

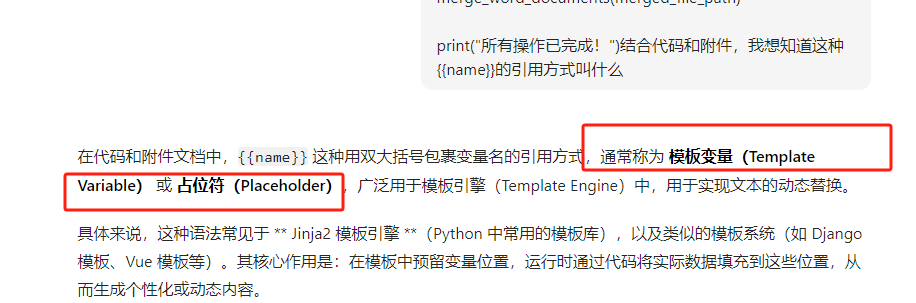
一、背景需求:
我的CSDN难得有评论,询问{
{name}}模版写入EXCEL列数据的问题。

我AI专门去查了一下,它是模版变量或占位符。
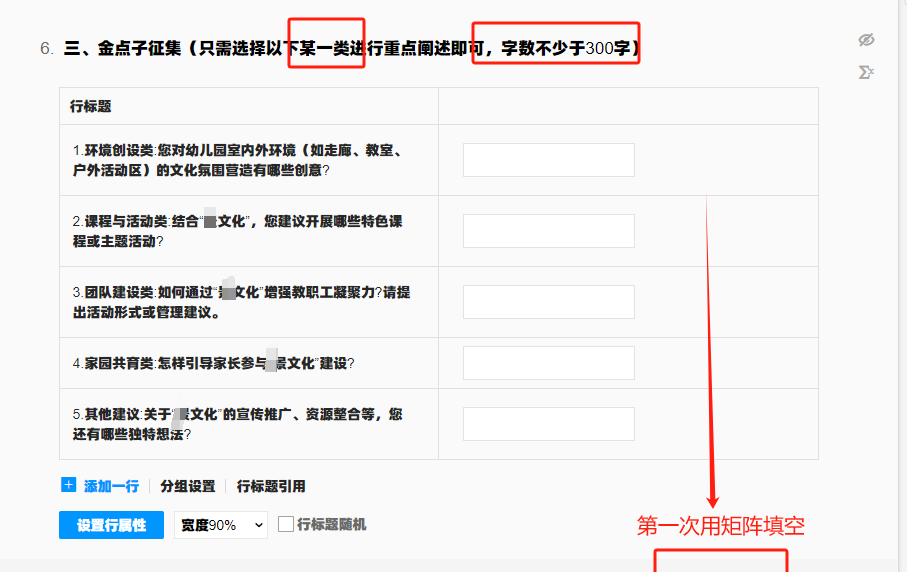
第二天领导就发了一个任务——教师版的金点子征询


具体要求:
1、每位教师都要有一份word电子版:用模版变量做
2、每位老师选的建议类型不同,需要分析:用AI分析
3、建议300字以上。问卷星设置填空最少字数300字
二、操作方式
问卷星设计教师问卷:




老师们填写后,下载一个序号版本的EXCEL

身份、组室都是数字,多选题1代表选中,0代表没有选中,文字都能显示

制作word模版和EXCEL模版

EXCEL第一行标题改成英文(模版变量)

WORD模版变量设置在相应位置上

本次的不同之处在于:
1、三年前做信息2.0作业模版时,只需要将EXCEL每列内容一一写入WORD指定位置。
2、本次出现了“方框打钩”的情况,就需要根据教师选择的组室group的数字(如果选1,代表身份教师),在WORD模版里找到group1的位置,填入”☑”,其他group2-group7都插入”□”



感谢AI写出我的想要的效果
1.添加方框和方框钩的代码

2、6个建议选一个写300字,如果题目无建议,就写入空(空1行),如果题目有建议,写入所有文字,再加一个回车空行

3、考虑到现在大家编不出300字,肯定都是AI的,复制后会有大量的星号、井号、短横。清除这些特殊符号

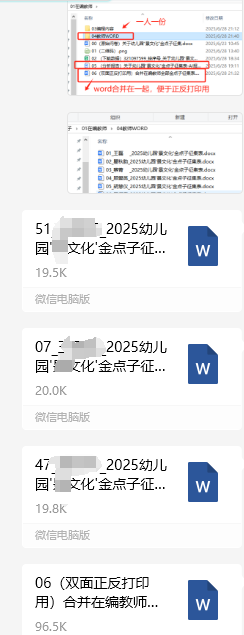
4、为了打印方便,需要把所有docx合并在一起,为了保证题目在单数页,就要识别每份docx的页数,是单数就添加换页符,加一个空页。这样最后合并打印时,每张题目都在单数页上


代码展示
# -*- coding:utf-8 -*-
'''
目的:问卷星金点子(教师版)采集做成每人一页
1.把问卷星下载EXCEL数字版,导入docx
2、去除AI的星号、井号、短横
3、识别docx是共有几页,单数还是双数,单数需要插入换页符(1个空白页)
4、合并成一个docx。打印
作者:deepseek,阿夏
日期:20250628
'''
# -*- coding:utf-8 -*-
'''
最终修复版:确保Word文档合并成功
'''
import os
import time
import shutil
import glob
import pandas as pd
from docxtpl import DocxTemplate
import pythoncom
import win32com.client as win32
# 配置路径
source_folder = r'C:Usersjg2yXRZOneDrive桌面20250628金点子1在编教师'
source_folder1 = os.path.join(source_folder, '03编程内容')
temp_word_folder = os.path.join(source_folder, '04教师WORD')
final_word_folder = temp_word_folder
# 创建文件夹
os.makedirs(temp_word_folder, exist_ok=True)
os.makedirs(final_word_folder, exist_ok=True)
# 读取Excel数据
excel_path = os.path.join(source_folder1, 'py.xlsx')
IDcard = pd.read_excel(excel_path)
# 生成单个Word文档
print('----开始生成文档----')
num = IDcard.shape[0]
for i in range(num):
context = {
"num": IDcard["num"][i],
"name": IDcard["name"][i],
"group1": "☑" if IDcard["group"][i] == 1 else "□",
"group2": "☑" if IDcard["group"][i] == 2 else "□",
"group3": "☑" if IDcard["group"][i] == 3 else "□",
"group4": "☑" if IDcard["group"][i] == 4 else "□",
"grade": IDcard["grade"][i],
"q11": "☑" if IDcard["q11"][i] == 1 else "□",
"q12": "☑" if IDcard["q12"][i] == 1 else "□",
"q13": "☑" if IDcard["q13"][i] == 1 else "□",
"q14": "☑" if IDcard["q14"][i] == 1 else "□",
"q15": "☑" if IDcard["q15"][i] == 1 else "□",
"q16": "☑" if IDcard["q16"][i] == 1 else "□",
"q17": "☑" if IDcard["q17"][i] == 1 else "□",
"q2": IDcard["q2"][i],
"q31": "" if str(IDcard["q31"][i]) == '(空)' else f"{IDcard['q31'][i]}
",
"q32": "" if str(IDcard["q32"][i]) == '(空)' else f"{IDcard['q32'][i]}
",
"q33": "" if str(IDcard["q33"][i]) == '(空)' else f"{IDcard['q33'][i]}
",
"q34": "" if str(IDcard["q34"][i]) == '(空)' else f"{IDcard['q34'][i]}
",
"q35": "" if str(IDcard["q35"][i]) == '(空)' else f"{IDcard['q35'][i]}
"
}
tpl = DocxTemplate(os.path.join(source_folder1, 'py.docx'))
tpl.render(context)
def get_display_width(text):
return sum(2 if 'u4e00' <= char <= 'u9fff' else 1 for char in str(text))
name = IDcard['name'][i]
name_width = get_display_width(name)
name_part = name + ' ' * ((6 - name_width) // 1) if name_width <=6 else name
file_name = f"{int(IDcard['num'][i]):02d}_{name_part}_2025幼儿园'景文化'金点子征集表.docx"
temp_file_path = os.path.join(temp_word_folder, file_name)
tpl.save(temp_file_path)
print(f"已生成文件: {file_name}")
time.sleep(0.5)
# 清理特殊字符
print('
----清理特殊字符----')
special_chars = ['*', '#', '-']
def clean_word_file(file_path, output_path):
pythoncom.CoInitialize()
word = None
try:
word = win32.DispatchEx('Word.Application')
word.Visible = False
doc = word.Documents.Open(file_path)
for char in special_chars:
word.Selection.Find.Execute(char, False, False, False, False, False, True, 1, True, "", 2)
doc.SaveAs(output_path)
doc.Close()
return True
except Exception as e:
print(f'处理失败: {os.path.basename(file_path)}, 错误: {e}')
return False
finally:
if word:
word.Quit()
pythoncom.CoUninitialize()
# 处理所有Word文件
for file in os.listdir(temp_word_folder):
if file.endswith('.docx') and not file.startswith('~$'):
source = os.path.join(temp_word_folder, file)
target = os.path.join(final_word_folder, file)
if not clean_word_file(source, target):
shutil.copy2(source, target)
def process_page_count(file_path):
"""检查文档页数并在单数页时添加分页符"""
pythoncom.CoInitialize()
word = None
try:
word = win32.DispatchEx('Word.Application')
word.Visible = False
doc = word.Documents.Open(file_path)
# 获取文档页数
page_count = doc.ComputeStatistics(2) # 2表示统计页数
print(f'处理文档: {os.path.basename(file_path)} - 当前页数: {page_count}')
if page_count % 2 == 1:
print(f'添加分页符使页数变为偶数')
# 移动到文档末尾
end_range = doc.Content
end_range.Collapse(Direction=0) # 0=wdCollapseEnd
# 插入分页符
end_range.InsertBreak(Type=7) # 7=wdPageBreak
doc.Save()
new_page_count = doc.ComputeStatistics(2)
print(f'添加分页符后页数: {new_page_count}')
else:
print(f'页数已是偶数,无需修改')
doc.Close()
return True
except Exception as e:
print(f'处理失败: {os.path.basename(file_path)}, 错误: {str(e)}')
return False
finally:
if word:
word.Quit()
pythoncom.CoUninitialize()
# 处理所有文件
for file in os.listdir(final_word_folder):
if file.endswith('.docx') and not file.startswith('~$'):
full_path = os.path.join(final_word_folder, file)
process_page_count(full_path)
# 合并所有Word文档
def merge_word_documents(output_path):
pythoncom.CoInitialize()
word = None
try:
word = win32.DispatchEx('Word.Application')
word.Visible = False
# 获取所有要合并的Word文件
files = sorted([f for f in os.listdir(final_word_folder) if f.endswith('.docx') and not f.startswith('~$')])
if not files:
print("没有找到要合并的Word文档")
return False
# 使用第一个文档作为主文档
main_file = os.path.join(final_word_folder, files[0])
doc = word.Documents.Open(main_file)
# 插入其他文档内容
for file in files[1:]:
file_path = os.path.join(final_word_folder, file)
print(f"正在合并文件: {file}")
# 移动到文档末尾
end_range = doc.Content
end_range.Collapse(Direction=0) # 0=wdCollapseEnd
# 插入分页符
end_range.InsertBreak(Type=7) # 7=wdPageBreak
# 插入文件内容
end_range.InsertFile(file_path)
# 保存合并后的文档
doc.SaveAs(output_path)
doc.Close()
print(f"所有文档已成功合并到: {output_path}")
return True
except Exception as e:
print(f'合并失败, 错误: {str(e)}')
return False
finally:
if word:
word.Quit()
pythoncom.CoUninitialize()
# 执行合并
merged_file_path = os.path.join(source_folder, "06(双面正反打印用)合并在编教师全部金点子征集表.docx")
merge_word_documents(merged_file_path)
print("所有操作已完成!")



每个人的作业(显示每个人都填了一份电子稿)


问卷星的AI报告

合并正反打印(所以1份必须是双数,这里还是需要手动调整的,有的第3页正好一个回车,需要手动删除)

发给领导看


二、二大员版(保育员、营养员)
然后领导又设计一份保育员的问卷(比教师版的题目少,简单)

前期教师问卷时问卷星电脑查看,每次查询“谁没有做”比较烦,因此轮到保育员填写时,我就用了“接龙管家”预设了保育员名单)



保育员的问卷简单多了。而且可以看到那些老师没有填写

接龙管家导出数据只有一个“文本版”


制作WORD和EXCEL的模版


AI解决的问题




来回生成了十几份代码才解决了“多选”的问题
# # -*- coding:utf-8 -*-
'''
目的:接龙管家金点子(保育员版)采集做成每人一页
1.把问卷星下载EXCEL数字版,导入docx
2、去除AI的星号、井号、短横
3、识别docx是共有几页,单数还是双数,单数需要插入换页符(1个空白页)
4、合并成一个docx。打印
作者:deepseek,阿夏
日期:20250628
'''
import os
import time
import shutil
import pythoncom
import win32com.client as win32
import pandas as pd
from docxtpl import DocxTemplate
# 配置路径
source_folder = r'C:Usersjg2yXRZOneDrive桌面20250628金点子2三大员'
source_folder1 = os.path.join(source_folder, '03编程内容')
temp_word_folder = os.path.join(source_folder, '04保育员WORD')
final_word_folder = os.path.join(source_folder, '05最终WORD') # 新增最终文件夹
os.makedirs(temp_word_folder, exist_ok=True)
os.makedirs(final_word_folder, exist_ok=True)
# 读取Excel数据
excel_path = os.path.join(source_folder1, 'py.xlsx')
df = pd.read_excel(excel_path, sheet_name='反馈列表')
# 选项映射表(选项文本 → 模板字段名)
OPTION_MAPPING = {
"温馨和谐的园所环境": "q11",
"以儿童为中心的教育理念": "q12",
"团结协作的教职工团队文化": "q13",
"丰富的传统文化传承": "q14",
"特色课程与活动设计": "q15",
"家园社协同育人模式": "q16",
"其他______(请补充)": "q17"
}
def get_display_width(text):
"""计算字符串的显示宽度(中文算2个字符,英文算1个)"""
return sum(2 if 'u4e00' <= char <= 'u9fff' else 1 for char in str(text))
print('----开始生成文档----')
for index, row in df.iterrows():
# 处理姓名和编号
full_name = str(row['name'])
name = full_name[2:] if len(full_name) > 2 else full_name
num = full_name[:2] if len(full_name) > 2 else f"{index+1:02d}"
# 初始化上下文
context = {
"name": name,
"q2": row['q2'],
"q3": row['q3']
}
# 初始化所有选项为未选中
for field in OPTION_MAPPING.values():
context[field] = "□"
# 处理选中的选项
selected_items = str(row['q1']).split(',')
for item in selected_items:
item = item.strip()
if item in OPTION_MAPPING:
context[OPTION_MAPPING[item]] = "☑"
# 加载并渲染模板
tpl = DocxTemplate(os.path.join(source_folder1, 'py.docx'))
tpl.render(context)
# 处理文件名(确保名称对齐)
name_width = get_display_width(name)
name_part = name + ' ' * ((6 - name_width) // 2) # 中文对齐调整
# 生成文件名(格式:01_姓名_2025幼儿园'景文化'金点子征集表.docx)
file_name = f"{num}_{name_part}_2025幼儿园'景文化'金点子征集表.docx"
temp_file_path = os.path.join(temp_word_folder, file_name)
# 保存文件
tpl.save(temp_file_path)
print(f"已生成文件: {file_name}")
time.sleep(0.5)
print('----文档生成完成----')
# 清理特殊字符
print('
----清理特殊字符----')
special_chars = ['*', '#', '-']
def clean_word_file(file_path, output_path):
pythoncom.CoInitialize()
word = None
try:
word = win32.DispatchEx('Word.Application')
word.Visible = False
doc = word.Documents.Open(file_path)
for char in special_chars:
word.Selection.Find.Execute(char, False, False, False, False, False, True, 1, True, "", 2)
doc.SaveAs(output_path)
doc.Close()
return True
except Exception as e:
print(f'处理失败: {os.path.basename(file_path)}, 错误: {e}')
return False
finally:
if word:
word.Quit()
pythoncom.CoUninitialize()
# 处理所有Word文件
for file in os.listdir(temp_word_folder):
if file.endswith('.docx') and not file.startswith('~$'):
source = os.path.join(temp_word_folder, file)
target = os.path.join(final_word_folder, file)
if not clean_word_file(source, target):
shutil.copy2(source, target)
def process_page_count(file_path):
"""检查文档页数并在单数页时添加分页符"""
pythoncom.CoInitialize()
word = None
try:
word = win32.DispatchEx('Word.Application')
word.Visible = False
doc = word.Documents.Open(file_path)
# 获取文档页数
page_count = doc.ComputeStatistics(2) # 2表示统计页数
print(f'处理文档: {os.path.basename(file_path)} - 当前页数: {page_count}')
if page_count % 2 == 1:
print(f'添加分页符使页数变为偶数')
# 移动到文档末尾
end_range = doc.Content
end_range.Collapse(Direction=0) # 0=wdCollapseEnd
# 插入分页符
end_range.InsertBreak(Type=7) # 7=wdPageBreak
doc.Save()
new_page_count = doc.ComputeStatistics(2)
print(f'添加分页符后页数: {new_page_count}')
else:
print(f'页数已是偶数,无需修改')
doc.Close()
return True
except Exception as e:
print(f'处理失败: {os.path.basename(file_path)}, 错误: {str(e)}')
return False
finally:
if word:
word.Quit()
pythoncom.CoUninitialize()
# 处理所有文件
for file in os.listdir(final_word_folder):
if file.endswith('.docx') and not file.startswith('~$'):
full_path = os.path.join(final_word_folder, file)
process_page_count(full_path)
# 合并所有Word文档
def merge_word_documents(output_path):
pythoncom.CoInitialize()
word = None
try:
word = win32.DispatchEx('Word.Application')
word.Visible = False
# 获取所有要合并的Word文件
files = sorted([f for f in os.listdir(final_word_folder) if f.endswith('.docx') and not f.startswith('~$')])
if not files:
print("没有找到要合并的Word文档")
return False
# 使用第一个文档作为主文档
main_file = os.path.join(final_word_folder, files[0])
doc = word.Documents.Open(main_file)
# 插入其他文档内容
for file in files[1:]:
file_path = os.path.join(final_word_folder, file)
print(f"正在合并文件: {file}")
# 移动到文档末尾
end_range = doc.Content
end_range.Collapse(Direction=0) # 0=wdCollapseEnd
# 插入分页符
end_range.InsertBreak(Type=7) # 7=wdPageBreak
# 插入文件内容
end_range.InsertFile(file_path)
# 保存合并后的文档
doc.SaveAs(output_path)
doc.Close()
print(f"所有文档已成功合并到: {output_path}")
return True
except Exception as e:
print(f'合并失败, 错误: {str(e)}')
return False
finally:
if word:
word.Quit()
pythoncom.CoUninitialize()
# 执行合并
merged_file_path = os.path.join(source_folder, "06(双面正反打印用)合并二大员全部金点子征集表.docx")
merge_word_documents(merged_file_path)
print("所有操作已完成!")

最后把所有内容合并,便于打印。
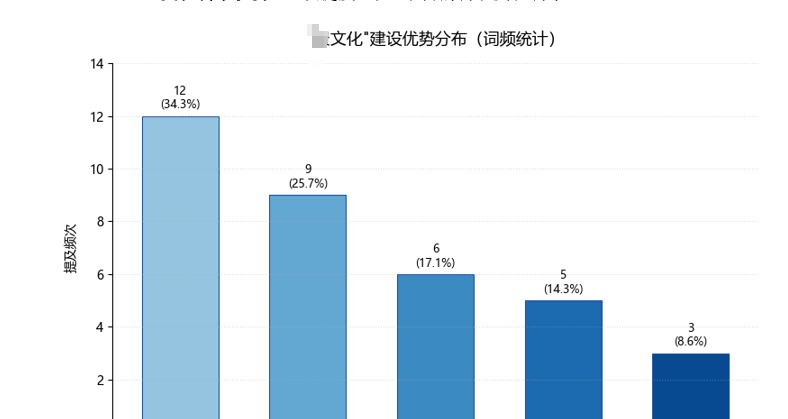
 AI报告:把EXCEL放到deepseek里进行分析,并画好柱状图
AI报告:把EXCEL放到deepseek里进行分析,并画好柱状图


把文字先复制到WORD里,然后再用Python做图




最后做了三组图
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 微软雅黑
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 数据准备
advantages = ['环境创设', '教育理念', '团队协作', '课程特色', '文化传承']
frequencies = [12, 9, 6, 5, 3]
x_pos = np.arange(len(advantages)) # x轴位置
# 创建蓝色渐变配色(从浅蓝到深蓝)
colors = plt.cm.Blues(np.linspace(0.4, 0.9, len(advantages)))
# 创建图表
plt.figure(figsize=(8, 5)) # 调整画布比例
bars = plt.bar(x_pos, frequencies, color=colors, edgecolor='#1E50A0', linewidth=0.8, width=0.6)
# 图表美化
plt.title('"景文化"建设优势分布(词频统计)', pad=15, fontsize=13)
plt.xticks(x_pos, advantages, rotation=0) # 设置x轴标签
plt.ylim(0, 14) # y轴范围
plt.ylabel('提及频次', labelpad=8) # y轴标签
# 添加数据标签(显示频次+百分比)
total = sum(frequencies)
for i, bar in enumerate(bars):
height = bar.get_height()
percentage = 100 * height / total
plt.text(bar.get_x() + bar.get_width()/2.,
height + 0.2,
f'{height}
({percentage:.1f}%)',
ha='center',
va='bottom',
fontsize=9,
linespacing=1.2)
# 网格线和边框设置
plt.grid(axis='y', linestyle=':', alpha=0.4)
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
plt.tight_layout()
plt.show()import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 数据准备
keywords = ['自然', '和谐/温馨', '成长', '家园', '色彩']
counts = [18, 15, 12, 9, 7]
colors = plt.cm.Blues([0.5, 0.6, 0.7, 0.8, 0.9]) # 蓝色渐变
# 创建环形图
fig, ax = plt.subplots(figsize=(8, 6))
wedges, texts, autotexts = ax.pie(
counts,
labels=keywords,
colors=colors,
autopct='%1.1f%%',
pctdistance=0.85,
startangle=90,
wedgeprops={'width': 0.4, 'edgecolor': 'white', 'linewidth': 2}
)
# 美化标签
plt.setp(autotexts, color='white', fontweight='bold')
plt.setp(texts, fontsize=10)
# 添加中心标题
ax.text(0, 0, '关键词
频次', ha='center', va='center', fontsize=12, fontweight='bold')
plt.title('"景文化"理解关键词分布(n=30)', pad=20)
plt.tight_layout()
plt.show()# 数据准备
categories = ['环境育人型', '理念传递型', '情感联结型']
percentages = [45, 35, 20]
colors = ['#5B9BD5', '#4472C4', '#2F5597'] # 阶梯蓝色
# 创建环形图
fig, ax = plt.subplots(figsize=(8, 6))
wedges, texts, autotexts = ax.pie(
percentages,
labels=categories,
colors=colors,
autopct='%1.1f%%',
pctdistance=0.8,
startangle=90,
wedgeprops={'width': 0.4, 'edgecolor': 'white', 'linewidth': 2}
)
# 美化标签
plt.setp(autotexts, color='white', fontweight='bold')
plt.setp(texts, fontsize=10)
# 添加中心标题
ax.text(0, 0, '理解模式
占比', ha='center', va='center', fontsize=12, fontweight='bold')
plt.title('"景文化"理解模式分类(n=30)', pad=20)
plt.tight_layout()
plt.show()


最后,二大员的问卷也完成了

三、感悟:
一些难题通过AI自动解答,不再需要自己去理解,让模版变量的制作效率大大提高。本次的基于条件“插入符号”就是一个例子。
人工智能真的解决了大问题
© 版权声明
文章版权归作者所有,未经允许请勿转载。如内容涉嫌侵权,请在本页底部进入<联系我们>进行举报投诉!
THE END























暂无评论内容