
原文: https://magazine.sebastianraschka.com/p/beyond-standard-llms 有删减
从DeepSeek R1到MiniMax-M2,当今规模最大、能力最强的开放权重大语言模型仍然采用自回归解码器风格的Transformer架构,这些架构都基于原始多头注意力机制的不同变体。

(线性)注意力混合架构
近年来,线性注意力机制重新兴起,以提升大语言模型的效率。
传统注意力与二次成本
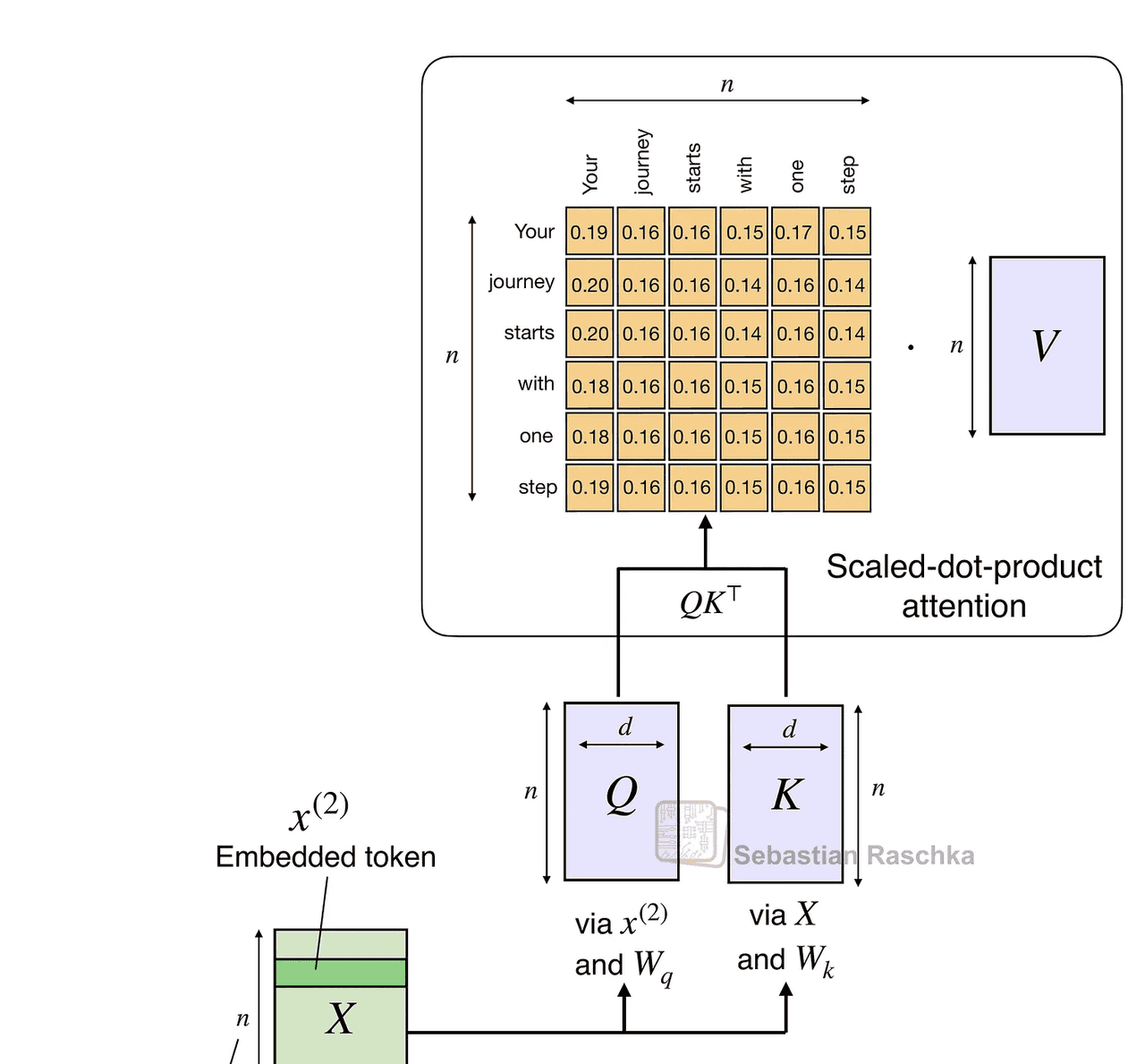
原始注意力机制随序列长度呈二次方扩展:

这是因为查询(Q)、键(K)和值(V)是 n×d 矩阵,其中 d 是嵌入维度(超参数),n 是序列长度(即令牌数量)。
线性注意力
线性注意力变体已存在多年,我记得在2020年代看到了大量相关论文。例如,我最早回忆起的是2020年的《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》论文,其中研究者通过以下方式近似注意力机制:
![图片[1] - Transformers之外的注意力机制 - 宋马](https://pic.songma.com/blogimg/20251115/6c89b389eafc41448feac6af1917d200.png)
此处 ϕ(⋅) 是一个核特征函数,设置为 ϕ(x) = elu(x) + 1。
这种近似之所以高效,是因为它避免了显式计算 n×n 注意力矩阵 QKᵀ。但归根结底,它们将时间和空间复杂度从 O(n²) 降低至 O(n),使得注意力机制对长序列的处理效率大幅提升。然而,这些方法从未真正流行起来,因为它们会降低模型精度,而且我从未在开放权重的顶尖大语言模型中见到这些变体的实际应用。
线性注意力复兴
今年下半年,线性注意力变体重新兴起,部分模型开发者之间还出现了一些反复讨论,如下图所示。
![图片[2] - Transformers之外的注意力机制 - 宋马](https://pic.songma.com/blogimg/20251115/87818c8d972e40dfbaa0685728b27311.png)
首个值得关注的模型是采用闪电注意力(lightning attention)的MiniMax-M1。
随后在8月,Qwen3团队推出了Qwen3-Next(我在前文已详细讨论)。9月,DeepSeek团队发布了DeepSeek V3.2(虽然其稀疏注意力机制并非严格线性,但计算成本至少是次二次的,因此我认为将其与MiniMax-M1、Qwen3-Next和Kimi Linear归为同一类别是合理的)。
这三个模型(MiniMax-M1、Qwen3-Next、DeepSeek V3.2)在大部分或全部层中用高效的线性变体取代了传统的二次注意力机制。
在线性注意力方面,Qwen3-Next和Kimi Linear都采用了Gated DeltaNet(Gated DeltaNet),将在接下来几节中以这种混合注意力架构为例进行讨论。
Qwen3-Next
我们先从Qwen3-Next说起,该模型使用Gated DeltaNet + Gated Attention混合机制取代常规注意力。
![图片[3] - Transformers之外的注意力机制 - 宋马](https://pic.songma.com/blogimg/20251115/21fb5bc863c54623bad5c47287f8133c.png)
如上图所示,注意力机制通过门控注意力或门控DeltaNet实现。这意味着该架构中的48个Transformer块(层)会交替使用这两种机制。具体来说,如前所述,它们以3:1的比例交替排列。例如,Transformer块的排列顺序如下:
第1-3层:Gated DeltaNet第4层:Gated Attention第5-7层:Gated DeltaNet第8层:Gated Attention…(以此类推,共48层)
Gated Attention
在深入探讨Gated DeltaNet之前,我们先简要说明Gated机制。从前面图示中Qwen3-Next架构的上半部分可以看出,该模型采用了“Gated Attention”。这本质上是在常规完整注意力机制基础上增加了sigmoid门控。
通过sigmoid函数将其约束在0到1之间,并与注意力输出相乘。这使得模型能够动态调整某些特征的权重。Qwen3-Next开发团队指出这有助于提升训练稳定性:
[…] 注意力输出门控机制有助于消除注意力下沉和大规模激活值等问题,确保模型整体的数值稳定性。
Gated DeltaNet
那么,什么是门控DeltaNet?门控DeltaNet(Gated Delta Network的简称)是Qwen3-Next采用的线性注意力层,旨在替代标准的softmax注意力机制。它借鉴自前文提到的论文《Gated Delta Networks: Improving Mamba2 with Delta Rule》。
Delta规则部分指的是计算新值与预测值之间的差异(delta,Δ),用于更新作为记忆状态的隐藏状态。
如下所示,门控DeltaNet采用了与前述门控注意力相似的门控机制,不同之处在于它使用SiLU激活函数而非逻辑sigmoid函数(选择SiLU可能是为了改善梯度流与稳定性)。
![图片[4] - Transformers之外的注意力机制 - 宋马](https://pic.songma.com/blogimg/20251115/e8a36ecd219c4d2cacd5479911055736.png)
然而,如上图所示,除输出门外,门控DeltaNet中的“门控”还涉及多个附加门控:
α(衰减门)控制记忆随时间的衰减或重置速度β(更新门)控制新输入对状态的修改强度
在门控注意力中,模型计算所有令牌间的标准注意力(每个令牌关注其他所有令牌),随后通过sigmoid门控决定保留多少注意力输出。关键在于它仍是随上下文长度呈二次扩展的标准缩放点积注意力。
回顾一下,缩放点积注意力的计算方式为softmax(QKᵀ)V,其中Q和K是n×d矩阵(n为输入令牌数,d为嵌入维度)。因此QKᵀ会生成n×n注意力矩阵,再与n×d维的值矩阵V相乘。
而在门控DeltaNet中,不存在n×n注意力矩阵。模型逐令牌处理数据,维护一个随新令牌输入而更新的运行记忆(状态)。这体现为代码中随时间步t循环更新的状态S。
门控机制控制着记忆的更新方式:
α控制旧记忆的遗忘(衰减)程度β控制当前时刻t的令牌对记忆的更新强度
(未在代码片段中展示的最终输出门与门控注意力类似,控制输出保留比例)
从某种意义上说,门控DeltaNet中的状态更新类似于循环神经网络的工作方式。其优势在于通过循环处理实现了与上下文长度的线性而非二次方扩展。
但这种循环状态更新的缺点在于,与常规(或门控)注意力相比,它牺牲了全配对注意力所具有的全局上下文建模能力。门控DeltaNet虽能一定程度捕获上下文,但必须通过记忆瓶颈S来实现——该记忆具有固定尺寸因而更高效,但会将过往上下文压缩至单一隐藏状态中(与RNN类似)。
DeltaNet内存优化
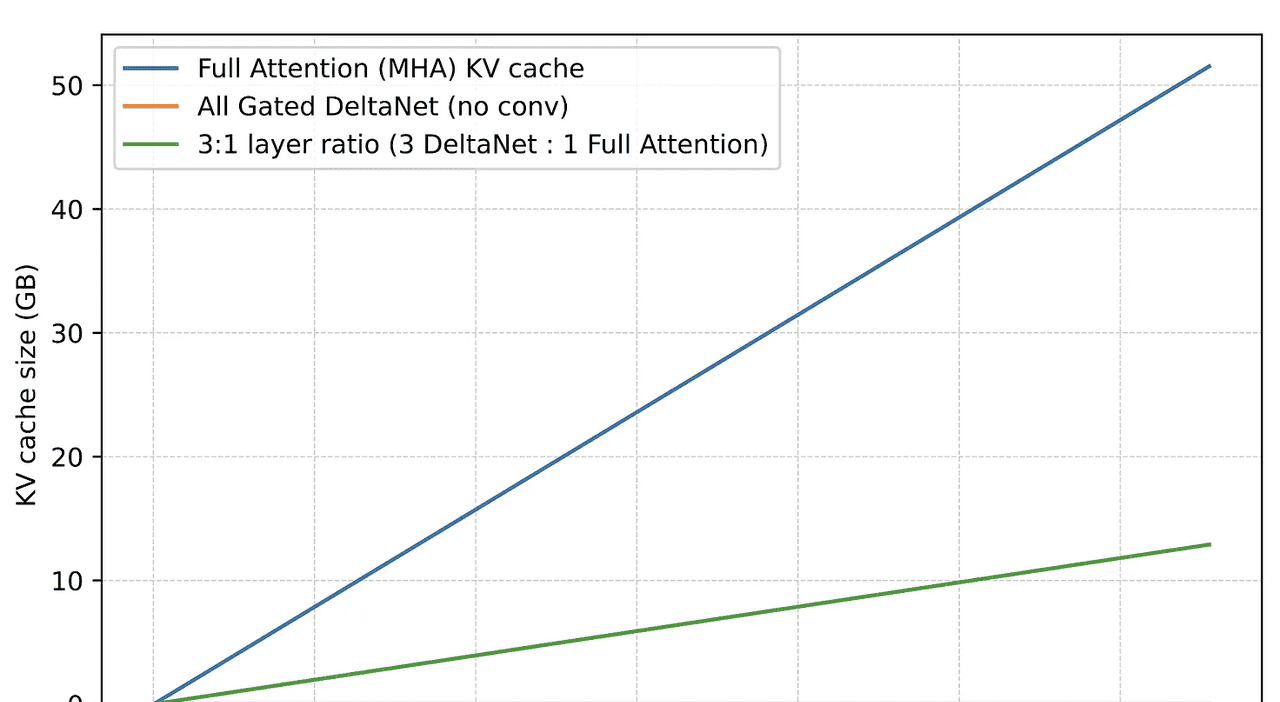
在上一节中,我们讨论了DeltaNet相对于全注意力机制的优势——其计算复杂度随上下文长度呈线性而非二次方增长。
除了线性计算复杂度外,DeltaNet的另一大优势在于内存节省,因为DeltaNet模块不会增长KV缓存。如前所述,它们维持一个固定大小的循环状态,因此内存占用随上下文长度保持恒定。
对于常规的多头注意力层,我们可以通过以下公式计算KV缓存大小:
KV_cache_MHA ≈ batch_size × n_tokens × n_heads × d_head × 2 × bytes
(乘数2的存在是因为我们需要在缓存中同时存储键和值。)
对于前文实现的简化版DeltaNet,其缓存为:
KV_cache_DeltaNet = batch_size × n_heads × d_head × d_head × bytes
值得注意的是,KV_cache_DeltaNet的内存大小与上下文长度(n_tokens)无关。同时,我们仅存储记忆状态S而非独立的键和值,因此2 × bytes简化为bytes。但需要注意,此处出现了二次项d_head × d_head,这源于状态矩阵的维度。
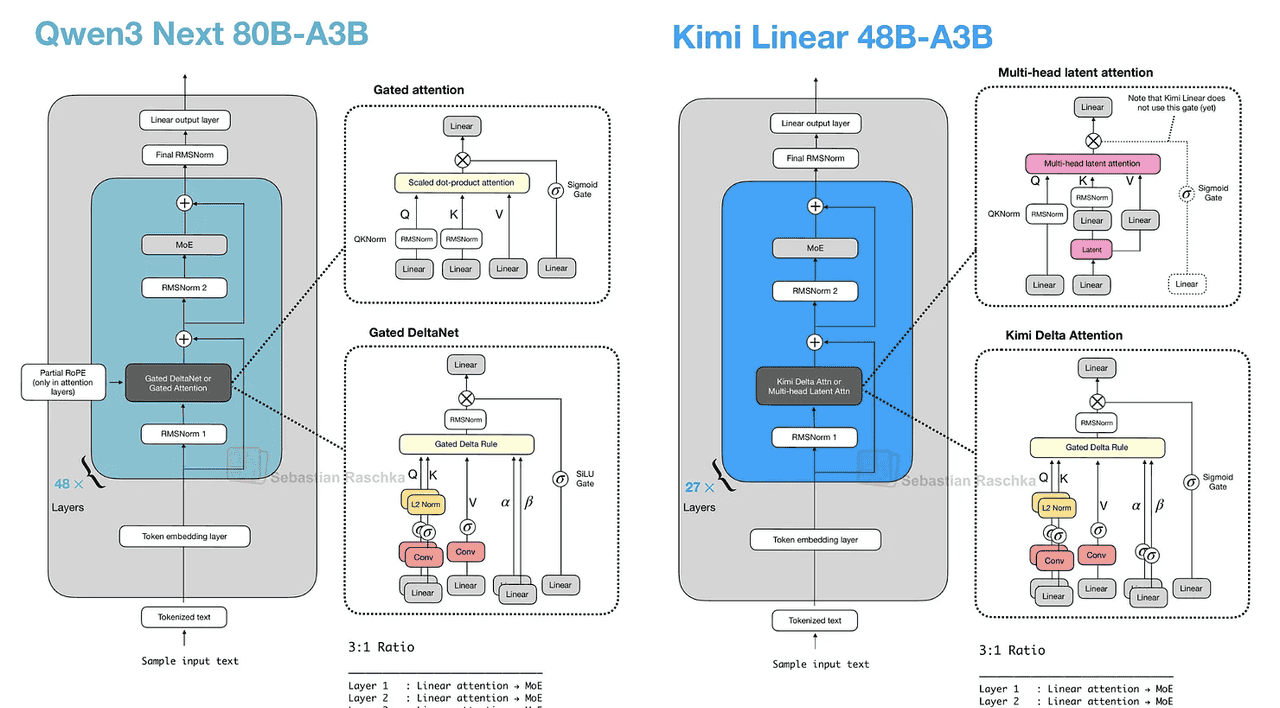
Kimi Linear与Qwen3-Next对比
Kimi Linear与Qwen3-Next在结构上存在诸多相似之处。两款模型均采用混合注意力策略:具体而言,它们将轻量级线性注意力与计算量更大的全注意力层相结合。特别值得注意的是,两者均使用3:1的配比方案,即每三个使用线性Gated DeltaNet变体的Transformer块后,会搭配一个使用全注意力的块(如下图所示)。
Kimi Delta Attention
Kimi Linear通过Kimi Delta Attention机制对Qwen3-Next的线性注意力机制进行了改进,这本质上是Gated DeltaNet的优化版本。
Qwen3-Next采用标量门控(每个注意力头一个值)控制记忆衰减速率,而Kimi Linear则将其替换为针对每个特征维度的通道级门控。据作者称,这种设计能提供更精细的记忆控制,从而提升长上下文推理能力。Kimi Linear在长上下文和推理基准测试中表现优于MLA这一事实,使得线性注意力变体再次为更大型的顶尖模型带来了希望。
注意力混合架构的未来
线性注意力并非新概念,但近期混合方法的复兴表明研究人员正再次认真寻找提升Transformer效率的实用路径。例如,相较于常规全注意力机制,Kimi Linear实现了75%的KV缓存减少和最高6倍的解码吞吐量提升。
新一代线性注意力变体与早期尝试的根本区别在于,它们不再完全替代标准注意力,而是与其协同工作。
展望未来,预计下一波注意力混合架构将聚焦于进一步提升长上下文稳定性与推理精度,以逐步逼近全注意力机制的顶尖性能水平。
Text Diffusion Models
那么扩散模型有何优势?研究人员为何将其作为传统自回归大语言模型的替代方案来探索?
基于Transformer的传统(自回归)大语言模型逐令牌生成文本。为简洁起见,我们将其统称为自回归大语言模型。而基于文本扩散的大语言模型(暂称“扩散大语言模型”)的主要卖点在于能够并行生成多个令牌,而非顺序生成。
需注意,扩散大语言模型仍需要多步去噪处理。但即使某个扩散模型需要64步去噪来并行生成所有令牌,这仍然比逐次执行2000步生成2000个令牌的响应在计算上更高效。
去噪过程
文本扩散过程持续将[MASK]令牌替换为文本令牌以生成答案。若您熟悉BERT和掩码语言建模,可将此扩散过程视为BERT前向传递的迭代应用(每次使用不同掩码率)。
架构方面,扩散大语言模型通常采用解码器风格Transformer,但不使用因果注意力掩码。例如前述LLaDA模型基于Llama 3架构。这种无因果掩码的架构被称为“双向”模型,因为它们能同时访问所有序列元素。(注意这与BERT架构类似,后者因历史原因被称为“编码器风格”。)
扩散大语言模型通过随机渐进掩码令牌来破坏文本:每个令牌以指定概率被特殊掩码令牌替换。模型随后学习逐步预测缺失令牌的逆向过程,从而有效“去噪”(即解掩码)恢复原始文本。
文本扩散现状
当前出现有趣趋势:视觉模型采纳来自大语言模型的注意力等组件及Transformer架构本身,而文本大语言模型则从纯视觉模型获得灵感,为文本实现扩散机制。
扩散大语言模型是值得探索的方向,但目前尚无法取代自回归大语言模型。不过我认为它们可作为较小规模设备端大语言模型的替代方案,或许能取代经蒸馏的小型自回归大语言模型。
例如谷歌已宣布正在开发文本扩散模型Gemini Diffusion,并表示:
快速响应:生成内容的速度显著超越我们迄今最快的模型。
Small Recursive Transformers
专注于推理的架构并不总是必须规模庞大。事实上,随着分层推理模型(HRM)的出现,一种关于小型递归变换器的新方法最近在研究界获得了大量关注。
更具体地说,HRM的开发者表明,即使是非常小的变换器模型(仅包含4个块),当被训练以逐步优化其答案时,也能(在特定问题上)发展出令人印象深刻的推理能力。这使它在ARC挑战赛中获得了顶尖排名。
像HRM这样的递归模型背后的思想是,模型不是通过一次前向传播产生答案,而是以递归的方式反复优化其自身的输出。(在此过程中,每次迭代都会优化一个潜在表示,作者将其视为模型的“思考”或“推理”过程。)
第一个主要例子是今年早些时候的HRM,随后是混合递归(MoR)论文。
最近,《少即是多: Tiny 网络的递归推理》(2025年10月)提出了微型递归模型(TRM,如下图所示),这是一个更简单、更小的模型(700万参数,比HRM小约4倍),在ARC基准测试中表现甚至更好。
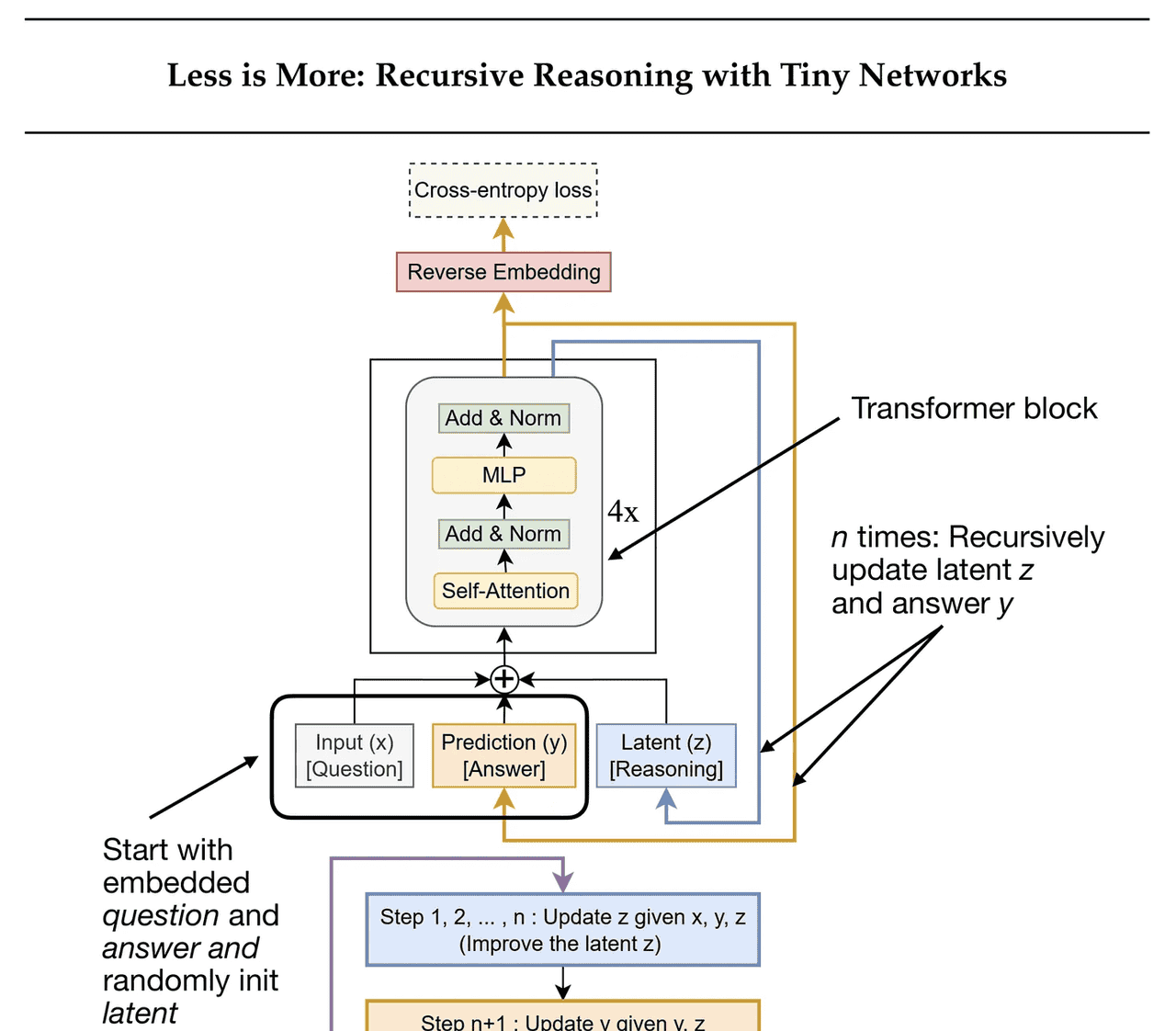
这里的递归是什么意思?
TRM通过两种交替更新来优化其答案:
它从当前问题和答案计算出一个潜在推理状态。然后基于该潜在状态更新答案。
需要注意的是,TRM并非操作文本的语言模型。然而,由于
(a)它是基于变换器的架构
(b)推理现在是LLM研究的核心焦点,而该模型代表了一种截然不同的推理方法
(c)许多读者要求我涵盖HRM(而TRM是其更先进的继任者),我决定在此包含它。
TRM 与 HRM 有何不同?
HRM由两个小型变换器模块(每个4个块)组成,这些模块在递归级别之间通信。TRM仅使用一个2层变换器。(注意,之前的TRM图中在变换器块旁边显示了一个4×,但这可能是为了更容易与HRM进行比较。)
TRM通过所有递归步骤进行反向传播,而HRM仅通过最后几个步骤进行反向传播。
HRM包含一个明确的停止机制来确定何时停止迭代。TRM用一个简单的二元交叉熵损失替换了该机制,该损失学习何时停止迭代。
更大的背景
尽管HRM和TRM在这些基准测试中实现了非常好的推理性能,但将它们与大型LLM进行比较并不完全公平。HRM和TRM是专用于ARC、数独和迷宫路径规划等任务的专用模型,而LLM是通用模型。当然,HRM和TRM也可以适配其他任务,但必须针对每个任务进行专门训练。因此,从这个意义上说,我们或许可以将HRM和TRM视为高效的口袋计算器,而LLM更像计算机,可以执行许多其他任务。





















暂无评论内容