

目录
导读
一、MNIST数据揭秘:70,000张手写数字的奥秘
1. 数据加载:5行代码获取经典数据集
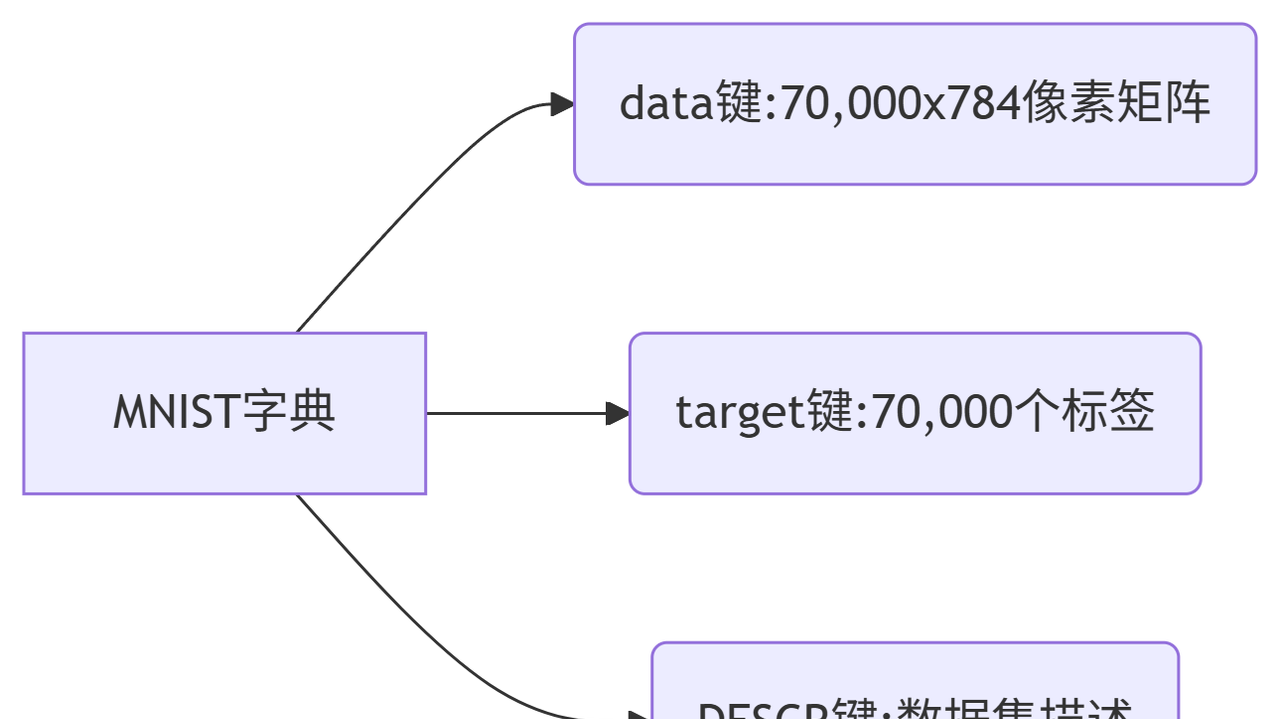
2. 数据结构解析(图解)
3. 像素的秘密:28×28的数字世界
二、数据预处理:模型训练前的关键步骤
1. 标签类型转换:字符串→整数
2. 数据集划分:官方预设 vs 自定义
3. 为什么要混洗数据?
三、数据可视化:一眼看懂数字特征
1. 多数字对比展示(代码模板)
2. 像素强度分布直方图
四、避坑指南:新手必知的5大陷阱
标签类型陷阱
数据顺序依赖
维度误解
测试集污染
内存爆炸
导读
手写数字识别是机器学习的经典入门项目,堪称AI界的“Hello World”。本文将以MNIST数据集为核心,手把手带你完成数据加载、探索、预处理全流程,并揭秘数据混洗的重要性。文末附数字可视化代码与数据处理思维导图,新手也能轻松上手机器学习!
一、MNIST数据揭秘:70,000张手写数字的奥秘
1. 数据加载:5行代码获取经典数据集
from sklearn.datasets import fetch_openml
# 国内镜像加速下载(避免卡顿)
mnist = fetch_openml('mnist_784', version=1, parser='auto',
data_home='https://m.openml.org/')
X, y = mnist.data, mnist.target
print(f"数据维度:{X.shape}") # (70000, 784)
print(f"标签示例:{y[:5]}") # ['5' '0' '4' '1' '9']2. 数据结构解析(图解)
3. 像素的秘密:28×28的数字世界
import matplotlib.pyplot as plt
# 随机抽取一个数字
index = 42
digit_image = X.iloc[index].values.reshape(28, 28)
plt.imshow(digit_image, cmap='binary')
plt.title(f"标签值:{y[index]}")
plt.axis('off')
plt.show()二、数据预处理:模型训练前的关键步骤
1. 标签类型转换:字符串→整数
坑点警示:Scikit-Learn的多数分类器不接受字符串标签!
import numpy as np
y = y.astype(np.uint8) # 转换为0-9的整数2. 数据集划分:官方预设 vs 自定义
# 官方预设划分(前6万训练,后1万测试)
X_train, X_test = X[:60000], X[60000:]
y_train, y_test = y[:60000], y[60000:]
# 自定义混洗(解决顺序依赖问题)
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train.iloc[shuffle_index], y_train[shuffle_index]3. 为什么要混洗数据?
| 场景 | 未混洗风险 | 混洗解决方案 |
|---|---|---|
| 交叉验证 | 某些折叠可能缺失特定数字 | 确保数据分布均匀 |
| 梯度下降优化 | 连续相似样本导致震荡 | 打乱样本顺序 |
| 模型评估 | 测试集特性与训练集不一致 | 反映真实数据分布 |
三、数据可视化:一眼看懂数字特征
1. 多数字对比展示(代码模板)
plt.figure(figsize=(10,8))
for i in range(25):
plt.subplot(5,5,i+1)
plt.imshow(X_train.iloc[i].values.reshape(28,28), cmap='binary')
plt.title(f"Label: {y_train[i]}")
plt.axis('off')
plt.tight_layout()
plt.show()2. 像素强度分布直方图
plt.hist(X_train.iloc[0], bins=50, color='steelblue')
plt.xlabel('像素强度(0-255)')
plt.ylabel('出现次数')
plt.title('单个数字的像素强度分布')四、避坑指南:新手必知的5大陷阱
标签类型陷阱
错误:直接使用字符串标签训练模型
正确:y = y.astype(np.uint8)
数据顺序依赖
错误:按原始顺序训练SGD分类器
正确:始终在训练前混洗数据
维度误解
错误:将784维特征视为28×28数组
正确:.reshape(28,28)恢复图像结构
测试集污染
错误:在划分前进行全局标准化
正确:先划分再分别处理训练/测试集
内存爆炸
错误:用plt.imshow()显示全部7万张图片
正确:采样可视化(如X_train[:100])
五、获取数据集
包含手写数字的 MNIST 数据库 – Azure Open Datasets | Microsoft Learn
© 版权声明
文章版权归作者所有,未经允许请勿转载。如内容涉嫌侵权,请在本页底部进入<联系我们>进行举报投诉!
THE END




















暂无评论内容