
目录
1. 什么是 “CDC”
2. Flink CDC 介绍
3. 一个简单的栗子
4. 与传统 CDC ETL 对比分析
5. 学习资料
1. 什么是 “CDC”
CDC 的全称是 Change Data Capture ,字面意思是“变化数据捕获”。广义上讲,是指各种能捕获数据变更的技术。一般谈到的 CDC 技术,主要指的是面向数据库的变更,监测并捕获数据库的变动(增删改等),将这些变更发送到下游消息中间件、数据库中。CDC 技术常应用在数据采集、数据分发、数据迁移等应用场景中。
1.2 CDC 实现机制
目前,业界主流的 CDC 实现机制可以分为两种:
① 基于查询的 CDC:
- 离线调度查询作业,批处理。依赖表中的更新时间字段,执行查询获取表中最新的数据。
- 无法捕获删除事件,无法保证数据一致性。
- 无法保障实时性,基于离线调度天然存在延迟。
② 基于日志的 CDC:
- 实时消费日志,流式处理。例如,MySQL 的 binlog 日志完整记录了数据库中的变更,把 binlog 文件当作流的数据源。
- 保障了数据一致性,binlog 日志文件包含了所有历史变更明细。
- 保障了实时性,binlog 日志文件可以“流式”消费,提供实时数据。
两种实现机制对比
|
基于查询实现CDC |
基于日志实现CDC |
|
|
典型产品 |
Sqoop/DataX/Kettle 等 |
Canal/Debezium/Flink CDC 等 |
|
执⾏模式 |
批处理 |
流处理 |
|
捕获所有数据变化 |
否 |
是 |
|
延迟性 |
高延迟 |
低延迟 |
|
数据库负载/业务入侵 |
入侵式 |
非入侵式 |
|
捕获删除事件 |
否 |
是 |
|
捕获旧记录的状态 |
否 |
是 |
基于日志的 CDC 实现起来可能会更复杂。但可以看到,具有数据捕获延迟低,能够提供准确的“变更”流,对源系统影响小等特点,超级适合实时场景。
1.2 CDC 常见方案对比
借鉴一张网上比较常见的 CDC 方案对比分析图:

- 对于DataX 等查询型的 CDC 机制,实际上并不是完全不支持“增量同步”,条件是需要侵⼊业务(提供增量字段)才能做到增量同步的,⽽且是 T+1 的增量同步。
- 在全量+增量一体化同步方面,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
- 在架构方面,需要像 Flink CDC 等具有超级灵活的水平扩展能力的分布式架构。而 DataX 和 Canal 是个单机架构。
- 在数据加工的能力上,Flink CDC 依托强劲的 Flink SQL 流式计算能力,可以超级方便地对数据进行加工。而 Debezium 等则需要通过复杂的 Java 代码才能完成,使用门槛比较高。
- 在生态方面,对上下游存储的支持。Flink CDC 上下游超级丰富,支持对接 MySQL、PostgreSQL 等数据源,还支持写入到 TiDB、HBase、Kafka、Hudi 等各种存储系统中,也支持自定义 Connector。
2. Flink CDC 介绍
Flink CDC 的核心实现是基于 Flnk 的一组源连接器(flink-cdc-connectors),它可以从不同数据库接收“更改”。Flink CDC Connectors,集成了 Debezium 作为捕获数据更改的引擎。因此,它可以充分利用 Debezium 的能力。
什么是 Debezium?
Debezium 是一个开源项目,它将现有数据库中的信息转换为事件流,使应用程序能够检测数据库中的行级更改并立即做出响应。Debezium 构建在 Apache Kafka 之上,并提供了一组与 Kafka Connect 兼容的连接器。每个连接器都与特定的数据库管理系统(DBMS)一起工作。连接器通过检测发生的更改,并将每个更改事件的记录流式传输到 Kafka Topic,来记录 DBMS 中数据更改的历史。然后,使用应用程序可以从Kafka主题中读取生成的事件记录。
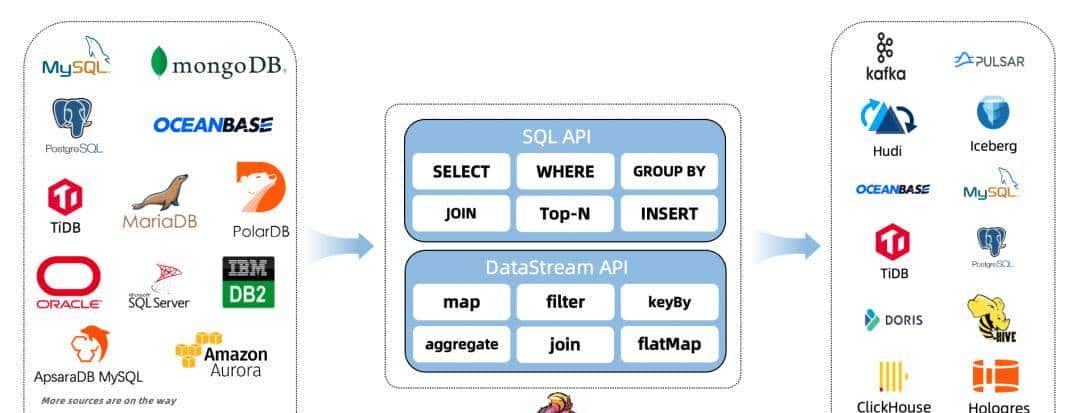
2.1 支持的 Connector
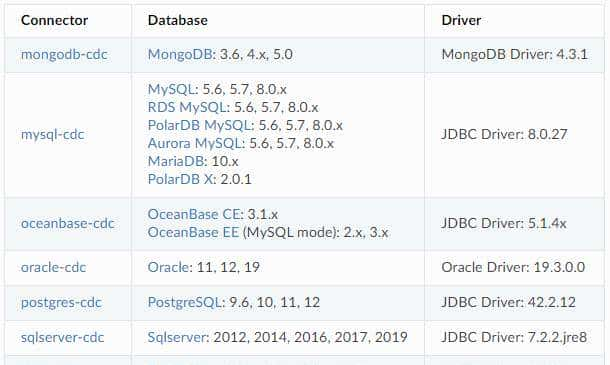
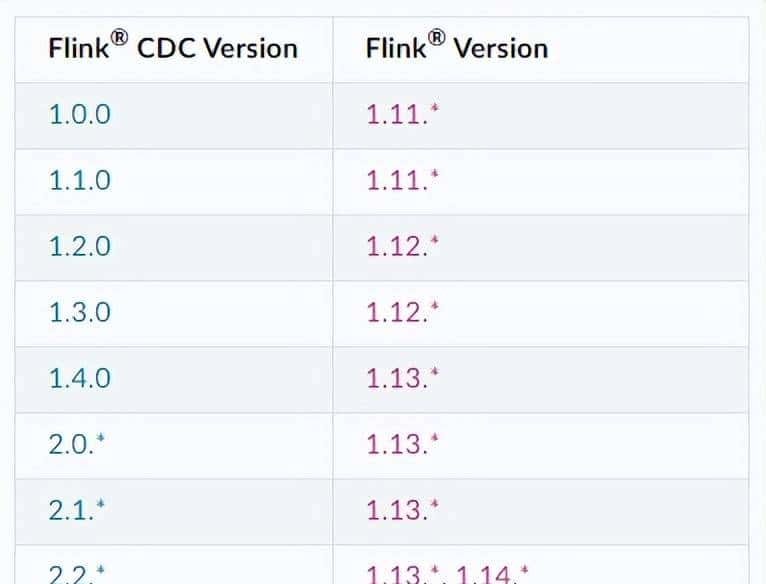
2.2 支持的 Flink 版本
2.3 如何使用 API
① 使用 Table/SQL API
-- creates a mysql cdc table source
CREATE TABLE mysql_binlog (
id INT NOT NULL,
name STRING,
description STRING,
weight DECIMAL(10,3),
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'flinkuser',
'password' = 'flinkpw',
'database-name' = 'inventory',
'table-name' = 'products'
);
-- read snapshot and binlog data from mysql, and do some transformation, and show on the client
SELECT id, UPPER(name), description, weight FROM mysql_binlog;② 使用 DataStream API
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
public class MySqlBinlogSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // set captured database
.tableList("yourDatabaseName.yourTableName") // set captured table
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enable checkpoint
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}
}
3. 一个简单的栗子
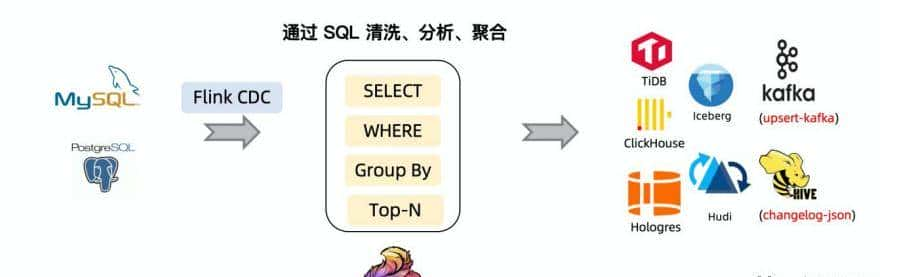
假设:基于 Flink CDC,实现一个的简单 demo,读取 MySQL(订单明细表) 并写入 MySQL(按渠道汇总订单量),下面基于 Flink SQL 零编码实现,最后在 SQL Client 进行作业提交。
3.1 准备数据
① 创建订单明细表 sxg_order,并写入 6 条数据:
CREATE TABLE `sxg_order` (
`order_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '订单ID',
`amount` int(11) NOT NULL COMMENT '订单量',
`channel_id` int(11) NOT NULL COMMENT '渠道ID',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8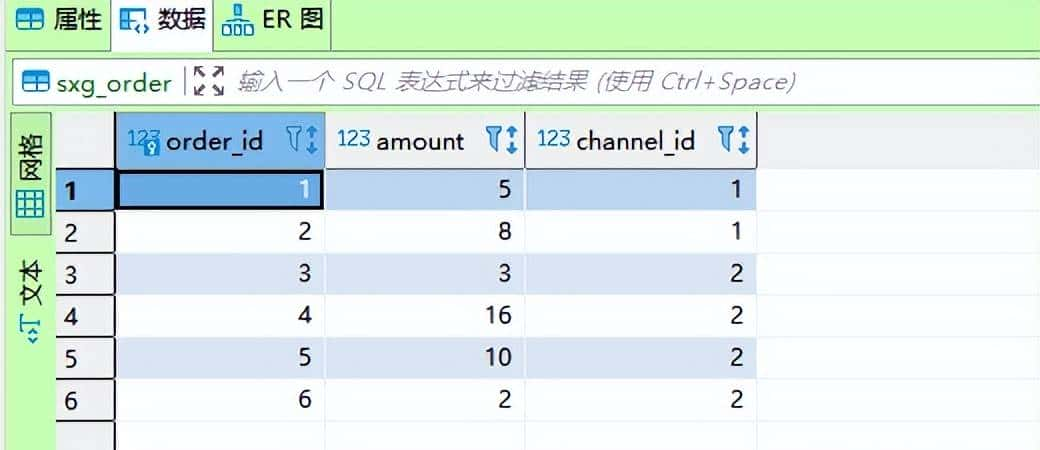
② 创建订单汇总表按渠道(channel_id )统计订单量:
CREATE TABLE `sxg_order_sum` (
`channel_id` int(11) NOT NULL COMMENT '渠道ID',
`sum_amount` bigint(20) NOT NULL COMMENT '汇总订单量',
`udpate_time` datetime NOT NULL COMMENT '更新时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf83.2 编写 Flink SQL 脚本
① 使用 set 对一些参数进行配置。
② 使用 HiveCatalog 做存储元数据,也可以不使用。
③ 使用 CDC Connector 定义源表。
④ 使用 Table Connector 定义目标表。
⑤ 将按渠道会总后的数据写入订单汇总表,这里用了一个系统内置函数,获取当前时间。
-- 设置 job 名称
SET 'pipeline.name' = 'sxg_cdc_job';
-- 设置 checkpoint
SET 'execution.checkpointing.interval' = '300s';
-- 使用 HiveCatalog 存储元信息
CREATE CATALOG hiveCatalog
WITH (
'type' = 'hive',
'default-database' = 'tmp',
'hive-conf-dir' = '/app/hive/conf'
);
USE CATALOG hiveCatalog;
-- 使用 tmp 库
USE tmp;
-- 使用 CDC Connector 定义源表
DROP TABLE IF EXISTS sxg_cdc_order;
CREATE TABLE sxg_cdc_order (
order_id BIGINT,
amount BIGINT,
channel_id INT,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '10.112.182.11',
'port' = '3306',
'username' = 'root',
'password' = 'root_use68pw9esd',
'database-name' = 'test',
'table-name' = 'sxg_order',
'server-id' = '1'
);
-- 使用 Table Connector 定义目标表
DROP TABLE IF EXISTS sxg_cdc_order_sum;
CREATE TABLE sxg_cdc_order_sum(
channel_id INT,
sum_amount BIGINT,
update_time TIMESTAMP(3),
PRIMARY KEY (channel_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://10.112.182.11:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false',
'table-name' = 'sxg_order_sum',
'username' = 'root',
'password' = 'root_use68pw9esd'
);
-- 将会总后的数据写入订单汇总表
INSERT INTO sxg_cdc_order_sum
SELECT channel_id,sum(amount),LOCALTIMESTAMP
FROM sxg_cdc_order
GROUP BY channel_id;关于 Flink SQL、函数等的使用方法,回顾 【Flink 系列十二】Flink Table & SQL 实践原理(下)
3.3 导入所需依赖包
到 Flink CDC 项目网站,下载本例所需要(MySQL CDC Connector)的 jar 包,并导入到目录 ${flink.version}/lib/ 下:
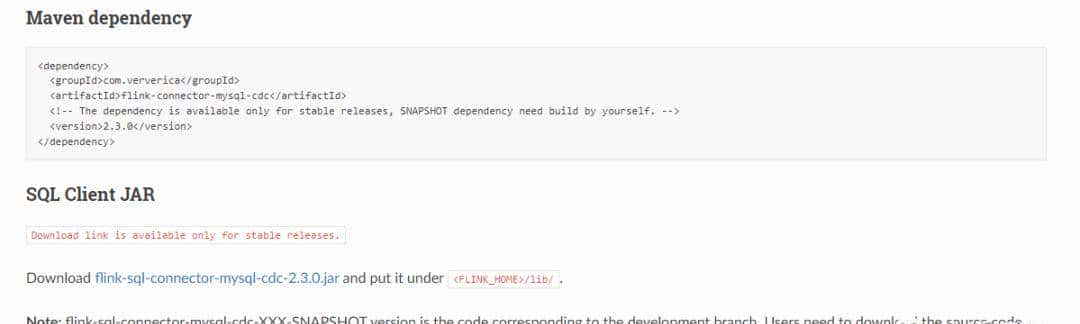
下载地址:
https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mongodb-cdc/
3.4 执行 SQL 脚本,提交作业
第一启动 Flink SQL Client,将 3.2 部分的 SQL 保存为,cdc.sql 的文件,可以将程序依赖的 jar 包放到 lib 目录。
关于 SQL Client 的配置和使用参考:【Flink 系列十一】Flink Table & SQL 实践原理(中) 第 3 部分内容。
① 使用 -f 选项,执行上边编写的 SQL 脚本。
./bin/sql-client.sh embedded -s yarn-session -f cdc.sql -l ./lib
② 执行命令,提交作业,以下为提交打印的日志。
[root@hktest-client-01 flink-sql-client]# vim cdc.sql
[root@hktest-client-01 flink-sql-client]# /app/arch-pkg/flink-1.16.1/bin/sql-client.sh embedded -s yarn-session -f cdc.sql -l ./lib
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/app/arch-pkg/flink-1.16.1/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/app/arch-pkg/hadoop-3.1.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2023-05-25 16:46:40,832 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2023-05-25 16:46:40,832 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
[INFO] Executing SQL from file.
Command history file path: /root/.flink-sql-history
Flink SQL> [INFO] Session property has been set.
Flink SQL> [INFO] Session property has been set.
Flink SQL>
>
> -- 使用 HiveCatalog 存储元信息
> CREATE CATALOG hiveCatalog
> WITH (
> 'type' = 'hive',
> 'default-database' = 'tmp',
> 'hive-conf-dir' = '/app/hive/conf'
> )[INFO] Execute statement succeed.
Flink SQL> [INFO] Execute statement succeed.
Flink SQL> [INFO] Execute statement succeed.
Flink SQL> [INFO] Execute statement succeed.
Flink SQL>
> CREATE TABLE sxg_cdc_order (
> order_id BIGINT,
> amount BIGINT,
> channel_id INT,
> PRIMARY KEY (order_id) NOT ENFORCED
> ) WITH (
> 'connector' = 'mysql-cdc',
> 'hostname' = '10.112.182.11',
> 'port' = '3306',
> 'username' = 'data_api_user',
> 'password' = 'api_use68pw9esd',
> 'database-name' = 'test',
> 'table-name' = 'sxg_order'
> )[INFO] Execute statement succeed.
Flink SQL> [INFO] Execute statement succeed.
Flink SQL>
> CREATE TABLE sxg_cdc_order_sum(
> channel_id INT,
> sum_amount BIGINT,
> update_time AS PROCTIME(),
> PRIMARY KEY (channel_id) NOT ENFORCED
> ) WITH (
> 'connector' = 'jdbc',
> 'url' = 'jdbc:mysql://10.112.182.11:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false',
> 'table-name' = 'sxg_order_sum',
> 'username' = 'data_api_user',
> 'password' = 'api_use68pw9esd'
> )[INFO] Execute statement succeed.
Flink SQL>
>
> -- 将会总后的数据写入订单汇总表
> INSERT INTO sxg_cdc_order_sum
> SELECT channel_id,sum(amount)[INFO] Submitting SQL update statement to the cluster...
2023-05-25 16:46:47,297 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/app/arch-pkg/flink-1.16.1/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2023-05-25 16:46:47,602 INFO org.apache.hadoop.yarn.client.AHSProxy [] - Connecting to Application History server at hktest-admin5/10.112.185.18:10201
2023-05-25 16:46:47,614 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2023-05-25 16:46:47,616 WARN org.apache.flink.yarn.YarnClusterDescriptor [] - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2023-05-25 16:46:47,661 INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider [] - Failing over to rm2
2023-05-25 16:46:47,716 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hktest-admin1:8082 of application 'application_1656075154719_109037'.
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 2817c919f3e32e743a25067c05de8c87
Flink SQL>
Shutting down the session...
done
③ 启动过程中可能遇到的问题(如果启动成功,忽略此步):
【问题1】MySQL CDC Connector 不支持 Mysql <=5.5 的版本:
Caused by: org.apache.flink.table.api.ValidationException: Currently Flink MySql CDC connector only supports MySql whose version is larger or equal to 5.6, but actual is 5.5.
at com.ververica.cdc.connectors.mysql.MySqlValidator.checkVersion(MySqlValidator.java:117) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.ververica.cdc.connectors.mysql.MySqlValidator.validate(MySqlValidator.java:78) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.ververica.cdc.connectors.mysql.source.MySqlSource.createEnumerator(MySqlSource.java:170) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at org.apache.flink.runtime.source.coordinator.SourceCoordinator.start(SourceCoordinator.java:213) ~[flink-dist-1.16.1.jar:1.16.1]
at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator$DeferrableCoordinator.applyCall(RecreateOnResetOperatorCoordinator.java:315)
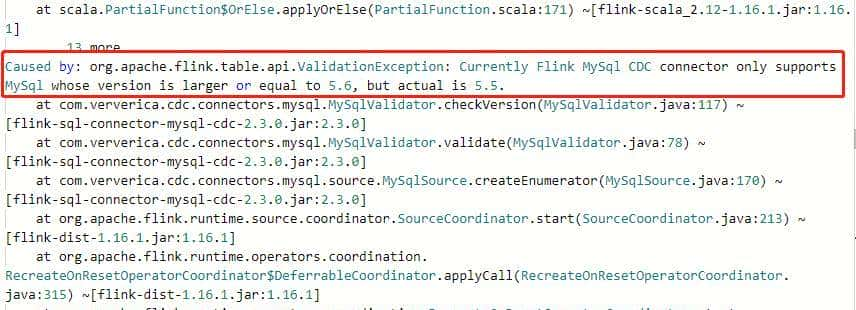
【解决】通过官方文档提供连接器,选择支持的 MySQL 版本。
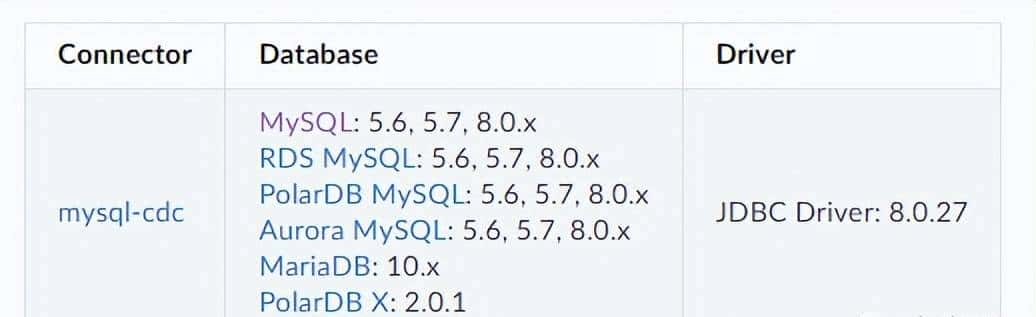
【问题2】确认 MySQL 的 binlog 是否开启:
org.apache.flink.table.api.ValidationException: The MySQL server is configured with binlog_format STATEMENT rather than ROW, which is required for this connector to work properly. Change the MySQL configuration to use a binlog_format=ROW and restart the connector.
at com.ververica.cdc.connectors.mysql.MySqlValidator.checkBinlogFormat(MySqlValidator.java:134) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.ververica.cdc.connectors.mysql.MySqlValidator.validate(MySqlValidator.java:79) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.ververica.cdc.connectors.mysql.source.MySqlSource.createEnumerator(MySqlSource.java:170) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at org.apache.flink.runtime.source.coordinator.SourceCoordinator.start(SourceCoordinator.java:213) ~[flink-dist-1.16.1.jar:1.16.1]
at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator$DeferrableCoordinator.applyCall(RecreateOnResetOperatorCoordinator.java:315) ~[flink-dist-1.16.1.jar:1.16.1]
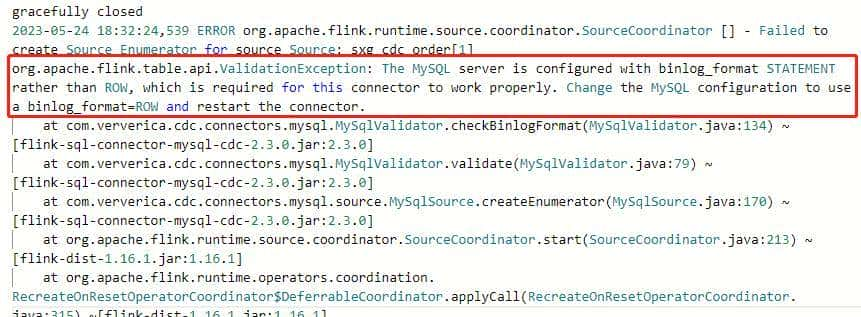
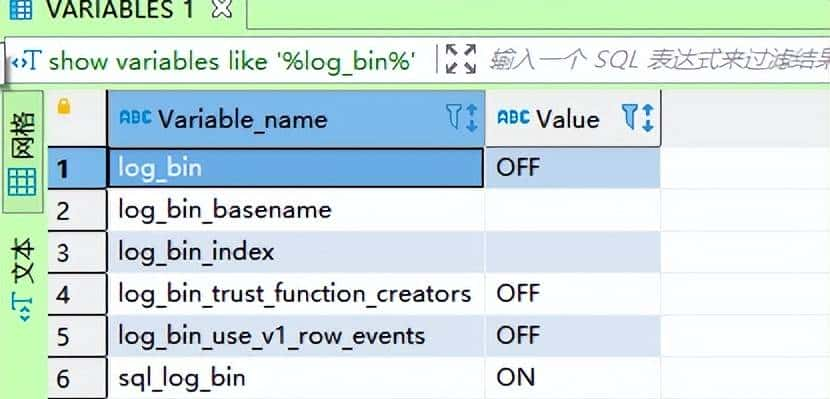
【解决】编辑 MySQL 配置文件 my.cnf,在 [mysqld] 下添加两行,log_bin=mysql_bin 和 binlog_format=”ROW”。
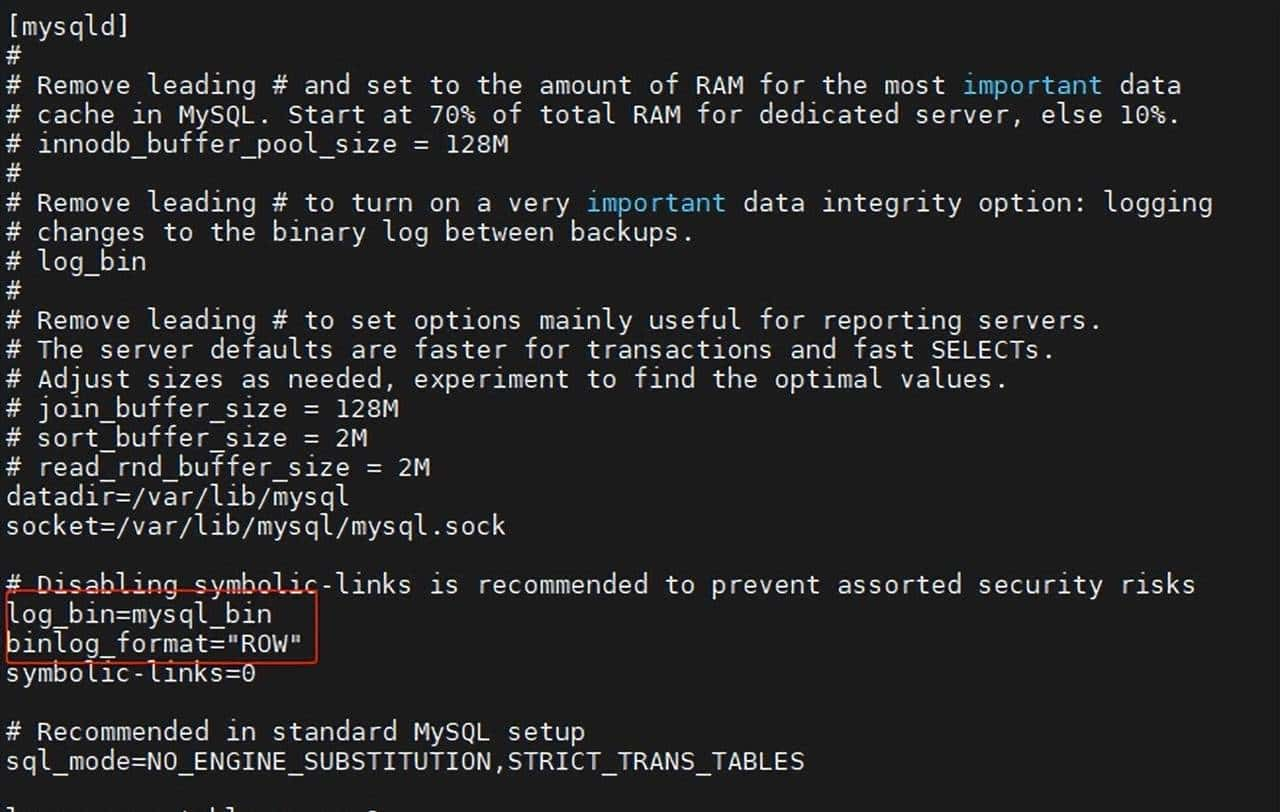
保存后退出,重启数据库服务 service mysqld restart。再次查看:
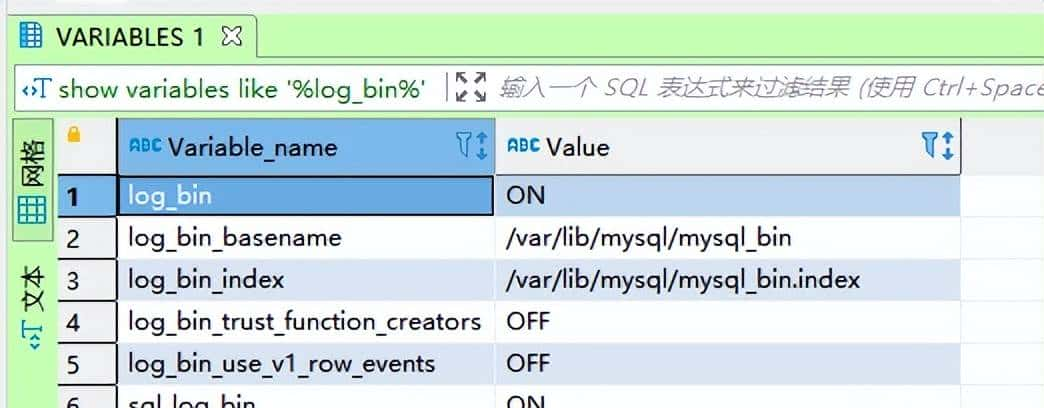
【问题3】MySQL 用户权限的问题:
Caused by: java.sql.SQLSyntaxErrorException: Access denied; you need (at least one of) the SUPER, REPLICATION CLIENT privilege(s) for this operation
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.mysql.cj.jdbc.StatementImpl.executeQuery(StatementImpl.java:1206) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at io.debezium.jdbc.JdbcConnection.queryAndMap(JdbcConnection.java:648) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
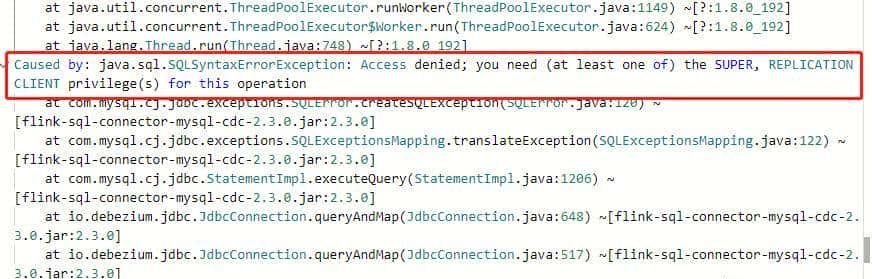
【解决】使用 root 用户或者给普通用户赋予权限(super 或者 replication client)。这里,我直接切换到 root 用户(后一种方式没有尝试)。
【问题4】没有配置 server-id
Caused by: io.debezium.DebeziumException: Misconfigured master – server_id was not set Error code: 1236; SQLSTATE: HY000.
at io.debezium.connector.mysql.MySqlStreamingChangeEventSource.wrap(MySqlStreamingChangeEventSource.java:1383) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at io.debezium.connector.mysql.MySqlStreamingChangeEventSource$ReaderThreadLifecycleListener.onCommunicationFailure(MySqlStreamingChangeEventSource.java:1439) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.github.shyiko.mysql.binlog.BinaryLogClient.listenForEventPackets(BinaryLogClient.java:980) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.github.shyiko.mysql.binlog.BinaryLogClient.connect(BinaryLogClient.java:599) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.github.shyiko.mysql.binlog.BinaryLogClient$7.run(BinaryLogClient.java:857) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
… 1 more
Caused by: com.github.shyiko.mysql.binlog.network.ServerException: Misconfigured master – server_id was not set
at com.github.shyiko.mysql.binlog.BinaryLogClient.listenForEventPackets(BinaryLogClient.java:944) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.github.shyiko.mysql.binlog.BinaryLogClient.connect(BinaryLogClient.java:599) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
at com.github.shyiko.mysql.binlog.BinaryLogClient$7.run(BinaryLogClient.java:857) ~[flink-sql-connector-mysql-cdc-2.3.0.jar:2.3.0]
… 1 more
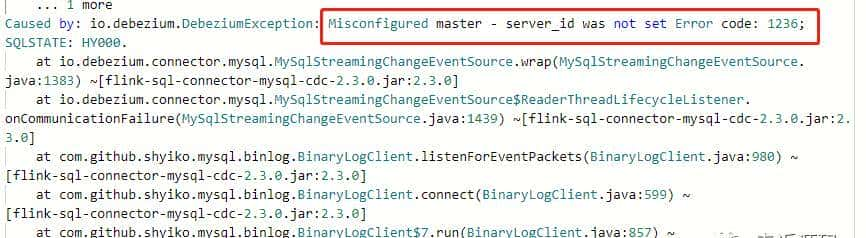
【解决】修改 MySQL 配置 my.cnf,增加 “server-id=1”。
3.6 查看运行状态及结果:
① 查看作业运行情况:
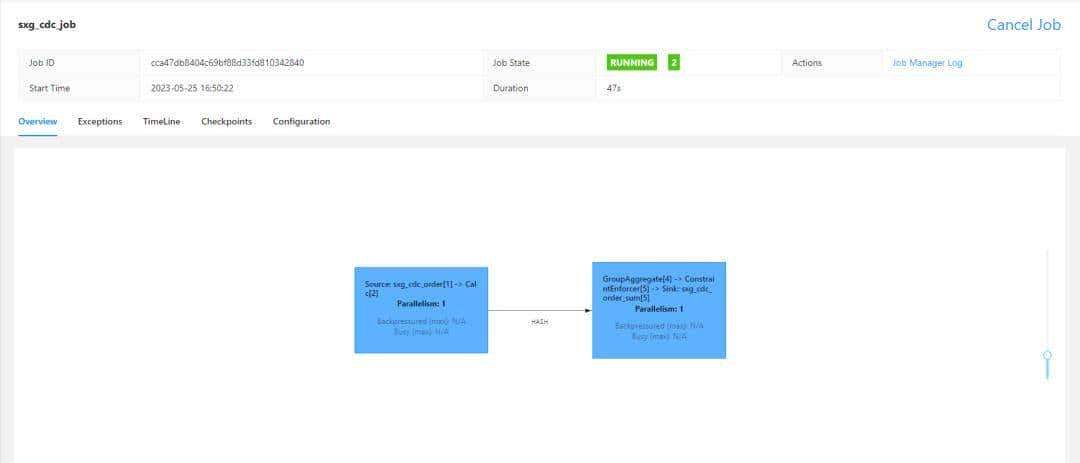
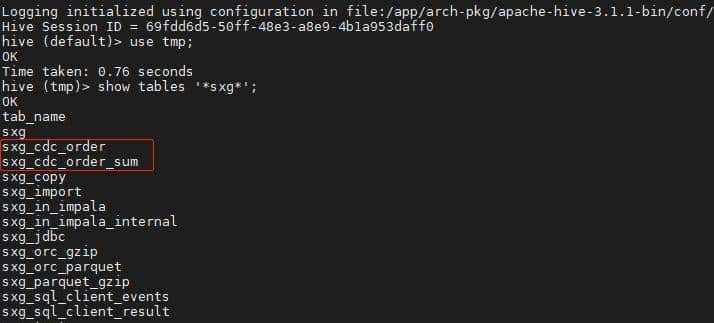
② 查看源表和目标 2 个表,在 Hive 中的元数据信息:
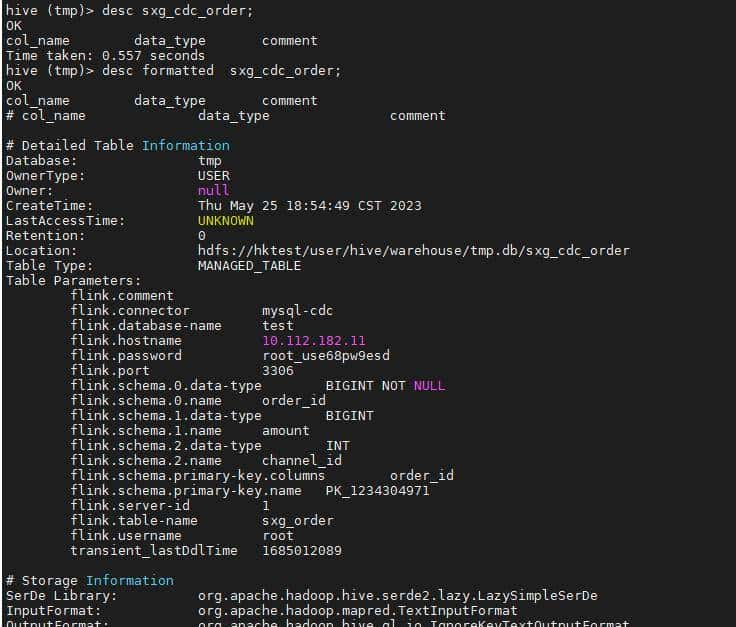
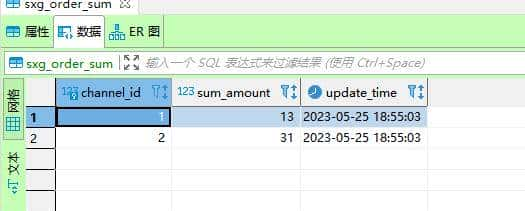
③ 查看 MySQL 中 sxg_order_sum 表的数据:
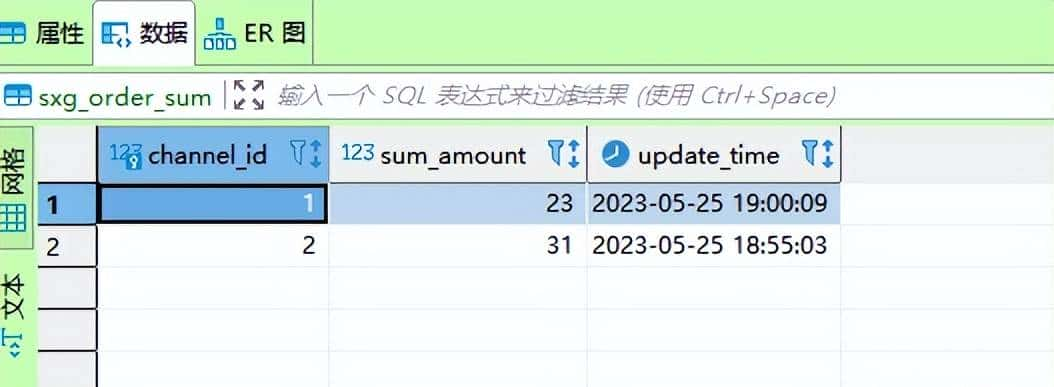
④ 对源订单表,再写入有一条数据,查看数据变化:
INSERT INTO test.sxg_order (amount,channel_id) VALUES (10,1);
⑤ 此时,订单汇总表变为:
4. 与传统 CDC ETL 对比分析
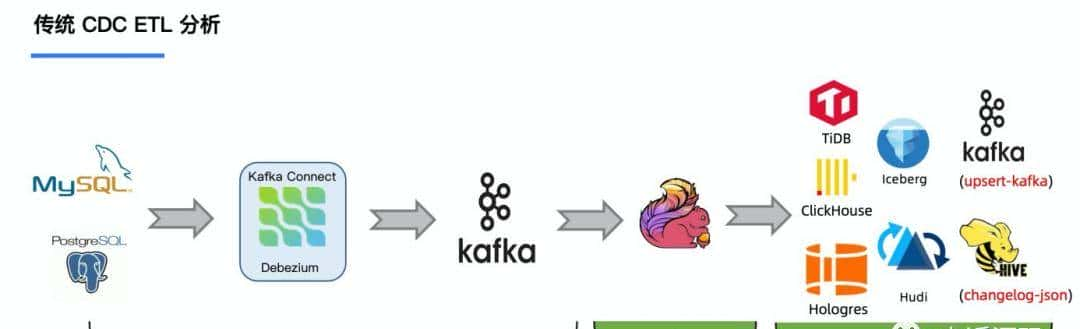
传统的基于 CDC 的 ETL 分析中,数据采集一般使用 Debezium、Canal 等工具,负责采集数据库的增量数据,一些采集工具也支持全量数据同步。采集到的数据一般输出到消息中间件如 Kafka,然后 Flink 计算引擎再去消费数据并写入到目的端,目的端可以是各种数据库、数据仓库、数据湖和消息队列等。
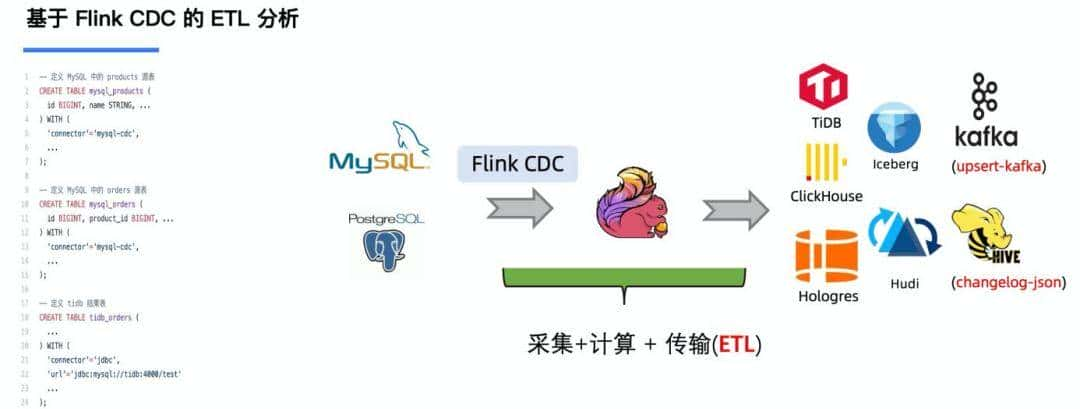
使用了 Flink CDC 之后,替换了传统 CDC 链路当中采集组件和消息队列,组件更少,维护更方便。同时更少的组件也意味着数据时效性能够进一步提高。
除此之外, Flink SQL 极大地降低了用户使用门槛,通过一个纯 SQL 作业,就可以完成数据清洗、分析和聚合。此外,利用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法可以很容易地完成数据打宽及各种业务的逻辑加工。
为什么 Flink 做 CDC,从技术上看有着天然的匹配性?
前面文章介绍过 Flink 两个基础概念:Dynamic Table 和 Changelog Stream。
关于 Dynamic Table 回顾:【Flink 系列十】Flink Table & SQL 实践原理(上)第 2 部分。
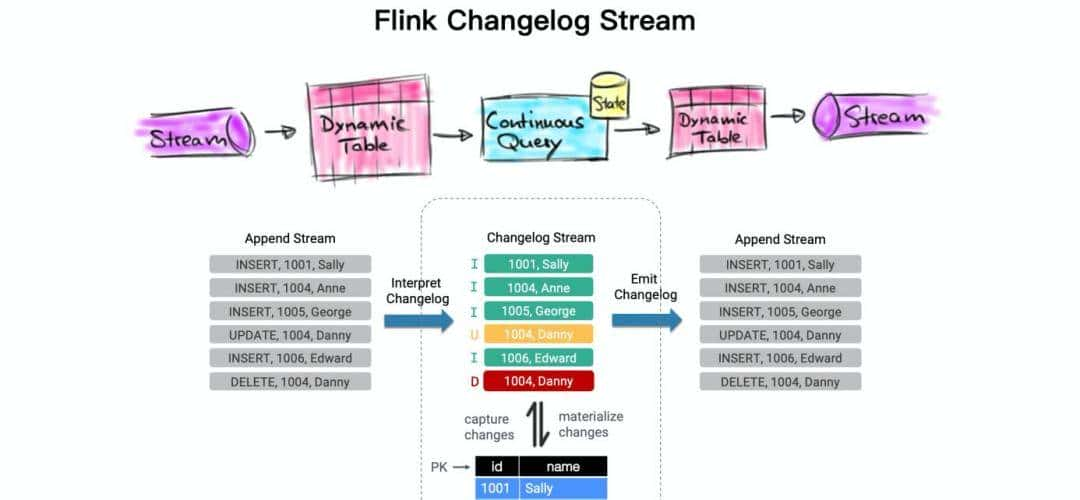
如上图所示,Dynamic Table 和 Stream 是相对应的,并且可以相互转化。在 Flink SQL 中,数据在从一个算子流向另外一个算子时都是以 Changelog Stream 的形式,任意时刻的 Changelog Stream 可以生成一个表,也可以生成为一个流。
而数据库的 binlog 日志,也一直不断的追加数据库所有的变更,这种日志流就是将表的变更数据持续捕获的结果。这可以很自然的由 Flink SQL 的 Dynamic Table 来表明。
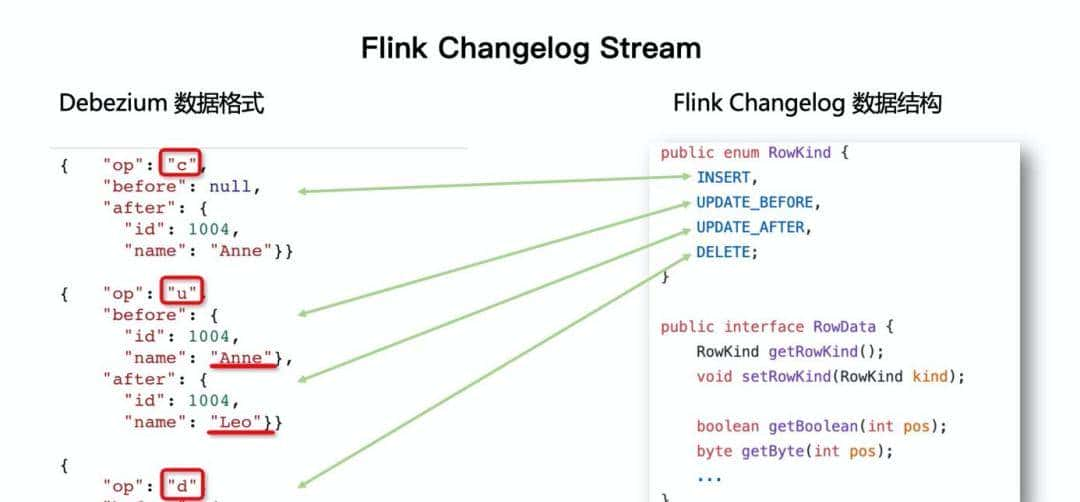
我们知道,Flink CDC 采用 Debezium 作为底层采集技术,它的数据结构与 Flink SQL 的内部数据结构 RowKind 超级类似,可以超级方便地对接起来。
每条 RowData 都有一个元数据 RowKind,包括 4 种类型, 分别是插入 (INSERT)、更新前镜像 (UPDATE_BEFORE)、更新后镜像 (UPDATE_AFTER)、删除 (DELETE),这四种类型和数据库里面的 binlog 概念保持一致。
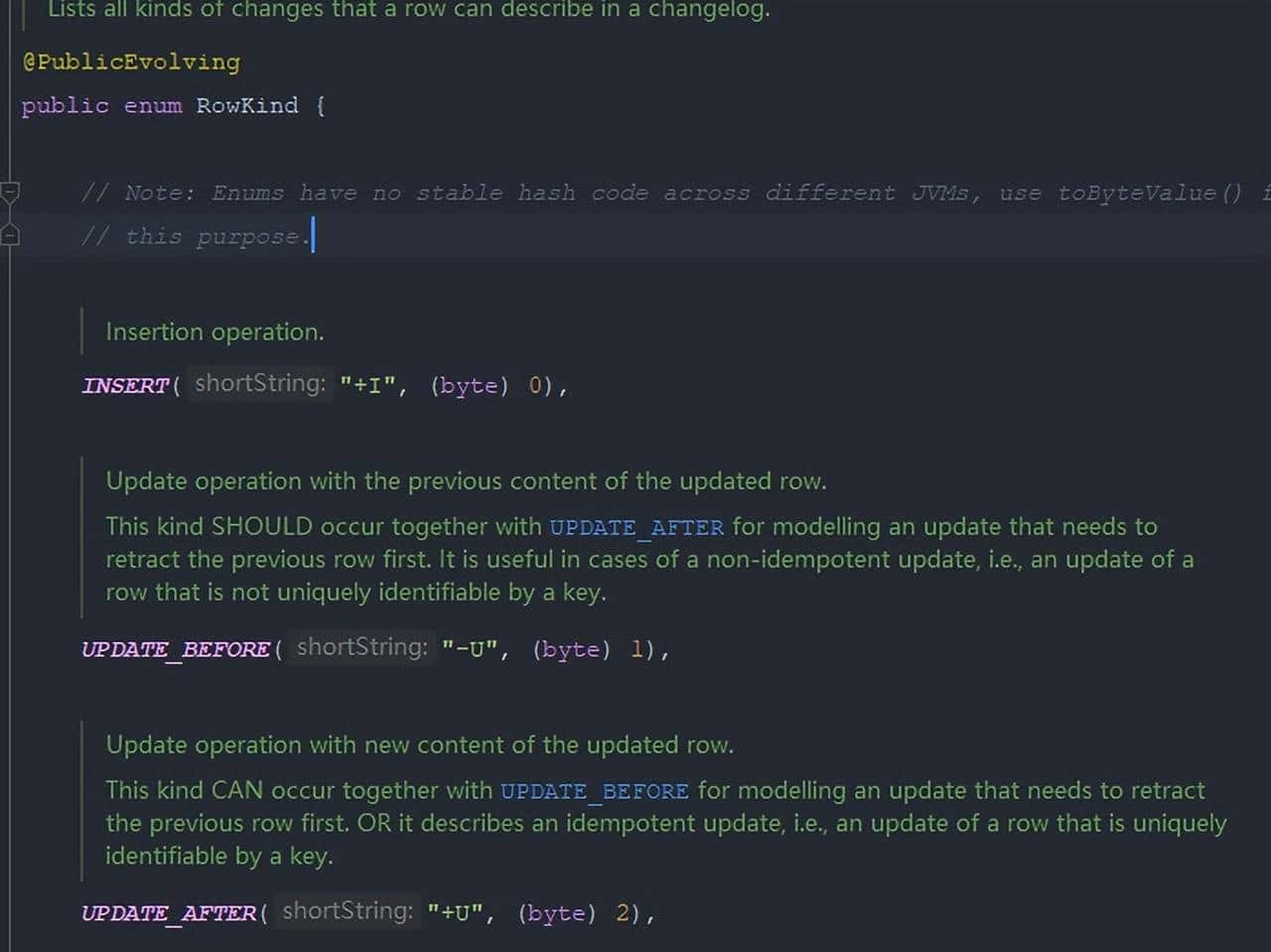
而 Debezium 的数据结构,也有一个类似的元数据 op 字段, op 字段的取值也有四种,分别是 c、u、d、r,各自对应 create、update、delete、read。对于代表更新操作的 u,其数据部分同时包含了前镜像 (before) 和后镜像 (after)。
5. 学习资料
【1】项目文档:
https://ververica.github.io/flink-cdc-connectors/master
【2】项目 git 地址:
https://github.com/ververica/flink-cdc-connectors
【3】Flink CDC 新一代数据集成框架:
https://developer.aliyun.com/topic/download?spm=a2csy.flink.0.0.cf655badCs6svP&id=8256
【4】Debezium 官方文档:
https://debezium.io

















- 最新
- 最热
只看作者