
偏差和方差
bias and variance
观察学习算法的偏差和方差,可以发现下一步如何调优
高偏差:欠拟合,训练集上误差太大;
高方差:过拟合,泛化能力太差;
当有更多特征(即更多维度)时,无法画图查看其拟合程度,是欠拟合/过拟合/刚刚好;
而更普遍和通用的方法是,查看模型在训练集和验证集上的表现;
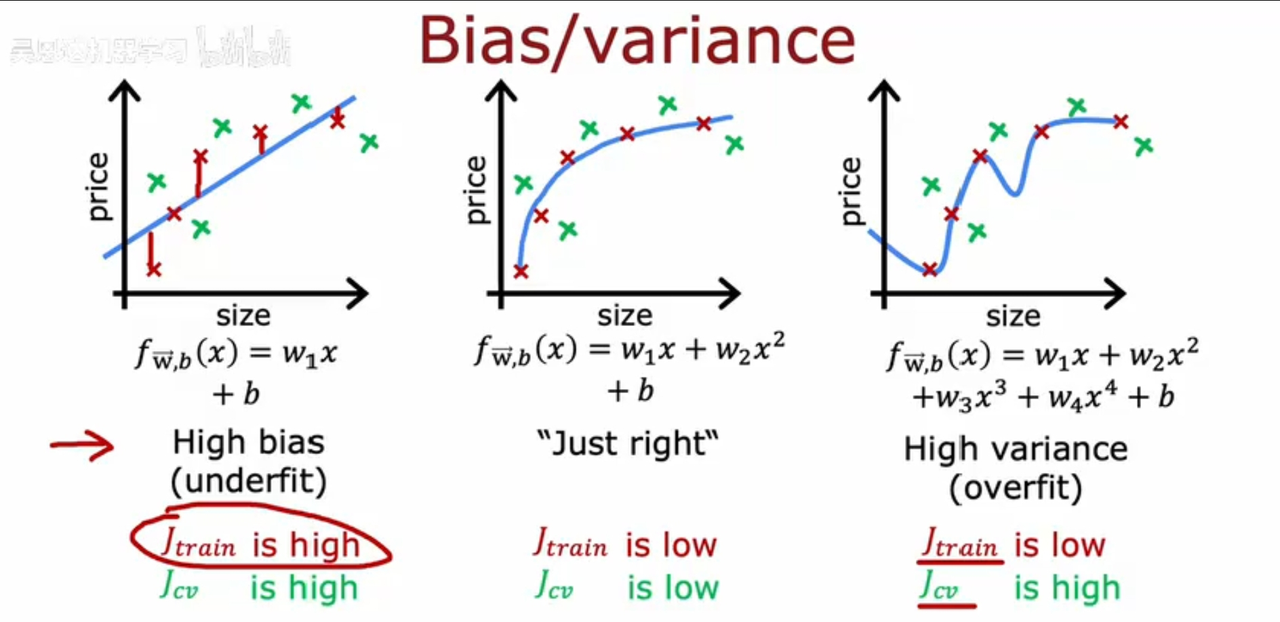
Jtrain 和 Jcv 来体现,具体来说:
高偏差:Jtrain和Jcv都很高;
高方差:Jtrain 很低,Jcv很高;
刚刚好:Jrain较低,Jcv较低;
如何判断模型是高方差/高偏差
另一个视角:Jtrain Jcv如何随着多项式的阶数变化:
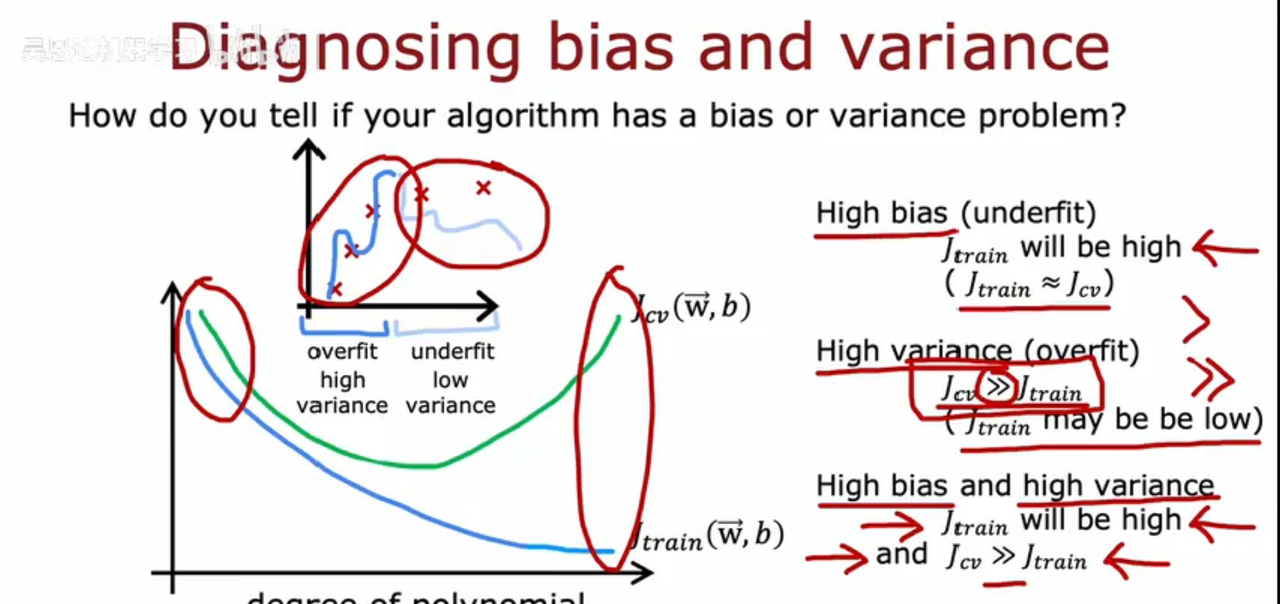
有时会同时出现高方差和高偏差(在线性回归中少见),Jtrain很高,但Jcv还远大于Jtrain(例如:对部分数据过拟合,对部分数据欠拟合)。
正则化参数lambda
前面说过,训练中的成本函数中的正则化项,是为了避免过拟合的问题,避免某一些特征过大地影响预测结果。

当lambda值选择过小比如0时,该正则化项消失,特征值对预测结果的影响过大,则容易产生过拟合;
当lambda值过大时,特征值的对预测结果的影响极小,容易产生欠拟合,即接近一条直线J(w,b) = b;
lambda的选择,要保证w较小的同时也要拟合好训练数据,在特征值对预测结果的影响上要做好平衡,以避免过拟合/欠拟合;

对于lambda的选择,交叉验证提供了一种方式:
尝试一组不同的lambda的值,然后最小化成本函数J,得到一组w,b,然后用交叉验证数据集cross-valid来查看拟合结果,最后选择一个Jcv最小的lambda的值;

查看误差值Jcv/Jtrain,随着lambda参数的大小如何变化,
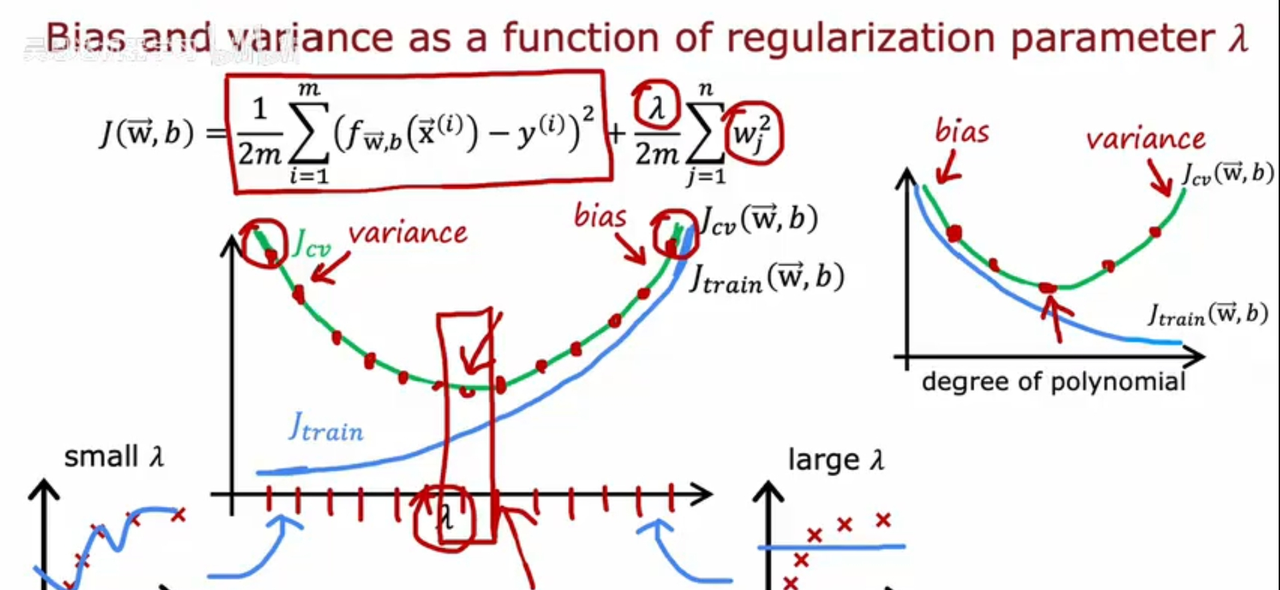
lambda越大,正则化项的权重越大,则特征值对结果的影响就越小,拟合程度就会越来越偏离训练数据,因此Jtrain会越来越大;
lambda很小时,处于过拟合状态,因此模型泛化能力差,Jcv就较大,随着lambda的增加,lambda逐渐走向合理取值,模型去除过拟合,则泛化能力增强,Jcv就变小,当lambda继续增大超出合理范围,则正则化权重过大,特征值影响过于小,模型偏离,此时根据特征值已不能较准确预测结果,泛化能力变差,这时Jcv继续增大;
如何判断Jtrain Jcv值的高低
建立性能的基线水准 baseline level – 基本标准
示例:语音识别
训练语音识别系统并测量训练误差,
训练误差:算法在训练集中的音频片段中没有正确识别转录的百分比,假设为10.8%(看起来相当高);
测量系统在验证集中的误差,即泛化误差,假设为14.8%(看起来更高);
但是需要根
![[9.30更新]windows防止电脑休眠小工具 - 宋马](https://pic.songma.com/blogimg/20250422/c4e741116a5c479fb3d21efb18c0a346.png)




















暂无评论内容