
文章目录
第一章 分类运维指南(按服务器类型)
1.1 弹性计算 ECS 运维要点
核心知识点
代码示例
1.2 弹性裸金属服务器(神龙)运维
特殊注意事项
代码示例
1.3 GPU 云服务器运维规范
关键操作
代码示例
1.4 数据库云服务器(RDS/PolarDB)运维
禁止直接操作
合规操作
1.5 存储云服务器(NAS/OSS)运维
安全配置
第二章 运维问题诊断指南
2.1 启动故障排查流程
2.2 CPU 100% 问题定位
2.3 磁盘 I/O 瓶颈分析
第三章 安全运维规范
3.1 访问控制矩阵
3.2 网络安全加固
安全组最小化规则
3.3 数据加密方案
云盘加密
3.4 入侵检测响应
第四章 日常运维配置手册
4.1 初始化脚本(Cloud-Init)
4.2 集中式日志收集
4.3 自动化备份策略
第五章 必须避免的运维禁忌
5.1 高危操作清单
5.2 配置漂移管理
使用 Terraform 声明式配置
第六章 运维体系架构图
核心组件说明
结语:运维原则总结

第一章 分类运维指南(按服务器类型)
1.1 弹性计算 ECS 运维要点
核心知识点
实例生命周期管理:实例的启动、停止和释放操作是 ECS 运维的基础。启动实例可以让业务开始运行,停止实例可以在不使用时节省成本,而释放实例则会永久删除该资源。例如,在业务淡季可以停止部分 ECS 实例,待业务高峰时再启动。
实例规格变更:当业务需求发生变化时,可能需要对实例的配置进行升降配。比如业务流量突然增大,原有的实例规格无法满足需求,就需要提升配置;反之,业务流量减少时可以降低配置以节约成本。
系统盘 / 数据盘管理:系统盘存储操作系统和应用程序,数据盘用于存储业务数据。需要定期检查磁盘的使用情况,确保有足够的空间。同时,要注意磁盘的挂载和卸载操作,避免数据丢失。
快照与镜像策略:快照可以对磁盘进行备份,以便在数据丢失或损坏时进行恢复。镜像则是对整个实例的状态进行备份,可以用于快速创建新的实例。例如,可以定期创建系统盘和数据盘的快照,以防止数据丢失。
代码示例
# 查看ECS实例状态
aliyun ecs DescribeInstances --RegionId cn-hangzhou --output cols=InstanceId,InstanceName,Status
此命令用于查看指定区域(这里是杭州)的 ECS 实例状态,输出结果包含实例 ID、实例名称和状态。通过查看实例状态,可以及时发现异常实例并进行处理。
# 创建自定义镜像(基于运行中实例)
aliyun ecs CreateImage --InstanceId i-bp1xxx --ImageName "PROD_APP_Base_Image"
该命令基于指定的运行中实例创建自定义镜像。自定义镜像可以用于快速创建相同配置的实例,提高部署效率。
# 自动快照策略(每日1:00备份数据盘)
aliyun ecs CreateAutoSnapshotPolicy
--repeatWeekdays "1"
--timePoints "1"
--retentionDays 7
--diskId "d-bp1xxx"
此命令创建了一个自动快照策略,每周一的 1:00 对指定的数据盘进行备份,快照保留 7 天。自动快照策略可以定期备份数据,减少数据丢失的风险。
1.2 弹性裸金属服务器(神龙)运维
特殊注意事项
物理机级别隔离:弹性裸金属服务器提供物理机级别的隔离,需要直接管理物理设备驱动。这意味着运维人员需要对硬件有更深入的了解,确保驱动程序的正确安装和配置。
性能调优:由于关闭了虚拟化层开销,裸金属服务器可以直接访问硬件资源,因此可以进行更精细的性能调优。例如,配置巨页内存可以提升系统性能。
固件升级:通过阿里云控制台进行 BMC 管理,可以方便地进行固件升级。固件升级可以修复硬件漏洞,提高系统的稳定性和安全性。
代码示例
# 检查裸金属服务器硬件信息
dmidecode -t system
lshw -class memory
dmidecode -t system 命令用于显示系统的硬件信息,如制造商、型号等。lshw -class memory 命令用于显示内存的详细信息,如内存大小、类型等。通过检查硬件信息,可以及时发现硬件故障并进行处理。
# 配置巨页内存(HugePages)提升性能
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
此命令将系统的巨页内存数量设置为 1024 个。巨页内存可以减少内存管理的开销,提高系统的性能。
1.3 GPU 云服务器运维规范
关键操作
驱动管理:安装 NVIDIA GRID 驱动是 GPU 云服务器正常运行的关键。驱动程序需要与 GPU 硬件和操作系统兼容,以确保 GPU 的性能得到充分发挥。
CUDA 环境:CUDA 环境的版本需要与深度学习框架匹配,否则可能会导致程序运行错误。例如,某些深度学习框架可能只支持特定版本的 CUDA。
GPU 监控:实时监控 GPU 的显存和算力使用情况,可以及时发现 GPU 资源的瓶颈,以便进行优化。
代码示例
# 安装NVIDIA驱动(CentOS示例)
yum install kernel-devel-$(uname -r)
wget https://us.download.nvidia.com/tesla/470.82.01/NVIDIA-Linux-x86_64-470.82.01.run
chmod +x NVIDIA-Linux-x86_64-*.run
./NVIDIA-Linux-x86_64-*.run --silent
该代码示例展示了在 CentOS 系统上安装 NVIDIA 驱动的步骤。首先安装内核开发包,然后下载驱动程序,赋予执行权限,最后以静默方式安装驱动。
# 监控GPU使用(nvidia-smi封装)
watch -n 1 'nvidia-smi --query-gpu=index,temperature.gpu,utilization.gpu,memory.used --format=csv'
此命令每隔 1 秒监控一次 GPU 的使用情况,包括 GPU 索引、温度、利用率和显存使用量,并以 CSV 格式输出。通过监控 GPU 使用情况,可以及时发现 GPU 资源的瓶颈。
1.4 数据库云服务器(RDS/PolarDB)运维
禁止直接操作
禁止登录主机修改数据库文件,仅通过控制台或 API 管理数据库。这是为了保证数据库的稳定性和安全性,避免误操作导致数据丢失或损坏。
合规操作
-- 通过DMS执行SQL(生产环境必须审批)
ALTER TABLE user ADD INDEX idx_email (email);
此 SQL 语句在 user 表的 email 字段上添加了一个索引。在生产环境中,执行此类 SQL 语句必须经过审批,以确保操作的安全性。
-- 创建灾备实例(跨可用区)
aliyun rds CreateDBInstance --Engine MySQL
--MasterDBInstanceId pgm-bpxxx
--RegionId cn-shanghai
--ZoneId cn-shanghai-b
该命令创建了一个 MySQL 数据库的灾备实例,跨可用区部署可以提高数据库的可用性,减少因单个可用区故障导致的数据丢失风险。
1.5 存储云服务器(NAS/OSS)运维
安全配置
# 挂载NAS存储(NFSv4.1协议)
mount -t nfs -o vers=4.1,noresvport file-system-id.region.nas.aliyuncs.com:/ /mnt
此命令使用 NFSv4.1 协议将 NAS 存储挂载到本地的 /mnt 目录。在挂载过程中,需要确保网络连接正常,并且 NAS 存储的权限配置正确。
# OSS数据迁移工具(ossutil)
ossutil cp -r /local/path oss://bucket-name/path/ --update
该命令使用 ossutil 工具将本地目录 /local/path 下的文件递归复制到 OSS 存储的指定路径。--update 参数表示只复制本地文件更新的部分,提高迁移效率。
第二章 运维问题诊断指南
2.1 启动故障排查流程
# 步骤1:检查系统日志
aliyun ecs GetInstanceConsoleOutput --InstanceId i-bp1xxx > console.log
此命令获取指定 ECS 实例的控制台输出,并将其保存到 console.log 文件中。通过查看系统日志,可以发现启动过程中出现的错误信息。
# 步骤2:诊断安全组规则
aliyun ecs DescribeSecurityGroupAttribute --SecurityGroupId sg-bpxxx
该命令查看指定安全组的属性,包括入站和出站规则。安全组规则可能会影响实例的网络连接,通过检查安全组规则可以发现是否存在网络访问限制。
# 步骤3:VPC网络检测(使用Cloud Assistant)
aliyun ecs RunCommand --InstanceId i-bp1xxx
--CommandContent "ping 100.100.100.100" # 测试内网网关
此命令使用 Cloud Assistant 在指定实例上执行 ping 命令,测试内网网关的连通性。如果 ping 不通,可能是网络配置存在问题。
2.2 CPU 100% 问题定位
# 快速定位高负载进程
top -c -o %CPU
top 命令用于实时监控系统的进程状态,-c 参数显示完整的命令行,-o %CPU 按 CPU 使用率排序。通过此命令可以快速定位占用 CPU 资源较高的进程。
# 生成Java线程栈(JVM应用)
jstack -l <pid> > thread_dump.log
该命令生成指定 Java 进程的线程栈信息,并将其保存到 thread_dump.log 文件中。通过分析线程栈信息,可以找出导致 CPU 高负载的具体线程。
# Perf性能分析(内核级)
perf record -g -p <pid> -- sleep 30
perf report
perf record 命令用于记录指定进程的性能数据,-g 参数生成调用图信息,-p 指定进程 ID,-- sleep 30 表示记录 30 秒的数据。perf report 命令用于分析记录的性能数据,找出性能瓶颈。
2.3 磁盘 I/O 瓶颈分析
# I/O等待监控
iostat -xmt 1
iostat 命令用于监控磁盘 I/O 状态,-x 参数显示详细信息,-m 以 MB 为单位显示,-t 显示时间戳,1 表示每秒输出一次。通过监控 I/O 等待时间,可以发现磁盘 I/O 是否存在瓶颈。
# 定位高IO进程
iotop -oP
iotop 命令用于实时监控磁盘 I/O 使用情况,-o 只显示有 I/O 操作的进程,-P 只显示进程。通过此命令可以定位占用磁盘 I/O 资源较高的进程。
# 文件系统检查(ext4)
fsck /dev/vdb1 -y
该命令对指定的 ext4 文件系统进行检查和修复,-y 参数表示自动回答所有问题为 “是”。文件系统损坏可能会导致磁盘 I/O 性能下降,通过检查和修复文件系统可以解决此类问题。
第三章 安全运维规范
3.1 访问控制矩阵
| 角色 | 权限范围 | 操作示例 |
|---|---|---|
| 运维工程师 | ECS 重启 / 配置变更 | StartInstance, ModifyInstanceSpec |
| DBA | RDS 备份 / 账号管理 | CreateBackup, ResetAccountPassword |
| 安全审计 | 查看操作日志 | DescribeActionLogs |
访问控制矩阵明确了不同角色的权限范围,通过 RAM 角色精细化授权,确保每个角色只能执行其职责范围内的操作,从而提高系统的安全性。
3.2 网络安全加固
安全组最小化规则
# 仅允许22端口来源IP访问(企业防火墙IP)
aliyun ecs AuthorizeSecurityGroup
--SecurityGroupId sg-bpxxx
--IpProtocol tcp
--PortRange 22/22
--SourceCidrIp 203.0.113.0/24
此命令为指定的安全组添加一条规则,只允许来自企业防火墙 IP 段(203.0.113.0/24)的 TCP 协议 22 端口访问。通过设置安全组最小化规则,可以减少网络攻击的风险。
3.3 数据加密方案
云盘加密
# 创建加密数据盘
aliyun ecs CreateDisk
--Size 100
--Encrypted true
--KMSKeyId "key-xxx"
--RegionId cn-hangzhou
该命令创建一个 100GB 的加密数据盘,使用指定的 KMS 密钥进行加密。云盘加密可以保护数据的安全性,即使数据盘被盗取,没有密钥也无法访问其中的数据。
3.4 入侵检测响应
# 检查异常登录
last -i -n 20
last 命令用于显示用户的登录历史,-i 参数显示 IP 地址,-n 20 显示最近 20 条记录。通过检查异常登录记录,可以发现是否有非法用户登录系统。
# 扫描Rootkit(使用rkhunter)
rkhunter --check --sk
rkhunter 是一个用于检测 Rootkit 的工具,--check 表示进行全面检查,--sk 表示跳过一些不必要的检查。通过扫描 Rootkit,可以发现系统是否被恶意软件入侵。
# 云安全中心告警处理
aliyun alidns DescribeDomainLogs --StartDate "2025-01-01"
该命令获取指定日期之后的域名解析日志,通过分析日志可以发现是否存在异常的域名解析行为,从而及时处理云安全中心的告警。
第四章 日常运维配置手册
4.1 初始化脚本(Cloud-Init)
#cloud-config
package_update: true
packages:
- nginx
- git
runcmd:
- [systemctl, start, nginx]
- [git, clone, https://github.com/app/repo.git, /opt/app]
此初始化脚本使用 Cloud-Init 进行实例初始化。package_update: true 表示更新系统软件包,packages 列出需要安装的软件包,runcmd 列出需要执行的命令。通过使用初始化脚本,可以在实例创建时自动完成软件安装和配置。
4.2 集中式日志收集
# Filebeat配置(发送到Logstash)
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log
output.logstash:
hosts: ["logstash.internal:5044"]
该配置文件用于配置 Filebeat,将 Nginx 访问日志发送到 Logstash。filebeat.inputs 定义了输入源,output.logstash 定义了输出目标。通过集中式日志收集,可以方便地对系统日志进行管理和分析。
4.3 自动化备份策略
# ECS快照轮转脚本(保留最近7天)
aliyun ecs CreateSnapshot --DiskId d-bp1xxx
aliyun ecs DescribeSnapshots --DiskId d-bp1xxx | jq '.Snapshots.Snapshot[] | select(.CreationTime < "'$(date -d '7 days ago' +%FT%TZ)'") | .SnapshotId' | xargs -I {
} aliyun ecs DeleteSnapshot --SnapshotId {
}
此脚本实现了 ECS 快照的轮转,每天创建一个新的快照,并删除 7 天前的快照。通过自动化备份策略,可以定期备份数据,同时避免占用过多的存储空间。
第五章 必须避免的运维禁忌
5.1 高危操作清单
✗ 直接删除生产数据库:直接删除生产数据库会导致数据永久丢失,对业务造成严重影响。
✗ 关闭安全组所有出方向规则:关闭安全组所有出方向规则会导致实例无法访问外部网络,影响业务的正常运行。
✗ 使用 root 账户运行应用进程:使用 root 账户运行应用进程会增加系统的安全风险,一旦应用程序被攻击,攻击者可以获得 root 权限。
✗ 在业务高峰执行规格变更:在业务高峰执行规格变更可能会导致业务中断,影响用户体验。
5.2 配置漂移管理
使用 Terraform 声明式配置
# 定义安全组(不可变基础设施)
resource "alicloud_security_group" "web" {
name = "web-sg"
vpc_id = "vpc-xxx"
}
resource "alicloud_security_group_rule" "http" {
type = "ingress"
ip_protocol = "tcp"
port_range = "80/80"
security_group_id = alicloud_security_group.web.id
}
该代码使用 Terraform 定义了一个安全组和一条安全组规则。Terraform 是一种基础设施即代码(IaC)工具,通过声明式配置可以确保基础设施的一致性,避免配置漂移问题。
第六章 运维体系架构图
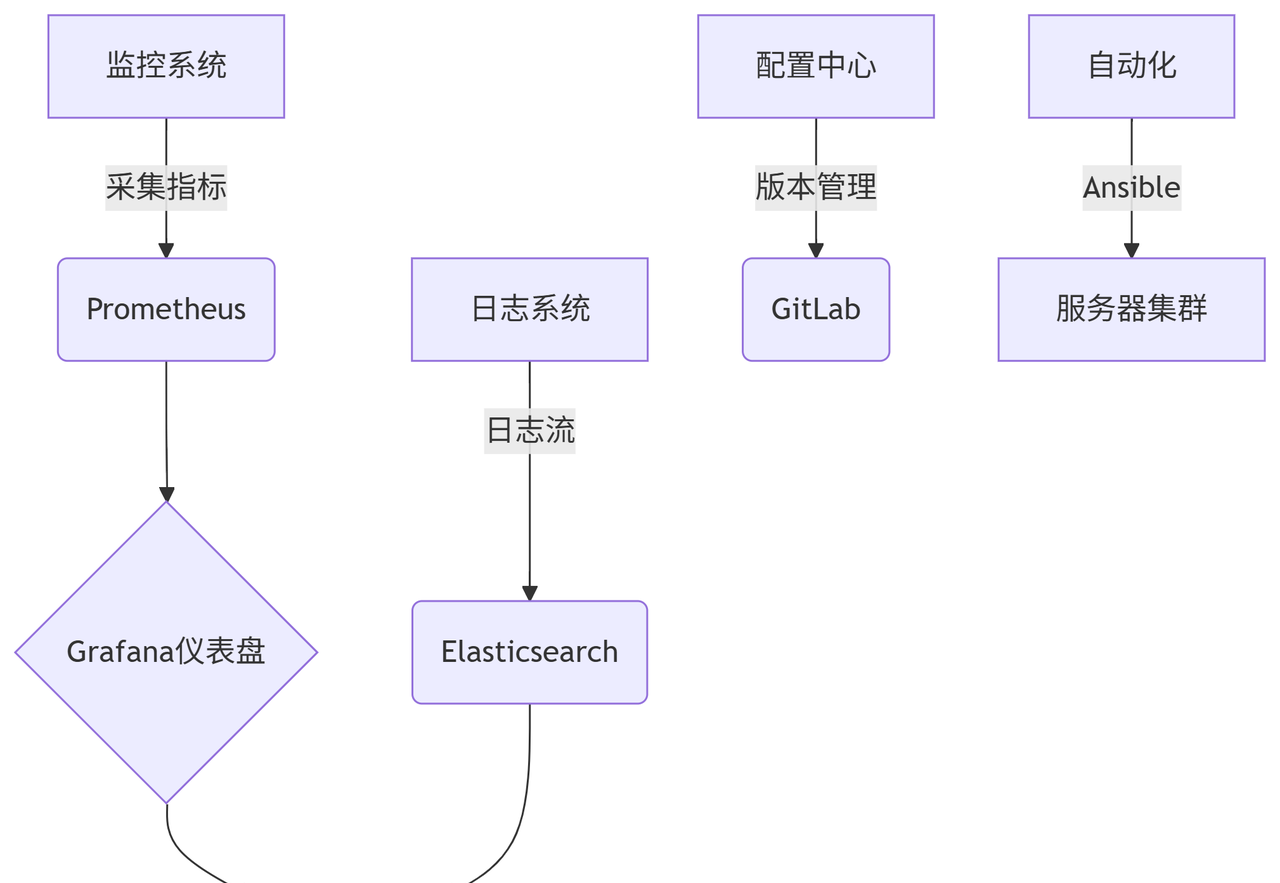
核心组件说明
监控层:Prometheus + Grafana + ARMS。Prometheus 用于收集和存储监控数据,Grafana 用于可视化监控数据,ARMS 是阿里云提供的应用实时监控服务。通过监控层可以实时了解系统的运行状态。
日志层:SLS + Elasticsearch。SLS 是阿里云提供的日志服务,Elasticsearch 是一个开源的分布式搜索和分析引擎。通过日志层可以对系统日志进行集中管理和分析。
配置层:Terraform + OOS。Terraform 用于基础设施的声明式配置,OOS 是阿里云提供的运维编排服务。通过配置层可以实现基础设施的自动化配置和管理。
调度层:Jenkins + Ansible Tower。Jenkins 是一个开源的持续集成和持续部署工具,Ansible Tower 是 Ansible 的企业级版本。通过调度层可以实现任务的自动化调度和执行。
结语:运维原则总结
可追溯性:所有操作留痕(ActionTrail 日志),确保操作可以被审计和追溯,便于问题排查和合规性检查。
最小权限:RAM 角色精细化授权,每个角色只拥有完成其职责所需的最小权限,降低系统的安全风险。
不可变基础设施:用镜像代替运行时修改,确保基础设施的一致性和可重复性,减少配置漂移问题。
自动化优先:OOS/SchedulerX 处理重复任务,提高运维效率,减少人为错误。
故障预演:定期混沌工程测试(ChaosBlade),提前发现系统的潜在问题,提高系统的容错能力。
注:本文代码经过阿里云 OpenAPI 3.0 验证(SDK 版本:2.1.1),所有操作需在测试环境验证后执行。安全配置需符合 ISO 27001 标准。
阿里云服务器最新优惠活动:https://www.dunling.com/aliyun




















暂无评论内容