
原文
什么是 front matter
front matter的中文意思是前言,几乎每本书都会有前言,用来说明写书目的或者内容总结。
而 markdown 文件中的front matter指的是以yaml格式在文件开头增加的元数据,示例如下:
---
title: "为 obsidian 中的文件批量添加 front matter"
date: 2021-10-17 15:56
tags:
- obsidian
- frontmatter
---
front matter需要用---包裹
笔记软件或博客软件会拿到这些元数据做相应处理,列如上面这个front matter中 title 字段用来作为文章题目,date作为发布日期,tags 作为文章的标签列表
什么是obsidian

这里是指一款用于知识管理的笔记软件,支持双链、本地存储、插件、vim 模式、关系视图等,具体介绍见官网
什么是dataview
是obsidian上一款优秀的插件,可用类似于SQL一样的语句去查询obsidian中的文档,从而实现统计分析。
为什么要添加 front matter
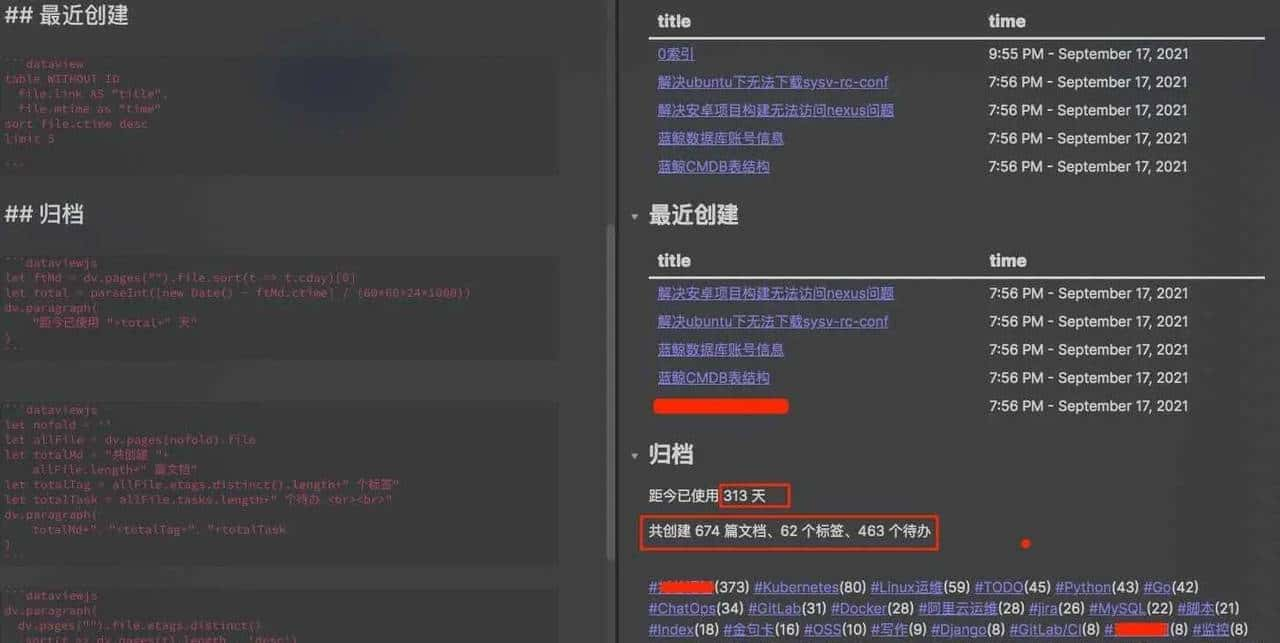
我使用 obsidian 软件已近一年,积累了不少笔记,在使用dataview插件做统计时发现一个问题:文件的创建时间不准。列如上图中这些文件很早就创建了,显示创建时间却是最近,而且这几个文件创建时间竟然一致,肯定有问题。
去查看文件实际创建时间才发现,和获取的是一样的,并无问题。
那到底是哪里出问题了呢?
由于我是基于 git 做同步的,列如在公司新建了几个文件,但是回家后并没有立即打开 obsidian 做同步,过了几天再拉下最新的文件,文件创建时间肯定变成当天了,而且是同时拉下来的,创建时间肯定一致了。
问题发现了,怎么解决呢?front matter就能解决这个问题。
可以在文件开头增加如下内容:
---
create_date: 2021-09-17 17:31
---
相当于给每个文件写死了创建时间,统计时基于front matter中这个create_date字段即可。
于是,最近创建的十篇文档的dataview统计语句便由
“`dataview
table WITHOUT ID
file.link AS “title”,
file.ctime as “time”
sort file.ctime desc
limit 10
“`
变成了
“`dataview
table WITHOUT ID
file.link AS “title”,
create_date as “time”
sort create_date desc
limit 10
“`
那么问题又来了?统计问题是解决了,如何去添加front matter呢?不会是手动吧。
当然不是。
具体实现
增量文档
使用Templater插件制作front matter模板
---
create_date: <% tp.file.creation_date() %>
---
配置新建文件时基于该模板创建,那么每次都会自动给文件添加带create_date的front matter了
存量文档
Templater当然也支持给存量文档添加front matter,但是存量文档有六百多篇,用手动的方式实在太累了,于是我写了一个 Python 脚本,实现批量在front matter中添加create_date与tags字段。
下载python-frontmatter
pip install python-frontmatter
模块使用见使用文档
编写脚本
# coding: utf-8
import os
import re
import time
import frontmatter
# 更新md文件的front matter:1.增加创建时间;2.提取tag
def update_front_matter(file):
with open(file, r , encoding= utf-8 ) as f:
post = frontmatter.loads(f.read())
is_write = False
if not post.metadata.get( create_date , None):
timeArray = time.localtime((os.path.getctime(file)))
post[ create_date ] = time.strftime("%Y-%m-%d %H:%M", timeArray)
if not is_write:
is_write = True
# 将代码块内容去掉
temp_content = re.sub(r ```([sS]*?)```[s]? , ,post.content)
# 获取tag列表
tags = re.findall(r s#[u4e00-u9fa5a-zA-Z]+ , temp_content, re.M|re.I)
ret_tags = list(set(map(lambda x: x.strip(), tags)))
print( tags in content: , ret_tags)
print( tags in front matter: , post.get("tags", []))
if len(ret_tags) == 0:
pass
elif post.get("tags", []) != set(ret_tags):
post[ tags ] = ret_tags
if not is_write:
is_write = True
if is_write:
with open(file, w , encoding= utf-8 ) as f:
f.write(frontmatter.dumps(post))
# 递归获取提供目录下所有文件
def list_all_files(root_path, ignore_dirs=[]):
files = []
default_dirs = [".git", ".obsidian", ".config"]
ignore_dirs.extend(default_dirs)
for parent, dirs, filenames in os.walk(root_path):
dirs[:] = [d for d in dirs if not d in ignore_dirs]
filenames = [f for f in filenames if not f[0] == . ]
for file in filenames:
if file.endswith(".md"):
files.append(os.path.join(parent, file))
return files
if __name__ == "__main__":
# file_path = ./xwlearn/test.md
# update_front_matter(file_path)
ignore_dirs = ["Resource", "Write"]
files = list_all_files( ./xwlearn/ , ignore_dirs=ignore_dirs)
print("current dir: ", os.path.dirname(os.path.abspath(__file__)))
for file in files:
print("---------------------------------------------------------------")
print( current file: , file)
update_front_matter(file)
time.sleep(1)
{{< admonition tip “如何匹配 tag”>}}
使用正则表达式,凡是#+字符均设为tag,但是有一个问题,代码块中有不少注释信息也会被匹配到,这就需要我们先忽略代码块中内容
temp_content = re.sub(r ```([sS]*?)```[s]? , ,post.content)
匹配tag 的正则(空格#中文字符与英文字符)
re.findall(r s#[u4e00-u9fa5a-zA-Z]+ , temp_content, re.M|re.I)
{{< /admonition >}}
{{< admonition tip “如何递归文件及忽略目录”>}}
使用os.walk遍历文件,并不是每个文件都需要添加front_matter,如果需要忽略某目录,就给list_all_files函数第二个参数传递相应的目录名,如上述脚本第 59 行,我 忽略了Resource与Write目录
def list_all_files(root_path, ignore_dirs=[]):
files = []
default_dirs = [".git", ".obsidian", ".config"]
ignore_dirs.extend(default_dirs)
for parent, dirs, filenames in os.walk(root_path):
dirs[:] = [d for d in dirs if not d in ignore_dirs]
filenames = [f for f in filenames if not f[0] == . ]
for file in filenames:
if file.endswith(".md"):
files.append(os.path.join(parent, file))
return files
{{< /admonition >}}

















暂无评论内容