
论文标题:
10Cache: Heterogeneous Resource-Aware Tensor Caching and Migration for LLM Training
论文链接:
https://arxiv.org/pdf/2511.14124
一句话总结 (TL;DR)
10CACHE解决了大型语言模型(LLM)训练中GPU内存不足导致的效率瓶颈,通过创新的异构资源感知张量缓存与迁移技术,将训练速度提升至多2倍,并显著提高内存利用率。
研究背景:为什么这项研究很重要?
随着LLM参数规模突破万亿级,训练所需的内存已远超单块GPU的容量(如H100仅80GB)。云上训练成本高昂,业界常通过将张量卸载到CPU或NVMe硬盘来扩展内存,但现有方法(如DeepSpeed ZeRO-Infinity)存在明显缺陷:数据迁移延迟高,且GPU和CPU内存利用率低下(仅38%-74%),导致训练时间延长和资源浪费。
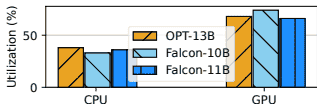
例如,训练一个70B参数的模型时,GPU内存可能频繁等待张量从慢速存储中加载,造成计算卡顿。这种内存墙瓶颈已成为LLM普惠化训练的主要障碍,尤其对成本敏感的中小企业而言。
核心思想与方法:它的解决方案是什么?
10CACHE的核心思想是将异构内存(GPU、CPU、NVMe)视为一个整体,通过动态调度张量位置来最小化数据迁移开销。其工作原理类似“智能交通系统”:根据张量的使用时机,提前将其调度到高速车道(GPU内存),避免拥堵等待。系统包含四个关键组件:
张量特征分析器:预跑模型一次,记录每个张量的执行顺序、大小和活跃时间,生成“预取时刻表”。缓存分配器:预分配固定大小的内存缓冲区(如512B、1KB块),复用这些缓冲区避免重复分配开销,并采用CPU固定内存加速传输。张量分配器:根据内存容量动态分配张量位置——优先驻留GPU,次选CPU,最后NVMe。预取-驱逐调度器:在GPU计算时异步迁移数据,例如在前向传播中提前加载下一层张量,并淘汰已用张量。
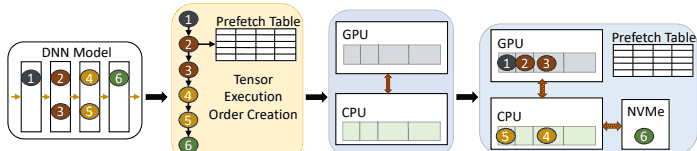
例如,训练时若GPU内存仅能容纳当前层,10CACHE会提前将下一层张量从NVMe悄悄加载到CPU缓冲区,待GPU就绪时直接传入,实现“零等待”。
实验与效果:它的效果如何?
论文在OPT、Falcon、Bloom等模型上对比了8种基线方法(如ZeRO-Infinity、Megatron-LM)。关键结果如下:
训练速度:在单GPU训练7B参数模型时,10CACHE比ZeRO-Infinity提速2倍(图10),在13B模型上仍快25%。缓存命中率:GPU缓存命中率提升高达86.6倍(图15),因更多张量直接驻留GPU。资源利用率:CPU/GPU内存利用率分别提升2.15倍和1.33倍(表7),大幅减少NVMe依赖。延迟优化:93%的张量加载等待时间低于0.03ms(图13),而基线方法常因同步加载产生卡顿。
这些优势源于10CACHE精准的张量生命周期预测和异步数据传输,使其在批大小增加时仍保持稳定性能(图20)。
价值与展望:它对我们有什么启发?
实际应用:
云成本优化:企业可用中低端GPU(如L40S)微调10B级模型,降低云账单30%以上。边缘训练:为资源受限设备(如工作站)提供大模型轻量化训练能力。环保意义:通过提升硬件效率,减少训练碳足迹。
未来方向:
当前仅支持静态计算图(如Transformer),需扩展至动态图模型(如MoE)。分布式版本尚未开发,未来可结合流水线并行进一步扩展。推理场景潜力待挖掘,如优化KV缓存管理。
局限性在于依赖预分析阶段,但开销仅占训练时间1%(表8),对长周期训练可忽略。
总结
10CACHE通过“预测式张量调度”和“多级内存池化”,实现了LLM训练效率的阶跃式提升。它不仅是一项内存优化技术,更为云原生AI训练提供了可扩展、低成本的工程范本,有望加速大模型的普及化进程。
关于作者
大家好,我是宝爷,浙大本科、前华为工程师、现某芯片公司系统架构负责人,关注个人成长。
新的图解文章都在公众号「宝爷说」首发,别忘记关注了哦!
感谢你读到这里。
如果这篇文章对您有所帮助,欢迎点赞、分享或收藏!你的支持是我创作的动力!
如果您不想错过未来的更新,记得点个星标 ⭐,下次我更新你就能第一时间收到推送啦。






















暂无评论内容