
你想一键拥有私有部署的阿里开源的声音克隆模型CosyVoice吗?
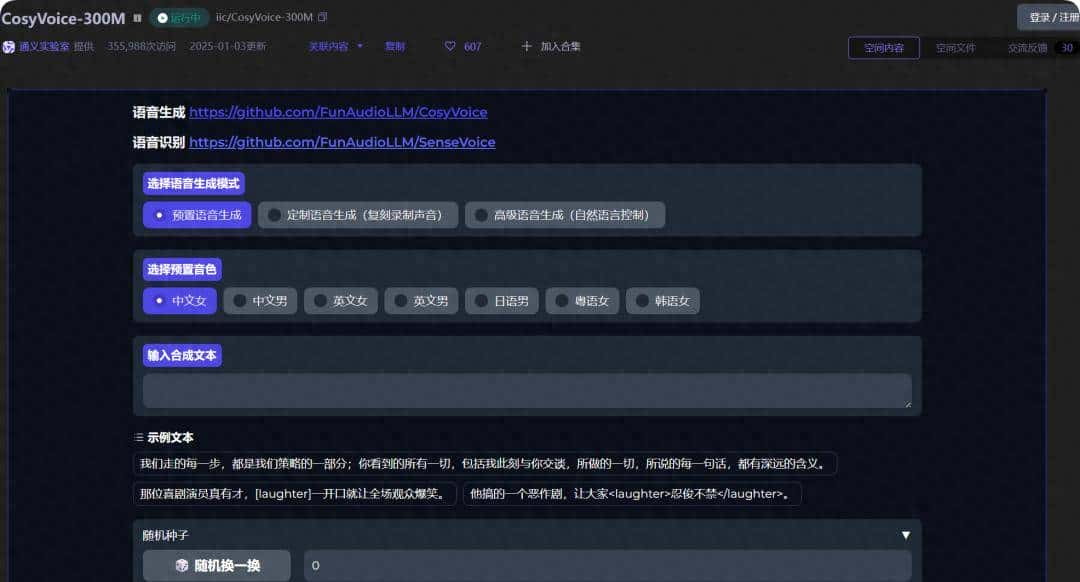
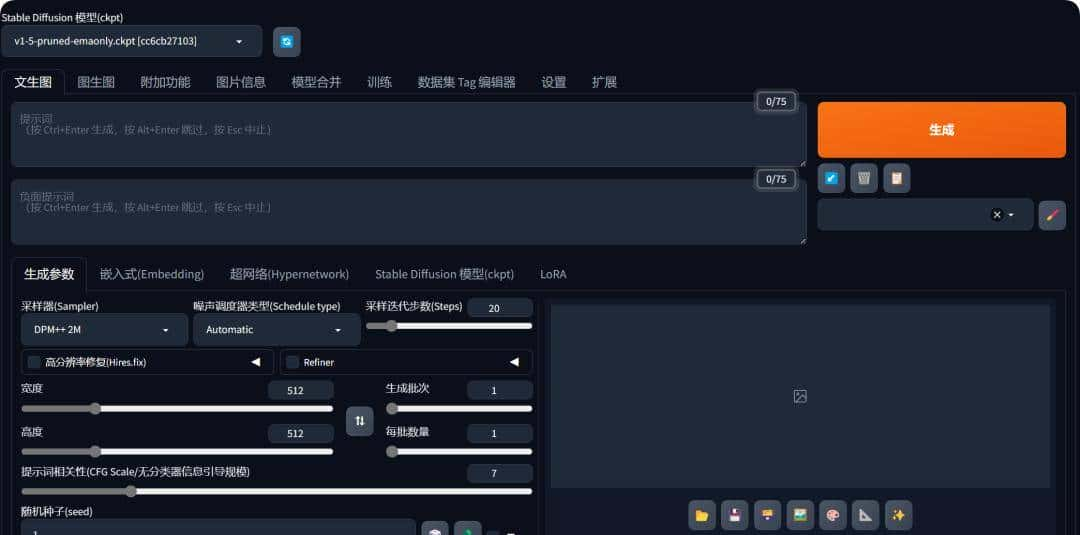
你想一键拥有私有部署的文生图模型StalbeDiffusion吗?
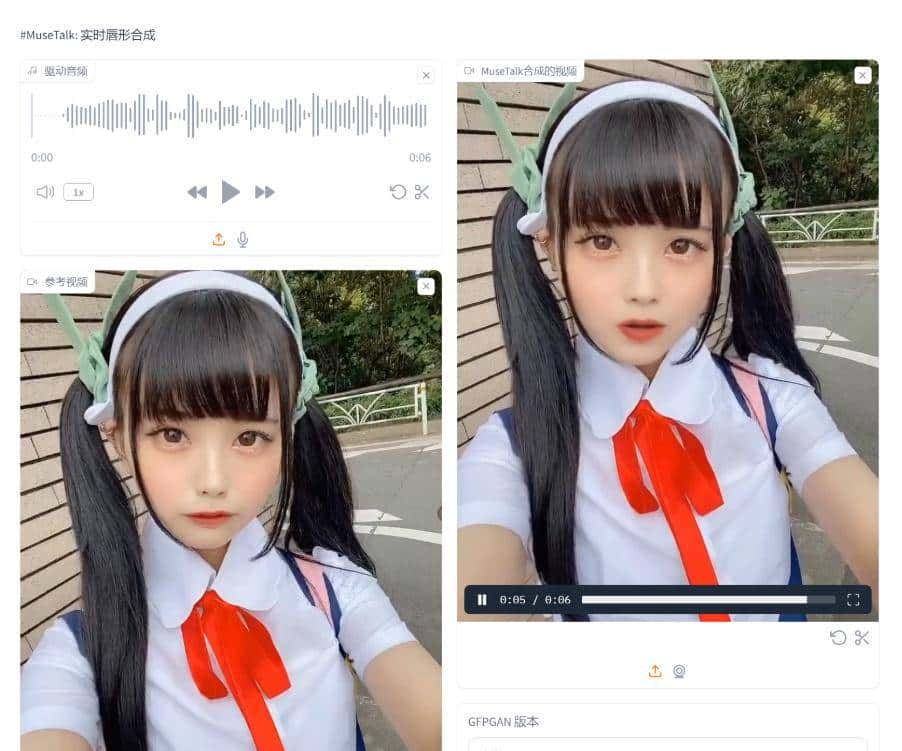
你想一键部署腾讯对口型的开源数字人模型MuseTalk吗?
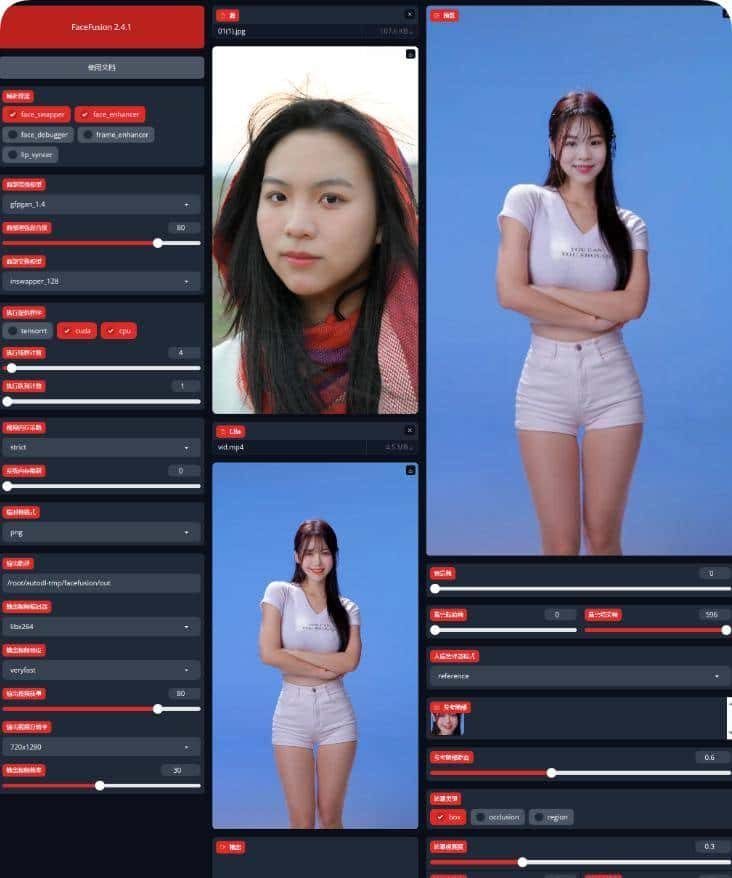
你想一键部署换脸模型FaceFusion吗?
真的只需要一键!我折腾过很长时间的这种模型的部署,踩过许多坑,列如用Google Colab的千兆宽带快速制作镜像,然后将这个Linux系统打包下载;列如直接在云服务器商做成Docker镜像等等!这种模型的部署的大坑主要有两点:
1.国内的网速太慢了,大部分模型权重文件需要从HuggingFace上下载,这个网站国内是没法访问的!能访问速度也很感人!光这一关就花掉许多时间。
2.各种开源的模型还不成熟就匆匆开源了,等你部署的时候,会发现各种python包的版本不匹配,各种配置文件乱七八糟,你自己从零去调试,又浪费了许多时间。等你部署完,新的模型又出来了 ,你花了大时间研究的模型已经成了明日黄花!
这种感觉真的太痛苦了,当时义愤填膺的我,忍不住给模型的作者发过邮件吐槽!列如腾讯的MuseV开源模型!
事后也收到了腾讯团队他们的回信,目前回想起来,觉得自己有点过于情绪化了!

所以,如果大家想体验数字人的开源模型,千万不要自己部署了,太浪费时间了,可以用一下下面这个方法。
国内国外有许多GPU服务商,他们都有自己的社区,提供免费的Docker镜像下载,直接下载他们现成的镜像就可以了。
直说最有用的方法,魔搭社区当然是最好的,但是本地部署还是不太好用。国内做的最好的就是AutoDL,它的社区是CodeWithGPU ,里面可以找到超级多的模型。
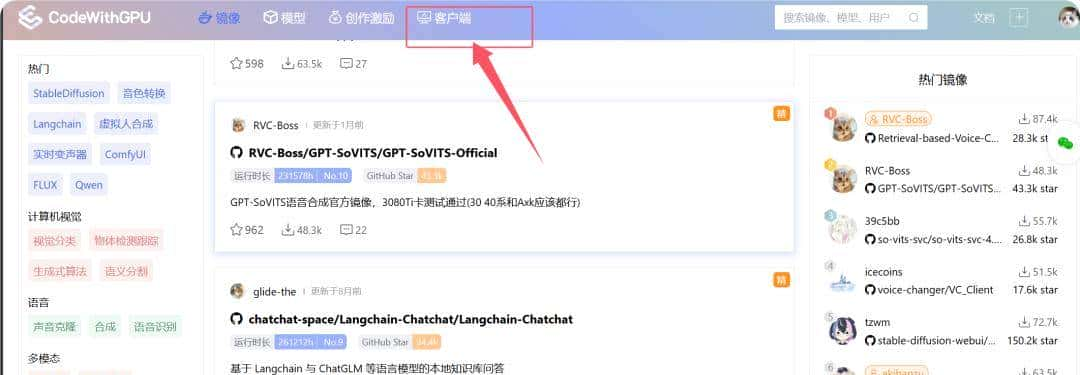
我们需要做的就是下载它的客户端到Linux主机上,运行服务,然后访问localhost:2022+token的链接。
# 下载客户端并添加可执行权限
wget -O cg-client https://codewithgpu.ks3-cn-beijing.ksyuncs.com/cg-client
chmod +x cg-client
# 启动客户端,需要使用到sudo权限否则有docker使用上的异常
sudo ./cg-client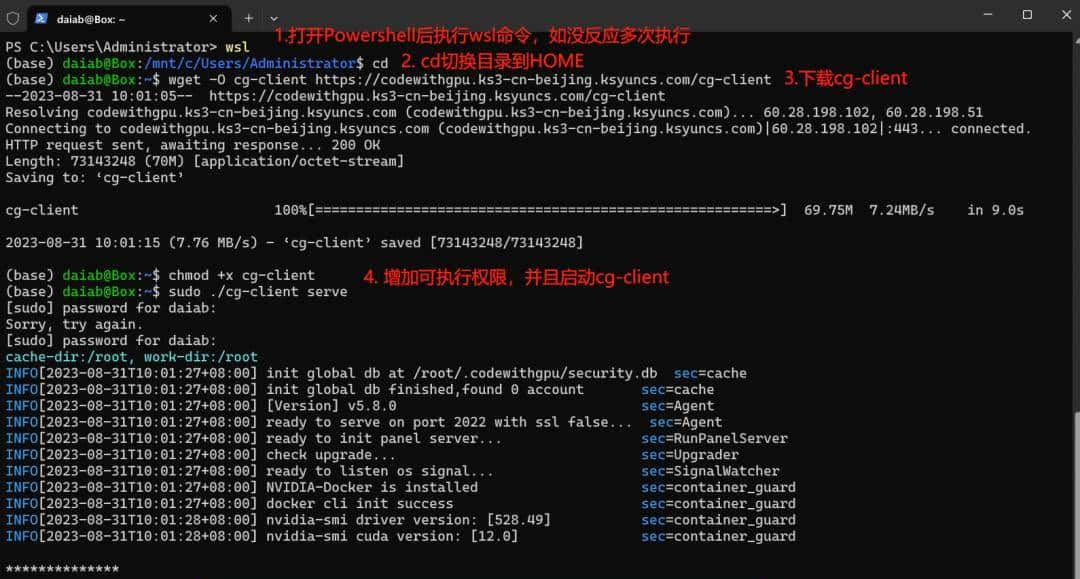
在本地访问这个链接(可以使用vscode将2022端口转发到本地),然后安装下图的方法下载镜像!
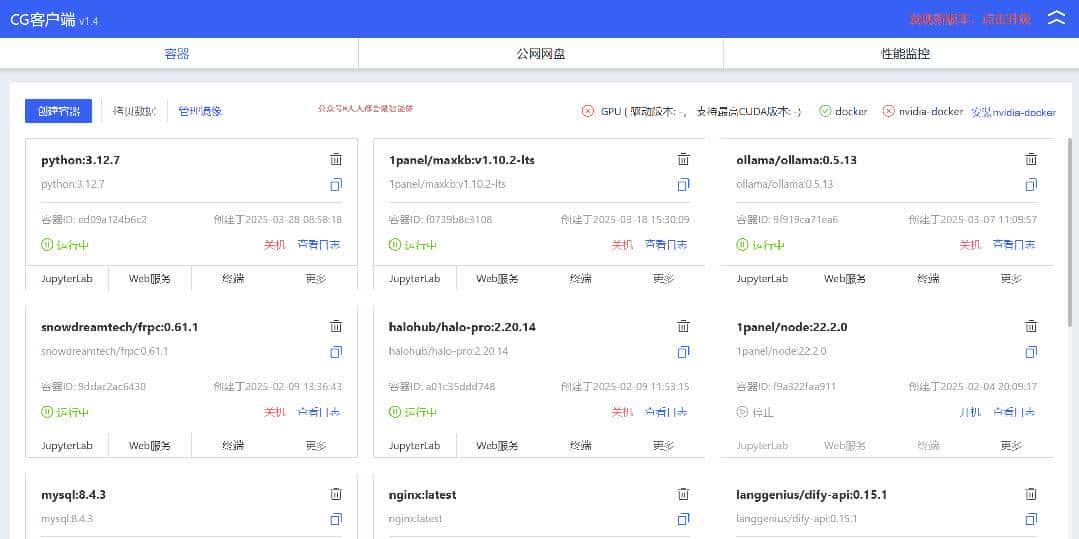
下载速度还算不错,基本1个小时内都能下载完成。重大的是这些镜像可以直接使用,不需要自己部署了,如果怕浪费时间,可以直接在线租赁GPU先体验一番。
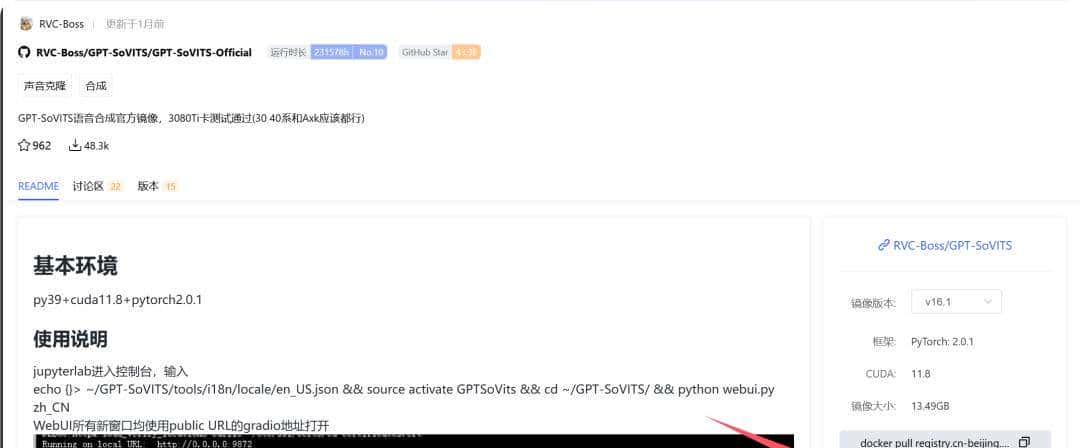
我目前个人使用的声音克隆、声音合成、文生图、对口型的数字人模型,基本都是从这里获取的。
模型下载完成后,不需要继续使用它的客户端对容器进行管理,可以直接用1Panel面板,把创建的容器删除,将镜像修改标签后,重新创建容器。
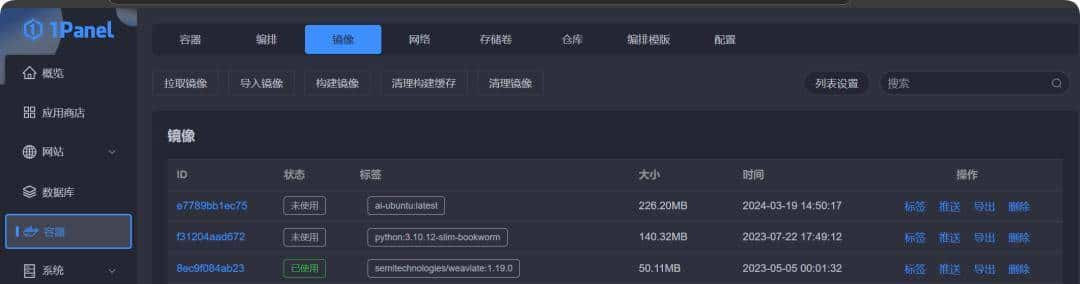
如果想对镜像做备份,可以直接将镜像推送到阿里云或者腾讯云上的容器管理服务就可以了。





![[office] Excel 输入时如何自动标注颜色 - 宋马](https://pic.songma.com/blogimg/20250413/e6171a9f169940b0a92fbc4ffbd8ba0e.jpg)













- 最新
- 最热
只看作者