
自学
目录
1.两个例子
2.计算图概念
3.正向传播
4.反向传播
5.代码
(1). 基础例子:点积 + backward
(2). 清零梯度
(3). 元素平方
(4). 使用 .detach() 切断计算图
(5). Python 控制流里的梯度
1.两个例子

ps:
转置符号没看懂原因:忘记了点积符号


2.计算图概念
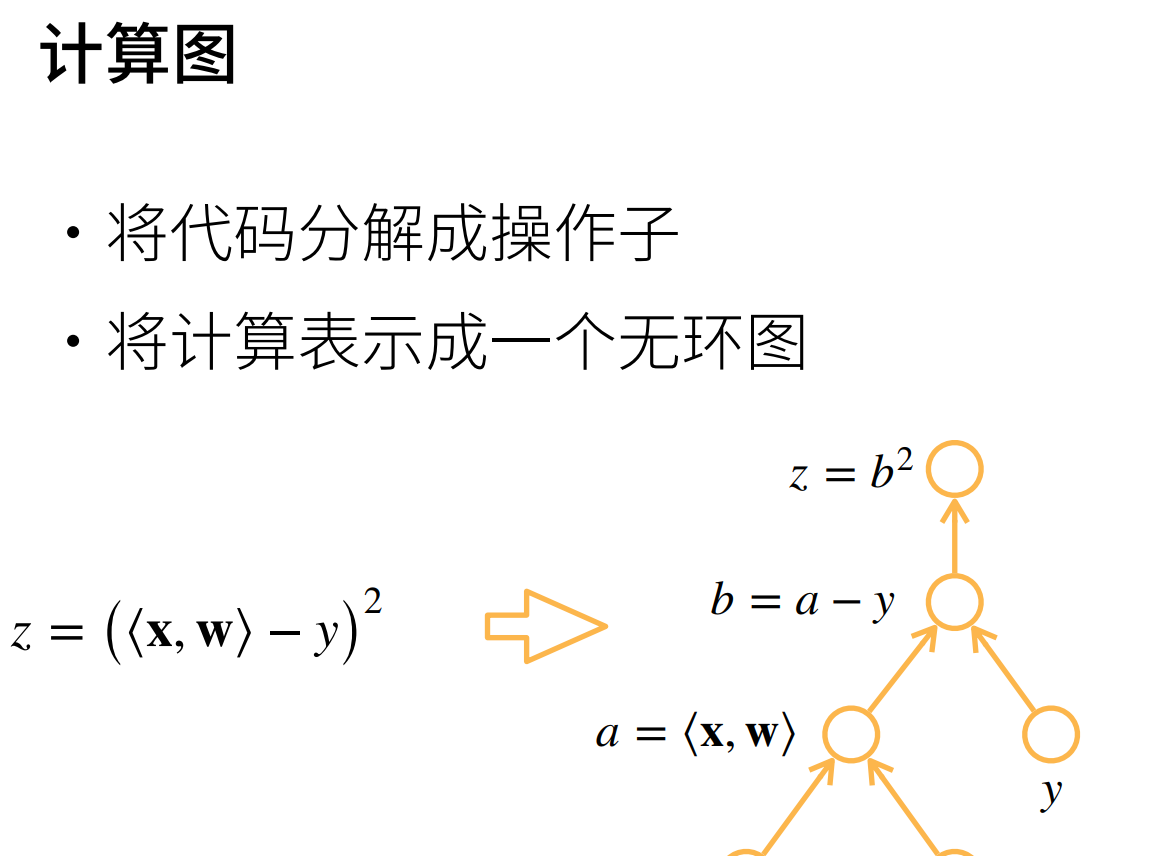
3.正向传播
输入数据经过网络层层计算,得到输出
4.反向传播
利用链式法则,计算损失函数对参数的梯度,用来更新参数。

5.代码
手工求导:即把导数直接写出来
自动求导:pytorch自带函数
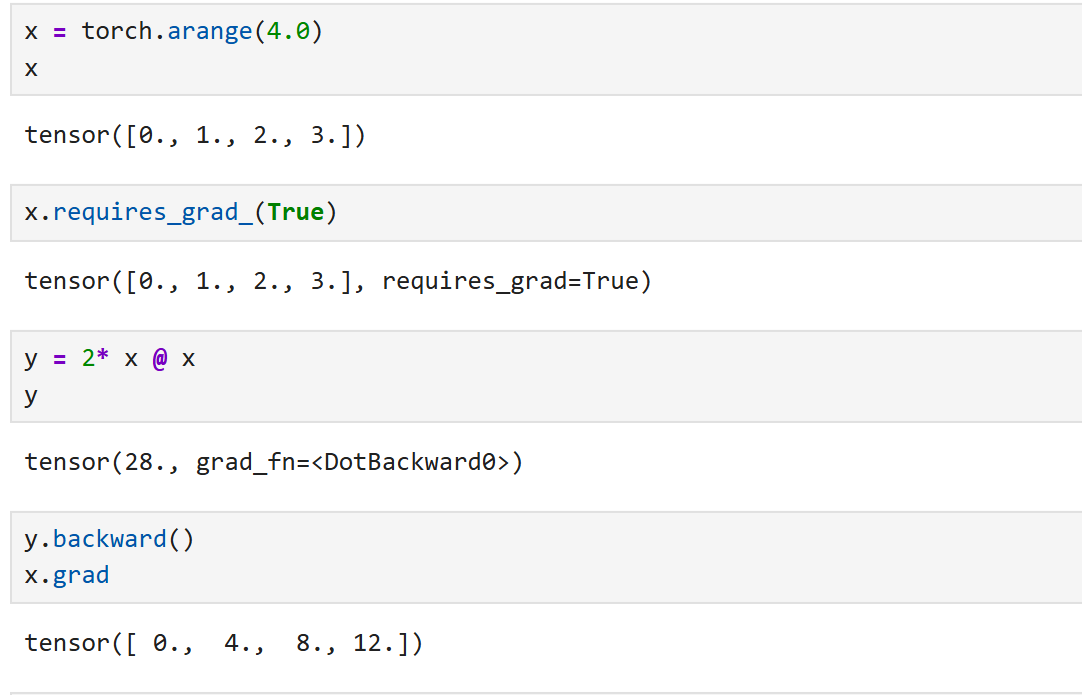
(1). 基础例子:点积 + backward
x = torch.arange(4.0)
x.requires_grad_(True)
y = 2 * torch.dot(x, x) # y = 2*(0² + 1² + 2² + 3²) = 28
y.backward()
print(x.grad) # tensor([ 0., 4., 8., 12.])
【1】requires_grad=True
x.requires_grad_(True)
作用:告诉 PyTorch 对这个张量 x 及其计算结果,追踪计算图,并能在 backward 时计算梯度。
_ 结尾说明它是 in-place 操作(直接修改 x 本身的属性)。
换句话说:
requires_grad=False(默认值):普通变量,不计算梯度。requires_grad=True:可训练变量,参与自动微分。
【2】backward的必要性
backward()
前向传播只建图,不算梯度。
只有调用
backward()
.grad
(2). 清零梯度
x.grad.zero_()
y = x.sum()
y.backward()
print(x.grad) # tensor([1., 1., 1., 1.])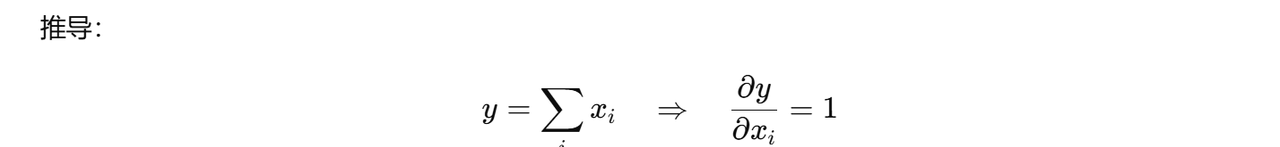
梯度是累加的,不是覆盖的
在 PyTorch 里,当你调用 backward() 时,计算出来的梯度会 累加 到 .grad 上,而不是直接替换
什么时候不需要清零?
如果 想要手动累加多个 batch 的梯度(比如梯度累积,显存不够时常用),那就不清零。
但在标准训练里,每个 batch 前都要清零。
(3). 元素平方
x.grad.zero_()
y = x * x
y.sum().backward()
print(x.grad) # tensor([0., 2., 4., 6.])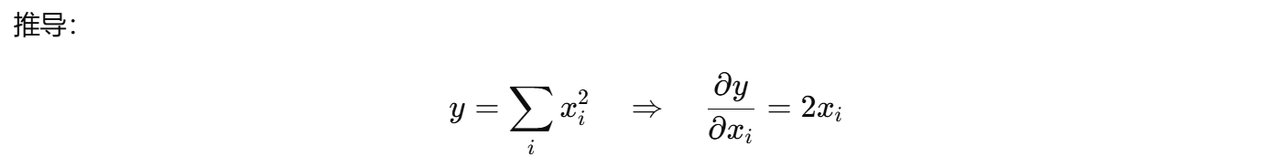
(4). 使用
.detach()
.detach()
x.grad.zero_()
y = x * x
u = y.detach() # u 不再跟踪梯度
z = u * x
z.sum().backward()
print(x.grad == u) # True

(5). Python 控制流里的梯度
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
print(a.grad == d / a)
© 版权声明
文章版权归作者所有,未经允许请勿转载。如内容涉嫌侵权,请在本页底部进入<联系我们>进行举报投诉!
THE END




















暂无评论内容