> List[List[Alert]]:
"""告警关联性分析"""
correlation_groups = []
unprocessed_alerts = alerts.copy()
while unprocessed_alerts:
current_alert = unprocessed_alerts.pop(0)
correlation_group = [current_alert]
# 查找相关告警
related_alerts = []
for alert in unprocessed_alerts:
if self.are_alerts_correlated(current_alert, alert):
related_alerts.append(alert)
correlation_group.append(alert)
# 从未处理列表中移除相关告警
for alert in related_alerts:
unprocessed_alerts.remove(alert)
correlation_groups.append(correlation_group)
return correlation_groups
def are_alerts_correlated(self, alert1: Alert, alert2: Alert) -> bool:
"""判断两个告警是否相关"""
correlation_score = 0.0
# 1. 时间相关性(时间窗口内的告警更可能相关)
time_diff = abs((alert1.timestamp - alert2.timestamp).total_seconds())
if time_diff <= 300: # 5分钟内
correlation_score += 0.3
# 2. 服务相关性
if alert1.service == alert2.service:
correlation_score += 0.4
elif self.are_services_dependent(alert1.service, alert2.service):
correlation_score += 0.25
# 3. 指标相关性
if self.are_metrics_related(alert1.metric, alert2.metric):
correlation_score += 0.2
# 4. 标签相关性
common_labels = set(alert1.labels.keys()) & set(alert2.labels.keys())
if common_labels:
matching_values = sum(
1 for label in common_labels
if alert1.labels[label] == alert2.labels[label]
)
correlation_score += 0.1 * (matching_values / len(common_labels))
return correlation_score > 0.6 # 相关性阈值
def aggregate_alerts(self, correlation_groups: List[List[Alert]]) -> List[Alert]:
"""告警聚合"""
aggregated_alerts = []
for group in correlation_groups:
if len(group) == 1:
# 单个告警不需要聚合
aggregated_alerts.append(group[0])
else:
# 多个告警聚合为一个
aggregated_alert = self.create_aggregated_alert(group)
aggregated_alerts.append(aggregated_alert)
return aggregated_alerts
def create_aggregated_alert(self, alerts: List[Alert]) -> Alert:
"""创建聚合告警"""
# 选择最高严重级别
max_severity = min(alert.severity for alert in alerts)
# 选择最新时间戳
latest_timestamp = max(alert.timestamp for alert in alerts)
# 合并服务列表
services = list(set(alert.service for alert in alerts))
# 合并标签和注释
merged_labels = {}
merged_annotations = {}
for alert in alerts:
merged_labels.update(alert.labels)
merged_annotations.update(alert.annotations)
# 添加聚合信息
merged_annotations['aggregated_count'] = str(len(alerts))
merged_annotations['aggregated_services'] = ', '.join(services)
merged_annotations['summary'] = f"聚合了{len(alerts)}个相关告警"
return Alert(
id=f"aggregated_{hashlib.md5(str(sorted([a.id for a in alerts])).encode()).hexdigest()[:8]}",
service=services[0] if len(services) == 1 else "multiple",
metric="aggregated",
value=max(alert.value for alert in alerts),
threshold=min(alert.threshold for alert in alerts),
severity=max_severity,
status=AlertStatus.FIRING,
timestamp=latest_timestamp,
labels=merged_labels,
annotations=merged_annotations
)
def filter_noise(self, alerts: List[Alert]) -> List[Alert]:
"""噪音过滤"""
filtered_alerts = []
for alert in alerts:
if not self.is_noise_alert(alert):
filtered_alerts.append(alert)
else:
# 记录被过滤的噪音告警
self.record_noise_pattern(alert)
return filtered_alerts
def is_noise_alert(self, alert: Alert) -> bool:
"""判断是否为噪音告警"""
# 1. 检查历史噪音模式
if self.matches_noise_pattern(alert):
return True
# 2. 检查告警频率
if self.is_high_frequency_alert(alert):
return True
# 3. 检查告警持续时间
if self.is_short_lived_alert(alert):
return True
# 4. 检查业务影响
if not self.has_business_impact(alert):
return True
return False
def reprioritize_alerts(self, alerts: List[Alert]) -> List[Alert]:
"""重新评估告警优先级"""
for alert in alerts:
# 基于多个因素重新计算严重性
business_impact_score = self.calculate_business_impact(alert)
technical_severity_score = self.calculate_technical_severity(alert)
user_impact_score = self.calculate_user_impact(alert)
# 综合评分
overall_score = (
business_impact_score * 0.4 +
technical_severity_score * 0.3 +
user_impact_score * 0.3
)
# 更新严重性等级
if overall_score >= 0.9:
alert.severity = AlertSeverity.CRITICAL
elif overall_score >= 0.7:
alert.severity = AlertSeverity.HIGH
elif overall_score >= 0.5:
alert.severity = AlertSeverity.MEDIUM
elif overall_score >= 0.3:
alert.severity = AlertSeverity.LOW
else:
alert.severity = AlertSeverity.INFO
# 按严重性排序
return sorted(alerts, key=lambda x: x.severity.value)
# 告警路由和通知
class AlertRouter:
def __init__(self):
self.notification_channels = {
'email': EmailNotifier(),
'slack': SlackNotifier(),
'sms': SMSNotifier(),
'webhook': WebhookNotifier()
}
self.routing_rules = self.load_routing_rules()
def route_alerts(self, alerts: List[Alert]):
"""告警路由"""
for alert in alerts:
routing_config = self.determine_routing(alert)
for channel_name, config in routing_config.items():
if channel_name in self.notification_channels:
notifier = self.notification_channels[channel_name]
try:
# 格式化告警消息
message = self.format_alert_message(alert, channel_name)
# 发送通知
notifier.send_notification(
message=message,
recipients=config['recipients'],
urgency=alert.severity
)
# 记录发送日志
self.log_notification(alert, channel_name, 'success')
except Exception as e:
# 记录发送失败
self.log_notification(alert, channel_name, 'failed', str(e))
def determine_routing(self, alert: Alert) -> Dict[str, Dict]:
"""确定告警路由配置"""
routing_config = {}
for rule in self.routing_rules:
if self.matches_routing_rule(alert, rule):
for channel in rule['channels']:
routing_config[channel['type']] = {
'recipients': channel['recipients'],
'template': channel.get('template', 'default'),
'escalation': channel.get('escalation', False)
}
return routing_config
def format_alert_message(self, alert: Alert, channel_type: str) -> str:
"""格式化告警消息"""
templates = {
'slack': self.format_slack_message,
'email': self.format_email_message,
'sms': self.format_sms_message
}
formatter = templates.get(channel_type, self.format_default_message)
return formatter(alert)
def format_slack_message(self, alert: Alert) -> str:
"""格式化Slack消息"""
color_map = {
AlertSeverity.CRITICAL: 'danger',
AlertSeverity.HIGH: 'warning',
AlertSeverity.MEDIUM: 'good',
AlertSeverity.LOW: '#439FE0',
AlertSeverity.INFO: '#808080'
}
return {
"attachments": [{
"color": color_map[alert.severity],
"title": f"🚨 {alert.severity.name} Alert",
"fields": [
{
"title": "Service",
"value": alert.service,
"short": True
},
{
"title": "Metric",
"value": alert.metric,
"short": True
},
{
"title": "Current Value",
"value": f"{alert.value}",
"short": True
},
{
"title": "Threshold",
"value": f"{alert.threshold}",
"short": True
}
],
"text": alert.annotations.get('description', ''),
"ts": int(alert.timestamp.timestamp())
}]
}预测性运维
预测模型架构
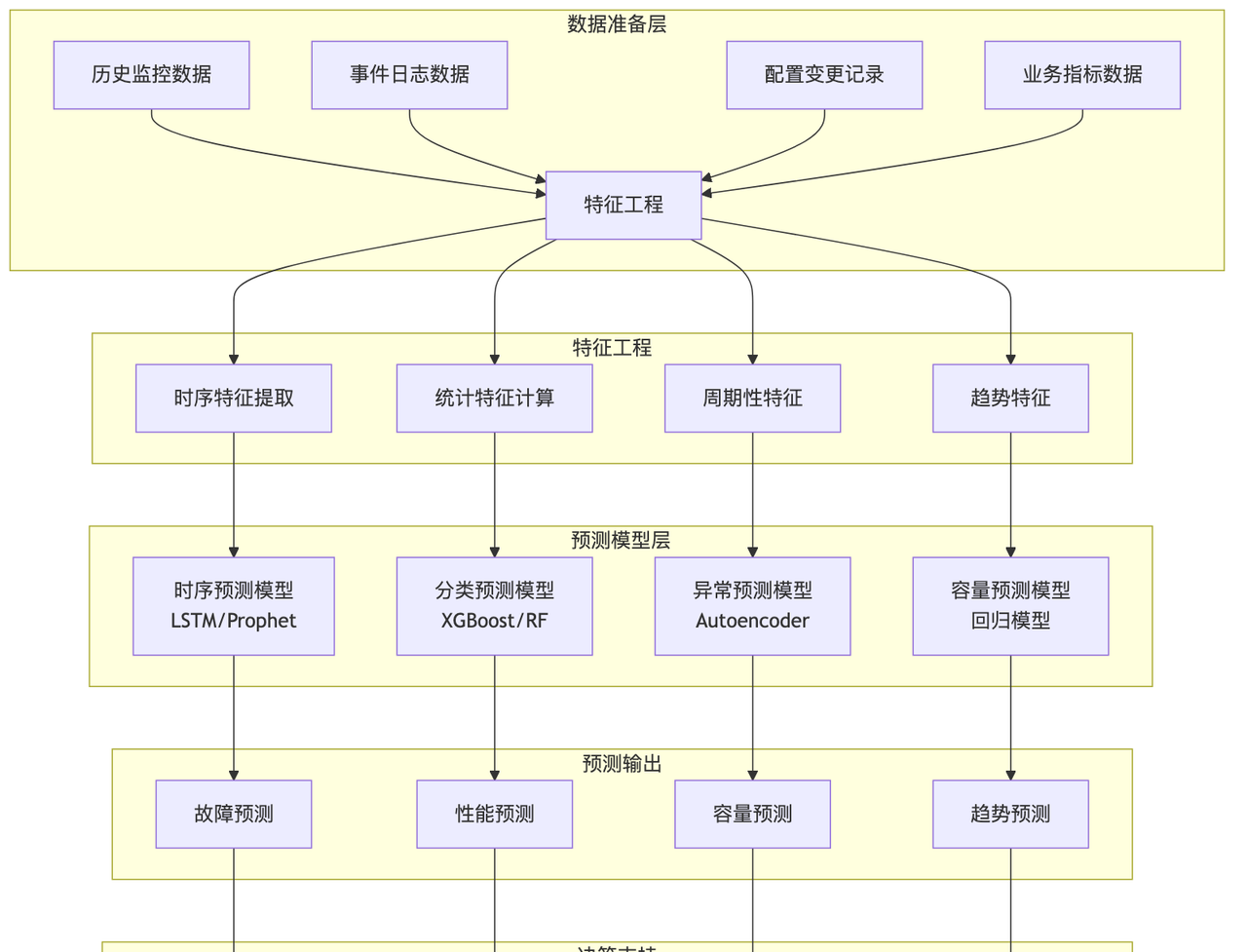
预测性运维实现
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.ensemble import RandomForestRegressor, IsolationForest
from sklearn.metrics import mean_squared_error, mean_absolute_error
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from prophet import Prophet
import warnings
warnings.filterwarnings('ignore')
class PredictiveMaintenanceEngine:
def __init__(self):
self.models = {}
self.scalers = {}
self.feature_columns = []
self.prediction_horizon = 24 # 预测未来24小时
def prepare_time_series_data(self, data, target_column, sequence_length=24):
"""准备时序数据"""
# 确保数据按时间排序
data = data.sort_values('timestamp')
# 特征工程
data['hour'] = pd.to_datetime(data['timestamp']).dt.hour
data['day_of_week'] = pd.to_datetime(data['timestamp']).dt.dayofweek
data['month'] = pd.to_datetime(data['timestamp']).dt.month
# 滚动统计特征
for window in [6, 12, 24]:
data[f'{target_column}_ma_{window}'] = data[target_column].rolling(window).mean()
data[f'{target_column}_std_{window}'] = data[target_column].rolling(window).std()
# 滞后特征
for lag in [1, 6, 12, 24]:
data[f'{target_column}_lag_{lag}'] = data[target_column].shift(lag)
# 差分特征
data[f'{target_column}_diff'] = data[target_column].diff()
data[f'{target_column}_diff_2'] = data[target_column].diff(2)
return data.dropna()
def build_lstm_model(self, input_shape):
"""构建LSTM预测模型"""
model = Sequential([
LSTM(100, return_sequences=True, input_shape=input_shape),
Dropout(0.2),
LSTM(50, return_sequences=True),
Dropout(0.2),
LSTM(25),
Dropout(0.2),
Dense(1)
])
model.compile(
optimizer='adam',
loss='mse',
metrics=['mae']
)
return model
def train_failure_prediction_model(self, training_data):
"""训练故障预测模型"""
# 数据预处理
processed_data = self.prepare_time_series_data(training_data, 'cpu_usage')
# 创建故障标签(基于阈值或历史故障记录)
processed_data['failure_risk'] = self.create_failure_labels(processed_data)
# 特征选择
feature_columns = [col for col in processed_data.columns
if col not in ['timestamp', 'failure_risk']]
X = processed_data[feature_columns].values
y = processed_data['failure_risk'].values
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 创建序列数据
X_sequences, y_sequences = self.create_sequences(X_scaled, y, sequence_length=24)
# 划分训练测试集
split_idx = int(len(X_sequences) * 0.8)
X_train, X_test = X_sequences[:split_idx], X_sequences[split_idx:]
y_train, y_test = y_sequences[:split_idx], y_sequences[split_idx:]
# 训练LSTM模型
lstm_model = self.build_lstm_model((X_train.shape[1], X_train.shape[2]))
history = lstm_model.fit(
X_train, y_train,
epochs=50,
batch_size=32,
validation_data=(X_test, y_test),
verbose=0
)
# 保存模型和预处理器
self.models['failure_prediction'] = lstm_model
self.scalers['failure_prediction'] = scaler
self.feature_columns = feature_columns
# 评估模型
train_pred = lstm_model.predict(X_train)
test_pred = lstm_model.predict(X_test)
train_rmse = np.sqrt(mean_squared_error(y_train, train_pred))
test_rmse = np.sqrt(mean_squared_error(y_test, test_pred))
return {
'model': lstm_model,
'training_history': history.history,
'train_rmse': train_rmse,
'test_rmse': test_rmse,
'feature_importance': self.calculate_feature_importance(X_train, y_train)
}
def create_failure_labels(self, data):
"""创建故障风险标签"""
# 基于多个指标综合判断故障风险
risk_score = 0.0
# CPU使用率风险
cpu_risk = np.where(data['cpu_usage'] > 80, 0.3, 0.0)
# 内存使用率风险
memory_risk = np.where(data['memory_usage'] > 85, 0.3, 0.0)
# 响应时间风险
response_time_risk = np.where(data['response_time'] > 1000, 0.2, 0.0)
# 错误率风险
error_rate_risk = np.where(data['error_rate'] > 0.05, 0.2, 0.0)
# 综合风险评分
risk_score = cpu_risk + memory_risk + response_time_risk + error_rate_risk
# 标准化到0-1范围
return np.clip(risk_score, 0, 1)
def predict_future_metrics(self, current_data, horizon_hours=24):
"""预测未来指标"""
if 'failure_prediction' not in self.models:
raise ValueError("模型未训练,请先调用train_failure_prediction_model")
model = self.models['failure_prediction']
scaler = self.scalers['failure_prediction']
# 预处理当前数据
processed_data = self.prepare_time_series_data(current_data, 'cpu_usage')
# 获取最新的序列数据
recent_data = processed_data[self.feature_columns].tail(24).values
recent_data_scaled = scaler.transform(recent_data)
predictions = []
current_sequence = recent_data_scaled.reshape(1, 24, -1)
# 递归预测
for _ in range(horizon_hours):
next_pred = model.predict(current_sequence)
predictions.append(next_pred[0, 0])
# 更新序列(滚动窗口)
next_features = self.estimate_next_features(
current_sequence[0, -1], next_pred[0, 0]
)
current_sequence = np.roll(current_sequence, -1, axis=1)
current_sequence[0, -1] = next_features
return {
'predictions': predictions,
'timestamps': self.generate_future_timestamps(horizon_hours),
'confidence_intervals': self.calculate_confidence_intervals(predictions)
}
def calculate_confidence_intervals(self, predictions, confidence_level=0.95):
"""计算预测置信区间"""
predictions = np.array(predictions)
# 基于历史预测误差估算不确定性
if hasattr(self, 'historical_errors'):
error_std = np.std(self.historical_errors)
else:
error_std = np.std(predictions) * 0.1 # 默认估算
# 计算置信区间
z_score = 1.96 if confidence_level == 0.95 else 2.58 # 95% or 99%
margin = z_score * error_std
lower_bound = predictions - margin
upper_bound = predictions + margin
return {
'lower_bound': lower_bound.tolist(),
'upper_bound': upper_bound.tolist(),
'confidence_level': confidence_level
}
# 容量预测系统
class CapacityPredictionSystem:
def __init__(self):
self.growth_models = {}
self.seasonality_models = {}
def analyze_growth_patterns(self, usage_data):
"""分析增长模式"""
growth_analysis = {}
for metric in ['cpu_usage', 'memory_usage', 'disk_usage', 'network_io']:
if metric in usage_data.columns:
# 使用Prophet分析趋势和季节性
prophet_data = usage_data[['timestamp', metric]].rename(
columns={'timestamp': 'ds', metric: 'y'}
)
model = Prophet(
yearly_seasonality=True,
weekly_seasonality=True,
daily_seasonality=True,
changepoint_prior_scale=0.05
)
model.fit(prophet_data)
# 预测未来3个月
future = model.make_future_dataframe(periods=90, freq='D')
forecast = model.predict(future)
# 分析增长率
growth_rate = self.calculate_growth_rate(forecast)
# 预测容量耗尽时间
depletion_time = self.predict_capacity_depletion(
forecast, capacity_limit=90 # 90%容量阈值
)
growth_analysis[metric] = {
'growth_rate': growth_rate,
'depletion_time': depletion_time,
'forecast': forecast,
'model': model,
'seasonality_components': self.extract_seasonality(model, forecast)
}
return growth_analysis
def calculate_growth_rate(self, forecast):
"""计算增长率"""
recent_values = forecast['yhat'].tail(30).mean() # 最近30天平均值
historical_values = forecast['yhat'].head(30).mean() # 历史30天平均值
if historical_values > 0:
growth_rate = (recent_values - historical_values) / historical_values
else:
growth_rate = 0
return growth_rate * 100 # 转换为百分比
def predict_capacity_depletion(self, forecast, capacity_limit=90):
"""预测容量耗尽时间"""
future_forecast = forecast[forecast['ds'] > pd.Timestamp.now()]
# 查找首次超过容量限制的时间点
exceeding_capacity = future_forecast[future_forecast['yhat'] > capacity_limit]
if not exceeding_capacity.empty:
depletion_date = exceeding_capacity.iloc[0]['ds']
days_until_depletion = (depletion_date - pd.Timestamp.now()).days
return {
'depletion_date': depletion_date,
'days_until_depletion': days_until_depletion,
'risk_level': self.categorize_depletion_risk(days_until_depletion)
}
else:
return {
'depletion_date': None,
'days_until_depletion': float('inf'),
'risk_level': 'low'
}
def generate_capacity_recommendations(self, growth_analysis):
"""生成容量规划建议"""
recommendations = []
for metric, analysis in growth_analysis.items():
depletion_info = analysis['depletion_time']
growth_rate = analysis['growth_rate']
if depletion_info['days_until_depletion'] < 30:
recommendations.append({
'metric': metric,
'priority# 智能运维AIOps的实施路径:从监控到自愈的技术演进
'level': 'high',
'FormatAlerts' >> beam.Map(format_alert)
'WriteToAlertTopic' >> beam.io.WriteToPubSub(topic='alerts-topic'))
def create_capacity_prediction_pipeline(self):
"""创建容量预测流水线"""
def extract_capacity_features(elements):
"""提取容量相关特征"""
capacity_features = []
for element in elements:
metric_data = json.loads(element)
if metric_data['metric_name'] in ['cpu_usage', 'memory_usage', 'disk_usage']:
capacity_features.append({
'service': metric_data['service_name'],
'metric': metric_data['metric_name'],
'value': metric_data['value'],
'timestamp': metric_data['timestamp']
})
return capacity_features
def predict_capacity(elements):
"""容量预测"""
predictor = CapacityPredictionSystem()
# 按服务分组
grouped_data = {}
for element in elements:
service = element['service']
if service not in grouped_data:
grouped_data[service] = []
grouped_data[service].append(element)
predictions = []
for service, data in grouped_data.items():
if len(data) >= 24: # 至少24个数据点
df = pd.DataFrame(data)
prediction = predictor.analyze_growth_patterns(df)
predictions.append({
'service': service,
'prediction': prediction,
'timestamp': datetime.now().isoformat()
})
return predictions
with beam.Pipeline(options=self.pipeline_options) as pipeline:
(pipeline
| 'ReadMetrics' >> beam.io.ReadFromPubSub(topic='metrics-topic')
| 'WindowIntoHours' >> beam.WindowInto(beam.window.FixedWindows(3600)) # 1小时窗口
| 'ExtractCapacityFeatures' >> beam.FlatMap(extract_capacity_features)
| 'GroupByService' >> beam.GroupByKey()
| 'PredictCapacity' >> beam.FlatMap(predict_capacity)
| 'WriteToCapacityTopic' >> beam.io.WriteToPubSub(topic='capacity-predictions'))自动化修复与自愈系统
自愈系统架构
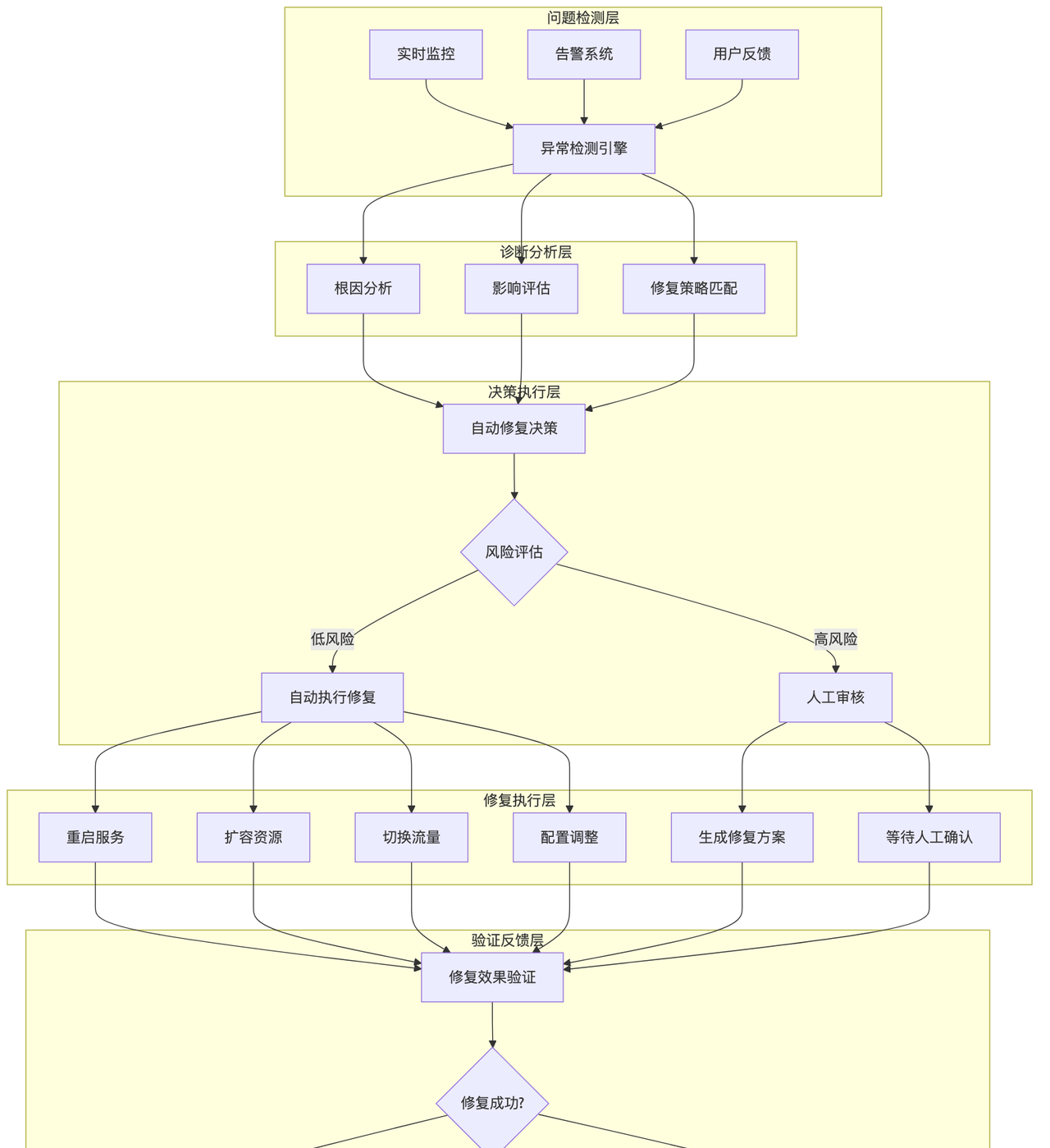
自愈系统核心实现
from abc import ABC, abstractmethod
from dataclasses import dataclass
from enum import Enum
from typing import List, Dict, Any, Optional
import time
import logging
from datetime import datetime, timedelta
class HealingActionType(Enum):
RESTART_SERVICE = "restart_service"
SCALE_OUT = "scale_out"
SCALE_UP = "scale_up"
TRAFFIC_REDIRECT = "traffic_redirect"
CONFIG_ADJUST = "config_adjust"
CIRCUIT_BREAKER = "circuit_breaker"
ROLLBACK_DEPLOYMENT = "rollback_deployment"
CLEAR_CACHE = "clear_cache"
class RiskLevel(Enum):
LOW = 1
MEDIUM = 2
HIGH = 3
CRITICAL = 4
@dataclass
class HealingAction:
action_type: HealingActionType
target_service: str
parameters: Dict[str, Any]
risk_level: RiskLevel
estimated_duration: int # 秒
success_probability: float
rollback_action: Optional['HealingAction'] = None
class HealingExecutor(ABC):
@abstractmethod
def can_handle(self, action: HealingAction) -> bool:
pass
@abstractmethod
def execute(self, action: HealingAction) -> Dict[str, Any]:
pass
@abstractmethod
def rollback(self, action: HealingAction) -> Dict[str, Any]:
pass
class ServiceRestartExecutor(HealingExecutor):
def __init__(self, k8s_client):
self.k8s_client = k8s_client
def can_handle(self, action: HealingAction) -> bool:
return action.action_type == HealingActionType.RESTART_SERVICE
def execute(self, action: HealingAction) -> Dict[str, Any]:
"""执行服务重启"""
try:
service_name = action.target_service
namespace = action.parameters.get('namespace', 'default')
# 记录重启前状态
pre_restart_state = self.k8s_client.get_pod_status(service_name, namespace)
# 执行滚动重启
restart_result = self.k8s_client.restart_deployment(service_name, namespace)
# 等待重启完成
self.wait_for_restart_completion(service_name, namespace)
# 验证服务健康状态
health_check_result = self.verify_service_health(service_name, namespace)
return {
'success': True,
'action_id': f"restart_{service_name}_{int(time.time())}",
'pre_restart_state': pre_restart_state,
'restart_result': restart_result,
'health_check': health_check_result,
'execution_time': datetime.now()
}
except Exception as e:
return {
'success': False,
'error': str(e),
'execution_time': datetime.now()
}
def rollback(self, action: HealingAction) -> Dict[str, Any]:
"""重启操作通常不需要回滚,但可以记录状态"""
return {
'rollback_needed': False,
'reason': '服务重启操作不需要回滚'
}
def wait_for_restart_completion(self, service_name: str, namespace: str, timeout: int = 300):
"""等待重启完成"""
start_time = time.time()
while time.time() - start_time < timeout:
pod_status = self.k8s_client.get_pod_status(service_name, namespace)
if all(pod['status'] == 'Running' and pod['ready'] for pod in pod_status):
return True
time.sleep(10)
raise TimeoutError(f"服务重启超时: {service_name}")
class AutoScalingExecutor(HealingExecutor):
def __init__(self, k8s_client, monitoring_client):
self.k8s_client = k8s_client
self.monitoring_client = monitoring_client
def can_handle(self, action: HealingAction) -> bool:
return action.action_type in [HealingActionType.SCALE_OUT, HealingActionType.SCALE_UP]
def execute(self, action: HealingAction) -> Dict[str, Any]:
"""执行自动扩容"""
try:
service_name = action.target_service
namespace = action.parameters.get('namespace', 'default')
if action.action_type == HealingActionType.SCALE_OUT:
return self.scale_out_pods(service_name, namespace, action.parameters)
else:
return self.scale_up_resources(service_name, namespace, action.parameters)
except Exception as e:
return {
'success': False,
'error': str(e),
'execution_time': datetime.now()
}
def scale_out_pods(self, service_name: str, namespace: str, parameters: Dict) -> Dict:
"""水平扩容(增加Pod数量)"""
current_replicas = self.k8s_client.get_replica_count(service_name, namespace)
target_replicas = parameters.get('target_replicas')
if not target_replicas:
# 智能计算目标副本数
current_load = self.monitoring_client.get_current_load(service_name)
target_replicas = self.calculate_target_replicas(current_replicas, current_load)
# 执行扩容
scale_result = self.k8s_client.scale_deployment(
service_name, namespace, target_replicas
)
# 等待扩容完成
self.wait_for_scaling_completion(service_name, namespace, target_replicas)
return {
'success': True,
'action_type': 'scale_out',
'previous_replicas': current_replicas,
'target_replicas': target_replicas,
'scale_result': scale_result,
'execution_time': datetime.now()
}
def calculate_target_replicas(self, current_replicas: int, current_load: float) -> int:
"""智能计算目标副本数"""
# 基于当前负载和目标负载计算
target_load_per_pod = 0.7 # 目标每个Pod负载70%
if current_load > 0:
required_replicas = int(current_replicas * current_load / target_load_per_pod)
# 限制扩容倍数,避免过度扩容
max_replicas = current_replicas * 3
target_replicas = min(required_replicas, max_replicas)
else:
target_replicas = current_replicas + 1
return max(target_replicas, current_replicas + 1)
class SelfHealingOrchestrator:
def __init__(self):
self.executors = []
self.healing_history = []
self.risk_assessor = RiskAssessor()
self.knowledge_base = HealingKnowledgeBase()
def register_executor(self, executor: HealingExecutor):
"""注册修复执行器"""
self.executors.append(executor)
def handle_incident(self, incident_data: Dict[str, Any]) -> Dict[str, Any]:
"""处理故障事件"""
incident_id = incident_data.get('incident_id')
try:
# 1. 分析故障并生成修复方案
healing_plan = self.generate_healing_plan(incident_data)
if not healing_plan:
return {
'incident_id': incident_id,
'status': 'no_healing_plan',
'message': '未找到适合的自愈方案'
}
# 2. 风险评估
risk_assessment = self.risk_assessor.assess_healing_plan(healing_plan)
# 3. 执行决策
if risk_assessment['overall_risk'] <= RiskLevel.MEDIUM:
# 自动执行
execution_result = self.execute_healing_plan(healing_plan)
return {
'incident_id': incident_id,
'status': 'auto_healed',
'healing_plan': healing_plan,
'execution_result': execution_result,
'risk_assessment': risk_assessment
}
else:
# 需要人工审核
approval_request = self.create_approval_request(healing_plan, risk_assessment)
return {
'incident_id': incident_id,
'status': 'pending_approval',
'healing_plan': healing_plan,
'approval_request': approval_request,
'risk_assessment': risk_assessment
}
except Exception as e:
logging.error(f"处理故障事件失败: {incident_id}, 错误: {str(e)}")
return {
'incident_id': incident_id,
'status': 'error',
'error': str(e)
}
def generate_healing_plan(self, incident_data: Dict[str, Any]) -> List[HealingAction]:
"""生成修复方案"""
service_name = incident_data.get('service_name')
incident_type = incident_data.get('incident_type')
symptoms = incident_data.get('symptoms', {})
# 从知识库查找匹配的修复方案
similar_cases = self.knowledge_base.find_similar_cases(
service_name, incident_type, symptoms
)
healing_actions = []
# 基于相似案例生成修复动作
for case in similar_cases:
if case['success_rate'] > 0.7: # 成功率阈值
action = HealingAction(
action_type=HealingActionType(case['action_type']),
target_service=service_name,
parameters=case['parameters'],
risk_level=RiskLevel(case['risk_level']),
estimated_duration=case['estimated_duration'],
success_probability=case['success_rate']
)
healing_actions.append(action)
# 如果没有历史案例,使用默认策略
if not healing_actions:
healing_actions = self.generate_default_healing_actions(incident_data)
return healing_actions
def execute_healing_plan(self, healing_plan: List[HealingAction]) -> Dict[str, Any]:
"""执行修复方案"""
execution_results = []
overall_success = True
for action in healing_plan:
# 查找合适的执行器
executor = self.find_executor(action)
if not executor:
execution_results.append({
'action': action,
'status': 'failed',
'error': '未找到合适的执行器'
})
overall_success = False
continue
try:
# 执行修复动作
result = executor.execute(action)
execution_results.append({
'action': action,
'status': 'success' if result['success'] else 'failed',
'result': result
})
if not result['success']:
overall_success = False
# 验证修复效果
if result['success']:
verification_result = self.verify_healing_effect(action)
if not verification_result['success']:
# 修复验证失败,执行回滚
rollback_result = executor.rollback(action)
execution_results[-1]['rollback'] = rollback_result
overall_success = False
except Exception as e:
execution_results.append({
'action': action,
'status': 'error',
'error': str(e)
})
overall_success = False
# 记录修复历史
self.record_healing_history(healing_plan, execution_results, overall_success)
return {
'overall_success': overall_success,
'execution_results': execution_results,
'execution_time': datetime.now()
}
def verify_healing_effect(self, action: HealingAction, timeout: int = 300) -> Dict[str, Any]:
"""验证修复效果"""
service_name = action.target_service
start_time = time.time()
# 等待系统稳定
time.sleep(30)
while time.time() - start_time < timeout:
# 检查服务健康状态
health_status = self.check_service_health(service_name)
if health_status['healthy']:
# 检查关键指标是否恢复正常
metrics_status = self.check_key_metrics(service_name)
if metrics_status['normal']:
return {
'success': True,
'health_status': health_status,
'metrics_status': metrics_status,
'verification_time': datetime.now()
}
time.sleep(30)
return {
'success': False,
'reason': '修复效果验证超时',
'health_status': health_status,
'verification_time': datetime.now()
}
class HealingKnowledgeBase:
def __init__(self):
self.cases_database = []
self.pattern_matcher = PatternMatcher()
def find_similar_cases(self, service_name: str, incident_type: str,
symptoms: Dict) -> List[Dict]:
"""查找相似的历史案例"""
similar_cases = []
for case in self.cases_database:
similarity_score = self.calculate_similarity(
case, service_name, incident_type, symptoms
)
if similarity_score > 0.7: # 相似度阈值
case['similarity_score'] = similarity_score
similar_cases.append(case)
# 按相似度排序
return sorted(similar_cases, key=lambda x: x['similarity_score'], reverse=True)
def calculate_similarity(self, case: Dict, service_name: str,
incident_type: str, symptoms: Dict) -> float:
"""计算案例相似度"""
similarity = 0.0
# 服务名称相似性
if case['service_name'] == service_name:
similarity += 0.3
elif case['service_type'] == self.get_service_type(service_name):
similarity += 0.2
# 故障类型相似性
if case['incident_type'] == incident_type:
similarity += 0.3
# 症状相似性
symptom_similarity = self.calculate_symptom_similarity(
case['symptoms'], symptoms
)
similarity += 0.4 * symptom_similarity
return min(1.0, similarity)
def learn_from_execution(self, healing_plan: List[HealingAction],
execution_results: List[Dict], success: bool):
"""从执行结果中学习"""
# 更新知识库中的成功率和参数
for action, result in zip(healing_plan, execution_results):
self.update_action_statistics(action, result['status'] == 'success')
# 如果整体修复失败,分析失败原因
if not success:
failure_analysis = self.analyze_failure_patterns(healing_plan, execution_results)
self.store_failure_patterns(failure_analysis)AIOps平台架构设计
平台整体架构
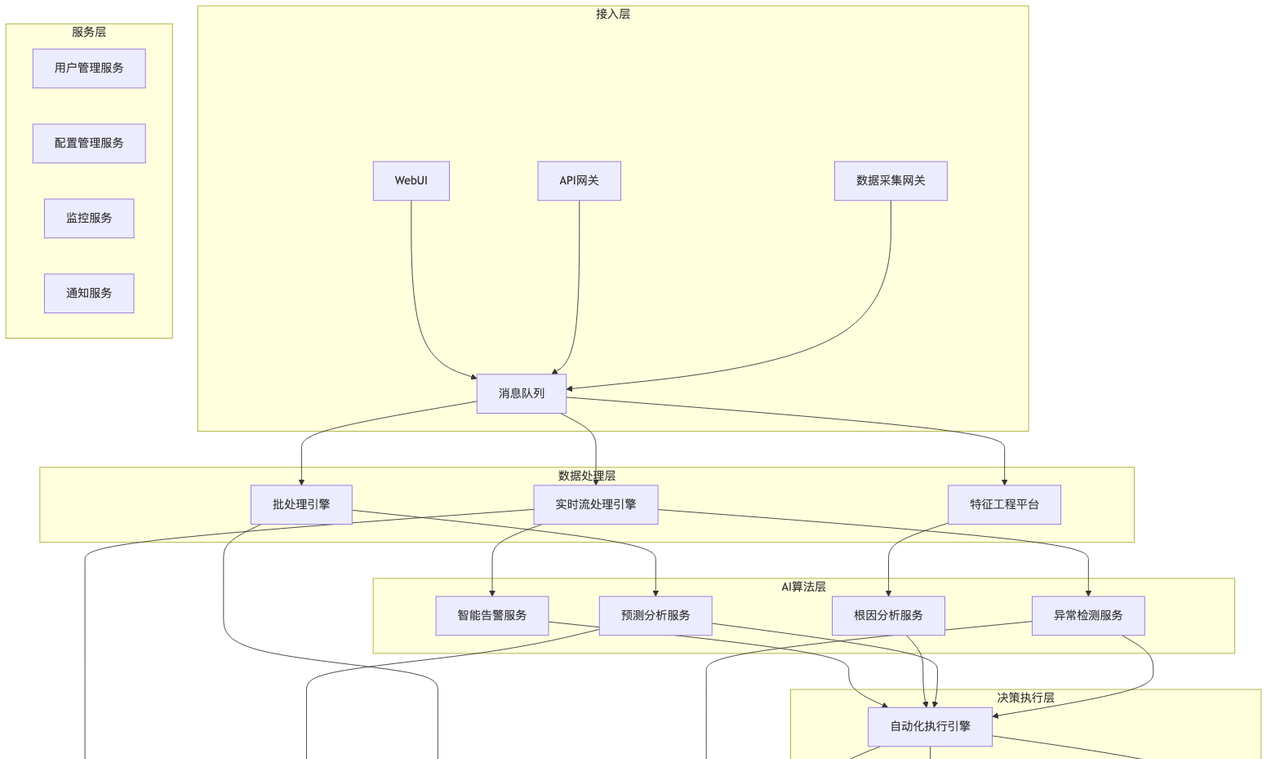
微服务架构实现
from fastapi import FastAPI, HTTPException, Depends
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from typing import List, Dict, Any, Optional
import asyncio
import uvicorn
from datetime import datetime
# 数据模型定义
class MetricData(BaseModel):
service_name: str
metric_name: str
value: float
timestamp: datetime
labels: Dict[str, str] = {}
class AnomalyResult(BaseModel):
service_name: str
metric_name: str
anomaly_score: float
is_anomaly: bool
confidence: float
timestamp: datetime
class HealingRequest(BaseModel):
incident_id: str
service_name: str
incident_type: str
symptoms: Dict[str, Any]
priority: str = "medium"
# 异常检测微服务
class AnomalyDetectionService:
def __init__(self):
self.app = FastAPI(title="AnomalyDetectionService", version="1.0.0")
self.setup_routes()
self.setup_middleware()
self.detector = AnomalyDetectionEngine()
def setup_routes(self):
@self.app.post("/detect", response_model=List[AnomalyResult])
async def detect_anomalies(metrics: List[MetricData]):
"""检测异常"""
try:
results = []
for metric in metrics:
anomaly_result = await self.detect_single_metric(metric)
results.append(anomaly_result)
return results
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@self.app.get("/health")
async def health_check():
return {"status": "healthy", "timestamp": datetime.now()}
@self.app.post("/train")
async def train_model(training_data: List[MetricData]):
"""训练异常检测模型"""
try:
result = await self.train_anomaly_model(training_data)
return {"status": "success", "model_info": result}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
def setup_middleware(self):
self.app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
async def detect_single_metric(self, metric: MetricData) -> AnomalyResult:
"""检测单个指标异常"""
# 异步处理异常检测
loop = asyncio.get_event_loop()
detection_result = await loop.run_in_executor(
None, self.detector.detect_anomaly, metric.dict()
)
return AnomalyResult(
service_name=metric.service_name,
metric_name=metric.metric_name,
anomaly_score=detection_result['anomaly_score'],
is_anomaly=detection_result['is_anomaly'],
confidence=detection_result['confidence'],
timestamp=metric.timestamp
)
async def train_anomaly_model(self, training_data: List[MetricData]):
"""训练异常检测模型"""
loop = asyncio.get_event_loop()
training_result = await loop.run_in_executor(
None, self.detector.train_model, [m.dict() for m in training_data]
)
return training_result
# 自愈服务微服务
class SelfHealingService:
def __init__(self):
self.app = FastAPI(title="SelfHealingService", version="1.0.0")
self.setup_routes()
self.orchestrator = SelfHealingOrchestrator()
def setup_routes(self):
@self.app.post("/heal")
async def trigger_healing(request: HealingRequest):
"""触发自愈流程"""
try:
healing_result = await self.execute_healing(request)
return healing_result
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@self.app.get("/healing-history/{incident_id}")
async def get_healing_history(incident_id: str):
"""获取修复历史"""
history = self.orchestrator.get_healing_history(incident_id)
return history
@self.app.post("/approve-healing/{request_id}")
async def approve_healing(request_id: str, approved: bool):
"""审批修复请求"""
result = await self.process_healing_approval(request_id, approved)
return result
async def execute_healing(self, request: HealingRequest):
"""执行自愈流程"""
loop = asyncio.get_event_loop()
healing_result = await loop.run_in_executor(
None, self.orchestrator.handle_incident, request.dict()
)
return healing_result
# API网关服务
class AIOpsAPIGateway:
def __init__(self):
self.app = FastAPI(title="AIOpsAPIGateway", version="1.0.0")
self.setup_routes()
self.setup_service_discovery()
def setup_routes(self):
@self.app.post("/api/v1/metrics/anomaly-detection")
async def detect_anomalies_proxy(metrics: List[MetricData]):
"""代理异常检测请求"""
anomaly_service_url = await self.get_service_url("anomaly-detection")
async with httpx.AsyncClient() as client:
response = await client.post(
f"{anomaly_service_url}/detect",
json=[m.dict() for m in metrics]
)
return response.json()
@self.app.post("/api/v1/healing/trigger")
async def trigger_healing_proxy(request: HealingRequest):
"""代理自愈请求"""
healing_service_url = await self.get_service_url("self-healing")
async with httpx.AsyncClient() as client:
response = await client.post(
f"{healing_service_url}/heal",
json=request.dict()
)
return response.json()
@self.app.get("/api/v1/dashboard/overview")
async def get_dashboard_overview():
"""获取仪表板概览"""
return await self.aggregate_dashboard_data()
async def aggregate_dashboard_data(self):
"""聚合仪表板数据"""
# 并发获取各种数据
tasks = [
self.get_system_health_metrics(),
self.get_recent_anomalies(),
self.get_healing_statistics(),
self.get_capacity_predictions()
]
results = await asyncio.gather(*tasks)
return {
"system_health": results[0],
"recent_anomalies": results[1],
"healing_stats": results[2],
"capacity_predictions": results[3],
"timestamp": datetime.now()
}
# 数据流处理服务
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
class AIOpsDataPipeline:
def __init__(self):
self.pipeline_options = PipelineOptions([
'--streaming',
'--project=aiops-project',
'--region=us-central1',
'--temp_location=gs://aiops-temp',
'--staging_location=gs://aiops-staging'
])
def create_anomaly_detection_pipeline(self):
"""创建异常检测数据流水线"""
def detect_anomalies(element):
"""异常检测处理函数"""
metric_data = json.loads(element)
# 调用异常检测算法
detector = AnomalyDetectionEngine()
result = detector.detect_anomaly(metric_data)
if result['is_anomaly']:
# 发送到告警系统
return [{
'service': metric_data['service_name'],
'metric': metric_data['metric_name'],
'anomaly_score': result['anomaly_score'],
'timestamp': metric_data['timestamp']
}]
return []
def format_alert(element):
"""格式化告警信息"""
return json.dumps({
'alert_type': 'anomaly_detected',
'service': element['service'],
'metric': element['metric'],
'score': element['anomaly_score'],
'timestamp': element['timestamp']
})
with beam.Pipeline(options=self.pipeline_options) as pipeline:
(pipeline
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(topic='metrics-topic')
| 'DetectAnomalies' >> beam.FlatMap(detect_anomalies)
| 'FormatAlerts' >> beam # 证据类型权重
evidence_weights = {
'anomaly_origin': 0.3,
'causal_analysis': 0.25,
'dependency_impact': 0.2,
'historical_pattern': 0.15,
'correlation_analysis': 0.1
}
# 计算基础得分
for evidence in candidate_info['evidence']:
score += evidence_weights.get(evidence, 0.1)
# 置信度因子
confidence_multiplier = 1.0
evidence_count = len(candidate_info['evidence'])
if evidence_count >= 3:
confidence_multiplier = 1.2
elif evidence_count >= 2:
confidence_multiplier = 1.1
final_score = min(1.0, score * confidence_multiplier)
scored_candidates.append({
'service': service,
'score': final_score,
'evidence': candidate_info['evidence'],
'supporting_factors': candidate_info['supporting_factors'],
'recommendation': self.generate_root_cause_recommendation(service, candidate_info)
})
# 按得分排序
return sorted(scored_candidates, key=lambda x: x['score'], reverse=True)
def generate_root_cause_recommendation(self, service, candidate_info):
"""生成根因处理建议"""
recommendations = []
# 基于证据类型生成建议
if 'anomaly_origin' in candidate_info['evidence']:
recommendations.append(f"优先检查 {service} 服务的健康状态和资源使用情况")
if 'dependency_impact' in candidate_info['evidence']:
recommendations.append(f"检查 {service} 的下游依赖服务状态")
if 'historical_pattern' in candidate_info['evidence']:
recommendations.append(f"参考历史同类问题的解决方案")
# 通用建议
recommendations.extend([
f"检查 {service} 的日志和错误信息",
f"验证 {service} 的配置和部署状态",
f"监控 {service} 的性能指标变化"
])
return recommendations实施路径与最佳实践
分阶段实施策略
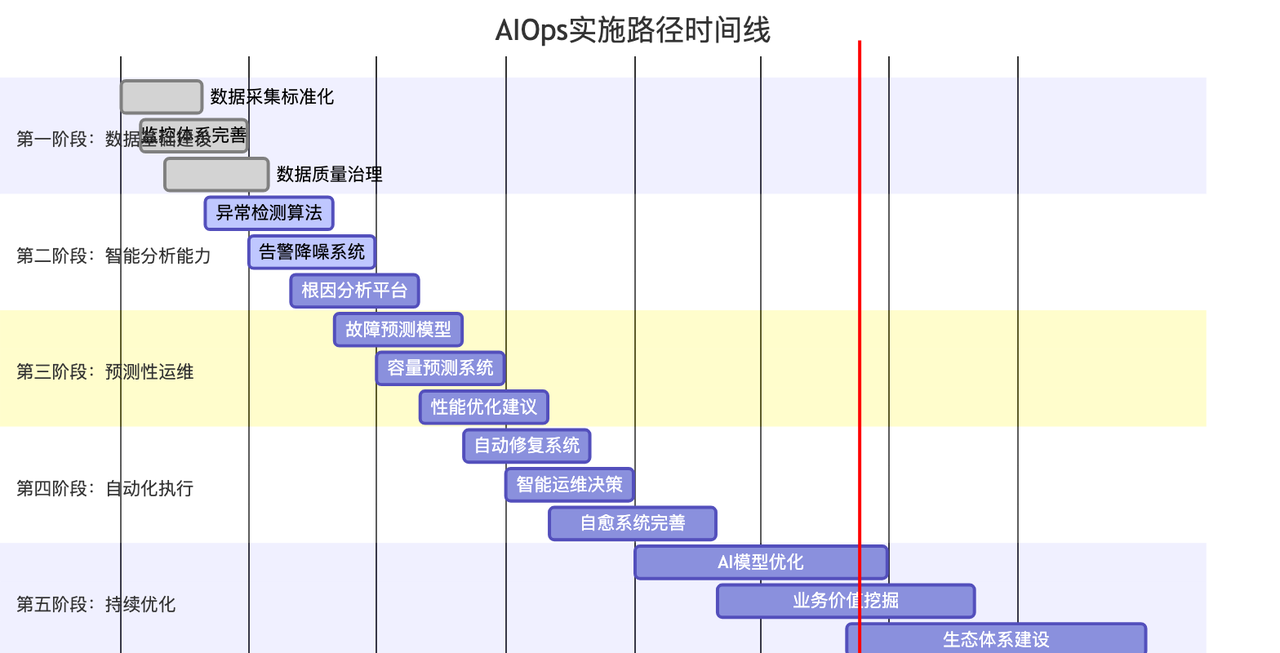
组织架构与团队建设
1. AIOps团队结构

2. 技能发展计划
class AIOpsSkillDevelopmentPlan:
def __init__(self):
self.skill_matrix = {
'data_engineering': {
'required_skills': [
'数据建模', 'ETL/ELT', '实时流处理', '数据质量管理',
'Kafka', 'Flink', 'Spark', 'Airflow'
],
'training_plan': self.create_data_engineering_plan()
},
'machine_learning': {
'required_skills': [
'监督学习', '无监督学习', '深度学习', '时序分析',
'Python', 'TensorFlow', 'PyTorch', 'Scikit-learn'
],
'training_plan': self.create_ml_training_plan()
},
'platform_engineering': {
'required_skills': [
'微服务架构', '云原生技术', 'Kubernetes', 'Docker',
'分布式系统', 'API设计', '系统监控'
],
'training_plan': self.create_platform_training_plan()
},
'domain_expertise': {
'required_skills': [
'IT运维实践', '故障排除', '容量规划', '性能调优',
'ITIL', '监控工具', '自动化脚本'
],
'training_plan': self.create_domain_training_plan()
}
}
def create_data_engineering_plan(self):
return {
'beginner': [
{'course': 'SQL基础与数据建模', 'duration': '2周'},
{'course': 'Python数据处理', 'duration': '3周'},
{'course': 'Kafka消息队列', 'duration': '2周'}
],
'intermediate': [
{'course': 'Apache Flink流处理', 'duration': '4周'},
{'course': '数据质量管理实践', 'duration': '3周'},
{'course': 'Airflow工作流调度', 'duration': '2周'}
],
'advanced': [
{'course': '大数据架构设计', 'duration': '6周'},
{'course': '实时数据处理优化', 'duration': '4周'},
{'course': '数据治理实践', 'duration': '3周'}
]
}
def assess_team_skills(self, team_members):
"""评估团队技能水平"""
skill_assessment = {}
for member in team_members:
member_skills = {}
for skill_area, skills_info in self.skill_matrix.items():
required_skills = skills_info['required_skills']
member_proficiency = []
for skill in required_skills:
# 通过测试、项目经验等评估技能水平
proficiency_score = self.evaluate_skill_proficiency(
member, skill
)
member_proficiency.append({
'skill': skill,
'score': proficiency_score,
'level': self.categorize_proficiency(proficiency_score)
})
member_skills[skill_area] = {
'overall_score': np.mean([s['score'] for s in member_proficiency]),
'skill_details': member_proficiency
}
skill_assessment[member['name']] = member_skills
return skill_assessment
def generate_training_recommendations(self, skill_assessment):
"""生成培训建议"""
recommendations = {}
for member_name, skills in skill_assessment.items():
member_recommendations = []
for skill_area, skill_info in skills.items():
overall_score = skill_info['overall_score']
# 根据技能水平推荐培训
if overall_score < 3.0: # 初级水平
training_level = 'beginner'
elif overall_score < 7.0: # 中级水平
training_level = 'intermediate'
else: # 高级水平
training_level = 'advanced'
training_plan = self.skill_matrix[skill_area]['training_plan'][training_level]
# 识别薄弱技能
weak_skills = [
s for s in skill_info['skill_details']
if s['score'] < overall_score - 1.0
]
member_recommendations.append({
'skill_area': skill_area,
'current_level': training_level,
'training_courses': training_plan,
'focus_skills': [s['skill'] for s in weak_skills],
'priority': self.calculate_training_priority(skill_area, overall_score)
})
recommendations[member_name] = member_recommendations
return recommendations技术选型指南
1. 核心技术栈对比
| 组件类型 | 选项A | 选项B | 选项C | 推荐 | 理由 |
|---|---|---|---|---|---|
| 消息队列 | Apache Kafka | RabbitMQ | Apache Pulsar | Kafka | 高吞吐量、生态丰富 |
| 流处理 | Apache Flink | Apache Storm | Kafka Streams | Flink | 低延迟、容错性强 |
| 机器学习 | TensorFlow | PyTorch | Scikit-learn | PyTorch | 研究友好、动态图 |
| 时序数据库 | InfluxDB | TimescaleDB | Prometheus | TimescaleDB | SQL兼容、扩展性好 |
| 容器编排 | Kubernetes | Docker Swarm | Nomad | Kubernetes | 事实标准、生态完整 |
| 监控工具 | Prometheus | Datadog | New Relic | Prometheus | 开源、灵活配置 |
2. 架构决策记录 (ADR)
# ADR-001: 选择微服务架构实现AIOps平台
## 状态
已接受
## 背景
需要构建一个可扩展、高可用的AIOps平台,支持多种AI算法和自动化流程。
## 决策
采用微服务架构,将不同功能模块拆分为独立的服务。
## 后果
### 优势
- 技术栈多样性:不同服务可以选择最适合的技术
- 独立部署:服务可以独立发布和扩展
- 故障隔离:单个服务故障不会影响整个系统
- 团队独立:不同团队可以并行开发
### 劣势
- 系统复杂性增加
- 网络通信开销
- 分布式系统的一致性挑战
- 运维复杂度提升
## 缓解措施
- 使用Service Mesh管理服务通信
- 实施分布式追踪监控服务调用
- 建立统一的日志和监控体系
- 采用GitOps进行统一部署管理实施检查清单
阶段一:基础设施准备 (1-3个月)
数据收集标准化
定义统一的数据模型和格式
部署数据采集Agent到所有节点
建立数据质量监控机制
配置数据备份和恢复策略
监控体系建设
部署Prometheus监控系统
配置Grafana可视化仪表板
建立告警规则和通知渠道
实施分布式追踪系统
数据存储架构
部署时序数据库集群
配置数据分片和副本策略
建立数据归档和清理机制
实施数据安全和访问控制
阶段二:AI能力建设 (3-6个月)
异常检测系统
开发基础异常检测算法
训练服务特定的检测模型
实施实时异常检测流水线
建立模型评估和更新机制
智能告警系统
实现告警聚合和降噪算法
开发告警关联分析功能
建立告警优先级评分系统
配置智能告警路由规则
根因分析平台
构建服务依赖关系图
开发因果关系分析算法
实现知识图谱构建
建立历史案例学习机制
阶段三:预测性运维 (6-9个月)
故障预测模型
收集历史故障数据并标注
训练多种预测算法模型
实施模型A/B测试框架
建立预测准确性评估体系
容量预测系统
分析资源使用增长趋势
开发容量预测算法
实现自动化容量规划
建立容量告警和建议系统
阶段四:自动化执行 (9-12个月)
自动修复系统
定义标准修复动作库
实现风险评估机制
开发审批工作流
建立修复效果验证系统
智能运维决策
构建决策树和规则引擎
实现多目标优化算法
建立决策历史追踪
开发决策效果评估系统
案例研究与效果评估
大型互联网公司案例
公司背景:某知名电商平台,日活用户超过1亿,拥有3000+微服务实例。
实施前挑战: – 告警数量每日超过10万条,90%为噪音告警 – 故障平均发现时间:25分钟 – 故障平均修复时间:180分钟 – 运维人员疲于应对告警风暴,无法专注于价值创造
AIOps解决方案:
# 电商平台AIOps实施案例
class EcommerceAIOpsCase:
def __init__(self):
self.metrics_before = {
'daily_alerts': 100000,
'noise_ratio': 0.90,
'mttr_minutes': 180,
'mttd_minutes': 25,
'false_positive_rate': 0.85,
'ops_efficiency_score': 3.2
}
self.implementation_phases = {
'phase1': self.implement_intelligent_alerting(),
'phase2': self.implement_anomaly_detection(),
'phase3': self.implement_predictive_maintenance(),
'phase4': self.implement_auto_healing()
}
def implement_intelligent_alerting(self):
"""第一阶段:智能告警系统"""
return {
'duration': '2个月',
'key_technologies': [
'基于机器学习的告警聚合算法',
'时间序列相关性分析',
'历史模式匹配',
'业务影响评估模型'
],
'implementation_details': {
'alert_correlation': {
'algorithm': 'DBSCAN聚类 + 时间窗口分析',
'time_window': '5分钟',
'similarity_threshold': 0.8
},
'noise_reduction': {
'ml_model': 'Random Forest',
'features': ['频率', '持续时间', '历史解决率', '业务影响'],
'accuracy': 0.92
},
'priority_scoring': {
'business_impact_weight': 0.4,
'technical_severity_weight': 0.3,
'frequency_weight': 0.2,
'user_feedback_weight': 0.1
}
},
'results': {
'noise_reduction': '从90%降至15%',
'alert_volume_reduction': '85%',
'response_time_improvement': '60%'
}
}
def implement_anomaly_detection(self):
"""第二阶段:异常检测系统"""
return {
'duration': '3个月',
'key_technologies': [
'Isolation Forest异常检测',
'LSTM时序预测模型',
'多维度异常关联分析',
'自适应阈值算法'
],
'implementation_details': {
'metrics_coverage': [
'CPU使用率', '内存使用率', '响应时间', '错误率',
'吞吐量', '连接数', '队列长度', 'GC时间'
],
'detection_algorithms': {
'statistical': 'Z-score + IQR',
'ml_based': 'Isolation Forest + One-Class SVM',
'time_series': 'Prophet + LSTM',
'ensemble': '加权投票机制'
},
'real_time_processing': {
'processing_latency': '< 30秒',
'throughput': '100万指标/分钟',
'availability': '99.9%'
}
},
'results': {
'detection_accuracy': '提升至94%',
'false_positive_rate': '从85%降至8%',
'early_detection': '提前20分钟发现问题'
}
}
def calculate_roi(self):
"""计算投资回报率"""
implementation_cost = {
'platform_development': 500_000, # 平台开发成本
'infrastructure': 200_000, # 基础设施成本
'training': 100_000, # 培训成本
'maintenance_annual': 150_000 # 年维护成本
}
total_investment = (
implementation_cost['platform_development'] +
implementation_cost['infrastructure'] +
implementation_cost['training'] +
implementation_cost['maintenance_annual']
)
annual_savings = {
'reduced_downtime': 2_000_000, # 减少故障时间节省
'ops_efficiency': 800_000, # 运维效率提升节省
'automated_tasks': 600_000, # 自动化任务节省
'early_detection': 400_000 # 提前发现问题节省
}
total_annual_savings = sum(annual_savings.values())
roi_calculation = {
'total_investment': total_investment,
'annual_savings': total_annual_savings,
'payback_period_months': round(total_investment / (total_annual_savings / 12), 1),
'roi_3_years': round(((total_annual_savings * 3 - total_investment) / total_investment) * 100, 1)
}
return roi_calculation
# 金融服务公司案例
class FinancialServicesAIOpsCase:
def __init__(self):
self.compliance_requirements = [
'SOX合规性监控',
'PCI DSS数据安全',
'实时风险监控',
'审计追踪完整性'
]
self.critical_metrics = {
'transaction_latency': {'sla': '< 100ms', 'current': '150ms'},
'system_availability': {'sla': '99.99%', 'current': '99.85%'},
'security_incidents': {'target': '< 5/month', 'current': '12/month'},
'compliance_violations': {'target': '0', 'current': '3/quarter'}
}
def implement_compliance_monitoring(self):
"""实施合规监控"""
return {
'automated_compliance_checks': {
'real_time_monitoring': '24/7连续监控',
'policy_enforcement': '自动化策略执行',
'audit_trail': '完整审计日志',
'reporting': '自动化合规报告生成'
},
'risk_assessment': {
'real_time_scoring': '实时风险评分',
'predictive_alerts': '预测性风险告警',
'impact_analysis': '影响范围分析',
'mitigation_recommendations': '自动生成缓解建议'
},
'results': {
'compliance_violations': '减少90%',
'audit_preparation_time': '从2周缩短至2天',
'regulatory_response_time': '提升80%'
}
}
# 效果评估框架
class AIOpsEffectivenessEvaluator:
def __init__(self):
self.evaluation_metrics = {
'operational_efficiency': [
'MTTR (Mean Time To Recovery)',
'MTTD (Mean Time To Detection)',
'MTBF (Mean Time Between Failures)',
'告警噪音率',
'自动化率'
],
'business_impact': [
'系统可用性',
'用户体验分数',
'业务连续性',
'成本节约',
'ROI'
],
'technical_performance': [
'预测准确性',
'异常检测精度',
'处理延迟',
'系统吞吐量',
'资源利用率'
]
}
def create_evaluation_dashboard(self):
"""创建效果评估仪表板"""
dashboard_config = {
'kpi_overview': {
'widgets': [
{
'type': 'metric_card',
'title': 'MTTR改善',
'metric': 'mttr_improvement_percentage',
'target': 50,
'current': 73
},
{
'type': 'metric_card',
'title': '告警降噪',
'metric': 'noise_reduction_percentage',
'target': 80,
'current': 85
}
]
},
'trend_analysis': {
'widgets': [
{
'type': 'line_chart',
'title': '故障恢复时间趋势',
'metrics': ['mttr_before', 'mttr_after'],
'time_range': '6months'
}
]
},
'roi_analysis': {
'widgets': [
{
'type': 'waterfall_chart',
'title': 'ROI分解分析',
'categories': ['投资成本', '运维节约', '故障减少', '效率提升']
}
]
}
}
return dashboard_config
def generate_effectiveness_report(self, before_metrics, after_metrics):
"""生成效果评估报告"""
improvements = {}
for metric, before_value in before_metrics.items():
if metric in after_metrics:
after_value = after_metrics[metric]
if metric in ['mttr', 'mttd', 'alert_volume', 'false_positive_rate']:
# 越低越好的指标
improvement = (before_value - after_value) / before_value * 100
else:
# 越高越好的指标
improvement = (after_value - before_value) / before_value * 100
improvements[metric] = {
'before': before_value,
'after': after_value,
'improvement_percentage': round(improvement, 1),
'status': 'improved' if improvement > 0 else 'declined'
}
# 计算综合评分
overall_score = self.calculate_overall_score(improvements)
report = {
'summary': {
'overall_score': overall_score,
'total_metrics_evaluated': len(improvements),
'improved_metrics': len([m for m in improvements.values() if m['status'] == 'improved']),
'evaluation_period': '6个月'
},
'detailed_improvements': improvements,
'recommendations': self.generate_improvement_recommendations(improvements)
}
return report制造业案例研究
行业特点: – 设备密集型环境 – 高可靠性要求 – 预测性维护需求强烈 – 安全要求严格
AIOps应用场景: 1. 设备故障预测:通过振动、温度、压力等传感器数据预测设备故障 2. 生产线优化:实时监控生产线效率,智能调度优化 3. 质量控制:基于历史数据预测产品质量问题 4. 能耗优化:智能调节设备运行参数,降低能耗
实施效果: – 设备故障预测准确率:87% – 计划外停机时间:减少65% – 维护成本:降低40% – 生产效率:提升15%
挑战与解决方案
技术挑战
1. 数据质量问题
class DataQualityChallenge:
def __init__(self):
self.common_issues = {
'missing_data': '数据缺失导致模型训练困难',
'data_drift': '数据分布变化影响模型性能',
'inconsistent_format': '数据格式不一致',
'real_time_requirements': '实时数据处理要求高'
}
def implement_solutions(self):
return {
'missing_data_handling': {
'interpolation': '时序插值算法',
'model_based': '基于模型的数据补全',
'multiple_imputation': '多重插值技术',
'domain_knowledge': '结合业务知识的补全策略'
},
'data_drift_detection': {
'statistical_tests': 'KS检验、卡方检验',
'ml_based': '基于ML的分布变化检测',
'continuous_monitoring': '持续监控数据分布',
'adaptive_models': '自适应模型更新机制'
},
'data_standardization': {
'schema_registry': '统一数据模式注册中心',
'data_validation': '实时数据验证管道',
'transformation_engine': '自动化数据转换引擎',
'quality_gates': '数据质量检查点'
}
}2. 模型可解释性
AI黑盒问题是AIOps实施中的关键挑战,特别是在金融、医疗等严格监管的行业。
class ModelExplainabilityChallenge:
def __init__(self):
'priority': 'critical',
'action': f'立即扩容{metric}资源',
'details': f'预计{depletion_info["days_until_depletion"]}天后达到容量限制',
'suggested_increase': self.calculate_capacity_increase(growth_rate, 90)
})
elif depletion_info['days_until_depletion'] < 90:
recommendations.append({
'metric': metric,
'priority': 'high',
'action': f'计划扩容{metric}资源',
'details': f'预计{depletion_info["days_until_depletion"]}天后达到容量限制',
'suggested_increase': self.calculate_capacity_increase(growth_rate, 60)
})
elif growth_rate > 20: # 高增长率
recommendations.append({
'metric': metric,
'priority': 'medium',
'action': f'监控{metric}增长趋势',
'details': f'当前增长率{growth_rate:.1f}%较高,需持续已关注',
'suggested_increase': self.calculate_capacity_increase(growth_rate, 30)
})
return recommendations
def calculate_capacity_increase(self, growth_rate, safety_days):
"""计算建议的容量增加量"""
# 基于增长率和安全天数计算需要增加的容量
daily_growth = growth_rate / 365 # 日增长率
safety_buffer = daily_growth * safety_days # 安全缓冲
recommended_increase = max(20, safety_buffer * 1.5) # 至少增加20%
return f"{recommended_increase:.1f}%"class ModelExplainabilityFramework:
def __init__(self):
self.explainability_methods = {
'local_explanations': ['LIME', 'SHAP', 'Anchors'],
'global_explanations': ['Feature Importance', 'Partial Dependence', 'Model Agnostic'],
'model_specific': ['Decision Trees', 'Linear Models', 'Rule-based Systems']
}
def implement_explainable_ai(self):
"""实施可解释AI框架"""
return {
'shap_integration': {
'description': 'SHAP值解释每个特征对预测的贡献',
'implementation': '''
import shap
class ExplainableAnomalyDetector:
def __init__(self, model):
self.model = model
self.explainer = shap.Explainer(model)
def explain_prediction(self, instance):
shap_values = self.explainer(instance)
return {
'prediction': self.model.predict(instance)[0],
'feature_contributions': dict(zip(
instance.columns,
shap_values.values[0]
)),
'base_value': shap_values.base_values[0],
'explanation_text': self.generate_explanation_text(shap_values)
}
def generate_explanation_text(self, shap_values):
"""生成人类可读的解释文本"""
feature_impacts = []
for feature, value in zip(shap_values.feature_names, shap_values.values[0]):
if abs(value) > 0.1: # 只已关注重要特征
direction = "增加" if value > 0 else "降低"
feature_impacts.append(f"{feature}{direction}了异常概率{abs(value):.2f}")
return f"主要影响因素: {'; '.join(feature_impacts)}"
'''
},
'rule_extraction': {
'description': '从复杂模型中提取可理解的规则',
'methods': [
'决策树近似',
'线性模型替代',
'规则归纳算法'
]
},
'counterfactual_explanations': {
'description': '解释"如果...会怎样"的场景',
'use_cases': [
'故障预防建议',
'性能优化方案',
'容量规划指导'
]
}
}3. 模型性能衰减
class ModelPerformanceMonitoring:
def __init__(self):
self.monitoring_metrics = [
'accuracy_drift',
'prediction_distribution_shift',
'feature_importance_change',
'prediction_confidence_decline'
]
def implement_continuous_monitoring(self):
"""实施持续模型监控"""
return {
'performance_tracking': {
'metrics_collection': '''
class ModelPerformanceTracker:
def __init__(self):
self.baseline_metrics = {}
self.current_metrics = {}
self.performance_history = []
def track_model_performance(self, model, test_data, predictions):
"""追踪模型性能"""
current_performance = {
'accuracy': self.calculate_accuracy(test_data, predictions),
'precision': self.calculate_precision(test_data, predictions),
'recall': self.calculate_recall(test_data, predictions),
'f1_score': self.calculate_f1(test_data, predictions),
'timestamp': datetime.now()
}
# 检测性能衰减
if self.baseline_metrics:
degradation = self.detect_performance_degradation(
self.baseline_metrics, current_performance
)
if degradation['requires_retraining']:
self.trigger_model_retraining(degradation)
self.performance_history.append(current_performance)
return current_performance
def detect_performance_degradation(self, baseline, current):
"""检测性能衰减"""
degradation_threshold = 0.05 # 5%性能下降阈值
accuracy_drop = baseline['accuracy'] - current['accuracy']
return {
'accuracy_degradation': accuracy_drop,
'requires_retraining': accuracy_drop > degradation_threshold,
'severity': 'high' if accuracy_drop > 0.1 else 'medium' if accuracy_drop > 0.05 else 'low'
}
'''
},
'automated_retraining': {
'trigger_conditions': [
'性能指标下降超过阈值',
'数据分布发生显著变化',
'新的标注数据达到一定量',
'定期重训练周期到达'
],
'retraining_pipeline': [
'数据质量检查',
'特征工程更新',
'模型架构优化',
'超参数调优',
'A/B测试验证'
]
}
}组织挑战
1. 技能差距

2. 文化变革管理
class CultureChangeManagement:
def __init__(self):
self.change_challenges = {
'resistance_to_automation': '担心被自动化替代',
'trust_in_ai_decisions': '对AI决策的信任度不足',
'blame_culture': '出错时的责任归属问题',
'learning_curve': '新技术学习曲线陡峭'
}
def implement_change_strategy(self):
"""实施变革管理策略"""
return {
'communication_strategy': {
'transparency': '透明沟通AIOps的目标和价值',
'success_stories': '分享早期成功案例',
'regular_updates': '定期更新实施进展',
'feedback_loops': '建立双向反馈机制'
},
'training_and_development': {
'skill_assessment': '评估现有技能水平',
'personalized_learning': '个性化学习路径',
'hands_on_practice': '实际项目练习',
'certification_programs': '技能认证计划'
},
'incentive_alignment': {
'kpi_adjustment': '调整绩效考核指标',
'innovation_rewards': '创新激励机制',
'career_development': '职业发展路径',
'recognition_programs': '成就认可计划'
},
'gradual_transition': {
'pilot_projects': '小规模试点项目',
'phased_rollout': '分阶段推广',
'safety_nets': '保留人工干预机制',
'rollback_plans': '回滚计划和应急预案'
}
}
def measure_culture_change(self):
"""衡量文化变革效果"""
return {
'survey_metrics': [
'AI接受度评分',
'自动化信任度',
'学习意愿指数',
'创新参与度'
],
'behavioral_indicators': [
'主动使用AI工具频率',
'提出改进建议数量',
'跨团队协作项目',
'知识分享活动参与'
],
'business_outcomes': [
'员工满意度',
'人才保留率',
'创新项目数量',
'客户满意度提升'
]
}伦理与合规挑战
1. 算法偏见和公平性
class AlgorithmicFairnessFramework:
def __init__(self):
self.fairness_metrics = [
'demographic_parity',
'equalized_odds',
'calibration',
'individual_fairness'
]
def implement_fairness_monitoring(self):
"""实施算法公平性监控"""
return {
'bias_detection': {
'data_bias_analysis': '训练数据偏见分析',
'model_bias_testing': '模型输出偏见测试',
'outcome_disparity_monitoring': '结果差异监控',
'feedback_loop_bias': '反馈循环偏见检测'
},
'mitigation_strategies': {
'data_augmentation': '数据增强平衡',
'algorithmic_debiasing': '算法去偏技术',
'post_processing_adjustment': '后处理公平性调整',
'human_oversight': '人工监督机制'
},
'governance_framework': {
'ethics_committee': '算法伦理委员会',
'bias_auditing': '定期偏见审计',
'transparency_reporting': '透明度报告',
'stakeholder_engagement': '利益相关者参与'
}
}2. 数据隐私保护
class PrivacyPreservingAIOps:
def __init__(self):
self.privacy_technologies = [
'differential_privacy',
'federated_learning',
'homomorphic_encryption',
'secure_multiparty_computation'
]
def implement_privacy_protection(self):
"""实施隐私保护机制"""
return {
'differential_privacy': {
'description': '在数据查询中添加数学噪声保护隐私',
'implementation': '''
import numpy as np
class DifferentialPrivacyProtector:
def __init__(self, epsilon=1.0):
self.epsilon = epsilon # 隐私预算
def add_laplace_noise(self, true_value, sensitivity):
"""添加拉普拉斯噪声"""
scale = sensitivity / self.epsilon
noise = np.random.laplace(0, scale)
return true_value + noise
def private_mean_calculation(self, data, bounds):
"""隐私保护的均值计算"""
clipped_data = np.clip(data, bounds[0], bounds[1])
true_mean = np.mean(clipped_data)
sensitivity = (bounds[1] - bounds[0]) / len(data)
return self.add_laplace_noise(true_mean, sensitivity)
'''
},
'federated_learning': {
'description': '分布式训练,数据不离开本地',
'benefits': [
'数据隐私保护',
'降低数据传输成本',
'符合监管要求',
'利用更多数据源'
]
},
'data_minimization': {
'principles': [
'只收集必要数据',
'限制数据保留期',
'实施数据匿名化',
'定期数据清理'
]
}
}未来发展趋势
技术发展方向
1. 认知计算与自主运维
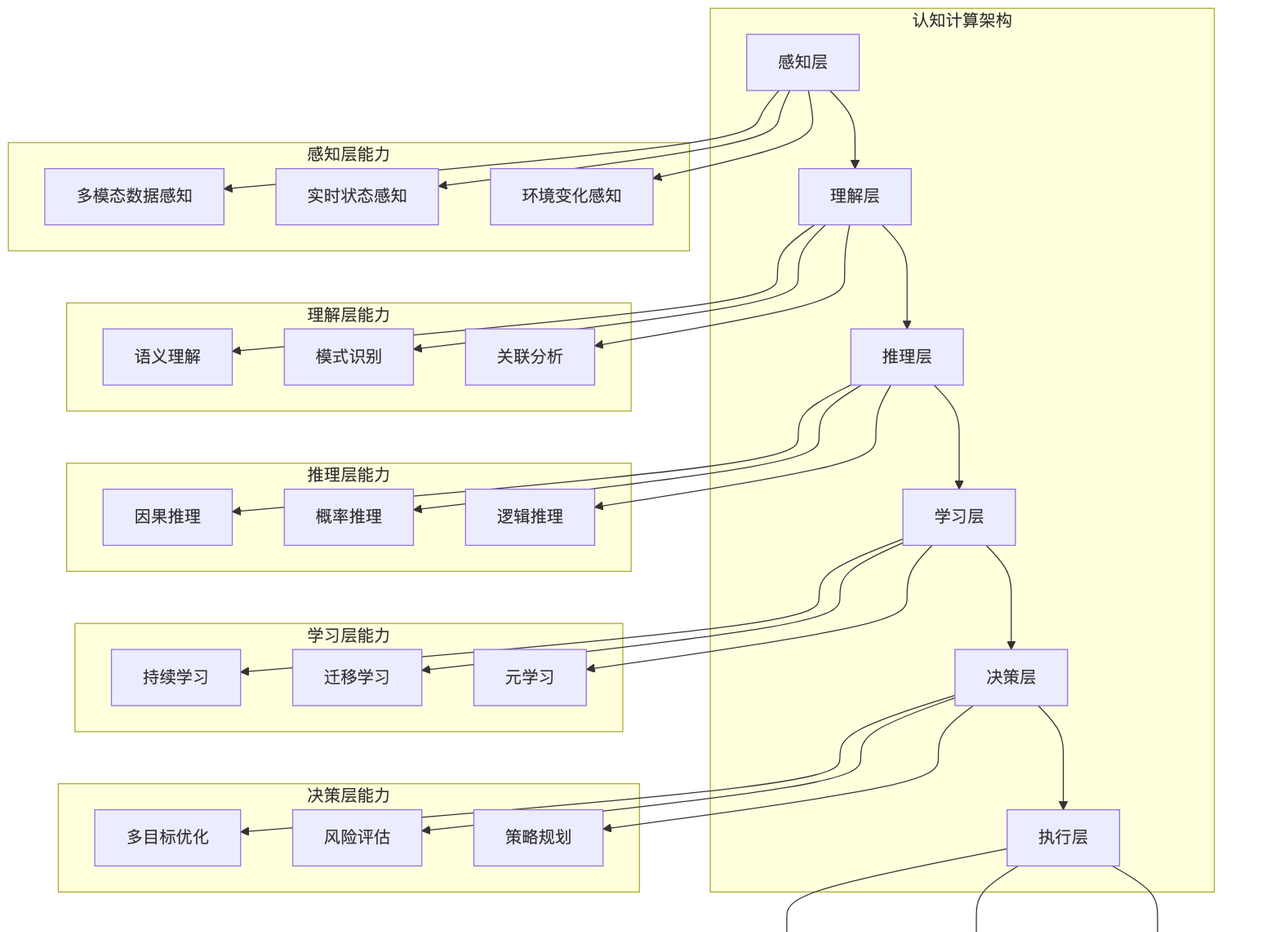
2. 大语言模型在AIOps中的应用
class LLMPoweredAIOps:
def __init__(self):
self.llm_applications = {
'intelligent_troubleshooting': '智能故障排除',
'automated_documentation': '自动化文档生成',
'natural_language_queries': '自然语言查询',
'code_generation': '运维代码生成'
}
def implement_llm_troubleshooting(self):
"""实施LLM驱动的故障排除"""
return {
'conversational_interface': {
'description': '与运维人员进行自然语言对话',
'capabilities': [
'理解问题描述',
'提供排除步骤',
'解释技术概念',
'生成解决方案'
],
'example_interaction': '''
用户: "订单服务响应很慢,用户反馈页面加载超过10秒"
AI助手: "我来帮您诊断订单服务的性能问题。首先让我检查一下相关指标:
1. 当前订单服务响应时间: 8.5秒 (正常< 2秒)
2. CPU使用率: 85% (接近饱和)
3. 数据库连接池: 95%使用率
4. 缓存命中率: 23% (正常> 80%)
根据这些指标,我发现了几个问题:
- 缓存命中率异常低,可能是缓存失效或配置问题
- 数据库连接池接近饱和,可能存在慢查询
- CPU使用率过高,可能有性能瓶颈
建议的排查步骤:
1. 检查Redis缓存服务状态
2. 分析最近的慢查询日志
3. 查看是否有大量并发请求
您希望我先从哪个方面开始排查?"
'''
},
'automated_runbook_generation': {
'description': '自动生成运维手册',
'process': [
'分析历史故障处理记录',
'提取成功的解决模式',
'生成标准化处理流程',
'持续更新和优化'
]
}
}
def implement_code_generation(self):
"""实施运维代码生成"""
return {
'monitoring_script_generation': {
'input': '自然语言描述的监控需求',
'output': '可执行的监控脚本',
'example': '''
需求: "监控所有Web服务器的CPU使用率,当超过80%时发送告警"
生成的脚本:
#!/bin/bash
# 自动生成的CPU监控脚本
THRESHOLD=80
SERVERS=("web1" "web2" "web3")
for server in "${SERVERS[@]}"; do
CPU_USAGE=$(ssh $server "top -bn1 | grep 'Cpu(s)' | awk '{print $2}' | cut -d'%' -f1")
if (( $(echo "$CPU_USAGE > $THRESHOLD" | bc -l) )); then
echo "ALERT: $server CPU usage is ${CPU_USAGE}%"
# 发送告警
curl -X POST "http://alert-manager/api/alerts"
-H "Content-Type: application/json"
-d "{
"alertname": "HighCPUUsage",
"instance": "$server",
"value": "$CPU_USAGE"
}"
fi
done
'''
}
}3. 边缘智能与分布式AIOps
class EdgeIntelligentAIOps:
def __init__(self):
self.edge_capabilities = [
'local_anomaly_detection',
'edge_model_inference',
'distributed_learning',
'autonomous_decision_making'
]
def design_edge_architecture(self):
"""设计边缘智能架构"""
return {
'edge_computing_nodes': {
'local_processing': '本地数据处理和分析',
'model_inference': '轻量级模型推理',
'real_time_response': '毫秒级响应能力',
'offline_operation': '断网情况下的自主运行'
},
'cloud_edge_collaboration': {
'model_distribution': '云端训练,边缘部署',
'federated_learning': '联邦学习框架',
'knowledge_synchronization': '知识同步机制',
'hierarchical_decision': '分层决策体系'
},
'edge_specific_optimizations': {
'model_compression': '模型压缩和量化',
'resource_constraints': '资源受限环境优化',
'power_efficiency': '功耗优化算法',
'communication_efficiency': '通信效率优化'
}
}行业标准化发展
1. AIOps成熟度模型标准
class AIOpsMaturityModel:
def __init__(self):
self.maturity_levels = {
'level_0': {
'name': '传统运维',
'characteristics': [
'人工监控和响应',
'被动故障处理',
'经验驱动决策',
'孤立的工具和系统'
],
'capabilities': ['基础监控', '人工告警', '脚本自动化']
},
'level_1': {
'name': '工具化运维',
'characteristics': [
'标准化监控工具',
'自动化脚本',
'基础告警系统',
'简单数据分析'
],
'capabilities': ['监控自动化', '告警管理', '基础报表']
},
'level_2': {
'name': '数据驱动运维',
'characteristics': [
'集中式数据收集',
'数据可视化',
'基础分析能力',
'简单的自动化'
],
'capabilities': ['数据整合', '趋势分析', '简单预测']
},
'level_3': {
'name': '智能化运维',
'characteristics': [
'AI驱动的异常检测',
'智能告警降噪',
'根因分析能力',
'预测性分析'
],
'capabilities': ['异常检测', '智能告警', '预测分析']
},
'level_4': {
'name': '自动化运维',
'characteristics': [
'自动问题诊断',
'自动修复执行',
'智能容量规划',
'端到端自动化'
],
'capabilities': ['自动诊断', '自动修复', '智能优化']
},
'level_5': {
'name': '自主运维',
'characteristics': [
'完全自主决策',
'自我学习和进化',
'业务价值优化',
'预测性业务洞察'
],
'capabilities': ['自主决策', '自我进化', '业务优化']
}
}
def assess_organization_maturity(self, assessment_data):
"""评估组织AIOps成熟度"""
assessment_areas = {
'data_management': assessment_data.get('data_management', 0),
'analytics_capabilities': assessment_data.get('analytics_capabilities', 0),
'automation_level': assessment_data.get('automation_level', 0),
'ai_adoption': assessment_data.get('ai_adoption', 0),
'organizational_readiness': assessment_data.get('organizational_readiness', 0)
}
# 计算总体成熟度得分
overall_score = sum(assessment_areas.values()) / len(assessment_areas)
# 确定成熟度等级
if overall_score < 1:
maturity_level = 0
elif overall_score < 2:
maturity_level = 1
elif overall_score < 3:
maturity_level = 2
elif overall_score < 4:
maturity_level = 3
elif overall_score < 5:
maturity_level = 4
else:
maturity_level = 5
return {
'current_level': maturity_level,
'level_description': self.maturity_levels[f'level_{maturity_level}'],
'area_scores': assessment_areas,
'improvement_recommendations': self.generate_improvement_plan(maturity_level, assessment_areas)
}生态系统发展
1. AIOps平台生态

2. 产业联盟与标准化
预计未来几年将出现更多的AIOps产业联盟和标准化组织,推动:
技术标准统一:数据格式、API接口、算法评估标准
最佳实践共享:跨行业的成功案例和方法论
人才培养体系:认证体系和教育培训标准
工具互操作性:不同厂商工具之间的集成标准
总结
AIOps作为IT运维领域的革命性变革,正在重新定义现代企业的运维方式。通过人工智能与传统运维的深度融合,AIOps实现了从被动响应到主动预防、从人工操作到智能自动化的根本性转变。
核心价值总结
技术价值: – 智能化程度显著提升:从简单的规则引擎发展到复杂的机器学习模型 – 自动化水平大幅提高:从单点自动化到端到端的智能流程 – 预测能力不断增强:从历史分析到未来预测和主动预防
业务价值: – 系统可靠性提升:通过预测性维护显著降低故障率 – 运维效率大幅改善:自动化和智能化减少人工干预需求 – 成本控制效果明显:优化资源配置和提高设备利用率
组织价值: – 运维团队能力升级:从传统运维向数据科学和AI工程转型 – 决策质量显著提高:基于数据和算法的科学决策 – 创新能力持续增强:为业务创新提供更稳定的技术支撑
实施关键成功因素
1. 战略层面 – 明确的业务目标和价值预期 – 高层领导的坚定支持和资源投入 – 渐进式的实施路线图和里程碑规划
2. 技术层面 – 高质量的数据基础和治理体系 – 合适的技术架构和工具选择 – 持续的模型优化和系统演进
3. 组织层面 – 跨职能团队的有效协作 – 持续的技能培养和知识更新 – 开放包容的学习型文化建设
未来展望
随着人工智能技术的不断发展和成熟,AIOps将朝着更加智能化、自主化的方向演进:
短期发展(1-2年): – 大语言模型在运维场景的深度应用 – 边缘智能和分布式AIOps的普及 – 行业标准和最佳实践的进一步完善
中期发展(3-5年): – 认知计算在复杂运维场景的突破 – 自主运维系统的规模化部署 – 跨云、跨平台的统一AIOps生态
长期愿景(5-10年): – 完全自主的智能运维系统 – 业务与技术的深度融合优化 – 运维即服务的新商业模式
建议与行动指南
对于准备实施AIOps的企业,建议遵循以下原则:
1. 从小处着手,逐步扩展 – 选择影响面相对可控的试点场景 – 验证技术可行性和业务价值 – 积累经验后再扩展到核心业务系统
2. 重视数据基础建设 – 优先解决数据质量和标准化问题 – 建立完善的数据治理体系 – 确保数据安全和合规要求
3. 平衡技术先进性与实用性 – 选择成熟稳定的技术方案 – 避免过度追求技术新颖性 – 已关注长期的可维护性和扩展性
4. 投资于人才和文化 – 制定系统的技能发展计划 – 营造学习和创新的文化氛围 – 建立有效的激励和认可机制
AIOps的成功实施不仅仅是技术项目,更是一场涉及技术、流程、组织和文化的全面数字化转型。只有在战略规划、技术实施、组织变革等各个层面协调推进,才能真正实现AIOps的价值,构建面向未来的智能运维体系。
通过持续的技术创新、实践优化和生态建设,AIOps必将成为企业数字化转型的重要支撑,为业务发展创造更大的价值空间。
关键词:AIOps, 智能运维, 自愈系统, 技术演进, 机器学习, 自动化运维, 异常检测, 预测性维护

















暂无评论内容