
YOLO:一次性检测器

YOLO(You Only Look Once)是一种流行的目标检测算法,其核心思想是将目标检测问题视为一个回归问题,通过单个卷积神经网络(CNN)实现端到端的训练,从而实现快速且准确的目标检测。以下是关于YOLO的详细介绍:

一、基本特点
1、端到端训练:
YOLO将目标检测任务简化为一个回归问题,通过一个CNN模型同时预测多个边界框和类别概率,省去了传统目标检测方法中的多个步骤,如候选区域生成、分类器评估、边界框优化等。
2、快速检测速度:
YOLO的设计使其在保持较高检测精度的同时,能够实现接近实时的检测速度。不同版本的YOLO在检测速度上有所差异,但通常都能达到较高的帧率。
3、全局视野:
与传统的基于滑动窗口和候选区域的方法不同,YOLO在训练和测试时能够看到整个图像,这使得它能够隐式编码类别间的上下文信息和外观特征。
4、抽象特征学习:
YOLO通过训练学习图像的抽象特征,使其在不同领域的图像上都有很好的检测效果。
二、发展历程
YOLO系列算法自推出以来,经历了多个版本的迭代和优化,主要包括YOLOv1、YOLOv2(YOLO9000)、YOLOv3、YOLOv4、YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOv9、YOLOv10等。每个版本都在前一个版本的基础上进行了改进和增强,以提高检测的准确性、速度和泛化能力。
YOLOv1:
YOLOv1是YOLO系列的第一个版本,它将目标检测任务视为一个回归问题,通过单个CNN模型实现快速且准确的目标检测。YOLOv1在保持较高检测精度的同时,能够实现接近实时的检测速度。

YOLOv2(YOLO9000):
YOLOv2在YOLOv1的基础上进行了多项改进,包括引入了批量归一化、高分辨率分类器、锚框(Anchor Boxes)等,显著提高了检测的准确性和速度。此外,YOLOv2还能够检测9000种不同类别的目标,因此被称为YOLO9000。
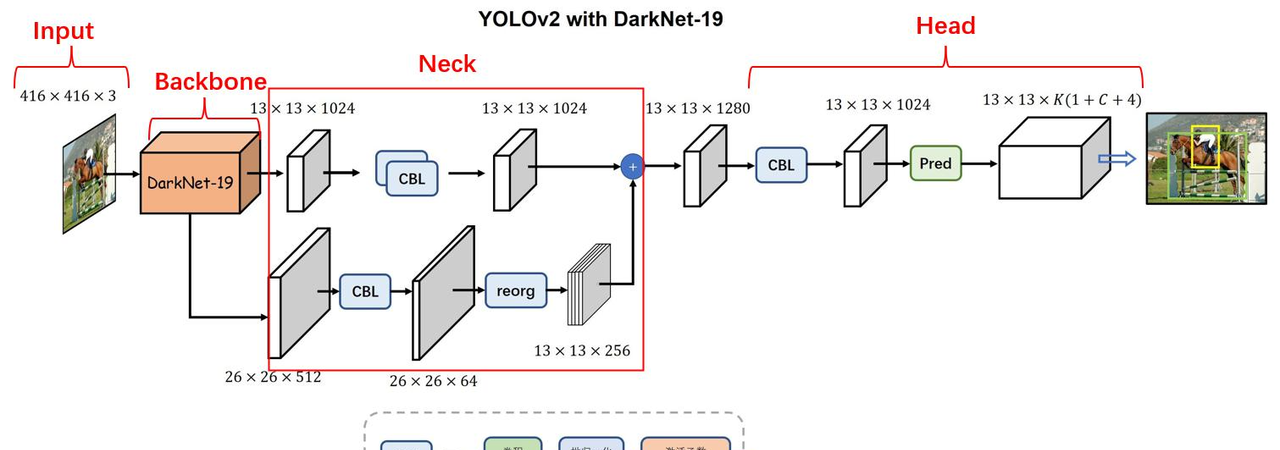
YOLOv3:
YOLOv3采用了更加复杂的骨干网络(Darknet-53)来提取特征,并引入了多尺度预测和上采样与特征融合技术,以更好地检测不同大小的目标。YOLOv3在检测精度和速度上都有了显著提升。

YOLOv4:
YOLOv4在YOLOv3的基础上进行了进一步的优化和改进,包括采用了更高效的模型设计、验证了最新的训练方法和数据增强技术等。YOLOv4在保持高检测精度的同时,进一步提高了检测速度,并适用于各种平台和应用场景。

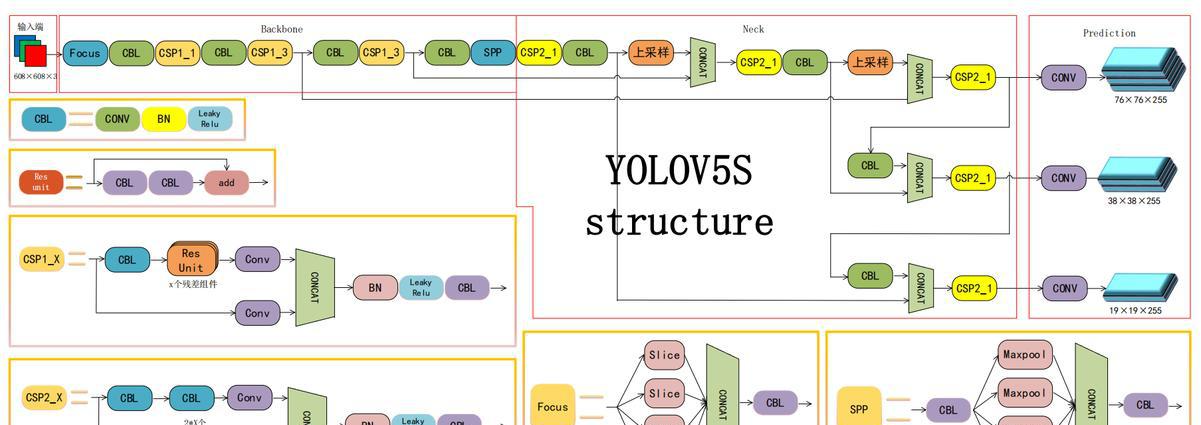
YOLOv5:
YOLOv5是YOLO系列中的一个重要进展,它提供了不同大小的模型版本以适应不同的性能需求和部署环境。YOLOv5采用了PyTorch框架实现,使得它更容易被社区接受和使用,同时也方便了模型的部署和集成。
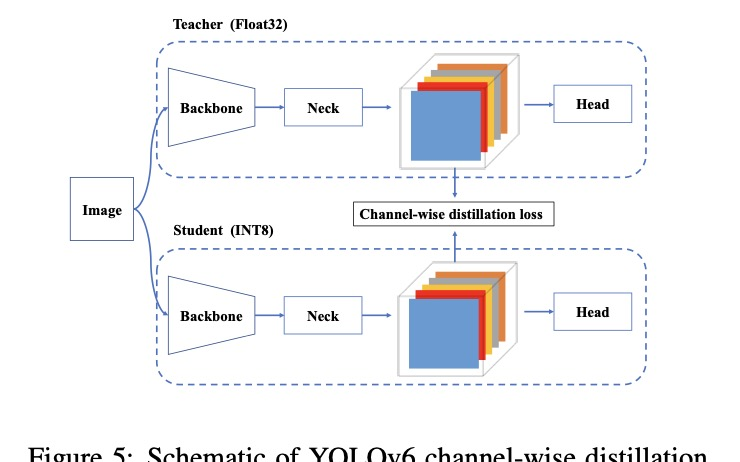
YOLOv6:
由美图团队发布,专注于工业应用。其核心是自研的高效主干网络和解耦检测头,并在Backbone和Neck中使用了RepVGG风格的重参数化结构,在速度和精度上实现了良好平衡。
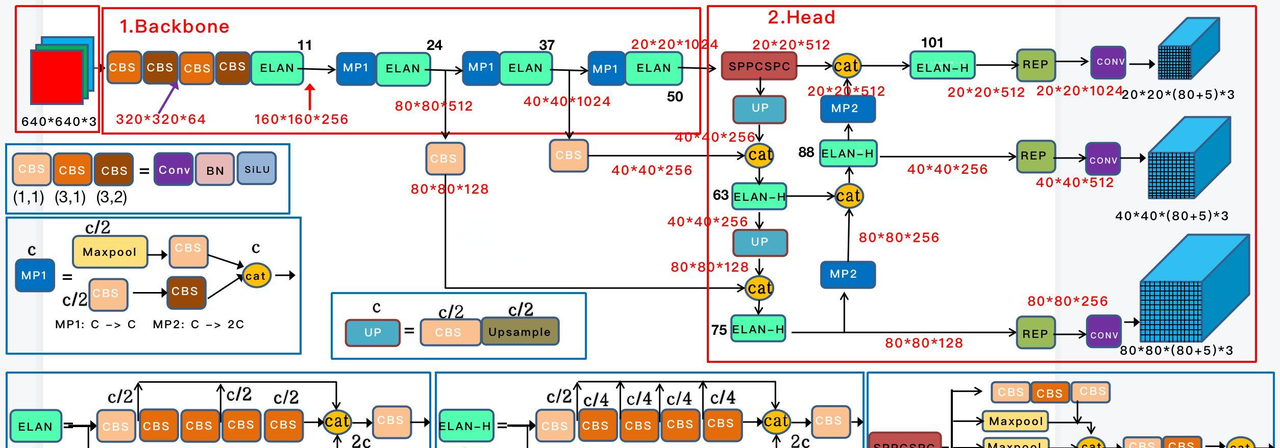
YOLOv7:
官方团队作品。通过扩展和复合缩放(E-ELAN) 优化模型结构,引入辅助头辅助训练和重参数化模块,大幅提升了模型性能,尤其是在速度和精度权衡方面表现优异。
YOLOv8:
由Ultralytics发布,成为当前最流行的版本。它采用了无锚点(Anchor-Free) 设计和新的卷积模块,并配备了非常用户友好的API,在分类、检测、分割任务上均表现强大且易于使用。
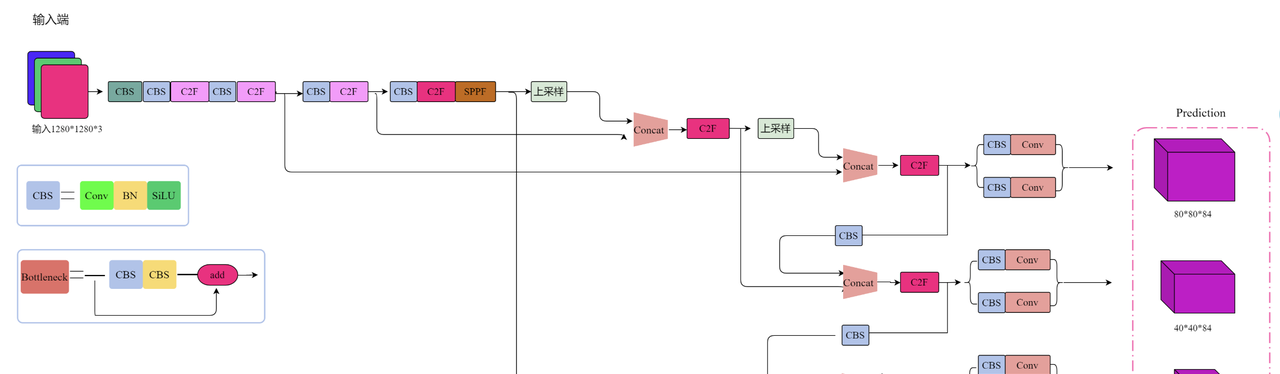
YOLOv9:
官方重磅更新。提出了可编程梯度信息(PGI) 和通用高效层聚合网络(GELAN),旨在解决深度网络中的信息丢失问题,在极大幅减少参数的同时,实现了精度上的显著提升。

YOLOv10:
清华大学团队发布。主打无NMS的端到端检测,通过双标签分配和一致性匹配策略消除推理时对NMS的依赖。同时进行了整体模型结构和轻量化设计,提升效率。

YOLOv11:
主要引入了自适应特征增强模块(AFE)13,通过结合空间上下文模块(SCM)和特征细化模块(FRM)13,显著提升了模型在复杂场景(如杂乱背景、半透明物体和尺度变化)下的检测精度和鲁棒性135。

YOLOv12:
作为首个以注意力机制为核心的YOLO框架2410,其核心创新是提出了区域注意力模块(A²)246和残差高效层聚合网络(R-ELAN)246。A²模块通过将特征图划分为区域降低计算复杂度4610,R-ELAN则优化了梯度流动和特征聚合246,在保持高速度的同时显著提升了检测精度246。

三、技术细节
1、网络结构:
YOLO系列算法的网络结构通常包括特征提取层、特征融合层和检测层等部分。特征提取层负责从输入图像中提取有用的特征信息;特征融合层将不同尺度的特征图进行融合,以提高对小目标的检测能力;检测层则负责预测边界框和类别概率。
2、损失函数:
YOLO的损失函数通常包括边界框损失、置信度损失和类别损失等部分。通过优化损失函数,YOLO可以实现对边界框、置信度和类别概率的准确预测。
核心组成部分:
边界框回归损失(Bounding Box Regression Loss)
用于精确预测目标框的位置和大小。
演进: 从早期的MSE/L2 Loss → IoU Loss → GIoU → DIoU/CIoU(当前主流)。CIoU同时考虑了重叠面积、中心点距离和宽高比,收敛更快,精度更高。YOLOv8/v9/v10等均使用IoU系列变体。
置信度损失(Confidence Loss)
用于判断预测框内是否包含目标(Objectness)。
通常使用二元交叉熵损失(BCE Loss),区分前景(有物体)和背景(无物体)。
分类损失(Classification Loss)
用于判断预测框内物体的具体类别。
传统YOLO使用多分类交叉熵损失。后来为处理类别不平衡问题,一些版本(如YOLOX)引入了Focal Loss或带sigmoid的BCE Loss(每类独立判断,替代softmax)。
YOLO损失函数是 “CIoU + BCE + BCE” 或 “CIoU + BCE + Focal Loss” 等的加权组合,通过权衡不同任务的重要性来协同优化,最终实现准确的目标定位与分类。

3、非极大值抑制(NMS):
在YOLO的检测过程中,会产生大量的边界框。为了去除冗余的边界框并保留最佳的预测结果,通常采用非极大值抑制算法对边界框进行筛选。

综上所述,YOLO作为一种一次性检测器,在目标检测领域具有广泛的应用前景和重要的研究价值。随着技术的不断发展和优化,YOLO的性能和效果将会得到进一步提升和拓展。
关注微信公众号:深漂梦实,给你更多干货分享!




















暂无评论内容