
文章目录
Flink城市交通实时监控平台
1 项目整体介绍
1.1 项目架构
1.2 项目数据流
1.3 项目主要模块
2 数据采集
logback日志配置
数据采集服务器接口
模拟实际交通数据
3 项目数据字典
3.1 卡口车辆采集数据
3.2 城市交通管理数据表
3.3 车辆轨迹数据表
4 实时卡口监控分析
4.1 flume采集日志数据写入kafka
4.2 实时车辆超速监控
4.3 实时卡口拥堵情况监控
4.4 实时最通畅的 TopN 卡口
5 智能实时报警
5.1 实时套牌分析
5.2 实时危险驾驶分析
5.3 违法王车辆轨迹跟踪
6 实时车辆布控
6.1 实时车辆分布情况
6.2 布隆过滤器(BloomFilter)
布隆过滤器的原理
Trigger的作用
Flink城市交通实时监控平台
1 项目整体介绍
近几年来,随着国内经济的快速发展,高速公路建设步伐不断加快,全国机动车辆、驾驶员数量迅速增长,交通管理工作日益繁重,压力与日俱增。为了提高公安交通管理工作的科学化、现代化水平,缓解警力不足,加强和保障道路交通的安全、有序和畅通,减少道路交通违法和事故的发生,全国各地建设和使用了大量的“电子警察”、“高清卡口”、“固定式测速”、“区间测速”、“便携式测速”、“视频监控”、“预警系统”、“能见度天气监测系统”、“LED信息发布系统”等交通监控系统设备。尽管修建了大量的交通设施,增加了诸多前端监控设备,但交通拥挤阻塞、交通安全状况仍然十分严重。由于道路上交通监测设备种类和生产厂家繁多,目前还没有一个统一的数据采集和交换标准,无法对所有的设备、数据进行统一、高效的管理和应用,造成各种设备和管理软件混用的局面,给使用单位带来了很多不便,使得国家大量的基础建设投资未达到预期的效果。各交警支队的设备大都采用本地的数据库管理,交警总队无法看到各支队的监测设备及监测信息,严重影响到全省交通监测的宏观管理;目前网络状况为设备专网、互联网、公安网并存的复杂情况,需要充分考虑公安网的安全性,同时要保证数据的集中式管理;监控数据需要与“六合一”平台、全国机动车稽查布控系统等的数据对接,迫切需要一个全盘考虑面向交警交通行业的智慧交通管控指挥平台系统。
智慧交通管控指挥平台建成后,达到了以下效果目标:
交通监视和疏导:通过系统将监视区域内的现场图像传回指挥中心,使管理人员直接掌握车辆排队、堵塞、信号灯等交通状况,及时调整信号配时或通过其他手段来疏导交通,改变交通流的分布,以达到缓解交通堵塞的目的。
交通警卫:通过突发事件的跟踪,提高处置突发事件的能力。
建立公路事故、事件预警系统的指标体系及多类分析预警模型,实现对高速公路通行环境、交通运输对象、交通运输行为的综合分析和预警,建立真正意义上的分析及预警体系。
及时准确地掌握所监视路口、路段周围的车辆、行人的流量、交通治安情况等,为指挥人员提供迅速直观的信息从而对交通事故和交通堵塞做出准确判断并及时响应。
收集、处理各类公路网动静态交通安全信息,分析研判交通安全态势和事故隐患,并进行可视化展示和预警提示。
提供接口与其他平台信息共享和关联应用,基于各类动静态信息的大数据分析处理,实现交通违法信息的互联互通、源头监管等功能。
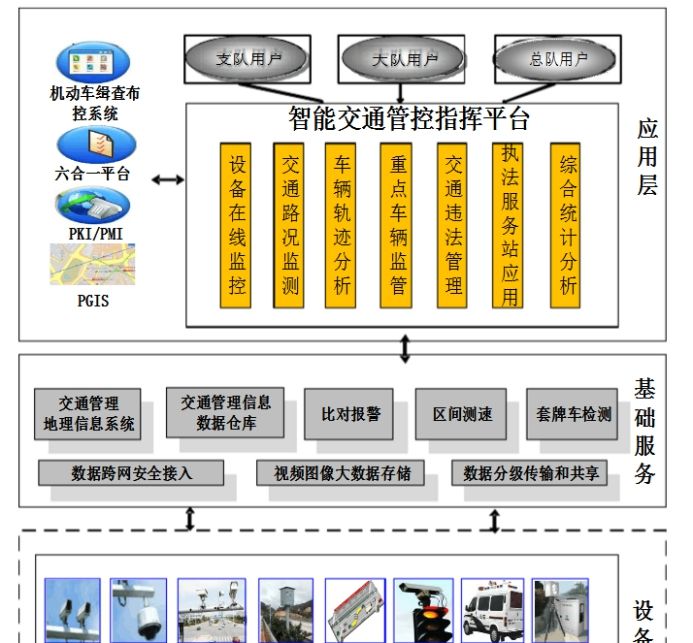
1.1 项目架构
本项目是与公安交通管理综合应用平台、机动车缉查布控系统等对接的,并且基于交通部门现有的数据平台上,进行的数据实时分析项目。
相关概念
卡口:道路上用于监控的某个点,可能是十字路口,也可能是高速出口等。

通道:每个卡口上有多个摄像头,每个摄像头有拍摄的方向,这些摄像头也叫通道。
“违法王“车辆:该车辆违法未处理超过50次以上的车。

摄像头拍照识别:
一次拍照识别:经过卡口摄像头进行的识别,识别对象的车辆号牌信息、车辆号牌颜色信息等,基于车辆号牌和车辆颜色信息,能够实现基本的违法行为辨识、车辆黑白名单比对报警等功能。
二次拍照识别:可以通过时间差和距离自动计算出车辆的速度。
1.2 项目数据流
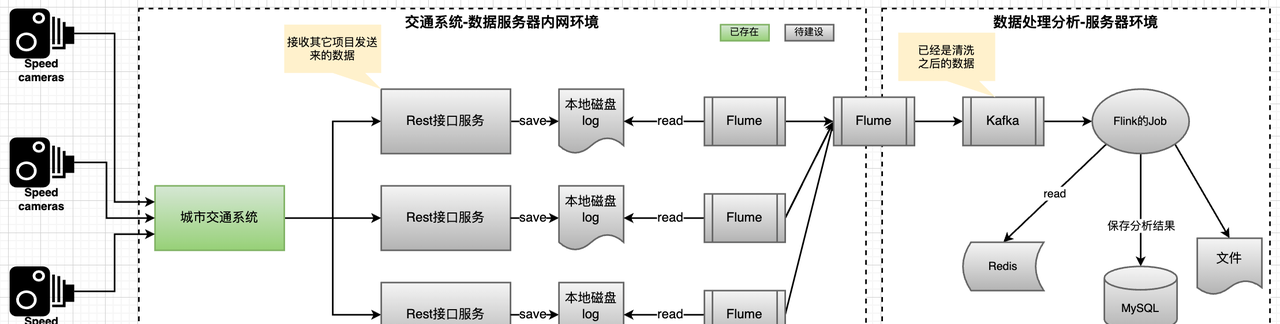
实时处理流程:Http请求 → 数据采集接口 → 数据目录 → flume监控目录(监控目录下的文件按照日期分区) → Kafka → Flink分析数据 → MySQL(给运营中心使用)。
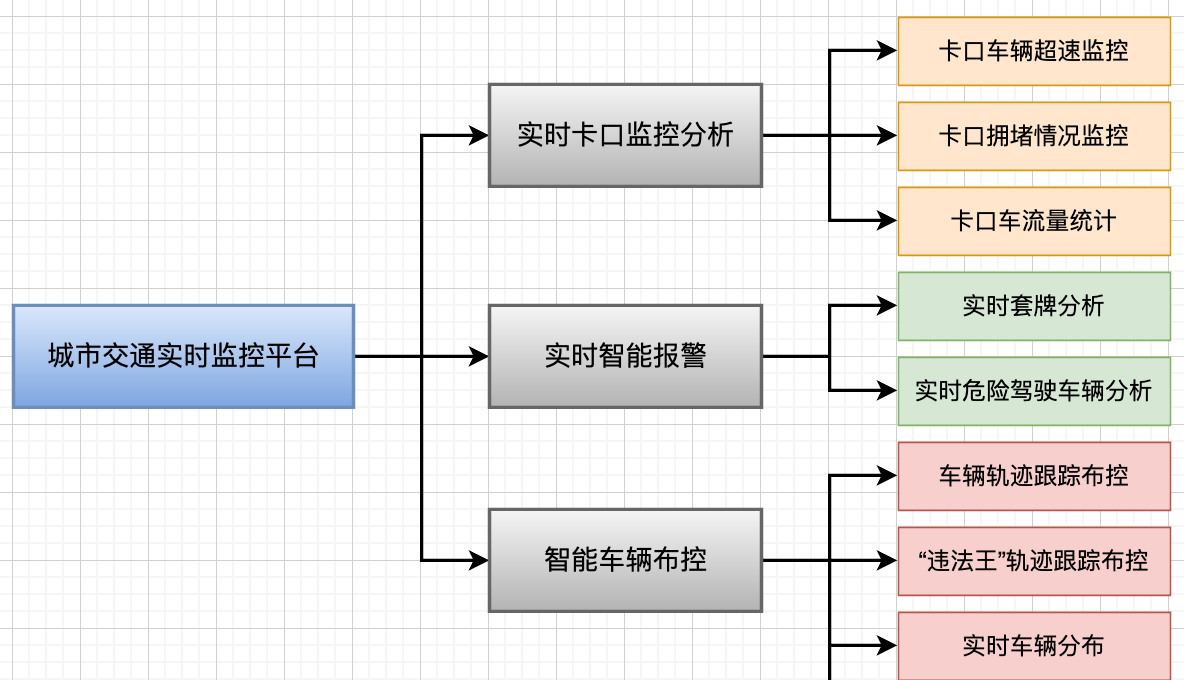
1.3 项目主要模块
本项目的主要模块有三个方向:
实时卡口监控分析:依托卡口云管控平台达到降事故、保畅通、服务决策、引领实战的目的,最大限度指导交通管理工作。丰富了办案手段,提高了办案效率、节省警力资源,最终达到牵引警务模式的变革。利用摄像头拍摄的车辆数据来分析每个卡口车辆超速监控、卡口拥堵情况监控、每个区域卡口车流量TopN统计。
实时智能报警:该模块主要针对路口一些无法直接用单一摄像头拍摄违章的车辆,通过海量数据分析并实时智能报警。在一时间段内同时在 2 个区域出现的车辆记录则为可能为套牌车。这个模块包括:实时套牌分析,实时危险驾驶车辆分析。
智能车辆布控:该模块主要从整体上实时监控整个城市的车辆情况,并且对整个城市中出现“违法王”的车辆进行布控。主要功能包括:单一车辆轨迹跟踪布控,“违法王”轨迹跟踪布控,实时车辆分布分析,实时外地车分布分析。
2 数据采集
logback日志配置
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false">
<!-- 定义日志文件的存储地址 -->
<property name="LOG_SYSTEM" value="logs/system"/>
<property name="LOG_COMMON" value="logs/common"/>
<!-- %m输出的信息, %p日志级别, %t线程名, %d日期, %c类的全名, %i索引 -->
<!-- appender是configuration的子节点,是负责写日志的组件 -->
<!-- 控制台输出 -->
<!-- ConsoleAppender把日志输出到控制台 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度,%msg:日志消息,%n是换行符-->
<pattern>%msg%n</pattern>
<!--<!– 控制台也要使用utf-8,不要使用gbk –>-->
<!--<charset>UTF-8</charset>-->
</encoder>
</appender>
<!-- 按照每天生成系统日志文件 -->
<appender name="SYSTEM_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<FileNamePattern>${LOG_SYSTEM}/system_%d{yyyy-MM-dd}_%i.log</FileNamePattern>
<MaxHistory>15</MaxHistory>
<maxFileSize>256MB</maxFileSize>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %c - %msg%n</pattern>
</encoder>
</appender>
<!-- RollingFileAppender:滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 -->
<!-- 1.先按日期存日志,日期变了,将前一天的日志文件名重命名为xxx%日期%索引,新的日志仍然是xxx.log -->
<!-- 2.如果日期没有变化,但是当前日志文件的大小超过 256M 时,对当前日志进行分割 重名名 -->
<!-- 按照每天生成通用日志文件,单个文件超过256M则拆分 -->
<appender name="COMMON_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 活动文件的名字会根据fileNamePattern的值,每隔一段时间改变一次 -->
<FileNamePattern>${LOG_COMMON}/log_%d{yyyy-MM-dd}_%i.log</FileNamePattern>
<!-- 每产生一个日志文件,该日志文件的保存期限为15天 -->
<MaxHistory>15</MaxHistory>
<!-- maxFileSize:这是活动文件的大小,默认值是10MB,这里设置256M -->
<maxFileSize>256MB</maxFileSize>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!-- pattern节点,用来设置日志的输入格式 -->
<pattern>%msg%n</pattern>
<!--<!– 记录日志的编码 –>-->
<!--<charset>UTF-8</charset> <!– 此处设置字符集 –>-->
</encoder>
</appender>
<!-- 控制台日志输出级别 -->
<!-- 日志输出级别 -->
<root level="INFO">
<!-- 启动name为“STDOUT”的日志级别,默认可以配置多个 -->
<appender-ref ref="STDOUT"/>
<appender-ref ref="SYSTEM_FILE"/>
</root>
<!-- 在哪些包下,日志输出的级别 -->
<!-- 指定项目中某个包,当有日志操作行为时的日志记录级别 -->
<!-- 级别依次为【从高到低】:FATAL > ERROR > WARN > INFO > DEBUG > TRACE -->
<logger name="com.yw.datacollector.service.DataService" level="INFO" additivity="false">
<appender-ref ref="STDOUT"/>
<appender-ref ref="COMMON_FILE"/>
</logger>
</configuration>
数据采集服务器接口
DataController
@RestController
@RequestMapping("/api")
public class DataController {
@Resource
private DataService dataService;
@PostMapping("/sendData/{dataType}")
public RestResponse<Void> collect(@PathVariable("dataType") String dataType,
HttpServletRequest request) {
dataService.process(dataType, request);
return RestResponse.success();
}
}
DataService
@Slf4j
@Service
public class DataService {
public void process(String dataType, HttpServletRequest request) {
// 校验数据类型
if (StringUtils.isBlank(dataType)) {
throw new CustomException(RestResponseCode.LOG_TYPE_ERROR);
}
// 校验请求头中是否传入数据
int contentLength = request.getContentLength();
if (contentLength < 1) {
throw new CustomException(RestResponseCode.REQUEST_CONTENT_INVALID);
}
// 从请求request中读取数据
byte[] bytes = new byte[contentLength];
try (BufferedInputStream bis = new BufferedInputStream(request.getInputStream())){
// 最大尝试读取的次数
int maxTryTimes = 100;
int tryTimes = 0, totalReadLength = 0;
while (totalReadLength < contentLength && tryTimes < maxTryTimes) {
int readLength = bis.read(bytes, totalReadLength, contentLength - totalReadLength);
if (readLength < 0) {
throw new CustomException(RestResponseCode.BAD_NETWORK);
}
totalReadLength += readLength;
if (totalReadLength == contentLength) {
break;
}
tryTimes++;
TimeUnit.MILLISECONDS.sleep(200);
}
if (totalReadLength < contentLength) {
// 经过多处的读取,数据仍然没有读完
throw new CustomException(RestResponseCode.BAD_NETWORK);
}
String jsonData = new String(bytes, StandardCharsets.UTF_8);
log.info(jsonData);
} catch (Exception e) {
throw new CustomException(RestResponseCode.SYSTEM_ERROR, e.getMessage());
}
}
}
Mock发送请求数据
public class SendDataToServer {
public static void main(String[] args) throws Exception {
String url = "http://localhost:8686/api/sendData/traffic_data";
HttpClient client = HttpClients.createDefault();
int i = 0;
while (i < 20) {
HttpPost post = new HttpPost(url);
post.setHeader("Content-Type", "application/json");
String data = "11,22,33,京P12345,57.2," + i;
post.setEntity(new StringEntity(data, StandardCharsets.UTF_8));
HttpResponse response = client.execute(post); //发送数据
i++;
TimeUnit.SECONDS.sleep(1);
//响应的状态如果是200的话,获取服务器返回的内容
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
String result = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(result);
}
}
}
}
启动SpringBoot应用程序,并运行 SendDataToServer,可以看到设置的日志目录下生成的日志文件
模拟实际交通数据
public class CreateDatas {
public static void main(String[] args) throws Exception {
String url = "http://localhost:8686/api/sendData/traffic_data";
HttpClient client = HttpClients.createDefault();
String result = null;
String[] locations = {
"湘", "京", "京", "京", "京", "京", "京", "鲁", "皖", "鄂"};
// 模拟生成一天的数据
String day = "2025-06-21";
// 初始化高斯分布的对象
JDKRandomGenerator generator = new JDKRandomGenerator();
generator.setSeed(10);
GaussianRandomGenerator rg = new GaussianRandomGenerator(generator);
Random r = new Random();
// 模拟30000台车
for (int i = 0; i < 30000; i++) {
// 得到随机的车牌
String car = locations[r.nextInt(locations.length)] + (char) (65 + r.nextInt(26)) + String.format("%05d", r.nextInt(100000));
// 随机的小时
String hour = String.format("%02d", r.nextInt(24));
// 一天内,在一个城市里面,一辆车大概率经过30左右的卡口
double v = rg.nextNormalizedDouble(); // 标准高斯分布的随机数据,大概率在-1 到 1
int count = (int) (Math.abs(30 + 30 * v) + 1); // 一辆车一天内经过的卡口数量
for (int j = 0; j < count; j++) {
// 如果count超过30,为了数据更加真实,时间要1小时
if (j % 30 == 0) {
int newHour = Integer.parseInt(hour) + 1;
if (newHour == 24) {
newHour = 0;
}
hour = String.format("%02d", newHour);
}
// 经过卡口的时间
String time = day + " " + hour + ":" + String.format("%02d", r.nextInt(60)) + ":" + String.format("%02d", r.nextInt(60));
long actionTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(time).getTime();
// 卡口ID
String monitorId = String.format("%04d", r.nextInt(10000));
// 随机道路
String roadId = String.format("%02d", r.nextInt(100));
String areaId = String.format("%02d", r.nextInt(100));
String cameraId = String.format("%05d", r.nextInt(100000));
// 随机速度
double v2 = rg.nextNormalizedDouble();
String speed = String.format("%.1f", Math.abs(40 + (40 * v2))); //均值40,标准差是30
String data = actionTime + "," + monitorId + "," + cameraId + "," + car + "," + speed + "," + roadId + "," + areaId;
System.out.println(data);
HttpPost post = new HttpPost(url);
post.setHeader("Content-Type", "application/json");
post.setEntity(new StringEntity(data, StandardCharsets.UTF_8));
// 发送数据
HttpResponse response = client.execute(post);
TimeUnit.MILLISECONDS.sleep(200);
// 响应的状态如果是200的话,获取服务器返回的内容
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
result = EntityUtils.toString(response.getEntity(), "UTF-8");
}
System.out.println(result);
}
}
}
}
3 项目数据字典
3.1 卡口车辆采集数据
卡口数据通过 Flume 采集过来之后存入 Kafka 中,其中数据的格式为:
(
`action_time` long --摄像头拍摄时间戳,精确到秒,
`monitor_id` string --卡口号,
`camera_id` string --摄像头编号,
`car` string --车牌号码,
`speed` double --通过卡扣的速度,
`road_id` string --道路 id,
`area_id` string --区域 id
)
其中每个字段之间使用逗号隔开。区域 ID 代表一个城市的行政区域;摄像头编号:一个卡口往往会有多个摄像头,每个摄像头都有一个唯一编号;道路ID:城市中每一条道路都有名字,比如:蔡锷路。交通部门会给蔡锷路一个唯一编号。
3.2 城市交通管理数据表
Mysql 数据库中有两张表是由城市交通管理平台提供的,本项目需要读取这两张表的数据来进行分析计算。
城市区域表:t_area_info
drop table if exists `t_area_info`;
create table `t_area_info`(`area_id` varchar(255) default null, `area_name` varchar(255) default null);
-- 导入数据
insert into `t_area_info` values
('01', '海淀区'),
('02', '昌平区'),
('03', '朝阳区'),
('04', '顺义区'),
('05', '西城区'),
('06', '东城区'),
('07', '大兴区'),
('08', '石景区');
城市“违法”车辆列表:城市“违法”车辆,一般是指需要进行实时布控的违法车辆。
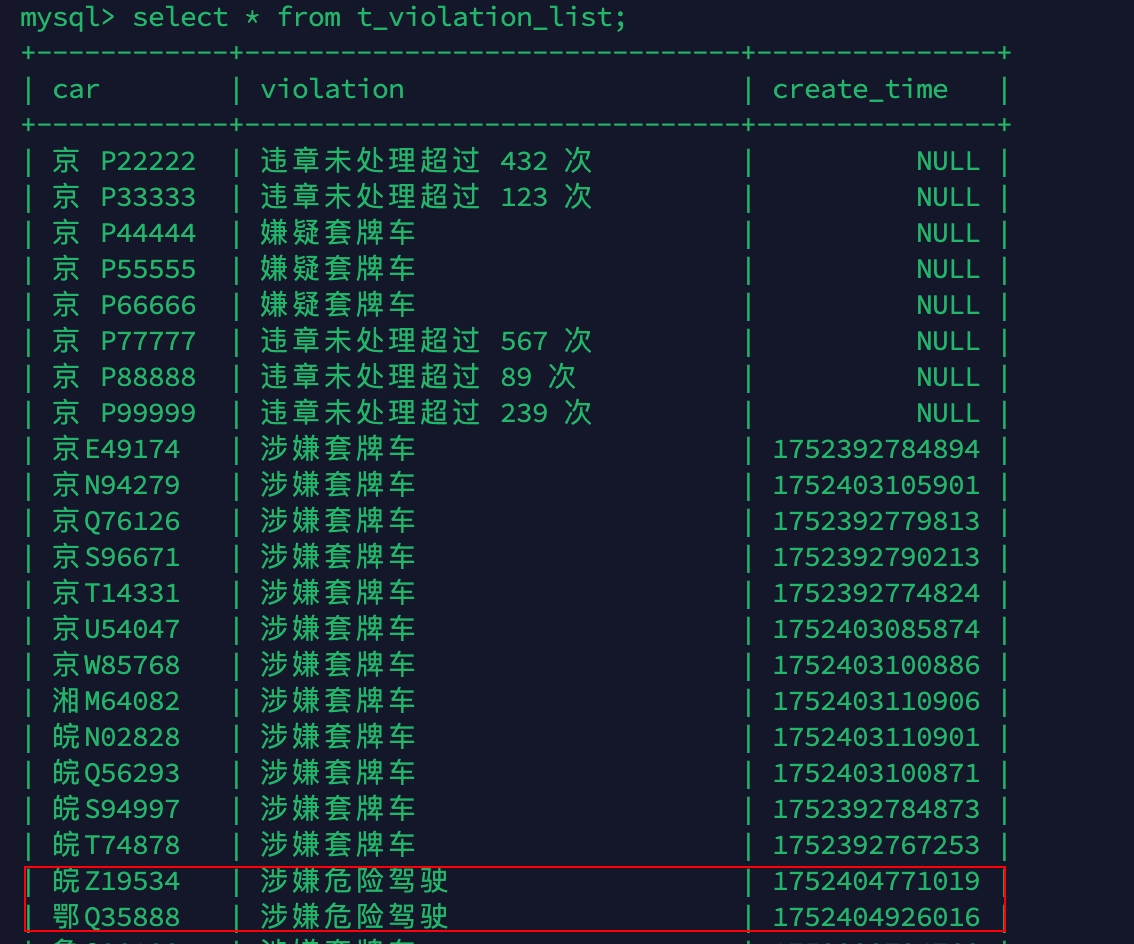
drop table if exists `t_violation_list`;
create table `t_violation_list` (
`car` varchar(255) not null,
`violation` varchar(1000) default null,
`create_time` bigint(20) default null,
primary key (`car`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 导入数据
insert into `t_violation_list` values
('京 P88888', '违章未处理超过 89 次',null),
('京 P99999', '违章未处理超过 239 次',null),
('京 P77777', '违章未处理超过 567 次',null),
('京 P66666', '嫌疑套牌车',null),
('京 P55555', '嫌疑套牌车',null),
('京 P44444', '嫌疑套牌车',null),
('京 P33333', '违章未处理超过 123 次',null),
('京 P22222', '违章未处理超过 432 次',null);
城市卡口限速信息表:
drop table if exists `t_monitor_info`;
create table `t_monitor_info` (
`monitor_id` varchar(255) not null,
`road_id` varchar(255) not null,
`speed_limit` int(11) default null,
`area_id` varchar(255) default null,
primary key (`monitor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 导入数据
insert into `t_monitor_info` values
('0000', '02', 60, '01'),
('0001', '02', 60, '02'),
('0002', '03', 80, '01'),
('0004', '05', 100, '03'),
('0005', '04', 0, NULL),
('0021', '04', 0, NULL),
('0023', '05', 0, NULL);
3.3 车辆轨迹数据表
在智能车辆布控模块中,需要保存一些车辆的实时行驶轨迹,为了方便其他部门和项目方便查询获取,我们在 Mysql 数据库设计一张车辆实时轨迹表。
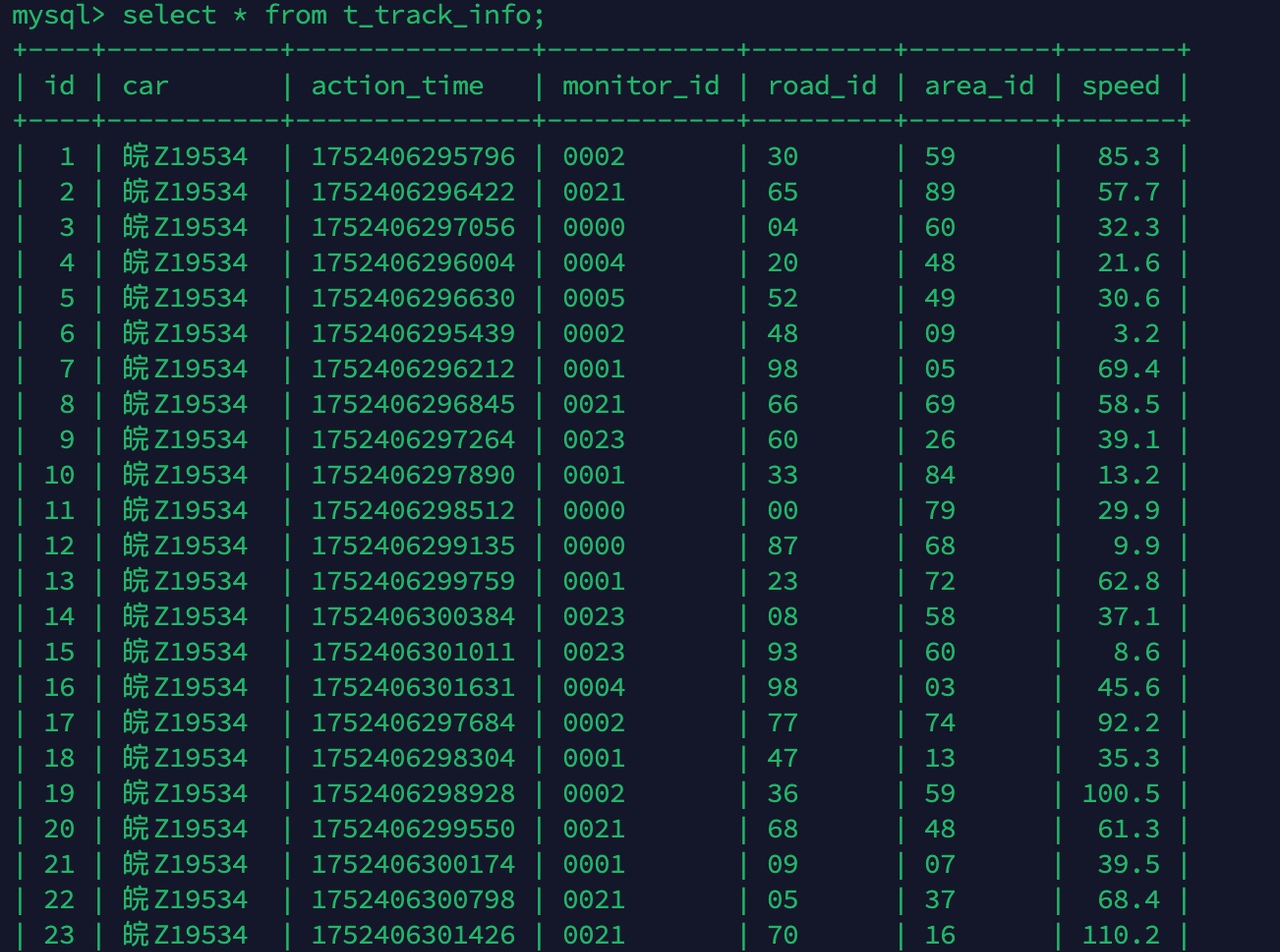
drop table if exists `t_track_info`;
create table `t_track_info` (
`id` int(11) not null AUTO_INCREMENT,
`car` varchar(255) default null,
`action_time` bigint(20) default null,
`monitor_id` varchar(255) default null,
`road_id` varchar(255) default null,
`area_id` varchar(255) default null,
`speed` double default null,
primary key (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
4 实时卡口监控分析
4.1 flume采集日志数据写入kafka
创建kafka topic
./kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic traffic_topic --partitions 3 --replication-factor 3
编写 flume 采集配置脚本
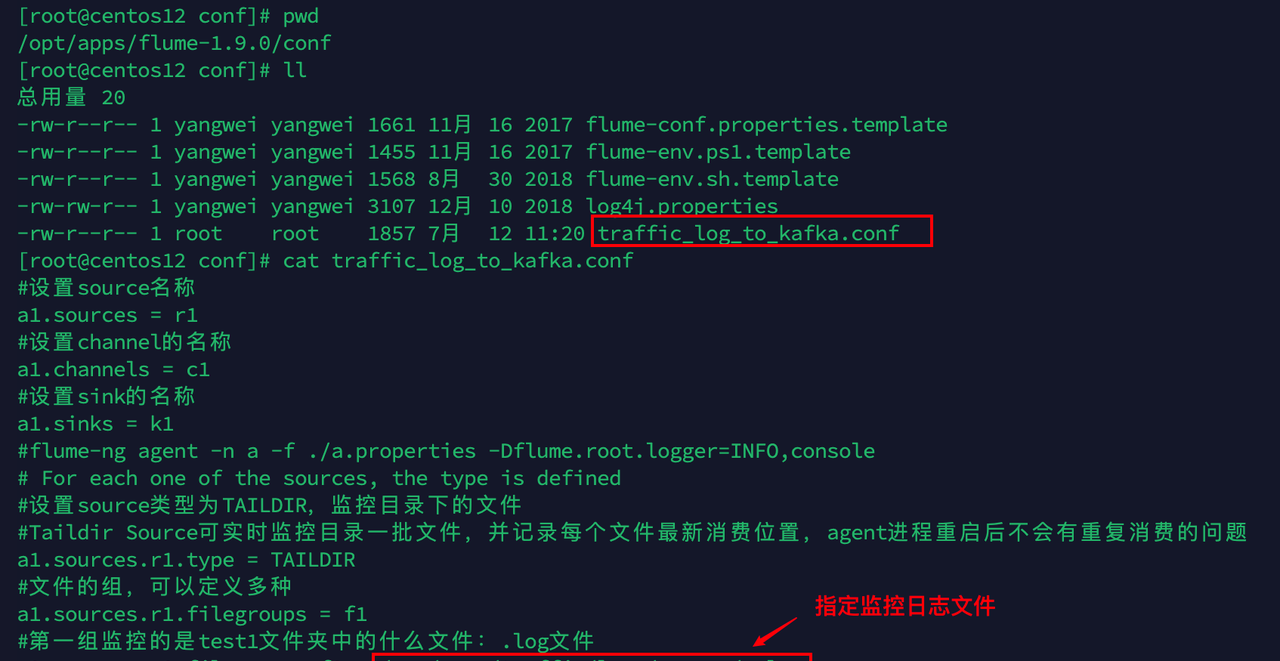
#设置source名称
a1.sources = r1
#设置channel的名称
a1.channels = c1
#设置sink的名称
a1.sinks = k1
#flume-ng agent -n a -f ./a.properties -Dflume.root.logger=INFO,console
# For each one of the sources, the type is defined
#设置source类型为TAILDIR,监控目录下的文件
#Taildir Source可实时监控目录一批文件,并记录每个文件最新消费位置,agent进程重启后不会有重复消费的问题
a1.sources.r1.type = TAILDIR
#文件的组,可以定义多种
a1.sources.r1.filegroups = f1
#第一组监控的是test1文件夹中的什么文件:.log文件
a1.sources.r1.filegroups.f1 = ${RT_MONITOR_COLLECTOR_PATH}/logs/common/.*log
#第二组监控的是test2文件夹中的什么文件:以.txt结尾的文件
#a.sources.r1.filegroups.f2 = /software/logs/system/*.txt
# The channel can be defined as follows.
#设置source的channel名称
a1.sources.r1.channels = c1
a1.sources.r1.max-line-length = 1000000
#a.sources.r1.eventSize = 512000000
# Each channel's type is defined.
#设置channel的类型
a1.channels.c1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
#设置channel道中最大可以存储的event数量
a1.channels.c1.capacity = 1000
#每次最大从source获取或者发送到sink中的数据量
a1.channels.c1.transcationCapacity = 100
# Each sink's type must be defined
#设置Kafka接收器
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
a1.sinks.k1.brokerList = node1:9092,node2:9092,node3:9092
#设置Kafka的Topic
a1.sinks.k1.topic = traffic_topic
#设置序列化方式
a1.sinks.k1.serializer.class = kafka.serializer.StringEncoder
#Specify the channel the sink should use
#设置sink的channel名称
a1.sinks.k1.channel = c1
启动flume采集
bin/flume-ng agent -c conf -f conf/traffic_log_to_kafka.conf -n a1 -Dflume.root.logger=INFO,console
测试kafka接收到日志采集数据
./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic traffic_topic --from-beginning
启动数据采集接口服务和数据生产方法,可以看到数据实时产生,并能实时被flume采集上报到Kafka中被消费。
打包数据采集应用,并将应用部署到服务器 node3 上
[root@centos12 traffic]# pwd
/usr/apps/traffic
[root@centos12 traffic]# ll
总用量 23936
-rw-r--r-- 1 root root 24499704 7月 12 11:09 data-collector-1.0.jar
drwxr-xr-x 4 root root 34 7月 12 11:14 logs
-rw------- 1 root root 1131 7月 12 11:14 nohup.out
-rwxr--r-- 1 root root 112 7月 12 11:14 start.sh
[root@centos12 traffic]# cat start.sh
nohup java -Xmx500m -Xms500m -Xmn500m -Xss256k -jar data-collector-1.0.jar -Dspring.profiles.active=prod 2>&1 &
[root@centos12 traffic]# ./start.sh
配置flume采集 traffic_log_to_kafka.conf
编写启动脚本,并启动 flume 采集程序
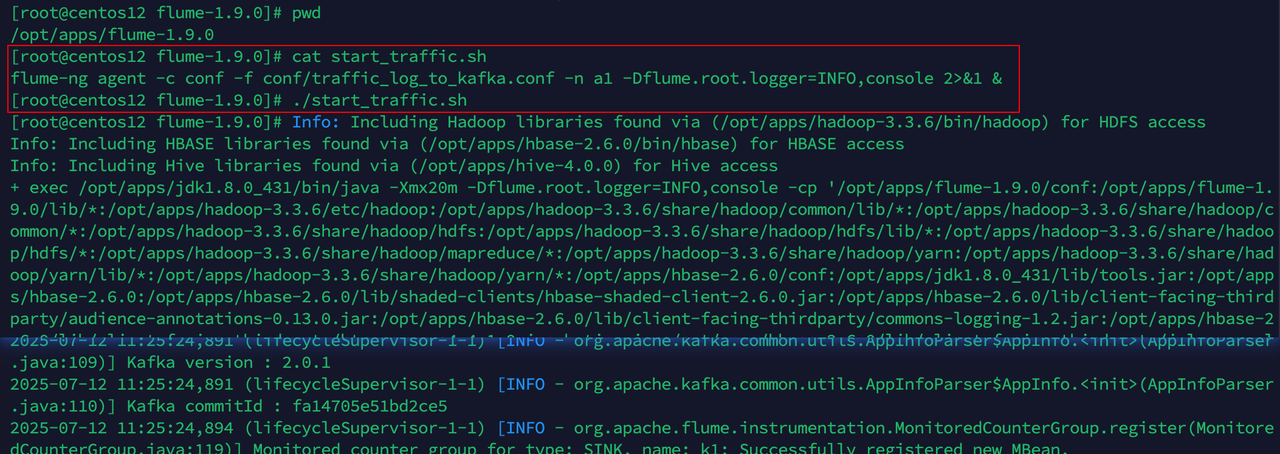
4.2 实时车辆超速监控
在城市交通管理数据库中,存储了每个卡口的限速信息,但是不是所有卡口都有限速信息,但不是所有的卡口都有限速信息,只有一部分卡口有限制。Flink中有广播状态流,JobManager 统一管理,TaskManager 中正在运行的 Task 不可以修改这个广播流,只能定时更新(自定义 Source)。
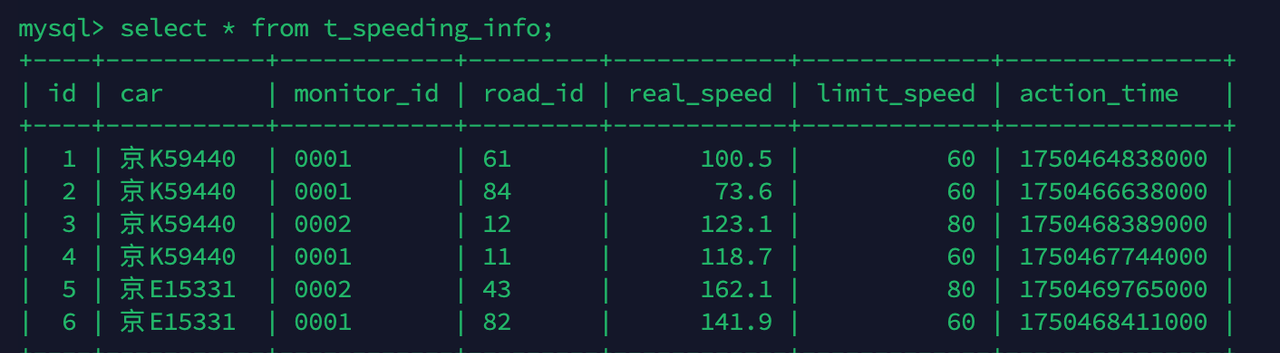
我们通过实时计算,需要把所有超速超过 10%的车辆找出来,并写入关系型数据库中。超速结果表如下:
drop table if exists `t_speeding_info`;
create table `t_speeding_info` (
`id` int(11) not null AUTO_INCREMENT,
`car` varchar(255) not null,
`monitor_id` varchar(255) default null,
`road_id` varchar(255) default null,
`real_speed` double default null,
`limit_speed` int(11) default null,
`action_time` bigint(20) default null,
primary key (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
在当前需求中,需要不定时的从数据库表中查询所有限速的卡口,再根据限速的卡口列表来实时的判断是否存在超速的车辆,如果找到超速的车辆,把这些车辆超速的信息保存到Mysql 数据库的超速违章记录表中 t_speeding_info。
我们把查询限速卡口列表数据作为一个事件流,车辆通行日志数据作为第二个事件流。广播状态可以用于通过一个特定的方式来组合并共同处理两个事件流。第一个流的事件被广播到另一个 operator 的所有并发实例,这些事件将被保存为状态。另一个流的事件不会被广播,而是发送给同一个 operator 的各个实例,并与广播流的事件一起处理。广播状态非常适合两个流中一个吞吐大,一个吞吐小,或者需要动态修改处理逻辑的情况。
我们对两个流使用了 connect() 方法,并在连接之后调用 BroadcastProcessFunction 接口处理两个流:
1)processBroadcastElement()方法:每次收到广播流的记录时会调用。将接收到的卡口限速记录放入广播状态中;
2)processElement()方法:接受到车辆通行日志流的每条消息时会调用。并能够对广播状态进行只读操作,以防止导致跨越类中多个并发实例的不同广播状态的修改。
代码实现如下:
object GlobalConstants {
lazy val MONITOR_STATE_DESCRIPTOR = new MapStateDescriptor[String, MonitorInfo]("monitor_info", classOf[String], classOf[MonitorInfo])
lazy val VIOLATION_STATE_DESCRIPTOR = new MapStateDescriptor[String, ViolationInfo]("violation_info", classOf[String], classOf[ViolationInfo])
lazy val KAFKA_SOURCE = KafkaSource.builder[String]()
.setBootstrapServers("node1:9092,node2:9092,node3:9092")
.setTopics("traffic_topic")
.setGroupId("traffic_speed_monitor")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build()
}
object OutOfSpeedMonitor {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
// val result: DataStream[String] = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "KafkaSource")
// result.print()
val mainStream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "KafkaSource")
.map(line => {
val slices = line.split(",")
TrafficInfo(slices(0).toLong, slices(1), slices(2), slices(3), slices(4).toDouble, slices(5), slices(6))
})
// 读取广播状态的Source,并广播出去
val broadcastStream = env.addSource(new JdbcReadDataSource[MonitorInfo](classOf[MonitorInfo]))
.broadcast(GlobalConstants.MONITOR_STATE_DESCRIPTOR)
// 主流.connect 算子,再调用 Process 底层API
mainStream.connect(broadcastStream)
.process(new ProcessOutOfSpeedFunction)
// 写入MySQL表中
.addSink(new JdbcWriteDataSink[OutOfLimitSpeedInfo](classOf[OutOfLimitSpeedInfo]))
env.execute("OutOfSpeedMonitor")
}
class ProcessOutOfSpeedFunction extends BroadcastProcessFunction[TrafficInfo, MonitorInfo, OutOfLimitSpeedInfo] {
// 处理主流中的数据
override def processElement(value: TrafficInfo,
ctx: BroadcastProcessFunction[TrafficInfo, MonitorInfo, OutOfLimitSpeedInfo]#ReadOnlyContext,
out: Collector[OutOfLimitSpeedInfo]): Unit = {
// 根据卡口ID,从广播状态中得到当前卡口的限速对象
val monitorInfo = ctx.getBroadcastState(GlobalConstants.MONITOR_STATE_DESCRIPTOR).get(value.monitorId)
if (monitorInfo != null) {
// 有限速设置
val limitSpeed = monitorInfo.limitSpeed
val realSpeed = value.speed
println(s"limitSpeed: ${limitSpeed}, realSpeed: ${realSpeed}")
if (limitSpeed * 1.1 <= realSpeed) {
// 超速通过卡口
val outOfLimitSpeedInfo = OutOfLimitSpeedInfo(value.car, value.monitorId, value.roadId, realSpeed, limitSpeed, value.actionTime)
// 只要超速就对外输出
out.collect(outOfLimitSpeedInfo)
}
}
}
// 处理广播状态流中的数据,从数据流中得到数据,放入广播状态中
override def processBroadcastElement(value: MonitorInfo,
ctx: BroadcastProcessFunction[TrafficInfo, MonitorInfo, OutOfLimitSpeedInfo]#Context,
collector: Collector[OutOfLimitSpeedInfo]): Unit = {
val bcState = ctx.getBroadcastState(GlobalConstants.MONITOR_STATE_DESCRIPTOR)
bcState.put(value.monitorId, value)
}
}
}
object GlobalConstants {
lazy val MONITOR_STATE_DESCRIPTOR = new MapStateDescriptor[String, MonitorInfo]("monitor_info", classOf[String], classOf[MonitorInfo])
lazy val VIOLATION_STATE_DESCRIPTOR = new MapStateDescriptor[String, ViolationInfo]("violation_info", classOf[String], classOf[ViolationInfo])
}
启动 Flink 实时监控程序 OutOfSpeedMonitor,并运行 CreateDatas 生产数据,之后在 MySQL 数据库中查看是否有超速车辆的信息。
注意:CreateDatas 生产数据的 monitorIds 需要修改一下
# 卡口ID String[] monitorIds = { "0000", "0001", "0002", "0004", "0005", "0021", "0023"}; .... String monitorId = monitorIds[r.nextInt(monitorIds.length)];
4.3 实时卡口拥堵情况监控
卡口的实时拥堵情况,其实就是通过卡口的车辆平均车速和通过的车辆的数量,为了统计实时的平均车速。设定一个滑动窗口,窗口长度为 5 分钟,滑动步长为 1 分钟。平均车速 = 当前窗口内通过车辆的车速之和 / 当前窗口通过的车辆数量;并且在 Flume 采集数据时,我们发现数据可能出现时间乱序问题,最长迟到 5 秒。
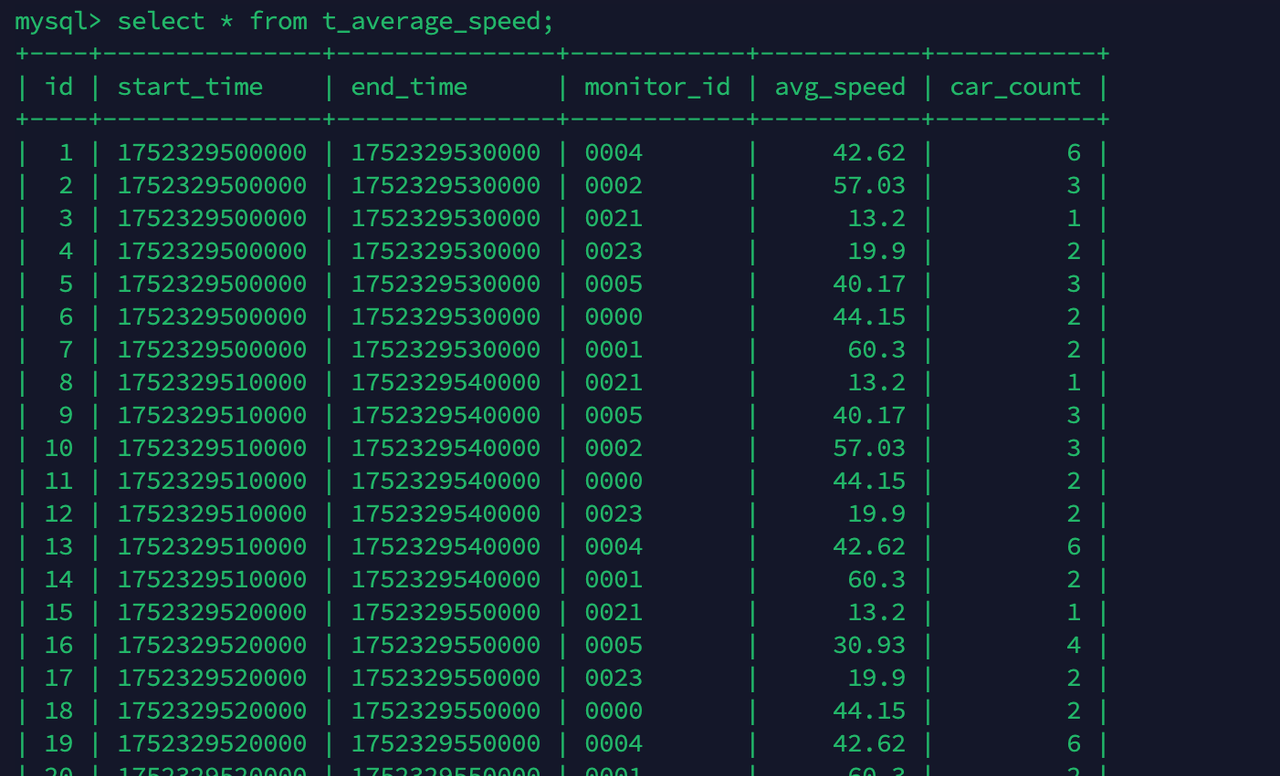
试试卡口平均速度需要保存到 MySQL 数据库中,结果表设计为:
drop table if exists `t_average_speed`;
create table `t_average_speed` (
`id` int(11) not null AUTO_INCREMENT,
`start_time` bigint(20) default null,
`end_time` bigint(20) default null,
`monitor_id` varchar(255) default null,
`avg_speed` double default null,
`car_count` int(11) default null,
primary key (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
代码实现如下:
object AverageSpeedMonitor {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val keyedStream = env.fromSource(KAFKA_SOURCE, WatermarkStrategy.noWatermarks(), "KafkaSource")
.map(line => {
println(s"$line")
val slices = line.split(",")
TrafficInfo(slices(0).toLong, slices(1), slices(2), slices(3), slices(4).toDouble, slices(5), slices(6))
}).assignTimestampsAndWatermarks(
// 设置watermark
WatermarkStrategy.forBoundedOutOfOrderness[TrafficInfo](Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner[TrafficInfo] {
override def extractTimestamp(t: TrafficInfo, l: Long): Long = t.actionTime
}).withIdleness(Duration.ofSeconds(5))
).keyBy(_.monitorId)
// 统计每个卡口的平均速度,设置滑动窗口
keyedStream.window(
// SlidingEventTimeWindows.of(Time.minutes(1), Time.minutes(5))
// 为了测试方便,滑动步长10秒,窗口长度30秒
SlidingEventTimeWindows.of(Time.seconds(30), Time.seconds(10))
).aggregate(new SpeedAggregate, new AverageSpeedFunction)
.addSink(new JdbcWriteDataSink[AvgSpeedInfo](classOf[AvgSpeedInfo]))
env.execute(this.getClass.getSimpleName)
}
// 当前需求中,累加器需要同时计算车辆的数量,还需要累加所有车速之后,使用二元组(累加车速之后,车的数量)
class SpeedAggregate() extends AggregateFunction[TrafficInfo, (Double, Long), (Double, Long)] {
override def createAccumulator(): (Double, Long) = (0.0, 0)
override def add(value: TrafficInfo, acc: (Double, Long)): (Double, Long) = {
(acc._1 + value.speed, acc._2 + 1)
}
override def getResult(acc: (Double, Long)): (Double, Long) = acc
override def merge(a: (Double, Long), b: (Double, Long)): (Double, Long) = (a._1 + b._1, a._2 + b._2)
}
// 计算平均速度,然后输出
class AverageSpeedFunction extends WindowFunction[(Double, Long), AvgSpeedInfo, String, TimeWindow] {
// 计算平均速度
override def apply(key: String, window: TimeWindow, input: Iterable[(Double, Long)], out: Collector[AvgSpeedInfo]): Unit = {
val t: (Double, Long) = input.iterator.next()
val avgSpeed = "%.2f".format(t._1 / t._2).toDouble
out.collect(AvgSpeedInfo(window.getStart, window.getEnd, key, avgSpeed, t._2.toInt))
}
}
}
启动 Flink 实时监控程序 AverageSpeedMonitor,并运行 CreateDatas 生产数据,之后在 MySQL 数据库中查看各个卡口车辆平均时速信息。
注意:CreateDatas 生产数据的 actionTime 需要修改一下
// 经过卡口的时间 // String time = day + " " + hour + ":" + String.format("%02d", r.nextInt(60)) + ":" + String.format("%02d", r.nextInt(60)); // long actionTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(time).getTime(); long actionTime = System.currentTimeMillis(); TimeUnit.SECONDS.sleep(1);
4.4 实时最通畅的 TopN 卡口
所谓的最通畅的卡口,其实就是当时的车辆数量最少的卡口,所以,其实之后在上一个功能的基础上再次开启第二个窗口操作。然后使用 AllWindowFunction 实现一个自定义的 TopN 函数 Top 来计算车速排名前 3 名的卡口,并将排名结果格式化成字符串,便于后续输出。(第二种方法:不用Flink计算,直接在Mysql数据库中计算平均车速的TopN)
代码实现如下:
stream.keyBy(_.monitorId).window(
// SlidingEventTimeWindows.of(Time.minutes(1), Time.minutes(5))
// 为了测试方便,滑动步长10秒,窗口长度30秒
SlidingEventTimeWindows.of(Time.seconds(30), Time.seconds(10))
).aggregate(new SpeedAggregate(), new AverageSpeedFunction)
// .addSink(new JdbcWriteDataSink[AvgSpeedInfo](classOf[AvgSpeedInfo]))
.windowAll(TumblingEventTimeWindows.of(Time.seconds(30)))
.process(new TopNProcessFunction(3))
.print()
// 降序排序,并取 topN,其中 n 可以通过参数传入
class TopNProcessFunction(topN: Int) extends ProcessAllWindowFunction[AvgSpeedInfo, String, TimeWindow] {
override def process(context: Context, elements: Iterable[AvgSpeedInfo], out: Collector[String]): Unit = {
// 从 Iterable 得到数据按照访问的次数降序排序
val list = elements.toList.sortBy(_.avgSpeed)(Ordering.Double.reverse).take(topN)
val sb = new StringBuilder
sb.append(s"最通畅Top${topN}个时间窗口时间: ${new Date(context.window.getStart)} ~ ${new Date(context.window.getEnd)}
")
list.foreach(t => {
sb.append(s"卡口ID: ${t.monitorId},平均车速是: ${t.avgSpeed}
")
})
sb.append("----------------------------------
")
out.collect(sb.toString())
}
}
5 智能实时报警
5.1 实时套牌分析
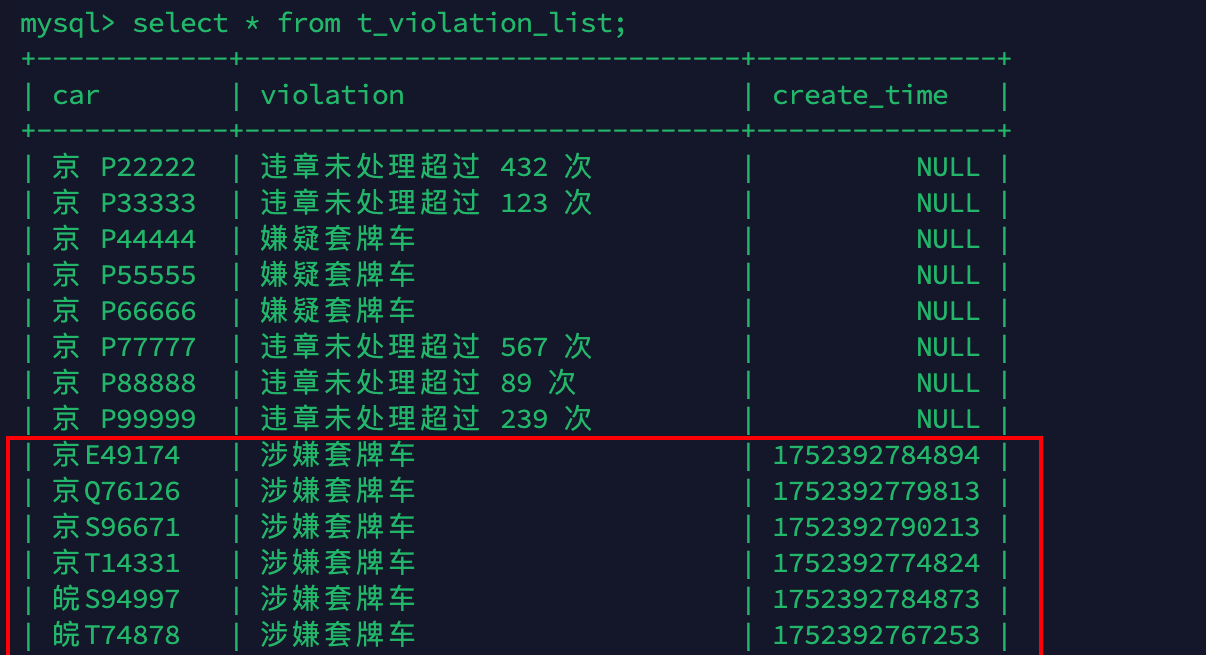
当某个卡口中出现一辆行驶的汽车,我们可以通过摄像头识别车牌号,然后在 10 秒内,另外一个卡口(或者当前卡口)也识别到了同样车牌的车辆,那么很有可能这两辆车之中有很大几率存在套牌车,因为一般情况下不可能有车辆在 10 秒内经过两个卡口。如果发现涉嫌套牌车,系统实时发出报警信息,同时这些存在套牌车嫌疑的车辆,写入 Mysql 数据库的结果表中,在后面的模块中,可以对这些违法车辆进行实时轨迹跟踪。
本需求可以使用 CEP 编程,也可以使用状态编程,这里我们采用状态编程。
代码实现如下:
object RepetitionCarWarning {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.fromSource(KAFKA_SOURCE, WatermarkStrategy.noWatermarks(), "KafkaSource")
.map(line => {
println(s"$line")
val slices = line.split(",")
TrafficInfo(slices(0).toLong, slices(1), slices(2), slices(3), slices(4).toDouble, slices(5), slices(6))
}).assignTimestampsAndWatermarks(
// 设置watermark
WatermarkStrategy.forBoundedOutOfOrderness[TrafficInfo](Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner[TrafficInfo] {
override def extractTimestamp(t: TrafficInfo, l: Long): Long = t.actionTime
}).withIdleness(Duration.ofSeconds(5))
)
stream.keyBy(_.car)
.process(new RepetitionCarWarningProcess)
.addSink(new JdbcWriteDataSink[RepetitionCarWarning](classOf[RepetitionCarWarning]))
env.execute(this.getClass.getSimpleName)
}
// 当前业务需要判断在10秒内,不同卡口或同一卡口出现同一个车牌
class RepetitionCarWarningProcess extends KeyedProcessFunction[String, TrafficInfo, RepetitionCarWarning] {
// 使用状态保存该车辆第一次通过卡口的时间
lazy val firstState = getRuntimeContext.getState(new ValueStateDescriptor[TrafficInfo]("first", classOf[TrafficInfo]))
override def processElement(value: TrafficInfo,
ctx: KeyedProcessFunction[String, TrafficInfo, RepetitionCarWarning]#Context, out: Collector[RepetitionCarWarning]): Unit = {
val first = firstState.value()
if (first == null) {
// 当前车辆第一次经过某个路口
firstState.update(value)
} else {
// 当前车辆之前已经出现在某个卡口,现在要判断时间间隔是否超过10秒
// 超过10秒则认为不是套牌车的概率大,没超过10秒时套牌车的概率大
val nowTime = value.actionTime
val firstTime = first.actionTime
val diffSec = (nowTime - firstTime).abs / 1000
if (diffSec <= 10) {
val warning = new RepetitionCarWarning(value.car,
if (nowTime > firstTime) first.monitorId else value.monitorId,
if (nowTime < firstTime) first.monitorId else value.monitorId,
"涉嫌套牌车", System.currentTimeMillis())
firstState.update(null)
out.collect(warning)
} else if (nowTime > firstTime) {
firstState.update(value)
}
}
}
}
}
启动 Flink 实时监控程序 RepetitionCarWarning,并运行 CreateDatas 生产数据,之后在 MySQL 数据库中查看实时套牌告警信息。
5.2 实时危险驾驶分析
在本项目中,危险驾驶是指在道路上驾驶机动车,追逐超速竞驶。我们规定:如果一辆机动车在 2 分钟内,超速通过卡口超过 3 次以上;而且每次超速的超过了规定速度的 20%以上;这样的机动车涉嫌危险驾驶。系统需要实时找出这些机动车,并报警,追踪这些车辆的轨迹。注意:如果有些卡口没有设置限速值,可以设置一个城市默认限速。
这样的需求在 Flink 也是有两种解决思路,第一:状态编程。第二:CEP 编程。但是当前的需求使用状态编程过于复杂了。所以我们采用第二种。同时还要注意:Flume 在采集数据的过程中出现了数据乱序问题,一般最长延迟 5 秒。
涉嫌危险驾驶的车辆信息保存到 Mysql 数据库表(t_violation_list)中,以便后面的功能中统一追踪这些车辆的轨迹。
代码实现如下:
object DangerousDriverWarning {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.fromSource(KAFKA_SOURCE, WatermarkStrategy.noWatermarks(), "KafkaSource")
.map(line => {
// println(s"$line")
val slices = line.split(",")
TrafficInfo(slices(0).toLong, slices(1), slices(2), slices(3), slices(4).toDouble, slices(5), slices(6))
}).assignTimestampsAndWatermarks(
// 设置Watermark
WatermarkStrategy.forBoundedOutOfOrderness[TrafficInfo](Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner[TrafficInfo] {
override def extractTimestamp(t: TrafficInfo, l: Long): Long = t.actionTime
}).withIdleness(Duration.ofSeconds(5))
)
// 定义Pattern
val pattern = Pattern.begin[OutOfLimitSpeedInfo]("first")
.where(t => {
// 超速20%
t.realSpeed >= t.limitSpeed * 1.2
}).timesOrMore(3) // 超过三次以上
.greedy // 尽可能多的匹配次数
.within(Time.minutes(2)) // 2分钟以内
// 没有设置限速的卡口默认是限速是 80
val outOfSpeedStream = stream.map(new TrafficOutOfSpeedFunction(80))
CEP.pattern(outOfSpeedStream.keyBy(_.car), pattern)
.select(new PatternSelectFunction[OutOfLimitSpeedInfo, DangerousDrivingWarning] {
override def select(map: util.Map[String, util.List[OutOfLimitSpeedInfo]]): DangerousDrivingWarning = {
val list = map.get("first")
val first = list.get(0)
val msg = "涉嫌危险驾驶"
val warning = DangerousDrivingWarning(first.car, msg, System.currentTimeMillis(), 0)
println(first.car + "" + msg + ",经过的卡口有:" + list.asScala.map(_.monitorId).mkString("->"))
warning
}
}).addSink(new JdbcWriteDataSink[DangerousDrivingWarning](classOf[DangerousDrivingWarning]))
env.execute(this.getClass.getSimpleName)
}
class TrafficOutOfSpeedFunction(defaultLimitSpeed: Double) extends RichMapFunction[TrafficInfo, OutOfLimitSpeedInfo] {
private val monitorMap = new mutable.HashMap[String, MonitorInfo]()
override def open(params: Configuration): Unit = {
val conn = DriverManager.getConnection("jdbc:mysql://node2/traffic_monitor", "root", "123456")
val sql = "select monitor_id,road_id,speed_limit,area_id from t_monitor_info where speed_limit > 0"
val pst = conn.prepareStatement(sql)
val res = pst.executeQuery()
while (res.next()) {
val monitorInfo = MonitorInfo(res.getString(1), res.getString(2), res.getInt(3), res.getString(4))
monitorMap.put(monitorInfo.monitorId, monitorInfo)
}
res.close()
pst.close()
conn.close()
}
override def map(value: TrafficInfo): OutOfLimitSpeedInfo = {
val monitorInfo = monitorMap.getOrElse(value.monitorId, MonitorInfo(value.monitorId, value.roadId, defaultLimitSpeed.toInt, value.areaId))
OutOfLimitSpeedInfo(value.car, value.monitorId, value.roadId, value.speed, monitorInfo.limitSpeed, value.actionTime)
}
}
}
思考题:实时违法车辆的出警分析
第一种,当前的违法车辆(在 5 分钟内)如果已经出警了。(最后输出道主流中做删除处理)。
第二种,当前违法车辆(在 5 分钟后)交警没有出警(发出出警的提示,在侧流中发出第一个侧流)。
第三种,有交警的出警记录,但是不是由监控平台报的警。(第二次侧流中)
启动 Flink 实时监控程序 DangerousDriverWarning,并运行 CreateDatas 生产数据,之后在 MySQL 数据库中查看实时危险驾驶告警信息。
5.3 违法王车辆轨迹跟踪
城市交通中,有些车辆需要实时轨迹跟踪,这些需要跟踪轨迹的车辆,保存在城市违法表中:t_violation_list。系统需要实时打印这些车辆经过的卡口,并且把轨迹数据插入表 t_track_info(HBase或MySQL数据库中)。
可以使用 Flink 中的广播状态完成这个功能,代码实现如下:
object CarTracking {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val mainStream = env.fromSource(KAFKA_SOURCE, WatermarkStrategy.noWatermarks(), "KafkaSource")
.map(line => {
// println(s"$line")
val slices = line.split(",")
TrafficInfo(slices(0).toLong, slices(1), slices(2), slices(3), slices(4).toDouble, slices(5), slices(6))
}).assignTimestampsAndWatermarks(
// 设置Watermark
WatermarkStrategy.forBoundedOutOfOrderness[TrafficInfo](Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner[TrafficInfo] {
override def extractTimestamp(t: TrafficInfo, l: Long): Long = t.actionTime
}).withIdleness(Duration.ofSeconds(5))
)
val broadcastStream = env.addSource(new JdbcReadDataSource[ViolationInfo](classOf[ViolationInfo]))
// 获取违法车辆信息,并广播出去
.broadcast(GlobalConstants.VIOLATION_STATE_DESCRIPTOR)
mainStream.connect(broadcastStream)
.process(new ProcessCarTracingFunction)
// 实时写入MySQL数据库中
.addSink(new JdbcWriteDataSink[TrackInfo](classOf[TrackInfo]))
// // 批量写入数据到Hbase表中,启动CountWindow 来完成批量插入,批量的条数由窗口大小决定
// .countWindowAll(10)
// .apply((win: GlobalWindow, in: Iterable[TrackInfo], out: Collector[java.util.List[Put]]) => {
// val list = new java.util.ArrayList[Put]()
// for (info <- in) {
// // 在hbase表中为了方便查询每辆车最近的车辆轨迹,根据车辆通行的时间降序排序
// // rowKey: 车牌号 + (Long.maxValue - actionTime)
// val put = new Put(Bytes.toBytes(info.car + "_" + (Long.MaxValue - info.actionTime)))
// put.add("cf1".getBytes(), "car".getBytes(), Bytes.toBytes(info.car))
// put.add("cf1".getBytes(), "actionTime".getBytes(), Bytes.toBytes(info.actionTime))
// put.add("cf1".getBytes(), "monitorId".getBytes(), Bytes.toBytes(info.monitorId))
// put.add("cf1".getBytes(), "roadId".getBytes(), Bytes.toBytes(info.roadId))
// put.add("cf1".getBytes(), "areaId".getBytes(), Bytes.toBytes(info.areaId))
// put.add("cf1".getBytes(), "speed".getBytes(), Bytes.toBytes(info.speed))
// list.add(put)
// }
// print(list.size() + ",")
// out.collect(list)
// }).addSink(new HbaseWriterDataSink[TrackInfo](classOf[TrackInfo]))
env.execute(this.getClass.getSimpleName)
}
class ProcessCarTracingFunction extends BroadcastProcessFunction[TrafficInfo, ViolationInfo, TrackInfo] {
override def processElement(value: TrafficInfo,
ctx: BroadcastProcessFunction[TrafficInfo, ViolationInfo, TrackInfo]#ReadOnlyContext,
out: Collector[TrackInfo]): Unit = {
val violationInfo = ctx.getBroadcastState(GlobalConstants.VIOLATION_STATE_DESCRIPTOR).get(value.car)
if (violationInfo != null) {
// 需要跟踪的车辆
val trackInfo = TrackInfo(value.car, value.actionTime, value.monitorId, value.roadId, value.areaId, value.speed)
out.collect(trackInfo)
}
}
override def processBroadcastElement(value: ViolationInfo,
ctx: BroadcastProcessFunction[TrafficInfo, ViolationInfo, TrackInfo]#Context,
out: Collector[TrackInfo]): Unit = {
val state = ctx.getBroadcastState(GlobalConstants.VIOLATION_STATE_DESCRIPTOR)
state.put(value.car, value)
}
}
}
注意:CreateDatas 生产数据的 car 需要修改一下
String[] cars = { "京E49174", "京N94279", "京Q76126", "京S96671", "京T14331", "京U54047", "京W85768", "湘M64082", "皖N02828", "皖Q56293", "皖S94997", "皖T74878", "皖Z19534", "鄂Q35888", "鲁O98192", "鲁R41791"}; // String car = locations[r.nextInt(locations.length)] + (char) (65 + r.nextInt(26)) + String.format("%05d", r.nextInt(100000)); String car = cars[r.nextInt(cars.length)];
启动 Flink 实时监控程序 CarTracking,并运行 CreateDatas 生产数据,之后在 MySQL 数据库中查看实时w违法车辆的轨迹信息。
6 实时车辆布控
在交警部门的指挥中心应该实时的知道整个城市的上路车辆情况,需要知道每个区一共有多少辆车?现在是否有大量的外地车进入城市等等。本模块主要是针对整个城市整体的实时车辆情况统计。
6.1 实时车辆分布情况
实时车辆分布情况,是指在一段时间内(比如:10 分钟)整个城市中每个区多少分布多少量车。这里要注意车辆的去重,因为在 10 分钟内一定会有很多的车,经过不同的卡口。这些车牌相同的车,我们只统计一次。其实就是根据车牌号去重。
代码实现如下:
object AreaDistribution {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.fromSource(KAFKA_SOURCE, WatermarkStrategy.noWatermarks(), "KafkaSource")
.map(line => {
// println(s"$line")
val slices = line.split(",")
TrafficInfo(slices(0).toLong, slices(1), slices(2), slices(3), slices(4).toDouble, slices(5), slices(6))
}).assignTimestampsAndWatermarks(
// 设置watermark
WatermarkStrategy.forBoundedOutOfOrderness[TrafficInfo](Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner[TrafficInfo] {
override def extractTimestamp(t: TrafficInfo, l: Long): Long = t.actionTime
}).withIdleness(Duration.ofSeconds(5))
)
stream.keyBy(_.areaId)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply(new WindowFunction[TrafficInfo, (String, Long), String, TimeWindow] {
override def apply(key: String, window: TimeWindow, in: Iterable[TrafficInfo], out: Collector[(String, Long)]): Unit = {
// 使用Set集合去重
var ids = Set[String]()
for (t <- in) {
ids += t.car
}
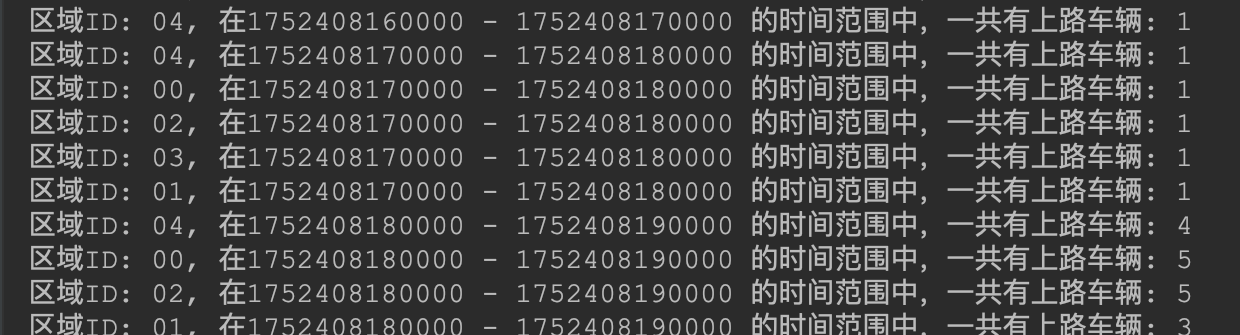
val msg = s"区域ID: ${key}, 在${window.getStart} - ${window.getEnd} 的时间范围中,一共有上路车辆: ${ids.size}"
println(msg)
out.collect(msg, ids.size)
}
})
env.execute(this.getClass.getSimpleName)
}
}
注意:CreateDatas 生产数据的 car 和 areaId 需要修改一下
// String[] cars = {"京E49174", "京N94279", "京Q76126", "京S96671", "京T14331", "京U54047", "京W85768", "湘M64082", "皖N02828", "皖Q56293", "皖S94997", "皖T74878", "皖Z19534", "鄂Q35888", "鲁O98192", "鲁R41791"}; // String car = cars[r.nextInt(cars.length)]; String car = locations[r.nextInt(locations.length)] + (char) (65 + r.nextInt(26)) + String.format("%05d", r.nextInt(100000)); ... String areaId = String.format("%02d", r.nextInt(100)); String areaId = String.format("%02d", r.nextInt(5));
启动 Flink 实时监控程序 AreaDistribution,并运行 CreateDatas 生产数据,之后控制台查看输出。
6.2 布隆过滤器(BloomFilter)
在上个例子中,我们把所有数据的车牌号 car 都存在了窗口计算的状态里,在窗口收集数据的过程中,状态会不断增大。一般情况下,只要不超出内存的承受范围,这种做法也没什么问题;但如果我们遇到的数据量很大呢?
把所有数据暂存放到内存里,显然不是一个好主意。我们会想到,可以利用 redis 这种内存级 k-v 数据库,为我们做一个缓存。但如果我们遇到的情况非常极端,数据大到惊人呢?比如上千万级,亿级的卡口车辆数据呢?(假设)要去重计算。
如果放到redis中,假设有6千万车牌号(每个10-20字节左右的话)可能需要几G的空间来存储。当然放到 redis 中,用集群进行扩展也不是不可以,但明显代价太大了。
一个更好的想法是,其实我们不需要完整地存车辆的信息,只要知道他在不在就行了。所以其实我们可以进行压缩处理,用一位(bit)就可以表示一个车辆的状态。这个思想的具体实现就是布隆过滤器(Bloom Filter)。
布隆过滤器的原理
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic datastructure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
它本身是一个很长的二进制向量,既然是二进制的向量,那么显而易见的,存放的不是0,就是 1。相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少。我们的目标就是,利用某种方法(一般是 Hash 函数)把每个数据,对应到一个位图的某一位上去;如果数据存在,那一位就是 1,不存在则为 0。
Bloom Filter 是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter 的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter 不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter 通过极少的错误换取了存储空间的极大节省。
Trigger的作用
Flink 中,window 操作需要伴随对窗口中的数据进行处理的逻辑,也就是窗口函数,而 Trigger 的作用就是决定何时触发窗口函数中的逻辑执行。
重写的函数:
onElement() 方法会在窗口中每进入一条数据的时候调用一次
onProcessingTime() 方法会在一个 ProcessingTime 定时器触发的时候调用
onEventTime()方法会在一个EventTime定时器触发的时候调用
clear()方法会在窗口清除的时候调用
TriggerResult 中包含四个枚举值:
CONTINUE:表示对窗口不执行任何操作。
FIRE:表示对窗口中的数据按照窗口函数中的逻辑进行计算,并将结果输出。注意计算完成后,窗口中的数据并不会被清除,将会被保留。
PURGE:示将窗口中的数据和窗口清除。
FIRE_AND_PURGE:表示先将数据进行计算,输出结果,然后将窗口中的数据和窗口进行清除。
代码实现如下:
object AreaDistributionByBloomFilter {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.fromSource(KAFKA_SOURCE, WatermarkStrategy.noWatermarks(), "KafkaSource")
.map(line => {
// println(s"$line")
val slices = line.split(",")
TrafficInfo(slices(0).toLong, slices(1), slices(2), slices(3), slices(4).toDouble, slices(5), slices(6))
}).assignTimestampsAndWatermarks(
// 设置watermark
WatermarkStrategy.forBoundedOutOfOrderness[TrafficInfo](Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner[TrafficInfo] {
override def extractTimestamp(t: TrafficInfo, l: Long): Long = t.actionTime
}).withIdleness(Duration.ofSeconds(5))
)
val map = new mutable.HashMap[String, Long]()
stream.keyBy(_.areaId)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 采用布隆过滤器处理海量数据去重的问题,同时采用 Trigger 来解决默认窗口状态中数据过大
.trigger(new MyTrigger) // 设置窗口触发的时机和状态是否清除的问题
.process(new BloomFilterProcess(map))
.print()
env.execute(this.getClass.getSimpleName)
}
// 自定义Trigger
class MyTrigger extends Trigger[TrafficInfo, TimeWindow] {
// 当前窗口进入一条数据的回调函数
override def onElement(t: TrafficInfo, l: Long, w: TimeWindow, triggerContext: Trigger.TriggerContext): TriggerResult = TriggerResult.FIRE_AND_PURGE
// 当前窗口已经结束的回调函数(基于运行时间)
override def onProcessingTime(l: Long, w: TimeWindow, triggerContext: Trigger.TriggerContext): TriggerResult = TriggerResult.CONTINUE
// 当前窗口已经结束的回调函数(基于事件时间)
override def onEventTime(l: Long, w: TimeWindow, triggerContext: Trigger.TriggerContext): TriggerResult = TriggerResult.CONTINUE
// 当前窗口对象销毁
override def clear(w: TimeWindow, triggerContext: Trigger.TriggerContext): Unit = {
}
}
// 采用布隆过滤器来去重,ProcessWindowFunction 是全量窗口函数
class BloomFilterProcess(map: mutable.HashMap[String, Long]) extends ProcessWindowFunction[TrafficInfo, String, String, TimeWindow] {
// 定义redis连接
var jedis: Jedis = _
var bloomFilter: MyBloomFilter = _
override def open(parameters: Configuration): Unit = {
jedis = new Jedis("node4")
jedis.select(0)
bloomFilter = new MyBloomFilter(1 << 27, 2)
}
// 当有一条数据进入窗口的时候就必须先使用布隆过滤器去重,然后在累加。
// 当这条数据累加之后把它从状态中清除
override def process(key: String,
context: Context,
elements: Iterable[TrafficInfo],
out: Collector[String]): Unit = {
val windowStart = context.window.getStart
val windowEnd = context.window.getEnd
val car = elements.last.car
// 1. redis 数据来负责 bitmap 计算(返回 1 或者 0)
// 2. redis 存储每一个区域中每个窗口的累加器
var count = 0L
// 先从 redis 中取得累加器的值
// 布隆过滤器的 key 有:区域 ID+窗口时间
val bloomKey = key + "_" + windowEnd;
if (map.contains(bloomKey)) {
// 第一次从 Map 集合中判断有没有这个累加器
count = map.getOrElse(bloomKey, 0)
}
val offsets = bloomFilter.getOffsets2(car)
// 为了计算准确,一区域中的一个窗口对应一个布隆过滤器
// 初始化一个判断是否重复车牌
var repeated = true // 默认所有车牌都重复
val loop = new Breaks
loop.breakable {
for (offset <- offsets) {
// 遍历下标的列表
// isContain = true(1),代表可能车牌重复,如果 isContain=false(0)代表当前车牌
// 绝对不可能重复
val isContain = jedis.getbit(bloomKey, offset)
if (!isContain) {
repeated = false
loop.break()
}
}
}
// 当前车牌号已经重复的,所以不用累加,直接输出
if (!repeated) {
// 当前车辆号没有出现过重复的,所以要累加
count += 1
for (offset <- offsets) {
// 把当前的车牌号写入布隆过滤器
jedis.setbit(bloomKey, offset, true)
}
// 把 redis 中保存的累加器更新一下
map.put(bloomKey, count)
}
out.collect(s"区域ID: ${key}, 在窗口起始时间: ${windowStart} --- 窗口结束时间: ${windowEnd}, 一共有上路车辆为: ${count}")
}
}
// 自定义布隆过滤器
class MyBloomFilter(numBits: Long, numFuncs: Int) extends Serializable {
// 自定义hash函数,采用google的hash函数
def myHash(car: String): Long = {
Hashing.murmur3_128().hashString(car, Charset.forName("UTF-8")).asLong()
}
// 根据车牌,去布隆过滤器中计算得到该车牌对应的下标
def getOffsets(car: String): Array[Long] = {
var firstHash = myHash(car)
// 无符号右移,左边没有0且没有符号
// val firstHash2Hash = firstHash >> 16
var secondHash = car.hashCode.toLong
// 数组长度和hash函数的个数一样
val result = new Array[Long](numFuncs)
for (i <- 1 to numFuncs) {
if (i == 1) {
// val combineHash = firstHash + i * firstHash2Hash
if (firstHash < 0) {
firstHash = ~firstHash //取反计算
}
// 得到一个下标保存到数组
result(0) = firstHash % numBits
}
if (i == 2) {
if (secondHash < 0) {
secondHash = ~secondHash
}
result(1) = secondHash % numBits
}
}
result
}
// 根据车牌,去布隆过滤器中计算得到该车牌对应的下标
def getOffsets2(car: String): Array[Long] = {
var firstHash = myHash(car)
if (firstHash < 0) {
firstHash = ~firstHash
}
val result = new Array[Long](numFuncs)
result(0) = firstHash % numBits
result
}
}
}
完整项目代码:https://github.com/shouwangyw/rt-monitor-ut


















暂无评论内容