
宇宙安全声明:仅用于学习目的,无商业用途
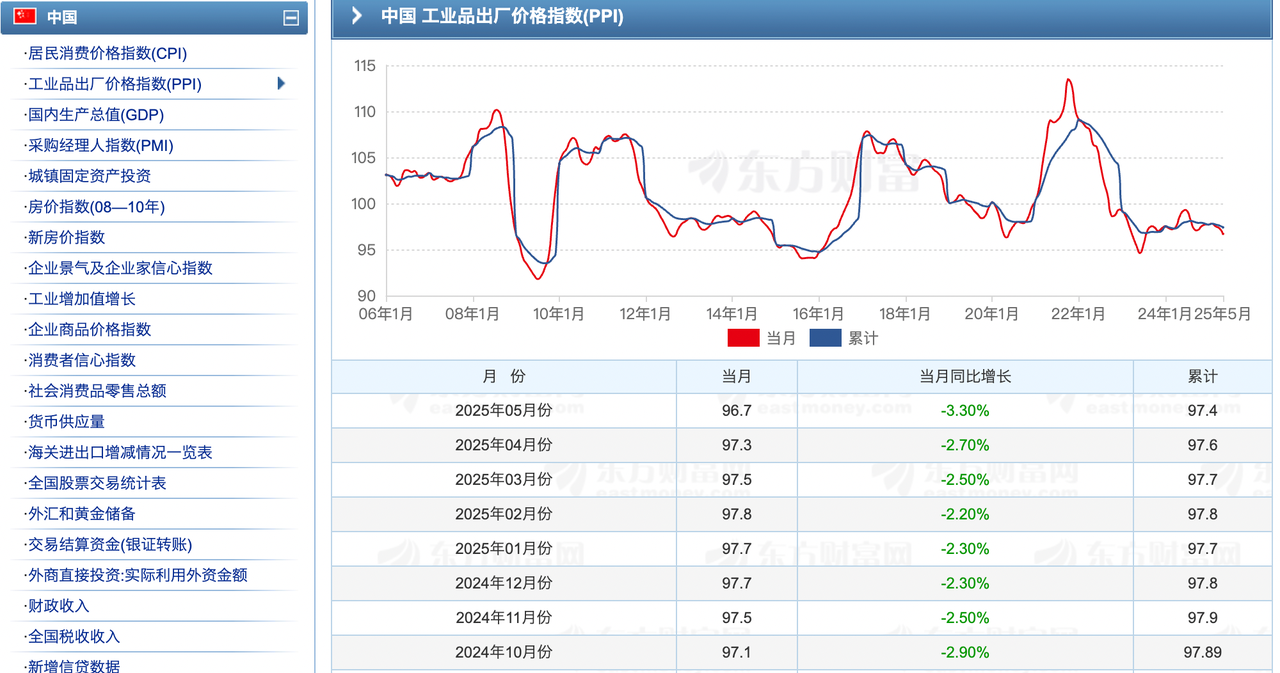
数据来源:东方财富网
web页面
1. 导入的库
import requests
import re
import json
import pandas as pd requests:用于发送HTTP请求,获取网页数据。
re:用于正则表达式匹配,从响应文本中提取JSON数据。
json:用于解析JSON格式的数据。
pandas:用于数据处理和保存为CSV文件。
2. get_one_data(url) 函数
def get_one_data(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
json_data_match = re.search(r'((.*))', response.text)
if json_data_match:
json_data = json_data_match.group(1)
try:
data_dict = json.loads(json_data)
if 'result' in data_dict and 'data' in data_dict['result']:
extracted_data = data_dict['result']['data']
data_list = []
for entry in extracted_data:
latest_price = entry.get("f2", "-")
latest_price = 0.0 if latest_price == "-" else float(latest_price)
data_list.append({
"时间": entry.get("REPORT_DATE"),
"指数": float(entry.get("BASE", 0)),
"增长率": float(entry.get("BASE_SAME", 0))
})
return data_list
except json.JSONDecodeError:
print("Error decoding JSON.")
return None功能:从指定的URL获取单页数据并解析为结构化格式。
发送HTTP请求:
使用requests.get发送GET请求,模拟浏览器行为(通过设置User-Agent伪装为Chrome浏览器)。
检查响应状态码是否为200(请求成功)。
提取JSON数据:
东方财富网的API返回的数据格式为callback_name(json_data),因此使用正则表达式re.search(r'((.*))', response.text)提取括号中的JSON内容。
使用json.loads将提取的JSON字符串解析为Python字典。
数据处理:
从解析后的字典中提取result.data字段,这是一个包含数据的列表。
遍历每个数据条目,提取以下字段:
REPORT_DATE:报告日期(时间)。
BASE:PPI指数,转换为浮点数,默认为0。
BASE_SAME:同比增长率,转换为浮点数,默认为0。
注意:代码中有latest_price = entry.get(“f2”, “-“),但f2并未在最终数据中使用,可能是遗留代码。
将提取的数据存入data_list,每个条目为一个字典。
错误处理:
如果JSON解析失败,打印错误信息并返回None。
如果请求失败或数据结构不符合预期,也返回None。
返回:包含单页数据的字典列表,或None(如果失败)。
3. save_to_csv(data, filename) 函数
def save_to_csv(data, filename):
if isinstance(data, list) and isinstance(data[0], dict):
df = pd.DataFrame(data)
df.to_csv(filename, index=False, encoding='utf-8')
elif isinstance(data, pd.DataFrame):
data.to_csv(filename, index=False, encoding='utf-8')
else:
print("Unsupported data format for CSV.")功能:将数据保存为CSV文件。
数据格式检查:
如果data是一个字典列表(如get_one_data的返回值),将其转换为pandas.DataFrame。
如果data已经是DataFrame,直接使用。
否则,打印错误信息。
保存到CSV:
使用df.to_csv保存数据到指定文件路径。
参数index=False表示不保存行索引。
使用utf-8编码以支持中文字符。
4. fetch_and_save_all_page(base_url, total_pages, filename) 函数
def fetch_and_save_all_page(base_url, total_pages, filename='/your path/ppi.csv'):
all_data = []
for page in range(1, total_pages + 1):
page_url = base_url.replace("pageNumber=1", f"pageNumber={page}")
print(f"Fetching page {page}...")
result = get_one_data(page_url)
if result:
all_data.extend(result)
else:
print(f"Failed to retrieve data for page {page}.")
if all_data:
save_to_csv(all_data, filename)
else:
print("No data fetched.")功能:抓取所有指定页数的数据并保存为一个CSV文件。
循环抓取:
通过替换URL中的pageNumber=1为pageNumber={page},构造每一页的URL。
调用get_one_data(page_url)获取单页数据。
如果获取成功,将数据追加到all_data列表中;否则,打印失败信息。
保存数据:
所有页面数据抓取完成后,如果all_data不为空,调用save_to_csv保存为CSV文件。
如果没有抓取到数据,打印提示信息。
注意:
默认文件名/your path/ppi.csv需要用户替换为实际路径,否则会报错。
每次抓取都会打印进度信息(如“Fetching page 1…”)。
爬取PPI全部代码,CPI同理:
import requests
import re
import json
import pandas as pd
def get_one_data(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)#发送请求get方法
if response.status_code == 200:#请求成功
json_data_match = re.search(r'((.*))', response.text)
if json_data_match:
json_data = json_data_match.group(1)
try:
data_dict = json.loads(json_data)
if 'result' in data_dict and 'data' in data_dict['result']:
extracted_data = data_dict['result']['data']
data_list = []
for entry in extracted_data:
# 处理各个字段可能为 '-' 的情况
latest_price = entry.get("f2", "-")
latest_price = 0.0 if latest_price == "-" else float(latest_price)
data_list.append({
"时间": entry.get("REPORT_DATE"),
"指数": float(entry.get("BASE",0)),
"增长率": float(entry.get("BASE_SAME", 0))
})
return data_list
except json.JSONDecodeError:
print("Error decoding JSON.")
return None
def save_to_csv(data, filename):
# 假设 `data` 是一个包含字典的列表或 pandas DataFrame
# 如果 `data` 是一个字典列表
if isinstance(data, list) and isinstance(data[0], dict):
df = pd.DataFrame(data)
df.to_csv(filename, index=False, encoding='utf-8') # 保存到 CSV,去掉索引列
elif isinstance(data, pd.DataFrame):
data.to_csv(filename, index=False, encoding='utf-8') # 如果 data 已经是 DataFrame,直接保存
else:
print("Unsupported data format for CSV.")
def fetch_and_save_all_page(base_url, total_pages, filename='/your path/ppi.csv'):
all_data = []
# 循环抓取所有页面的数据
for page in range(1, total_pages + 1):
page_url = base_url.replace("pageNumber=1", f"pageNumber={page}")
print(f"Fetching page {page}...")
result = get_one_data(page_url)
if result:
all_data.extend(result) # 将当前页的数据添加到 all_data 列表中
else:
print(f"Failed to retrieve data for page {page}.")
# 抓取完所有页面后保存为 CSV 文件
if all_data:
save_to_csv(all_data, filename)
else:
print("No data fetched.")
if __name__ == '__main__':
url = 'https://datacenter-web.eastmoney.com/api/data/v1/get?callback=datatable8420838&columns=REPORT_DATE%2CTIME%2CBASE%2CBASE_SAME%2CBASE_ACCUMULATE&pageNumber=1&pageSize=20&sortColumns=REPORT_DATE&sortTypes=-1&source=WEB&client=WEB&reportName=RPT_ECONOMY_PPI&_=1749603495964'
# 用户输入总页数
total_pages = int(input("请输入要抓取的总页数:"))
# # 每页抓取并保存
fetch_and_save_all_page(url, total_pages)




















暂无评论内容