
B站同步视频 -> 点击进入> 点击进入> B站同步视频> 点击进入> 点击进入> B站同步视频> 点击进入>
1、下载Qwen-7B-Chat的模型权重
在下载了Qwen的项目运行文件及配置好了Python的运行环境后,还剩下最后一步:需要把Qwen的这个模型本身下载到本地,从而才能通过项目文件中的代码逻辑,调用这个模型,最终达到启动模型服务的结果。
不同于GitHub,GitHub 仅仅是一个代码托管和版本控制平台,托管的是项目的源代码、文档和其他相关文件。同时对于托管文件的大小有限制,不适合存储大型文件,如训练好的机器学习模型。而模型权重都很大,自然是不适合放在Github平台上的,所以有其他的网站**在远端服务器上存储着真实的模型权重供我们下载。**对于大模型的权重存储,推荐使用的两个官方:
Hugging Face: https://huggingface.co/ ,限制条件:需要开启科学上网才可以访问;
摩搭社区:https://modelscope.cn/ ,优势:不需要科学上网,国内网络可直接访问;
接下来,我们依次介绍两个官方的下载方式,大家根据各自的实际情况灵活选择。
1.1方法一:在Hugging Face官方下载(需要科学上网)
再次声明:需要科学上网环境才能使用这种方法。
Step 1:进入Hugging Face 官网:https://huggingface.co/

Step 2:搜索 Qwen 模型
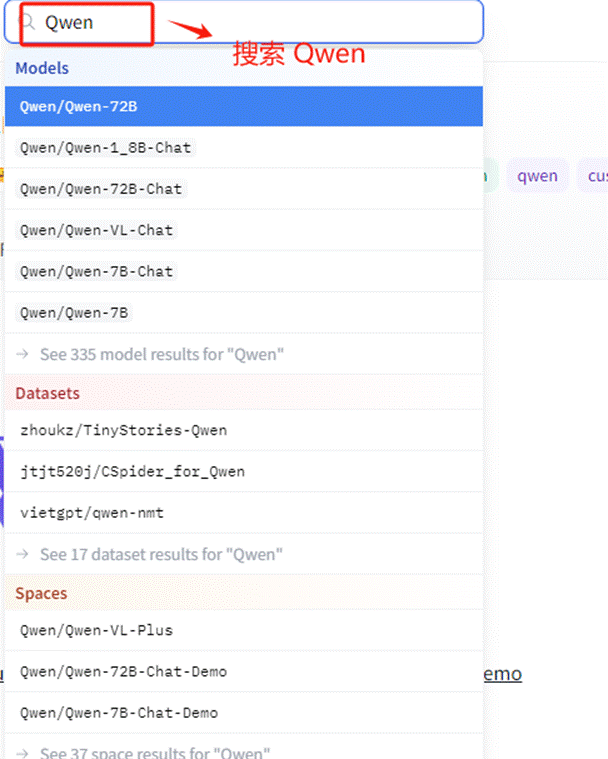
Step 3:选择 Qwen-7B-Chat 模型
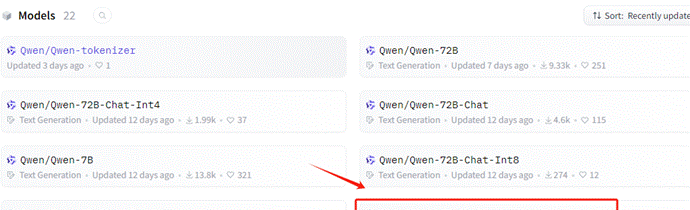
然后按照如下位置,找到对应的下载URL。

复制此命令,进入到服务器的命令行准备执行。

Step 4. 安装Git LFS
Git Large File Storage(Git LFS)是一种用于处理大文件的工具,在 Hugging Face 下载大模型时,通常需要安装 Git LFS,主要的原因是:Git 本身并不擅长处理大型文件,因为在 Git 中,每次我们提交一个文件,它的完整内容都会被保存在 Git 仓库的历史记录中。但对于非常大的文件,这种方式会导致仓库变得庞大而且低效。而 Git LFS, 就不会直接将它们的内容存储在仓库中。相反,它存储了一个轻量级的“指针”文件,它本身非常小,它包含了关于大型文件的信息(如其在服务器上的位置),但不包含文件的实际内容。当我们需要访问或下载这个大型文件时,Git LFS 会根据这个指针去下载真正的文件内容。
实际的大文件存储在一个单独的服务器上,而不是在 Git 仓库的历史记录中。所以如果不安装 Git LFS 而直接从 Hugging Face 或其他支持 LFS 的仓库下载大型文件,通常只会下载到一个包含指向实际文件的指针的小文件,而不是文件本身。
所以,需要先安装git-lfs这个工具。命令如下:
|
Bash |





















暂无评论内容